こんにちは。レアゾンホールディングス 25 卒エンジニアの押久保です。
この記事では、今年の新卒エンジニア研修の一環として実施されたインフラ研修の内容を、実際の体験を交えながらご紹介します。
インフラ研修の概要
インフラ研修では、まずインフラに関する基礎講義を受け、その後、Google Cloud を用いて実際にアプリケーションのデプロイを体験しました。
以下では、それぞれの内容について詳しく紹介します。
インフラ基礎講義
① インフラとは
アプリケーションが安定して動作するためには、裏側で支えるインフラが不可欠です。
インフラとは、アプリケーションを支える基盤のことで、以下のような要素が含まれます。
- 信頼性の高いハードウェア(サーバー、ネットワーク機器 など)
- 多数のリクエストを処理できる仕組み(スケーラビリティ、ロードバランサー)
- セキュリティ(不正アクセス防止、認証、通信の暗号化)
- 障害時の復旧能力(バックアップ、監視、冗長構成)
これらは、ユーザーからも開発者からも見えにくい部分ですが、アプリケーションの可用性・安定性・信頼性を確保するために欠かせない存在です。
② 良いインフラとは
「絶対にこれが正解!」というわけではありませんが、一般的に良いインフラとされる条件は以下の 3 つに分類できます。
- 高いパフォーマンス
- 高い可用性
- 堅牢なセキュリティ
それぞれについて簡単に紹介します。
高いパフォーマンス
ユーザー数の増加や大量のリクエストに対応するための仕組みが整っていることが重要です。
| 技術 | 説明 |
|---|---|
| スケーリング | アクセス数に応じてサーバー台数を増減し、リソースを自動調整する。 |
| シャーディング | データベースを複数に分割して、データを分散保存・処理し、負荷を分散する。 |
| キャッシュ | よく使うデータをメモリなどに保持して、データベースへのアクセス頻度を減らし高速化する。 |
| CDN | コンテンツを地理的に近いサーバーにキャッシュし、ユーザーへの配信速度を向上させる。 |
| メッセージキューイング | 処理を非同期で行うことで、リクエストの待ち時間を短縮し、全体のスループットを上げる。 |
これらを適切に組み合わせることで、アプリケーションのレスポンス速度や処理能力が向上します。
高い可用性
システム障害が発生してもサービスを継続できる設計が重要です。
| 技術 | 説明 |
|---|---|
| 冗長化 | 複数のサーバーを用意して、1 つが故障しても他が処理を引き継げるように構成する。 |
| リードレプリカ | データベースを複製し、読み取り専用のサーバーを追加して負荷分散を行う。 |
| オートスケーリング | 負荷に応じて自動でサーバー数を増減し、リソース不足によるダウンを防止。 |
| ロードバランサー | トラフィックを複数のサーバーに分散し、1 台の障害が全体に波及しないようにする。 |
これにより、システムのダウンタイムを最小限に抑えることができます。
堅牢なセキュリティ
データ漏洩や不正アクセスを防ぐための対策も不可欠です。
