@triwave33さんの良記事に触発され、GANに対しての関心が高まり、自分でもなにかアウトプットできないかなと思ったので、今回はキルミーベイベーの画像生成を行いました。
この記事では、GANについて基礎から解説し、最後にはDCGANを使ってキルミーベイベーの画像を生成することを目標としています。
以前、以下のような記事
Kerasでキルミーアイコン686枚によるキルミー的アニメ絵分類
を使ってKerasの勉強をし、面白いなと思ったので、
今回はDCGANを使って分類ではなく生成を行おうと思います。
また、潜在変数(ノイズ)に関して詰まったので、そこに関して掘り下げます。
ついでに、転置畳み込みに関しても少し触れています。
GAN関連の良記事としては
今さら聞けないGAN(1) 基本構造の理解
今さら聞けないGAN (2) DCGANによる画像生成
はじめてのGAN
があります。
実装は今さら聞けないGAN(1) 基本構造の理解と、今さら聞けないGAN (2) DCGANによる画像生成、eriklindernoren/Keras-GANを参考に行いました。
本記事での実装は私のGitHubに上げます。
キルミーベイベーデータセットとは
たぶん、本記事に来るような人はGANについてはなんとなく「いわゆる生成モデル」(画像を作るネットワーク)なんだよなぁくらいなことは知ってると思うので、先回りして、タイトルにあったキルミーベイベーとはなんぞやについて少しだけ触れます。
まず、キルミーベイベーとは、2012年ごろにアニメ化されたギャグアニメで、BDが686枚しか売れなかったらしいです。笑
↓こんな子たちがワイワイやってます。


そこで、キルミー公式はそのBD売上の686枚にちなんで、twitterのフォロワー1万人記念として686枚の画像(128x128x3)を公式サイトにアップしています。
本記事では、その686枚の画像をKerasでキルミーアイコン686枚によるキルミー的アニメ絵分類のクラス分類に則りデータセットを用意しています。手作業で分類しました。
分類済みのファイルを上げておくので、もしよかったらご利用ください。
今回は、画像生成なので、このようなクラス分けは不要なのですが、ついでにデータロード関数ではラベル付も行っています。クラス分類のためのデータセットにも使っていただけたら嬉しいです。
