ある日の真夜中。ぼんやりとQiitaを眺めていたらこんな記事に遭遇した。
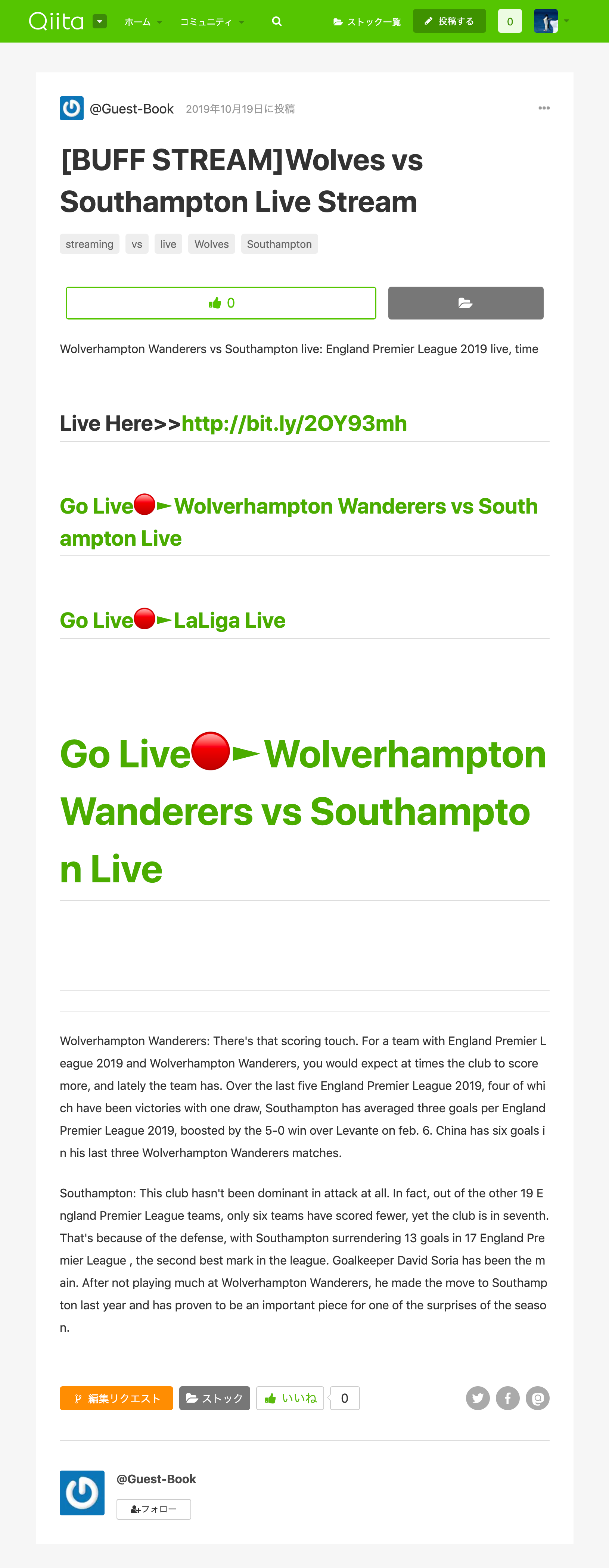
知っている人は知っていると思うが、Qiitaではたびたび大量のスパム記事が投稿されている。
深夜24~26時頃に記事一覧を確認してみて欲しい。
スパム記事がわんさか出てくるはず。
登録したてのQiitaユーザは不安よな。1
———— @dcm_chida 動きます🧐
はじめに
これはNTTドコモサービスイノベーション部AdventCalendar2019の1日目の記事です。
我々の部署では日頃から「KDDCUP2」や「論文読み会」に取り組んでおり、若手から中堅社員まで最先端の技術取得に励んでいます。
そうした活動をもっと外部へと発信していこうと始めたのがこのAdventCalendarです。社員一人一人が書いた記事を通して、少しでも多くの方に興味を持って頂ければ幸いです。
さて、僕は4年目社員ですがプログラミング初心者の頃から現在に至るまで、Qiitaにはかなりお世話になりました。
自分自身を育ててくれたQiitaへの限りなく大きな恩
自分なりに少しでも返そうと思い立ったのが
一日一回感謝のスパム狩り
本記事はQiitaのスパム記事を頑張って駆逐しようとして、最終的にAutoMLに仕事を奪われた話です。
今年自分が取得したスキル(BERTやLightGBMなど)を武器にアレコレ検証していこうと思います。
ざっくり言うと
- Qiitaに夜な夜な現れるスパム記事を駆逐してやりたい
- Qiita投稿記事の監視基盤をサーバレスサービスで作成した
- 機械学習でスパム記事検知をしてみた
対象とする人
- 実践から機械学習を学んでみたい
- データ分析、サーバレス、セキュリティに興味がある
- 溢れんばかりのQiita愛がある
やること
- Qiita投稿記事監視用ダッシュボードを作る
- 【使う技術】AWS Athena/ QuickSight

- BERTで記事タイトルをエンコード&可視化する
- 【使う技術】AWS SageMaker/ BERT

- 機械学習でスパム記事を検知してみる
- 【使う技術】LightGBM/ GCP AutoML Tables

作戦1:Qiita投稿記事監視プラットフォームの作成
アーキテクチャ概要

各コンポーネントは全てAWSのサーバレスサービスで構築されている。
- LambdaでQiitaAPIを叩いてデータ収集→S3へ格納(1時間に1回)
- Lambdaで集約、整形→S3へ格納(1日に1回)
- Athenaでテーブル化
- QuickSightで可視化
1ヶ月ほど使っているが、利用料金はなんと**$1前後**!これがサーバレスの凄さである!無料枠を超えると$10以上になる可能性はあるが、それでも比較的安価だ。
以下、それぞれのコンポーネントについてポイントをまとめていく。
生データ収集用Lambda
Qiita API v2を利用してQiitaへの投稿記事収集用Lambda関数を作成する。
Qiita APIの使い方については下記の記事を参照。
Qiitaの投稿記事からデータセット作った - Qiita
これをそのままLambda関数で実装すればよいのだが、pandasとrequestsモジュールはLambdaでそのまま動作しない。そのため今回はLambda Layersという機能を利用している。これコードの修正がしやすくてすごく便利。
その他細かい注意点は下記の通り
- QiitaAPIはUTC(世界標準時)を基準にしているが、取得されるデータのタイムスタンプはJST(日本時間)
- 記事タイトルに改行やタブが含まれている可能性がある
- S3へ保存するためのLambda関数のIAMロールを設定しておく
Lambda関数のコードはこちら
import json
import boto3
import time
import math
import requests
import datetime
import pandas as pd
# param
url = 'https://qiita.com/api/v2/items'
token = '<自分のトークンを入れる>'
bucket_name = "<保存先のS3バケット名>"
headers = {
'content-type': 'application/json',
'charset': 'utf-8',
'Authorization': 'Bearer {0}'.format(token)
}
label_list = [
'created_at',
'updated_at',
'id',
'title',
'user',
'likes_count',
'comments_count',
'page_views_count',
'url',
'tags',
#'rendered_body'
]
def get_request(url, params, headers):
"""
GETメソッドでリクエストを投げる
"""
r = requests.get(url, params=params, headers=headers)
return r
def print_response(r, title=''):
"""
レスポンスを整形して表示する
"""
c = r.status_code
h = r.headers
print('{0} Response={1}, Detail={2}'.format(title, c, h))
def extract_item(item, label_list):
"""
JSONデータから必要な情報を抽出してリストを返す
"""
l = []
for label in label_list:
if(type(item[label]) is str):
l.append(''.join(item[label].split()))
else:
l.append(item[label])
return l
def generate_daily_query(n_prev):
"""
直前n分のデータを抽出するクエリを生成する
"""
# 日本時間での現在時刻を取得
dt_jst = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9)))
dt_now = datetime.datetime.now()
dt_prev = dt_now - datetime.timedelta(minutes=n_prev)
dt_prev_jst = dt_jst - datetime.timedelta(minutes=n_prev)
query = 'created:>={0}-{1}-{2}'.format(dt_prev.year, dt_prev.month, dt_prev.day)
return query, dt_prev, dt_prev_jst
def calc_pages(query):
"""
クエリで出力される総記事数、総ページ数を算出
"""
params = {
'page': 1,
'per_page': 100,
'query': query
}
r = get_request(url, params, headers)
print_response(r)
total_articles = int(r.headers['Total-Count'])
total_pages = int(math.ceil(total_articles / float(params['per_page'])))
return total_articles, total_pages
def stack_series(items):
"""
リストのままtsvに変換するとタイトルに\tが含まれているときに表示が崩れるため
抽出したリストをSeriesに変換してからdataframeにスタックする
"""
tmp = pd.DataFrame(index=[], columns=label_list)
for i, item in enumerate(items):
l = extract_item(item, label_list)
s = pd.Series(l, index=label_list)
tmp = tmp.append(s, ignore_index=True)
return tmp
def lambda_handler(event, context):
# 取得する総記事数と必要なページ数を算出
query, date, jst_date = generate_daily_query(10)
total_articles, total_pages = calc_pages(query)
print(query, total_articles, total_pages)
# データ集約用の空のPandasデータフレームを作成
df = pd.DataFrame(index=[], columns=label_list)
subdf = pd.DataFrame(index=[], columns=label_list)
# ページングしながらリクエストを投げる
for page in range(1, total_pages + 1):
params = {
'page': page,
'per_page': 100,
'query': query
}
r = get_request(url, params, headers)
items = r.json()
print('{0} page/{1} \t {2} entries.'.format(page, total_pages, len(items)))
subdf = stack_series(items)
time.sleep(5)
df = pd.concat([df, subdf])
fname = '{:04}{:02}{:02}{:02}_qiita_data.tsv'.format(jst_date.year, jst_date.month, jst_date.day, jst_date.hour)
df.to_csv('/tmp/'+fname, index=False, sep='\t')
#df.to_pickle('./qiita_data.zip')
s3 = boto3.resource('s3')
#s3.Bucket(bucket_name).upload_file('/tmp/'+fname, str(date.year)+'/'+str(date.month)+'/'+fname)
s3.Bucket(bucket_name).upload_file('/tmp/'+fname, 'qiita_rawdata/dt='+str(jst_date.year)+'-'+str(jst_date.month)+'-'+str(jst_date.day)+'/'+fname)
print('Completed!!')
return {
'statusCode': 200,
'body': json.dumps(bucket_name)
}
データ集約・整形用Lambda
データ集約と整形は前述のLambda上で同時に実行できるが、今回は疎結合を意識してLambda関数を別に用意した。
※集約と整形は後からでも出来るが、生データの収集はその瞬間じゃないと出来ないため
- データ集約
- 生データ用のフォルダ(
qiita_rawdata)に格納された1時間毎のファイルを1日分のファイルにマージする- 加工済みデータ用のフォルダ(
qiita_data)に格納する
- 加工済みデータ用のフォルダ(
- 生データ用のフォルダ(
- データ整形
- 「ユーザ」のデータはarray形式で格納されるのでユーザID、フォロワー数、フォロー数を別カラムとして抽出する
- 「タグ」もarray形式で取得されるため、それぞれ別のカラムとして抽出する
- 「ユーザ」のデータはarray形式で格納されるのでユーザID、フォロワー数、フォロー数を別カラムとして抽出する
また、Athenaのパーティション3設定もこのLambda関数で行っている。
パーティションの設定は下記のように行う。
※Lambda関数自体にAthenaやS3のIAMロールがついていないとエラーになるので注意
def run_query(query, database, s3_output):
"""Execute athena query for creating the partition."""
try:
print("######### query ###########")
print(query)
print(database)
print(s3_output)
query_response = boto3.client('athena').start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': database
},
ResultConfiguration={
'OutputLocation': s3_output,
}
)
print(query_response)
except ClientError as e:
print(e.response['Error']['Message'])
return "FAILED", e.response['Error']['Message']
else:
return "SUCCESS", query_response
s3_output = "<athenaクエリの出力先S3バケット>"
database = "<athenaのデータベース名>"
# repair athena table partition
query = "MSCK REPAIR TABLE {};".format(tablename)
response = run_query(query, database, s3_output)
データ保存用のS3バケット
S3の内部の構成はこの通り
(bucket)
├ qiita_rawdata/
│ ├ 2019/
│ │ ├ dt=2019-10-19/
│ │ │ ├ 2019101900_qiita_data.tsv
│ │ │ ├ 2019101901_qiita_data.tsv
│ │ │ ├ …
│ │ │ └ 2019101923_qiita_data.tsv
│ │ ├ dt=2019-10-20/
│ │ ├ …
│ │
│ └ 2020/
└ qiita_data/
├ 2019/
│ ├ dt=2019-10-19/
│ │ └ 20191019_qiita_data.tsv
│ ├ dt=2019-10-20/
│ │ └ 20191020_qiita_data.tsv
│ ├ …
│
└ 2020/
ポイントは下記の二点
- 生データ用のフォルダと整形後のデータ用のフォルダを別に用意する
- Athenaからクエリを投げるため、Hiveパーティション形式でフォルダに格納する
分析用のAthenaテーブル
Amazon AthenaはS3のデータに対してクエリを実行できるサーバレスサービスである。
S3にきちんと整形されたデータが格納されてLambda関数がきちんとAthenaのテーブル作成を行っていれば、コンソール画面からそのままクエリを投げることができる。
AthenaとRedShiftとElasticSearch何が違うんじゃい!とよく言われるが、Athenaは運用が楽で料金が比較的安いというのがポイント。
Athenaで色々クエリを実行すれば
- 1日の投稿記事数
- Pythonをtagに含む記事
- Organizationが〇〇の投稿記事
など自由に絞り込むことが可能である。
ただし、Athenaのコンソールでクエリを投げるよりも、後述のQuickSightからGUIで色々絞り込んだ方が直感的でわかりやすい。

