こんにちは!J-Quants運営チームです。
運営チームでは、個人向けに金融データをAPIで配信するサブスクリプションサービスであるJ-Quantsを活用した、金融データの分析例などの技術記事を投稿しています。
このたび、J-Quants API V2の新しいアドオンとしてTDnet/Company Disclosure(TDnet/適時開示情報アドオン)(以下、TDnet-addon)をリリースいたしました。本アドオンを契約いただくと、適時開示書類を、開示同日に速やかに取得できるようになります。具体的には、過去5年分の適時開示インデックス情報、および全文情報PDF・サマリ情報PDF・XBRLファイルをAPI経由で取得可能です。
本記事では、
- TDnet-addonの概要と契約方法
- 3つのAPIエンドポイントの仕様と利用例(Pythonから
requestsで直接叩く) - 実用ユースケース2例(特定銘柄のPDF一括ダウンロード/日中の差分取得)
を通じて、契約から実装、運用までの一連の流れを紹介します。
なお、本記事で扱うデータの取得には、J-QuantsのTDnet/適時開示情報アドオンのご契約が必要です。
J-Quantsについては、巻末のJ-Quantsとはをご参照ください。
適時開示制度とTDnetについて
適時開示制度とは
適時開示とは、上場会社が投資判断に重要な影響を与える会社情報を、適時・適切に開示することを目的とした制度です。東京証券取引所(以下、東証)の有価証券上場規程等に基づき、上場会社には、決算情報、業務上の決定事項、発生事実、子会社等に係る情報などを開示する義務が課せられています。
これら適時開示情報の公衆縦覧手段として東証が運営しているシステムがTDnet(Timely Disclosure network)です。上場会社がTDnetを通じて開示した情報は、東証のWebサイト上の適時開示情報閲覧サービスで原則1か月間公開されます。
TDnet-addonで取得できるデータ
TDnet-addonでは、TDnetで開示された情報のうち、過去5年分のインデックス情報と添付ファイル(PDF・XBRL)をAPI経由で取得できます。
| データ | 内容 |
|---|---|
| インデックス情報 | 開示番号・開示日時・銘柄コード・会社名・タイトル・公開項目コード・添付書類種別 |
| 全文情報PDF | 開示資料の本文PDF |
| サマリ情報PDF | 決算短信等のサマリPDF |
| XBRL関連ファイル | 機械可読な構造化データ(決算短信等の財務諸表) |
タイムリーなデータ配信
TDnet-addonの特徴は、J-Quantsの中でも配信タイミングがタイムリーであることです。J-Quantsの既存データは日次バッチでの更新が中心ですが、本アドオンの適時開示データは、TDnetで公開されてからおおむね数分〜数十分(混雑時は1時間程度)の遅延でAPIから取得可能になります。
決算発表直後の銘柄ウォッチや、コーポレートアクションを日次より細かい粒度で追跡するなど、これまで日次バッチではカバーしきれなかったユースケースに対応できるようになりました。
ご利用上のご注意:あくまでリアルタイムではありません
前述の通り、TDnet-addonはJ-Quantsの中ではタイムリーなデータ配信を実現していますが、秒単位のリアルタイム性は保証していません。配信経路を経由する都合上、ある程度の時間差が生じます。とくに以下のような状況では、平常時より大きな遅延(最大1時間程度)が発生する可能性があります。
- 決算発表が集中する時間帯(例:15:00・15:30前後など)に開示量が一時的にスパイクする場面
- 配信基盤のメンテナンス・運用状況により一時的に処理が滞る場面
リアルタイム性を重視するコード(後述のポーリングやイベントトリガー型処理など)を組まれる場合は、「APIへの反映には常に多少の遅延が発生し得る」ことを前提に設計してください。短い間隔でリクエストしてもこの遅延を縮められるわけではなく、サーバーへの負荷を高めるだけになりますので、ご利用方法にはご注意ください。
TDnet-addonの契約手順
TDnet-addonは、有料のベースプラン(Light以上)に追加する形でご契約いただけます。
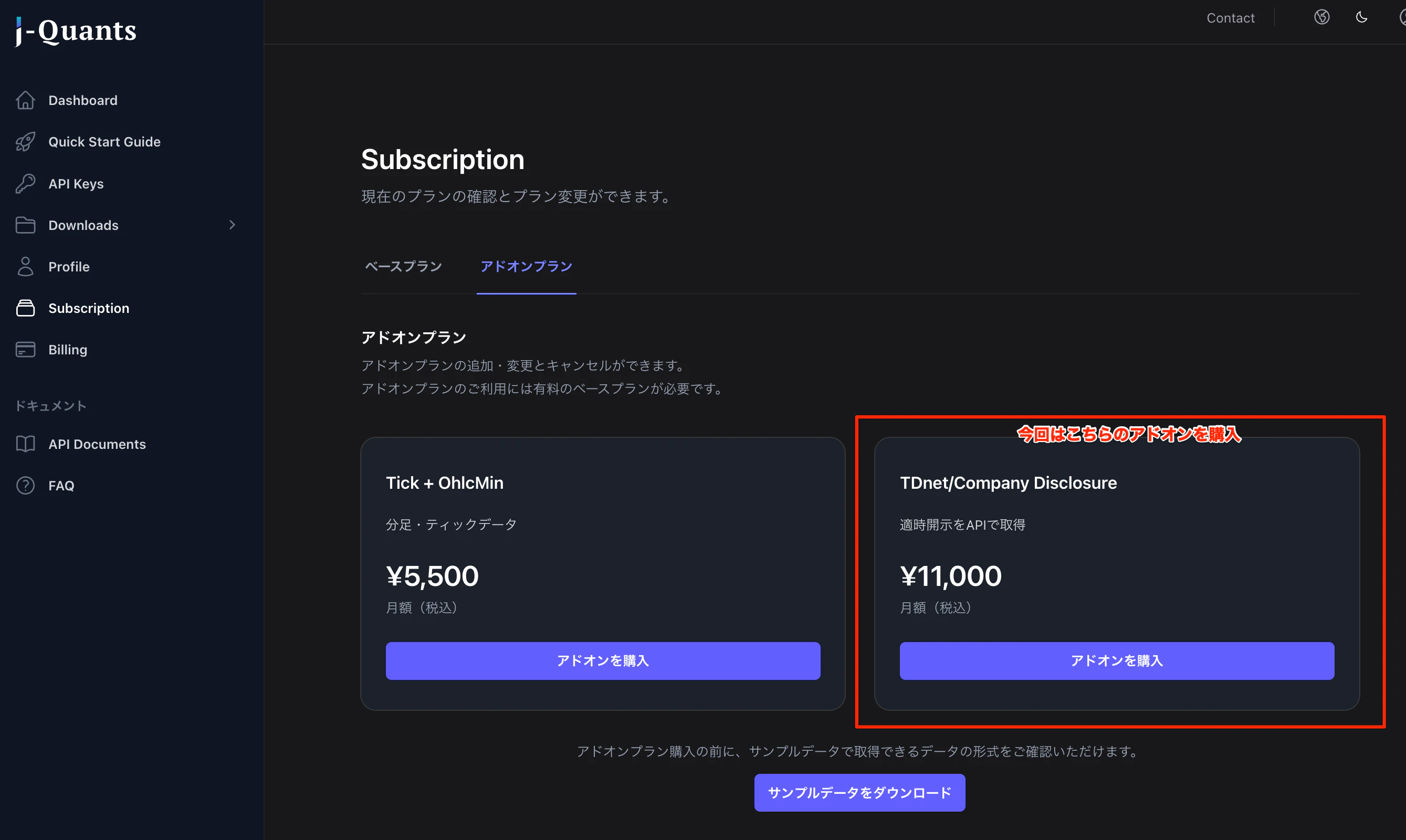
