この記事はNTTコミュニケーションズ Advent Calendar 2020の22日目の記事です。昨日は @xkumiyu さんのAmazon ECSとALBを利用した推論APIサーバの負荷分散でした。
はじめに
NTTコミュニケーションズでCI/CDインフラの開発をしている @jmaxi です。
今日は、普段私が利用しているInfrastructure as Codeの新しい形について思うところを書かせていただきます。
具体的には、Infrastructure as Codeを取り巻く状況 (宣言的API、Configuration as Data) についての考えを述べた後、CUEと呼ばれる新しいデータ記述言語を活用して、DevOpsを超えたユースケースでInfrastructure as Codeを実践してみたいと思います。
Google Cloud Buildを使って、@xkumiyu さんも紹介したTensorFlow Servingを実行するちょっと変わったデモを用意しています。
DevOpsのためのInfrastructure as Code
Infrastructure as Codeはインフラをソフトウェアと同じように取り扱うプラクティスです。具体的には、インフラ構築を自動化し、かつ何度でも再利用・再現可能にするための設定ファイルやコード/スクリプトに対して、バージョンコントロール、コードレビュー、試験、モジュール化などといった、ソフトウェア開発のプラクティスを適用します。つまり、ソフトウェア開発者のインターフェースとしてInfrastructure as Codeを定義し、ソフトウェアでインフラの課題を解こうという考え方です。
Cloudサービスが広がったことにより、Infrastructure as Codeの適用範囲が拡大しています。Oreillyの最新の調査結果を見ると、マイクロサービス技術を活用している企業は61%に登っており、分散されたアプリケーションを管理するためのスケーラブルな方式の需要が高まっていると考えることができます。さらには、アプリケーション自体の作り方も変わってきています。自分たちではデータストアを管理せずにManaged RDBサービスを利用するような、目的に沿ったデータストア/プラットフォームサービスを組み入れるアーキテクチャが増えてきており、Infrastructure as Codeにはそういったプラットフォームサービスの設定までもを取り扱うことが期待されています。
これらの背景から、DevOpsの現場では、アプリケーションのインフラとプラットフォームをスケーラブルに管理するために、Infrastructure as Codeを利用することが当たり前になってきています。事実、PuppetとCircleCIが報告した2020年のDevOps reportにおいても、効果的な変更管理を実現するための1つの要素として「変更点をCodeで書く」ことを挙げており、Infrastructure as Codeの重要性が分かります。言い換えると、Infrastructure as Codeなしでは、競争力のあるアプリケーションを開発し続けることが困難になっています。
ここでのInfrastructure as Codeでは、インフラ、プラットフォームの設定変更について、Terraformなどを使って適用する形が一般的です。つまり、DevOpsの工程の限られたタイミングにおいてのみ実行される、どちらかというと静的に活用されるケースが多いのですが、Infrastructure as Codeはもっと動的に活用できるのでは、というのが今日の主張です。
インフラ、プラットフォームが全て宣言的APIに
あえて極論に振ったタイトルをつけていますが、近年、インフラ管理(さらにはIT全体に)において、命令的(Imperative)から宣言的(Declarative)アプローチへのシフトが起きています。
宣言的なAPIを利用することで、ユーザは、背後のインフラの複雑な特性を意識することなく、インフラに対する期待値となる設定を渡すだけよくなるため、1つ1つのインフラ管理がシンプルになります。これにより、扱う範囲/コンポーネントが増えた場合でもスケーラブルにインフラやプラットフォームの管理ができることから、Infrastructure as Codeのツールでも宣言的アプローチを採用しているものが主流になりつつあります。Terraformがまさに宣言的ツールの代表格です。
この宣言的APIは、Software-Defined InfrastructureのコンテクストでCloudプロバイダがユーザにとって適切な抽象化を追求した結果でした。宣言的APIの裏では、インフラの複雑性を隠蔽するためのControl loopが動いています。Control loopの中で、インフラの状態を観察 (Observe)し、期待値との差分を計算(Diff)し、インフラを再設定(Feedback)することで、ユーザの期待値に収束するよう働きかけています。これらのControl loopは、しばしばCloudプロバイダやソフトウェア開発の土壌がある大きな組織でのみ実装・利用可能なものでした。AWSのエンジニアであるColm MacCárthaighのQConの発表を見て分かるように、CloudプロバイダはControl loopの実装の経験値・ノウハウをためており、一朝一夕で実現できるものではないことが容易に想像できます。事実、私もSDN (Software Defined Networking) コントローラの開発現場にいくつか参加してきましたが、Control loopを自分たちのものにするために膨大な努力が費やしていました。(機会があればこちらのトピックついてもいつか書いてみたいと思います。)
