はじめに
本稿はLLMと会話を出来るようにしようと企んだ記事です。そこで、Alibaba Cloudでが開発しているモデルのQwenです。Qwen-ChatはOpenAIのChatGPTのようなものです。一部でそれより高性能だとか、詳しいアカデミックな情報は下記のリンクから確認してください。
Qwenと会話するための、DemoサイトなどもあるようですがAPIなど外部公開はされていないようです。では実装してしまえば良いじゃないか!ついでに、会話できるようにしてしまえば良いじゃないかという安易な考えで始めましたが結構時間が掛かりました(;^ω^)
結果として、Alibaba Cloudがてんこ盛りな記事になったと思います。
構成
最初はECSで構成しようと考えていましたが、ドキュメントを読む限りではDockerで実装が行えるようなので、じゃぁKubernetesで実装できるじゃないか?
と、いうことでACKを利用して実装してみるのと、テキストでの会話じゃ面白くないですよね?ということで音声で会話を行えるようにIntelligent Speech Interaction で合成音声も利用しています。
ACKはAlibaba CloudのマネージドKubernetesサービスです。
Intelligent Speech InteractionはSpeech系のAI系のサービス群です。
全体構成図
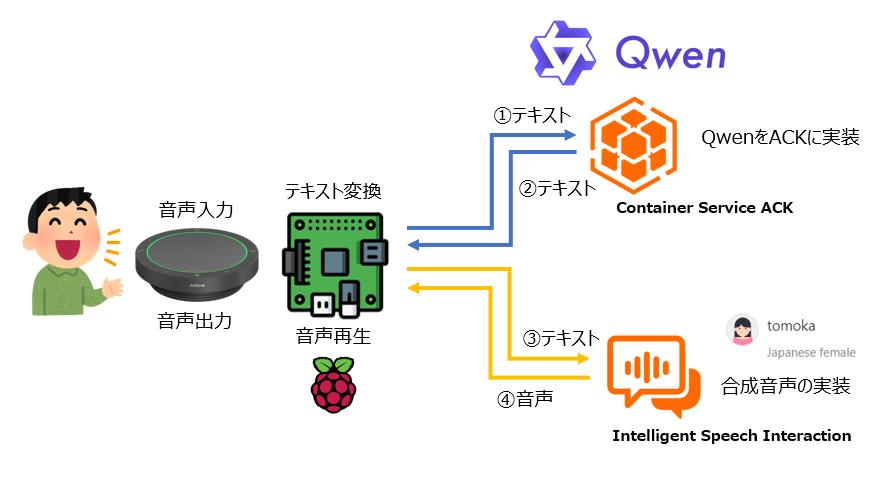
仕組み
以下のようにデータを取り扱っています。
- 音声入力
- 会話を入力するためのマイクです。
- テキスト変換
- Raspberry Pi 4で音声をテキストに変換しています。
- ACKに実装したQwenに入力
- Raspberry Pi 4で変換されたテキストをQwenに入力します。
- Qwenからの返答をRaspberry Pi 4に入力しIntelligent Speech Interactionに出力
- テキストをIntelligent Speech Interactionで合成音声に変換します。
- Intelligent Speech InteractionをRaspberry Pi 4に入力し音声出力
- 入力された音声をスピーカーで再生する。
大きく分けてQwenのACK実装とRaspberry Pi 4での合成音声の実装の2つのフェーズになります。
準備
Raspberry Pi 4
セットアップの方法は省略しますが以下のような構成です。
- Raspberry Pi OS with desktop (bookworm)
- デスクトップバージョンである必要があります。自分の環境はタッチパネルなど結構リッチな感じですw
- Pythonのバージョンが3.11以上にする必要があるためbookwormベースのものを選択します。
- UBS スピーカーマイク
- Jabra Speak2 55を利用しましたがRaspberry Pi OSで認識するものであればなんでも良いかと思います。
- Jabra Speak2 55を利用しましたがRaspberry Pi OSで認識するものであればなんでも良いかと思います。
ACKにQwenを実装
QwenをDockerで実装する場合にはローカルにモデルをダウンロードしてロードして利用します。
そこで、Kubernetesで実装するためにはローカルではなく外部のストレージをマウントして利用することにします。OSSをマウントします。
