Webスクレイピングを行う上で便利だったブラウザのデベロッパーツールについて備忘録代わりに紹介しておきます。
Webスクレイピングとは?
wikipediaのウェブスクレイピングのページに概要は書いてあります。簡単に言えば、Web上から情報を収集するための技術ってことですね。今回はMicrosoftのOffice365のFAQがデータとして欲しかったので、MicrosoftのOffice365のFAQのページから必要な情報を抽出するプログラムを作りました。
開発環境
Webスクレイピングのライブラリが豊富なPythonを使ってます。
- Ubuntu 16.04 LTS / 64bit
- Python3.6
- urllib.request : Webページにアクセスするライブラリ
- bs4.BeautifulSoup : Webページをパースし、FAQだけを抽出するのに必要なライブラリ
Pythonプログラム
web_scraping関数内でurllib.requestとBeatifulSoupライブラリを使うことで、パースされた情報がリスト型で返されます。urlはMicrosoftのFAQページ、headersにはユーザーエージェントを指定しています。request.urlopenを実行する際に、headersを指定していないと弾かれてしまうのでFirefoxのユーザーエージェント情報を指定しています。ユーザーエージェントについてはこちらのサイトを参考にしました。パースする際の条件にCSSセレクタを使っています。CSSセレクタを指定することで、html形式で書かれたページ内から任意の要素を抽出することができます。CSSセレクタの書式はこちらになります。ですが、このCSSセレクタが厄介で、使い慣れていない限り、何をどのようにして条件を設定すればいいのかが分かりづらいです。そこで頼りになるのが、ブラウザのデベロッパーツールです。デベロッパーツールについては、次項で説明しています。デベロッパーツールを利用して、Webページのhtml構造を把握し、抽出したいCSSセレクタを取得します。css_selector_titleはFAQの質問文、css_selector_textは質問文に対する回答を抽出するためのCSSセレクタです。抽出したFAQをファイルに書き込むことで完了なのですが、BeautifulSoupで抽出した情報にはhtmlタグがありますので、htmlタグを除去します。それを行う関数がMyHtmlStripperです。この関数はこちらのサイトから拝借いたしました。
