配列の要素の追加
以前のlectureでは配列について学んだ
→では、配列に新しい要素を追加する場合の処理について考える
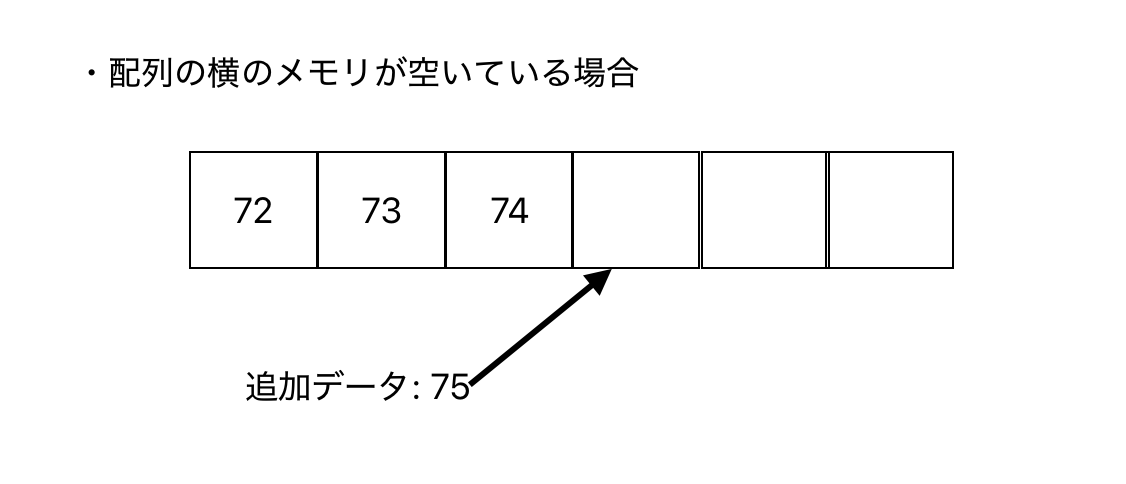
配列の横のメモリが空いていた場合
連続して、データを保存すればよい
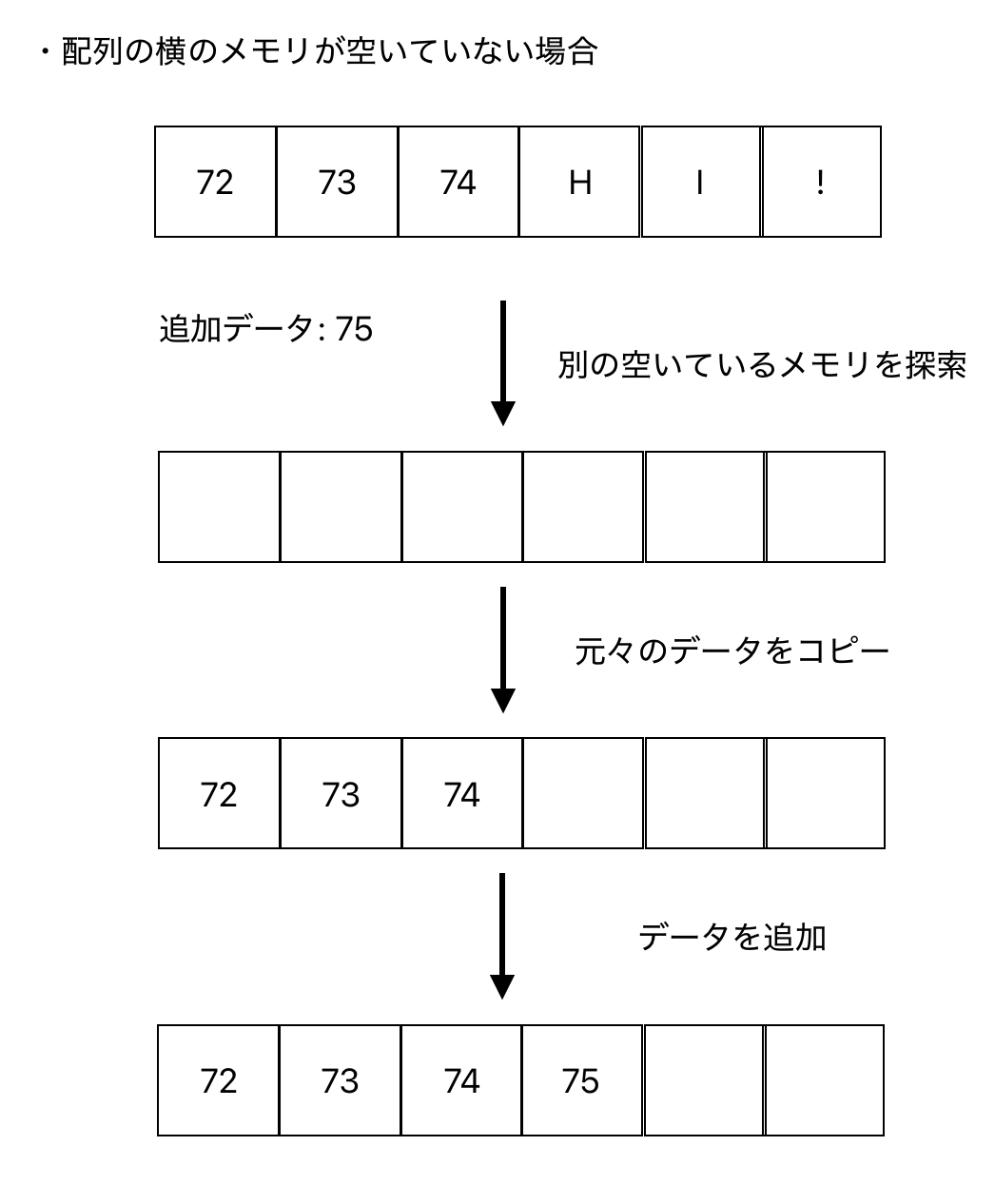
横のメモリが別のもので使用されていた場合
- 追加したデータのメモリ分が空いている領域を探索
- 元の配列を複製
- データを追加
この処理をコードで書いてみる
#include <stdio.h>
#include <stdlib.h>
int main(void){
int *list = malloc(3*sizeof(int));
if (list == NULL){
return 1;
}
list[0]=1;
list[1]=2;
list[2]=3;
list = malloc(4*sizeof(int));
list[3]=4;
for(int i = 0; i<4; i++){
printf("%i\n",list[i]);
}
free(list);
}
こうすると正しく追加できない、なぜだろうか??
・int *list = malloc(4*sizeof(int));を定義した後に、list[0]~list[2]をもう一度挿入していないからだ
→しかし、listを再定義しているので、データがあるメモリのアドレスを追えずコピーできない
正しくは、、、
#include <stdio.h>
#include <stdlib.h>
int main(void){
// 追加前の配列を作成
int *list = malloc(3*sizeof(int));
if (list == NULL){
return 1;
}
list[0]=1;
list[1]=2;
list[2]=3;
// 複製用の配列を作成
int *tmp = malloc(4*sizeof(int));
if (tmp == NULL){
free(list);
return 1;
}
// 以前のデータをコピー