QuickSightダッシュボード
Amazon QuickSightはAthenaのテーブルやDynamoDBなどのデータを可視化するマネージドサービスである。
RedashやApache SupersetなどのOSSを使ってもいいが、コストと手間を考えるとQuickSightの方がお手軽でオススメ。
Athenaのテーブルをデータセットとして登録すれば、QuickSight経由でクエリを実行できるようになる。
例えば「むむむ!こいつ…さてはスパムだな!」と思ったとしよう。
QuickSightならポチポチとクリックするだけでユーザ名や時間で絞り込むことができる。結果のcsv出力やメールでレポート送信なども可能だ。
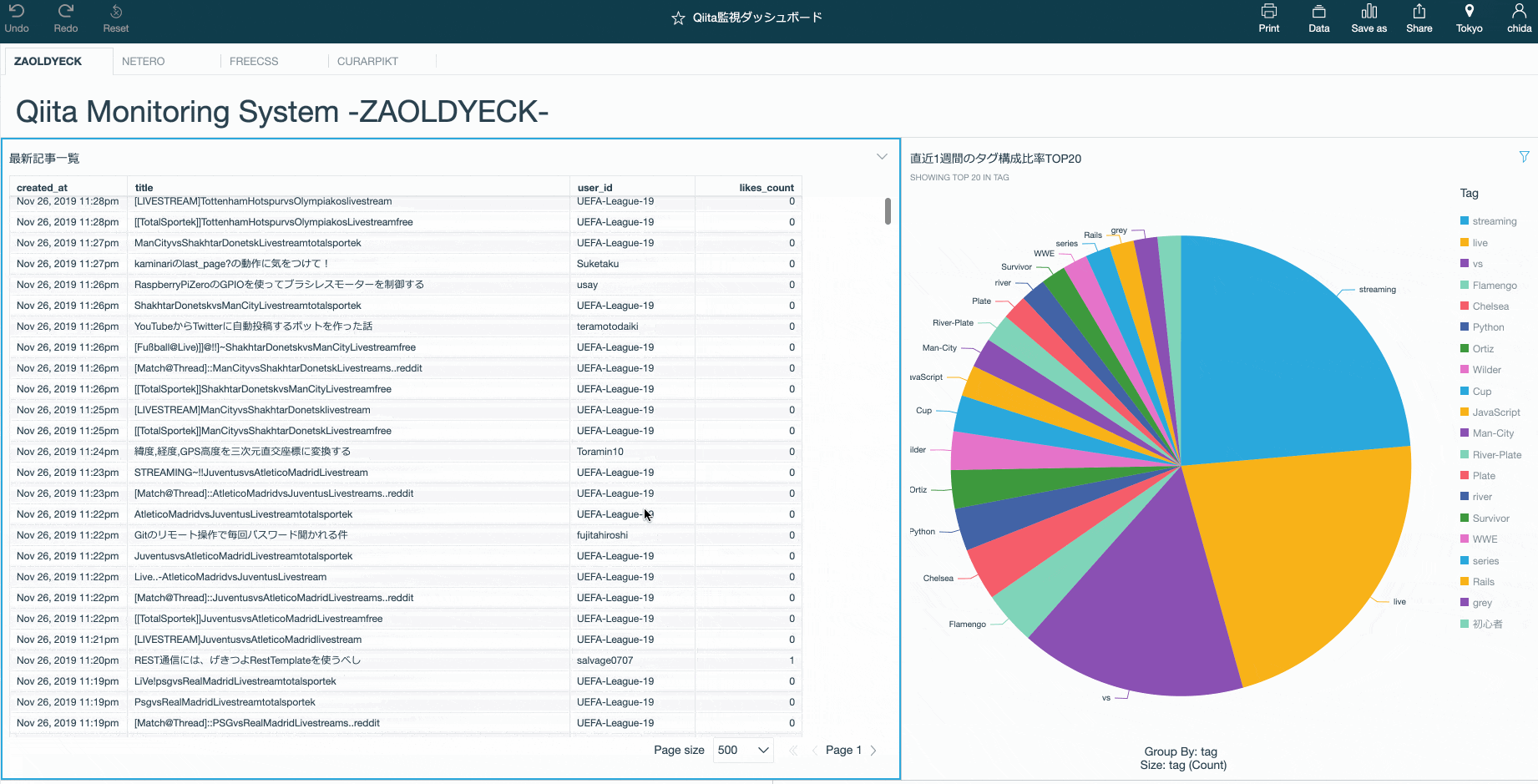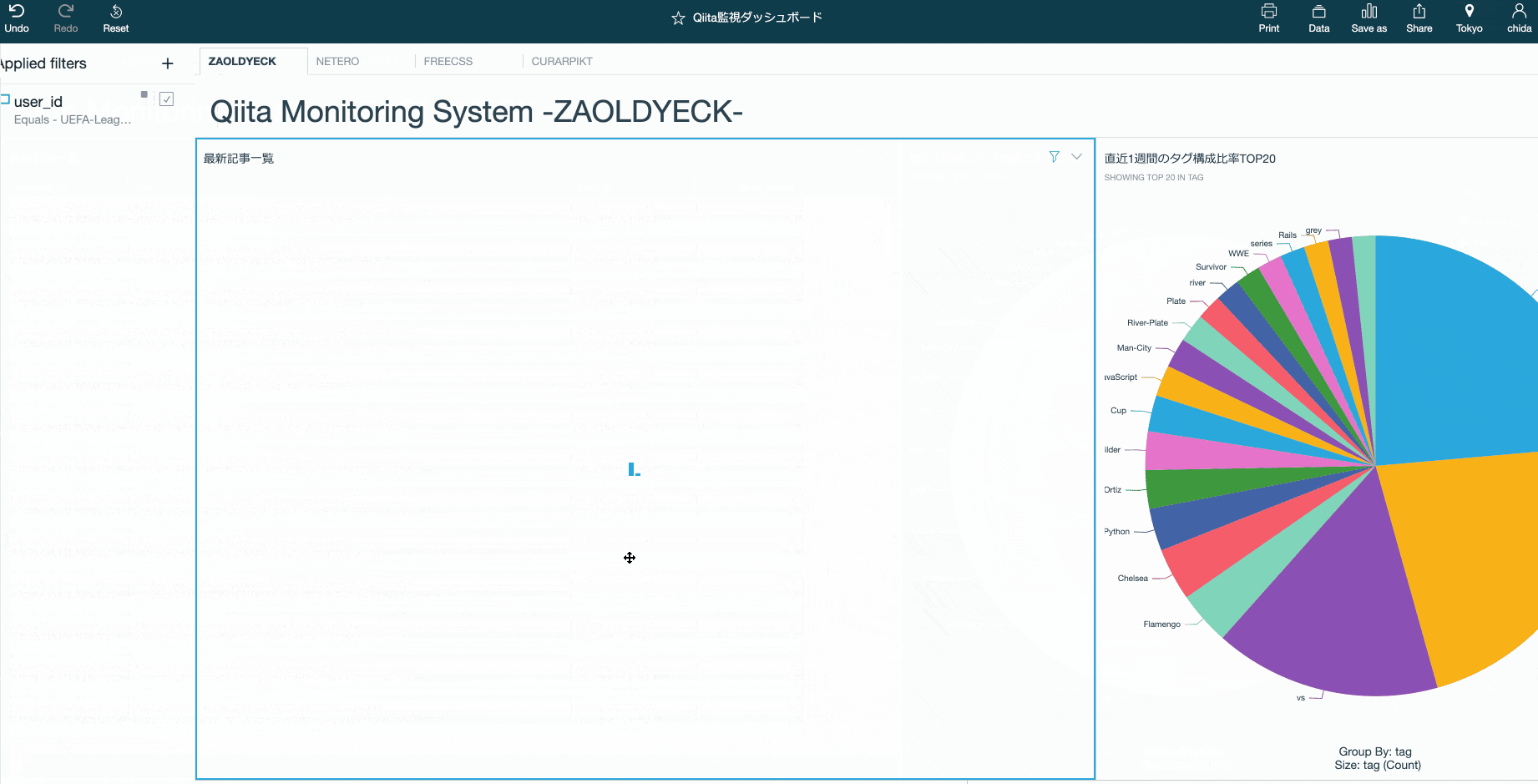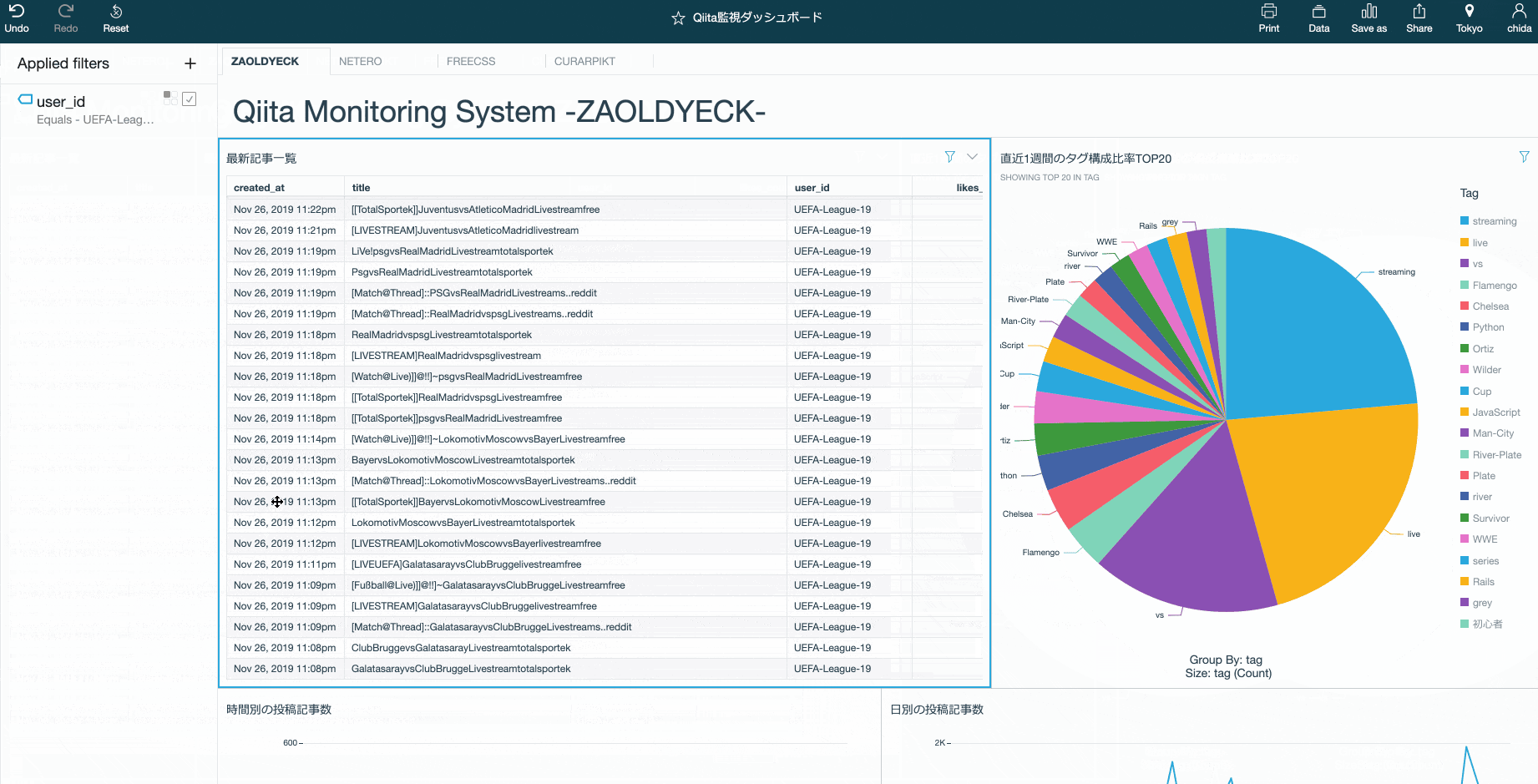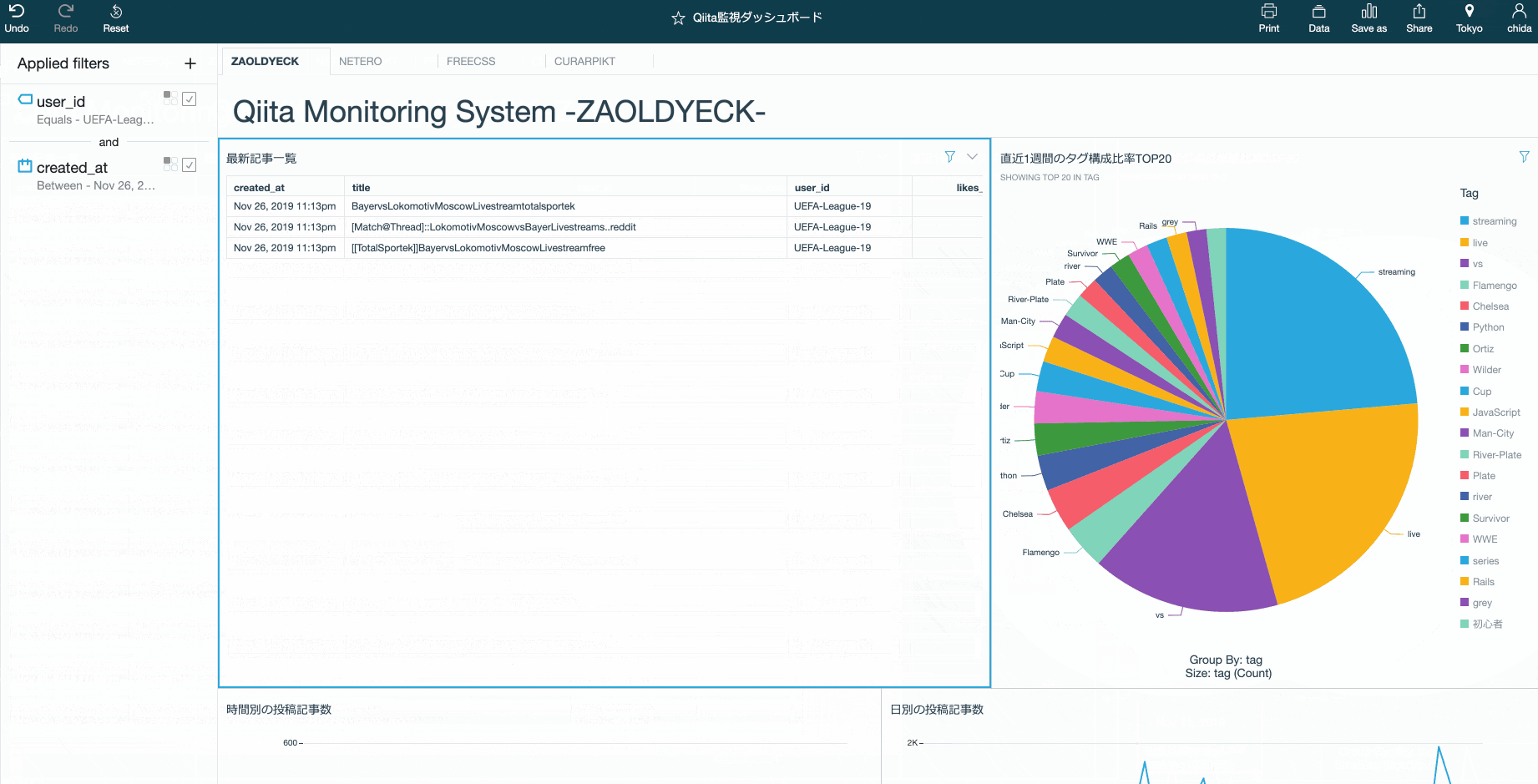
スパムだけじゃなくて、普通にいろんな記事を眺めるのもおもしろい。
作戦会議
さて、Qiitaに投稿される記事の監視基盤は出来た。
次にスパム記事をどう検出するかを考える必要がある。
まずはスパム記事のデータをじっくり観察してみよう。
こういう作業を探索的データ解析(EDA:Exploratory data analysis)と呼ぶ。
どのくらいのスパムが投稿されている? 【How many?】
毎日大量のスパムが投稿されているが、ありがたいことにボランティアやQiita運営の尽力によってしっかり除去されている。
おや…🤨?
ということは、「リアルタイムに取得した生データ(raw_data)」と「数日後に取得したデータ(clean_data)」の差分を取ることで、どの記事がスパムだったかを大まか4に知ることができるのでは!?
実際に2019/11/01-2019/11/15の期間で差分を取ることでスパム(Spam)か正常(Natural)かのラベルづけをすることができた。
それぞれの1日の平均投稿数を時間毎に集計したものがこちら↓