ダッシュボードのサイドメニュー[Subscription]から[アドオンプラン]タブを開き、「TDnet/Company Disclosure」カードの[アドオンを購入]ボタンから申込み手続きを進めてください。
決済が完了するとサブスクリプション画面のカードに[ご利用中]バッジが表示され、TDnet-addonのエンドポイントが利用可能になります。既に発行済みのAPIキーをそのまま使えますので、アドオン契約のためにAPIキーを再発行する必要はありません。
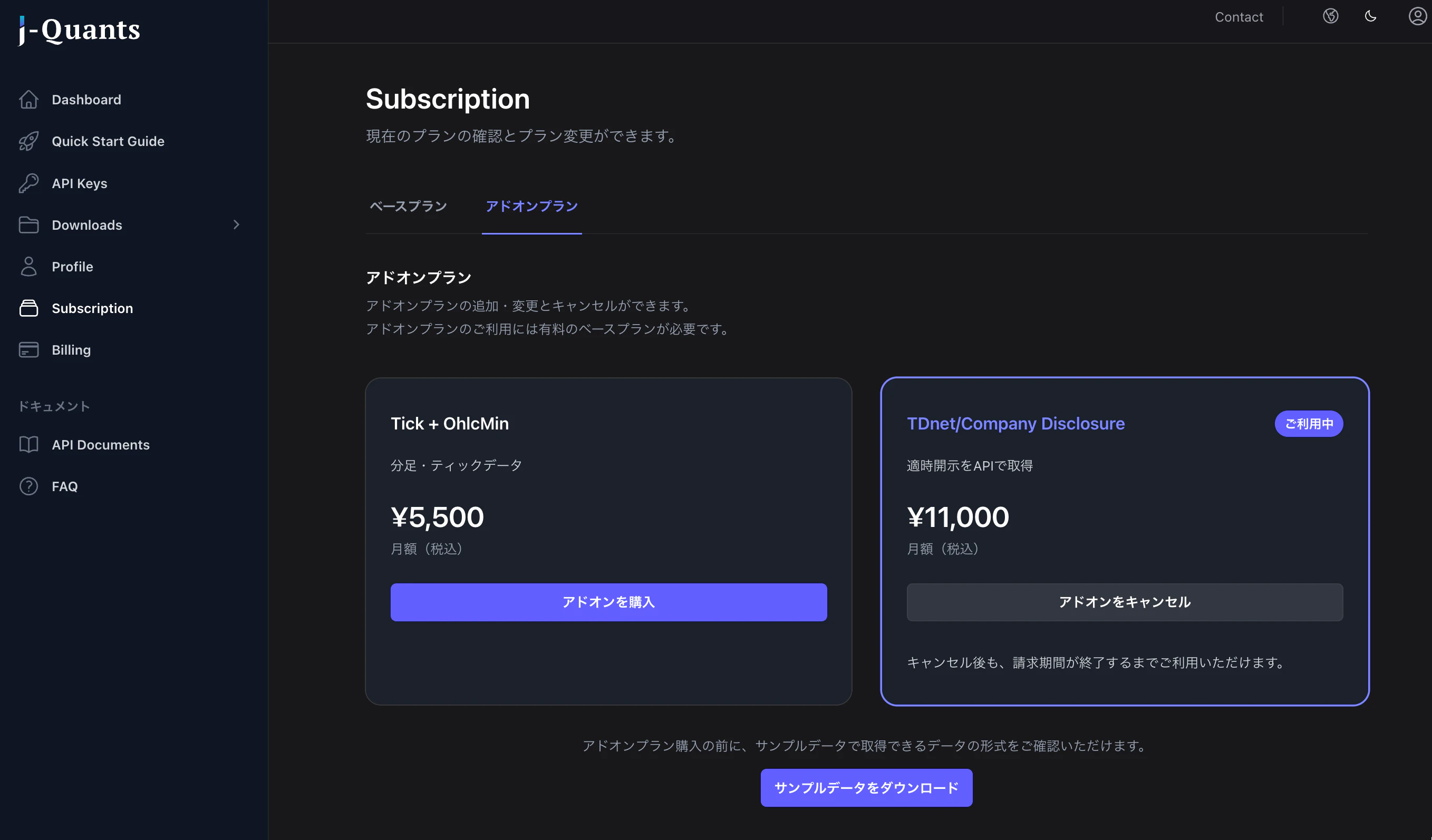
なお、APIキーはサイドメニュー[API Keys]から確認できます。本記事のサンプルコードでは、このAPIキーをローカルの.envファイルにJQUANTS_API_KEYとして保存して利用します。
# .env
JQUANTS_API_KEY=your_api_key_here
APIで取得する
ここからは、TDnet-addonの3つのAPIエンドポイントをPythonのrequestsから直接叩いて、実データを取得していきます。
API仕様の俯瞰
| エンドポイント | 用途 | 主要パラメータ |
|---|---|---|
GET /v2/td/list |
インデックス一覧取得 |
dateまたはcode(いずれか必須) |
GET /v2/td/files |
添付ファイルのダウンロードURL取得 |
discNo(必須) |
GET /v2/td/bulk |
過去5年分の一括CSVダウンロードURL取得 | (なし) |
すべてHTTPメソッドはGET、認証はx-api-keyヘッダーで行います。
環境準備
本記事のサンプルコードはPython 3.14を前提とします。requests,pandasをインストールしてください。
pip install requests pandas python-dotenv
.envファイルにAPIキーを記述しておきます(前述)。
import os
import time
import pathlib
import requests
import pandas as pd
from dotenv import load_dotenv
load_dotenv(".env")
API_KEY = os.environ["JQUANTS_API_KEY"]
BASE_URL = "https://api.jquants.com"
HEADERS = {"x-api-key": API_KEY}
利用例1:指定日の開示一覧を取得(/v2/td/list)
date
パラメータに開示日を指定すると、その日の開示情報の一覧を取得できます。
resp = requests.get(
f"{BASE_URL}/v2/td/list",
params={"date": "2026-05-15"},
headers=HEADERS,
)
data = resp.json()
df = pd.DataFrame(data["data"])
print(f"取得件数: {len(df)}件")
df.head()
取得件数: 3445件
| DiscNo | Code | Name | DiscDate | DiscTime | Title | DiscStatus | RevNo | DiscItems | Docs |
|---|---|---|---|---|---|---|---|---|---|
| 20260511523313 | 241A0 | G-ROXX | 2026-05-15 | 08:00 | 2026年9月期第2四半期 決算説明会Q&Aの公開に関するお知らせ | 1 | [‘11322’] | [‘g’] | |
| 20260511523321 | 241A0 | G-ROXX | 2026-05-15 | 08:00 | 2026年9月期第2四半期 決算説明会Transcriptの公開に関するお知らせ | 1 | [‘11322’] | [‘g’] | |
| 20260511523325 | 241A0 | G-ROXX | 2026-05-15 | 08:00 | 2026年9月期第2四半期 決算説明会 動画公開に関するお知らせ | 1 | [‘11802’] | [‘g’] | |
| 20260514533272 | 48750 | メディシノバ | 2026-05-15 | 08:00 | 2026年12月期 第1四半期決算短信〔米国基準〕(連結) | 1 | [‘11305’] | [‘g’, ‘s’] | |