実装するための作業用にECSが必要です。ECSではモデルをダウンロードし、OSSをマウントしてアップロードします。
その後、ACKでOSSをマウントしモデル利用することとします。
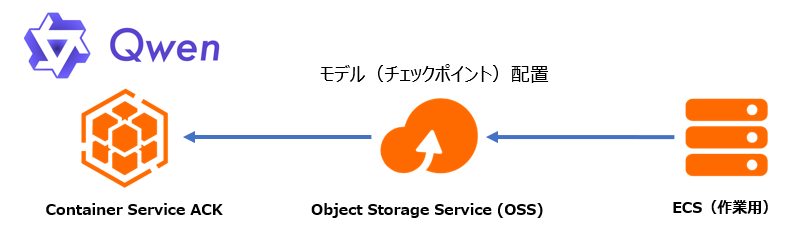
ECSでモデルのダウンロードとアップロード
モデルのダウンロード
ECS起動はUbuntu 22.04、ストレージは多めの100GBを確保しましょう。
ダウンロードは下記を参考に進めています。
GitからQwenをダウンロードします。
git clone https://github.com/QwenLM/Qwen.git
必要なものをインストールします
pip install -r requirements.txt
pip install modelscope
今回は最小モデルのQwen-7B-Chatモデルをダウンロードします。余裕がある人は上位のもをダウンロードするとよいと思います。
以下をmodel.pyとして保存します。
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# Downloading model checkpoint to a local dir model_dir
# model_dir = snapshot_download('qwen/Qwen-7B')
model_dir = snapshot_download('qwen/Qwen-7B-Chat')
# model_dir = snapshot_download('qwen/Qwen-14B')
# model_dir = snapshot_download('qwen/Qwen-14B-Chat')
# Loading local checkpoints
# trust_remote_code is still set as True since we still load codes from local dir instead of transformers
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
trust_remote_code=True
).eval()
.cache/modelscope/hub/qwen/にダウンロードされます
OSSの作成
OSSは名前だけ設定して作成します。その他は設定変更はありません。
モデルのアップロード
マウントの方法は下記を参考にしてください
モデルのアップロードにはAliyunOSSFullAccessの権限を持ったOpenAPIのユーザーを作成します。

作成直後に表示されるアクセスキーとシークレットをコピーしておきましょう。
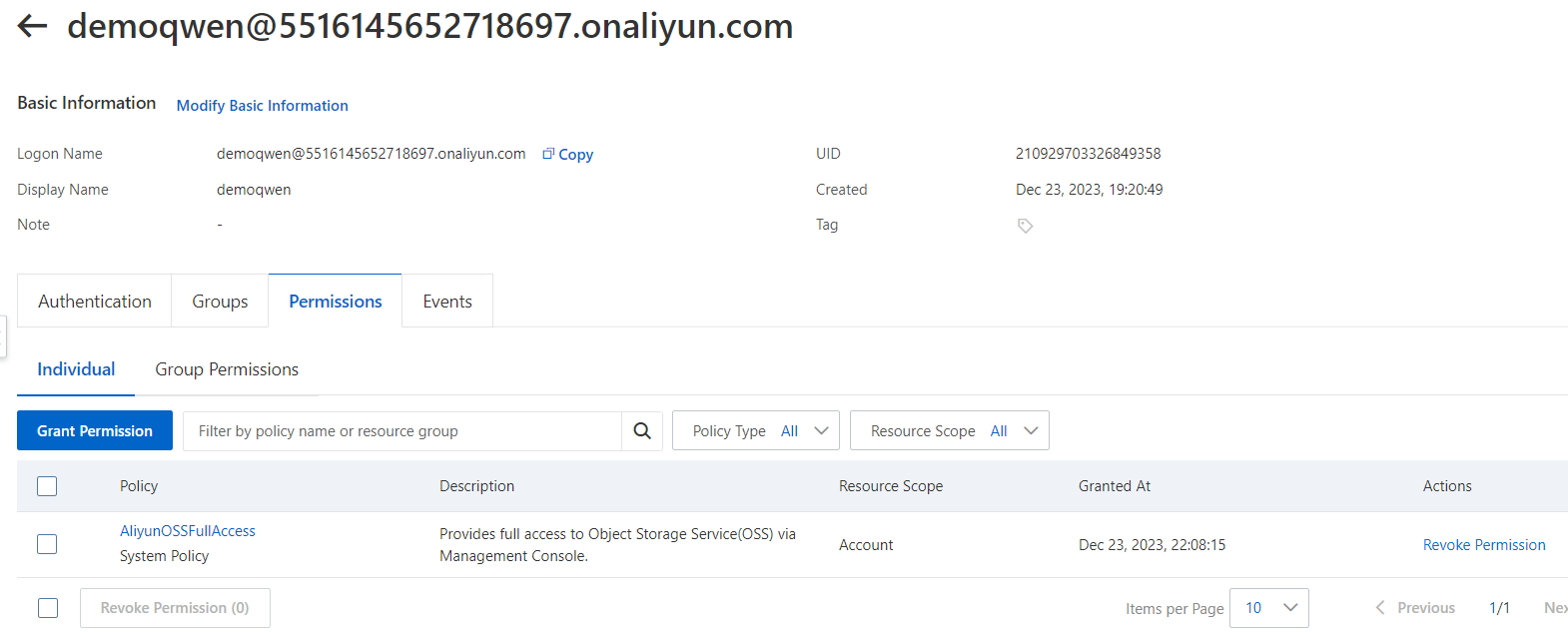
ユーザー作成後、ECSで以下のようにOSSをマウントしてダウンロードしたモデルをコピーします。
sudo echo BucketName:yourAccessKeyId:yourAccessKeySecret > /etc/passwd-ossfs
sudo chmod 640 /etc/passwd-ossfs
BucketNameは作成したOSSに読み替えてください。
yourAccessKeyId、yourAccessKeySecretは上記でコピーしたものに読み替えてください。