本題に入ります。
GANの仕組み
GAN全体の仕組みについて概説します。
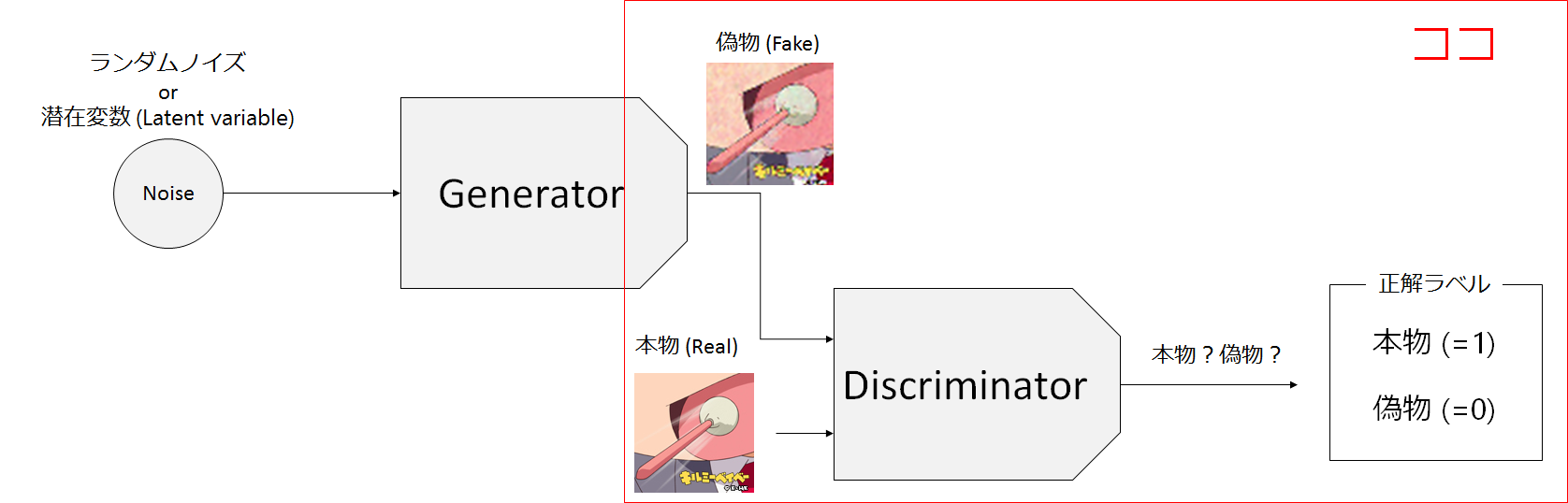
GANはGeneratorとDiscriminatorという別々の学習モデルを用います。
このGeneratorとDiscriminatorの関係は、しばしば紙幣の偽装者(Generator)と、その紙幣が偽装紙幣であるかを見抜く警察(Discriminator)の関係で表されます。偽装者はできるだけ本物の紙幣に近い偽装紙幣を作り出すことで、警察の目を騙そうとします。逆に、警察も目利きスキルを上げてより本物の紙幣か偽物の紙幣かを見抜こうとします。GANではGeneratorはできるだけ本物(オリジナル)に近い画像を生成し、Discriminatorはそれが本物の画像か否かを判定するような構造をしています。
つまりこの関係は、イタチごっこの関係にあり、よりツワモノの敵と競い合うことでスキルを高めていきます。GANでは、偽装者(Generator)の方に関心があり、より本物に近い画像などを生成することを目標としています。Generative Adversarial Nets(GAN)が敵対生成ネットワークという呼び名になっているのも、この競い合いのことを言っています。
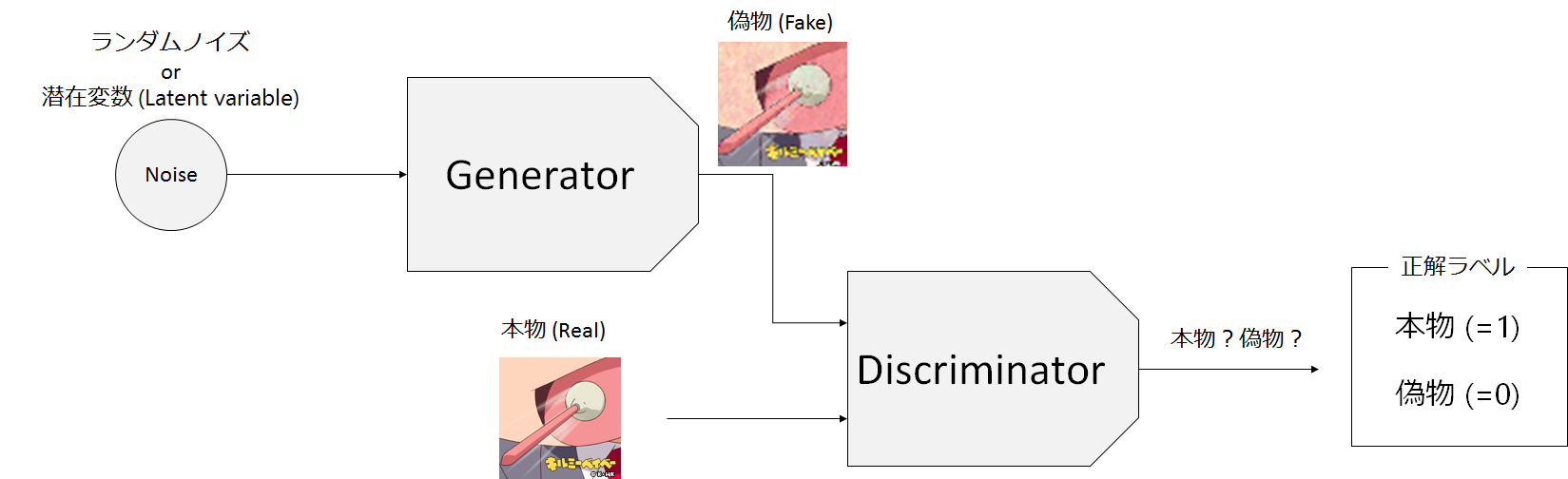
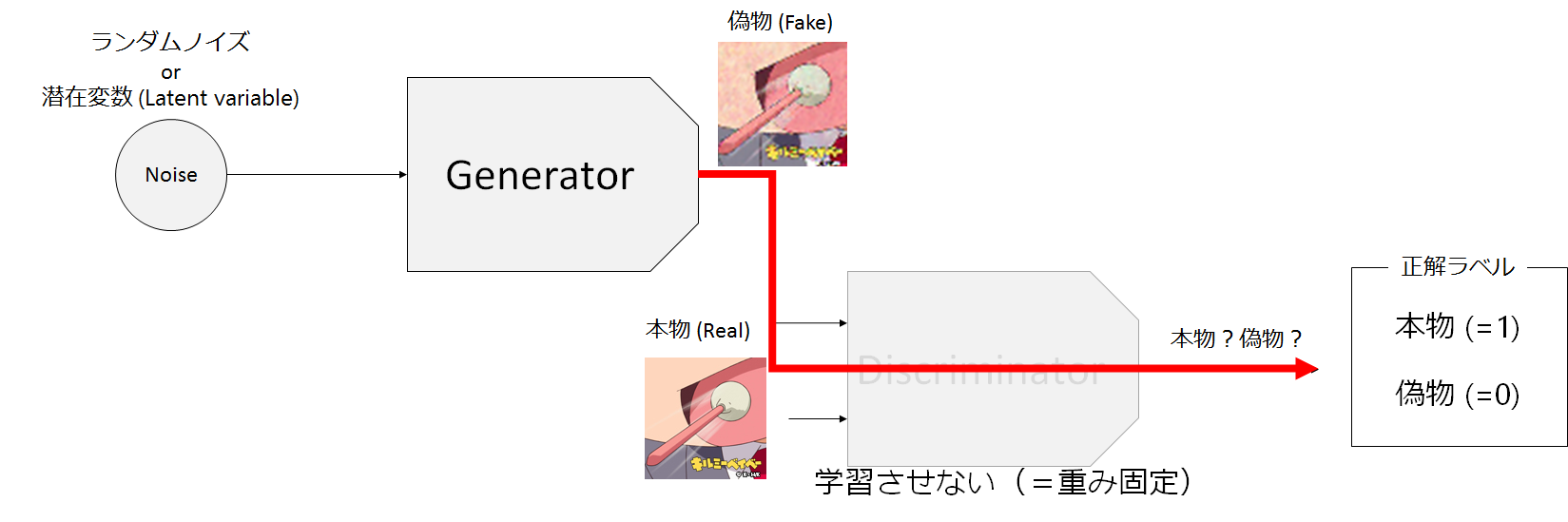
上の図ではGANの概略図を示しています。
GANでは入力としてノイズや潜在変数と呼ばれる乱数(Noise)をGANに入力し、偽物の画像(Fake)を生成します。Discriminatorは生成されたFakeと本物画像(Real)のいずれかを入力として受け取り、それが生成されたもの(Fake)であるか、本物(Real)であるのかを判別します。
Generatorの仕組み
GANの概説をしたところで、次に具体的な学習モデルの中身について見ていきます。