for(int i; i < 4; i++){
tmp[i] = list[i];
}
tmp[3]=4; // 新しい要素を追加
free(list); // 以前の配列を解放
list = tmp;
// 出力
for(int i = 0; i<4; i++){
printf("%i\n",tmp[i]);
}
free(list);
return 0;
}
そしてこのコードを realloc で書き直してみる
#include <stdio.h>
#include <stdlib.h>
int main(void){
// 追加前の配列を作成
int *list = malloc(3*sizeof(int));
if (list == NULL){
return 1;
}
list[0]=1;
list[1]=2;
list[2]=3;
// 複製用の配列を作成
int *tmp = realloc(list, 4*sizeof(int));
if (tmp == NULL){
free(list);
return 1;
}
tmp[3]=4; // 新しい要素を追加
list = tmp;
// 出力
for(int i = 0; i<4; i++){
printf("%i\n",tmp[i]);
}
free(list);
return 0;
}
⚪︎reallocの機能
- 指定した配列のサイズを変更する
- その配列の横に空きのメモリがあるならそれを使用。なければ別の空いているメモリ領域を確保し、そのアドレスを返す。その際に元の配列のデータをコピーした状態で返す。また、元の領域は自動で解放される
ではこの配列の要素追加での実行時間を考える。
→処理としては元のデータを複製して新しく要素を1つ追加する
→触れるデータの数は n + 1(配列の要素をnとすると)
→O(n)となる(・ω・)ケッコウジカンカカルナ
連結リスト(Linked List)
上記のように配列を用いると、データ量が増えた時にメモリをいちいち動かす必要があるため実行時間が遅くなってしまう
→必ずしもメモリが連続したものである必要はなくないか??