OSSマウントのossfsをダウンロードします。Ubutnu22.04バージョンです。
wget https://gosspublic.alicdn.com/ossfs/ossfs_1.91.1_ubuntu22.04_amd64.deb
gdebiでインストールします。
sudo apt-get install gdebi-core
sudo gdebi ossfs_1.91.1_ubuntu22.04_amd64.deb
マウントします。
sudo ossfs BucketName /tmp/ossfs -o url=http://oss-ap-northeast-1-internal.aliyuncs.com
BucketNameは読み替えてください。同一リージョンなのでinternalのURLです。異なるリージョン場合はインターネット経由のURLを利用します。OSSの画面で確認してください。
モデルをマウントしたOSSにコピーします。
mkdir /tmp/ossfs
cp -R .cache/modelscope/hub/qwen/ /tmp/ossfs/
以上でモデルの準備は完了です。
次にKubernetesを作成していきます。
ACKの作成とOSSのマウント
作成
ACKはJapanに作成します。
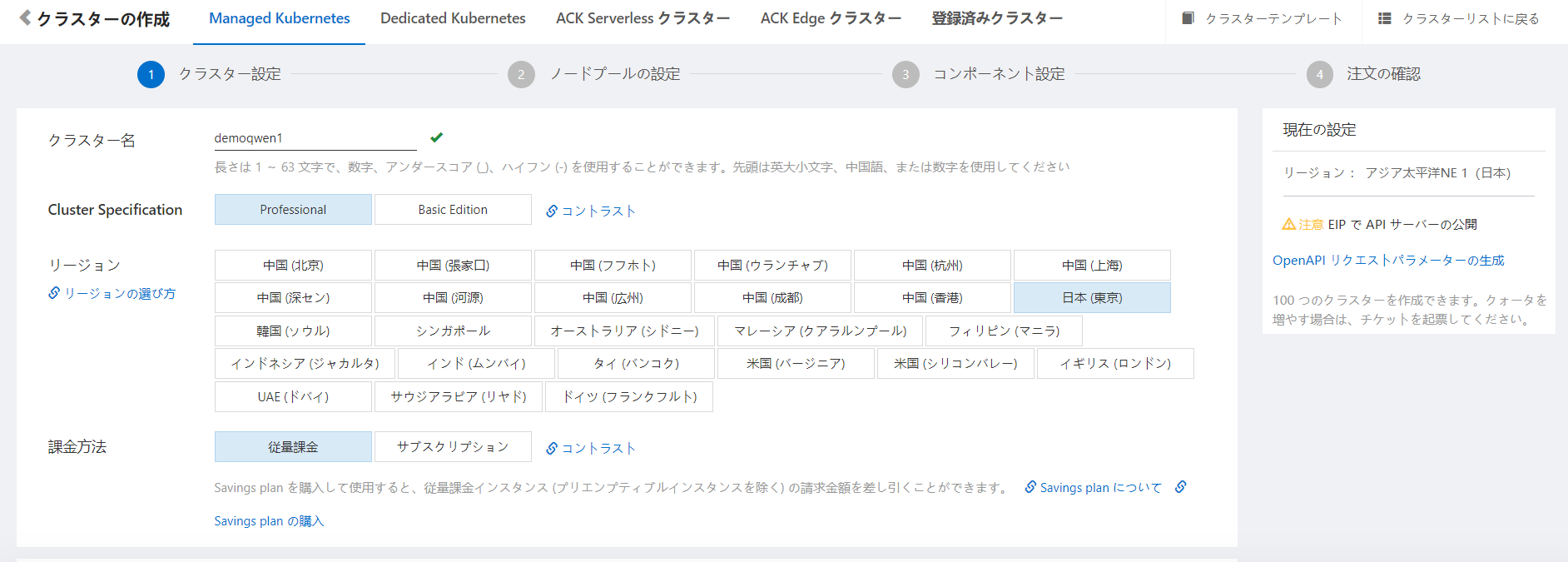
重要なのはインスタンスタイプです。GPUアクセラレーションを選択し、A10GPUを選択しましょう。A10以外では動作しないです。注意が必要です。そのためそれなりの価格になります。
またワーカーノードにはGPUドライバなどは、インストールされた状態のため関連作業はありません。
以上の設定で作成します。
OSSのマウント
デフォルトでは3つのワーカーノードが作成されます。それぞれのワーカーノードにOSSをマウントする必要があります(ひょっとしたらもっと良い方法があるかも)。
最初にワーカーノードの22番ポートを開けます。
ワーカーノードのセキュリティグループを開き追加します。

あとは各ワーカーノードに接続します。
接続後に前項のECSと同様にマウントします。ただしOSが異なるためダウンロードするものは異なります。Alibaba Cloud Linuxバージョンです。
wget https://gosspublic.alicdn.com/ossfs/ossfs_1.91.1_anolisos8.0_x86_64.rpm
マウントの認証情報を設定します。
sudo echo BucketName:yourAccessKeyId:yourAccessKeySecret > /etc/passwd-ossfs
sudo chmod 640 /etc/passwd-ossfs
BucketNameは作成したOSSに読み替えてください。
yourAccessKeyId、yourAccessKeySecretは上記でコピーしたものに読み替えてください。
インストールします。
yum install -y ./ossfs_1.91.1_anolisos8.0_x86_64.rpm
マウントします。
mkdir /tmp/ossfs
ossfs BucketName /tmp/ossfs -o url=http://oss-ap-northeast-1-internal.aliyuncs.com
BucketNameは作成したOSSに読み替えてください
3つワーカーノードある場合は全てで行います。
