作るもの
入力文の感情推定をするモジュールを、感情推定の訓練サンプル0個 でつくります。
つまり、感情推定のデータセットは使用しないで感情推定をします。
こんな感じで動作します。
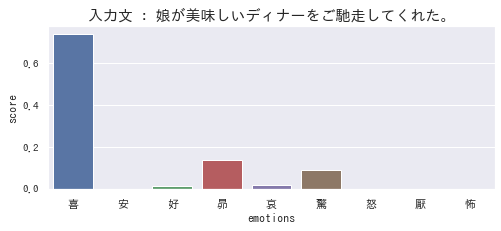
この例では、「娘が美味しいディナーをご馳走してくれた。」という文章に対して、感情を推定しています。結果、「喜(よろこび)」「昂(たかぶり)」「驚(おどろき)」といった感情が含まれていると推定されています。
概要
今回は、事前訓練済みのBERTを使用して、訓練サンプル0個で感情推定 をしてみます。
(「事前訓練済みモデルを使用するなら、訓練サンプル0個ではないのでは?」と思われる方もいるかもしれません。ここでの「訓練サンプルは0個」は「感情推定のための訓練サンプルが0個」という意味で使用しています。)
実施することはシンプルです。
- 入力文の後ろに 「私は
[MASK]気持ちです」 を追加し、 - BERTで
[MASK]を推定する( Fill Mask )
Fill-Maskとは、入力文の空欄に当てはまる単語を推定するタスク です。
例えば、「日本の首都は[MASK]です」という入力に対して「東京」を推定するということです。
BERTの事前学習は2種類あるのですが、1つはこの"Fill-Mask"のタスクです。なので、今回はBERTを事前学習と同じように使ってやる、ということです。
ただ、ここで、ちょっとした工夫をします。
感情推定したい文章の後に「私は[MASK]気持ちです」を追加する のです。
例えば、感情推定したい文章が「宝くじに当たった。」であれば、「宝くじに当たった。私は[MASK]気持ちです」となります。こうすることで、BERTは[MASK]に当てはまる単語を予想し、この例の場合は「嬉しい」「幸せな」などが出力される、という訳です。
本記事では、さらに、感情辞書と組み合わせることで、10種類の感情に分類する、ということをしてみようと思います。
内容目次
- 訓練サンプル0個での推論について
- Zero-shot learning
- Prompt learning
- Transformers で日本語 Fill-Mask を使用する
- 感情辞書と組み合わせて感情分類をする
- (参考)WRIMEデータセットで定量評価する
ソースコード
コードの詳細は、こちらのNotebookをご参照ください。
Google Colaboratoryで開く場合はこちらから。
訓練サンプル0個での推論について
本記事の内容と関連するものとして、「Zero-shot learning」と「Prompt learning」について、すごく簡単にですが、触れておきたいと思います。
Zero-shot learning
訓練データに含まれない未知の対象に対して推定をする ための機構や学習方法、です。
例えば、「象は鼻の長い四足歩行の動物」と聞いていれば、象の写真を初めて見た人でも「あ、これが象か」とわかると思います。つまり、象の写真を見たことはないが、象の写真を「象」と答えられるという状態であり、画像識別タスクにおいては未知の対象に対して推定をしている訳なので、zero-shot learningとなります。
他の例として、Wikipedia等の大量の文章を用いて訓練された言語モデル(BERT等)に、「日本の首都は?」と聞いて「東京」と答えさせる、というのもzero-shot learningと呼ばれます。このタスク(首都当てクイズ)のデータセットでは訓練していないので、zero-shotという訳です。
このように、文脈によって、意味(問題設定や前提条件)がやや異なる言葉のようです。
Prompt learning
自然言語処理で特有の学習・推論方法です。
プロンプト(入力となる文章)を用いて、タスク提示、訓練、推論を同時に行います。
例えば、「犬はdog、猫はcat、ウサギは」と入力することで、AIに「rabbit」と回答させる、というような感じです。「犬はdog、猫はcat」の部分で英訳タスクの提示と訓練をし、「ウサギは」で推論を促しています。
ちなみに、この例の場合、犬と猫で2つ訓練サンプルを与えているので、few-shot learningとなります。もし、「ウサギを英語で言うと」で「rabbit」と回答できれば、それはzero-shot learningということになると思います。
GPT-3に代表されるような、近年の大規模モデルで特に用いられています。
(理由は大きく2つで、モデルが大規模ゆえに従来方式の訓練はコストが高いこと、大規模で表現力が高まったためプロンプト方式でもそれなりの精度が得られるようになったこと、があると思います。)
以上、zero-shot learningとprompt learningの簡単な説明でした。
(ちなみに、今回試すものは、一応、prompt-based zero-shot learningと言えるのかなぁとは思っています)
Transformers で日本語 Fill-Mask を使用する
それでは、実装していきます。
まずは、Transformersを用いて、日本語BERTのFill-Maskを使えるようにします。
! pip install transformers[ja]==4.21.3
from transformers import pipeline, AutoTokenizer
# 使用するモデルを指定して、トークナイザとモデルを読み込む
checkpoint = 'cl-tohoku/bert-base-japanese-whole-word-masking'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
unmasker = pipeline('fill-mask', model=checkpoint, tokenizer=tokenizer, device=0) # GPU使用時は、明示的なdevice指定が必要?
