はじめに
書籍:すぐに使える! 業務で実践できる! Pythonによる AI・機械学習・深層学習アプリのつくり方 について
章ごとのポイントをまとめていきます。また、サンプルの実行と+αのサンプルを最後に載せています。
今回は2章で、ライブラリ部分を中心に触っていきます。
2-1 一番簡単な機械学習を実践しよう
scikit-learnについて
Python![]() 向けの機械学習フレームワーク
向けの機械学習フレームワーク
特徴
- 様々なアルゴリズムに対応
- すぐに機械学習を試せるサンプルデータを含んでいる
- PandasやNumpyMatplotlib
 等の親和性が高い
等の親和性が高い -
無料で商用利用可能

AND演算
| 入力 X | 入力 Y | 出力 Z (X and Y) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
ゴールの決定
はじめに、どのような機械学習プログラムを作成するかゴールを決める。
今回は次のような、教師あり学習の機械学習プログラムを作成する。
- 入力と出力のすべてのパターンを学習させる(上記表より4パターン)
- 4パターンいずれかの入力で正しい出力が返ってくるか評価する
アルゴリズムの選択
ゴールが決まったので、アルゴリズムを選択していく。
そこで、「どんなアルゴリズムがあるの?」 ![]() 、 「どんなときに、どのアルゴリズムが最適解なの?」
、 「どんなときに、どのアルゴリズムが最適解なの?」 ![]() といった
といった (越えられない) 壁が存在する。
そのような場合には、アルゴリズムチートシートを参考に決定することができる。
【機械学習初心者向け】scikit-learn「アルゴリズム・チートシート」の全手法を実装・解説してみた
今回のパターンは・・・
- カテゴリの予測
- ラベルを持っている
- データが10万より少ない
以上より、LinearSVCというアルゴリズムに決定。
実装
以下のコードをJupyter Notebookで実装する。
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
# input data X,Y
learn_data = [[0,0],[0,1],[1,0],[1,1]]
# Result Label
learn_label = [0, 0, 0, 1]
# Specified algorism( LinearSVC )
clf = LinearSVC()
# Learning ( input, label )
clf.fit(learn_data, learn_label)
# test
test_data = [[0,0],[0,1],[1,0],[1,1]]
test_label = clf.predict(test_data)
# Result
print(test_data , "の予測結果:", test_label)
print("正解率 = " , accuracy_score([0, 0, 0, 1], test_label))
Runボタンで結果を確認してみる。
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-2-36fc46ae7200> in <module>()
----> 1 from sklearn.svm import LinearSVC
2 from sklearn.metrics import accuracy_score
3
4 # input data X,Y
5 learn_data = [[0,0],[0,1],[1,0],[1,1]]
ImportError: No module named 'sklearn'
anacondaの仮想環境を作り、そこですぐ実行したため、モジュールがなかったみたい。
そのため、モジュールをインストール
pip install scikit-learn
そして実行してみる。
[[0, 0], [0, 1], [1, 0], [1, 1]] の予測結果: [0 0 0 1]
正解率 = 1.0
正解率が1.0のため、LinearSVCアルゴリズムによってAND演算の機械学習を実装できた。
改良する
ここで正解率が0.3や0.42などで優れなかった場合はどうするか。
その場合は、以下のどちらかのアプローチをとることになる。
- アルゴリズムはそのままで、アルゴリズムに指定するパラメーターを調整する
- アルゴリズムを変更する
ここでは、アルゴリズムを変更するを選択してみる。
チートシート![]() から、LinearSVCがうまくいかない場合に、
から、LinearSVCがうまくいかない場合に、
いくつか選択肢があり、その中から、KneighborsClassifierを試してみる。
変更箇所は上記のプログラムのインポートとアルゴリズムの指定部分のみ。
from sklearn.neighbors import KNeighborsClassifier
# Specified algorism( KNeighborsClassifier )
clf = KNeighborsClassifier(n_neighbors = 1)
実行結果
[[0, 0], [0, 1], [1, 0], [1, 1]] の予測結果: [0 0 0 1]
正解率 = 1.0
テストの結果が優れない場合は、アルゴリズムやパラメーターを調整していく。
それらはインポートするパッケージやオブジェクトの生成部分を変更するだけで、
手軽にアルゴリズムを変更できる。
2-2 アヤメの分類に挑戦してみよう
「Fisherのアヤメデータ」と呼ばれる有名な品種分類データを利用して、機械学習に挑戦します。
これから分類するものが、何かというくらいは最低限知っておきましょう。(どんな花かぼくはまったく知らなry)
アヤメデータのダウンロードと確認
以下URLよりアヤメデータをダウンロードする。
