前回はZabbixの導入を記しました。
今回は、PostgreSQL(Zabbixデータ格納先)からLogstash経由でElsticsearchへデータを格納し、Kibanaでの可視化までを記していきます。
導入環境
- OS : Ubuntu 16.04 LTS / 64bit
- PostgreSQL : 9.5
- Elasticsearch : 6.0.0
- Logstash : 6.0.0
- Kibana : 6.0.0
Logstashのインストール
インストールは公式サイトの以下のページに書いてあります。
こちらのページからDEBファイルをダウンロードし、dpkgコマンドにてインストールできます。
sudo dpkg -i logstash-6.0.0.deb
利用するLogstash Plugins
Input Pluginsのlogstash-input-jdbcを利用します。logstash-input-jdbcはJDBC接続でDBに接続することが可能です。JDBC Driverさえ用意すれば、対応するDBからデータ取得が可能です。MySQL、PostgreSQL、OracleDB、MSSQLなど代表的なDBには対応しています。Ubuntu16.04でdebファイルを使ってLogstashをインストールした場合のコマンドは/usr/share/logstash/bin内にあります。
sudo /usr/share/logstash/bin/logstash-plugin install logstash-input-jdbc
JDBC Driverのダウンロード
今回はPostgreSQL用のJDBC Driverを使用します。PostgreSQLのDriverは以下のページから探してきます。Current Versionの項目にPostgreSQL JDBC 4.2 Driver, 42.1.4と書かれたダウンロードリンクがありますので、こちらをクリックするとpostgresql-42.1.4.jarというjarファイルをダウンロードできます。(私が導入した時点でのバージョンです。もしかしたらこれを読んでいる時点での数字部分は変わっている場合があります。2017年12月27日)
PostgreSQLから引っ張ってくるデータ
PostgreSQLにはZabbixの初期設定で設定したDB、テーブルがあります。その中で時系列データが格納されているテーブルがtrends(1年分のデータ)、history(1週間分のデータ)の2つです。今回はtrendsテーブルを参照します。また、trendsテーブルに格納されている各データ情報(cpu, memory, network等々)も必要なので、itemsテーブルも一緒に参照します。
Logstash設定ファイル例