しかし、Kubernetesの登場により状況が一変します。Kubernetesは、Reconcile loopと呼ばれるControl loopを実装しており、コンテナ (Pod) の状態を観察し、コンテナ数を制御する (ReplicaSet) ような宣言的なAPIを実装しています。Kubernetesは、ユーザ自身で宣言的APIを実装できるプラットフォームとしての顔を持っており、ユーザが、このReconcile loopを使って簡単にコントローラを実装できるようなインターフェース・ツールセットを提供しています。実際、Kubernetesを使った宣言的APIの実装が増えてきており、これからもますます増えるのではないかと考えています。
このように、宣言的APIがユーザおよびInfrastructure as Codeに受け入れられ、かつControl loopの実装方式が広まった結果、これからも宣言的APIが増えていき、様々な抽象レベルでの宣言的APIがあふれるのではないかと考えています。さらには、宣言的APIを利用するための方式としてのInfrastructure as Codeが担う役割も増えてくると予想されます。
Infrastructure as Codeでデータを扱う
宣言的APIの世界は素晴らしいのですが、インフラやプラットフォームのコンポーネント1つ1つの設定を宣言し、それをそのままコードで管理する従来のInfrastructure as Codeでは、スケールしなくなってきています。YAMLファイルで設定を1つ1つ管理するのが辛くなるのは目に見えていますが、TerraformなどのDSLを使って効率化したとしても、設定を列挙していくアプローチには変わりはないため、どうしても設定の重複、競合、ずれ(Configration drift)などの課題が発生しやすくなり、一貫性を保つのが難しくなってきます。Terraformを利用していて、コンポーネントが増えるにつれてコードベースが大きくなり、1つ1つのリソース設定が追いかけづらくなった結果、コードのレビューが難しくなった、などといった経験はないでしょうか。これは、インフラやプラットフォーム1つ1つ設定を列挙していく形がソフトウェア開発者にとっての適切なインターフェースではなかった、すなわちソフトウェアでインフラの課題を解決するには別のインターフェースがある、という意味なのだと思います。
そのなか、Configuration as Dataについての議論を見るようになりました。Google Cloudは、自身のブログで、Kubernetes APIを通してGoogle Cloudのサービスを構築・設定できるConfig Connectorサービスを、スケーラブルなConfiguration as Dataとして紹介しています。これは、KubernetesのAPIを通して管理されるのはデータであり、Kubernetesの中で加工・収束させていく、より動的なものだ、という主張です。優れたエコシステムがあるKubernetesの宣言的APIで統合的にクラウドのAPIを管理できる点でとても魅力的なアプローチであり、Crossplaneも同様に、Kubernetes APIを通してMulti Cloudを管理するソリューションを提案しています。
ここで、Google Cloudの同記事では、Terraformを使ってGCP APIを写像しているKubernetes APIを実行しているため、ソフトウェア開発者のインターフェースとしてのInfrastructure as Codeという観点では、大きな改善になっていません。しかし、Configuration as Dataは、「インフラやプラットフォームの設定は、コードのように静的なものではなく、データのように動的なものである」、という考え方のシフトをもたらした点で注目すべきだと考えています。データは加工・処理を施してデータベースに保存するものであり、ソフトウェア開発者のインターフェースとしてGitにpushするものではありません。したがって、データを加工処理するためのツールやプラットフォームこそが、ソフトウェア開発者のインターフェースとなるInfrastructure as Codeの対象であると言えます。
データの加工処理にPythonなどの一般的なプログラミング言語を利用してもよいですが、データ処理に特化した言語・フレームワークが必要とされ、近年、Infrastructure as Codeで活用可能なデータ記述言語が増えてきています。その一部を以下に列挙していますが、そのなかでも動的にデータを生成するためにはCUEが適していると私は考えており、次の章でCUEのその最大の特徴の1つを使ったデモを紹介します。
- Jsonnet
- Kustomize
- Dhall
- Tanka
- CUE
CUE - データ処理に特化したソフトウェア開発者のための言語
CUEは、GoogleのMarcel van Lohuizenが作った、データ制約記述言語です。詳細はMarcelの講演に譲りますが、一貫性に重きをおいており、スケーラブルにデータを検証、結合、生成することができるのが特徴です。個人的には、複雑性を上げる原因となる継承やオーバーレイを認めていない点が好みです。
さらに、CUEは、豊富なGolang SDKを提供しており、CUEで生成したデータにかかる処理をGolangで書くことができます。つまり、動的にデータを生成するだけでなく、データをつかったオペレーション、APIまでをCUE-Golangの組み合わせで実装することが可能であり、それを実現させているCUEは強力な言語であると考えています。Infrastructure as Codeの対象としてCUEを捉えたとき、インフラの期待値・データを宣言するだけでなく、インフラをこれまで以上に動的にコントロールすることができるため、インフラやプラットフォームを活用したユースケースの幅が広がると考えています。
その一例として、Cloud Buildを使って、オンデマンドでコンピュートリソースを確保するデモを紹介します。
デモ: Cloud Buildを使った宣言的なPredictionツール
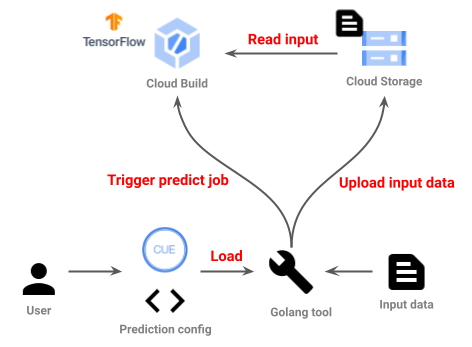