たしかにスパム記事の投稿は深夜帯に集中している。**一時間に50件以上のスパム記事が投稿されている。**とくに早朝3~4時くらいが凄まじい。欧州のサッカーの放送がこのくらいの時間だからか?
ついでにQiitaの正規ユーザーの投稿が多いのは夕方17時ごろと深夜23~24時だった。日報/日記的に投稿している人が多いのだろうか?
日中も意外と投稿している人多いんだなぁ…
スパム流行語大賞2019【What?】
スパム記事記事の内容はどんなものが多いのだろうか?
以前Qiitaのタイトルの固有名詞を抽出していろいろ遊んだことがある5が、これをスパム記事だけでやってみた。
通常であれば英語はスペース区切りなので単語分割は不要だが、スパム記事はスペースが潰されているので区切りがわからない。
※例えばこんなの「Live•Tv^TsitsipasvsThiemlivestream」
ここではWordNinjaというマニアックな単語分割ツールを使って単語を集計している。
集計期間は15日間(2019/11/01-2019/11/15)とやや短めだが、数千件のスパム記事から集計できた。
import pandas as pd
import wordninja
l = []
# キャプチャした生データ
df_raw = pd.read_csv('./20191101_1115_rawdata.csv', sep="\t")
# 数日後に再取得したデータ
df_clean = pd.read_csv("./20191101-1115_cleandata.csv", sep="\t")
# cleanと一致しないもの = スパム
df_spam = df_raw[~df_raw["id"].isin(df_clean["id"])]
# スペースなしの英文字列を分割
for title in df_spam["title"]:
l.extend(wordninja.split(title.lower())) #小文字にすること!
s = pd.Series(l).value_counts()
# 上位20単語を表示
s[:20].plot(kind='bar', fontsize=20, figsize=(18,9))