- inputにjdbcを指定し、logstash-input-jdbcを利用します。
- 指定可能なパラメータは公式ドキュメントをご参照ください。今回は最低限のDriver、Driver Class、URL、Username、Password、SQLを指定します。
- outputにElasticsearchのプラグイン、Elasticsearchホスト、データを投入するindexを指定します。
input {
jdbc {
jdbc_driver_library => "jarファイルの格納先/postgresql-42.1.4.jar"
jdbc_driver_class => "org.postgresql.Driver"
jdbc_connection_string => "jdbc:postgresql://localhost:5432/zabbix"
jdbc_user => "zabbix"
jdbc_password => "****************"
statement => "select itemid, items.name, items.hostid, to_timestamp(trends.clock), trends.num, trends.value_min, trends.value_avg, trends.value_max from trends JOIN items using (itemid)"
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "trends"
}
}
Elasticsearchへの取り込み
作成した設定ファイルを元にLogstashを起動し、DBからElasticsearchへデータを送ります。
/usr/share/logstash/bin/logstash -f jdbc.conf
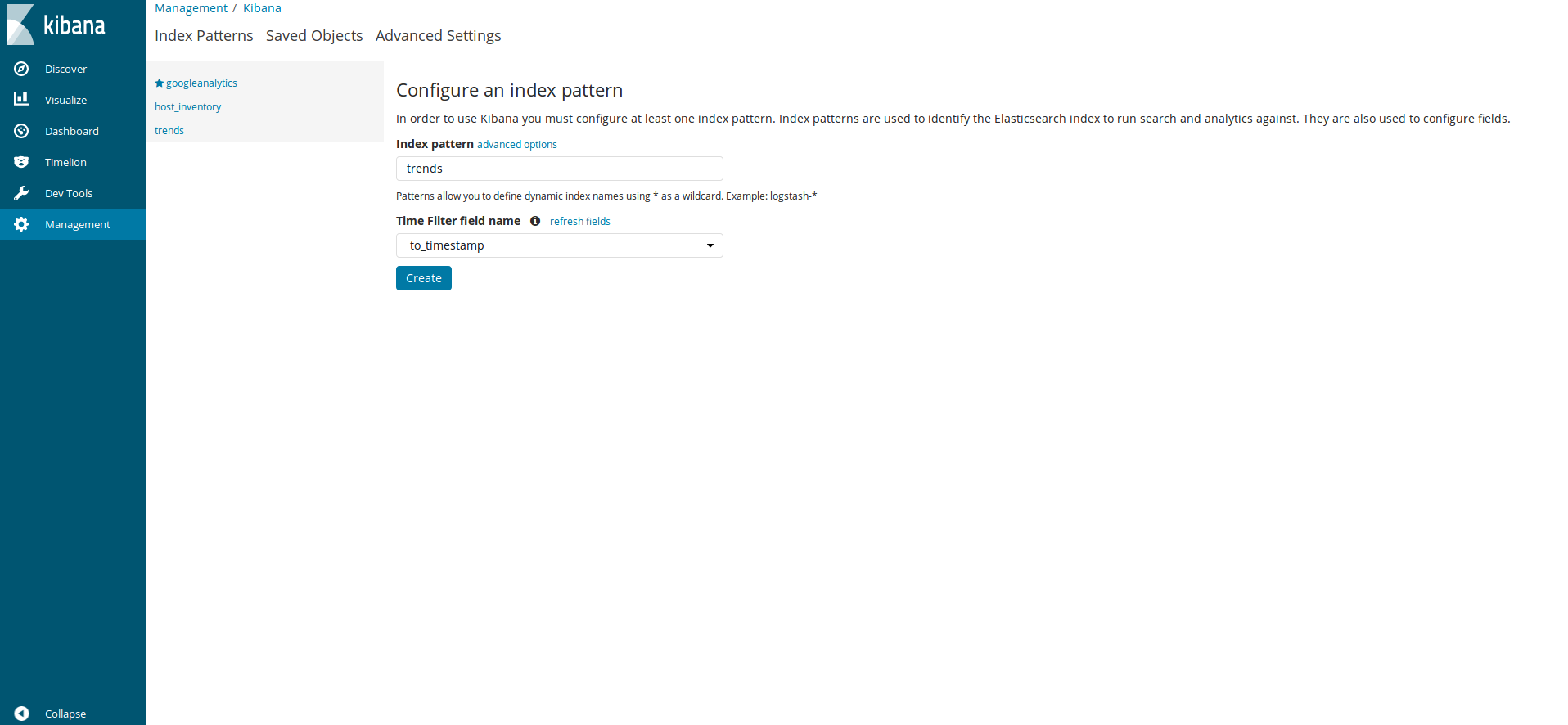
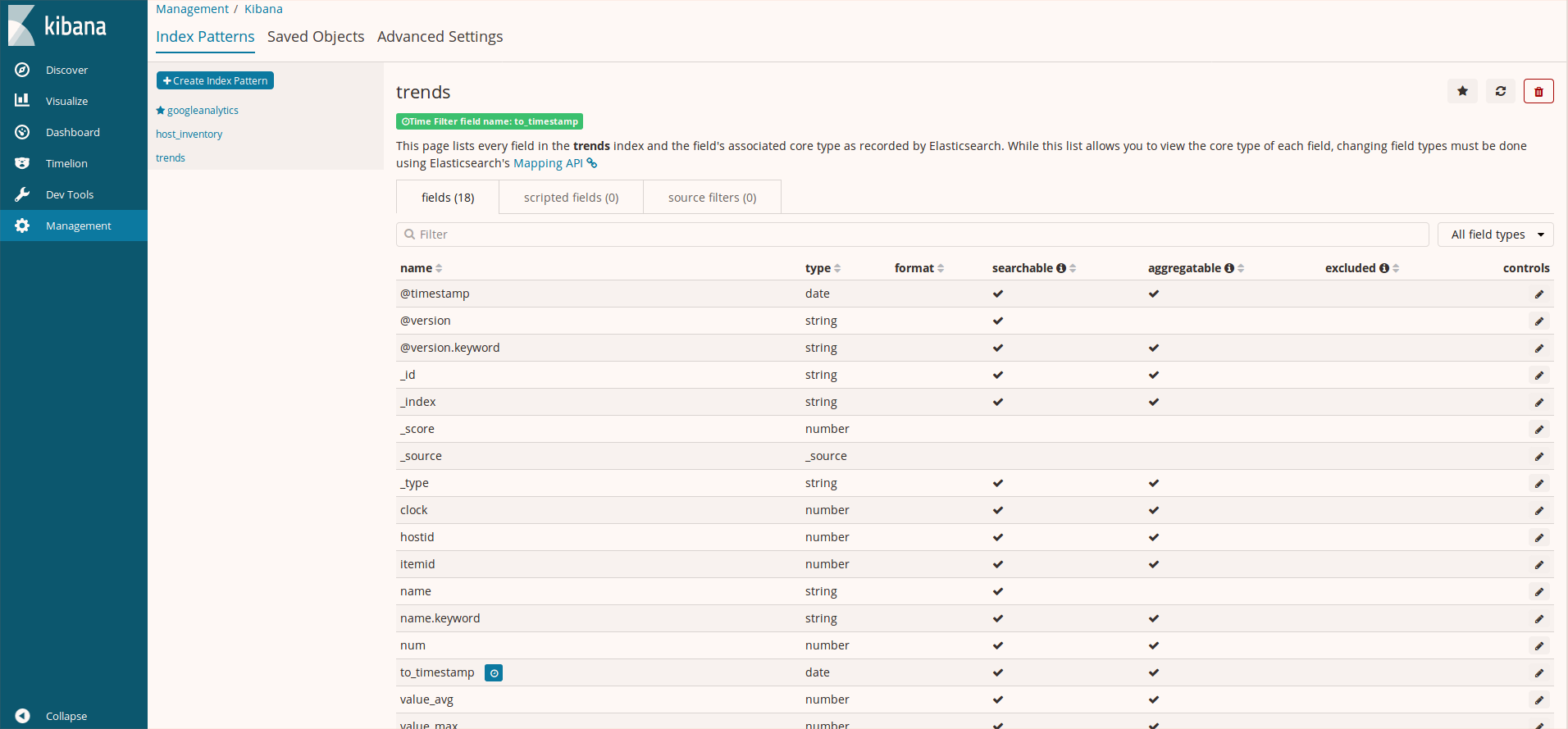
indexが作成されたかKibanaで確認します。KibanaのManagementのCreate Index Patternをクリックし登録したindex名(今回はtrends)をindex patternに入力すると、以下のようにtrendsインデックスが見つかります。Time Filter field nameにはto_timestamp(UNIX時間をpostgresqlコマンドのto_timestampで変換したフィールド)を設定してあります。
Kibanaでの可視化
今回は、初期設定の各項目の中のCPU utilization情報を可視化します。zabbixではCPU utilizationは以下のように見れます。
