今回作るもの
文章中の情報(キーとなる単語)を抽出する「エンティティ抽出」 を、チャットボット開発フレームワークである Rasa Open Source を用いて実現する方法を解説します。
具体例として、外食に関する文章に対して、以下のような各種情報を抽出するものを作ります。

概要
冒頭の例のような形で、Rasaを用いてエンティティ抽出 をする方法です。
文章からの情報抽出は、自然言語処理の基本であり重要な機能ですよね。
チャットボットであれば、抽出した情報に基づいて、予約・登録等の処理やレコメンド・情報提供をしていく訳なので、キーとなる機能になります。
今回は 自前で訓練データを作成してモデルを作成する 方法を取ります。
GiNZAのように、学習済みのエンティティ抽出を提供するライブラリもありますが、学習済みモデルは汎用的な用途であるため、冒頭に記載したような特定の文脈での使用には向きません。(GiNZAの学習済みモデルで抽出可能なエンティティは、人名、組織名、地名、日付などです 1)
また、どの程度訓練データが必要なのかを調べる簡単な実験もしてみました。
タスクによって異なる部分も多いとは思いますが、ちょっとした参考になりましたら幸いです。
対象読者
- 自然言語処理の初学者
- エンティティ抽出について知りたい方
- チャットボット開発フレームワークRasaに興味がある方
内容目次
- エンティティ抽出 とは?
- Rasa とは?
- Rasaを用いてエンティティ抽出
- Rasaのインストール
- エンティティ抽出の訓練と推論
- 訓練サンプルと精度の関係を見てみる
(a) サンプル数
(b) 文章の種類
(c) エンティティの種類
ソースコード
コードの詳細は、こちらのNotebookをご参照ください。
実行環境は、Google Colaboratoryを想定しています。
Google Colaboratoryで開く場合はこちらから。
エンティティ抽出 とは?
エンティティ(entity) とは 「(文章内にある) 特定の情報」 といった意味です。
具体的には、特定の人名、地名、組織名などの固有名詞、金額表現、電話番号、日付、年齢などです。それ以外にも、アプリケーションで必要な情報全般を指します。
チャットボットでの例をあげると、
「明日の18時から、3名で予約したい」という文章には、
- 日付:明日
- 時刻:18時
- 人数:3名
という3種類のエンティティが存在する、という具合です。
「エンティティ抽出」という呼び名以外に、「固有表現抽出」、「NER (Named Entity Recognition)」、「コンセプト抽出」とも呼ばれます。
呼び名による違いは特にないと思っていますが、チャットボットの文脈では、エンティティ抽出やコンセプト抽出、それ以外のNLP全般では、固有表現抽出、NERと呼ばれているように思います。
実装としては、トークナイズ(Tokenize、分かち書き)された、各Tokenに対してエンティティ種別を推定 しています。前述の例の場合、
明日 / の / 18時 / から / 3名 / で / 予約 / し / たい
のそれぞれのTokenがどのエンティティに当たるか(もしくは、非エンティティか)を推定します。
具体的な推定アルゴリズムは複数ありますが、今回は、CRF(Conditional Random Field、条件付き確率場)を用います。BERT等のDeepLearningを用いた手法もあります。
Rasa とは?
Rasa Open Source は、Pythonで作られたチャットボット開発フレームワーク です。
会話するための機能一式(文章理解、対話管理、文章生成)や、チャネル(例: Facebook Messenger)とのコネクタを提供してくれています。
GitHubでソースコードが公開されています。Apache-2.0 licenseです。
チャットボットというと、Googleの「Dialogflow」が有名かと思います。DialogflowがGUIで誰でも簡単に使用できるのに対して、Rasaはカスタム性が高く、どちらかというとエンジニア向け という印象です。設定ファイルを編集することで内部のアルゴリズムを選択できたり、コードを書くことで機能を拡張できたりします。
今回はエンティティ抽出を単体で使用したく、その目的では比較的使いやすそうだったのでRasaを試してみました。
ただ、大型アップデートが頻繁にあり(2021年11月〜 3.x系、2020年10月〜 2.x系)、それに起因するハードルの高さはあります。ただでさえ日本語記事は少ないのですが、1年前の記事でも情報が古い場合があるため、基本的には、公式リファレンスを読む必要があります。
主にエンティティ抽出に関連するものですが、今回参考になった記事を末尾の参考文献に挙げています。参考になりましたら幸いです。
特に、公式ブログの "Bending the ML Pipeline in Rasa 3.0" (2021.10.27) という記事がオススメです。Rasaのv0.x〜v3.0の設計思想の変遷について、各メジャーバージョンでの違いを説明してくれています。最新バージョンの設計の意図を知ることで、理解しやすくなると思いますので、Rasaを学ぶ際には一読するとよいかなと思います。
(補足ですが、GiNZA(spaCy)でも、エンティティ抽出のモデルを訓練することは可能です。2 チャットボットにあまり興味がない方は、GiNZAを使用する方がよいかもしれません。)
Rasaを用いてエンティティ抽出してみる
冒頭の例のように、外食に関する文章を受け取り、以下の5種類の情報を抽出してみます。
- いつ … 例)昨日, 明日
- どこに … 例)渋谷, 新宿
- 誰と … 例)友人, 姉
- 何を(ジャンル) … 例)中華, イタリアン
- 何を(料理名) … 例)坦々麺, パスタ
それでは、具体的な内容に入っていきましょう!