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from urllib import request
from time import sleep
from numpy.random import *
from MyHtmlStripper import MyHtmlStripper
def web_scraping(url, headers, css_selector):
req = request.Request(url = url, headers = headers)
res = request.urlopen(req)
soup = BeautifulSoup(res, "html.parser")
return soup.select(css_selector)
if __name__ == "__main__":
url = "https://products.office.com/ja-jp/business/microsoft-office-365-frequently-asked-questions"
headers = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",}
with open("Office365FAQ.txt", "a") as f:
for i in range(1, 31):
css_selector_title = "#question_title_{}".format(i)
css_selector_text = "#question_title_{}-content > div:nth-of-type(1)".format(i)
html_title = web_scraping(url, headers, css_selector_title)
html_text = web_scraping(url, headers, css_selector_text)
f.write(MyHtmlStripper(str(html_title[0])).value + "\n")
f.write(MyHtmlStripper(str(html_text[0])).value + "\n")
sleep(randint(5,11))
# -*- coding: utf-8 -*-
import io
from html.parser import HTMLParser
class MyHtmlStripper(HTMLParser):
def __init__(self, s):
super().__init__()
self.sio = io.StringIO()
self.feed(s)
def handle_starttag(self, tag, attrs):
pass
def handle_endtag(self, tag):
pass
def handle_data(self, data):
self.sio.write(data)
@property
def value(self):
return self.sio.getvalue()
デベロッパーツール
Firefoxのデベロッパーツールを使うには、画像のようにブラウザの右上の3本線をクリックし、ウェブ開発をクリックします。
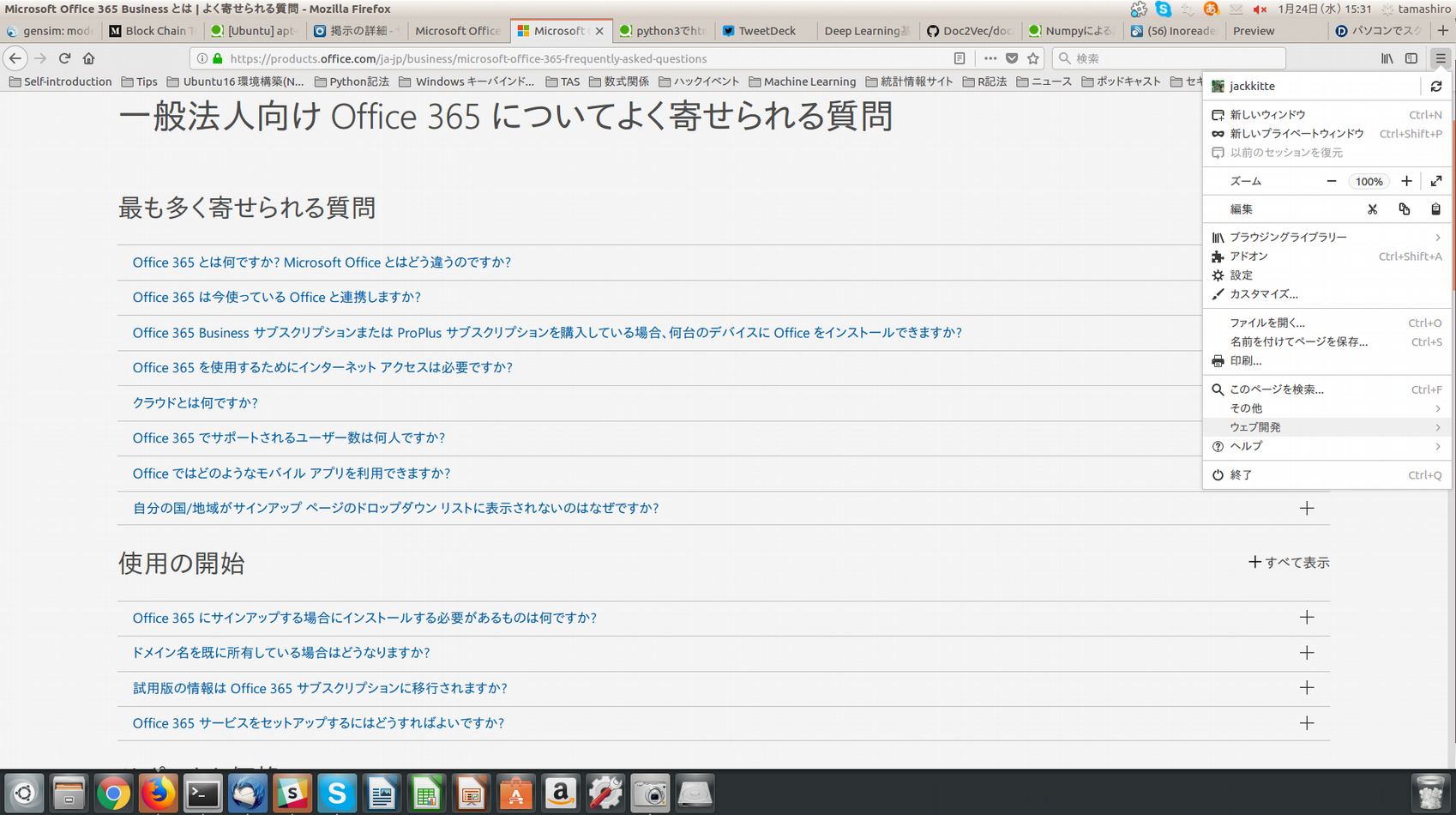
すると、画像のようにウェブ開発タグに変わりますので、その中の開発ツールを表示をクリックします。
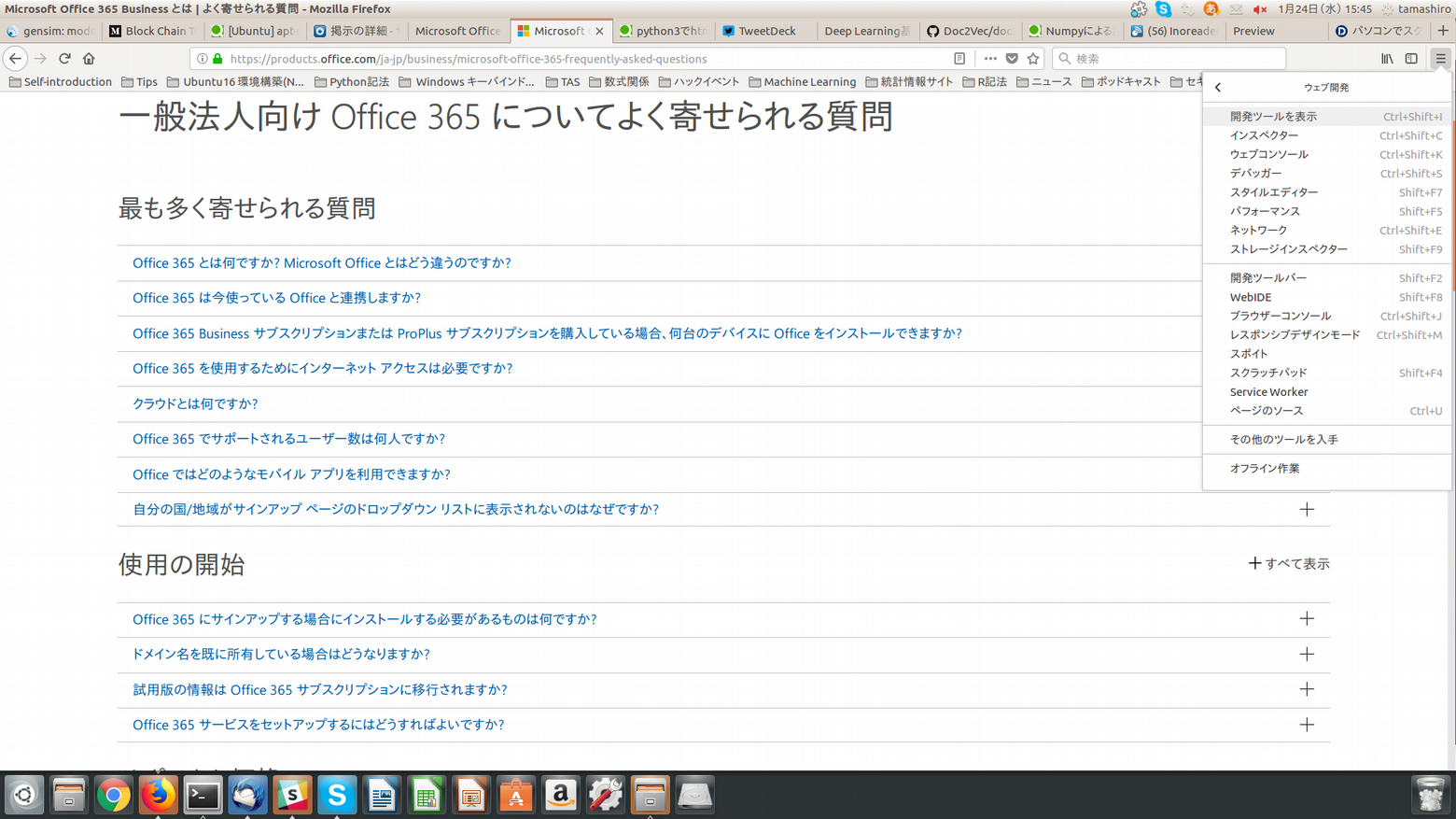
すると、ブラウザ下部に開発ツール用の画面が表示されます。開発ツールを用いると便利です。