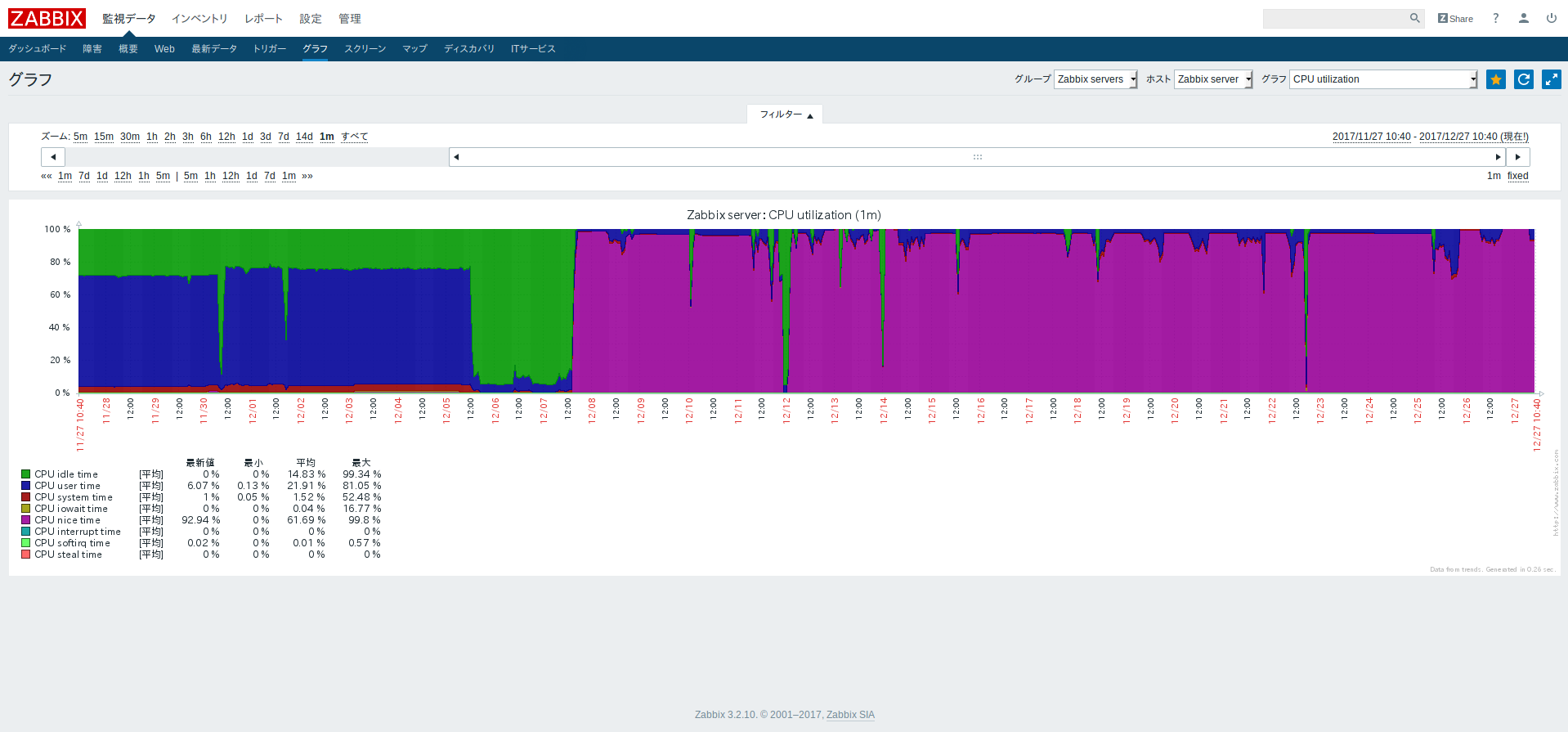
CPU utilizationは8項目の情報を取得しており、PostgreSQLでのitem IDは23299〜23306となります。なので、KibanaのVisualizeで可視化する際に条件として以下をlucene queryとして設定しています。
itemid: 23299 or itemid: 23300 or itemid: 23301 or itemid: 23302 or itemid: 23303 or itemid: 23304 or itemid: 23305 or itemid: 23306
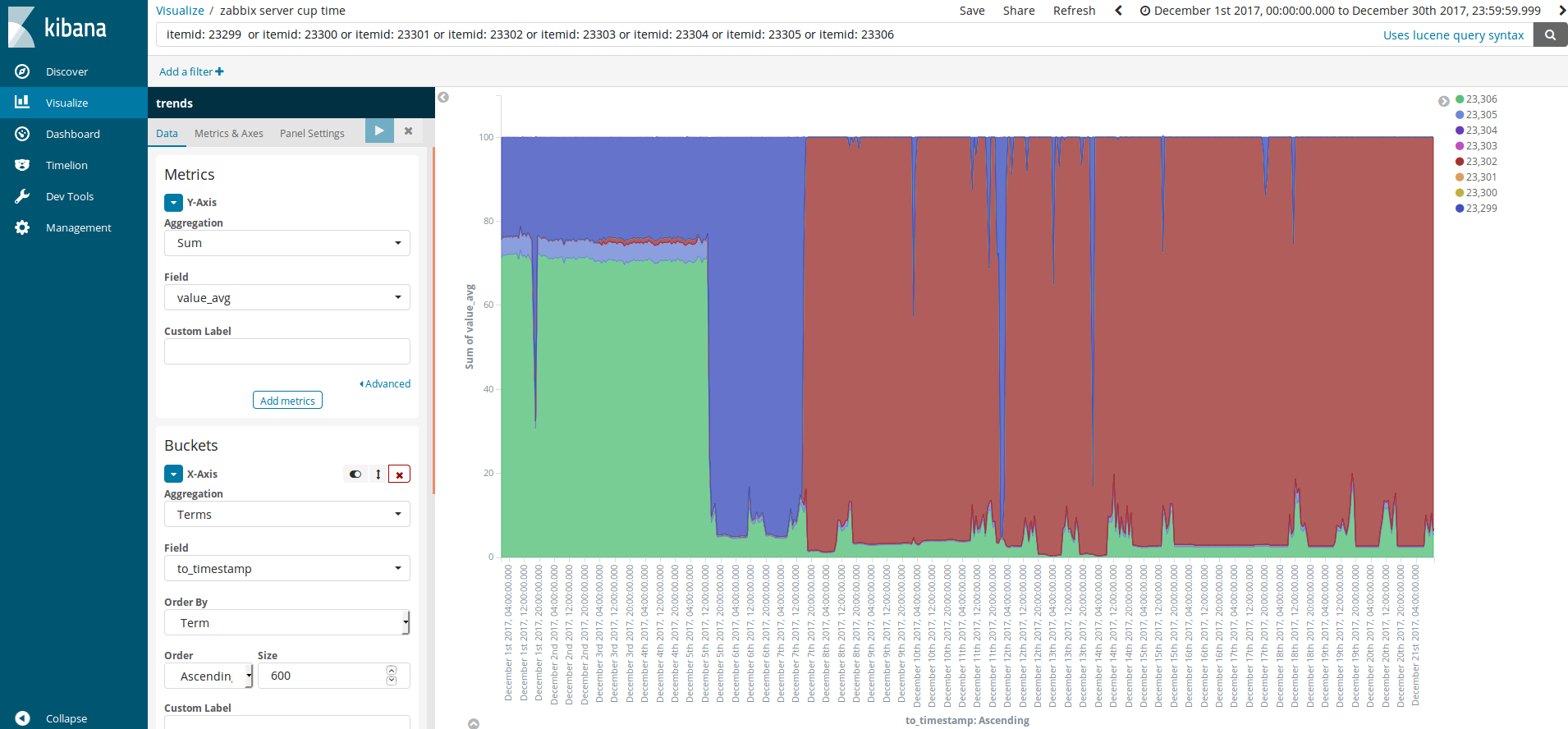
やったね!
取り敢えずは、ZabbixのデータをElasticsearch上で取り扱えるところまでは上手くいきました!しかし、実は可視化の部分において色々と設定しなければならないところが多くて大分時間を使っていたので、だったら、RやPythonで取り込んで可視化したほうが自分的には簡単だったのではないかと思っていたりしてます。ただ、恐らくそこら辺は、Elasticsearchの仕様に合わせてZabbixから流れるデータ項目設定(PostgreSQLでのテーブルやスキーマなど)をしてやればいいのかなと感じました。