まず、Generatorからですが、これは一様分布や正規分布(ガウス分布とも呼ばれる)から、取り出してきた潜在変数(Noise)を入力します。DCGANの論文では、64x64x3の画像の生成に100次元の潜在変数を使っています。この潜在変数を入力として、それを転置畳み込み層(Transposed Convolution、逆畳み込み(Deconvolution)と呼ばれることもある。)を行います。
転置畳み込みについては、ニューラルネットワークにおけるDeconvolutionに記述がありますが、少し解説を加えます。
次の図は転置畳み込みの動作を示した具体的なイメージ図になります。横幅があるので、クリックして拡大したほうが見やすいと思います。簡単に言うと、特徴から元画像を復元するようなことを行っています。図では、もともと小さいサイズの2x2の画像を2倍に拡大(2x2のアップサンプリング)して、3x3の畳み込みを掛けます。これが基本的な転置畳み込みの動作です。
しかし、今回は畳み込みの前にパディングをしています。理由は、畳み込みを行うとサイズが小さくなってしまい、転置畳み込みで拡大した効果得にくいということと、その方が、最終的な目標サイズに合わせやすいからです(2x2の転置畳み込みだと単純にサイズが2倍になるので)。
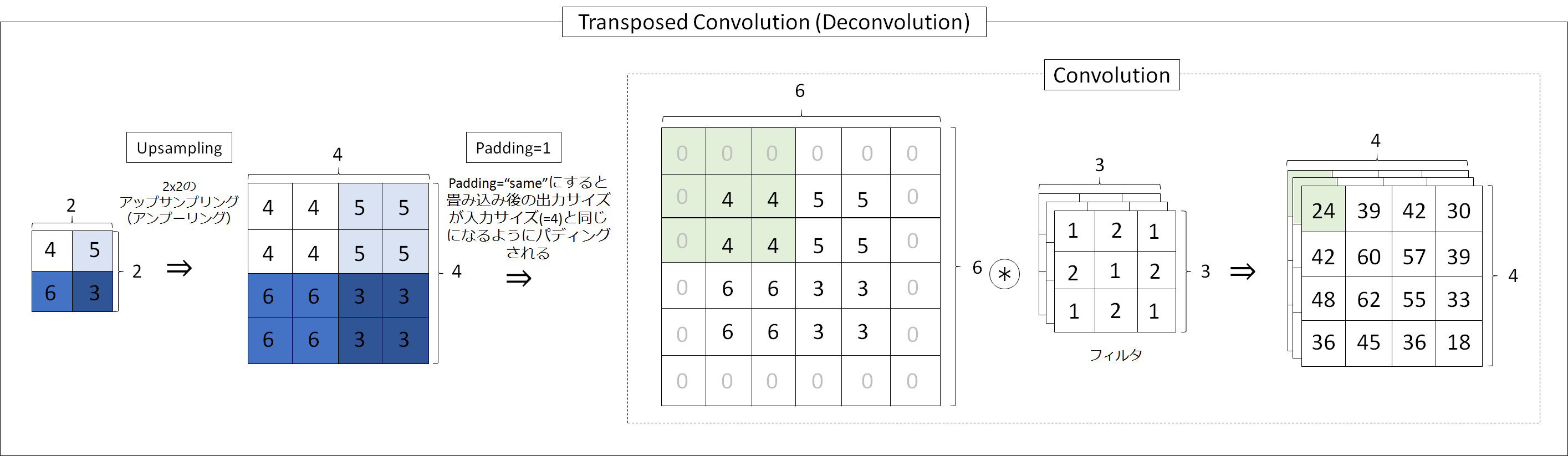
KerasやTensorFlowではpadding='same'と引数を取ると実装できます。図では周囲1マス分のパディング(ゼロパディング)を行っています。padding=1なのは、次式から導くことができます。
\lfloor \frac{I_{nput} - F_{ilter} + 2P_{adding}}{S_{tride}} \rfloor + 1= O_{utput}
今回は
I_{nput} = 4, F_{ilter}=3, S_{tride}=1, P_{adding}=Unknown, O_{utput}=4
なので、padding=1となります。
下のGeneratorの実装でもアップサンプリングをした後、畳込みを行っていますが結局は転置畳み込み層と同じ動作をしています。
