Python のウェブスクレイピングツールである Scrapy についての記事です。
すでに、関連記事は多数ありますが、あまり公式ドキュメントに沿った使い方で実装している記事が見当たらないので、原理主義の真髄基本を紹介するために書いてみました。
なお、これは2017年7月時点のサイトデザインをもとに記事やプログラムを書いています。
$ scrapy version
Scrapy 1.4.0
$ python3 -V
Python 3.4.5
(追記) ソースコードを github に置きました。クラス名などは、記事を書いた時点のものから少し変えています。
Scrapy の仕組み
下図は、ScrapyでHTMLを解析するときの典型的な処理の流れです。
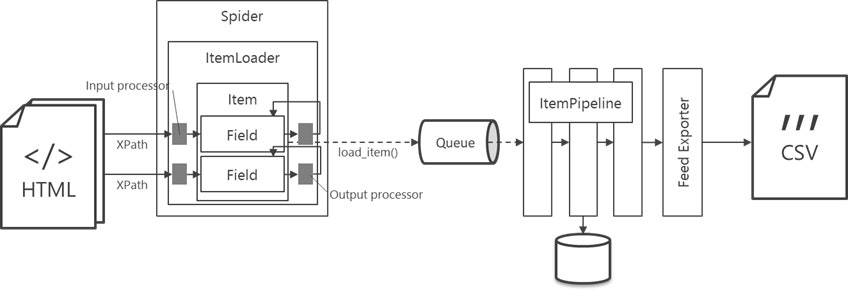
- Item
- 抽出する情報の一単位分を表すクラスです。スクレイピングする際はたいてい同じ構造を持つ情報を複数取り出して、CSVに変換したりデータベースに格納したりしますが、CSV ならその1行、データベースなら1レコードに相当するオブジェクトです。
- Field
- Item の属性を表すもので、CSVやデータベースのカラムに相当します。
- Spider
- サーバから受信したHTMLやJSONなどのデータを解析し、抽出した値を Item に詰め込む処理を記述する部分です。Scrapy では、これを書くのが最も重要なタスクになります。
- Item Loader
- 抽出したデータを Item に格納する際に使える便利メソッドを持つFactoryクラスです。それら便利メソッドを使って値を Field に格納し、最後に load_item() メソッドを呼び出すと Item インスタンスが一つ作成されます。
- Input processor
- 値を Item Loader 経由で Item に格納するときに、その値を加工する仕組みです。Field 毎に一つ設定できます。
- Output processor
- Item Loader から Item インスタンスを取り出すときに、Field 情報を加工する仕組みです。Field 毎に一つ設定できます。
- Item Pipeline
- Item 一つに対し加工を行ったり、データチェックしたり、外部に情報を出力したりする仕組みです。(この記事では使っていません)
- Feed Exporter
- 最終的な出力形式を生成するためのクラスです。
Item Pipeline と Feed Exporter はともに外部に情報を出力することができますが、予め準備されている出力形式 を利用する場合は、Feed Exporterのほうが設定だけで利用できるので楽です。
各構成要素の書き方
題材は SBI証券の投資信託のページです。
この章内で Scrapy の大枠を説明し、後続の章で課題対処ということで小ネタを紹介していきます。
Item の定義
最初に Item を定義します。投資信託商品一つを一つの Item に対応させて情報を読み取ることにします。scrapy startproject でプロジェクトを作成したら、まずは items.py 内に Item クラスを定義します。なお、今回のプログラムは趣味で作ったので、日本語メソッド、変数は遠慮なく使います![]() 。
。
from scrapy import Item, Field
class InvestmentTrust(Item):
投資信託名 = Field()
愛称 = Field()
委託会社 = Field()
:
分配金実績_1_決算日 = Field()
分配金実績_1_分配金 = Field()
分配金実績_2_決算日 = Field()
分配金実績_2_分配金 = Field()
分配金実績_3_決算日 = Field()
:
Item はドメインオブジェクトと考えないほうがよさそうです。取得する情報の論理的構造をあまり考えず、最終出力形式にベタベタに依存した形にします。例えばCSV形式の場合は、カラムごとに Field を定義します。下手に柔軟性を持たせると、出力処理の段階で却って面倒になります。どうしてもという場合は、いったんデータベースなどに格納し、そこから様々な形式に対応させるほうがよいと思います。
Item Loader の定義
Item Loader はscrapy.loader.ItemLoader クラスを継承して作ります。特に規定されていませんが、これもitem.py 内に書くのが楽です。ここに定義するのは、Input Processor と Output Processor です。
- Input Processor = 各 Field に値を格納する直前に適用される
- Output Processor =
load_item()が呼び出されたときに、Field 一つ毎に適用される
Input processor を設定するには フィールド名_in、Output processor を設定するには フィールド名_out というクラス変数を定義します。ただ、これらは開発しながら加工処理を追加していくものなので、最初はおそらく「何もしない」プロセッサ Identityをデフォルトプロセッサとして設定して終わりです。
from scrapy.loader import ItemLoader