| 20260514533280 | 48750 | メディシノバ | 2026-05-15 | 08:00 | 2026年12月期 第1四半期決算補足説明資料 | 1 | [‘11322’] | [‘g’] |
レスポンスの主要フィールドは以下のとおりです。
| フィールド | 説明 |
|---|---|
DiscNo |
開示番号(14桁。後続の/v2/td/filesで使用) |
Code |
銘柄コード(4桁または5桁) |
Name |
会社名 |
DiscDate / DiscTime
|
開示日/開示時刻 |
Title |
開示タイトル |
DiscItems |
公開項目コードの配列(決算短信・自己株式取得等を識別) |
Docs |
添付書類の種別(g:全文PDF、s:サマリPDF、x: XBRL) |
DiscItemsの公開項目コードは、TDnet API仕様書付録1で一覧を確認できます。たとえば「決算短信〔日本基準〕(連結)」は
11301です。
discItemsで絞り込む
discItems
クエリパラメータに公開項目コードを指定すると、特定の種類の開示だけを抽出できます。複数指定するとカンマ区切りでAND条件になります。
# 決算短信〔日本基準〕(連結)のみ抽出
resp = requests.get(
f"{BASE_URL}/v2/td/list",
params={"date": "2026-05-15", "discItems": "11301"},
headers=HEADERS,
)
df_earnings = pd.DataFrame(resp.json()["data"])
print(f"抽出件数: {len(df_earnings)}件")
df_earnings[["Code", "Name", "Title"]].head()
抽出件数: 426件
| Code | Name | Title |
|---|---|---|
| 30590 | ヒラキ | 2026年3月期 決算短信〔日本基準〕(連結) |
| 79880 | ニフコ | (訂正・数値データ訂正)「2026年3月期 決算短信〔日本基準〕(連結)」の一部訂正について |
| 80180 | 三共生興 | 2026年3月期 決算短信〔日本基準〕(連結) |
| 52370 | ノザワ | 2026年3月期 決算短信〔日本基準〕(連結) |
| 35510 | ダイニック | 2026年3月期決算短信〔日本基準〕(連結) |
利用例2:開示ファイルをダウンロードする(/v2/td/files)
/v2/td/listで取得したDiscNoを/v2/td/filesに渡すと、添付ファイルのダウンロードURLを取得できます。
# 添付ファイルの種別が揃っている決算短信(Docs=g|s|x)を例にする
target = df[df["Docs"].apply(lambda xs: set(xs) >= {"g", "s", "x"})].iloc[0]
disc_no = target["DiscNo"]
print(f"対象: {target['Name']} ({target['Code']}) - {target['Title']}")
resp = requests.get(
f"{BASE_URL}/v2/td/files",
params={"discNo": disc_no},
headers=HEADERS,
)
files = resp.json()["files"]
# URLは署名付きで15分で失効するため、ここではキー名と長さだけ確認する
{k: f"<signed URL> ({len(v)} chars)" for k, v in files.items()}
対象:ヒラキ(30590) - 2026年3月期 決算短信〔日本基準〕(連結)
{'pdf': '<signed URL> (413 chars)',
'summaryPdf': '<signed URL> (413 chars)',
'xbrl': '<signed URL> (406 chars)'}
レスポンスには、以下3種類のダウンロードURLが含まれます。
| フィールド | 内容 |
|---|---|
files.pdf |
