このポストは Inside of Deep Learning あるいは深層学習は何を変えるのか から分割したものです。全体があまりに長くなってしまったので、改善手法についても別のページにしました。
DL(ディープラーニング)の性能を改善していくポイントを駆け足で見て行きましょう。
学習データの追加、改善
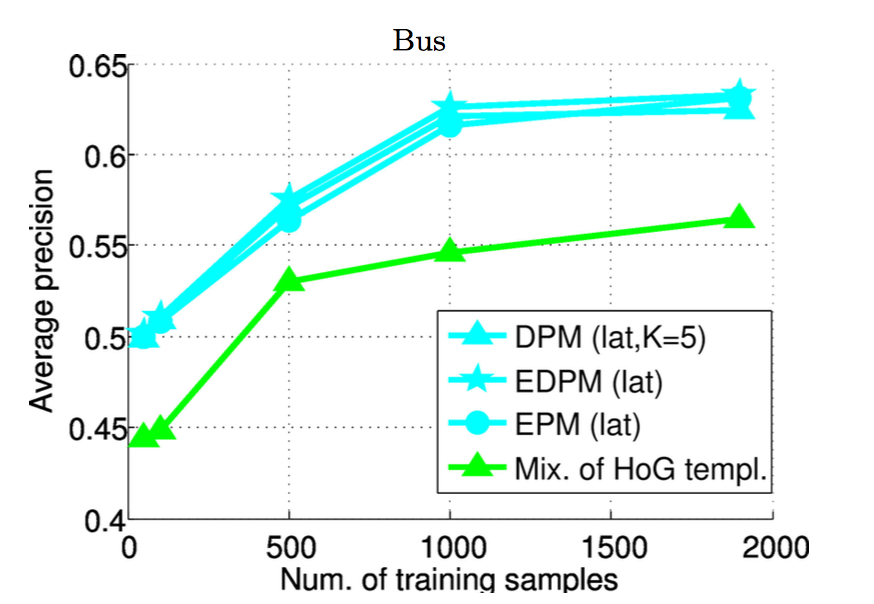
DLシステムの性能を上げるためにはためにはより沢山の学習データが必要と言われています。例えば下記の図は、顔のパーツやバスの認識について学習データを増やすほど性能が上がるとした論文のものです。

画像であれば左右、上下、および上下左右に反転させた画像を使ってどちらを向いていても正しく特徴を取れるようにしたり、あるいは少し拡大したりノイズを混ぜるなどしてデータを水増しする手法がよく使われます。ユニークなのは例えばCGを用いて画像を作成し学習データとして利用する方法などでしょうか。
またプレディクションなどに用いる場合は学習用データの分布が実データの分布と合っていることなども大事です。過学習を抑えるためにもデータ数は重要で、データ数がある数を超えた瞬間に急に性能が上がったというケースも沢山報告されています。
パラメータを収束させる
レイヤーの多いモデルを使うと表現力が上がる代わりにパラメータの収束(学習)が難しくなります。前に説明したResNetはそのために残差項を学習させるようにした例ですが、この先はもう少し一般的な手法を紹介して行きます。
初期値の調整 (Xavierの初期化, Heの初期化)
フォワードプロパゲーション及びバックプロパゲーション中に信号や逆伝搬誤差の大きさ(分散)がどのように変わるかを計算し、各層でそれらの分散が一様になるように各レイヤーのランダムな初期値の分散を決める手法です。利用する伝達関数によって最適な値が決まります。
何故これが重要かというと、例えばウェイトが大きすぎた場合は信号が層を経るごとにどんどん大きくなり発散する可能性が増えてしまうためで、逆に小さすぎた場合は信号が減衰し最終レイヤーに到達する前に消失してしまう可能性があるからです。また初期値を設定するという意味では転移学習も重要な技術です。これは後に解説します。
-
Understanding the difficulty of training deep feedforward neural networks
-
Delving Deep into Rectifiers:
Surpassing Human-Level Performance on ImageNet Classification
モデル規模の適正化(あるいはモデル圧縮)
今までに見て来た通り、モデルを複雑にしてノード(特徴量)やレイヤーを増やすと性能を上げられる代わりに汎化性能や学習能力が下がり、結果的にモデルの規模を大きくすると性能が下がってしまいます。"次元の呪い"などとも言われていますが適切なサイズのノード数が必要と言われています。
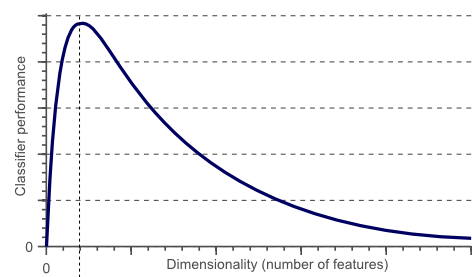
またモデルが複雑になるにつれパラメータ数や計算時間が増えてしまい、モバイル端末上などで実行するには難しくなってしまっていました。学習後にネットワークを圧縮することで同等の性能を持ちながらも計算やモデルを簡略化できる手法が提案されています。
ミニバッチ、(+確率的勾配降下法)
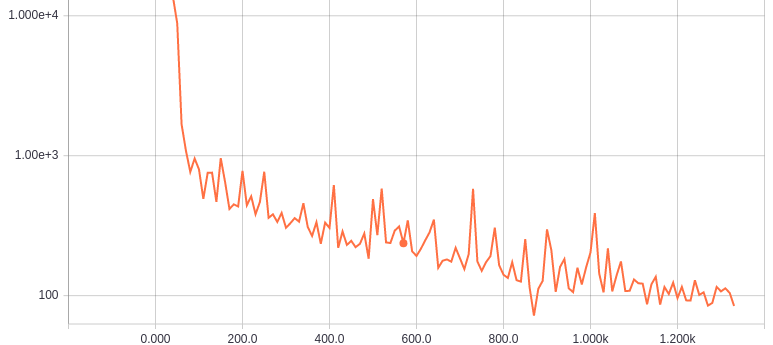