→新しいデータを追加した際に、そのデータがどこにあるかわかればいいよね
→それぞれが次のデータのアドレスがわかればいい
→それを実現したものが Linked list(連結リスト)
図で表すと、、、
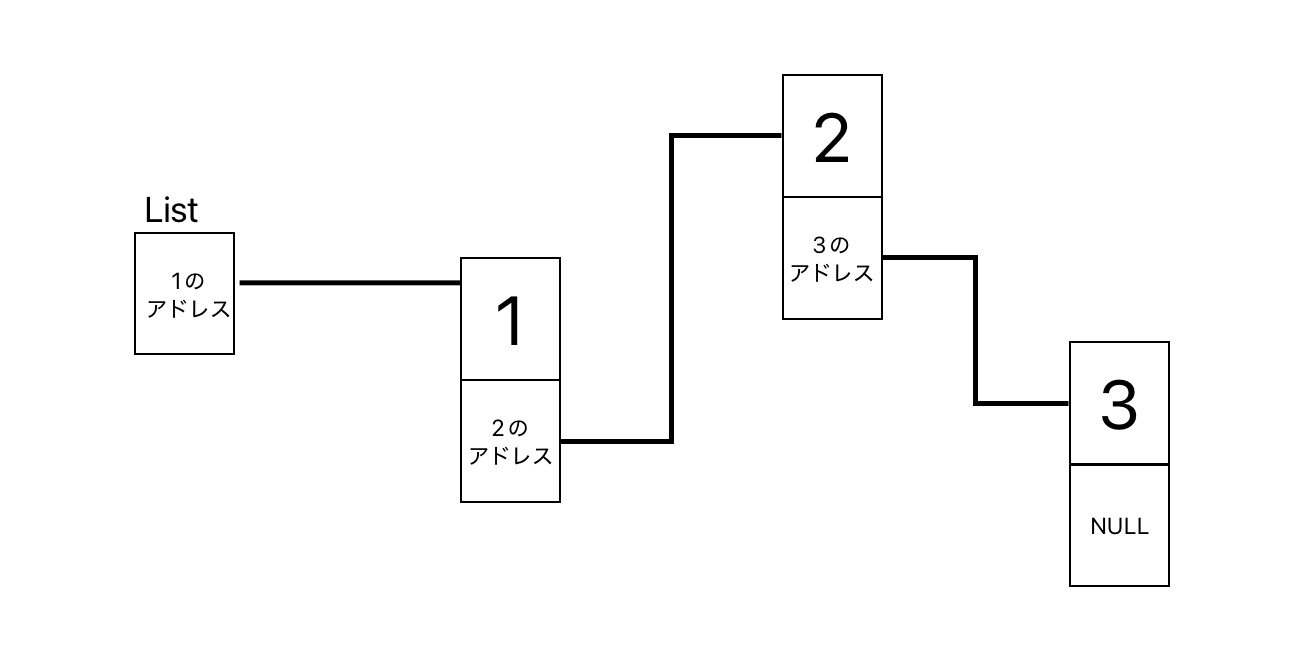
(最後の要素のアドレスをNULLにすることで、リストの終わりがわかる)
今まではmallocにて値のメモリ分を要求したが、今回は値+次のアドレス分のメモリを要求していく
→普通の配列よりかはポインタ分メモリ量は使うが、データを操作する際に配列のようにメモリの確保や解放をいちいちする必要がなくなる
↓
コードで書いてみよう!!
Node
連結リストには値と次のデータのアドレスを保持したデータ型が必要になってくる。→Node(ノード)とは、情報をカプセル化したデータ構造体の総称
typedef struct node{
int number;
struct node *next; ⇨この書き方は慣習のようなもの
} node;
連結リストの作成
1 まずは初期値を設定していく
node *list=NULL; //ゴミ値にならないようにNULLを設定する
2 メモリを確保
