Slide
目標
文字コードの概要とUnicode、UTF-8 の差を知ってもらう。
文字コードとは?
コンピュータ上で文字を表示・通信するための規格のこと。
文字コードは2つの概念によって、構成されている。
- 符号化文字集合
- 文字符号化方式
符号化文字集合と文字符号化方式は基本的には1対1に対応している。
この2つを合わせて、文字コードという。
符号化文字集合とは?
文字集合に対して、番号(コードポインタ)を対応させたもの。
身近なものでいうと、Unicode、ASCIIコード、JIS X 0208など。
文字符号化方式とは?
ある符号化文字集合を、バイト列に変換する際のルール。
どのように番号(コードポインタ)をバイトに変換するかは、それぞれのルール次第。
符号化文字集合に対して、いくつかの方式がある。
Unicodeに対する、文字符号化方式は、UTF-8, UTF-16, UTF-32などがある。
JISに対しては、Shift JIS。
雑学
なぜWindowsで、「\」(バックスラッシュ)が「¥」(円記号)になってしまうのか。
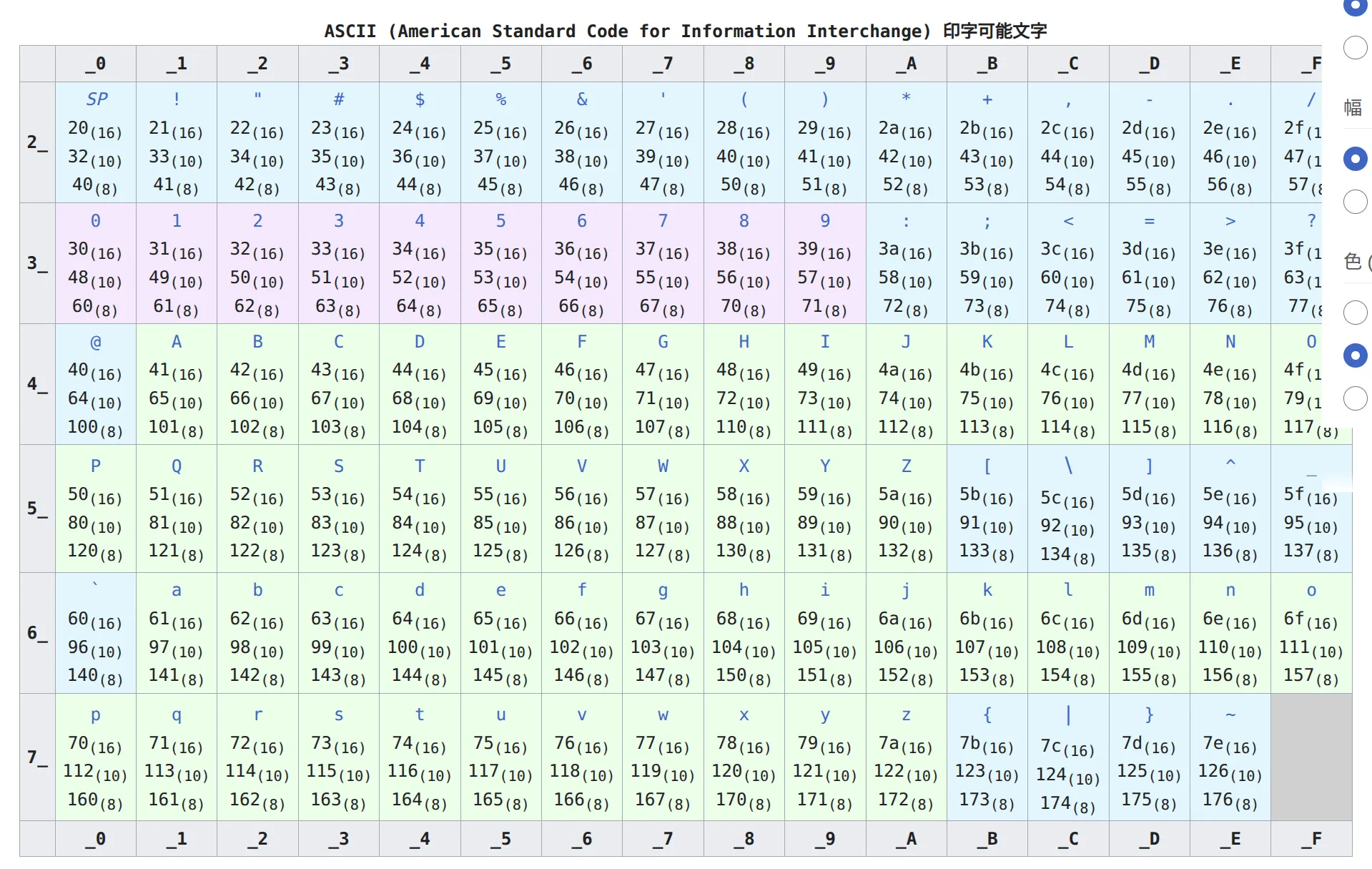
ASCIIコード
0x5c

Shift JIS
