はじめに
高度な機械学習モデルを構築していく前に、まずは目指すべきスコアの基準となるベースラインを設定します。ルールベースと機械学習モデルによって計3つ設定しました。
- ルールベース
- 全員を死亡と予測 ⇒正解率:0.622
- 男性は死亡、女性は生存と予測 ⇒正解率:0.76555
- 機械学習
- 既存特徴量のみで学習したLightGBMで予測 ⇒正解率:0.77033
1つのモデルでスコアを出したところで、それがどの程度優れているか判断することは難しいですが、ベースラインがあるとモデルの性能比較が容易になります。また、目標値が設定できるのでモチベーション維持にも繋がります。
kaggleからは話が逸れますが、複雑なモデルとシンプルなモデルに大差が無ければ、実務では解釈の容易性を考えてシンプルな方を採用することがあるのでベースラインモデルは作っておいた方がいいと思います。
全員を死亡と予測
学習データで多い方のラベル(死亡)で全員を予測します。今後この数値を超えないときは重大なミスがあると判断できます。sklearnにあるDummyClassifierを使います。説明変数は使わないので学習は行われません。学習データに含まれる目的変数の内容だけを使って結果を返します。
import os
import pandas as pd
from sklearn.dummy import DummyClassifier
# Data load
train = pd.read_csv('/kaggle/input/titanic/train.csv')
test = pd.read_csv('/kaggle/input/titanic/test.csv')
X_train = train['PassengerId']
X_test = test['PassengerId']
y_train = train['Survived'] # train['Survived']だけあれば予測可能なので説明変数はダミー
# most_frequent:学習データで最も頻度の高いラベルを常に予測
dummy = DummyClassifier(strategy='most_frequent', random_state=1234)
dummy.fit(X_train, y_train)
# 予測結果の出力
y_pred = dummy.predict(X_test)
y_pred = pd.DataFrame({'PassengerId': X_test, 'Survived': y_pred})
y_pred.to_csv('submission.csv', index=False)
正解率は0.622でした。つまり、学習データでは死亡:62%, 生存:38%ということがわかりました。
男性は死亡、女性は生存と予測
①データ分析より、性別が判明すれば高い確率で生存/死亡を的中させることができそうです。
テストデータでも性別ごとに同じラベルで予測することにします。
import os
import numpy as np
import pandas as pd
# Data Load
train = pd.read_csv("/kaggle/input/titanic/train.csv")
test = pd.read_csv("/kaggle/input/titanic/test.csv")
pid = test["PassengerId"]
# 男性:死亡、女性:生存と予測
test.loc[test["Sex"]=="male", "Survived"] = 0
test.loc[test["Sex"]=="female", "Survived"] = 1
test["Survived"] = test["Survived"].astype(int)
# 予測結果の出力
pred = test["Survived"]
pred = pd.DataFrame({"PassengerId": pid, "Survived":pred})
pred.to_csv("submission_baseline2.csv", index=False)
正解率は0.76555でした。
LeaderBoardで他人の結果を見てみると、このやり方でもまずまずの精度であることが分かります。
既存特徴量のみで学習したLightGBMで予測
既存特徴量のみで学習したLightGBMで予測します。LightGBMは欠損補完、特徴量のスケーリングなど手間のかかる前処理を必要としないにもかかわらず精度が出やすいためまずはこちらを使うことにします。扱いが難しそうなName, Ticket, Cabinはベースラインモデルの段階では削除します。
%matplotlib inline
import lightgbm as lgb
from sklearn.model_selection import KFold, train_test_split
from sklearn.metrics import accuracy_score, log_loss