全文情報PDF |
files.summaryPdf |
サマリ情報PDF(決算短信等に存在) |
files.xbrl |
XBRL関連ファイル(ZIP) |
実際にダウンロードして保存してみます。
out_dir = pathlib.Path("./downloads")
out_dir.mkdir(exist_ok=True)
# 全文情報PDFを保存
pdf_resp = requests.get(files["pdf"])
pdf_path = out_dir / f"{disc_no}.pdf"
pdf_path.write_bytes(pdf_resp.content)
print(f"保存しました: {pdf_path} ({pdf_path.stat().st_size:,} bytes)")
保存しました: downloads/20260514535526.pdf (600,419 bytes)
docsクエリパラメータで取得対象を絞ることもできます(g/s/xをカンマ区切りで指定)。XBRLだけ欲しい場合はdocs=xを指定すると、files.xbrlのみが返却されます。
利用例3:過去5年分を一括取得する(/v2/td/bulk)
過去5年分のインデックス情報をまとめて手元に置きたい場合は、/v2/td/bulkからgzip圧縮されたCSVをダウンロードできます。日次の差分取得を運用する前に、まず初期データを揃えるのに便利です。
import gzip
import io
# ダウンロードURLと最終更新日時を取得
resp = requests.get(f"{BASE_URL}/v2/td/bulk", headers=HEADERS)
bulk = resp.json()
print(f"最終更新: {bulk['lastUpdated']}")
# gzip CSV をダウンロードしてそのまま pandas で読み込む
csv_resp = requests.get(bulk["url"])
df_bulk = pd.read_csv(
io.BytesIO(gzip.decompress(csv_resp.content)),
dtype={"DiscNo": str, "Code": str, "DiscStatus": str, "RevNo": str},
)
print(f"全件数: {len(df_bulk):,}件")
print(f"期間: {df_bulk['DiscDate'].min()} 〜 {df_bulk['DiscDate'].max()}")
df_bulk.head()
- 最終更新: 2026-05-19T17:03:12Z
- 全件数: 757,197件
- 期間: 2021-05-20 〜 2026-05-19
| DiscNo | Code | Name | DiscDate | DiscTime | Title | DiscStatus | RevNo | DiscItems | Docs |
|---|---|---|---|---|---|---|---|---|---|
| 20210330486750 | 27640 | ひらまつ | 2021-05-20 | 10:13 | コーポレート・ガバナンスに関する報告書2020/05/20 | nan | 1 | 11727 | g |
| 20210412493247 | 18690 | 名工建 | 2021-05-20 | 16:00 | 剰余金の配当に関するお知らせ | nan | 1 | 11108 | g |
| 20210412493252 | 18690 | 名工建 | 2021-05-20 | 16:00 | 役員等の異動に関するお知らせ | nan | 1 | 11199 | g |
/v2/td/bulkのCSVではDiscItemsとDocsは|区切りの文字列として格納されている点に注意してください(/v2/td/listのレスポンスでは配列)。
# 「決算短信〔日本基準〕(連結)」を含むレコードのみ抽出
mask = df_bulk["DiscItems"].fillna("").str.contains("11301")
df_earnings_all = df_bulk[mask]
print(f"過去5年分の決算短信〔日本基準〕(連結): {len(df_earnings_all):,}件")
