はじめに
②ベースラインモデルで作成したLightGBMより高い性能となるように特徴量作成、欠損補完を工夫するパートです。結果的に正解率は0.77751となったのでLightGBMのベースラインモデルよりは精度が上がりました。
%matplotlib inline
import lightgbm as lgb
from sklearn.model_selection import KFold, train_test_split
from sklearn.metrics import accuracy_score, log_loss
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold, GridSearchCV
from pprint import pprint
import matplotlib.pyplot as plt
import pandas_profiling
import seaborn as sns
import numpy as np
import pandas as pd
import itertools
# Data Load
train = pd.read_csv("/kaggle/input/titanic/train.csv")
test = pd.read_csv("/kaggle/input/titanic/test.csv")
pid = test["PassengerId"]
# 目的変数
y_train = train.pop("Survived")
# データセットの結合
dataset = pd.concat([train, test], axis=0)
del dataset["PassengerId"]
特徴量生成
与えられた特徴量から生存率に影響を与えそうな特徴量を新たに作成します。Nameに含まれる敬称は年齢、性別という重要な情報を含んでいそうなので新たにTitle列を作成します。
敬称(Title)
# 敬称列を全データセットに追加
titles = pd.Series(dtype="object")
for fullname in dataset["Name"]:
title = pd.Series(fullname.split(", ")[1].split(".")[0])
titles = titles.append(title)
titles.reset_index(inplace=True, drop=True)
dataset.insert(2,"Title",titles)
dataset.head()
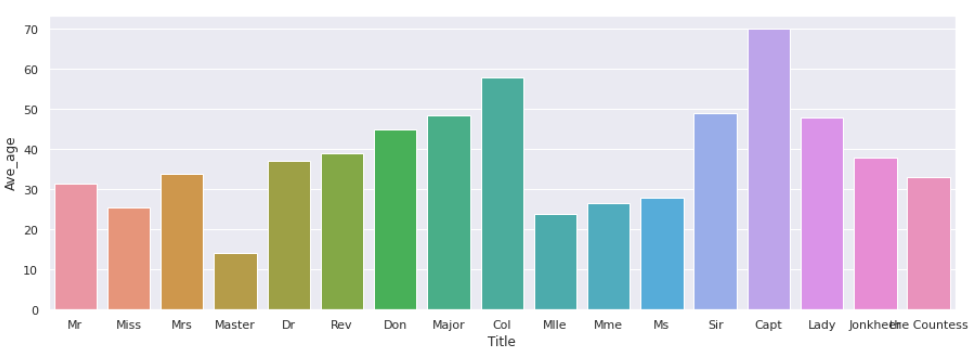
敬称ごとの平均年齢を確認します。キャプテンが子供であることは考えられないので、敬称から年齢を考える視点は妥当であることがわかりました。
def cal_age():
"""敬称ごとに人数、平均年齢、割合を算出
"""
t_num = pd.DataFrame(dataset.groupby('Title').count()["is_train"]).sort_values("is_train", ascending=False)
t_num["Ratio"] = (t_num["is_train"] / t_num["is_train"].sum()).round(2)
ave_age = pd.DataFrame(dataset.groupby('Title').mean()["Age"])
df = pd.concat([t_num, ave_age],axis=1)
df = df.rename(columns={'is_train':'Count', 'Age':'Ave_age'}).reset_index()
sns.set()
sns.set_context("notebook")
plt.figure(figsize=(15, 5))
sns.barplot(x="Title", y="Ave_age", data=df) # エラーバーは95%信頼区間
plt.show()
return df
cal_age()
家族(Family)
①データ分析より、Parch、SibSpは似たような傾向があるのでFamilyとしてまとめます。
new_feature = "Family"
# 新しい列の生成
dataset[new_feature] = dataset["Parch"] + dataset["SibSp"] + 1
①データ分析より、次の3つの特徴量は生存率に寄与してそうだと判断し、モデルに加えます。
年齢が欠損/推定値かどうか(IsAgeNanEst)
# 推測(年齢が〇〇.5)及び欠損値の人の生存率
feature = "Age"
new_feature = "IsAgeNanEst"
# 新しい列の生成
dataset[new_feature] = 0
# 欠損している人
dataset.loc[dataset["Age"].isnull()==True, new_feature] = 1
# 推定されている人
dataset.loc[dataset["Age"].isnull()==False, new_feature] = dataset[dataset["Age"].isnull()==False][feature].map(lambda x: 1 if x - int(x) > 0 else 0)
客室番号が欠損しているかどうか(IsCabinNan)
# Cabin
feature = "Cabin"
new_feature = "IsCabinNan"
# new_feature列の生成
dataset[new_feature] = 0
dataset.loc[dataset[feature].isnull()==True, new_feature] = 1
一人かどうか(IsAlone)
new_feature = "IsAlone"
# 新しい列の生成
dataset[new_feature] = 0
dataset.loc[dataset["Family"] == 1, new_feature] = 1
ラベルエンコーディング
le = LabelEncoder()
cat_cols = ["Sex", "Embarked", "Title"]
for c in cat_cols:
le.fit(dataset[c])
dataset[c] = le.transform(dataset[c])
欠損補完
欠損数が多く重要そうな年齢の欠損補完をします。欠損補完には、①平均値で補完、②グループごとの平均値で補完、③他の特徴量から予測などがあります。①、②、③の順で試しています。②は敬称ごとに平均値を求めて補完しました。Submitしてみて③の精度が最も良いことがわかったのでLightGBMで年齢を予測して補完するパターンを記載しています。
row_age = copy.deepcopy(dataset["Age"])
# 年齢推定で学習する用の特徴量
age_df = dataset[["Pclass", "Title", "Sex", "Age", "Family", "Fare", "Embarked"]]
# train:年齢が数値
X_train_age = age_df[age_df["Age"].isnull()==False].drop(["Age"], axis=1)