live, vs, streamなどが圧倒的に多い。
そのほか欧州のサッカーチームが多いが、これはUEFAチャンピオンズリーグ予選日程(11/6-11/7)と被ったためである。おそらくラグビーW杯の時期で集計すればEngland、NZなどが上位に来たはずだ。
ちなみにスポーツ別で集計するとこのとおり。やはりサッカーが人気のようだ。日本語の記事も含めるともっと多くなるだろう。その後のスパム観測の結果、フィギュアスケートやプロレス、アメフトなどの存在も確認している。
来年は東京五輪2020もあるしスパム記事も多様化しそうだ。
| 種目 | 投稿数(2019/11/01-2019/11/15) |
|---|---|
| soccer | 99 |
| football | 52 |
| boxing | 50 |
| rugby | 35 |
| tennis | 26 |
| baseball | NaN |
| golf | NaN |
| ping-pong | NaN |
| bascketball | NaN |
| valleyball | NaN |
スパムが投稿される時間帯【When?】
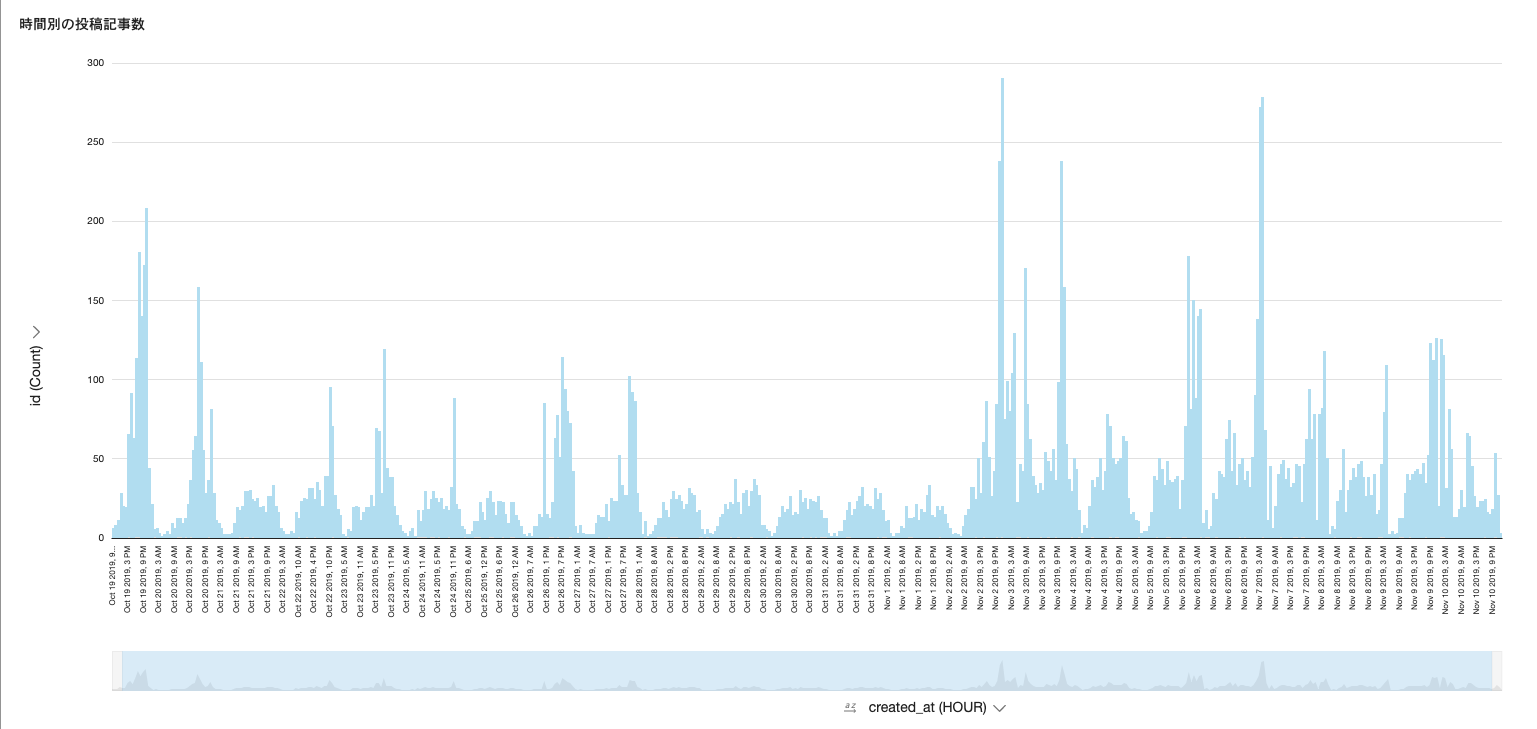
下のグラフは時間別の記事投稿数を表しているが、ところどころスパイクが発生しているのがわかる。
一時間に数百件の記事が投稿されるなんて普通ではありえないため、ここでスパム記事が大量に投稿されていると考えられる。何となくDoS攻撃っぽい。
スパム記事はスポーツの試合の時間に合わせて発生しているため時間の目星がつけられそうだが、結論から言うと周期性はあまりない。
サッカーのリーグ戦などは時間が固定されているから簡単だと思うかもしれないが、Jリーグからプレミアまでスパム化される。時系列予測などはかなり難しいだろう。
スパムを投稿しているユーザ【Who?】
こんな大量のスパムを毎晩投稿するなんて…一体誰がやっているの?こわい!と思うだろう。
11/1-11/15の総記事投稿数をユーザでグルーピングした結果がこちら。
上位100ユーザをプロットしてある。

1ユーザあたりおよそ40~100くらいのスパム記事を投稿している。
また、ユーザ名は記事のタイトルと似ている?ような気がする。機械的に生成された文字列なのか?
そういえば最近怪しげなユーザ6からフォローされた記憶もある。
どこから来てどこへ行く?【Where?】
タイトルを眺めると英語だけでなく日本語のスパム記事も存在する。これは明らかに日本人をターゲットにしていると言っていいだろう。他にもアラビア語やハングル文字の記事も存在するので、アジアを中心に世界中の人たちを狙っていると推測される。
こんな怪しげなリンクを踏む人などいないと思うが、一応リンク先がどうなっているのかを調べてみた。
以下はリンク先のスクショである。

どうやらラスベガスのサーバ上のページに繋がるようだ。SkySportsというのは実在するサイトだが、これはフィッシングサイトっぽい。Liveを観るためには登録が必要とのことだが、おそらく登録しても放送は見られない。こうして個人情報を集めているのだろう。
特にサッカーは世界的人気コンテンツだから、いろんな国のサッカー少年少女がここにたどり着くのではなかろうか。
なんでQiitaにスパム記事が? 【Why?】
スパム記事のほとんどはスポーツ関連のものが多いということが判明した。
だが、なぜプログラミングに特化したQiitaにスポーツ関連のスパム記事を投稿するのだろうか?
ここから先は推測だが…
- QiitaはGoogle検索などで上位に食い込みやすい。(SEO効果)
- プログラミング関連の記事が多いのでスパム検知が難しい
- エラーメッセージやソースコードなど、無機質な文字列が豊富
- QiitaAPIで投稿を自動化できる
- メールアドレスだけで登録できてしまうので、アカウント作り放題
こんな理由がありそうだ。
実際に深夜にGoogle検索をかけてみると…

やはりヒットする…
うーん確かにヒットしたんだが…
GitLabにも同じような記事がある…これは…?🤔
**実はこの手のスパムはQiitaに限った問題ではない。**GitLabやMediumでも同じようなスパム記事が投稿されているようだ。ここまで熱心にスパム投稿を続けるということは、裏を返せばそれだけ効果があるということだ。このまま放っておくわけにはいかない。
ここまでのまとめ
以上の分析でわかったことを下記にまとめる
- 記事の内容はスポーツの試合のストリーミングサイトへのリンク
- 特にサッカーが多い
- リンク先はフィッシングサイトっぽい
- スポーツの試合時間に合わせて出現するが周期性はない
- 投稿自体は22時~翌4時に集中
- 1つのアカウントで20~100件くらい投稿される
- タイトルにLiveやStreamを含む
- ユーザ名は記事タイトルと似ている
- 機械的に生成されている可能性あり
こういったスパム記事、実は有志の方々がボーイスカウト的に人手で頑張って削除しているらしい。
スパム狩り活動支援ブックマークレット【運営にスパム記事を通知するツール】 - Qiita
来年は東京五輪だ。
スポーツの中継も増えるし、スパム記事も増加するだろう。
このままではいつか限界が来るに違いない。
何か効率のいい方法はないのか…?
ボクエイアイ🤖!ボーイスカウトヤリマス🤖!
そうか、AIだな!
これより次の作戦に移る。
作戦2:Qiitaスパム駆逐用AIの生成
AIといっても一体何のことを指しているのかわからないので、もう少し具体的に説明する。
こうしたスパム検知はデータ分析の世界では異常検知タスクと見做せる。
もっと踏み込んでスパム記事か普通の記事かを分類する二値分類タスクと言ってもいい。
方法は大きく3つ考えられる。
- ルールベースによるスパム検出
- 教師なし機械学習によるスパム検出
- 教師あり機械学習によるスパム検出
ルールベースによるスパム検出
ルールベースというのは要するにif ~ else ~で7スパムを見つける方法である。
そんな単純なのやってないで、もっとカッコよくDeepLearningやろうぜ!
と思うかもしれないが、ルールベースを侮ってはならない。これで十分なケースは結構多い。
では、どうやってルールを定義すれば良いのか?
先ほど作戦会議の部分でスパム記事の特徴(ドメイン知識)についてある程度洗い出した。
- 投稿時間(created_at)が深夜22~26時
- 同一ユーザが大量に投稿している
- タイトルとユーザ名にLive, Streamといった文字列が含まれる
これをそのままフィルタリングルール化しよう。
実際には次のように各ルールに対してフラグをつける。フラグが3つ以上のものはスパム認定だ。
def get_spammer_list(df):
postcount = df.groupby([df["created_date"].dt.day, "user_id"]).count().groupby("user_id").mean()
return postcount[postcount["id"]>=10].index.to_list()
def lookup(l1, l2):
"""
l1のなかにl2の要素が含まれるかを1つずつ照合する
"""
l = []
for x in l1:
z = False
for y in l2:
z = z or (str(y) in str(x))
l.append(z)
return l
# データ読み込み
df = pd.read_csv("20191101-1115_dataset.csv", sep="\t")
df["created_date"] = pd.to_datetime(df["created_at"], format="%Y-%m-%d")
# テスト期間のデータを切り出し
df_test = df[(df["created_date"]>= "2019-11-13")&(df["created_date"]<= "2019-11-16")].reset_index(drop=True) # 3 days
spammers = get_spammer_list(df_test)
spam_words = ["live", "vs", "stream", "free", "sport", "streaming"]
# ルール1:投稿時間が22~5
df_test["is_midnight"] = df_test["created_date"].dt.hour.apply(lambda x: True if ((x>=22)|(x<=4)) else False)
# ルール2:1日に10件以上投稿している
df_test["is_toomanypost"] = pd.Series(lookup(df_test["user_id"].str.lower(), spammers))
# ルール3:タイトルに指定文字列が含まれる
df_test["isin_title"] = pd.Series(lookup(df_test["title"].str.lower(), spam_words))
# ルール4:ユーザ名に指定文字列が含まれる
df_test["isin_use_id"] = pd.Series(lookup(df_test["user_id"].str.lower(), spam_words))
# 深刻度
df_test["severity"] = df_test[["is_midnight", "is_toomanypost", "isin_title", "isin_use_id"]].sum(axis=1)
# スパムかどうか(serverityが3以上のものを抽出)
df_test["is_spam"] = df_test["severity"].apply(lambda x: 1 if x>=3 else 0)
テストデータは11/13-11/15の三日間(1859記事で検証)
二値分類ということでAUCを評価値として計算してみる。
AUC: 0.7986778846153846
混同行列も確認してみる
- 左上&右下は正しく分類できたもの
- 精度は0.82(=0.55+0.27)
- 左下はスパムなのに正常と判定したもの(見逃し)
- 右上は正常なのにスパムと判定されたもの(誤検知)