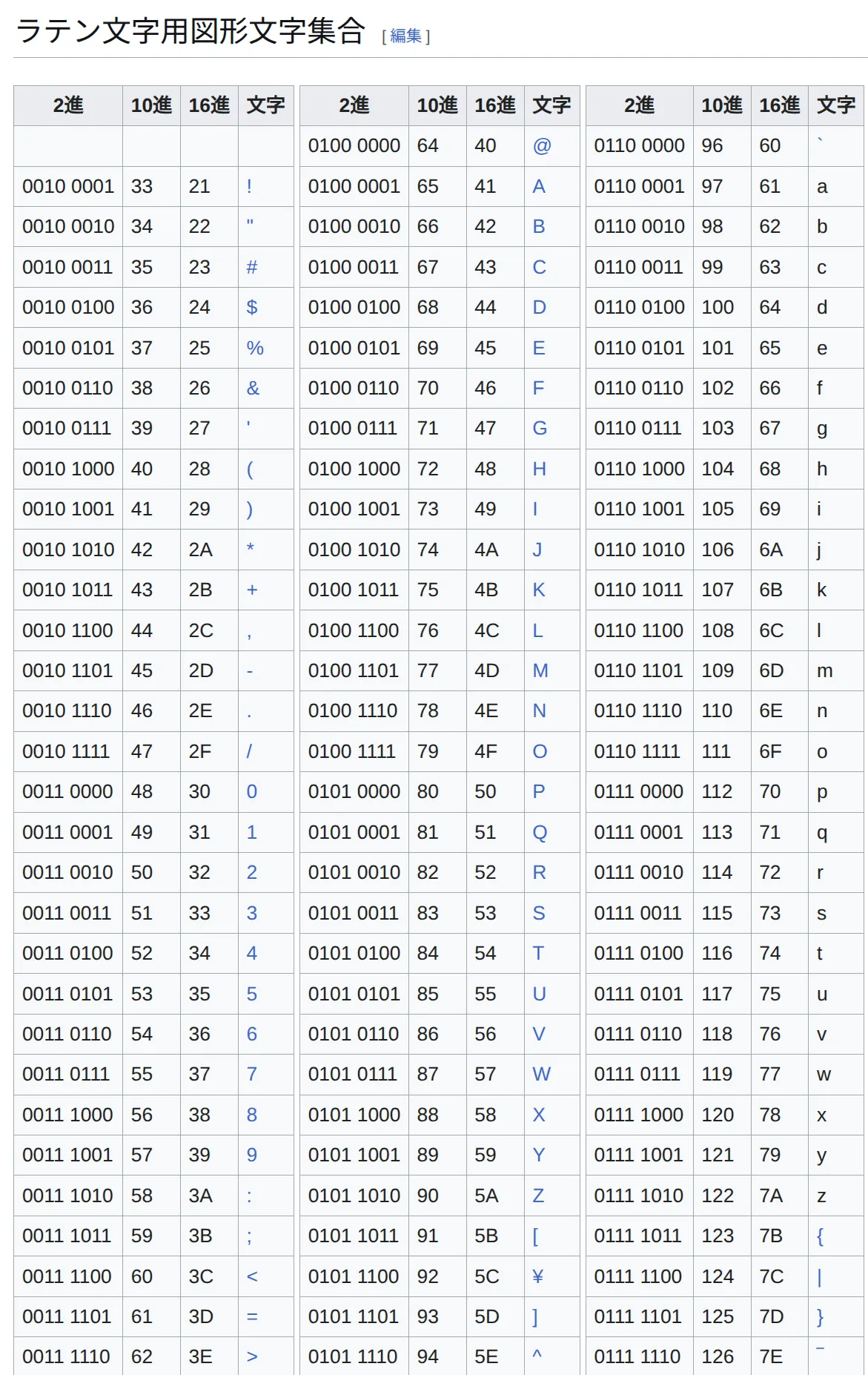
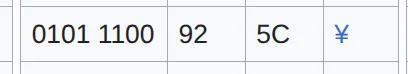
0x5c
ASCII とShit JISでかぶってしまったから。
互換について
互換の種類
- 前方互換
- 後方互換
- 上位互換
- 下位互換
大事なのは、後方互換
後方互換性について
Versionの後ろのサービスで作成した資料が、そのまま作成できること。
WiiUはWiiに対して、後方互換性を持つ。
WiiUはWiiに対して、上位互換である。
今回話したいことは、Unicodeについて。
特にUTF-8について。
Unicode について。
UTF-8, 16, 32 それぞれの違いについて。
世界の文字たちを1個にまとめようと企画されて作られたもの。
めっちゃすごい。
今までは、世界各国でたくさんの文字集合が使われていたが、現在はUnicodeにまとまりつつある。
実際に私達も、JISとともにUnicodeも使用している。
マックスが2 ^ 21、つまり最大で 21 bit が必要。
後ろの8, 16, 32は、最小単位のbit数を表している。
例えば、UTF-16は、最小単位が16 bitで構成されている。