ヘッダー(がく片の長さや花びらの幅)とそれに対するデータがずらっと入っているみたいです。
JupyterNotebook上で確認してみます。
import urllib.request as req
import pandas as pd
# Download File
url = "https://github.com/pandas-dev/pandas/raw/master/pandas/tests/data/iris.csv"
save_file = "iris.csv"
req.urlretrieve(url, save_file)
print("Save successful")
# Open File
csv = pd.read_csv(save_file, encoding="utf-8")
csv
このデータを使って教師あり学習を行っていきます。
アヤメデータを使って機械学習してみる
- 手順
- データ取り込み
- データ部とラベル部に分離
- 全データのうち、80%を学習用に、20%をテスト用に分離
- 学習データで学習後、テスト用データを与えた時に、正しく分類するか評価
アルゴリズムの選択
SVCアルゴリズム
理由:1回も使ってないから、試しにね。
実装
import urllib.request as req
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Open File
iris_csv = pd.read_csv( "iris.csv" , encoding="utf-8")
# Separation into label and input
y = iris_csv.loc[:,"Name"]
x = iris_csv.loc[:,["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
# Separation into Learning and Test
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
# Learning
clf = SVC()
clf.fit(x_train, y_train)
# Evaluation
y_pred = clf.predict(x_test)
print("正解率 = ", accuracy_score(y_test, y_pred))
実行結果
正解率 = 0.9666666666666667
これまでに使用したメソッドの整理
上記ソースコードで使用したメソッドたちを整理しときます。
| 分類 | ライブラリ | メソッド名 |
|---|---|---|
| データ読み込み | Pandas | read_csv() |
| データ分離(列) | Pandas | loc() |
| データ分離(行) | scikit-learn | train_test_split() |
| 学習 | scikit-learn | fit() |
| 予測 | scikit-learn | predict() |
| 正解率の計算 | scikit-learn | accuracy_score() |
2-3 AIで美味しいワイン を判定しよう
を判定しよう
ワインの美味しさは、成分を調べるおとで判別できるといわれているそうです。
そこで、ワインの成分からランクを判定するプログラムを作ってみます。![]()
ワインデータのダウンロードと確認
機械学習の練習で使えるデータは、「UCI Machine Learning Repository」で多く公開されており、
そこにワインデータもあります。
from urllib.request import urlretrieve
import pandas as pd
url = "https://archive.ics.uci.edu"+ \
"/ml/machine-learning-databases/wine-quality" + \
"/winequality-white.csv"
save_file = "winequality-white.csv"
urlretrieve(url, save_file)
df = pd.read_csv(save_file, sep = ";", encoding ="utf-8")
df
11種類の成分表と、ワイン専門家によるワインの品質データからなっています。
qualityは0~10で10に近いほど品質がいいことを示しています。
アルゴリズムの決定
ランダムフォレスト
理由:1回も使ってないから、試しにね。
実装
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
# Read Data
wine = pd.read_csv("winequality-white.csv", sep = ";", encoding = "utf-8")
# Separation into label and input
y = wine["quality"]
x = wine.drop("quality", axis=1)
# Separation into Learning and Test
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
# Learning
model = RandomForestClassifier()
model.fit(x_train, y_train)
# Evaluation
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))
print("正解率 = ", accuracy_score(y_test, y_pred))
実行結果
precision recall f1-score support
3 0.00 0.00 0.00 3
4 0.67 0.29 0.41 34
5 0.66 0.67 0.66 291
6 0.63 0.74 0.68 435