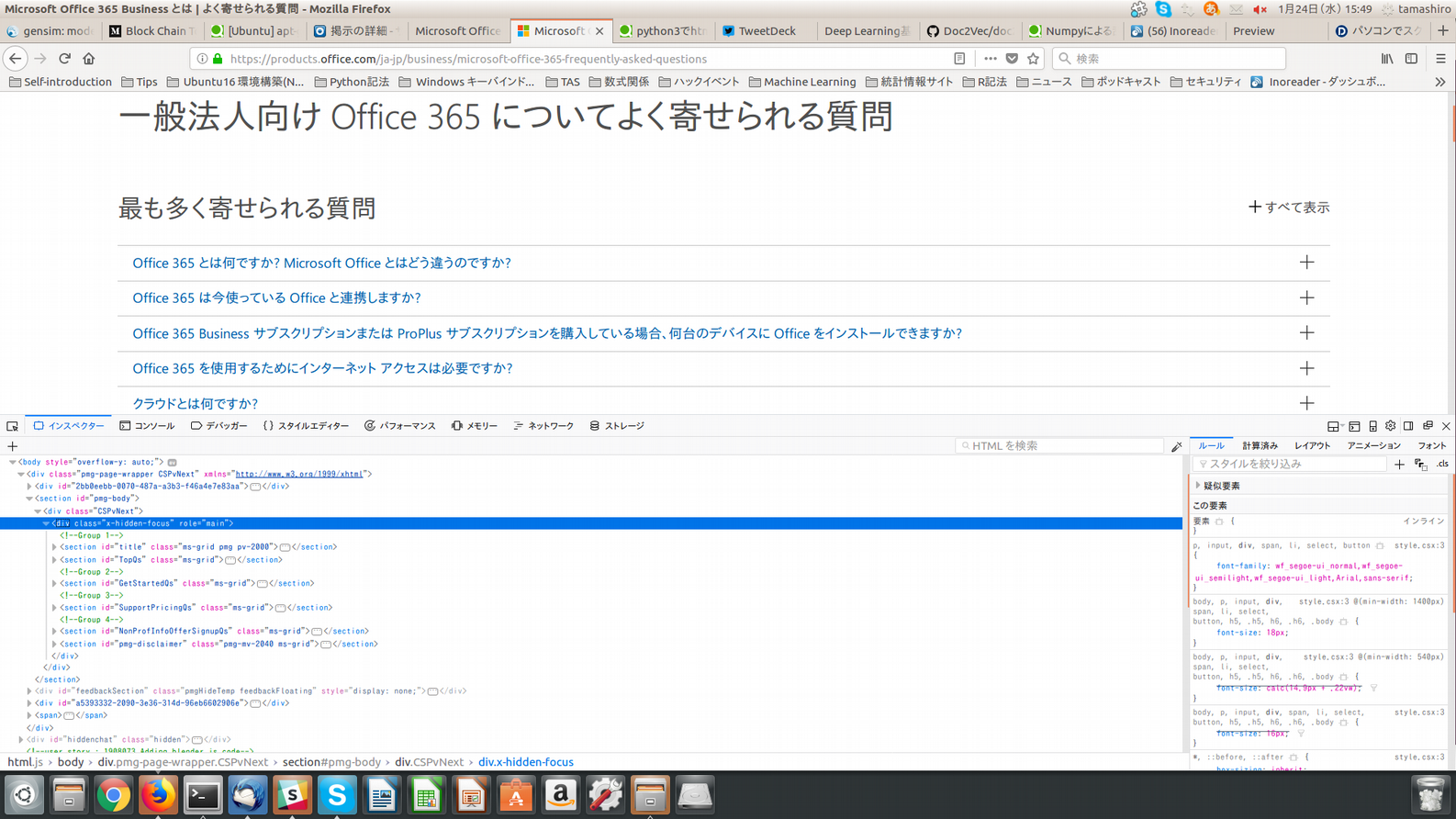
今回の場合ですと、開発ツール内のhtml構造を探索していくと、画像のように選択したhtml構造がwebページのどの部分かを水色で表示してくれます。このような機能を用いて、複雑なhtml構造の探索も簡単に行なえます。
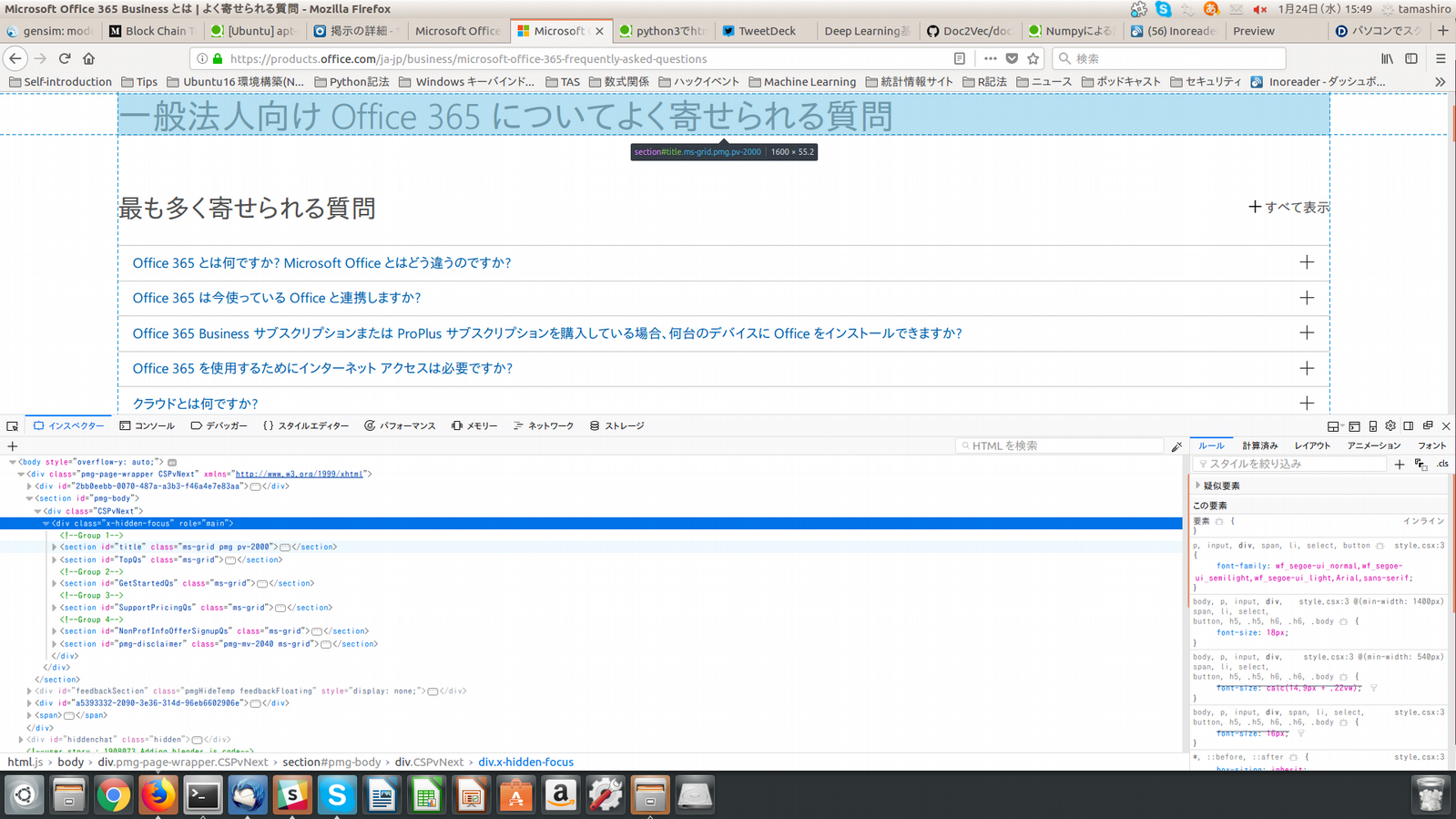
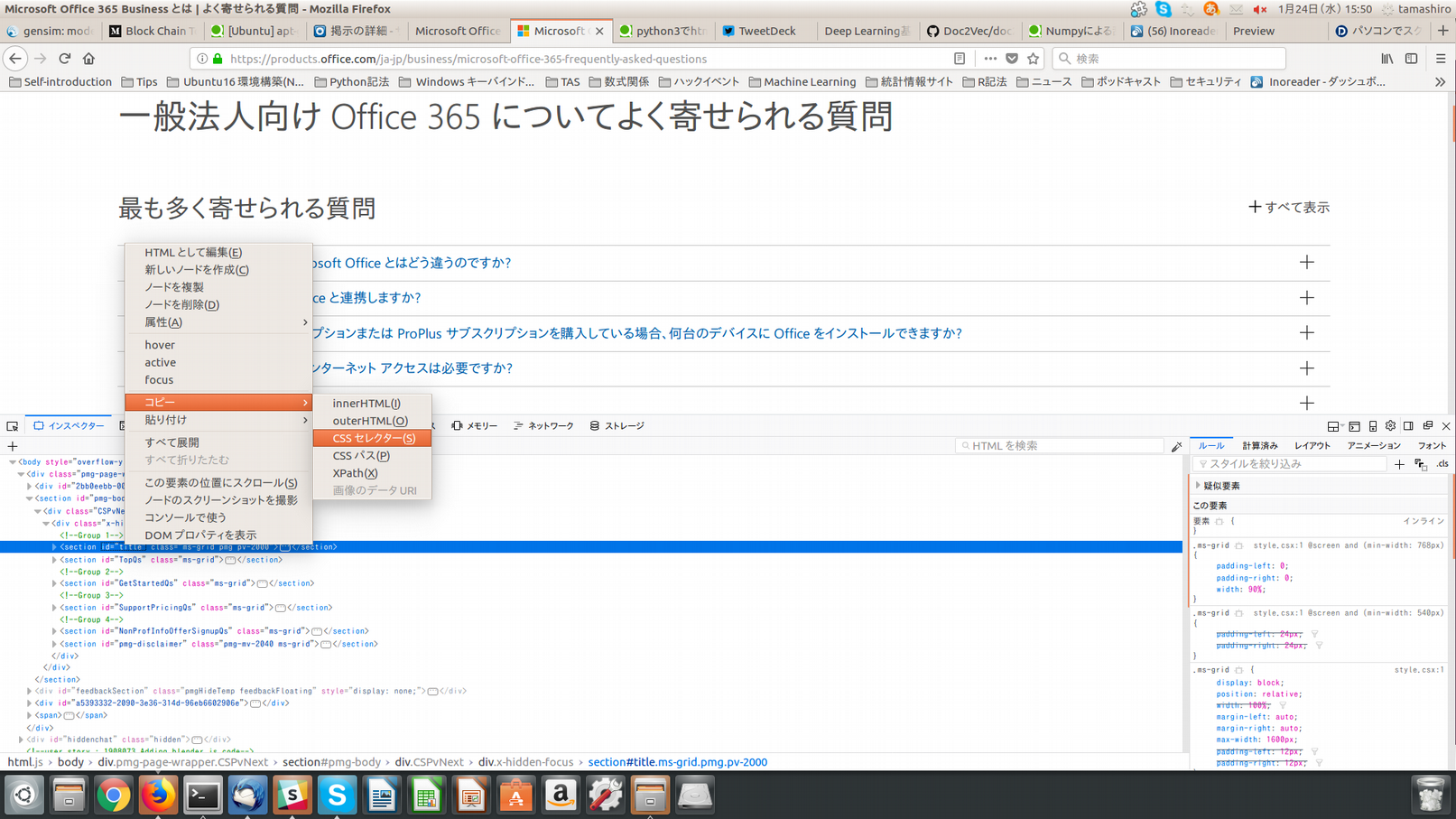
抽出したい部分を見つけたら、その部分を抽出するためのCSSセレクタを設定します。それも開発ツールを使えば簡単で、画像のように選択したhtml構造の部分で右クリックし、コピー→CSSセレクタの順で選択しますと、CSSセレクタがクリップボード上にコピーされます。この場合ですと"#title"がCSSセレクタになります。
忘れた時のために.....
前にも同じことをやった記憶はあるんですが、やり方をすっかり忘れていたので、今回は記事として残しておこうと思い記しました。Pythonを使えばWebクロール&スクレイピングを簡単に行うことができます。ですが、最近は規制やら何やらが厳しくなっているので、クロール&スクレイピングをする時は注意する必要があります。