実戦に耐えうるかと言われると微妙だが…そんなに絶望するほど悪くもない。
見逃しが多いのが気になるものの、これだけでもスパム狩りは可能だろう。
とはいえ、正直なところこの方法はあまり得策ではない。
静的なルールで検知しようとしてもうまくいくのは最初だけだ。
攻撃者側も当然、そうしたルールを掻い潜ろうとしてくる。
例えば「見逃し」してしまったものを見てみよう。
- タイトルが英語じゃないもの
- ŽIVě:Českárepublika-Anglieživýpřenos
- ユーザ名がシンプルすぎるもの
- EFL-Trophy-2k, soccer_19_20など
少しの変更で簡単に検出を逃れることが出来てしまうのが予想される。こうしたパターン全てに静的なルールで対応するのは非現実的だ。最終的にはイタチゴッコになってしまう。
やはり「攻撃者が変化を加えるたびに、いちいちデータを観察してルールを定義して…」というのを繰り返すのは悪手だ。結局人手がかかる。それが出来れば苦労はしねぇ。
そこで機械学習の出番だ。
教師なし機械学習によるスパム検出
教師なし機械学習による代表的な異常検知手法はざっと下記の通り。
- Tree系
- IsolationForest
- RandomCutForest
- NeuralNet系
- AutoEncoder
- AnoGAN
- 密度ベース・クラスタリング系
- LOF
- DBSCAN
- その他
- One-ClassSVM
ここではAutoEncoderを用いた異常検知を試してみる。
AutoEncoderによる異常検知
AutoEncoderとは下記のように入力と出力が同じになるように学習させるNeuralNetのことだ。
「そんなことをして何になる!」と思うかもしれないが、これが異常検知に使えるのだ。

まずは正常なデータだけをひたすら学習させたAutoEncoderを用意する。
これに生データを入力すると…
- 正常なデータ→「🤖ガクシュウズミデス!」→きれいに復元される
- 異常なデータ→「🤖ミタコトアリマセン!」→ぐちゃぐちゃに復元される
ということで入力と出力の再構成誤差(Reconstruction Error)を計測すれば、異常検知ができるのだ。
タイムスタンプやユーザの情報は後述の教師あり学習で頑張るので、ここではタイトル文字列に対して異常検知をしてみる。
ここで1つの壁にぶち当たる。
「あれ?ちょっとまて、文字列のままではAutoEncoderに入力できないぞ…」
そこで使えるのが**BERT**だ。
タイトル文字列をBERTエンコードする
今年もっともNLP界を震撼させたモノといえば、何と言ってもBERTだろう。
技術者として生まれたからには、死ぬまでに一回はBERTで遊んでみたい。(きっとみんなそうだ…)
これを使うと**「可変長の文字列」を「固定長の数値列」**に変換することが出来る。
例えばこんなふうに…
長さnのタイトル:「なんでドコモがアドベントカレンダー?」
↓
768次元ベクトル:[0.4112, 0.1899, -1.189, ..., 0.8319, -0.3271]
このように固定長の数値ベクトルであればコンピュータによる解析が可能となって、「このタイトルとこのタイトルは似ているな」とか「このタイトルは日本語としておかしいな」みたいなことが定量的に分析8できる。
今回は事前学習済みの日本語BERTモデルは京都大学のBERT日本語Pretrainedモデル - KUROHASHI-KAWAHARA LABを用いた。こうして学習済みモデルが提供されるのは非常にありがたいことである。
本記事では導入方法やファイルの扱いの詳細は割愛するが、AWSのSageMakerで環境構築する場合は下記のスクリプト一撃。最初のセルでそのまま実行すれば5~10分くらいでBERTが使えるようになるはずだ。
%%bash
git clone https://github.com/boostorg/boost.git
cd boost
git checkout boost-1.63.0
git submodule update --init
sudo ./bootstrap.sh
./b2
sudo ./b2 install
export BOOST_ROOT=/usr/local/include/boost/
echo $BOOST_ROOT
cd ../
export BOOST_ROOT=/usr/local/include/boost/
echo $BOOST_ROOT
wget http://lotus.kuee.kyoto-u.ac.jp/nl-resource/jumanpp/jumanpp-1.02.tar.xz
tar xJvf jumanpp-1.02.tar.xz
cd jumanpp-1.02
./configure
make
sudo make install
pip install pyknp
最終的にタイトルの文字列を768次元のベクトルに変換することが出来た。
きちんと意味のあるベクトルが得られているか可視化して確認してみよう!下記のツールを用いるとお手軽に結果を可視化することができる。
Embedding projector - visualization of high-dimensional data
ここでは768次元のベクトルを3次元に次元削減(UMAPを利用)してプロットしてみる。スパムが多かった11/6のデータを対象とする。
まずは正常な記事から…
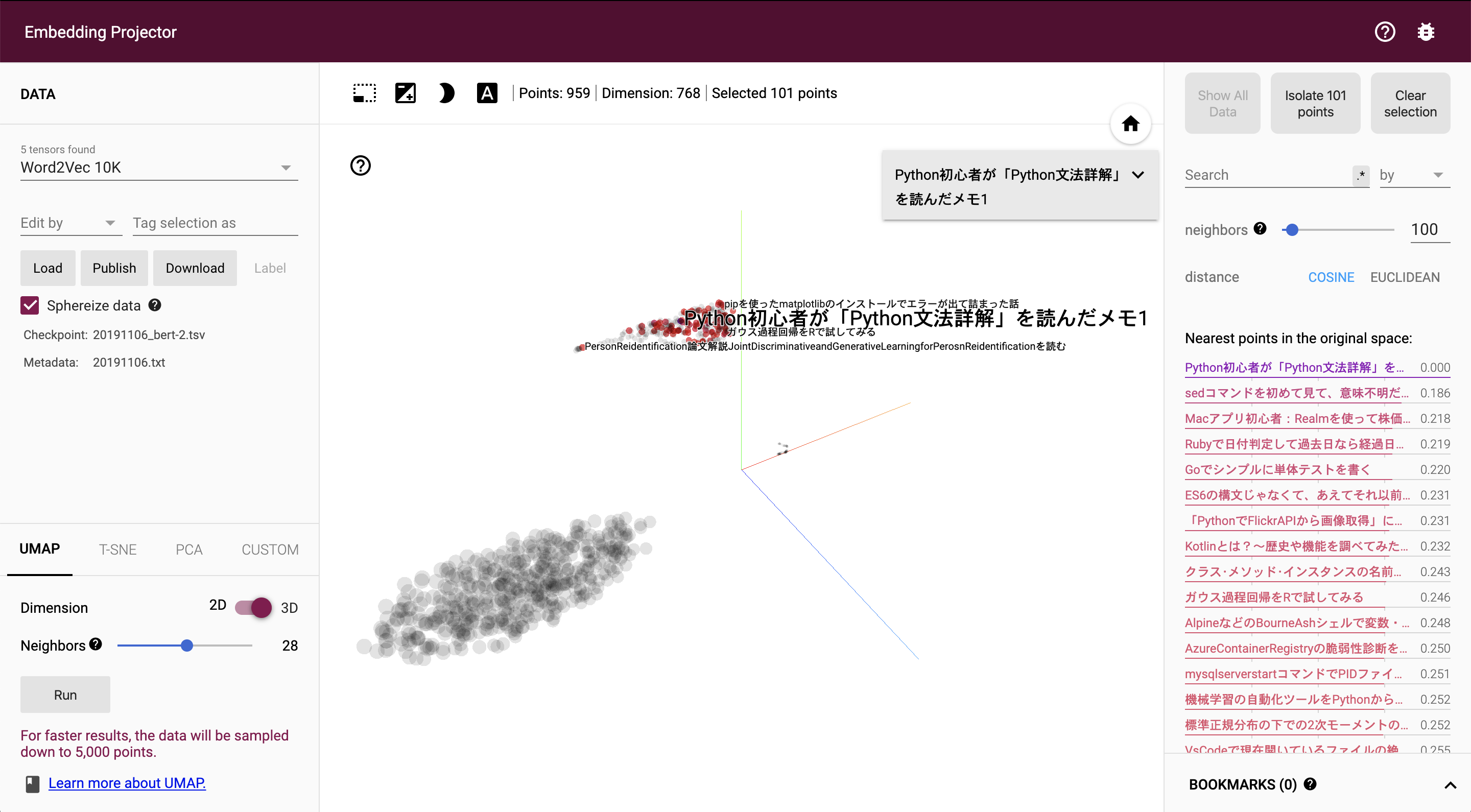
ほうほう。初心者向けの記事なのか?いずれにしても近い記事(右のカラム)としてスパムは見当たらない。
次はスパム記事を見てみる…

お!スパムが大集合している!これはうまくいきそうだ!
BERT-AutoEncoder異常検知
下のグラフは正常なデータのみの再構成誤差をプロットしたものだ。2019年9月と10月の正常なデータのみを学習させている。
横はデータのインデックスだが時間でソートしてある。
とりあえず0.9くらいに閾値を設けておこう。これを超えてくるものは異常とみなす。