Rasaのインストール
pipでインストール可能です。
今回は、GiNZAの日本語モデル(ja-ginza)を使用したいので、一緒にインストールしておきます。
# Rasa と GiNZA をインストール (@Google Colaboratory)
# Rasaの内部でspacyを使用する際の言語モデルも一緒にインストール ( ja-ginza : GiNZAの日本語モデル )
! pip install rasa==3.2.8 ja-ginza==5.1.2
エンティティ抽出の使用方法
Rasaを使用するためには、パイプラインの設定ファイル が必要です。
また、今回はモデル訓練を行うので、訓練データを記載したファイル も必要になります。
訓練および推論は、以下の手順で実施していきます。
- 訓練
-
rasa.model_training.train_nlu()でモデルを訓練
-
- 推論
-
rasa.core.agent.Agentクラスを生成 -
Agent.load_model()により、訓練済みモデルを読込 -
Agent.parse_message()で文章を解析
-
訓練
(1)パイプライン設定ファイル、(2)訓練データファイルを作成します。
(1) パイプライン設定ファイル
pipelineの要素に、使用する機能要素を列挙していきます。
本記事のメインであるエンティティ抽出は、末尾のCRFEntityExtractorです。
また、今回はGiNZAの日本語モデルを使用したいので、SpacyNLPにmodel:ja_ginzaを指定しています。
なお、SpacyFeaturizerとRegexFeaturizerは、エンティティ抽出で使用される特徴抽出器です。前者はSpacyNLPの言語モデル(ここでは、ja_ginza)による特徴抽出を、後者は訓練サンプルに基づいた正規表現による特徴抽出を実施してくれるようです。
recipe: default.v1
language: ja
pipeline:
- name: SpacyNLP
model: ja_ginza
- name: SpacyTokenizer
- name: SpacyFeaturizer
- name: RegexFeaturizer
- name: CRFEntityExtractor
(2) 訓練データファイル
アノテーションは、[値]{"entity": "種別"}という形式で記載します。
文の意図(intent)は、今回は使用しませんが、記載が必須なため記載しています。
nlu:
- intent: eat_out
examples: |
- [昨日]{"entity": "date"}は[両親]{"entity": "companion"}と一緒に[銀座]{"entity": "place"}の[寿司]{"entity": "food_genre"}を食べにいきました。
- [おととい]{"entity": "date"}、[友人]{"entity": "companion"}と一緒に[中華料理]{"entity": "food_genre"}を食べに、[横浜]{"entity": "place"}に行った。
- [一週間前]{"entity": "date"}に、[祖父母]{"entity": "companion"}と[日本食]{"entity": "food_genre"}を食べました。
- [今日]{"entity": "date"}は[弟]{"entity": "companion"}に[台湾料理]{"entity": "food_genre"}に連れて行ってもらう。
- [明日]{"entity": "date"}、[恋人]{"entity": "companion"}と[恵比寿]{"entity": "place"}に[イタリアン]{"entity": "food_genre"}を食べに行く予定。
モデル訓練
作成した2つのファイルと、モデル出力先を指定して、モデル訓練を実行します。
# NLUモデルを訓練
# cf. https://rasa.com/docs/rasa/reference/rasa/model_training
from rasa.model_training import train_nlu
train_nlu(
config='config_ja.yml',
nlu_data='train_samples.yml',
output='nlu_models')
Your Rasa model is trained and saved at 'nlu_models/nlu-20220915-141527-inclusive-sofa.tar.gz'.