CUEとGolangを使ってデモアプリケーションを実装してみました。以下の構成図のように、CUEで書かれたPrediction設定をGolangのツールが読み取り、Google Cloud Buildを使ってTensorFlow ServingsのPredictionを実行します。ここで、Cloud Buildをどう実行するか、すなわちメインとなるCloud Buildの宣言的データの部分をCUEで書き、Cloud Build APIにそのデータを渡すドライバ相当の部分をGolangで書いています。また、Cloud Buildへのインプットを用意するために、Cloud Storageにデータをアップロードする前処理についてもGolangで書いています。
デモで実装したコードは全てこちらにおいていますので、興味があれば見てみてください。
https://github.com/j-maxi/declarative-tools/tree/20201222-blog
デモの実行自体はとてもシンプルで、以下のようにGolangでビルドされたバイナリ /bin/predict に、Prediction設定 config.cue を渡せば実行できます。今回実行しているPrediction modelは half_plus_two であり、単純に入力データを半分に割って2足すだけのサンプルであり、実際に以下の結果がそうなっていることが確認できます。
# Input file
$ cat sample-data.txt
1.0
5.0
3.5
2.0
8.0
8.0
4.0
5.5
5.0
# Execution
$ ./bin/predict config.cue
2020/12/22 01:11:45 Loading Predict instruction (id=e3862052).
2020/12/22 01:11:46 Uploading input file sample-data.txt.
2020/12/22 01:11:48 Writing input file to gs://predictor-sample/workspace-e3862052/input.tar.gz.
2020/12/22 01:11:49 Triggering CloudBuild.
2020/12/22 01:11:53 Build triggered with projects/531053117292/locations/global/builds/fe34d02e-db0e-45b8-a72b-6e67778b773f. Waiting for its completion.
2020/12/22 01:12:30 Downloading results.
2020/12/22 01:12:32 Prediction succeeded. Output written to output-e3862052.txt.
# check output
$ cat output-e3862052.txt
2.5
4.5
3.75
3
6
6
4
4.75
4.5
config.cue では以下のように、Predictionで利用する入力ファイルおよび推論モデルを宣言しています。
import (
"github.com/j-maxi/declarative-tools/predictor"
)
predictor.Predict & {
input: "sample-data.txt"
model: "half_plus_two"
}
Prediction設定の詳細は、上記 github.com/j-maxi/declarative-tools/predictor でimportしている元のCUEファイル predict/main.cue に記載しています。以下に、その実装の一部をお見せします。Predict.cloudbuild は、Cloud Buildの宣言部分であり、その中で複数のステップを宣言しています。具体的には、入力を整形するための _stepFormatInput やPredictionを実行する _stepPredict などがあります。_stepPredict の詳細については、snippet下部に示しており、ここで呼んでいる myserving Docker imageは、TensorFlow Servingを実行し、サンプルのモデルから結果を得るだけのシンプルな実装となっています。
package predictor
import (
cb "google.golang.org/genproto/googleapis/devtools/cloudbuild/v1:cloudbuild"
)
Predict: {
model: string
projectID: string // filled by go runtime
(skip)
cloudbuild: cb.#Build
cloudbuild: {
steps: [
_stepFormatInput,
_stepPredict,
_stepFormatOutput,
_stepSaveOutput,
]
(skip)
_stepPredict: {
name: "asia.gcr.io/\(projectID)/myserving:test"
args: [
"\(model)",
"input.json",
]
env: [
"MODEL_NAME=\(model)",
]
}
(skip)
}
}
上記で、cloudbuild: cb.#Build という記述がありますが、これはCloud Buildが提供するprotobufから生成したCUE schemaを適用している箇所であり、cloudbuild structで宣言しているデータについて、Cloud Build APIで定義しているものか、Validationをかけることができています。
次に、Golang側の実装を解説します。以下は、デモ実装を一部の処理部分をシンプル化したsnippetです。