node *n=malloc(sizeof(node));
3 ノードに値を挿入
if(n != NULL){
(*n).number = 1; //ここでの*nは間接参照
(*n).next = NULL;
}
↓この書き方だと、可読性が下がる
if(n != NULL){
n->number = 1;
n->next=NULL;
}
4 変数にコピー
list = n;
これらの方法を使用して、3つの要素を持つ連結リストを作成していこう
#include <stdio.h>
#include <stdlib.h>
typedef struct node{
int number;
struct node *next;
} node;
int main(void){
node *list = NULL;
node *n = malloc(sizeof(node));
if (n == null){
return 1;
}
n->number = 1;
n->next = NULL;
list = n;
// -----ここまでで1つの要素を持つ連結リストが完成------
n = malloc(sizeof(node));
if (n == NULL){
free(list);
return 1;
}
n->number = 2;
n->next = NULL;
list->next = n; // listの要素のnextに次の要素のアドレスを格納
// -----ここまでで2つの要素を持つ連結リストが完成------
n = malloc(sizeof(node));
if (n == NULL){
free(list->next);
free(list);
return 1;
}
n->number = 3;
n->next = NULL;
list->next->next = n;
// -----ここまでで3つの要素を持つ連結リストが完成------
// 連結リストの値を出力
for(node *tmp = list; tmp != NUll; tmp->next){
printf("%i\n", tmp->number);
}
// 連結リストの解放
while(list != NULL){
node *tmp = list->next;
free(list);
list = tmp;
}
return 0;
}
連結リストの途中に新しくデータを追加する