そしてこれが実際のデータ(2019/11/01-2019/11/15)の再構成誤差だっ!
デキマシタ🤖

…😳
思ったのと違う…😳
スパム記事全然検知できていない…😳
一応説明しておくとオレンジがスパム記事だ。特定の時間帯に線状に並んでいるのがわかる。
似たようなタイトルのスパム記事が同じ再構成誤差になるのは望ましいことだが、学習させていないのに何故かきれいに復元されてしまっている。
ちなみに再構成誤差が大きいものTOP3をチラ見してみると…
- Data point index: 5512/5639
- (البثالمباشرلمصرضدليبيريا)(البثالمباشرلمصرضدلي...(アラビア語)
- (البثالمباشرلمصرضدليبيريا)(البثالمباشرلمصرضدلي...(アラビア語)
- Data point index: 10588
- ТУРЦИЯИСЛАНДИЯ::СМОТРЕТЬОНЛАЙН14-11-2019МАТЧ-H... (ブルガリア語?)
うーんなるほど。流石に言語や文字そのものが違うと再構成誤差が大きいようだ。
この手の記事はルールベースだと簡単にすり抜けられてしまうが、BERTの目からはしっかり捉えられている。
だが、その他多くの典型的なスパムを捉えられないのは残念だ。もし仮にスパムの数が全体の5%程度であればDBSCANなどの密度ベースの異常検知につなげられるのだが、Qiitaのスパムは全体の40%くらいだからだめだな…
その他、後学のために反省点を残しておく
- Qiitaのタイトルはそもそも多様性が高すぎて正常なものの間でも再構成誤差のばらつきが大きい
- 日本語BERTはWikipediaで学習しているためQiitaと相性が悪かった?
- エラーメッセージの文字列とスパムの文字列を区別できない?
- 正常なデータの学習が足りていなかった?
BERT×AutoEncoderによる異常検知では異形なスパム記事は検出できるため、ルールベースの補助的に使うのは有効だと考えられる。
こうしてBERTアノマリーディテクションプロジェクトは幕を下ろした…
気を取り直して次へ行こう。ByeByeBERT。
教師あり機械学習によるスパム検出
スパムかスパムじゃないかは二値分類タスクと見做せるため、ラベル付のデータがあればロジスティック回帰やランダムフォレストなどの教師あり学習の適用も可能だ。
と、言っても**イマドキはほぼLightGBM一択9**である。
こうした教師あり学習の分類タスクはデータの前処理と特徴量生成が重要である。LightGBMの場合、前処理はほとんど不要なので、ここでは主に特徴量生成について述べる。
時間的な前処理・特徴量生成
時間に依存する(Temporalな)特徴量を作る。
- 時間での集計処理
- 直近(1時間/1日)の記事投稿数、いいね数、タグ、ユーザ数
- 時間形式の変換処理
- 曜日、祝日情報の付与
- 時刻の丸め込み
- 更新時刻と投稿時刻の時間差
空間的な前処理・特徴量生成
特に時間に依存しない(Spatioな)特徴量を作る。
- カテゴリ値の変換
- カウントエンコード(ユーザ名)
- 文字列の長さ
- ユーザ情報の分解
- フォロー/フォローワー数
- 所属する組織アカウントの有無
- tagの分解
- ついているtagの数
- テキストデータのベクトル化
- タイトルやユーザ名をBERTなどで変換する
前処理用・特徴量生成のコードはコチラ
dropcols = ["created_at",
"updated_at",
"id",
"title",
"user",
"page_views_count",
"url",
"tags",
"user_id",
"organization",
"tags_0", "tags_1", "tags_2", "tags_3", "tags_4",
"dt",
"created_date",
"updated_date"
]
count_dic = {"user_id":None}
def nan_encode(s):
return s.isnull().replace({True: 1, False:0})
def nan_of_row_encode(df):
return df.isnull().sum(axis=1)
def get_freq(df, col, key, freq):
df_count = df.groupby(pd.Grouper(key=key, freq=f'1{freq}')).nunique()
df_day = df[key].dt.floor(freq)
result = pd.merge(df_day, df_count[col], on=key, how='left')
return result[col]
def spatio_preprocess(df, phase):
"""
空間特徴量の前処理
- Categoryのエンコーディング
- テキストの前処理
- その他(欠損具合、外部テーブルとの集約など)
"""
# count_encode
if(phase=='fit'):
count_dic["user_id"] = df["user_id"].value_counts()[:300] # 上位300ユーザ以下は切り捨て
df["user_count"] = df["user_id"].map(count_dic["user_id"]).fillna(0).astype(np.int32)
else:
df["user_count"] = df["user_id"].map(count_dic["user_id"]).fillna(0).astype(np.int32)
# tagの数
df["num_tag"] = 5 - nan_of_row_encode(df[["tags_0","tags_1","tags_2", "tags_3", "tags_4"]])
# organizationの有無
df["isorganization"] = nan_encode(df["organization"])
# titleの長さ
df["len_title"] = df["title"].map(lambda x: len(x))
# user_idの長さ
df["len_user_id"] = df["user_id"].map(lambda x: len(x))
def temporal_preprocess(df):
"""
時間特徴量の前処理
- タイムスタンプ丸め、差分
- 時間集約など
"""
# 時間帯
df["hour"] = df["created_date"].map(lambda x: x.hour)
df["weekday"] = df["created_date"].map(lambda x: x.weekday)
# 時間差分
df["timedelta"] = (df["created_date"]- df["created_date"].shift(1)).map(lambda x: x.seconds).fillna(0)
df["timediff"] = (df["updated_date"]-df["created_date"]).map(lambda x: x.seconds)
# 時間グルーピング
df["postperday"] = get_freq(df, "id", "created_date", "D")
df["postperhour"] = get_freq(df, "id", "created_date", "H")
df["userperday"] = get_freq(df, "user_id", "created_date", "D")
df["userperhour"] = get_freq(df, "user_id", "created_date", "H")
def drop_col(df, cols):
return df.drop(columns=cols, inplace=True)
def preprocess(df, phase, dropcols):
spatio_preprocess(df, phase)
temporal_preprocess(df)
drop_col(df, dropcols)
X, y = df.drop("label", axis=1), df["label"]
return X, y
特徴量詳細はコチラ
初期特徴量
| 名前 | 型 | 説明 |
|---|---|---|
| created_at | timestamp | 記事の投稿時刻 |
| updated_at | timestamp | 記事の更新時刻 |
| id | string | 記事ID |
| title | string | 記事タイトル |
| user | string | ユーザ名 |
| likes_count | int | いいね数 |
| comments_count | int | コメント数 |
| page_views_count | int | ページ閲覧数 |
| url | string | 記事URL |
| tags | string | タグ(0~4まで最大5つ) |
| user_follower | int | フォロワー数 |
| user_followee | int | フォロー数 |
| items_count | int | 投稿記事数 |
| organization | string | 所属する組織アカウント |
追加特徴量
※BERT特徴量はメモリやCPU負担が大きい。システム化を見据えるとLightGBMの軽量動作の利点を殺してしまうので今回は除外
| 名前 | 型 | 説明 |
|---|---|---|
| user_count | int | ユーザ名を出現回数でエンコードしたもの |
| num_tag | int | ついているタグの数 |
| isorganization | int | 組織アカウントとの紐付けの有無 |
| len_title | int | 記事タイトルの文字数 |
| len_user_id | int | ユーザ名の文字数 |
| hour | int | 時間(hour) |
| weekday | int | 曜日 |
| timediff | int | 更新時刻と投稿時刻の差分 |
| timedelta | int | 直前の投稿時刻との差分 |
| postperday | int | 1日あたりの投稿数 |
| postperhour | int | 1時間あたりの投稿数 |
| userperday | int | 1日あたりのユーザ数 |
| userperhour | int | 1時間あたりのユーザ数 |
不要な特徴量を削除すると最終的にこうなる

ここまでスムーズに特徴量を作れたのは、「作戦会議」でデータをよく観察していたからだ。EDAを怠るとろくな特徴量が出てこない。
とりあえずこれでLightGBMに流してみよう。もしこれであまり精度が良くなければ、また作戦会議からやりなおしだ。
LightGBMによるスパム検知
学習・予測用のコードはコチラ
LGBM_PARAMS = {
"learning_rate": 0.01,
"objective": "binary",
"metric": "auc",
"verbosity": -1,
"seed": 13,
"num_threads": -1
}
def train_lightgbm(X_train: pd.DataFrame, X_val: pd.DataFrame, y_train: pd.Series, y_val: pd.Series, hyperparams):
params = LGBM_PARAMS
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_val, label=y_val)
score = {}
model = lgb.train({**params, **hyperparams},
train_data,
1500,
valid_data,
early_stopping_rounds=300,
evals_result = score,
#feval = eval_auc, # numba高速化
verbose_eval=100)
score = score['valid_0']['auc'][-1]
print("Best Score\t:", score)
del train_data, valid_data
gc.collect()
return score, model
def predict_lightgbm(X_test: pd.DataFrame, model):
pred = model.predict(X_test
return pred
def hyperopt_lightgbm(X_train: pd.DataFrame, X_opt: pd.DataFrame, y_train: pd.Series, y_opt: pd.Series):
params = LGBM_PARAMS
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_opt, label=y_opt)
space = {
"max_depth": hp.choice("max_depth", [-1, 3, 4, 5, 6]),
"num_leaves": hp.choice("num_leaves", np.linspace(10, 200, 50, dtype=int)),
"feature_fraction": hp.quniform("feature_fraction", 0.5, 1.0, 0.1),
"bagging_fraction": hp.quniform("bagging_fraction", 0.5, 1.0, 0.1),
"bagging_freq": hp.choice("bagging_freq", np.linspace(0, 50, 10, dtype=int)),
"reg_alpha": hp.uniform("reg_alpha", 0, 2),
"reg_lambda": hp.uniform("reg_lambda", 0, 2),
"min_child_weight": hp.uniform('min_child_weight', 0.5, 10),
}
def objective(hyperparams):
model = lgb.train({**params, **hyperparams},
train_data,
300, # ここ少なく
valid_data,
#feval = eval_auc, # numba高速化
#early_stopping_rounds=50,
verbose_eval=0)
#score = model.best_score["valid_0"]["auc"]
score = model.best_score["valid_0"][params["metric"]]
# in classification, less is better
return {'loss': -score, 'status': STATUS_OK}
trials = Trials()
best = hyperopt.fmin(fn=objective, space=space, trials=trials,
algo=tpe.suggest, max_evals=10, verbose=1,
rstate=np.random.RandomState(1))
hyperparams = space_eval(space, best)
print(f"auc = {-trials.best_trial['result']['loss']:0.4f} {hyperparams}")
del train_data, valid_data
gc.collect()
return hyperparams
hyperparams = hyperopt_lightgbm(X_train, X_opt, y_train, y_opt)
score, model = train_lightgbm(X_train, X_val, y_train, y_val, hyperparams)
ポイントを簡単に述べる。
- データ分割(train/validation/test)は時系列に沿って行う
- Hyperoptでパラメータ調整
結論からいうとAUC0.99というオバケ分類器が出来上がった。
普通AUC0.99なんてアリエナイ。というかLeakageの可能性が高い。全然嬉しくないし、むしろ不安だ。
…と思っていろんなデータでテストしたが、確かに高精度で予測できている。
今回はデータが単純だし、強力な特徴量がありそうだから問題はないようだ。
混同行列はこんな感じである。
左上と右下の数字はきちんとスパム検知できているものである。概ね良い。精度で言えば驚異の93%だ。
左下は「見逃し」、右上は「誤検知」である。どちらも小さく抑えられていることがわかる。
ユーザが自分で記事を消した場合もスパムラベルがついてしまうので誤検知が僅かに存在するが、学習データを増やせばその影響も小さくなるだろう。

また、LightGBMでは特徴量重要度算出という神機能がついている。デフォルトでは「木の分岐(split)に使われた回数」が重要度としてプロットされる。
これを確認することでLightGBMがどの特徴量に注目してスパムかどうかを判断したのかがわかる。
下記のグラフからはuser_count(ユーザ名)が一番重要で次にフォロー数、投稿記事数と続く。