y_train_age = age_df[age_df["Age"].isnull()==False]["Age"].astype("int")
display(X_train_age)
# test:年齢がNan
X_test_age = age_df[age_df["Age"].isnull()==True].drop(["Age"], axis=1)
# 学習
model_age = lgb.LGBMRegressor(learning_rate=0.01,
n_estimators=100,
max_depth=5,
random_state=0)
model_age.fit(X_train_age, y_train_age)
# 予測
pred_age = model_age.predict(X_test_age)
# 予測値をデータセットに代入
dataset.loc[dataset["Age"].isnull()==True, "Age"] = pred_age
# 補完前後の年齢
two_age = pd.DataFrame({"row_age":row_age,
"fillna_age":dataset["Age"]})
two_age.plot(kind="hist",alpha=0.5)
年齢の予測に使う特徴量です。

オレンジが欠損補完後のヒストグラムです。20,30代が多く補完されていることがわかりました。

モデルに使用する特徴量は最初はすべての特徴量を入れて予測します。
次に、特徴量重要度が低い順に削除していき精度が改善しなくなるところで特徴量を決定します。
# 使用する特徴量を抽出
# dataset = dataset[["Pclass", "Sex", "Age", "Family", "Fare", "Embarked", "IsCabinNan", "IsAlone"]]
dataset = dataset[["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]]
# 訓練データ
X_train = dataset[:len(train)]
X_test = dataset[len(train):]
モデルの構築と予測
以下は、②ベースラインモデルと中身はほとんど同じなので読み飛ばしてください。
# パラメータの探索範囲
params_space = {
"max_depth":list(range(3,10)),
"min_child_weight":list(range(1,5))
}
# 探索するハイパラの組み合わせ
param_combinations = itertools.product(params_space["max_depth"], params_space["min_child_weight"])
# 各パラメータの組み合わせ、それに対するスコアを保存するリスト
params = []
acc_folds = []
logloss_folds = []
iter_folds = []
# 各パラメータごとにクロスバリデーションで評価
for param_id, (max_depth, min_child_weight) in enumerate(param_combinations):
# 各foldのスコアを保存
acc_fold = []
logloss_fold = []
iter_fold = []
# 学習データを訓練・検証に分割
kf = StratifiedKFold(n_splits=4, shuffle=True, random_state=0)
for fold_id, (tr_idx, val_idx) in enumerate(kf.split(X_train, y_train)):
X_tr, y_tr = X_train.iloc[tr_idx], y_train.iloc[tr_idx]
X_val, y_val = X_train.iloc[val_idx], y_train.iloc[val_idx]
# LightGBMで学習
model = lgb.LGBMClassifier(learning_rate=0.05,
n_estimators=10000,
max_depth=max_depth,
min_child_weight=min_child_weight,
random_state=0
)
model.fit(X_tr, y_tr,
eval_set=[(X_val, y_val)],
early_stopping_rounds=50,
verbose=None)
# 予測
pre_val = model.predict(X_val)
# 検証データのスコア
acc = accuracy_score(y_val, pre_val)
logloss = log_loss(y_val, pre_val) # accuracyでは小さな改善が捉えにくいのでloglossも利用
# 各foldのスコア保存
acc_fold.append(acc)
logloss_fold.append(logloss)
iter_fold.append(model.best_iteration_)
# パラメータの組み合わせを保存
params.append((max_depth, min_child_weight, int(np.mean(iter_fold))))
# 各パラメータの平均スコアを保存
acc_folds.append(np.mean(acc_fold)) # 参考用に出力
logloss_folds.append(np.mean(logloss_fold))
# 最もスコアが高いものをベストなパラメータとする
best_idx = np.argsort(logloss_folds)[0]
best_param = params[best_idx]
print(f"""
=======最適パラメータ======
max_depth:{best_param[0]}, min_child_weight:{best_param[1]}, best_iteration_:{best_param[2]}
""")
# n_estimatorsもアーリーストッピングで得られた一番良いパラメータを使用する
# 最適パラメータで学習
model = lgb.LGBMClassifier(learning_rate=0.05,
n_estimators=best_param[2],
max_depth=best_param[0],
min_child_weight=best_param[1],
random_state=0)
model.fit(X_train, y_train)
# 予測
pred = model.predict(X_test)
pred = pd.DataFrame({"PassengerId": pid, "Survived":pred})
pred.to_csv("lightgbm_predage.csv", index=False)
=======最適パラメータ======
max_depth:10, min_child_weight:4, best_iteration_:306
おわりに
正解率0.77751とベースラインモデルより精度を上げることができました。この段階でEmbarkedとFareの欠損補完をしても良いですが次に持ち越しとします。特徴量作成と欠損補完という一通りの処理は実装したので、次はLightGBM以外のモデルを使ってみようと思います。