以上でモデルの準備は完了です。
Qwen-Chatのデプロイ
ここからはKubernetesの世界です。
kubectlのインストールや、ACKへの接続方法は省略します。各自調べてください。
QwenはOpenAIのAPI風に動作するように起動します。これはDocker Hubのイメージにスクリプトが含まれています。これを利用します。
下記のスクリプトをもとにKubernetesのデプロイ用のyamlに書き換えます。
イメージをデプロイするためdeploy.yamlとして以下を保存します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwen-deployment
spec:
replicas: 1
selector:
matchLabels:
app: qwen-app
template:
metadata:
labels:
app: qwen-app
spec:
containers:
- name: qwen-container
image: qwenllm/qwen:cu117
args: ["python", "openai_api.py", "--server-port", "80", "--server-name", "0.0.0.0", "-c", "/data/shared/Qwen/Qwen-Chat/"]
ports:
- containerPort: 80
volumeMounts:
- name: qwen-checkpoint
mountPath: /data/shared/Qwen/Qwen-Chat
volumes:
- name: qwen-checkpoint
hostPath:
path: /tmp/ossfs/qwen/Qwen-7B-Chat
作成します。イメージのサイズが大きく起動まで時間が掛かります。焦らずまちます。
kubectl apply -f deploy.yaml
次に外部に公開するためにserviceを作成します。タイプはロードバランサーです。80番ポートで公開します。
service.yamlとして保存します。
apiVersion: v1
kind: Service
metadata:
name: qwen-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 80
selector:
app: qwen-app
作成します。
kubectl apply -f service.yaml
作成されたことを確認します。
kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 192.168.0.1 <none> 443/TCP 6h9m
qwen-service LoadBalancer 192.168.107.250 47.xxx.10.43 80:31749/TCP 179m
確認
以下のスクリプトでクライアントから動作確認してみましょう。
返答があれば完了です。ドキュメントのスクリプトで上部はストリームか、そうじゃない方です。日本語も中国語も大丈夫ですね。
openai.api_baseは上記で確認したLoadBalancerのEXTERNAL-IPを入力します。
import openai
openai.api_base = "http://47.xxx.10.43:80/v1"
openai.api_key = "none"