| 技術 | 説明 |
|---|---|
| HTTPS | 通信内容を暗号化し、盗聴や改ざんを防止する。 |
| ファイアウォール | 外部との通信を制限し、不正アクセスや不要な通信を遮断する。 |
| VPC(Virtual Private Cloud) | インターネットから隔離された仮想ネットワークを構築し、セキュリティを強化する。 |
| IAM(Identity and Access Management) | ユーザーやサービスごとにアクセス権限を細かく設定し、最小権限の原則を実現する。 |
これらの対策が整っていることで、安心してサービスを運用できます。
③ クラウドインフラ
クラウドインフラとは、 インターネット経由で使える仮想的なインフラの仕組みのことです。
クラウドインフラとは、クラウドコンピューティング・サービスの提供を可能にするハードウェアおよびソフトウェアコンポーネントの総称です.それらには、サーバー、ソフトウェア、ネットワーク、ストレージ、仮想化テクノロジーなどが含まれます.クラウドインフラは遠隔地のデータセンターに展開されます.ユーザーはそこにインターネット経由でアクセスし、コンピューティングリソースをオンデマンドで利用します. > https://www.akamai.com/ja/glossary/what-is-cloud-infrastructure
クラウドインフラができた背景
クラウドインフラが普及する前、サービスを提供するには自社で物理サーバーを購入・設置・運用する必要がありました。
これはオンプレミス(オンプレ)と呼ばれる方式です。
しかし、オンプレミスには次のような課題がありました。
| 課題 | 詳細説明 |
|---|---|
| 初期コストが高い | サーバーは 1 台あたり数十万円〜数百万円かかり、設備投資が大きい。 |
| スケールが難しい | 急なアクセス増加に対してサーバーをすぐに増設できず、対応が遅れる。 |
| 運用負荷が高い | 障害対応やアップデート、監視など運用作業をすべて自社で行う必要がある。 |
こうした課題を解決するために登場したのが、 複数の企業が共有できるサーバーリソースを提供するサービス(クラウドインフラ)です。これにより、自社でサーバーを買わなくても、インターネット経由でリソースを借りて使えるようになりました。
よく使われるクラウドインフラ
| クラウドサービス | 特徴・強み |
|---|---|
| AWS(Amazon Web Service) | 2025 年現在、シェア No.1。サービスが最も充実している。 |
| Google Cloud | データ分析や機械学習に適している。 |
| Microsoft Azure | Microsoft 製品との親和性が高い。 |
クラウドサービスを利用すると、② で紹介した内容は基本的に実現可能です。
デプロイ体験
今回のインフラ研修では、2 種類の方法でアプリケーションをデプロイする体験を行いました。
- 仮想マシンを使ったデプロイ
- コンテナを使ったデプロイ