その他わかることは
- タイトル、ユーザ名の長さも重要(多分アルファベットの羅列は長くなりがちだから?)
- フォロー数 > フォロワー数
- コメント数はほぼ無価値(投稿したばかりだからコメントがつくわけない)
なるほど、ユーザ名が一番重要なのか。LightGBMがここまで言うんだから、よっぽど重要な特徴量なのだろう。
ん?ということは、BERT異常検知でもタイトルよりユーザ名に着目した方がうまくいったかもしれないな…
やはり初手LightGBMは真理だったか。
GCP AutoML Tablesによるスパム検知
AutoMLとは先ほどやってきた前処理・特徴量生成・パラメータ調整・学習などを全自動でやってくれるという夢のような機能だ。
GCPは今年からこのAutoMLをサービスとして提供しており、**「データサイエンティストがAIに仕事を奪われた!」**と非常に話題になった。
さぁ、機械学習3年生の僕から仕事を奪えるかな…?
まずはBigQueryにデータをアップロードしてAutoML Tablesにインポートしてみる。
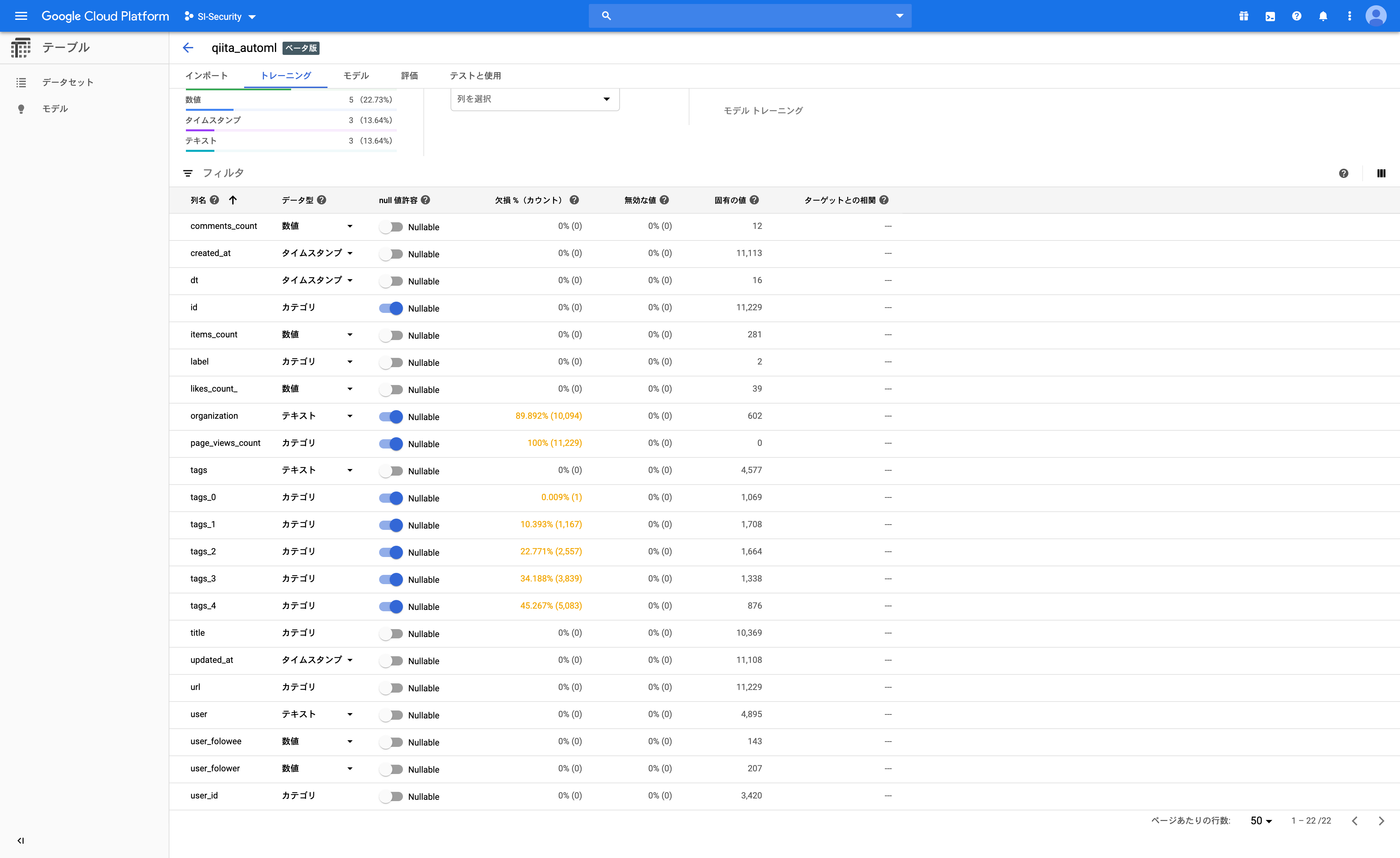
お、なかなかやるな!ちゃんとデータ型や欠損値、ユニーク要素数(カーディナリティ)10など把握できている。
あとは目的変数の設定とデータの分割を時系列(time_split)にするだけだ。
AutoML Tablesは利用時間に対して課金される。
1時間19ドル程度らしいのでひとまず2時間くらいにしておこう…
さぁ、少しコーヒーでも飲んで横須賀の風にでも当たってくるか…
そして2時間後…
僕はAIに仕事を奪われることになる
オマタセシマシタ🤖
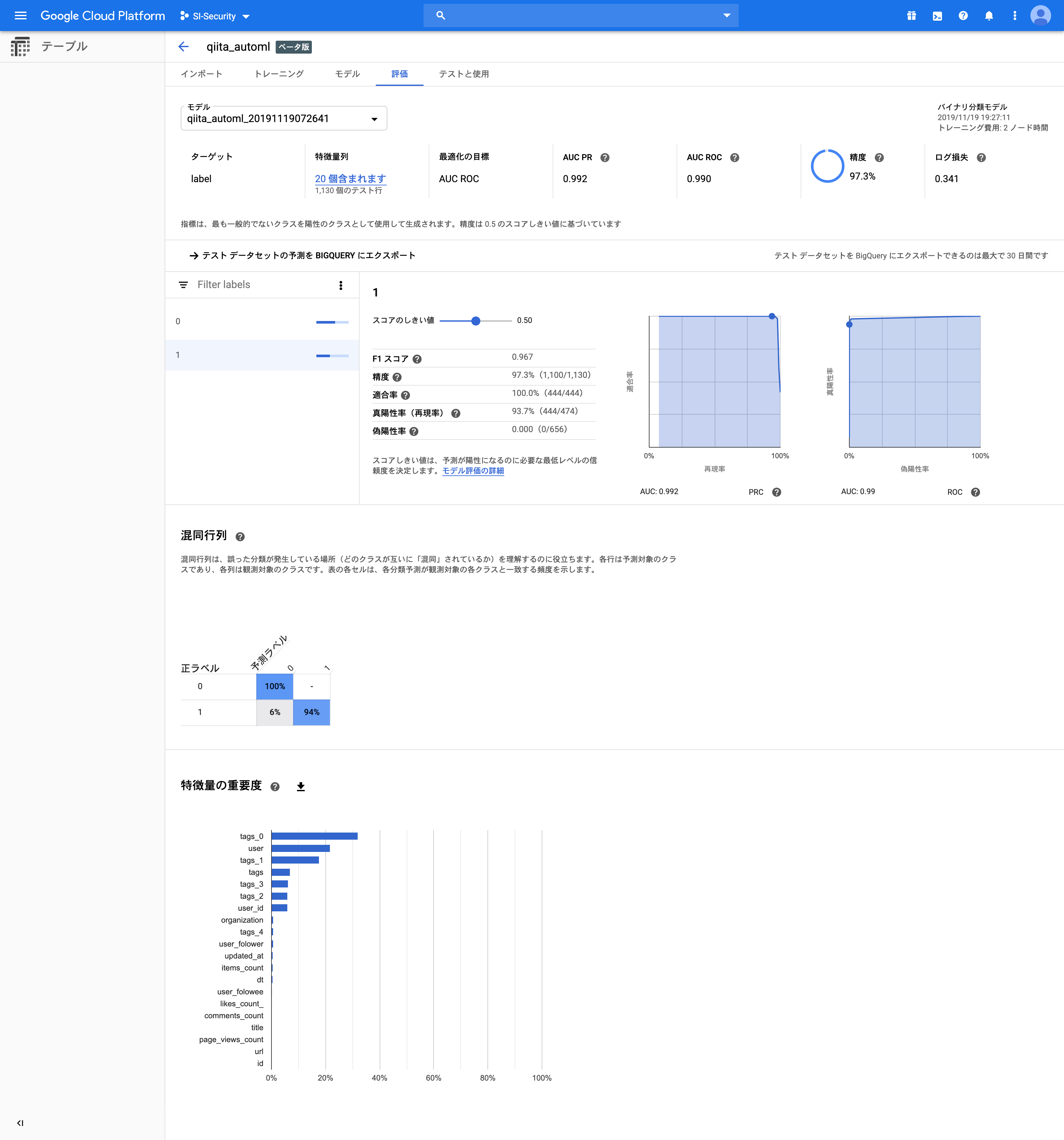
ぐぇぇ…っ🤮!?
つ…強いっ…!
精度97%…先ほど頑張って動かしたLightGBMとほぼ同等の結果11が出ている。
しかも今回は全く前処理をしていない!おまけにご丁寧に特徴量重要度までグラフ化してやがる…
これがAutoMLのチカラ…
これがデータサイエンティストの死…
ここでやめるのもまた勇気…
すごい…恐るべしAutoML Tables!
一瞬死にかけたが冷静に考えると、さすがに今回の使ったデータはやや単純すぎたような気もする。
そもそも元のLightGBMでもオバケ性能なんだから、あまり凝った前処理や特徴量生成しなくても十分だったのだろう。
ここはAutoML Tablesが賢いのではなく、もとの分類タスクが簡単すぎたと見るべきだと思う。 そうしないと僕の立場がn
少し使ってみた所感をまとめておく。
- スゴいところ
- 前処理しないでデータを投入しても、良い感じに学習してくれる
- 欠損具合や特徴量重要度などの参考情報も出力される
- EmbeddingやOne-hotエンコードもやってくれる
- AdaNet(NAS)が使える🤤
- REST APIやコンテナデプロイも可能
- IoTのエッジ推論と相性が良さそう
- 前処理しないでデータを投入しても、良い感じに学習してくれる
- ネックになりそうなところ
- 学習一回でおよそ200~4000円
- 予測させるとさらに課金される
- 使えるアルゴリズムが少ない
- 特徴量生成が貧弱?
- FeatureImportanceを見ると、独自の特徴量は生成していない?
- 学習一回でおよそ200~4000円
AutoML Tablesは学習したモデルをシームレスにデプロイできるのが地味にスゴいところ。特に今回のようにセキュリティ目的で機械学習を導入する場合は、インフラと密接に連携する必要がある。
AWSでもSageMakerでコードを書いて推論エンドポイントをデプロイすれば同じようなことができるが、その場合はある程度自力で実装する必要があってハードルが高い。
その点、GCPのAutoML Tablesはデータを放り込むだけなので誰でも使えるだろう。データの入出力やパラメータ調整のインターフェースが整備された感じだ。これから機械学習をやってみようというインフラエンジニアにはぴったりなサービスなのかもしれない。
本気のルールベース
LightGBMとAutoML Tablesを使ってみて「user_id」と「タグ」が重要であるということが判明した。逆にこれをルールベースの方へフィードバックしてみよう。先ほどのルールではタグの情報を使っていなかったので新しくフラグを追加する。
# tags_0に指定文字列が含まれる
df_test["isin_tags"] = pd.Series(lookup(df_test["tags_0"].str.lower(), spam_words))
するとどうだろうか…
結果は…
AUC:0.9471153846153846
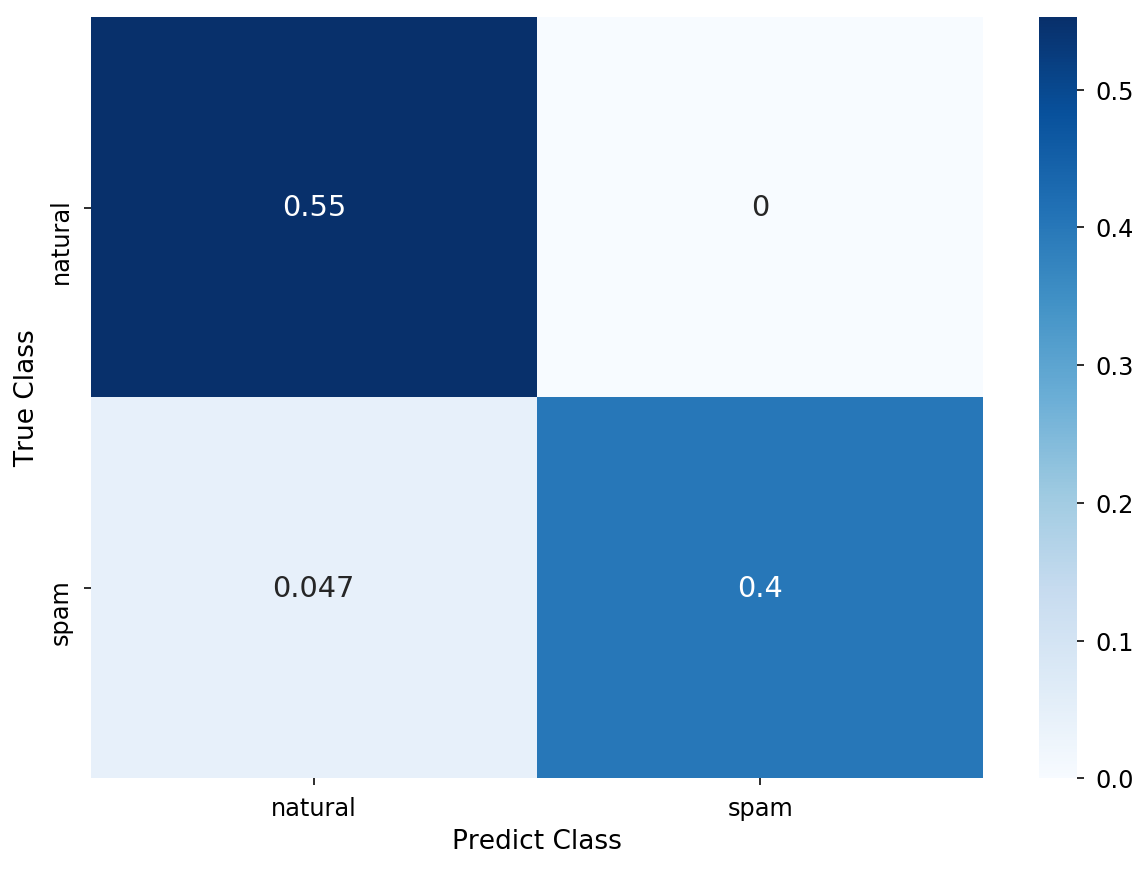
精度95%🤩!!よい!よいではないか!
先ほどはAutoMLに手足をもがれてしまったが、ここまで精度が出ていればルールベースでもAutoMLと遜色ないスパム検知ができそうだ。誤検知が0なのも素晴らしい。無実の記事をスパム扱いするわけにはいかないからな。ルールの更新は人手だけど、これくらい精度が出るならやる価値はある。
おまけにメモリやCPUも消費しなくて済むし動作も高速だろう。
これならAWSのLambdaでも簡単に動かせる!
覚醒したルールベーススパム検知Lambda関数のコードはこちら
import json
import io
import datetime
import pprint
import boto3
from botocore.exceptions import ClientError
import pandas as pd
label_list = [
'created_at',
'updated_at',
'id',
'title',
'user',
'likes_count',
'comments_count',
'page_views_count',
'url',
'tags',
#'rendered_body'
]
def get_spammer_list(df):
postcount = df.groupby([df["created_date"].dt.day, "user_id"]).count().groupby("user_id").mean()
return postcount[postcount["id"]>=10].index.to_list()
def lookup(l1, l2):
"""
l1のなかにl2の要素が含まれるかを1つずつ照合する
"""
l = []
for x in l1:
z = False
for y in l2:
z = z or (str(y) in str(x))
l.append(z)
return l
def anomaly_detection(s3, f_list, bucketname):
fname=f_list[-1]
# データ読み込み
obj = s3.get_object(Bucket=bucketname, Key=fname)
df = pd.read_csv(io.BytesIO(obj['Body'].read()), sep='\t')
df["created_date"] = pd.to_datetime(df["created_at"], format="%Y-%m-%d")
spammers = get_spammer_list(df)
spam_words = ["live", "vs", "stream", "free", "sport", "streaming"]
# 投稿時間が22~5
df["is_midnight"] = df["created_date"].dt.hour.apply(lambda x: True if ((x>=22)|(x<=4)) else False)
# 1日に10件以上投稿している
df["is_toomanypost"] = pd.Series(lookup(df["user_id"].str.lower(), spammers))
# タイトルに指定文字列が含まれる
df["isin_title"] = pd.Series(lookup(df["title"].str.lower(), spam_words))
# ユーザ名に指定文字列が含まれる
df["isin_use_id"] = pd.Series(lookup(df["user_id"].str.lower(), spam_words))
# tags_0に指定文字列が含まれる
df["isin_tags"] = pd.Series(lookup(df["tag_0"].str.lower(), spam_words))
# 深刻度
df["severity"] = df[["is_midnight", "is_toomanypost", "isin_title", "isin_use_id", "isin_tags"]].sum(axis=1)
# スパムかどうか(serverityが3以上のものを抽出)
df["is_spam"] = df["severity"].apply(lambda x: 1 if x>=3 else 0)
print(df.describe())
return df
def lambda_handler(event, context):
s3 = boto3.client('s3')
bucketname = 'xxxxxxxxxxxxxxx<バケット名>'
date = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9)))
date = date - datetime.timedelta(days=2)
i_prefix = 'qiita_data'
o_prefix = 'qiita_anomaly'
partition = f'dt={date.year:02}-{date.month:02}-{date.day:02}'
response = s3.list_objects_v2(
Bucket=bucketname,
Prefix=i_prefix+'/'+str(date.year)+'/'+partition
)
print(response)
f_list = [f['Key'] for f in response['Contents'] if f['Key'].endswith('.tsv')]
print("f_list", f_list[-1])
# anomaly hunting
result = anomaly_detection(s3, f_list, bucketname)
# save file
fname = '{:04}{:02}{:02}_qiita_anomaly.tsv'.format(date.year, date.month, date.day)
result.to_csv('/tmp/'+fname, index=False, sep='\t')
s3.upload_file('/tmp/'+fname, bucketname,
o_prefix+'/'+str(date.year)+'/'+partition+'/'+fname)
print('Upload Complete!!')
print(fname, len(result))
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
この覚醒ルールベースLambdaは僕の手元で毎日スパム検知している。精度が不安定12だがLightGBMやBERTの結果を加えていけばもっと改善するはずだ。