# create a request activating streaming response
for chunk in openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "こんにちは"}
],
stream=True
# Specifying stop words in streaming output format is not yet supported and is under development.
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
# create a request not activating streaming response
response = openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=False,
stop=[] # You can add custom stop words here, e.g., stop=["Observation:"] for ReAct prompting.
)
print(response.choices[0].message.content)
python3 k8sqwan.py
こんにちは!お話しできて嬉しいです。何かお困りですか?你好!有什么我能为你效劳的吗?
以上で第1フェーズのACK にQwenを実装は完了です。
次に会話を行う仕組みを作成します。
合成音声での会話実装
ここからはACKに実装したQwenと会話を行うための仕組みを作成していきます。
合成音声の実装
これは最初はSpeech to Textもクラウド上で実装を行おうと考えましたが、Intelligent Speech InteractionがRestAPIに対応していなかったため、Text to Speechのみ対応させました。
あまり見慣れないサービスだと思います。検索窓からspeechと検索すると見つかります。
初回はアクティブ化する必要があります。

トライアルで問題ないのでアクティブ化します。
アクティブ化されると画面を見ることができるようになります。
最初にプロジェクトを作成します。Create Projectをクリックします。
名前を付け作成します。
作成したプロジェクトを開きます。今回は合成音声を利用するためspeech synthesis serviceのTo Configureをクリックします。
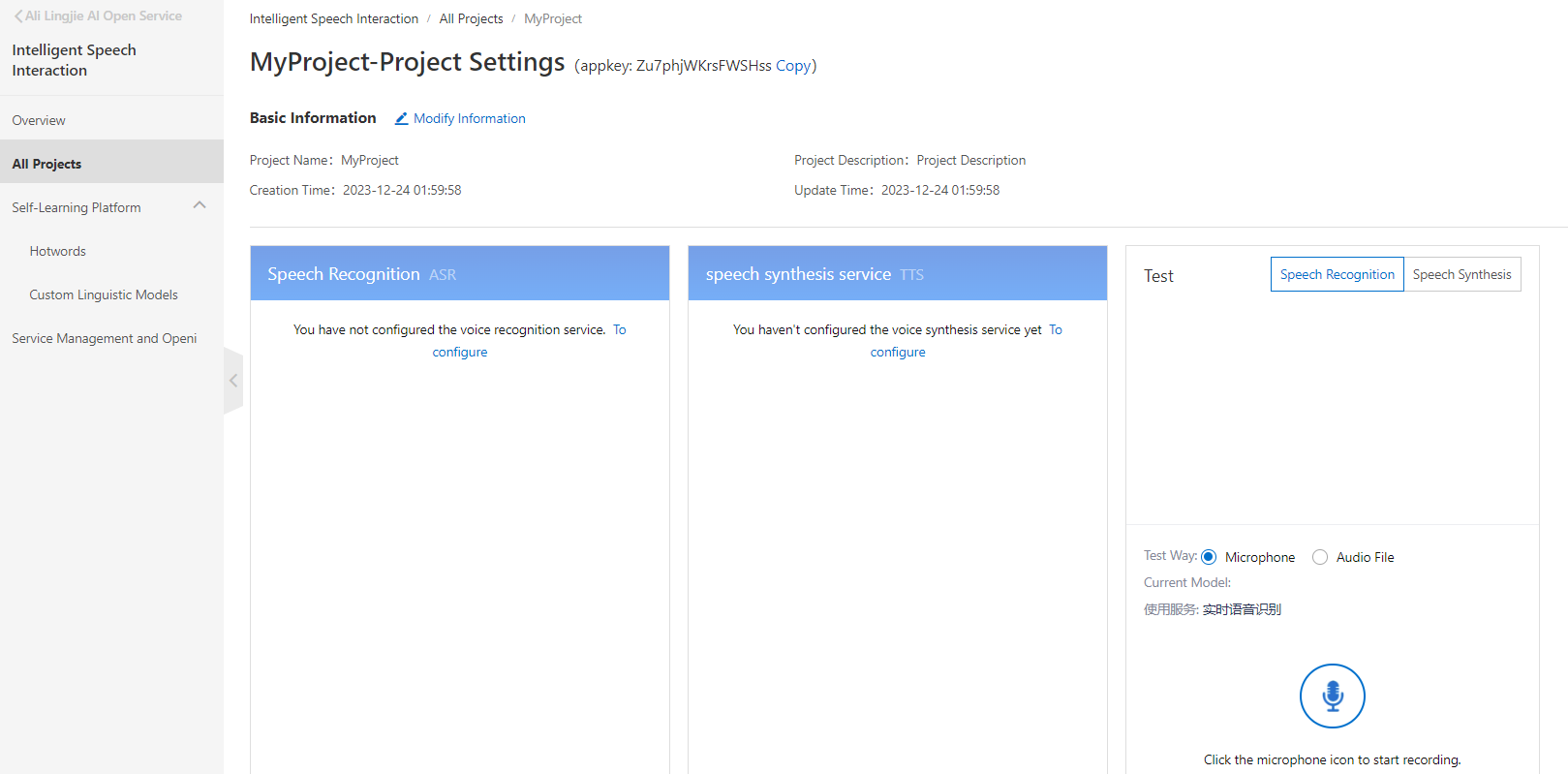
開くと Multingualをクリックすると、Japanese female と Japanese maleがあります。そうです日本語対応しています!
今回は女性のTomokaさん(だれ?)を選択しています。好みでどちらでも構いません。confirm to useをクリックします。
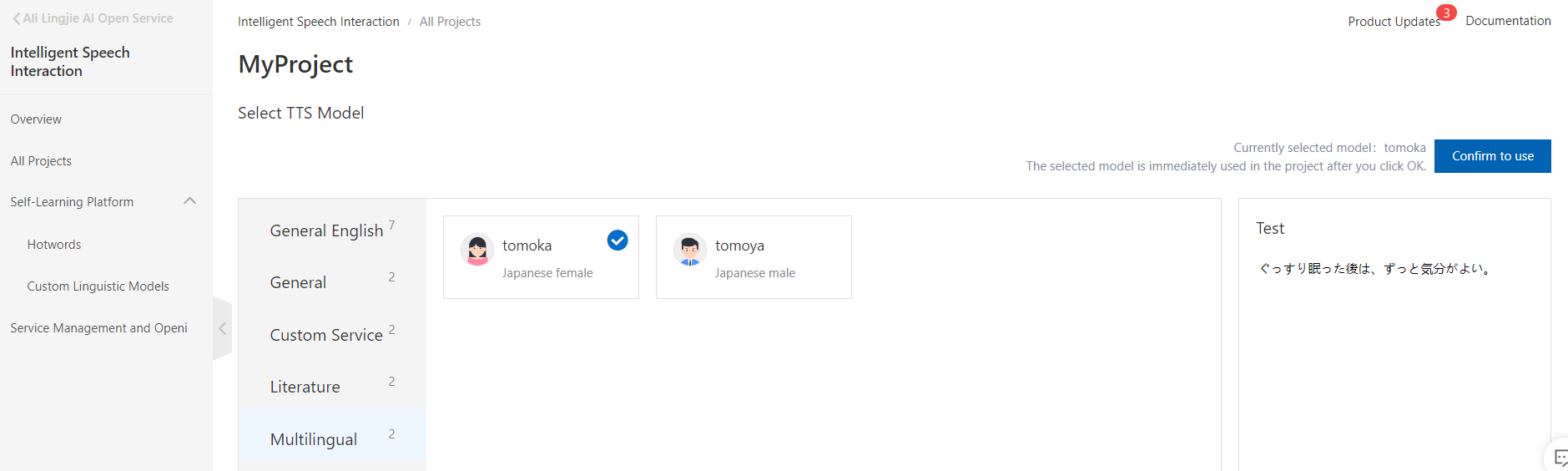
以上でIntelligent Speech Interactionの設定は完了です。
TokenとAppkeyの確認
Tokenは隠れていますがクリックすると表示されます。
Appkeyはプロジェクトの画面で確認できます。
Raspberry Pi 4に音声入力出力を実装し会話する
これまでに作成したQwenと連携していきたいと思います。
音声からテキストに起こす部分については下記を参考にしています。
必要なアプリをインストールします。
sudo apt-get install portaudio19-dev