noise_shape=(self.z_dim,)は潜在変数の次元数を示しています。また、MNIST(28x28x1)と異なり、今回のキルミーベイベーデータセットは、それぞれ128x12math8x3の画像であるので、始めのノード数は3232128となっています。128の部分は任意ですが、32*32は必然です。理由は転置畳み込みを2回行っているからで、32x32 --> 64x64 --> 128x128と画像が変化していくことを見越して設定する必要があります(Conv2Dのpadding='same'となっているのに注意)。また、もう一点違う点は最終の畳み込みフィルタが3枚であるということで、これは画像のチャネル数と一致させる必要があります。
def build_generator(self):
noise_shape = (self.z_dim,)
model = Sequential()
model.add(Dense(128 * 32 * 32, activation="relu", input_shape=noise_shape))
model.add(Reshape((32, 32, 128)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(3, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=noise_shape)
img = model(noise)
return Model(noise, img)
次に、Generatorの入力である潜在変数って何かについて少し詰まったので、自分的に腑に落ちた解説をもう少し行います。
潜在変数(Generatorの入力)
潜在変数(Latent Variable)というのは、潜在空間(Latent space)の中にある変数のことを言っていて、じゃあ潜在空間って何かというと、自己符号化器(Autoencoder)の折り返し地点(Bottleneck)のところです。潜在変数は解釈的には「入力データの別表現」と捉えることができます。
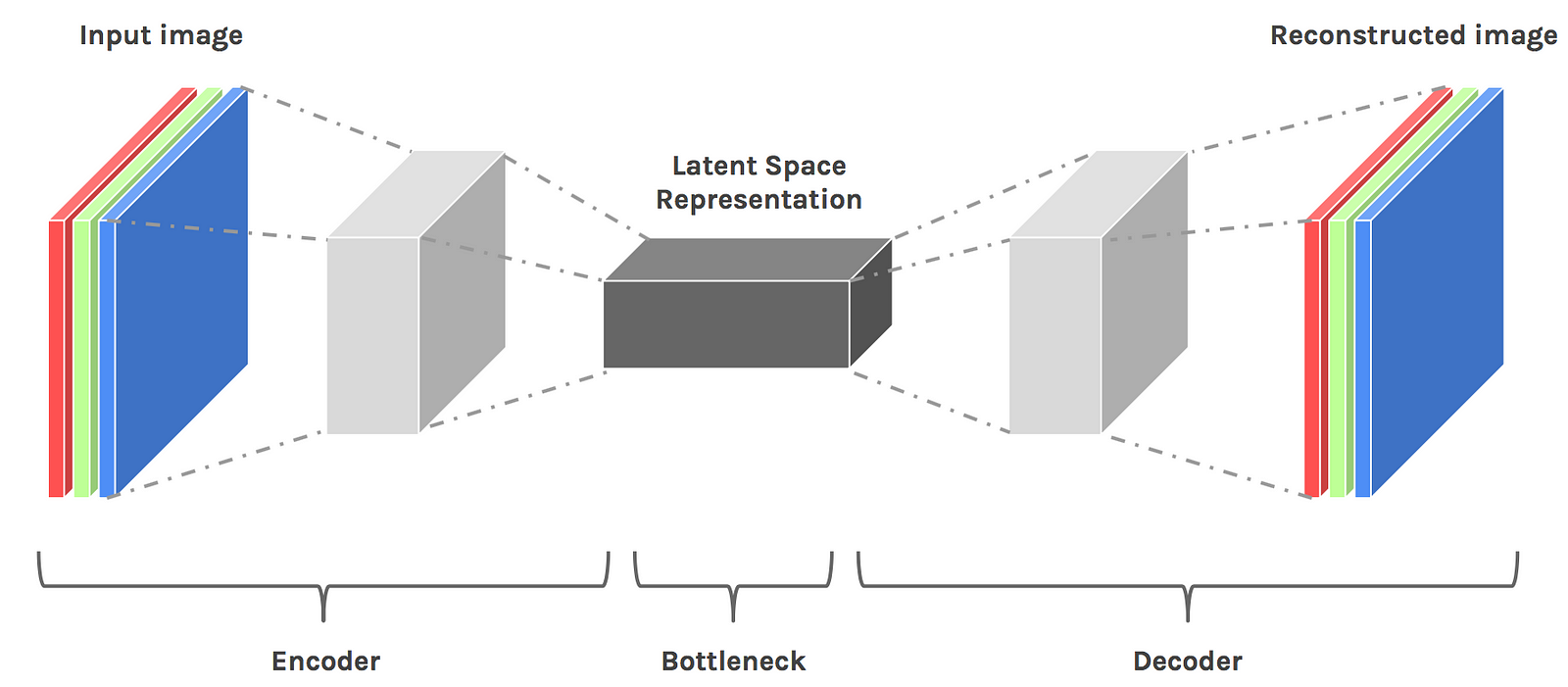
潜在変数(Noise、Latent variable)は、この自己符号化器のデコーダ(Decoder)の部分の入力であり、画像を復元、生成するための素であることがわかります。Generatorは、Decoderとほぼ役割は同じです。つまり、潜在変数(Noise)の次元というのは、自己符号化器でいうところのEncoderによってどれだけの次元になっていることにするのかに当たります。(GANにEncoderはありませんが)