どちらも Google Cloud 上にインフラを構築し、それぞれのデプロイ方法の特徴や違いを学びました。
① 仮想マシンを使ったデプロイ
まずは、仮想マシン(VM)を使った一般的なデプロイ方法を体験しました。
VM とは、ソフトウェアで構成された仮想的なコンピュータで、物理的なマシンと同様に OS やアプリケーションを動かすことができます。
アーキテクチャ概要
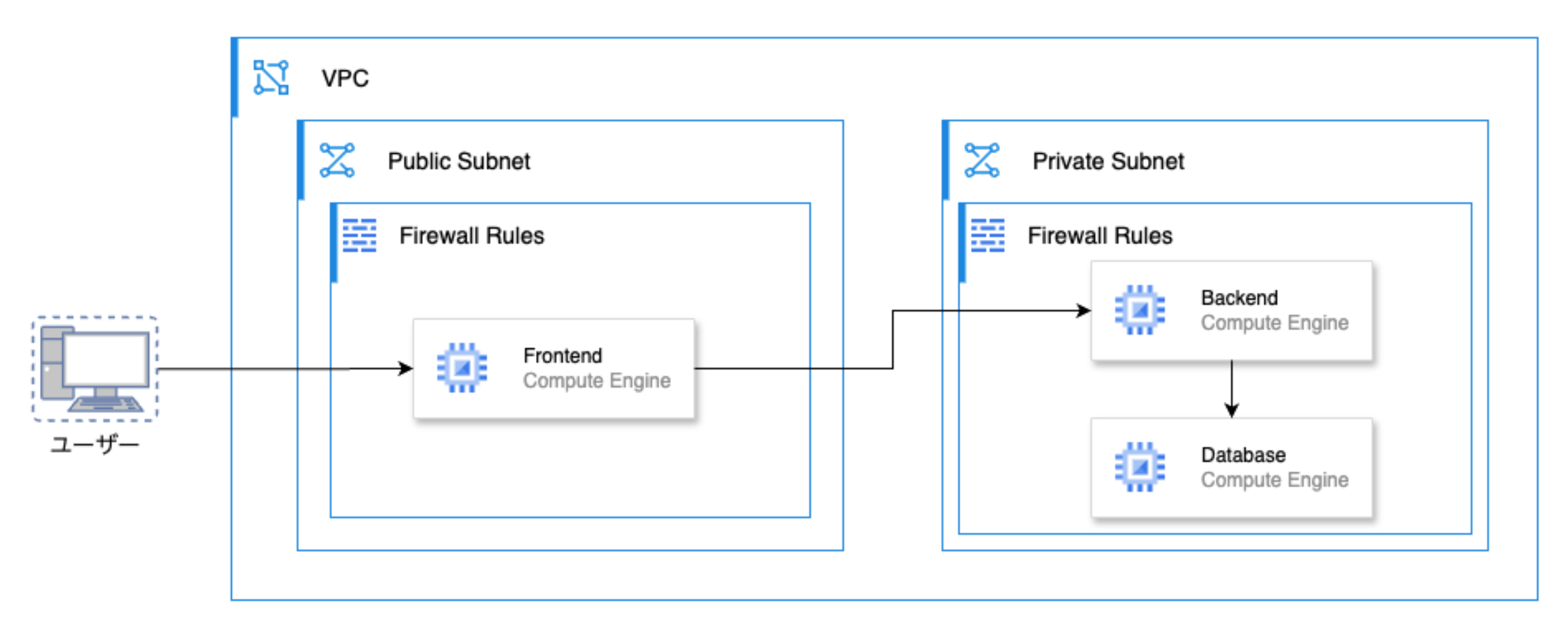
実施内容
すべての構成・デプロイ作業は手動で行い、インフラの基本操作を実践的に学びました。
- Google Cloud の Compute Engine で VM を作成
- VPC ネットワークとファイアウォールルールを設定
- 各 VM に SSH で接続し、GitHub からソースコードを取得
- シェルコマンドでアプリケーションを起動
② コンテナを使ったデプロイ
次に、Cloud Run を使ったコンテナベースのデプロイを体験しました。
Cloud Run は、Google Cloud が提供するフルマネージドなサーバーレス環境で、Docker image をデプロイするだけで自動的にスケーリングやリクエスト処理を行ってくれます。
アーキテクチャ概要
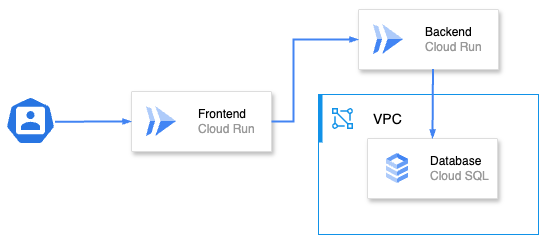
実施内容
インフラ構成やアプリケーションのデプロイは、主にコンテナ化と Google Cloud サービスの設定によって自動化されており、より少ないステップで公開が可能でした。
- Cloud Shell 上で Docker イメージをビルド
- Artifact Registry にコンテナイメージを登録
- Cloud Run にイメージを指定してサービスを作成
- Cloud SQL との接続設定
研修を通して感じたこと
今回の研修を通して、インフラの基礎から実際のデプロイまでを体験することで、理論だけでは理解しづらい具体的な操作方法などを深く学べました。
特に、VM を使った手動デプロイでは、ネットワーク設定やサーバー管理の基礎を身につけることができ、インフラの仕組みを理解する上で非常に重要だと感じました。一方で、運用には多くの工程が必要であることも実感し、インフラの重要性と責任の重さを改めて感じました。
対して、Cloud Run を使ったコンテナデプロイでは、サービスが多く自動化されているため、簡単にアプリケーションを公開できることを実感しました。スケーリングや管理の手間が省けるため、今後の開発・運用に非常に役立つスキルだと感じました。
このように、両者を比較しながら実践することで、インフラ設計や運用の選択肢を幅広く理解でき、今後の業務に活かせる貴重な経験となりました。
▼ 採用情報
レアゾン・ホールディングスは、「世界一の企業へ」というビジョンを掲げ、「新しい"当たり前"を作り続ける」というミッションを推進しています。
現在、エンジニア採用を積極的に行っておりますので、ご興味をお持ちいただけましたら、ぜひ下記リンクからご応募ください。