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold, GridSearchCV
from pprint import pprint
import matplotlib.pyplot as plt
import lightgbm as lgb
import pandas_profiling
import seaborn as sns
import numpy as np
import pandas as pd
import itertools
import copy
import os
train = pd.read_csv("/kaggle/input/titanic/train.csv")
label = train.pop("Survived")
test = pd.read_csv("/kaggle/input/titanic/test.csv")
pid = test["PassengerId"]
# データセットの結合
dataset = pd.concat([train, test], axis=0)
del dataset["PassengerId"]
dataset.head()
# ラベルエンコーディング
le = LabelEncoder()
cat_cols = ["Sex", "Embarked"]
for c in cat_cols:
le.fit(dataset[c])
dataset[c] = le.transform(dataset[c])
# 使用しない特徴量を削除
dataset = dataset.drop(["Name","Ticket","Cabin"], axis=1)
dataset.head()
学習用の特徴量が出そろいました。
特徴量がかなり少ないのでルールベースより精度が出るか心配になりました。

モデル定義
LightGBMはTraining APIとScikit-learn APIの書き方があります。最初はそこに気が付かなかったので戸惑いました。書き方に馴染みのあるScikit-learn APIで書くことにします。
def LightGBM(nes, md, mcw):
"""LightGBMのインスタンス生成
"""
return lgb.LGBMClassifier(learning_rate=0.01,
n_estimators=nes,
max_depth=md,
min_child_weight=mcw,
importance_type="gain",
random_state=0)
ハイパーパラメータチューニング
どの機械学習モデルにおいてもハイパーパラメータチューニングすることになるのでベースラインモデルの段階で実装します。クロスバリデーション(CV)を用いたグリッドサーチでチューニングします。
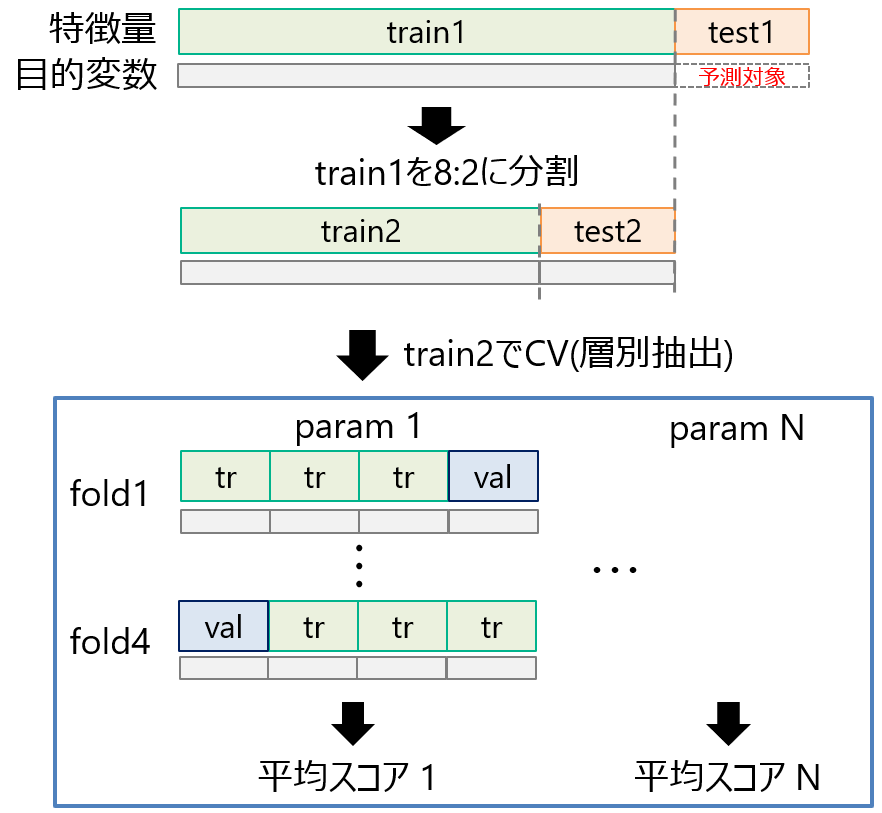
スクリプトの変数名と画像内の名前は一致してないことご了承ください。まずtrain1を8:2に分割してtrain2, test2を作ります。Titanicは全データ数が1200件くらいと少なく、学習不足に陥る可能性があるためtrain2は8割確保しました。
test = dataset[len(train):]
# 訓練データをtrain,testに分割
train = dataset[:len(train)]
X_train, X_test, y_train, y_test = train_test_split(train, label, test_size=0.2, random_state=0, shuffle=True)
train2で4分割交差検証を行う時にtr, valの目的変数は等しい割合になるように分割し、valで安定した評価ができるようにします。valでの評価後に平均スコア1~平均スコアNを算出します。
自身の理解のためにsklearnのGridSearchCV()は使わずにスクラッチで実装しました。
# パラメータの探索範囲
params_space = {
"max_depth":list(range(7,12)),
"min_child_weight":list(range(3,7))
}
# 探索するハイパラの組み合わせ
param_combinations = itertools.product(params_space["max_depth"], params_space["min_child_weight"])
# 各パラメータの組み合わせ、それに対するスコアを保存するリスト
params = []
acc_folds = []
logloss_folds = []
iter_folds = []
print("train,valでの目的変数の割合を確認".center(40,"="))
# 各パラメータごとにクロスバリデーションで評価
for param_id, (max_depth, min_child_weight) in enumerate(param_combinations):