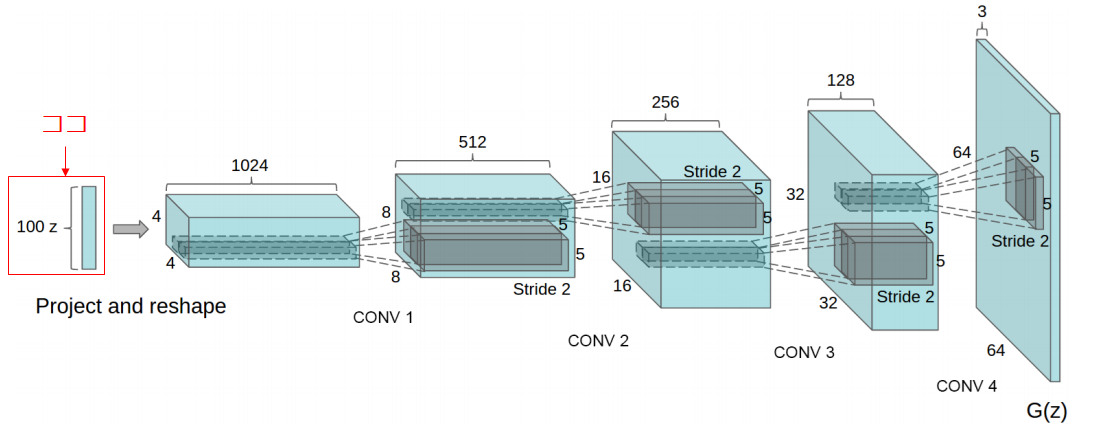
この画像から見てもわかるようにNoiseの次元というのはGeneratorの入力層の単なるノード数でしかないということがわかります。
さらに、潜在空間での潜在変数値が意味しているものに関して追加で説明をします。
これはLatent space visualization — Deep Learning bitsに詳しい説明があります。

この図の下のスライドバーは、潜在変数をスライドさせています。この様に左の椅子の潜在変数を右の椅子の潜在変数へと徐々に近づけて行くことで、生成画像も当然右の椅子に近づいて行きます。ここで、注目すべき点は生成画像も次第に近づいているという点で、ただの画像の重なり合いによって近づいているのではなく、うねうね形状が変化して近づいています。
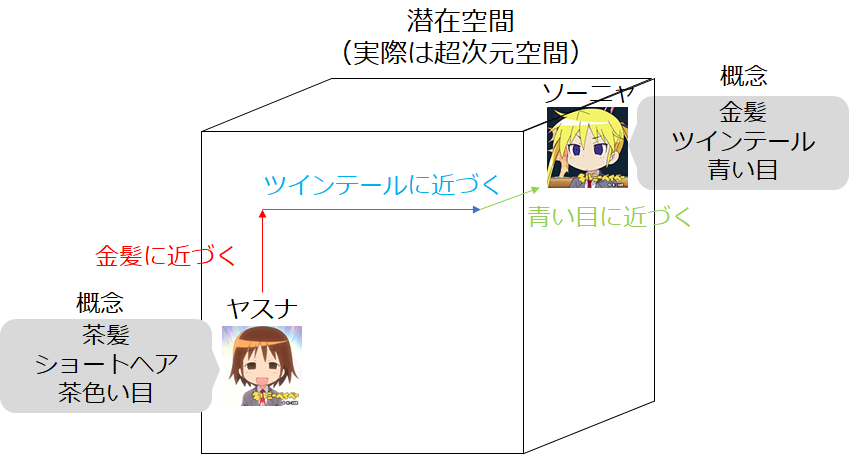
抽象的な説明になりますが、これは概念を少しずつ近づけているものだとみることができて、下の図の様に、その中間概念の椅子を取り出すことができます。左の図を見てもらうとわかるように腕掛けはなくなっていますが背もたれの形は左側の椅子のままです。また右側の図は今回使うキルミーベイベーでのイメージ図で、ヤスナの「髪色」や「髪型」、「目の色」などの概念を遷移させていくことで、ソーニャに近づいていくことを示しています。

これがただの画像の重なり合い出会った場合は、下図の様になり、某番組のアハ体験みたいな変化になります。

これが、潜在変数の遷移と単なる画像の遷移との差だと思います。
(ゆっくりですが動いてます!下のバーは動いてないですが)
さらに、この潜在変数の遷移に関して面白いことがあります。
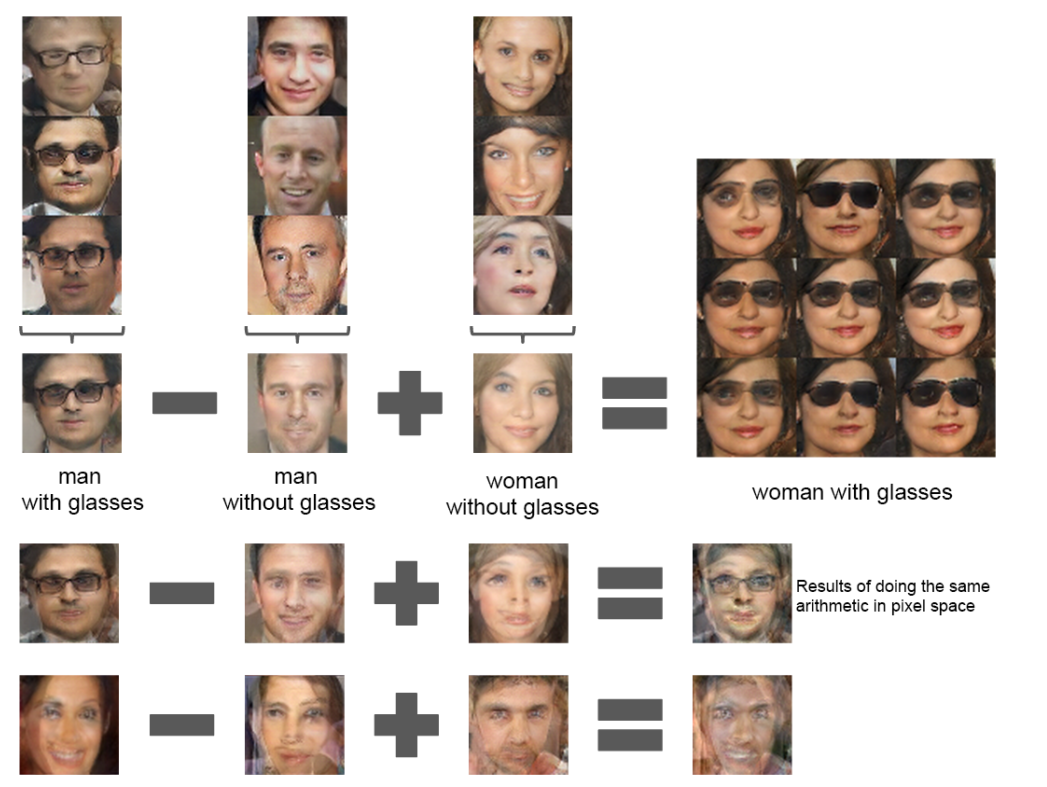
潜在空間は言わば概念みたいなもので、その中の一つのベクトルである潜在変数は一つの概念みたいなものだと解釈できます。なので、潜在変数を足したり引いたりすることで、概念の足し引きができるんです!