# Fill-Maskを実行
text = '今日はいい天気で、散歩していて気持ちがいい。'
template = '私の気持ちは[MASK]です。' # [MASK]が予測対象
unmasker(text + template)
[{'score': 0.20724758505821228,
'token': 12453,
'token_str': '元 気',
'sequence': '今日 は いい 天気 で 、 散歩 し て い て 気持ち が いい 。 私 の 気持ち は 元気 です 。'},
{'score': 0.06613747775554657,
'token': 13215,
'token_str': '幸 せ',
'sequence': '今日 は いい 天気 で 、 散歩 し て い て 気持ち が いい 。 私 の 気持ち は 幸せ です 。'},
{'score': 0.038396257907152176,
'token': 26051,
'token_str': 'ま っ す ぐ',
'sequence': '今日 は いい 天気 で 、 散歩 し て い て 気持ち が いい 。 私 の 気持ち は まっすぐ です 。'},
{'score': 0.03444681689143181,
'token': 2575,
'token_str': 'い い',
'sequence': '今日 は いい 天気 で 、 散歩 し て い て 気持ち が いい 。 私 の 気持ち は いい です 。'},
{'score': 0.031215133145451546,
'token': 16665,
'token_str': 'ハ ッ ピ ー',
'sequence': '今日 は いい 天気 で 、 散歩 し て い て 気持ち が いい 。 私 の 気持ち は ハッピー です 。'}]
[MASK]に入る言葉が、スコア順に5つ出力されています。
「元気」「幸せ」「いい」「ハッピー」など、それっぽく出力されていることがわかります。
使用しているモデルは、Wikipediaで事前訓練されています。
(cl-tohoku/bert-base-japanese-whole-word-maskingのページの「Dataset used to train」に記載されています。)
Wikipediaには多種多様なページがあるとはいえ、日常の出来事やその時の感情についての文章は少ないと思うので、こうして予測できるのは少々意外に感じました。
感情辞書と組み合わせて感情分類をする
このままだと感情推定としては使い勝手があまり良くないので、後処理を追加します。
感情辞書を使用して、出力された単語がどの感情(例:喜、哀)に属するかを調べて、それを最終出力とする ようにしたいと思います。
ここでは、ML-Askというの感情辞書を使用します。
ML-Askは、辞書ベースの、日本語の感情推定ライブラリです。
10種類の感情{喜, 怒, 哀, 怖, 恥, 好, 厭, 昂, 安, 驚}を表す単語が、テキストファイルに列挙されています。
# ML-Askの感情単語辞書をダウンロードする
# http://arakilab.media.eng.hokudai.ac.jp/~ptaszynski/repository/mlask.htm
! wget http://arakilab.media.eng.hokudai.ac.jp/~ptaszynski/ccount/click.php?id=3 -O emotions.zip
! unzip -o emotions.zip
単語を入力して、その単語が表す感情を出力する関数を定義します。
import os
import glob
# 感情辞書を読み込む
# emotion_dict = {'yorokobi': ['喜', '幸せ', ...], ...}
emotion_dict_files = glob.glob(os.path.join('emotions', '*.txt'))
emotion_dict = {}
for filepath in emotion_dict_files:
em_name = os.path.basename(filepath).split('_')[0] # aware_uncoded.txt --> aware
emotion_dict[em_name] = [x.replace('\n', '') for x in open(filepath, 'r').readlines()]
def search_emotion_dict(word):
"""感情辞書を検索し、どの感情の単語かを返す."""
for name, words in emotion_dict.items():
if word in words:
return name
return None
先ほどの、BERTのFill-Maskと組み合わせて、入力文に対して、10種類の感情の分布を出力する関数を実装します。
2点補足です。
(1)入力文の後ろに追加する文章を5つ用意しています。感情を表す単語は、名詞だけでなく、形容詞や動詞などもあります。それらも出力されるよう、種類を増やしています。
(2)感情ラベル毎にスコアを足し合わせることで、10種の感情の分布を算出しています。
def analayze_emotion_by_fillmask(text, ret_words=False):
"""Fill-Maskにより感情推定をする.