人間を舐めるなよ…AutoML
まとめ
下表はそれぞれの特徴をまとめたもの。
※あくまで今回のデータセットでの比較であることに注意!
| 手法 | 精度 | リアルタイム性 | 金銭コスト | 実装コスト | メンテナンス |
|---|---|---|---|---|---|
| ルールベース | △ | ◯ | ◯ | ◯ | × |
| 教師なしベース(AutoEncoder) | × | △ | △ | △ | ◯ |
| 教師ありベース(LightGBM) | ◯ | ◯ | ◯ | △ | × |
| 教師ありベース(AutoML) | ◯ | ◯ | × | ◯ | △ |
- ルールベースはルール定義、教師ありはラベル付で人手が必要となる。
- AutoEncoderの精度は要改善。ラベル付が不要だが、前処理がやや大変。
- LightGBMは高精度だが、人手でラベルを付けなければならない。
- AutoMLはLightGBMと同精度だが割高。実装やメンテナンスはLightGBMよりも低コスト。
スパム検知ではAutoMLを使うと全体のシステム運用が楽そうだ。
コストが気になる場合はルールの改善を頑張ろう。今回はAutoMLが「タグに注目すべし」と教えてくれた。機械学習アルゴリズムのメタ情報を使えば、より精度の高い検知ルールが判明するかもしれない。
今回は一気通貫サーバレスで構築したかったのでルールベースで実装したが、メンテナンスコストを考えればLightGBMをLambda実装した方が少しはマシな気がする。
人間がさき AutoMLがあと
今回は誠に残念ながらAutoMLに仕事を奪われてしまったが、だからと言って今後全てのデータサイエンティストの仕事がなくなることはないだろう。
僕はここ数年、多くのKagglerが特徴量ガチャに奔走し、Shakedownに阿鼻叫喚する姿を(主にSNSで)目の当たりにしてきた。AdversarialValidationやPseudoLabelingなどにはもはや狂気すら感じる。また、アルゴリズムの進歩も早い。最近ではDeepGBMやNGBoostなどが注目されているが、こういった最新手法をAutoMLに取り込むのは相当骨が折れるはずだ。
AutoMLは単純作業の自動化では活躍できるかもしれないが、こうした試行錯誤や最新手法の導入は人間にしかできない。AutoMLが登場したことによってKaggleやKDDCUPなどのデータ分析コンペはより重要になってくるだろう。データサイエンティストが道を切り開き、AutoMLが舗装し、一般人がそこを通るのだ。
おわりに
長い戦いだった…
サーバレス…
BERT…
AutoML…
AWSに始まり、機械学習の海を漂い、最終的になぜかGCPにたどり着いた。
ひとまず今回は「AutoMLで頑張ればスパム検出システムが作れそうだな」というところまでは検証できた。正月に時間があればAWS-GCP間の「クラウド越境」にチャレンジしようと思う。
また、現状ルールベースでスパム検知しているが正直何度もルールを更新するのは面倒だ。LightGBMくらいならLambdaでも動かせるはずなのでそこらへんもサクッと検証してみよう。
いずれ精度・性能が実戦投入可能なレベルになれば「作戦3: スパム通報の自動化」に移りたい。
それではみなさん、良い年末を…
じゃなくて、アドベントカレンダーはまだまだ続きますのでお楽しみに。
参考
-
AutoEncoderの異常検知
-
Qiitaスパム記事
-
AutoML
-
BERT
-
おそらく小中学生のユーザもいるだろうし ↩
-
KDD主催のデータ分析コンペティションhttps://www.nttdocomo.co.jp/binary/pdf/info/news_release/topics_190809_01.pdf ↩
-
“データベースの区切り目”のようなもの ↩
-
正規ユーザによる記事の投稿削除なども含まれていることに注意 ↩
-
統計量をもとに異常度を算出する場合もこちらに含める。 ↩
-
Word2Vecでも同じことができるが、イマドキはBERTだ ↩
-
AutoML界では前処理も自動化するため、カーディナリティを確認するのは重要。カーディナリティが高いカテゴリ列をカウントエンコーディングすると、ほとんどの値が1とか2になってしまう。ここを無視すると時間も計算資源も無限に消費してしまう。 ↩
-
テストデータの期間が異なるため厳密な比較にはなっていない。 ↩
-
たまにVSCodeが紛れ込んでくる ↩