7 0.64 0.50 0.56 174
8 0.74 0.33 0.46 42
9 0.00 0.00 0.00 1
micro avg 0.64 0.64 0.64 980
macro avg 0.48 0.36 0.40 980
weighted avg 0.64 0.64 0.63 980
正解率 = 0.6408163265306123
この値は実行するたびに、多少変動する。
それは、データを学習用とテスト用に分割するため、どのデータを学習したかによって、多少の誤差が生じるから。
プログラムでデータをラベルとデータに分離しているとこがありますが、
ラベル部分は目的変数、データ部分は説明変数といいます。この用語はよく出てくるので、覚えておきましょう。
精度向上に向けて
ワインデータ(入力データ)を可視化し、確認してみます。
実装
import matplotlib.pyplot as plt
import pandas as pd
# Read Data
wine = pd.read_csv("winequality-white.csv", sep=";", encoding ="utf-8")
# Count Data
count_data = wine.groupby('quality')["quality"].count()
print(count_data)
# Draw Graph
count_data.plot()
plt.savefig("wine-count-plt.png")
plt.show()
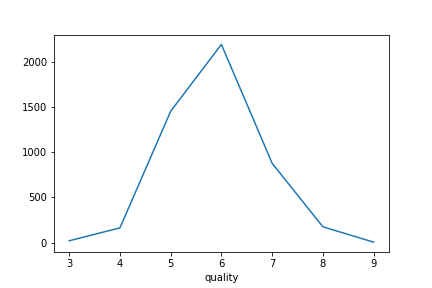
このような感じで、簡単にデータをグラフ![]() にプロットすることができます。
にプロットすることができます。
このデータは3~9の範囲で値をとっており、2以下と10は存在しません。
このような、データ数の分布数の差があるデータを不均衡データといいます。
そのため、ラベルを3段階に振り直してみます。
- ラベルの振り直し
- 4以下
- 5~7
- 8以上
再実装
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
# Read Data
wine = pd.read_csv("winequality-white.csv", sep = ";", encoding = "utf-8")
# Separation into label and input
y = wine["quality"]
x = wine.drop("quality", axis=1)
# Renumber the label
newlist = []
for i in list(y):
if i <= 4:
newlist += [0]
elif i <=7:
newlist += [1]
else:
newlist += [2]
y = newlist
# Separation into Learning and Test
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
# Learning
model = RandomForestClassifier()
model.fit(x_train, y_train)
# Evaluation
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))
print("正解率 = ", accuracy_score(y_test, y_pred))
実行結果
precision recall f1-score support
0 0.64 0.25 0.36 36
1 0.95 0.99 0.97 907
2 0.94 0.41 0.57 37
micro avg 0.94 0.94 0.94 980
macro avg 0.84 0.55 0.63 980
weighted avg 0.94 0.94 0.93 980
正解率 = 0.9438775510204082
ラベルの分類を減らすことで精度を向上させることができました。
MEMO
どんなデータをどのように分類しようとしているのか調べて、ちょっとデータを変形・整形することで
精度を向上させることができることがわかりました。
COLUMN
ランダムフォレストについて![]()
ランダムフォレストは複数の分類器を用いて性能を向上させるアンサンブル学習法の一つです。
学習用のデータをサンプリングして多数の決定木を作成し、作成した決定木をもとに
多数決で結果を決める手法から、「ランダムフォレスト」と呼ばれています。
2-4 過去10年間の気象データを解析してみよう
気象庁のアメダスデータから、データの解析と明日の気温予測に挑戦します。![]()
![]()
![]()
データの取得
過去の気象データ
ここから、大阪の10年分の平均気温を取得します。
取得期間:2007/1/1~2017/12/31
不要なヘッダーを削除し、(1,2,3,5行)
日付を、年・月・日に分解し、新たなcsvファイルを作ります。
input_file = "osaka_data.csv"
output_file = "temperature_10years.csv"
# Read line
with open(input_file, "rt", encoding="Shift_JIS") as fr:
lines = fr.readlines()
# New header
lines = ["年,月,日,気温,品質,均質\n"] + lines[5:]
lines = map(lambda v: v.replace('/', ','), lines)
result = "".join(lines).strip()
print(result)
# Output
with open(output_file, "wt", encoding="utf-8") as fw:
fw.write(result)
print("saved.")