下の図のように、上側の潜在空間(Latent space)のベクトルを足し合わせることで、一番右のような椅子ができあがります。
図の見方の注意点としては、画像そのものを足し引きしているのではなく、潜在変数を足し引きしているという点です。

これと同様によく見られる下のような画像の説明もできます。
上の例では潜在変数の加減算、下の図は単純な画像の加減算を行っています。非常に面白いですね。
Discriminatorの仕組み
Discriminatorは単純にクラス分類を行う識別器として動作します。
入力にはGeneratorからの生成画像(Fake)とオリジナルの画像(Real)の2種類があります。
Discriminatorが行う分類は、それがFakeかRealかを判別することです。
Discriminatorの実装を見ていきましょう。
def build_discriminator(self):
img_shape = self.shape
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0, 1), (0, 1))))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
正直DiscriminatorはCNNなので、全体を通して行っていることの解説は不要だと思います。今回は2値分類なのでシグモイド関数を出力層の活性化関数に使用しています。
また、DCGANのDiscriminatorの実装では以下のような特徴があります。
・中間層以外の活性化関数にLeakyReLUを用いる
・BatchNormalizationを頻繁にいれる
・プーリング層の代わりにstride=2の畳み込み層を使う
・全結合層をなくす
これらはDCGANの論文で記載されていた学習のテクニックです。
次に、実際の学習方法について説明をします。
学習方法
Generatorの学習
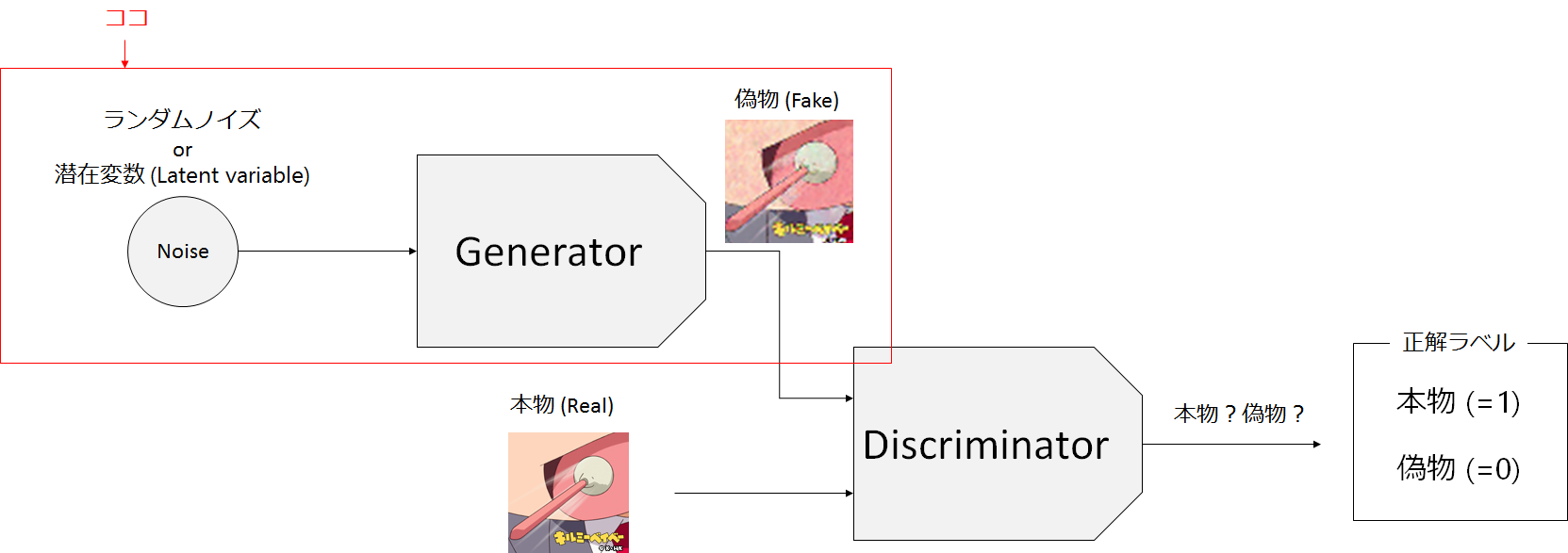
Generatorの学習では入力は、先程説明した潜在変数(Noise)、目標は「本物」か「偽物」かの正解ラベルです。画像が目標ではありません。Generatorの行いたいこととしては、Discriminatorに「本物」と判定されるような「偽物」画像を生成することです。Generatorの生成画像をDiscriminatorに入力して、本物(=1)と判定されることを目指します。
なので、Generatorの学習工程としては、下図の様にGeneratorとDiscriminatorとを組み合わせたCombined_modelを学習させることになります。
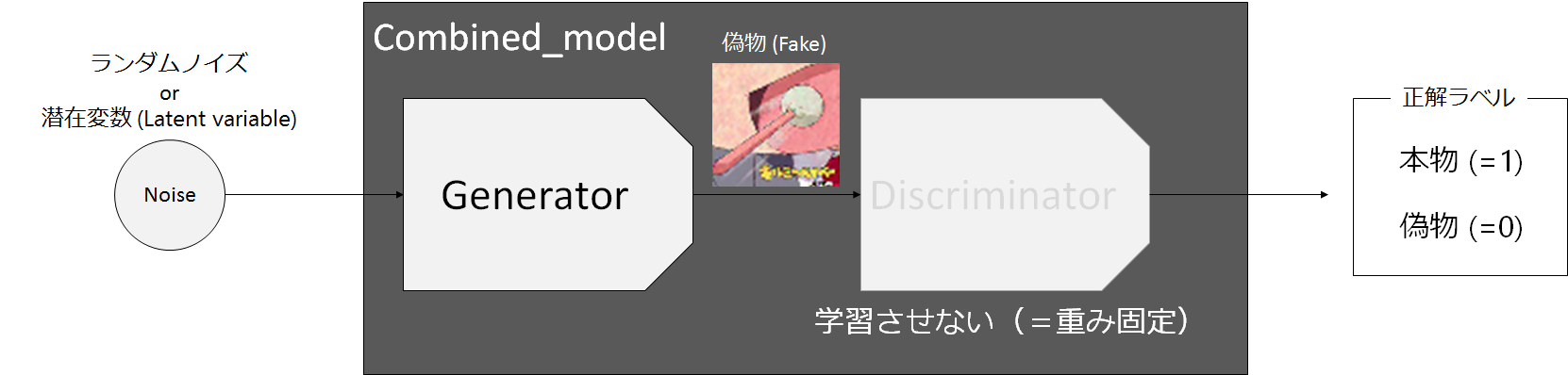
この時、Discriminatorのパラメータは固定し、Discriminatorは学習させないようにします(Generatorの学習なので当然ですね)。また、Generatorは生成画像全てが「本物」としてDiscriminatorに判断されることを望んでいるので、全ての正解ラベルは1になります。
Discriminatorの学習
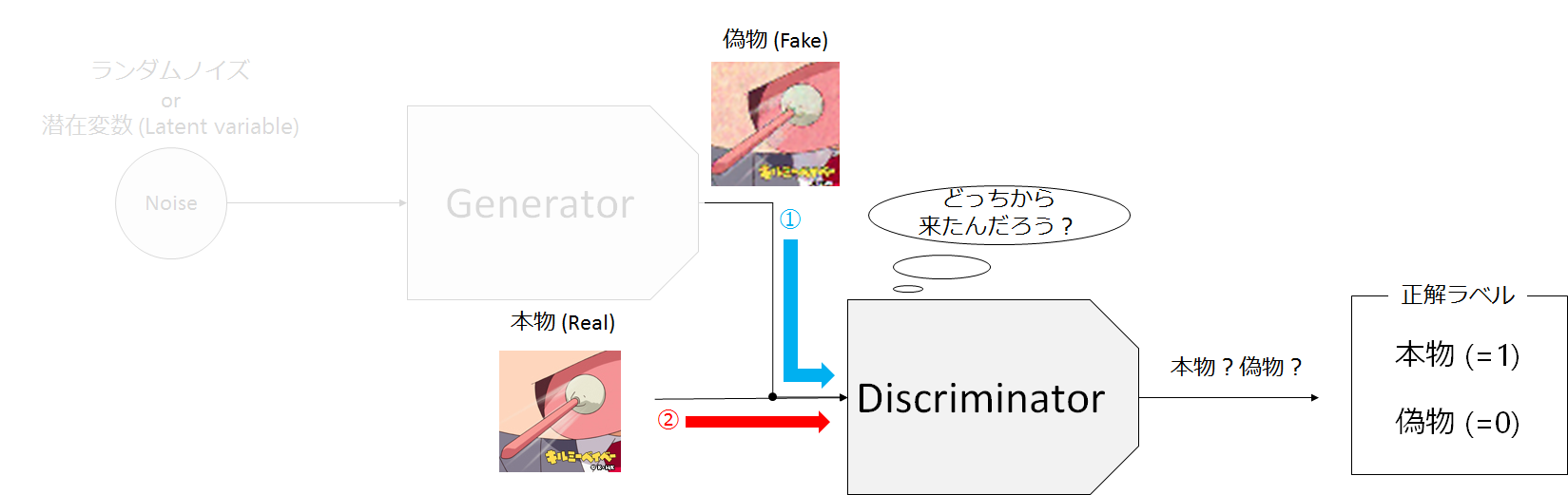
Discriminatorの学習では、ミニバッチ学習を行う場合、ミニバッチの半分を「本物」もう半分を「偽物」にして学習を行います。ただし、このミニミニバッチをミックスして学習させるのではなく、別々にミニミニバッチ学習を行います。下図でいうと-①→の矢印で偽物(Fake)の学習を行い、その次に続けて-②→の矢印から本物(Real)の学習を行います。合わせて学習させる方法もあるようですが、今回の場合DiscriminatorにはBatchNormalization層を入れているので、合わせてしまうとFakeとRealがまとめて正規化されてしまい、悪い方向に行ってしまう可能性があるので、FakeとRealを分けて学習させるほうが無難といえます。