ほとんどの大規模なDLのシステムではミニバッチを使用します。これは学習データの中からn個のサンプルごとに分けて各集合(ミニバッチ)に対して全ての勾配を計算し平均して利用する方法です。その勾配によりウェイトを更新したら次のミニバッチを利用し、全てのミニバッチを利用し終わったら学習用データの順番をランダムに入れ替えまた最初のミニバッチから処理を行います。(学習データを全て学習するたびにエポックという単位を1増やし、この値を用いて学習係数を減衰させたりします)
この方法を用いると下図のように損失の変化がギザギザして不安定に見えますが、これを行うことにより巨大なデータでも少しづつ学習を行うことができ、また局所解に落ちにくくなるというメリットもあります。
各種オプティマイザ (AdamとEve)
オプティマイザについてもいろいろな手法が考案されて来ました。オプティマイザのアルゴリズムによっては次に探索するべきパラメータをうまく求められず学習が進まなくなってしまうからです。
特にパラメータの数(次元)が増えると、局所解となるポイントが減り局所最適解に落ちる可能性は大幅に減りますが、代わりに損失値の勾配上で鞍点と呼ばれるポイントが増えます。これはある軸では局所的に損失が最小になり、ある軸では最大になるような点です。この点では勾配がすべての方向で0になるためどの方向にパラメータを持っていけば良いか分からず、ここから脱出するのが難しくなってしまいます。
__Momentum__という方法があります。これはその文字どおり、パラメータを探索してきた方向に慣性をつけて同じ方向へ移動し始めた場合に加速させてやる方法です。これにより鞍点からより早く脱出することができます。
Adagrad や Adadelta RMSprop などではさらに学習係数を自動で調節します。今まで何度も試してきたようなパラメータについては学習係数を小さくして探索幅を狭くし、逆にあまり試したことのない未知の領域にきた場合は学習係数を大きくして探索幅を広げていく方法です。
近年では __Adam(Adaptive Moment Estimation)__という上記のAdagradやRMSpropとMomentumのいいとこ取りをしたようなアルゴリズムで、今までの勾配の一次モーメント(指数移動平均)と2次モーメント(2乗値の移動指数平均)を考慮して更新値を決めます。
それぞれにモーメントの強さや初期値などの幾つかのパラメータがありこれらを適切に設定する必要があります。近年ではAdamオプティマイザが良く使われていますが、いつでもこれが良いというわけではなく損失空間の特徴によって適するアルゴリズムが異なります。下図はある損失空間上での各オプティマイザの動きです。


また、最近__Eve__という名前の新しいオプティマイザが考案されました。これはAdamの強化版で、論文を読んだ限りでは損失値の変化を見てやって、変化が大きい場合はより大きな学習係数を設定し変化が小さくなったらより小さな学習係数を設定する機能を追加したもののようです。これによりさらに性能が上がったとしています。イブというと僕は風邪薬を想起してしまいなかなか良く効きそうですが、Adamの上位版がEveというのはなかなか面白い名前だと思います。
入力データの正規化 及び バッチノーマライゼーション
入力データに対して前処理を行い、各入力データの平均を0、分散を1となるようにするに調整します。データごとに平均値や大きが違う場合、各層のウェイトやバイアスはそれに適合するための学習を行わなければなりません。入力データの正規化 (Data Normalization)によりこの手間を省き、各ウェイトと信号の大きさ(分散)を適切に保つ効果があります。
これを行うことで学習係数を大きくすることができたり多層でも収束するようにできる重要な要素です。入力データ全体の分散を揃え平均を0にする以外にもデータの最大値と最小値を揃える正規化の方法もあります。