UTF-8 がすごい!
上記3つの返還方式の中で、UTF-8は唯一、ASCIIコードに対して、後方互換性を持つ。
すごい。
これはどれだけすごいかというと、今までの文章が全てそのまま読み込めるから。
例えていうと、WiiUで、そのままWiiのカセットが遊べるようなもの。
補足
HTMLの先頭で、どの文字返還方式が使われているか、確認できる。
じゃあ、肝心な変換方式は?
比較するため、UTF-8, 16,32全ての変換方式について説明する。
簡単な順番で、UTF-32から説明する。
UTF-32 の実際の変換方式
UTF-32は非常に単純な変換方法である。
Unicodeは、文字に対して番号(コードポインタ)が振られている。
そのコードポインタを 32 bit に変換しただけである。
例えば、「A」はU+0041であるので、これをそのまま、
00000000 00000000 00000000 00101001
で表すだけである。超かんたん。
メリット
- 実装が超かんたん
デメリット
- データ量が多くなってしまう。
(1文字の情報を表すのに、4 Byte 必要。情報の密度が低い。)
UTF-16 の実際の変換方式
基本的には、16 bit(2 Byte)で表現する。
文字コードがある一定より大きい場合のみ、32 bit (4 Byte)使用して表す。
例えば、「文」という文字のコードポインタは、U+6587 (16 進数)なので、
2 Byte 利用して、
65 |87
0100 0001 |0101 0111
の2つのバイトを使用して表す。
しかし、これには、65 と 87 のどちらを先に持ってくるか、2通りの表し方がある。
これをバイトオーダー(Byte order)という。
そのまま上位 8 bitを先に持ってくるものを、ビッグエンディアン、
対して、下位 8 bitを先に持ってくるものを、リトルエンディアン、という。
メリット
3つの中で、日本語を表す際に最も情報効率が良い。
デメリット
ASCIIコードとの互換性がない。一度対応させるための処理が必要。
UTF-8 の実際の変換方式
コードポインタに対して、1 ~ 4 Byteを使い分ける。
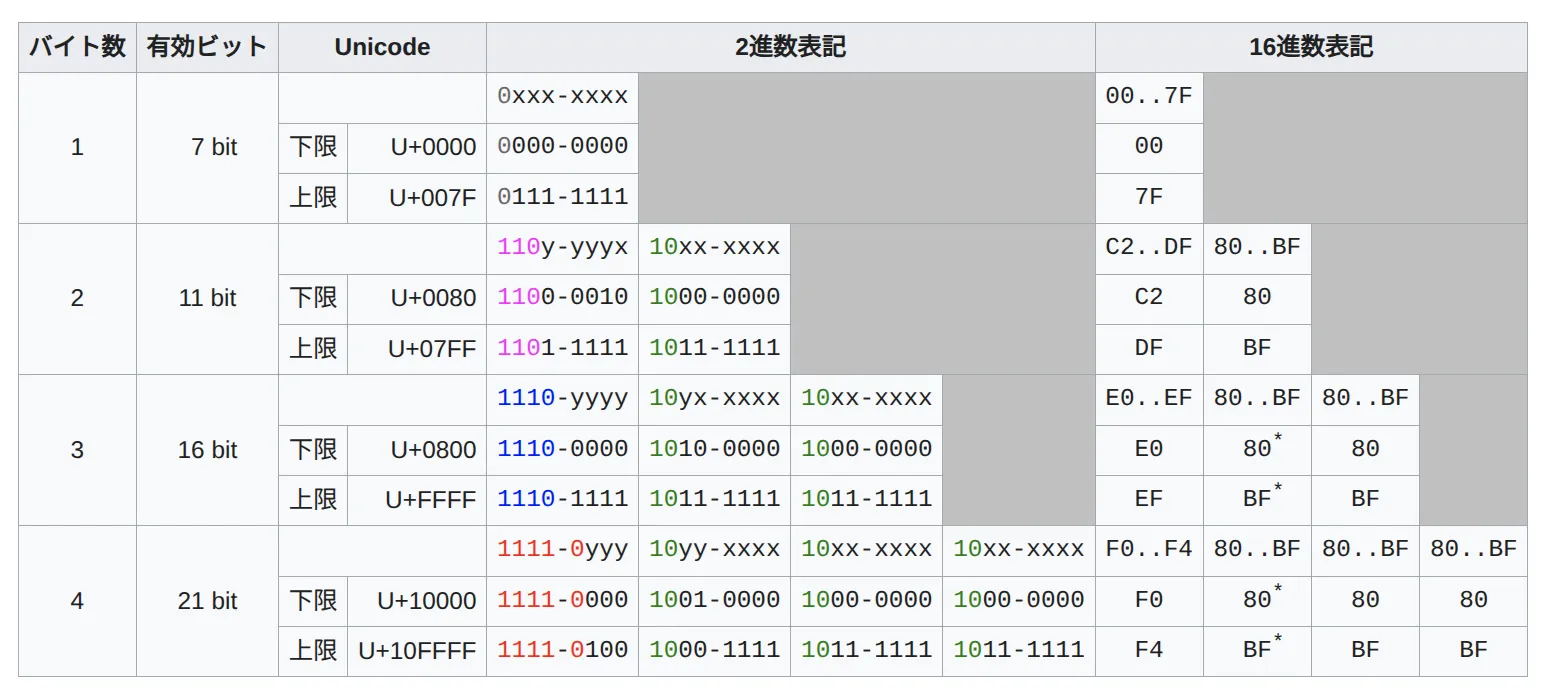
(引用元:https://ja.wikipedia.org/wiki/UTF-8)
これ。
メリット
3つの中で、唯一ASCIIコードに対して、後方互換性を持つ。
デメリット
実装がむずい。
参考文献
円記号問題