推論
それでは、先ほど訓練したモデルを用いて、エンティティ抽出を行ってみます。
rasa.core.agent.Agentクラスを使用します。
クラス名にある通り、チャットボットエージェント用のクラスです。(内部構造は理解できていませんが、パイプライン設定ファイルで必要な機能を指定しているので、そこまで無駄な処理は動作していないと想像しています。)
もしかしたら、もう少し下位のモジュールのみ動作させる方法があるかもしれません。今後もし判明した際には追記したいと思います。
# モデルを読み込んで、文章を解析
from rasa.core.agent import Agent
from rasa.model import get_local_model
# Agentを生成
agent = Agent()
# 訓練モデルを読み込み
model_path = get_local_model('nlu_models')
agent.load_model(model_path)
# 文章を解析(エンティティ抽出)
# notebook中なので await により実行. 一般的には asyncio.run() を使用する.
await agent.parse_message('昨日、友達と、恵比寿のイタリアンに行った。')
{'text': '昨日、友達と、恵比寿のイタリアンに行った。',
'intent': {'name': None, 'confidence': 0.0},
'entities': [{'entity': 'date',
'start': 0,
'end': 2,
'confidence_entity': 0.8748535803053381,
'value': '昨日',
'extractor': 'CRFEntityExtractor'},
{'entity': 'companion',
'start': 3,
'end': 5,
'confidence_entity': 0.7098377521624063,
'value': '友達',
'extractor': 'CRFEntityExtractor'},
{'entity': 'place',
'start': 7,
'end': 10,
'confidence_entity': 0.739316057201231,
'value': '恵比寿',
'extractor': 'CRFEntityExtractor'},
{'entity': 'food_genre',
'start': 11,
'end': 16,
'confidence_entity': 0.5424315319442129,
'value': 'イタリアン',
'extractor': 'CRFEntityExtractor'}],
'text_tokens': [(0, 2),
(2, 3),
(3, 5),
(5, 6),
(6, 7),
(7, 10),
(10, 11),
(11, 16),
(16, 17),
(17, 19),
(19, 20),
(20, 21)]}
入力文から抽出されたエンティティの、種別、値、スコアが出力されています。
訓練、推論ともに問題なく動作していることを確認できました。
訓練サンプルと精度の関係を見てみる
章題の通り「訓練サンプルの数や種類」と「推論時の精度」について、簡単な実験をしてみたいと思います。
「どの程度訓練サンプルが必要か?」は、タスクや他条件によって大きく変わってきますし、今回は訓練・評価データともに私が勝手に作成したものなので、ちょっとした参考程度に考えていただけるとよいかと思います。
実験は3種類です。
訓練データの (a)サンプル数、(b)文章の種類数、(c)エンティティの値の種類数、をいくつかの値で振って、それぞれの要素が精度にどう影響するかを確認します。
訓練データの生成は、テンプレート文と、エンティティとなる単語をそれぞれ複数個定義しておき、それらをランダムに組み合わせることで実施しています。(以下のコード内に記載していますが、文章、単語(エンティティ種別毎に)それぞれ10個程度ずつ用意しています。)
こちらが、訓練サンプルを生成するためのコードです。
import textwrap
# 文章の型(テンプレート)
train_templates = [
"(date)は、(companion)と一緒に(place)の(food_genre)を食べにいきます。",
"(date)行った(food_genre)で食べた(dish_name)は本当に美味しかった。",
"(date)は(companion)に(food_genre)に連れて行ってもらう。",
"(date)、(companion)と(place)に(food_genre)を食べに行く予定です。",
"(food_genre)で、(dish_name)を食べました。",
"(place)の(food_genre)はおいしい。",
"(dish_name)を食べに、(food_genre)に行きました。",
"(place)にある(food_genre)で、(dish_name)を食べた。",
"(date)、(companion)と(food_genre)を食べました。",
"(date)、(companion)と一緒に(food_genre)を食べに、(place)に行った。",
]
# エンティティの要素
train_entity_values = {
'date' : ['今日', '昨日', '一昨日', '3日前', '一週間前', '先週', '明日', '明後日', '来週'],
'companion' : ['友人', '家族', '両親', '父親', '母親', '父', '母', '祖父母', '祖父', '祖母', '恋人', '彼氏', '彼女', '上司', '部下', '同僚'],
'food_genre' : ['イタリアン', 'フレンチ', '中華', '中華料理', '和食', '日本食', '寿司', '懐石料理', '焼肉', '居酒屋', 'スペインバル', '韓国料理', 'エスニック料理'],
'dish_name' : ['パスタ', 'ピザ', '酢豚', '小籠包', '麻婆豆腐', '天ぷら', 'そば', 'うどん', 'とんかつ', '刺身', '生姜焼き', '野菜炒め', '焼き魚', 'ビビンバ', '冷麺', 'カルパッチョ', '純豆腐', 'チゲ鍋'],
'place' : ['池袋', '大塚', '巣鴨', '駒込', '田端', '西日暮里', '日暮里', '鶯谷', '上野', '御徒町', '秋葉原', '神田', '東京', '有楽町', '新橋', '浜松町', '田町', '高輪ゲートウェイ', '品川', '大崎', '五反田', '目黒', '恵比寿', '渋谷', '原宿', '代々木', '新宿', '新大久保', '高田馬場', '目白'],
}
def generate_train_samples(templates, entity_values, num_samples, seed=123):
"""テンプレートの文章にエンティティを埋め込み、訓練サンプルを生成する."""