# 各foldのスコアを保存
acc_fold = []
logloss_fold = []
iter_fold = []
# 学習データを訓練・検証に分割
kf = StratifiedKFold(n_splits=4, shuffle=True, random_state=0)
for fold_id, (tr_idx, val_idx) in enumerate(kf.split(X_train, y_train)):
X_tr, y_tr = X_train.iloc[tr_idx], y_train.iloc[tr_idx]
X_val, y_val = X_train.iloc[val_idx], y_train.iloc[val_idx]
# 学習
model = LightGBM(nes=10000, md=max_depth, mcw=min_child_weight)
model.fit(X_tr, y_tr,
eval_set=[(X_val, y_val),(X_tr, y_tr)],
early_stopping_rounds=50,
verbose=None)
# データの分布確認
if param_id == 0:
print(f"fold_id={fold_id} => train:{sum(y_tr)/len(y_tr):.3f} val:{sum(y_val)/len(y_val):.3f}")
# 学習曲線の描画
if fold_id == 0:
lgb.plot_metric(model,
title=f"fold_id={fold_id}:Metric during training\n(max_depth={max_depth}, min_child_weight={min_child_weight}, best_iter={model.best_iteration_})")
# 予測
pre_val = model.predict(X_val)
# 検証データのスコア
acc = accuracy_score(y_val, pre_val)
logloss = log_loss(y_val, pre_val) # accuracyでは小さな改善が捉えにくいのでloglossも利用
# 各foldのスコア保存
acc_fold.append(acc)
logloss_fold.append(logloss)
iter_fold.append(model.best_iteration_)
# パラメータの組み合わせを保存
params.append((max_depth, min_child_weight, int(np.mean(iter_fold))))
# 各パラメータの平均スコアを保存
acc_folds.append(np.mean(acc_fold)) # 参考用に出力
logloss_folds.append(np.mean(logloss_fold))
学習データ、検証データで目的変数の割合が一致していることを確認します。
=========train,valでの目的変数の割合を確認==========
fold_id=0 => train:0.384 val:0.382
fold_id=1 => train:0.384 val:0.382
fold_id=2 => train:0.384 val:0.382
fold_id=3 => train:0.382 val:0.388
学習曲線を描画して、valid_0の改善が落ち着いてきたところで学習が打ち切られていることを確認します。

次に、平均スコアが最大となる時のパラメーターセットを選択します。
print("""
=========各パラメータと精度=========
(maxd,mwei,ave_iter) ave_acc, ave_logloss""")
for param, acc, logloss in zip(params, acc_folds, logloss_folds):
print(f"{param}, {acc:.4f}, {logloss:.4f}")
# 最もスコアが高いものをベストなパラメータとする
best_idx = np.argsort(logloss_folds)[0]
best_param = params[best_idx]
print(f"""
=======最適パラメータ======
max_depth:{best_param[0]}, min_child_weight:{best_param[1]}, best_iteration_:{best_param[2]}
""")
=========各パラメータと精度=========
(maxd,mwei,ave_iter) ave_acc, ave_logloss
(7, 3, 267), 0.8272, 5.9667
(7, 4, 274), 0.8258, 6.0152
(7, 5, 268), 0.8174, 6.3063