各月の平均気温を調べてみる
まずは、データを見ることからはじめます。
実装
import matplotlib.pyplot as plt
# import matplotlib
import pandas as pd
# Read file
df = pd.read_csv("temperature_10years.csv", encoding ="utf-8")
# Average of Month
group = df.groupby(['月'])["気温"]
ave_group =group.sum() / group.count()
# Output Result
print(ave_group)
ave_group.plot()
plt.savefig("average_month_temperature.png")
plt.show()
# print(matplotlib.rcParams['font.family'])
# print(matplotlib.matplotlib_fname())
# print(matplotlib.get_configdir())
コメントアウトしている行はグラフの軸ラベルが文字化けしたため(□←こんなやつに)
解決するために、使用したコードです。
文字化けの解決に参考にしたサイト
matplotlib出力画像の文字化け解消法
実行結果
月
1 5.996736
2 6.708682
3 9.837537
4 15.024848
5 20.090323
6 23.526364
7 27.775953
8 29.103226
9 25.138485
10 19.594135
11 13.619394
12 8.375660
Name: 気温, dtype: float64
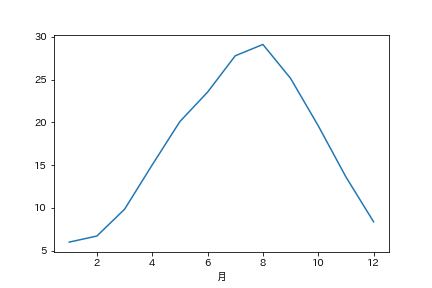
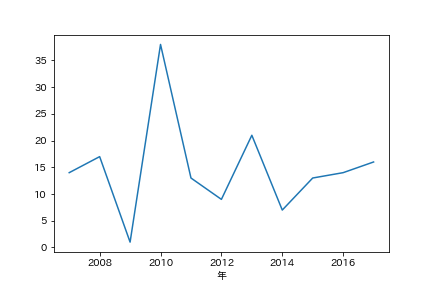
真夏日の日数を調べてみる -Pandasでフィルタリング-
同様の手法を用いて、真夏日(平均気温が30度以上)の日が、各年に何回あったのか調べてみます。
実装
import matplotlib.pyplot as plt
import pandas as pd
# Read File
df =pd.read_csv("temperature_10years.csv", encoding = "utf-8")
# Research Data over 30
is_hot = (df["気温"] > 30)
# Fill Data
hot_data = df[is_hot]
# Count
count_data = hot_data.groupby(["年"])["年"].count()
# Output
print(count_data)
count_data.plot()
plt.savefig("over30.png")
plt.show()
実行結果
年
2007 14
2008 17
2009 1
2010 38
2011 13
2012 9
2013 21
2014 7
2015 13
2016 14
2017 16
Name: 年, dtype: int64
回帰分析による明日の気温予測
本題の予測に入っていきます。
2016年までのデータを学習データとし、2017年をテストデータとします。
7日間の過去データを入れると、翌日の気温を予測するプログラムです。
実装
from sklearn.linear_model import LinearRegression
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Read File
df =pd.read_csv("temperature_10years.csv", encoding = "utf-8")
# Split Data
train_years = (df["年"] <= 2016)
test_year = (df["年"]>=2017)
interval = 7
# Learning Data
def make_data(data):
x = [] #Learning Data
y = [] # Result
temps = list(data["気温"])
for i in range(len(temps)):
if i <= interval: continue
y.append(temps[i])
xa = []
for j in range(interval):
d = ( i + j ) - interval
xa.append(temps[d])
x.append(xa)
return (x, y)
train_x, train_y = make_data(df[train_years])