from scrapy.loader.processors import Identity
class InvestmentTrustLoader(ItemLoader):
default_input_processor = Identity()
default_output_processor = Identity()
# 例
example_field_in = ExampleProcessor()
Spider の作成
クラス構成
HTMLなどのデータから必要な情報を抜き出し、Item Loaderに格納する処理を記述するクラスです。 spiders ディレクトリに配置します。このクラスで行うことは三つです。
- スパイダ名を
nameで指定する - 最初の HTTP リクエストを作るメソッド
start_requests()を定義する - 返ってきたHTTPレスポンスを解析するための
parseメソッド(群)を定義する
import scrapy
class InvestmentTrustSpider(scrapy.Spider):
# 1
name = 'sbi.investment_trust'
# 2
def start_requests(self):
...
yield scrapy.Request(url=..., callback=self._parse_search_result)
# or
yield scrapy.FormRequest(url=url_search, method='GET',
formdata={ ... },
callback=self._parse_search_result)
# 3
def _parse_search_result(self, response):
...
def _parse_page_X(self, response):
...
def _parse_page_Y(self, response):
...
name で指定したスパイダ名は、scrapy list など、scrapy コマンドで使われます。なお、スパイダ名はドメイン名にちなんでつけるのがベストプラクティスだそうです。例えば mydomain.com に対して mydomain と命名するとよい、ということです。従ってませんが。
解析の開始には、簡単なサイトあれば start_urls 変数を指定するのも可能ですが、フォームにデータを投げるなど、start_requests() でのみ可能なこともあります。このメソッドはリストなどイテレート可能なオブジェクトを返す必要があります。
サーバからHTTPレスポンスが返ってくると、その情報は Request オブジェクトの callback パラメタで指定したメソッドに渡されます。指定しない場合は parse() メソッドに渡されます。
parse() メソッド戦略
題材とした投資信託商品のページは、メインページが1ページあり、これに価額推移など日々変化する情報がAJAXなどでページ内に埋め込まれる形となっています。
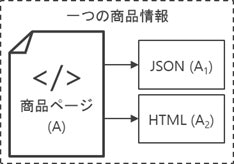
メソッド構成として、ページAを解析するメソッドの中でページA1, A2をそれぞれ解析するサブメソッドを呼び出し、最後に三ページ分の解析結果をまとめて一つの Item インスタンスを作成したい:
def _parse_A(self, response):
yield self._parse_A1(url=url_a1, callback=self._parse_A1)
:
yield self._parse_A2(url=url_a2, callback=self._parse_A2)
:
return loader.load_item()
...ところですが、Scrapy ではできません1。
Scrapy にとっては、リクエストを投げてレスポンスを取ってくるという意味ではメインページもサブページも同じものなので、順番に呼び出して最後に Item を返すようにします。
def start_requests(self):
:
yield Request(url=A, callback=_parse_A) # 最初に解析するページのリクエスト
def _parse_A(self, response):
:
return Requset(url=A1, callback=self._parse_A1) # 次に解析するページのリクエスト
def _parse_A1(self, response):
:
return Requset(url=A2, callback=self._parse_A2) # 次に解析するページのリクエスト
def _parse_A2(self, response):
:
return item_loader.load_item() # 最後に Item を返す
順序を変更したり、間に別ページ処理を挟んだりしにくく、少し使いづらい点です。
出力設定
上述のように Feed Exporter を使う場合は、出力に関するコーディングは不要です。設定だけでできます。settings.py に以下のような設定を追加します。
FEED_URI = 'file:///tmp/output.csv'
FEED_FORMAT = 'csv'
FEED_EXPORT_FIELDS = ['投資信託名', '委託会社', ...]