np.random.seed(seed)
samples = []
while len(samples) < num_samples:
template = templates[len(samples) % len(templates)]
for name, values in entity_values.items():
if f'({name})' in template:
value = np.random.choice(values)
template = template.replace(f'({name})', f'[{value}]{{"entity": "{name}"}}')
samples.append(template)
return samples
def output_train_samples(yml_filepath, train_samples):
"""訓練サンプルを、Rasaの訓練用YAMLファイルとして書き出す."""
assert yml_filepath.endswith('.yml')
TEXT_BASE = \
"""nlu:
- intent: eat_out
examples: |
"""
text_base = textwrap.dedent(TEXT_BASE) # 不要なインデントを削除
text_base += '\n'.join([f' - {text}' for text in train_samples])
open(yml_filepath, 'w').write(text_base)
print('Saved ...', yml_filepath)
train_samples_demo = generate_train_samples(train_templates, train_entity_values, num_samples=5, seed=1)
output_train_samples('train_samples_demo.yml', train_samples_demo)
続いて、評価で使いやすいよう、Agent.parse_message()の出力をラップする関数を作成します。
注意点として、一般的にエンティティ抽出では、1文から同じ種類のエンティティが複数個抽出される場合 があります。そのため、ここでは、スコアが最も高いものを採用することにしています。
async def extract_entities(agent, message):
"""エンティティ抽出."""
# 推論
pred_all = await agent.parse_message(message)
# エンティティの推定結果のみを抽出
pred_entities = {}
for pred in pred_all['entities']:
entity = pred['entity']
value = pred['value']
score = pred['confidence_entity']
# 同一のエンティティが複数抽出された場合は、スコアが高いものを採用.
if entity in pred_entities.keys():
_, s = pred_entities[entity]
if s >= score:
continue
pred_entities[entity] = (value, score)
return pred_entities
# 動作テスト
await extract_entities(agent, '昨日、友達と、恵比寿のイタリアンに行った。')
{'date': ('昨日', 0.8748535803053381),
'companion': ('友達', 0.7098377521624063),
'place': ('恵比寿', 0.739316057201231),
'food_genre': ('イタリアン', 0.5424315319442129)}
評価方法
評価サンプルも、訓練サンプルと同様に作成しています。
テンプレート文7個、エンティティは種類毎に10個を定義しました。これらを、ランダムに組み合わせて、200個の文章を生成しています。
なお、テンプレート文、エンティティの値ともに、訓練サンプルには含まれていないものを使用しています。
評価方法は、正解値との完全一致(種別が同じで、かつ、単語も過不足ない)を正解とし、正しく抽出できた割合(Recall)を評価します。
評価用のサンプルとコードは割愛します。
ご興味のある方は、notebookをご覧いただけますと幸いです。
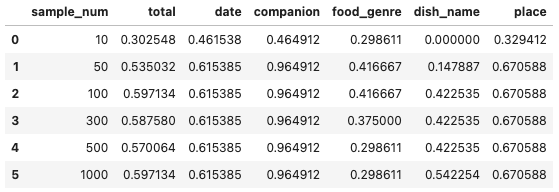
(a) サンプル数