過去5年分の決算短信〔日本基準〕(連結): 17,728件
実用ユースケース
ここまででTDnet-addonの3つのAPIを一通り触ってきました。最後に、実際のユースケースとしてよくある2つの例を実装してみます。
ユースケース①:特定銘柄の開示PDF一括ダウンロード
特定の上場会社についてリサーチを行う際、過去の開示資料を手元にまとめて取得したいことがあります。/v2/td/listでcodeを指定して開示一覧を取得し、各DiscNoからPDFをダウンロードする流れで実現できます。
CODE = "86970" # 例: 日本取引所グループ
MAX_DOWNLOADS = 3 # 本記事では先頭3件のみ取得。
out_dir = pathlib.Path(f"./downloads/{CODE}")
out_dir.mkdir(parents=True, exist_ok=True)
# 1. 過去5年分の開示一覧を取得(code指定で from/to 省略時は直近5年)
resp = requests.get(
f"{BASE_URL}/v2/td/list",
params={"code": CODE},
headers=HEADERS,
)
disclosures = resp.json()["data"]
print(f"取得件数: {len(disclosures)}件")
# 2. 各開示のPDFをダウンロード
for d in disclosures[:MAX_DOWNLOADS]:
disc_no = d["DiscNo"]
pdf_path = out_dir / f"{d['DiscDate']}_{disc_no}.pdf"
# 既にダウンロード済みならスキップ(冪等に運用できるように)
if pdf_path.exists():
print(f" skip (cached): {pdf_path.name}")
continue
# ダウンロードURLを取得(全文PDFのみ)
files_resp = requests.get(
f"{BASE_URL}/v2/td/files",
params={"discNo": disc_no, "docs": "g"},
headers=HEADERS,
)
pdf_url = files_resp.json()["files"]["pdf"]
# PDF本体を取得して保存
pdf_resp = requests.get(pdf_url)
pdf_path.write_bytes(pdf_resp.content)
print(f" saved: {pdf_path.name} ({pdf_path.stat().st_size:,} bytes)")
# API レート制限への配慮
time.sleep(0.2)
取得件数: 281件
saved: 2021-06-01_20210531435522.pdf
saved: 2021-06-01_20210531435505.pdf
saved: 2021-06-16_20210611447409.pdf
fromとtoを併用すれば、期間を絞ることもできます。
# 2025年の開示のみ取得
resp = requests.get(
f"{BASE_URL}/v2/td/list",
params={"code": CODE, "from": "2025-01-01", "to": "2025-12-31"},
headers=HEADERS,
)
ユースケース②:本日分の開示をcursorで差分取得をし、イベントを検知する
ニュース配信や監視用途では、その日の新しい開示が出るたびに差分だけを取得したいケースがあります。/v2/td/listは、当日をdateに指定して呼び出すと、レスポンスにcursorを含めて返却します。次回の呼び出し時に同じdateと直前のcursorをセットで指定すると、それ以降に配信された開示だけが取得できます。
まずは、差分取得用のヘルパー関数を定義します。
from datetime import date as date_cls
def fetch_new_disclosures(today: str, cursor: str | None):
"""直近のcursor以降に追加された開示を取得して返す。"""
params = {"date": today}
if cursor:
params["cursor"] = cursor