sudo apt-get install python-pyaudio python3-pyaudio
pip install pyaudio
必要なモジュールをインストールします。
pip install fastapi uvicorn "openai<1.0" pydantic sse_starlette
pip install SpeechRecognition
以下はマイクから音声を聞き取り、文章にしてQwenに送信、返答とIntelligent Speech Interactionに送信し音声を得る。それをスピーカーで再生するスクリプトです。
speech.pyとして保存します。
openai.api_base、appkey、tokenは環境に合わせて設定します。
import speech_recognition as sr
import openai
import http.client
import urllib.parse
import json
import os
# OpenAI APIの設定
openai.api_base = "http://47.xxx.10.43:80/v1"
openai.api_key = "none"
# 音声認識の初期化
r = sr.Recognizer()
mic = sr.Microphone()
# 音声をテキストに変換する関数
def speech_to_text():
with mic as source:
r.adjust_for_ambient_noise(source)
audio = r.listen(source)
return r.recognize_google(audio, language='ja-JP')
# OpenAI APIにテキストを送信して応答を得る関数
def get_response_from_openai(text):
response = openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": text}
]
)
return response.choices[0].message.content
# テキストを音声に変換して保存する関数(GETリクエスト)
def processGETRequest(appKey, token, text, audioSaveFile, format, sampleRate):
host = 'nls-gateway-ap-southeast-1.aliyuncs.com'
url = f'https://{host}/stream/v1/tts?appkey={appKey}&token={token}&text={text}&format={format}&sample_rate={sampleRate}'
conn = http.client.HTTPSConnection(host)
conn.request(method='GET', url=url)
response = conn.getresponse()
if response.status == 200 and response.getheader('Content-Type') == 'audio/mpeg':
with open(audioSaveFile, mode='wb') as f:
f.write(response.read())
print('The GET request succeeded!')
else:
print('The GET request failed.')
conn.close()
