画像の解像度をあげる超解像で、昨年のCVPR2016で採択されていた論文を実装してみました。
元論文:"Deeply-Recursive Convolutional Network for Image Super-Resolution", CVPR2016
これは同じCNNを何度もかけて少しづつ画像を綺麗にしていって、最終的に全ての結果をうまいこと混ぜ合わせて解像度の高い絵を得るものです。state of the artの結果を出しているとのこと。
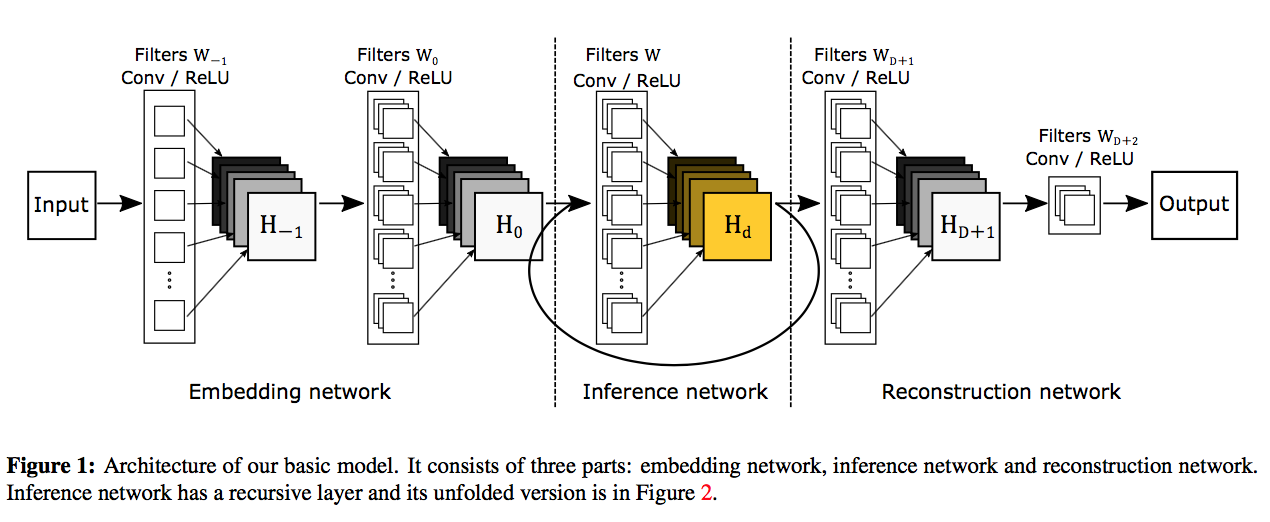
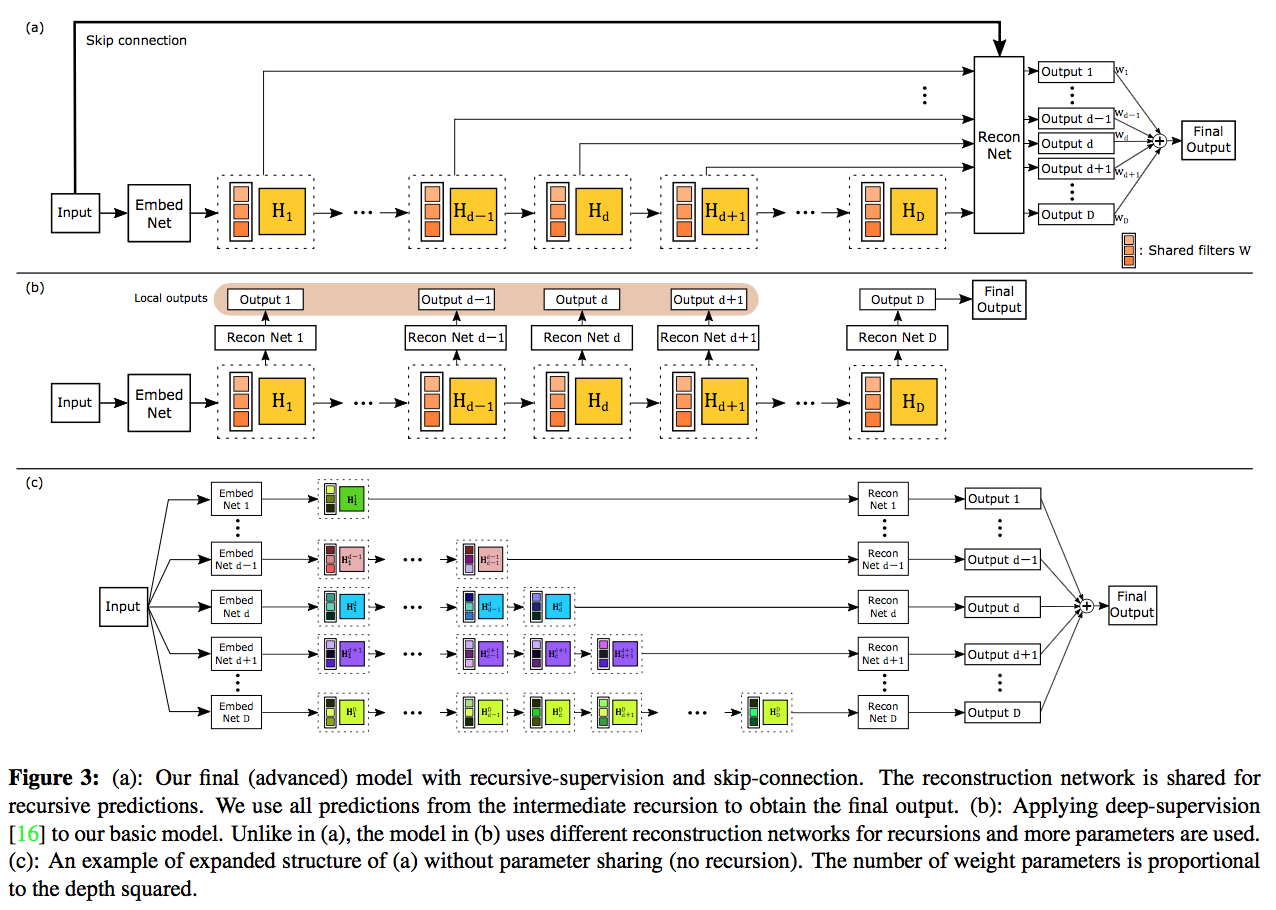
モデル図は下記のようになります。ちょっとブロックが多いように見えますが、斜めに走っている一群のブロックは重みを共有しているので実際のパラメータの数はそんなに多くないです。


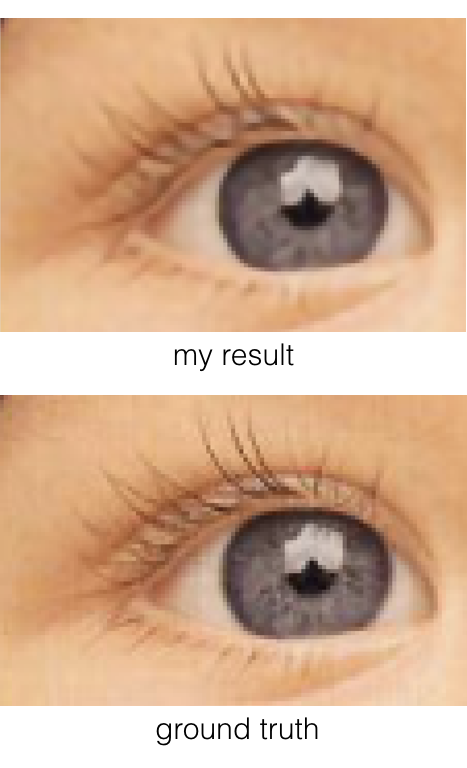
ただ、残念ながら他のアルゴリズムよりは概ね高いものの論文と同じ水準のPSNRは達成できませんでした。うまく収束できなかったために初期値は少しいじってありますが、それ以外はほとんど論文と同じはずなのですが。
| DataSet | Bicubic | SRCN | SelfEx | My Result | DRCN |
|---|---|---|---|---|---|
| Set5 x2 | 33.66 | 36.66 | 36.49 | 36.92 | 37.63 |
| Set14 x2 | 30.24 | 32.42 | 32.22 | 32.47 | 33.04 |
| BSD100 x2 | 29.56 | 31.36 | 31.18 | 31.47 | 31.85 |
| Urban100 x2 | 26.88 | 29.50 | 29.54 | 29.31 | 30.75 |
一応モデルの記述部分のコードのみ載せておきます。
def build_embedding_graph(self):
self.x = tf.placeholder(tf.float32, shape=[None, None, None, self.channels], name="X")
self.y = tf.placeholder(tf.float32, shape=[None, None, None, self.channels], name="Y")
# H-1 conv
self.Wm1_conv = util.weight([self.cnn_size, self.cnn_size, self.channels, self.feature_num],
stddev=self.weight_dev, name="W-1_conv", initializer=self.initializer)
self.Bm1_conv = util.bias([self.feature_num], name="B-1")
Hm1_conv = util.conv2d_with_bias_and_relu(self.x, self.Wm1_conv, self.cnn_stride, self.Bm1_conv, name="H-1")
# H0 conv
self.W0_conv = util.weight([self.cnn_size, self.cnn_size, self.feature_num, self.feature_num],