これまでは、Discriminatorに2つの方向から入力があるように描かれていましたが、実際にDiscriminatorの入り口は一つです(ノード数の意味ではありません、データの受け入れ口の話です)。つまり、Discriminatorはどちらの方向から入力されたのかを知る術はありません。下のような図だと、データをミックスしているような気がするので避けてました。
Generatorでは、全ての正解ラベルに=1を割り当てましたが、Discriminaorは当然「本物」のみ=1、「偽物」には=0を割り当てます。
以上のことをまとめた実装が以下です。
class DCGAN():
def __init__(self):
# クラス分類用のクラス名(ついで)
self.class_names = os.listdir(root_dir)
# 入力画像サイズと潜在変数の次元
self.shape = (128, 128, 3)
self.z_dim = 100
optimizer = Adam(lr=0.0002, beta_1=0.5)
# DiscriminatorはRealかFakeを見分ける二値分類を行うためbinary_crossentropy
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
# Generator学習用のCombined_modelを作る
self.generator = self.build_generator()
z = Input(shape=(100,))
img = self.generator(z)
# Discriminatorのパラメータは固定する必要がある
self.discriminator.trainable = False
valid = self.discriminator(img)
# これでcombined_modelができあがる。入力として潜在変数(Noise)zと出力にReal(=1), Fake(=0)を取るValid
# combined_model(Generatorの学習用モデル)も二値分類を行うためbinary_crossentropy
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_combined(self):
self.discriminator.trainable = False
model = Sequential([self.generator, self.discriminator])
def train(self, epochs, batch_size=128, save_interval=50):
X_train, labels = self.load_imgs()
half_batch = int(batch_size / 2)
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
for epoch in range(epochs):
# ------------------
# Training Discriminator
# -----------------
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
noise = np.random.uniform(-1, 1, (half_batch, self.z_dim))
gen_imgs = self.generator.predict(noise)