list → 1 → 3 → 4 となっていた時に2をソート順になるように挿入したい
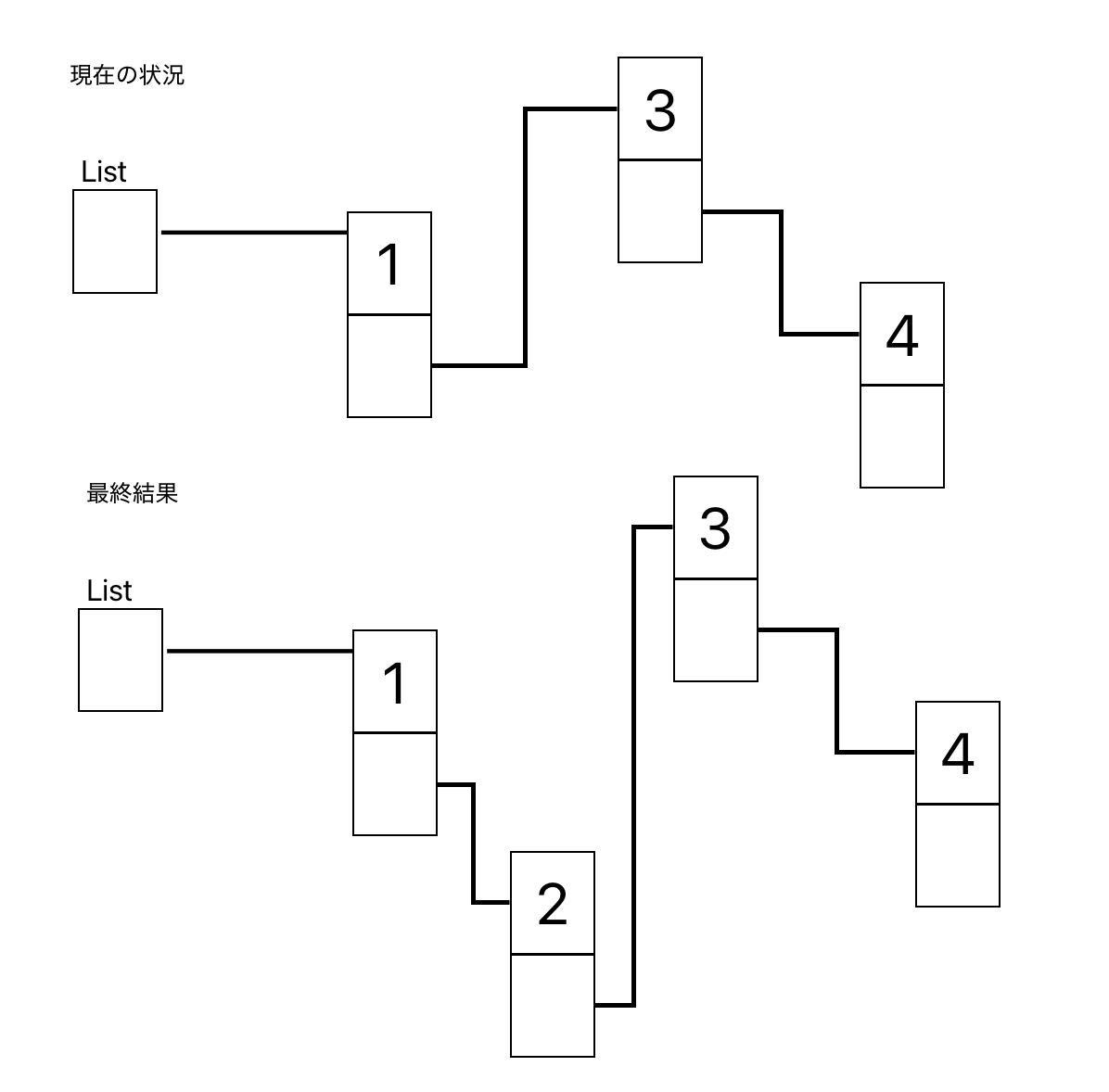
よくある間違い
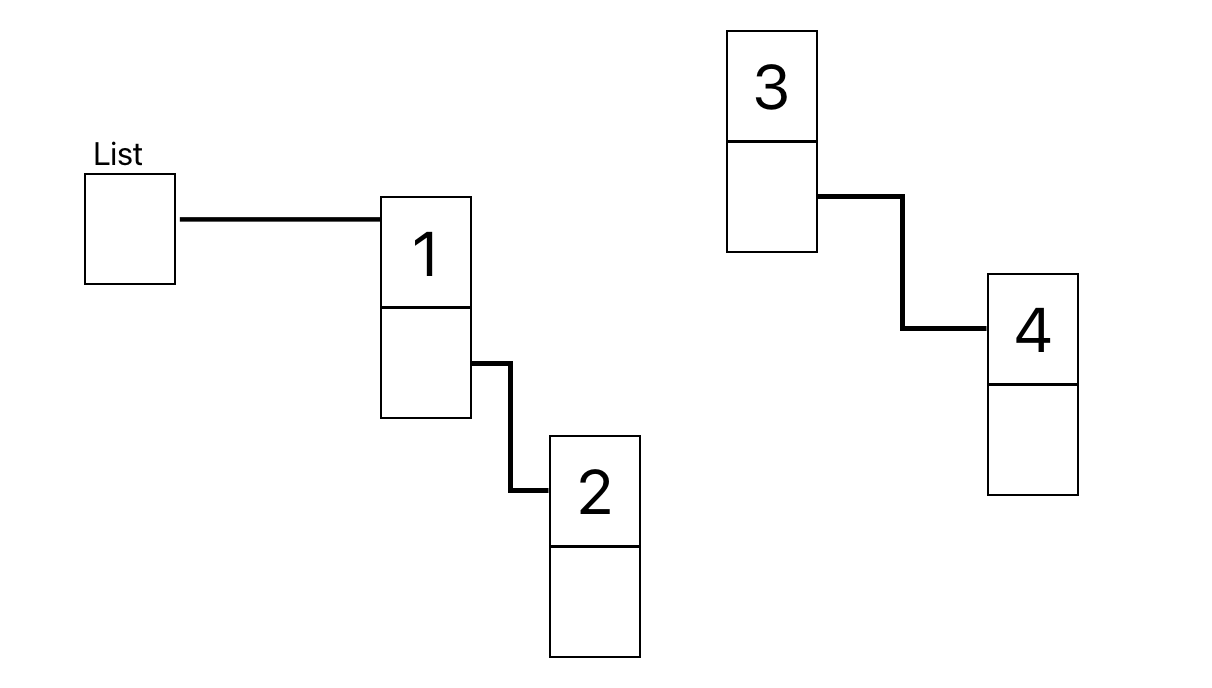
最初からList → 1 → 2の順で連結すると2のノードは次のノードがどれかわからくなり、3のノード以降のメモリリークが発生してしまう
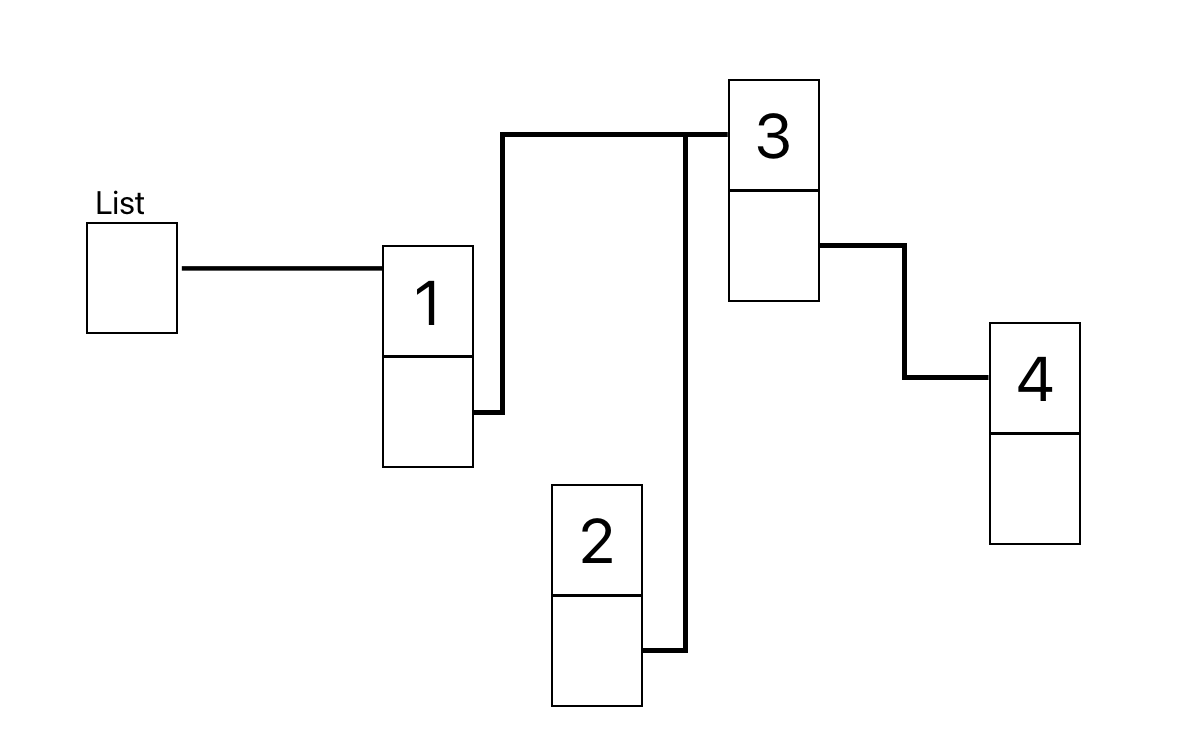
正しい方法
先に2のノードのアドレスを3のノードに設定した後、1のノードのアドレスを2のノードに設定する
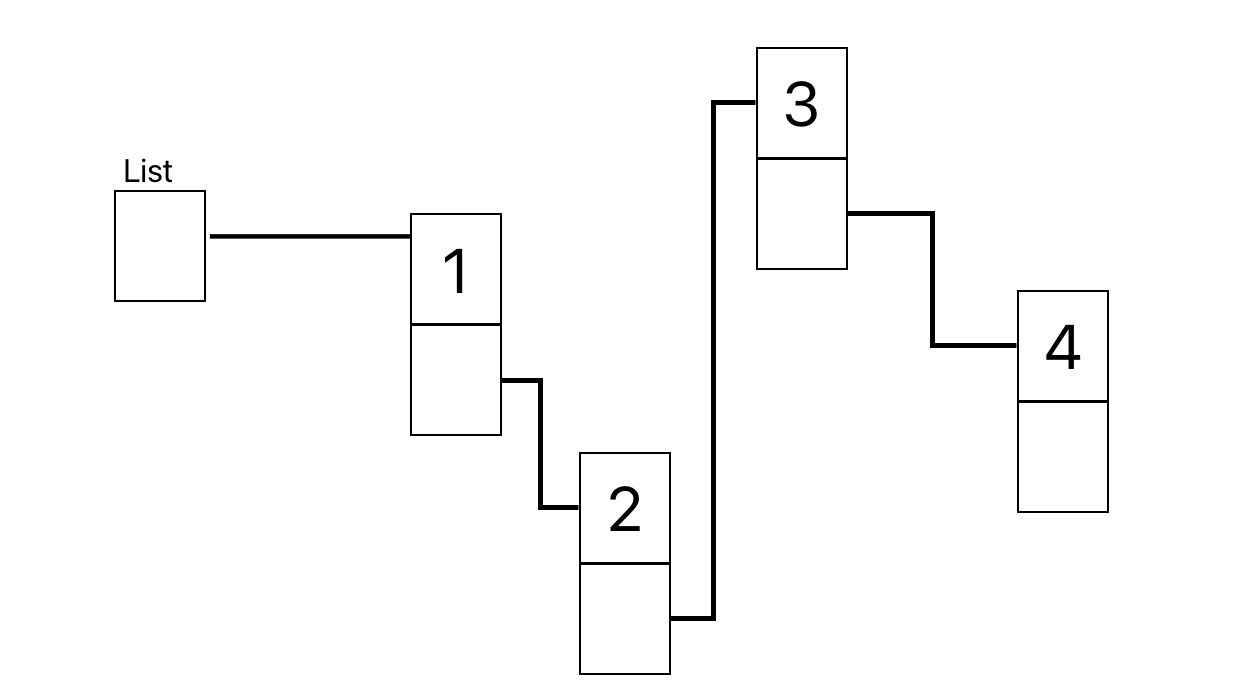
連結リストの検索・挿入の実行時間
検索
コンピュータは1度に1つしか値を見ることができない
→連結リストでは二分探索を使用することができない
→線形的に探すしかない
→全てのデータを見る必要があるため、実行時間はO(n)
挿入
- 最後の要素に追加するだけならO(1)
- ソート順になるように挿入するならO(n)
↓
連結リストでは検索も挿入も実行効率的に微妙だなあ(・ω・)
→1方向ではなく2次元的にみる方法はないか???