Args:
text (str): 入力文
ret_words (bool): Fill-Maskの出力(感情を含む単語のみ)を返すかどうか
Returns:
list[(str, float)]: 各感情スコア
list[str]: Fill-Mask出力. ret_words=Trueの場合のみ
"""
emotion_names = list(emotion_dict.keys())
# 追加する文章
templates = [
'私は[MASK]です。',
'私は[MASK]ました。',
'私は[MASK]しました。',
'私は[MASK]気持ちです。',
'私は[MASK]に感じました。',
]
# Fill-Maskを実行
results = []
for template in templates:
results += unmasker(text + template)
# 感情辞書と照合
# 各感情のスコアの総和を算出
emotion_scores = {em_name : 0 for em_name in emotion_names}
pred_words = []
for result in results:
pred_word = result['token_str'].replace(' ', '') # 推定された単語
pred_score = result['score'] # スコア
em_name = search_emotion_dict(pred_word) # 感情辞書と照合
if em_name is not None:
emotion_scores[em_name] += pred_score
pred_words.append(pred_word)
# 正規化する(スコアの総和を1にする)
score_sum = max(sum(emotion_scores.values()), 0.01)
emotion_scores = {n: v / score_sum for n, v in emotion_scores.items()}
# スコアの高い順に並び変える
pred_emotions = sorted(emotion_scores.items(), key=lambda x: x[1], reverse=True)
if ret_words:
return pred_emotions, pred_words
return pred_emotions
定性評価
それでは、実際にいくつか文章を入力して、結果を見てみます。
冒頭の例です。「喜」が高いのは当然納得ですが、「昂」はワクワクした感じを、「驚」は稀な出来事に対する驚きを表していると言えるかもしれません。割と納得感がある結果です。
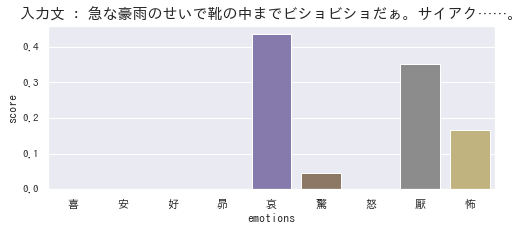
続いて、ネガティブな例です。「哀」と「厭」が高いのは正しく推定できていると言えると思います。一方で「怖」は若干違和感があるように感じます。(「豪雨」は「怖」と結びつく部分はあると思いますが、この文脈ではあまりふさわしくないですよね。)
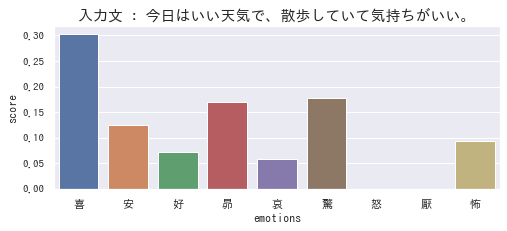
最後にもう1つ。7種類の感情が入り混じっていると推定されていますね。
「喜」「安」「好」「昂」はよいと思いますが、「哀」「驚」「怖」は誤推定と言わざるを得ないかなと思います。
(参考)WRIMEデータセットで定量評価する
最後に、感情推定データセットで訓練した場合との比較をしてみます。
ついでに、ML-Ask(辞書ベースの感情推定)とも比較してみます。
データセットは、WRIMEを使用しました。
日本語の感情分析の研究用データセットです。SNSの文章に、8種の感情の強度ラベルが付与されています。
WRIMEとML-Askでは感情の分類が異なるのですが、今回は適当に対応関係を定義し、WRIMEの8種に合わせる形としました。
なお、WRIMEデータセットのもう少し詳しい情報は、こちらの記事をご参照ください。
# WRIMEの感情分類に合わせた形式で出力する
# ※ 「信頼」に相当するものがML-Askには無い
convert_table = {
'yorokobi': '喜び',
'takaburi': '期待',
'odoroki': '驚き',
'aware': '悲しみ',
'suki': '喜び',
'iya': '嫌悪',
'yasu': '喜び',
'haji': '嫌悪', # 適切かは不明
'kowa': '恐れ',
'ikari': '怒り'
}
def prediction_for_wrime(text):
"""感情推定の出力を、ML-Askの10感情から、Plutchikの8基本感情に変換して出力."""
pred = analayze_emotion_by_fillmask(text)
em_name, score = pred[0]
wrime_em_name = convert_table[em_name]
return wrime_em_name
prediction_for_wrime("今日は久々に良い天気だ!")