# Discriminatorの学習をしている。
# 二行になっているのは、ミニバッチの半分はFake,もう半分はRealであるから
# このミニミニバッチを合わせて、学習するのは適切ではない
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# -----------------
# Training Generator
# -----------------
noise = np.random.uniform(-1, 1, (batch_size, self.z_dim))
# Generaterの学習をしている。
g_loss = self.combined.train_on_batch(noise, np.ones((batch_size, 1)))
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100 * d_loss[1], g_loss))
上の実装を見てもわかるように、Generatorの学習とDiscriminatorの学習は別々に行われていることがわかります。
↓この部分です。
# Discriminatorの学習をしている。
# 二行になっているのは、ミニバッチの半分はFake,もう半分はRealであるから
# このミニミニバッチを合わせて、学習するのは適切ではない
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
# Generaterの学習をしている。
g_loss = self.combined.train_on_batch(noise, np.ones((batch_size, 1)))
キルミーベイベー生成
実際にキルミーベイベー画像を生成した結果を示します。
ちなみにオリジナルの画像はこんな感じです。すみません、私の技術不足で、どの画像を生成したのかわからなかったので、それっぽいのを適当においています。






結果
iteration = 0 iteration = 1000
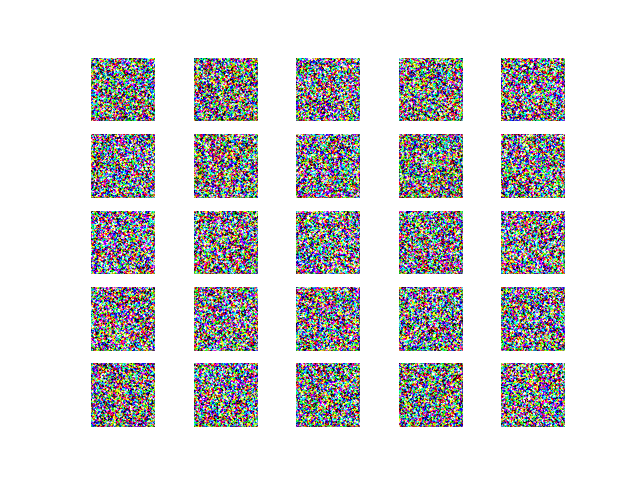

iteration = 10000 iteration = 25000


iteration = 49000

GANの学習難しいですね・・・それっぽいものはできていますがグニャグニャです・・・
潜在変数を動かす
潜在変数をスライドさせると画像が徐々に近づいていくみたいなことを話しました。
ここでも、同様のことを行い、横に並べてみました。
結果の1枚目と2枚目との間の潜在変数を10区間に分けて、それぞれに対して画像を生成しました。
この可視化は、このサイトの実装を参考に行っています。
左のヤスナっぽいものからソーニャっぽいものへとだんだん変わってますね。
イテレーション毎に結果を示します。1イテレーションは50サンプルです。
iteration = 0

iteration = 1000

iteration = 10000

iteration = 25000

iteration = 49000

全実装
こちらに全てのコードとデータセットをまとめています。
git clone https://github.com/taku-buntu/Killme_DCGAN.git
して、kill_me_baby_datasets.rarファイルをその場で解凍(unrar)すれば、そのまま
python3 dcgan.pyで実行できます。
まとめ
GANの基本的な説明からキルミーベイベーデータセットからのキルミー生成まで行いました。
この記事を書いていく中で、一番興味深かったのは潜在空間についてです。
ノイズってなんだろな、ノイズの値って生成画像にどう関係しているんだろうなと言ったような考察を進めることにつながりました。近年のGANの発展は凄まじいです。それだけ注目されているんだろうなと思います。
本記事で少しでも、皆様の理解につながれば幸いです。