trees(ツリー)
家系図のように分岐していくイメージ
二分探索木(binary search tree)
1つのデータにつき2つのポインタを持つ
特徴として、左の子はルートより小さく、右の子はルートより大きい→どの枝に関しても同じ
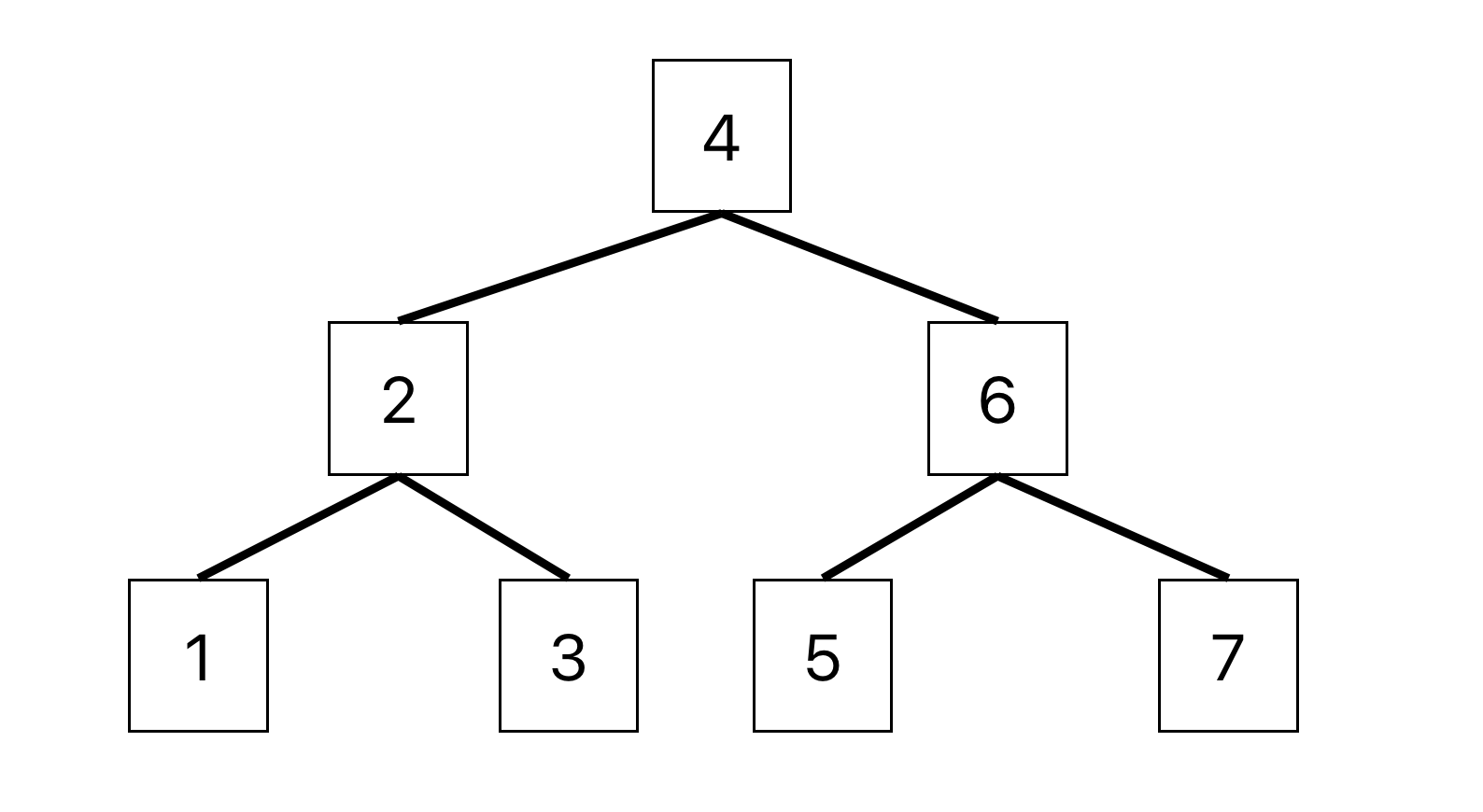
↓
nodeの定義の仕方
typedef struct node{
int number;
struct node *left;
struct node *right;
}node;
二分探索と同様なので検索の実行時間はO(log(n))
→実装時に、右の子だけ連結して二分探索木ではあるけど、ただの連結リストになってしまう場合もある
→意図しない形になる可能性について考える必要がある
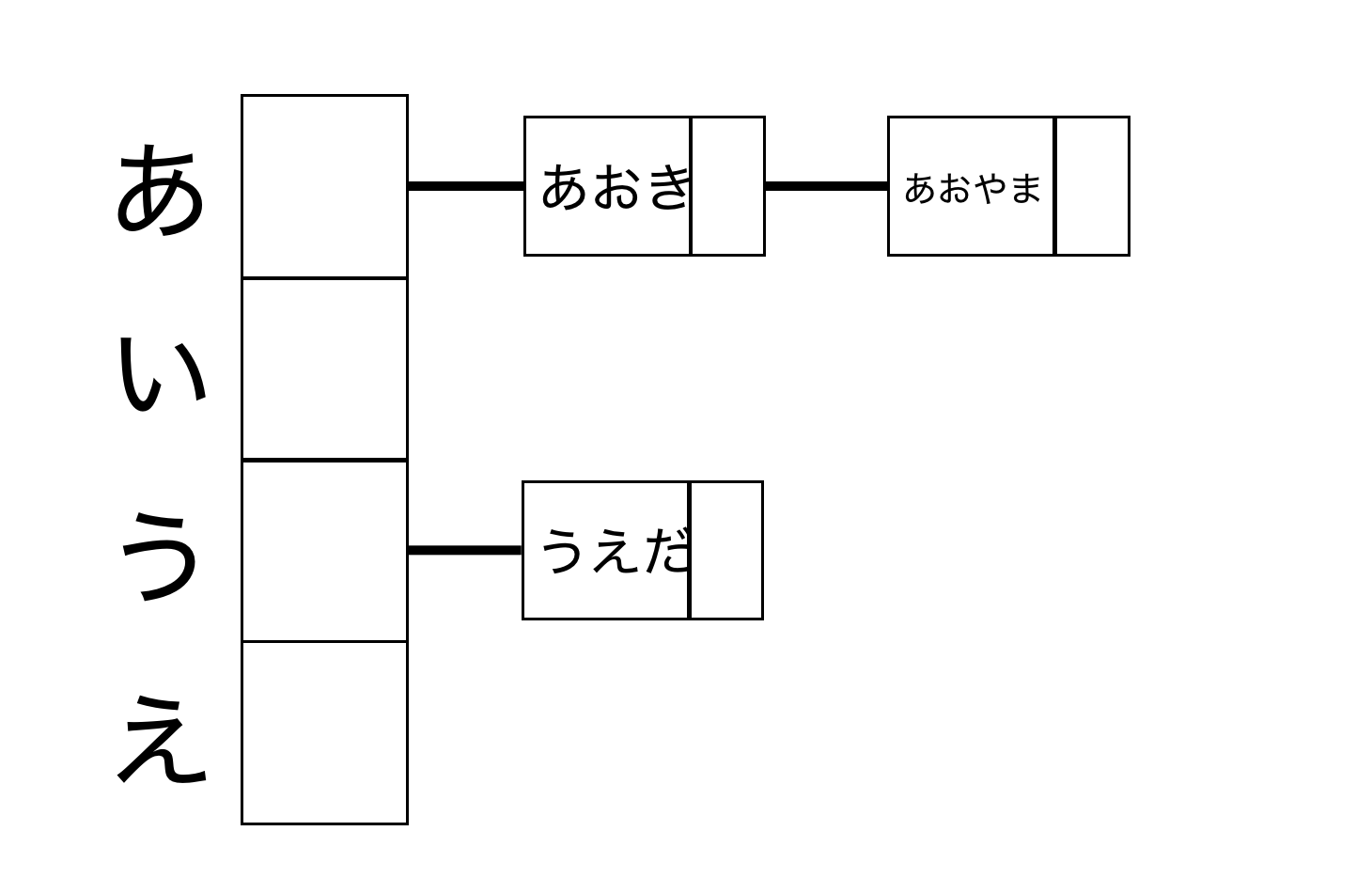
ハッシュテーブル
配列と連結リストを組み合わせたデータ構造→ 連結リストを要素とする配列
キーと値を関連づける
例)
ノードの表し方
typedef struct node{
char word[LONGEST_WORD + 1];
struct node *next;
}node;
- パフォーマンスについて考える
→理論上1つの配列の要素に大量の連結リストが入り→O(n)
→実際はただの連結リストよりハッシュテーブルの方が、配列の要素倍効率的である
tries
巨体なデータセットでも、一定時間で検索が可能なツリー
配列からツリーを作る→多層界のハッシュテーブル
typeof struct node {
bool is_word;
struct node *children[SIZE_OF_ALPHBET];
}node;
→検索の実行時間はO(1)だが、その分メモリを使用する、、、、