解析開始
解析開始前に、アクセス先サーバに負荷をかけないよう、以下の設定を settings.py に記述します。
アクセス間隔
他の Scrapy 紹介記事にもありますが、各リクエスト間に一定間隔を入れてアクセスするようにします。
DOWNLOAD_DELAY = 5
HTTPキャッシュ
開発中は必ずキャッシュの設定を有効化すべきです。最初のアクセスで、解析対象サイトから情報を取得し、ローカルにキャッシュします。データを取り直すときは、キャッシュディレクトリ2を削除するのが楽でした。
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
実行
設定が終わったら、解析を開始します。
$ scrapy crawl sbi.investment_trust
指定した CSV が生成されるか、またはエラーが出るので対処する、の繰り返しで開発していきます。
個別課題への対応
Scrapy の小ネタ集です。
長い XPath への対処
HTML構造が深くなると、その分 XPath も長くなりがちです。基準となる XPath を持つ Item Loader を ItemLoader#nested_xpath() で作成しておくことで、その基準要素以下にある値を取得するための Xpath を相対的に指定することができます。
def _parse_買付手数料(self, loader):
base_xpath = 'div[...]/.............................') # 基準となる長い XPath
subloader = loader.nested_xpath(base_xpath)
subloader.add_xpath('買付手数料_ネット_金額指定', 'div[2]/text()[2]')
subloader.add_xpath('買付手数料_ネット_NISA預かり', 'div[2]/text()[4]')
subloader.add_xpath('買付手数料_ネット_口数指定', 'div[2]/text()[6]')
...
データの加工
例えば、HTML:
<div>
ぴろぴろ株式会社
</div>
から XPath で単純にデータを引っ張ってきた場合、Field には以下のような値が格納されます。
item_loader.add_xpath('company_name', 'div/text()')
...
'company_name': ['\r\n',
'\t\t\r\n',
'\t\t\tぴろぴろ株式会社\r\n',
'\t\t\r\n',
'\t\t']
改行を取り除いたり、リストをスカラー値にしたりなど、値を加工する仕組みが Scrapy にはいくつか用意されています。
ItemLoader#add_xxx() の re パラメタ
抽出する値を正規表現で指定します。デフォルトの処理が記述できないので、特定の Field でピンポイントで必要となる処理が必要なときだけに使います。そうしないと、コードが汚くなります。
loader.add_xpath('愛称', 'div[2]/div/div/h3[2]/text()', re='\s*(愛称:(\S+))\s*$')
Input/Output Processor
空白除去など複数の Field で共通的に使われる処理は、こちらのプロセッサを使います。上述のように、デフォルトのプロセッサが指定できます。
Item Loaderに add_xpath() で値を追加していくことに示唆されるように、Field は(最初は)リストです。従って乱暴に分けると、リストの個々の要素の値の加工には Input Processorを、リスト全体の加工には Output Processor を使います。
いくつかのプロセッサが予め用意されています。また、MapCompose プロセッサにより、複数のプロセッサを組み合わせることができます。
from scrapy.loader.processors import Identity, MapCompose, TakeFirst
:
class InvestmentTrustItemLoader(ItemLoader):
# 各プロセッサの組み合わせ要素となるサブプロセッサ
def _Proc空白除去(s):
return s.strip()
def _Proc漢数字変換(s):
return s.replace('百', '00').\
replace('千', '000').replace('万', '0000').replace('円', '')
def _Proc数値型化(s):
return None if s == '' else\
int(s) if s.find('.') < 0 else\
float(s)
def _Procカンマ除去(s):
return s.replace(',', '')
def _Proc先頭プラス除去(s):
return s.lstrip('+')
# 各Fieldに対するプロセッサ
default_input_processor = MapCompose(_Proc空白除去)
default_output_processor = TakeFirst()
純資産_in = MapCompose(_Proc空白除去, _Proc漢数字変換, _Procカンマ除去, _Proc数値型化)
設定来安値_in = MapCompose(_Proc空白除去, _Proc漢数字変換, _Procカンマ除去, _Proc数値型化)
設定来高値_in = MapCompose(_Proc空白除去, _Proc漢数字変換, _Procカンマ除去, _Proc数値型化)
....