また、データの平均値と分散をレイヤーごとに揃えるバッチノーマライゼーション(Batch Normalization)という方法もあります。BN層はデータの分散を1に、平均が0になるように学習するレイヤーで、例えば伝達関数の前に置いてバイアス層の代わりに追加します。入力データがバッチごとに分布が違った場合などにそれを是正し学習を早く行わせる効果などがあります。物体認識やプレディクションなどの多くのモデルでパフォーマンスの向上に有効であるとのことなので、積極的に利用するのが良さそうです。
転移学習、ファインチューニング、ゼロショットラーニング
転移学習(Transfer learning)は、例えば事前に学習済みの他のモデルから初期値を得て自分のモデルに転移(コピー)して初期値とする方法です。現状の物体認識やその他の画像処理タスクではCNN層は特徴抽出器として利用されていますが、最新のモデルではこの学習に1週間や2週間かかることも珍しくありません。既に公開されている学習済みのウェイトを使って初期化し汎用性の高い特徴抽出機として利用できます。その後に、例えばある特別な花の判定に利用するためにその花のデータセットで追加で学習を行わせることで、データセットが少ない場合でも高い性能を出したり学習時間を大幅に節約することができます。
ファインチューニングも考え方は似ています。これは例えばディープなネットワークがあった場合に最初は少ない数のレイヤーで構築して学習させ、そのあとにレイヤーの数を増やして追加で学習を行わせたり、一部のネットワークの更新を止めてある部分のネットワークだけに学習を行わせる手法です。
ゼロショットラーニングも面白い概念です。これは、例えば学習時には猫のラベル付きデータがなくて猫を学習しなかったが、実行時にいきなり猫のデータが入って来ても今までの認識物とは違う別のクラスであると判定できるようにする学習方法です。入力する画像や文章についてその特徴をあらかじめ算出できるようにすることで、"対象物"ではなく"対象物を示す特徴ベクトル"を学習させる手法です。自然言語処理などでも有効でなかなか興味深いです。
パラメータを共有する
パラメータについてはその値が小さくなるようにすると多層でも発散しにくい等のノウハウも幾つかありますが、同じパラメータを他のレイヤーで共有して繰り返し使うとことで正則化の効果を強くしよりディープにしても学習できるようになるというテクニックもあります。
例えば下記のDRCNは超解像という画像の解像度を上げるためのモデルですが、全く同じCNNを16回もかけてそれぞれの結果を合成することによりstate of the artの補完性能を獲得しています。( 実は僕の方で実装したサンプルもgithubにおいてます )
汎化性能を上げる
過学習状態をいかに避けるかというトピックは今までも繰り返し出てきました。モデルが過学習しているかを判定するのは実はそれほど難しくなく、学習時の損失に対して実データの損失がずっと大きくなってしまっていれば過学習状態にあると見て取れます。
例えば学習が進み過学習状態になってしまうと、エポックが進むにつれテストセットでの損失が小さくならずに逆に大きくなってしまうことがあります。その場合は過学習が進む前に学習を中断させるアーリーストッピングというテクニックもあります。あるいは最小の損失が得られたパラメータ値を記憶しておきます。論文などで微妙な最高性能を出す時などは有効です。
ただしあまり本質的な対処ではないので他の手法も併用する方がお勧めではないかとも思いますが。
ウェイトディケイ (正則化)