# '喜び'
具体的なコードは省略します。ご興味ある方はNotebookをご参照ください。
以下、評価結果です。
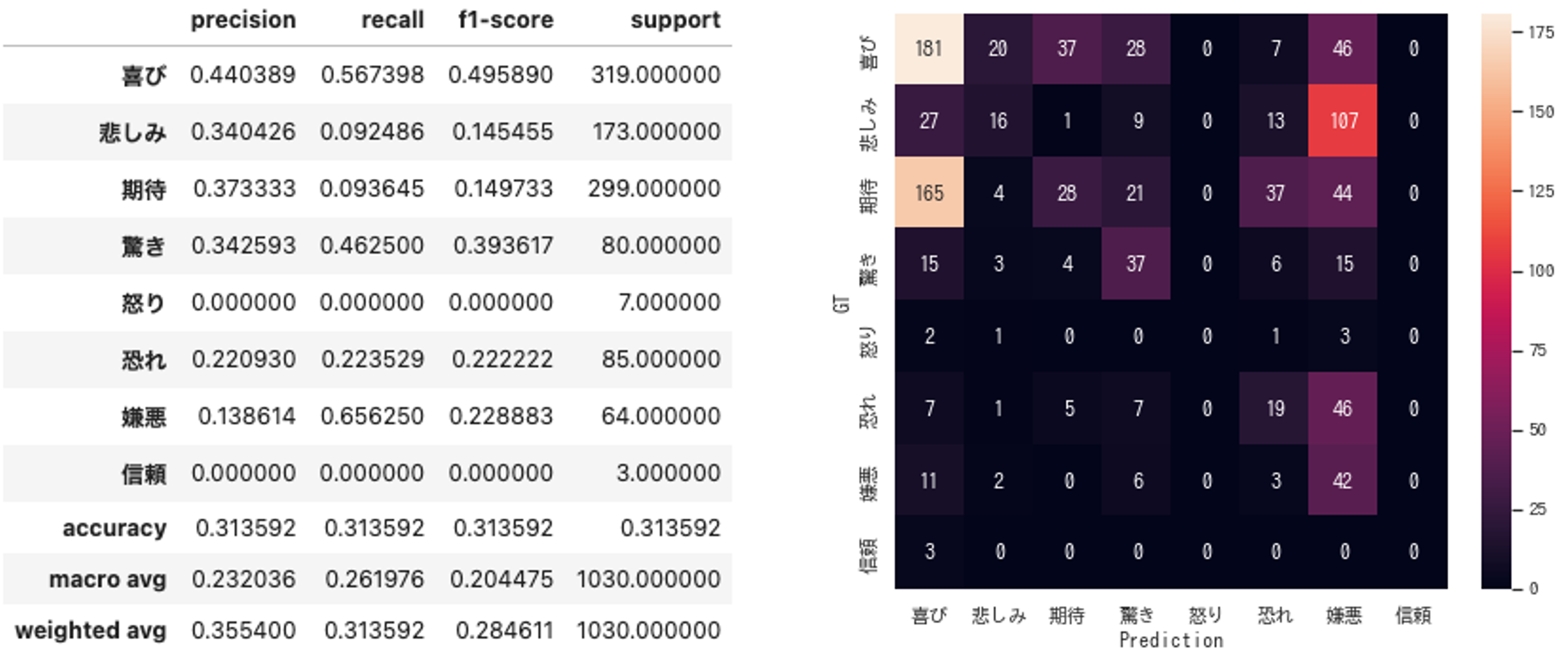
① Fill-Mask + 感情辞書
Accuracy : 0.314
② ML-Ask(辞書ベース)
Accuracy : 0.220
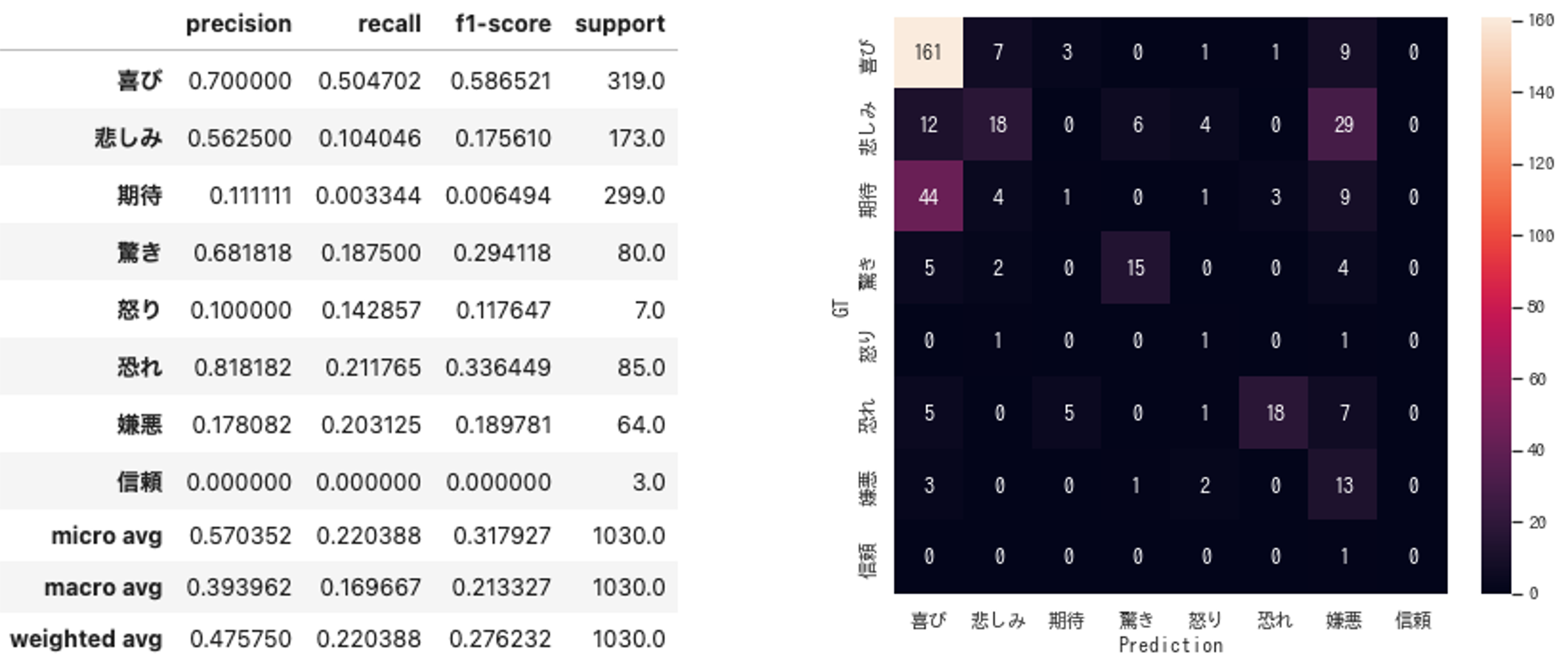
③ データセットで訓練(BERT)
Accuracy : 0.622
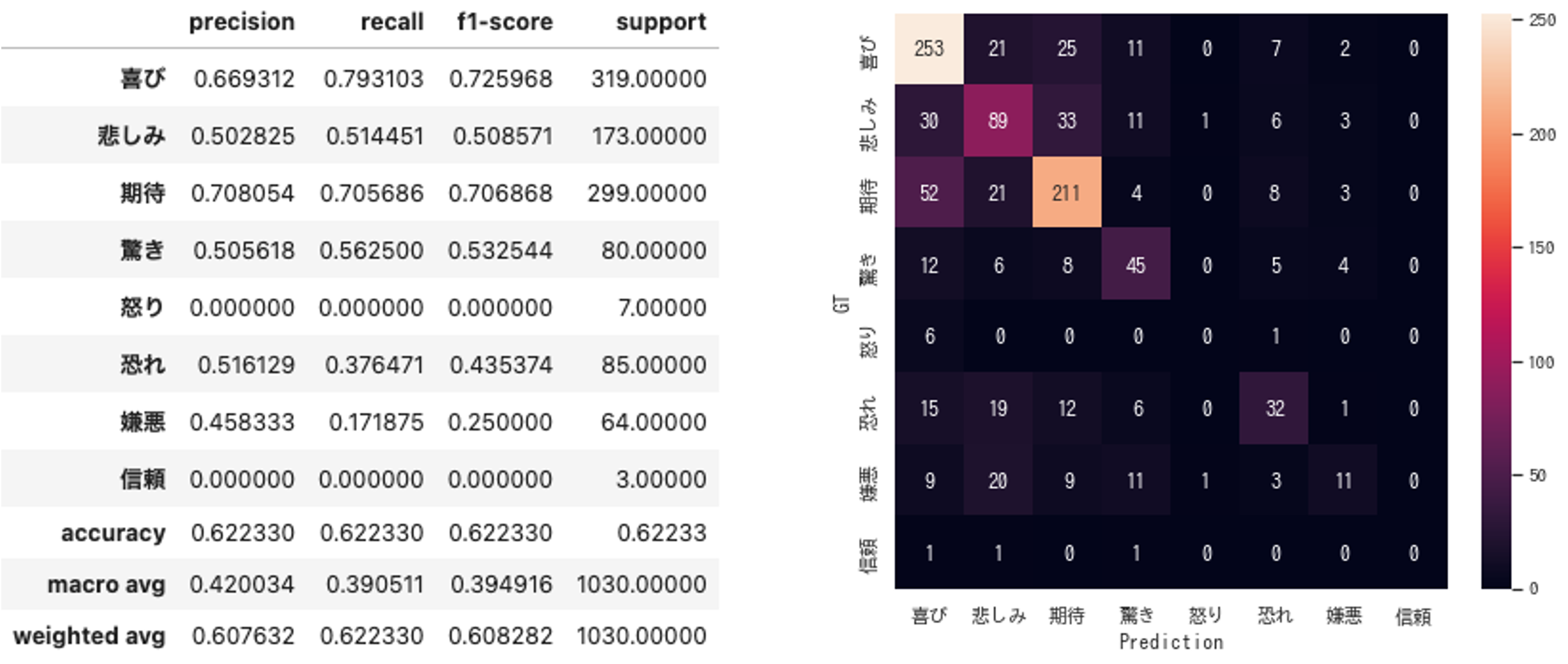
さすがに、データセットで訓練したものが圧勝、でした……。
ただ、「Fill-Mask+感情辞書」は割と善戦しているとは思います。とは言え、真逆の推定(「喜び」を「嫌悪」と推定など)がそれなりの割合で発生しているので、あまり実用的とは言えないと感じました。
また、今回の方式が、ML-Ask(辞書ベース)を上回ったのは面白いなと思いました。