test_x, test_y = make_data(df[test_year])
# Linear regression analysis
lr = LinearRegression(normalize=True)
lr.fit(train_x, train_y)
pre_y = lr.predict(test_x)
# Output
plt.figure(figsize=(10, 6), dpi=100)
plt.plot(test_y)
plt.plot(pre_y,linestyle="dashed")
plt.savefig("LinearRegression.png")
plt.show()
実行結果
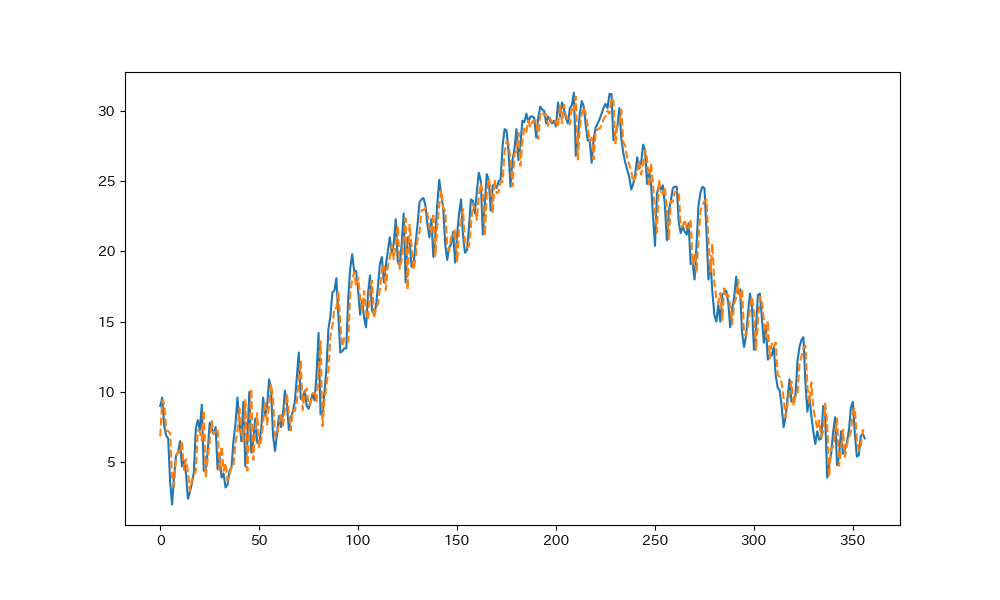
青色が実測のデータで、オレンジの破線が予測値です。
いい感じに重なっているので、誤差の確認をしてみます。
結果の評価
下記コードを新規セルに入力し、全体の誤差と最大誤差を確認する。
diff_y = abs(pre_y - test_y)
print("average = ", sum(diff_y) / len(diff_y))
print("max = ",max(diff_y))
average = 1.2037169855638823
max = 5.204742626546912
Points
ここで、過去7日間のデータを説明変数xとし、
翌日の気温を目的変数yとしました。
ここの目的変数を、別の要素に指定するなら、様々な予測プログラムに応用することができます。
2-5 最適なアルゴリズムやパラメーターを見つけよう
2-2のアヤメデータの分類では、SVCアルゴリズムを用いたが、「①他にもっと高い正解率を出せるアルゴリズムがあるんじゃないの?」![]()
**「②データの学習方法をいろんなパターンでやっても安定した結果を得られるの?」![]() **といったことが気になるところ。
**といったことが気になるところ。
そこで、この2つについては次のような解決策があります。
-
解決策
- ①について・・・各アルゴリズムの正解率を比較する
- ②について・・・クロスバリデーション
① 最適なアルゴリズムを見つける -各アルゴリズムの正解率を比較-
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import warnings
from sklearn.utils.testing import all_estimators
# Open File
iris_csv = pd.read_csv( "iris.csv" , encoding="utf-8")
# Separation into label and input
y = iris_csv.loc[:,"Name"]
x = iris_csv.loc[:,["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
# Separation into Learning and Test
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
# Get All Algorith
warnings.filterwarnings('ignore')
allAlgorithms = all_estimators(type_filter ="classifier")
for(name, algorithm) in allAlgorithms:
#Create Object
clf = algorithm()
#Learning and Evaluation
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print(name,"の正解率 = ", accuracy_score(y_test, y_pred))
実行時にFutureWarning(将来変更される予定であることを示す警告)などの警告が表示されるため、
結果を見やすくするために、非表示にしています。
AdaBoostClassifier の正解率 = 1.0
BaggingClassifier の正解率 = 1.0
BernoulliNB の正解率 = 0.3
CalibratedClassifierCV の正解率 = 0.9666666666666667
ComplementNB の正解率 = 0.6666666666666666
DecisionTreeClassifier の正解率 = 0.9666666666666667
ExtraTreeClassifier の正解率 = 1.0