# 音声を再生する関数
def play_audio(audio_file):
os.system(f'aplay {audio_file}')
# メイン処理
def main():
# appkeyとtokenを設定
appKey = 'Zu7xxxxxxxxHss'
token = '9bc1a6xxxxxxxxxxxxxx71c9086e9'
audioSaveFile = 'response_audio.wav'
format = 'wav'
sampleRate = 16000
while True:
print("Say something...")
try:
text = speech_to_text()
print(f"You said: {text}")
if text.lower() == "stop":
print("Stopping...")
break
response_text = get_response_from_openai(text)
print(f"Response: {response_text}")
text_urlencode = urllib.parse.quote_plus(response_text)
processGETRequest(appKey, token, text_urlencode, audioSaveFile, format, sampleRate)
play_audio(audioSaveFile)
except sr.UnknownValueError:
print("Could not understand audio")
except sr.RequestError as e:
print(f"Could not request results from Google Speech Recognition service; {e}")
if __name__ == "__main__":
main()
大きく、Qwenとやり取りを行う関数、テキストを音声に変換する関数、音声の再生する関数、メインの処理として、音声をテキストに取り込む部分になります。
他は特に詳しくコードについては解説しません。なんとなくコメントから察してくださいw
実行
スピーカーマイクを取り付けた後、スピーカーとマイクが取り付けたものになっているか確認します。
実行します。
python speech.py
実行して会話してみました。なかなか上手くいっているのでは?
以上のすべての工程は完了です。
これでQwenと会話ができます。まぁリアルタイムではないが十分なレスポンスなように思われます。仮想マシンや、手元のマシンでも実行可能ですの興味を持った人はQwenを試してみてはいかがでしょうか。
まとめ
Tongyi は日本で利用できないし、なんかQwenってあるんだよなと思ってOpenAIと同じようなAPIが利用できるし試してみようかなと思ったことがきっかけでした。ここまで上手く実装できるとは思いませんでした。Kubernetesに実装してServerless化する目論見もうまく行き会話もしたい欲求に駆られて最後までかこつけられて、とても良い経験になりました。今回はふだんやらない開発なども頑張りました。一応コピペ貼り付けで動作するようにしています。
Qwenはあまり日本では聞かないLLMですが、実は先日rinnaからも日本語継続事前学習モデル「Nekomata」シリーズが公開されました。結構、界隈では注目されているのでしょうかね。
あと、今回の検証で使った費用が怖くてまだ見てません。何度もECSでGPUインスタンスを立てて検証して、ACKのGPUインスタンスを立てたので怖くて見れない(;^ω^)