辞書ベースの感情推定では、文章そのものに感情を表す単語がないと分類できません。一方で、「Fill-Mask+感情辞書」の場合、感情を表す単語を推定してそれを辞書と照合するため、文章内には感情を表す単語がない場合にも対応が可能で、その差が正解率の差として出たものと思います。
おわりに
BERTのFill-Maskを用いて、感情推定の訓練サンプル0個での感情推定を試みました。
それらしく推定できていそう、とは言ってもよいかなと思いました。
少なくとも、訓練サンプルが全く無くともこうした推定ができるのはすごいなと個人的には感じました。
一方で、やはり、精度的には難アリ、でした。
具体的には、「今日はいい天気で、散歩していて気持ちがいい。」に対して「怖」を部分的に出力してしまっていたり、WRIMEを用いた定量評価においても「喜び」を「嫌悪」と誤推定する場合が一定数あったり、実用的とは言えない結果となりました。
想定原因と改善策を、簡単にですが2点挙げておきます。
(1)事前訓練を、日常的な出来事や感情をより含む文章(例えば小説)で行うことで、改善されるかもしれません。前述の通り、今回使用したモデルは、Wikipediaで事前訓練されており、今回のターゲットとなるような文章はあまり含まれていない可能性があります。
(2)入力文の後ろに追加する文章(例:私は[MASK]気持ちです。)を工夫することで、改善されるかもしれません。この文章は、出力される単語の傾向、ひいては最終的な推定の精度に大きく影響するためです。(今回はかなり適当に決めており、調整は出来ていないです)
その他にも、感情辞書の調整なども効果はあるかとは思います。
以上、「訓練データなしでも結構できるもんだ」という驚きと、「とは言え、ちゃんと訓練したモデルには到底敵わないのか……」という残念な気持ちを添えて、本記事を終わりたいと思います。
最後までお読みいただき、ありがとうございました。
少しでも楽しんでいただけたり、参考になる部分があったりしましたら幸いです。
それでは!(*ˊᗜˋ)ノシ