ここでは、CUEファイルを読み出し、そのなかでcloudbuildの宣言部分を探し出しています。そこで宣言されたデータをgRPCのリクエストデータとしてエンコードしており、CUEで宣言したデータをシームレスにGolangで取り扱うことができています。
// Simplified snippet from man.go
var runtime cue.Runtime
// Load
builds := load.Instances([]string{file}, nil)
instance, _ := runtime.Build(builds[0])
// Read Cloud Build declaration
data := instance.Lookup("cloudbuild")
// Create gRPC request data
build := &cloudbuildpb.Build{}
var buf bytes.Buffer
// CUE to JSON
json.NewEncoder(&buf).Encode(data)
// JSON to Protobuf
jsonpb.Unmarshal(&buf, build)
さらには、以下のようにGolang側でCUEの宣言データにパラメータを注入しています。具体的には、Golang側で生成したIDを埋めたGoのstrcut PredictInfo をCUEのstructに変換し、CUEで記述したCloud Buildの宣言データに結合 (Unify) しています。CUEは継承やOverlayをサポートしておらず、結合時に全ての入力を同列のデータとして扱うため、それぞれで宣言したデータに衝突があった場合、エラーとなります。すなわち、今回のケースで、例えば ProjectID について、Golang側で注入する値とは異なる値をCUEの宣言データで指定していた場合、結合に失敗し、双方のデータに矛盾があることに気づけます。これは、一貫性を保つのに優位な制約であると考えています。
// Simplified snippet from main.go
var runtime cue.Runtime
// parameters to inject
info := PredictInfo{
PredictID: predictID,
ProjectID: googleProjectID,
}
// convert Go struct to CUE Value
codec := gocodec.New(&runtime, nil)
infoValue, _ := codec.Decode(info)
// Unify and finalize the Predict operation to deal with
val := instance.Value().Unify(infoValue)
以上の実装により、Infrastructure as Codeの主役としてCUEでCloud Buildのデータを生成しつつ、データを使った処理をGolang側に委譲することで、必要なときだけCloud Buildでコンピュートリソースを確保して、Prediction計算する、簡易サーバレスツールができました。
このように、CUEは、データを検証、結合、生成するために強力なデータ記述言語であり、さらにGolang SDKによってシームレスにCUEのオペレーションをGolang側で実行できることが大きな強みとなっています。CUEのデータをGolangで評価したその場でAPIを呼び出し、APIのステート監視するようなControl loopを実装することも可能であり、動的かつ高度なインフラ制御も期待できます。
最後に
宣言的APIが増えてInfrastructure as Codeの適用範囲が拡大するなかで、Infrastructure as Codeのインターフェースとしてインフラのデータを加工処理できるような言語を使っていくことで、従来までのInfrastructure as Codeで実現できていたスコープから飛躍していくことができると考えています。
Infrastructure as CodeをDevOpsでアプリケーションのデプロイ時だけしか使わない技術としてとらえるのではなく、アプリケーションで価値を生み続ける技術、として捉えた場合、これまで以上に動的に利用していく形になってもよいと思います。そして、CUEはそれを実現する可能性を持った言語であり、これからも使っていきたいと考えています。
なお、KubeCon EU 2020で私がNTT CommunicationsとしてCUEを使って取り組んでいる内容を発表させていただきました。もし興味があればそちらもご覧になっていただけると嬉しいです。
Deliver Your Cloud Native Application with Design Pattern as Code - Jun Makishi & Rintaro Sekino, NTT Communications
明日は、 @kawatom さんのIoTの注目株!EnOcean対応マルチセンサをクラウドで可視化するです。お楽しみに!
参考文献
- Microservice Adoption in 2020
- 2020 State of DevOps Report
- PID Loops and the Art of Keeping Systems Stable
- I do declare! Infrastructure automation with Configuration as Data
- Manage any infrastructure your applications need directly from Kubernetes
- CUE: a data constraint language and shoo-in for Go. Marcel van Lohuizen, Google.
- TensorFlow Serving with Docker