new_items: list[dict] = []
while True:
resp = requests.get(
f"{BASE_URL}/v2/td/list",
params=params,
headers=HEADERS,
)
body = resp.json()
new_items.extend(body.get("data", []))
# pagination_keyが返ってきたら全件取得できていない → 即時に追加リクエスト
if "pagination_key" in body:
params = {"date": today, "pagination_key": body["pagination_key"]}
continue
# 全件取得できた場合は cursor が返るのでそれを次回に持ち越す
return new_items, body.get("cursor", cursor)
実際にリクエストしてみる
抽象的な説明だけでは挙動が掴みにくいので、本記事執筆時に上記のfetch_new_disclosuresを1分間隔で3回呼び出した結果を以下に示します。cursorを引き継ぐことで、2回目以降のリクエストでは「前回以降に新たに配信された開示」だけが返ってくることが確認できます。
from datetime import date as date_cls, datetime
today = date_cls.today().isoformat()
cursor = None
poll_log = []
all_new_items: list[dict] = [] # 3回分の新着開示を蓄積
for i in range(3):
requested_at = datetime.now().strftime("%H:%M:%S")
new_items, cursor = fetch_new_disclosures(today, cursor)
for item in new_items:
item["_poll"] = i + 1 # 何回目のリクエストで取得できたかを記録
all_new_items.extend(new_items)
poll_log.append({
"回数": i + 1,
"リクエスト時刻": requested_at,
"新着件数": len(new_items),
"cursor (先頭16字)": (cursor[:16] + "...") if cursor else "(なし)",
})
if i < 2:
time.sleep(60)
pd.DataFrame(poll_log)
| 回数 | リクエスト時刻 | 新着件数 | cursor (先頭16字) |
|---|---|---|---|
| 1 | 15:31:56 | 295 | eyJkIjoiMjAyNi0w... |
| 2 | 15:32:57 | 52 | eyJkIjoiMjAyNi0w... |
| 3 | 15:33:57 | 47 | eyJkIjoiMjAyNi0w... |
1回目のリクエストはcursorを指定していないため、その日の累積開示が一度に返却され、その時点までの「区切り」としてcursorが新規に発行されます。2回目以降は前回のcursorを引き継いでいるため、それ以降に新たに配信された開示のみが返却されます。
参考までに、取得できた新着開示の中身を、各リクエストの境界が見えるように抜粋して表示してみます。具体的には1回目の末尾2件、2回目の先頭2件と末尾2件、3回目の先頭2件をピックアップします。1回目の末尾と2回目の先頭がほぼ連続した時刻になっていれば、cursorが取りこぼしなく境界を辿れていることが確認できます。
def _pick_samples(items: list[dict], head_n: int, tail_n: int) -> list[dict]:
"""先頭 head_n 件と末尾 tail_n 件を抜き出し、間は省略行で埋める。"""
if len(items) <= head_n + tail_n:
return list(items)
omitted = len(items) - head_n - tail_n
ellipsis_row = {
"_poll": items[0]["_poll"],
"DiscTime": "—",
"Code": "—",