サンプル数100個程で、ほとんど限界性能に達しています。
やはり、ジャンル(food_genre)と料理名(dish_name)は、難しいようですね。種類が多い上に、特定トピック限定の単語のため、特徴抽出も難しい(共通した特徴がない、正しく抽出できていない)のかもしれません。
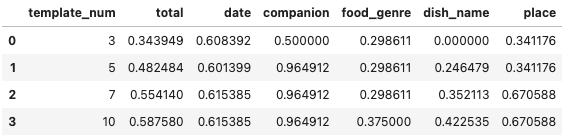
(b) 文章の種類
ジャンルや料理名を見ると、10種類より多くしていけばもう少し精度が向上するかもしれないですね。
一方で、誰と(companion)は、出現の形が固定的(基本的に「〜と」という形)なため、文章の種類数が少ない段階でほとんど100%の正答率となっています。
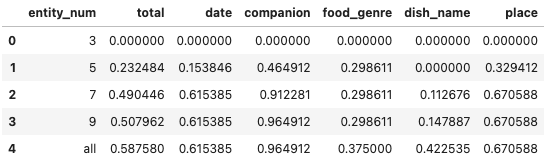
(c) エンティティの値の種類
これを見ると、少なくとも10種類ぐらいは、エンティティの値の種類を用意する必要があるようですね。
また、ある意味当然ですが、取りうる値の種類が多いエンティティ(ここでは、ジャンルと料理名)は、より多くの種類数が必要ということがわかります。
おわりに (感想です)
文章中の情報(キーとなる単語)を抽出する「エンティティ抽出」 を、チャットボット開発フレームワークである Rasa Open Source を用いて実施してみました。
エンティティ抽出(固有表現抽出)は、自然言語処理の重要かつ基本的な機能ですので、今回いろいろと試せて楽しかったですし学びがありました。
実際に試してみると、「こんなんも抽出できるのか!」と思う部分と「これは出来て欲しかったなぁ…」と思う部分の両方がありました。
最後の方の評価結果を見ていただければわかる通り、訓練サンプルにない単語での性能はあまり高いものではありません(特に、ジャンルや料理名)。より高精度な、安定した推定にはどういった工夫が必要なのか、今後学んでいけたらと思っています。
また、Rasaについては、前述の通り若干ハードルが高い部分がありますが、使い方がわかれば簡単かつシンプルに使えると思います。
本来はチャットボット開発フレームワークですので、エンティティ抽出以外にも、意図推定や対話生成なども可能です。今後、そうした機能の使い方も試していきたいなと思います。
最後までお読みいただき、ありがとうございました。
少しでも楽しんでいただけたり、参考になる部分があったりしましたら幸いです。
それでは!(*ˊᗜˋ)ノシ
参考文献
- Rasa Docs(公式リファレンス)
-
Tuning Your NLU Model
- エンティティ抽出を含む、NLU(文章理解)の機能について、使用方法を解説しています。
-
Tuning Your NLU Model
- Rasa Blog
-
Intents & Entities: Understanding the Rasa NLU Pipeline (2021.3.29)
- チャットボットの基本機能である「意図推定」と「エンティティ抽出」について、Rasaの設計・実装を解説しています。
-
Introducing Entity Roles and Groups (2020.8.1)
- Rasaのエンティティ抽出の特徴として、Roles と Groups という機能があります。それを解説してくれています(本記事ではこれらの機能は用いていませんが)
-
Bending the ML Pipeline in Rasa 3.0 (2021.10.27)
- Rasaのv0.x〜v3.0の設計思想の変遷について、各メジャーバージョンでの違いを説明してくれています。
-
Non-English Tools for Rasa NLU (2021.8.12)
- 日本語を含む英語以外の言語でRasaを使用する場合の手引きをしてくれています。
-
Intents & Entities: Understanding the Rasa NLU Pipeline (2021.3.29)
- 日本語記事
- もふもふ技術部 - Rasaとhuggingface/transformersを使って日本語の固有表現抽出する (2020.4.28)
-
オブジェクトの広場 - はじめての自然言語処理 第2回 Rasa NLU を用いた文書分類と固有表現抽出 (2019.4.23)
- Rasaのバージョンは古いので注意は必要ですが、技術の説明はとても参考になると思います。
-
GiNZAのエンティティ抽出(固有表現抽出)は、自然言語処理ライブラリGiNZAで固有表現抽出してみたがわかりやすいです。 ↩
-
GiNZAを用いたエンティティ抽出の訓練方法は、GiNZA入門 (2) - 固有表現抽出の「4. 固有表現抽出のモデルの学習」を参照ください。 ↩