stddev=self.weight_dev, name="W0_conv", initializer=self.initializer)
self.B0_conv = util.bias([self.feature_num], name="B0")
self.H_conv[0] = util.conv2d_with_bias_and_relu(Hm1_conv, self.W0_conv, self.cnn_stride, self.B0_conv, name="H0")
if self.summary:
# convert to tf.summary.image format [batch_num, height, width, channels]
Wm1_transposed = tf.transpose(self.Wm1_conv, [3, 0, 1, 2])
tf.summary.image("W-1" + self.model_name, Wm1_transposed, max_outputs=self.log_weight_image_num)
util.add_summaries("B-1:" + self.model_name, self.Bm1_conv, mean=True, max=True, min=True)
util.add_summaries("W-1:" + self.model_name, self.Wm1_conv, mean=True, max=True, min=True)
util.add_summaries("B0:" + self.model_name, self.B0_conv, mean=True, max=True, min=True)
util.add_summaries("W0:" + self.model_name, self.W0_conv, mean=True, max=True, min=True)
def build_inference_graph(self):
if self.inference_depth <= 0:
return
self.W_conv = util.diagonal_weight([self.cnn_size, self.cnn_size, self.feature_num, self.feature_num], name="W_conv")
self.B_conv = util.bias([self.feature_num], name="B")
for i in range(0, self.inference_depth):
self.H_conv[i+1] = util.conv2d_with_bias_and_relu(self.H_conv[i], self.W_conv, 1, self.B_conv, name="H%d"%(i+1))
if self.summary:
util.add_summaries("W:" + self.model_name, self.W_conv, mean=True, max=True, min=True)
util.add_summaries("B:" + self.model_name, self.B_conv, mean=True, max=True, min=True)
def build_reconstruction_graph(self):
# HD+1 conv
self.WD1_conv = util.weight([self.cnn_size, self.cnn_size, self.feature_num, self.feature_num],