"Name": "—",
"Title": f"(中略 {omitted} 件)",
}
return items[:head_n] + [ellipsis_row] + items[-tail_n:]
# 1回目: 末尾2件 / 2回目: 先頭2件+末尾2件 / 3回目: 先頭2件
sample_rules = [(1, 0, 2), (2, 2, 2), (3, 2, 0)]
rows: list[dict] = []
for poll_num, head_n, tail_n in sample_rules:
items_in_poll = [it for it in all_new_items if it["_poll"] == poll_num]
if not items_in_poll:
continue
rows.extend(_pick_samples(items_in_poll, head_n, tail_n))
pd.DataFrame(rows)[["_poll", "DiscTime", "Code", "Name", "Title"]] if rows else "新着開示はありませんでした"
| _poll | DiscTime | Code | Name | Title |
|---|---|---|---|---|
| 1 | — | — | — | (中略293件) |
| 1 | 15:00 | 77900 | バルコス | 株式会社FNホールディングスとの株式譲渡完了のお知らせ |
| 1 | 15:11 | 81980 | MV東海 | コーポレート・ガバナンスに関する報告書2026/05/20 |
| 2 | 15:30 | 45790 | G-ラクオリア創薬 | 米Velovia Pharma, LLCによるオプション権行使に伴う一時金受領のお知らせ |
| 2 | 15:30 | 26530 | イオン九州 | 第28回新株予約権(株式報酬型ストックオプション)の発行に関するお知らせ |
| 2 | — | — | — | (中略48件) |
| 2 | 15:30 | 92520 | G-ラストワンマイル | ログミーFinance主催「個人投資家向けIRセミナー」アーカイブ動画公開のお知らせ |
| 2 | 15:30 | 49260 | シーボン | (訂正)「中期経営計画の策定に関するお知らせ」の一部訂正について |
| 3 | 15:30 | 421A0 | G-ムービン | 2026年12月期 第1四半期決算説明会書き起こし |
| 3 | 15:30 | 37530 | フライト | 2026年3月期 決算説明資料 |
| 3 | — | — | — | (以降省略 ) |
_poll列は何回目のリクエストで取得できたかを表しています。5/20日分については、15:30開示のものが15:30にすぐに取得できるわけではないですが、数分以内に取得できるようになっています。
イベントトリガー型の簡便な実装
新着開示が到着したタイミングをトリガーに、何らかの処理を走らせる「イベントトリガー型」のシンプル実装を示します。ここではトリガー時の処理として、全文情報PDFをローカルに保存しています。発注ロジック、通知・特定タイトルのアラートなど、用途に応じてon_new_disclosureの中身を差し替える想定です。
POLL_INTERVAL_SEC = 60 # 1分間隔。
out_dir = pathlib.Path("./downloads/latest")
out_dir.mkdir(parents=True, exist_ok=True)
def on_new_disclosure(item: dict) -> None:
"""新着開示1件に対するハンドラ。
トレード執行・通知などのトリガー処理をここに実装する。"""
disc_no = item["DiscNo"]
# 全文情報PDFのダウンロードURLを取得(docs=gで全文のみに絞る)
files_resp = requests.get(
f"{BASE_URL}/v2/td/files",
params={"discNo": disc_no, "docs": "g"},
headers=HEADERS,
)
pdf_url = files_resp.json()["files"]["pdf"]