(7, 6, 296), 0.8174, 6.3063
(8, 3, 289), 0.8315, 5.8212
(8, 4, 263), 0.8244, 6.0637
(8, 5, 270), 0.8188, 6.2578
(8, 6, 303), 0.8146, 6.4033
(9, 3, 288), 0.8258, 6.0152
(9, 4, 267), 0.8287, 5.9182
(9, 5, 277), 0.8230, 6.1122
(9, 6, 301), 0.8160, 6.3548
(10, 3, 278), 0.8329, 5.7727
(10, 4, 265), 0.8244, 6.0637
(10, 5, 276), 0.8216, 6.1608
(10, 6, 301), 0.8160, 6.3548
(11, 3, 305), 0.8315, 5.8212
(11, 4, 266), 0.8258, 6.0152
(11, 5, 276), 0.8216, 6.1608
(11, 6, 301), 0.8160, 6.3548
=======最適パラメータ======
max_depth:10, min_child_weight:3, best_iteration_:278
最適パラメータは(max_depth, min_child_weight, best_iteration_) = (10, 3, 278)でした。
最適パラメータと特徴量が揃ったのでベースラインモデルとしての機能は果たせる状態ですが、今後を見据えて汎化性能の評価もしておきます。
汎化性能評価
kaggleではSubmit回数に上限があるので学習に使用していないデータで汎化性能を評価し、いまいちな精度の時はSubmitせずにモデルを再構築する手順がこの先必要になります。valの結果がベストになる時のパラメータを使って、valを評価しているのでパラメータチューニングにも使用していないtest2で評価する必要があります。そこで、最適パラメータを使用して分割前であるtrain2で学習後、test2を評価します。
# n_estimatorsもアーリーストッピングで得られた一番良いパラメータを使用する
# 最適パラメータで学習
model = LightGBM(nes=best_param[2], md=best_param[0], mcw=best_param[1])
model.fit(X_train, y_train)
モデルの詳細が出力されました。
LGBMClassifier(importance_type='gain', learning_rate=0.01, max_depth=10,
min_child_weight=3, n_estimators=278, random_state=0)
test2のスコアを出力します。
# 予測
pre = model.predict(X_test)
# 検証データのスコア
acc = accuracy_score(y_test, pre)
logloss = log_loss(y_test, pre)
print(f"""========y_testを予測==========
accuracy={acc:.3f}
""")
========y_testを予測==========
accuracy=0.838
0.838と比較的高い結果になったのでこのモデルでSubmitしても良さそうと判断できます。train1を再度学習してtest1を予測します。
# 学習
model = LightGBM(nes=best_param[2], md=best_param[0], mcw=best_param[1])
model.fit(train, label)
# 予測
pre = model.predict(test)
pre = pd.DataFrame({"PassengerId": pid, "Survived":pre})
pre.to_csv("lightgbm_baseline.csv", index=False)
おわりに
ベースラインモデルを作成し目標値を設定しました。次はこれらの目標値を超えるようにモデルをレベルアップしていきます。その一つに特徴量を作成/抜き差しして精度を高める方法があります。なので、今の段階でどの特徴量が精度向上に寄与しているかを確認しておきます。
# 特徴量重要度の確認
fi = model.feature_importances_
fi = pd.DataFrame(fi,
index=dataset.columns,
columns=["importance"])
fi = fi.sort_values("importance", ascending=True)
fi.plot.barh()
 Parchが低いので次回からは削除することにします。
Parchが低いので次回からは削除することにします。
ベースラインモデルの段階では汎化性能が低くてもそのまま予測に使うので、train1を4分割してパラメータチューニングしてもよかったかなと思いました。