stddev=self.weight_dev, name="WD1_conv", initializer=self.initializer)
self.BD1_conv = util.bias([self.feature_num], name="BD1")
# HD+2 conv
self.WD2_conv = util.weight([self.cnn_size, self.cnn_size, self.feature_num, self.channels],
stddev=self.weight_dev, name="WD2_conv", initializer=self.initializer)
self.BD2_conv = util.bias([1], name="BD2")
self.Y1_conv = (self.inference_depth + 1) * [None]
self.Y2_conv = (self.inference_depth + 1) * [None]
self.W = tf.Variable( np.full(fill_value=1.0 / (self.inference_depth + 1), shape=[self.inference_depth + 1], dtype=np.float32), name="layer_weight")
W_sum = tf.reduce_sum(self.W)
for i in range(0, self.inference_depth+1):
self.Y1_conv[i] = util.conv2d_with_bias_and_relu(self.H_conv[i], self.WD1_conv, self.cnn_stride, self.BD1_conv, name="Y%d_1"%i)
self.Y2_conv[i] = util.conv2d_with_bias_and_relu(self.Y1_conv[i], self.WD2_conv, self.cnn_stride, self.BD2_conv, name="Y%d_2"%i)
y_ = tf.mul(self.W[i], self.Y2_conv[i], name="Y%d_mul" % i)
y_ = tf.div(y_, W_sum, name="Y%d_div" % i)
if i == 0:
self.y_ = y_
else:
self.y_ = self.y_ + y_
if self.summary:
util.add_summaries("BD1:" + self.model_name, self.BD1_conv)
util.add_summaries("WD1:" + self.model_name, self.WD1_conv, mean=True, max=True, min=True)
util.add_summaries("WD2:" + self.model_name, self.WD2_conv, mean=True, max=True, min=True)
def build_optimizer(self):
self.lr_input = tf.placeholder(tf.float32, shape=[], name="LearningRate")
self.loss_alpha_input = tf.placeholder(tf.float32, shape=[], name="Alpha")