ExtraTreesClassifier の正解率 = 1.0
GaussianNB の正解率 = 1.0
GaussianProcessClassifier の正解率 = 0.9666666666666667
GradientBoostingClassifier の正解率 = 1.0
KNeighborsClassifier の正解率 = 1.0
LabelPropagation の正解率 = 1.0
LabelSpreading の正解率 = 1.0
LinearDiscriminantAnalysis の正解率 = 1.0
LinearSVC の正解率 = 1.0
LogisticRegression の正解率 = 1.0
LogisticRegressionCV の正解率 = 0.9666666666666667
MLPClassifier の正解率 = 1.0
MultinomialNB の正解率 = 1.0
NearestCentroid の正解率 = 0.9666666666666667
NuSVC の正解率 = 0.9666666666666667
PassiveAggressiveClassifier の正解率 = 0.7666666666666667
Perceptron の正解率 = 0.3333333333333333
QuadraticDiscriminantAnalysis の正解率 = 1.0
RadiusNeighborsClassifier の正解率 = 0.9666666666666667
RandomForestClassifier の正解率 = 1.0
RidgeClassifier の正解率 = 0.9666666666666667
RidgeClassifierCV の正解率 = 0.9666666666666667
SGDClassifier の正解率 = 0.6666666666666666
SVC の正解率 = 1.0
クロスバリデーションについて
複数のデータパターンで評価した場合でも、安定した結果を得られるにはどうすればいいか。
という時に**クロスバリデーション(cross-validation)を利用することができる。
クロスバリデーションはアルゴリズムの妥当性を評価する手法の一つで、「交差検証」**とも呼ばれています。
クロスバリデーションにもいくつか手法があるが、ここでは
k分割クロスバリデーションにより、評価してみる。
K-分割交差検証
K-分割交差検証では、標本群をK個に分割する。そして、そのうちの1つをテスト事例とし、残る K − 1 個を訓練事例とするのが一般的である。
https://ja.wikipedia.org/wiki/%E4%BA%A4%E5%B7%AE%E6%A4%9C%E8%A8%BC
-
k分割クロスバリデーションの手順例
- データをA・B・Cの3グループに分割する
- AとBを学習用データ、Cを評価用データとして、正解率を求める
- BとCを学習用データ、Aを評価用データとして、正解率を求める
- CとAを学習用データ、Bを評価用データとして、正解率を求める
実装
import pandas as pd
from sklearn.utils.testing import all_estimators
from sklearn.model_selection import KFold
import warnings
from sklearn.model_selection import cross_val_score
# Open File
iris_csv = pd.read_csv( "iris.csv" , encoding="utf-8")
# Separation into label and input
y = iris_csv.loc[:,"Name"]
x = iris_csv.loc[:,["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
# Get All Algorith
warnings.filterwarnings('ignore')
allAlgorithms = all_estimators(type_filter ="classifier")
# K-fold cross validation
kfold_cv = KFold(n_splits=5, shuffle=True)
for(name, algorithm) in allAlgorithms:
# Create Object
clf = algorithm()
# score method only
if hasattr(clf,"score"):
#cross validation
scores = cross_val_score(clf, x, y, cv=kfold_cv)