ウェイトディケイ、重み減衰、あるいは正則化などと呼ばれるテクニックは非常に広く使われています。損失関数に全ての重みの絶対値の総和=L1 Weight Decay(L1正則化)あるいは全ての重みの二乗値の総和=L2 Weight Decay(L2正則化)を係数をかけて足してやるだけです。(計算にはバイアスは含めず、基本的にはL2正則可よくが使われます)
これだけのものですが、パラメータの発散を防いで過学習状態を防ぐ強い効果があります。
ドロップアウト
ドロップアウトも有名です。これは学習時にランダムにノードのうち幾つかを全く使わずに出力とバックプロパゲーションを行うものです。これによりノード間の依存関係を減らしモデルが過学習してしまうことを防ぎます。ただし通常よりも学習が遅くなってしまうという欠点もあります。
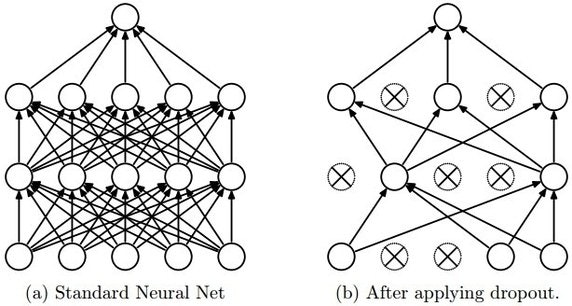
例えば擬人化して考えます。あるノードの前にはA,B,Cの3つのノードがありました。Aさんが非常に優秀なので、このノードは常にAさんの出した答えを後ろに渡すことしか考えていませんでした。ところがドロップアウトにより突然Aさんが失踪したので仕方なくBさんとCさんの答えも考慮して判断するようになり、そこにAさんが戻って来たというイメージです。また本質的にはアンサンブル学習と近い意味があるようです。
【Deep Learning】過学習とDropoutについて from sonickun.log
ハイパーパラメータの学習、自動調整
学習係数の大きさやCNNあるいはノード(特徴量)のサイズ、隠れ層の数は重要ですが、それ以外にも上で説明したようにドロップアウトやウェイトディケイの係数、バッチの大きさや利用するオプティマイザの種類・モーメントの強さなど沢山のハイパーパラメータがあります。
モデルについては、例えば精度が出なくなったらレイヤーを広く(ノードの数を大きく)して、過学習しはじめたらレイヤーを狭くしながら深くする(レイヤーを追加する)のを試すなど、それぞれのパラメータを調節するための指針はあります。しかし実際に調節して試していくには大きな時間がかかります。2週間以上かけたというケースも珍しくないほど、ここの調整が一番時間のかかるところかもしれません。
これらの各ハイパーパラメータを自動で調整する機構をつけるケースも増えて来ました。トレーニングデータや実際の評価用(テスト)データに対してバリデーションデータとして別のデータセットを追加し、この損失勾配からハイパーパラメータを自動調整する手法です。
伝達関数を変更する
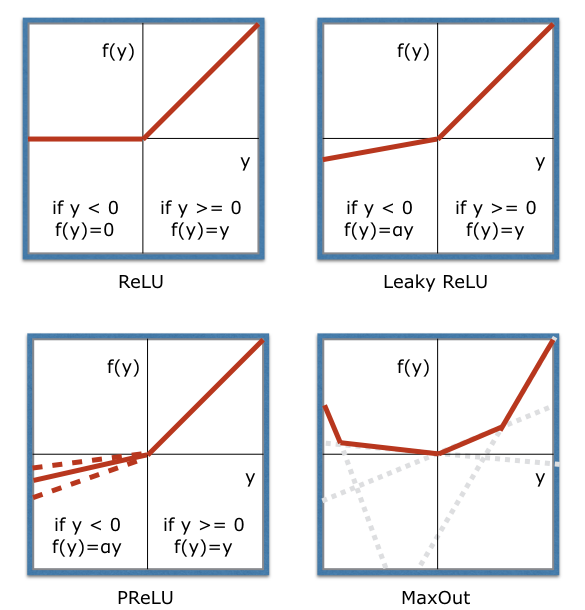
ReLUが良く使われていますが、近年ではLeaky ReLUやParametric ReLU, MaxOutなどの改良型も良く使われています。
ReLUでは正の値をリニアに伝えることができますが、出力値が大きくなりすぎた場合に発散する可能性がでてきてしまいます。また負の値は全てカットしてしまうので、何かの拍子に大きなバイアスを学習してしまうとそれ以降は多少ウェイトを学習させても値が全てゼロになってしまって学習が適切に行われなくなってしまう状況も起こり得ます。
(既に上で説明したバッチノーマライゼーションはこれを防ぎ入力を適切な値に持って来るための効果があります。)
LeakyReLUでは下図のようにαの値を使って入力が負の値でも出力値が穏やかに変化するようにし、ノードが死んでしまうのを防ぎます。(αは主に0.01などの小さな値を使います)
ParametricReLU(PReLU)ではこのαを各ノードごとに学習させて自動調整するもので、MaxOutでは複数の一次関数の最大値を使うことでさらに非線形性(表現力)を高くしたものです。これらを使いながら上記の他の手法も組み合わせていくことでモデルの持つポテンシャルを最大限に発揮させ性能を高めていくことができます。