mse = tf.reduce_mean(tf.square(self.y_ - self.y), name="Loss1")
if self.debug:
mse = tf.Print(mse, [mse], message="MSE: ")
if self.loss_alpha == 0.0 or self.inference_depth == 0:
loss = mse
else:
loss1_mse = self.inference_depth * [None]
for i in range(0, self.inference_depth):
inference_sub = tf.sub(self.y, self.Y2_conv[i], name="Loss1_%d_sub" % i)
inference_square = tf.square(inference_sub, name="Loss1_%d_squ" % i)
loss1_mse[i] = tf.reduce_mean(inference_square, name="Loss1_%d" % i)
loss1 = loss1_mse[0]
for i in range(1, self.inference_depth):
if i == self.inference_depth:
loss1 = tf.add(loss1, loss1_mse[i], name="Loss1")
else:
loss1 = tf.add(loss1, loss1_mse[i], name="Loss1_%d_add" % i)
loss1 = tf.mul(1.0 / self.inference_depth, loss1, name="Loss1_weight")
loss2 = mse
if self.visualize:
tf.summary.scalar("L1:" + self.model_name, loss1)
tf.summary.scalar("L2:" + self.model_name, loss2)
loss1 = tf.mul(self.loss_alpha_input, loss1, name="Loss1_alpha")
loss2 = tf.mul(1 - self.loss_alpha_input, loss2, name="Loss2_alpha")
if self.loss_beta > 0.0:
with tf.name_scope('Loss3') as scope:
loss3 = tf.nn.l2_loss(self.Wm1_conv) + tf.nn.l2_loss(self.W0_conv) \
+ tf.nn.l2_loss(self.W_conv) + tf.nn.l2_loss(self.WD1_conv) \
+ tf.nn.l2_loss(self.WD2_conv)
loss3 *= self.loss_beta
if self.visualize:
tf.summary.scalar("L3:" + self.model_name, loss3)
loss = loss1 + loss2 + loss3
else:
loss = loss1 + loss2
if self.visualize:
tf.summary.scalar("Loss:" + self.model_name, loss)
self.loss = loss
self.mse = mse
self.train_step = self.add_optimizer_op(loss, self.lr_input)