print(name, "の正解率= ")
print(scores)
実行結果
AdaBoostClassifier の正解率=
[0.96666667 0.9 0.93333333 0.93333333 1. ]
BaggingClassifier の正解率=
[0.9 1. 1. 0.86666667 1. ]
BernoulliNB の正解率=
[0.2 0.23333333 0.26666667 0.23333333 0.3 ]
CalibratedClassifierCV の正解率=
[0.93333333 0.83333333 0.96666667 0.93333333 0.96666667]
ComplementNB の正解率=
[0.7 0.73333333 0.56666667 0.66666667 0.66666667]
・・・
クロスバリデーションを行うには、score()メソッドを持っていることが前提のため、
その確認が必須となる。
最適なパラメータを見つける
これまでは、アルゴリズムのパラメータをデフォルトにしてきたが、
それぞれ設定することができる。
そのようなパラメータはハイパーパラメータと呼ばれ、
グリッドサーチという手法により、最適なパラメータを探してみる。
グリッドサーチについて
グリッドサーチは、ハイパーパラメータのチューニング手法の一つで、指定したパラメータの全パターンについて、正解率を比較する手法です。
実装
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.model_selection import GridSearchCV
# Open File
iris_csv = pd.read_csv( "iris.csv" , encoding="utf-8")
# Separation into label and input
y = iris_csv.loc[:,"Name"]
x = iris_csv.loc[:,["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
# Separation into Learning and Test
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2,
train_size = 0.8, shuffle = True)
# Specified Parameter
parameters = [
{"C":[1, 10, 100, 1000], "kernel":["linear"]},
{"C":[1, 10, 100, 1000], "kernel":["rbf"], "gamma":[0.001, 0.0001]},
{"C":[1, 10, 100, 1000], "kernel":["sigmoid"], "gamma":[0.001, 0.0001]}
]
# Grid Search
kfold_cv = KFold(n_splits=5, shuffle=True)
clf = GridSearchCV(SVC(), parameters, cv = kfold_cv)
clf.fit(x_train, y_train)
print("最適なパラメータ = ", clf.best_estimator_)
# Elevation
y_pred = clf.predict(x_test)
print("評価時の正解率 = ", accuracy_score(y_test, y_pred))
実行結果
最適なパラメータ = SVC(C=1, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='linear', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
評価時の正解率 = 1.0
何回か実行すると 1.0 になりました。
これにより、最適なパラメータと、そのパラメータを用いた場合の結果が表示されました。
これのほか、ハイパーパラメータのチューニングには、ランダムサーチという手法がある。
scikit-learnでは、GridSearchCVをRandomizedSearchCVオブジェクトに変えることで、ランダムサーチになる。
まとめ
この章ではアルゴリズムの選択に、チートシートを使うことを学んだ。
また、分類したいといった目的があった時に、様々なアルゴリズムを使用して予測できることがわかった。
そして、グラフの描画方法や最適なアルゴリズムの選択方法も学んだ。
Next![]()
次章は、OpenCVを用いた画像や動画の分析に入っていきます。
+α
全章投稿後に、復習をかねて実装予定