# PDF本体を取得して保存
pdf_path = out_dir / f"{item['DiscDate']}_{disc_no}.pdf"
pdf_path.write_bytes(requests.get(pdf_url).content)
print(
f"[{item['DiscTime']}] {item['Code']} {item['Name']}: "
f"{item['Title']} → {pdf_path.name}"
)
today = date_cls.today().isoformat()
cursor = None
while True:
new_items, cursor = fetch_new_disclosures(today, cursor)
for item in new_items:
on_new_disclosure(item)
time.sleep(POLL_INTERVAL_SEC)
イベント検知の設計上の注意点
このパターンを運用する際は、以下のポイントに注意してください。
-
pagination_keyとcursorは同時指定できません。1回の呼び出しで全件取得し切れなかった場合はpagination_keyを使って即時に追加リクエストを行い、最終ページで返ってきたcursorを次回の差分起点として保持します。 - 日付をまたいだ場合は
cursorをリセットして、新しい日付で初回リクエストを行います。実運用ではtodayを毎ループで更新し、日付が切り替わったらcursor = Noneに戻す処理を入れておくと安全です。 - リクエストの間隔は1分程度以上空けることお勧めします。本アドオンは個別に、100リクエスト/分のレートリミットを設定していて、開示一覧の取得
/v2/td/listとファイル取得/v2/td/filesは同じ枠を消費します。開示一覧をリクエストしすぎて、肝心の開示されたPDFやxbrlがダウンロードできなくなることを防ぐように工夫が必要です。 - 開示は時間帯で集中します。一般的に、決算発表が集中する15:00や15:30前後、後場引け後に開示量がスパイクする傾向があり、それに伴い取得にも遅延が発生します。秒単位で開示を捕捉する、などの利用方法には適さないのでご了承ください。
おわりに
本記事では、TDnet-addonの3つのエンドポイント(list / files /bulk)の使い方と実用ユースケース2例を紹介しました。
適時開示データは、決算情報やM&A、自己株式取得などの企業のコーポレートアクションを網羅的にカバーしており、定量分析だけでなくイベントスタディや決算カレンダー連動のニュース監視など、応用の幅は広いです。次のステップとしては以下のような発展が考えられます。
- XBRLファイルをパースして決算短信から定量データを自動抽出する
- 公開項目コード(
DiscItems)と銘柄マスタを組み合わせて、特定種別の開示が出た銘柄群の株価リアクションを分析する - 全文PDFをテキスト化し、自然言語処理で分類・サマリする
J-Quants運営チームでは、引き続き利用者の声をもとにアドオンやCLIの機能拡充を進めてまいります。ご要望・ご意見はJ-Quantsのお問い合わせフォーム、または公式Discordまでお寄せください。
JPX総研について
JPX総研ではJ-Quantsなどの新しいプロダクトを内製開発しています。キャリア採用を通年で行っておりますので、ご興味がある方は以下のリンクをご覧ください!
J-Quantsとは
J-Quantsとは、ヒストリカル株価データ・財務データなどの金融データを取得できる、個人投資家向けのAPIデータ配信サービスです。投資にまつわるデータを分析しやすい形式で提供し、個人投資家の皆様がデータを活用しやすくなることを目的としております。
個人投資家が投資などのために金融データを分析する際の大きな障壁は、整形された金融データの取得が難しいことであるという理由から、2022年7月にベータ版をリリースいたしました。ご好評の声を頂いたこともあり、2023年4月より正式にリリースしております。
ディスクレーマー
当記事は、J-Quantsを利用した金融データ分析に関する技術的事項の共有を目的としたものであり、株式などの投資商品への投資の推奨を目的とするものではありません。
また、当記事の内容をもとに投資等を行った結果損害等が生じた場合においても、一切の責任を負わないものとします。