その他
Item Pipeline では Python コードによって加工処理を記述できます。この記事では Pipeline は扱いませんので省略します。
parse() メソッド間でのデータ引き渡し
Spider クラスの parse() メソッドには response だけが渡されます。それ以外の情報、例えば解析結果の値を格納する Item Loader を、Request オブジェクトのメタデータ置き場に置き、受け取った側で Response から取り出すことで、parse()メソッド間で情報の受け渡しができます。
def _parse_1(self, response):
req = Request(..., callback=_parse_2)
req.meta['loader'] = loader
return req
def _parse_2(self, response):
loader = response.meta['loader']
:
return loader.load_item()
Item Loaderのコンテキスト変数
この題材サイトのHTMLでは、要素の論理的な意味を示す id 属性があまり使われていません3 。そのため、XPathでは id 指定ではなく「n 番目の div 要素」といった指定を書く必要があります。
ところが、商品によっては「お知らせ」が div 要素で挟み込まれ、この「n番目」がずれることがありました4。これに対処するため、このお知らせ有無のフラグを持たせるのに便利なのが、Item Loaderの context です。
# 初期化
loader.context['didx'] = 4
...
# お知らせの有無をチェック
div_お知らせ = loader.get_xpath('div[4]/h2/text()')
if 0 < len(div_お知らせ):
loader.context['didx'] += 1
# 後続の解析でこの変数を参照
didx = loader.context['didx']
loader.add_xpath('委託会社', 'div[{}]/div/p[2]/text()'.format(didx))
コンテキスト情報を使うことで、後続の処理に情報を渡すことができるということです。一般的に Item Loader の挙動を状況によって変えたいときに使います。
ロギング
Spider クラスでは、logger は初期化されていてすぐに使えます。地味にありがたい心遣いです。
def parse(self, response):
self.logger.info('start parsing.')
プロクシ指定
環境変数 http_proxy, https_proxy を使います。
ログイン処理
小ネタにできるかと思ってましたが、今回題材のサイトは、認証後に謎のリダイレクトを挟んだうえで、(目的URLではなく)認証後のトップページに飛ばされるので、非常にコードが書きづらく、残念ながらあきらめました (認証なくても検索は利用できるし…)。
そのような場合は、割り切って必ずログインしていない状態で開始し、ログイン処理→最初のページ解析→...と続くような書き方のほうが簡単になるかと思います。何かよい方法を見つけたら、また書きます。
これだけだと小ネタにならないので、フォームを使ったログインの場合に便利な、from_response() メソッドを紹介しておきます。Form要素に含まれる hidden パラメタなどを自動的に拾ってリクエストに含めてくれるので、ユーザの入力が想定されているところだけ formdata パラメタとして記述すればよいようになっています。
start_urls = [ url_login_page ]
def parse(self, resp):
# ログインしていない前提
return scrapy.FormRequest.from_response(resp,
formdata={'username': 'taro', 'password': 'secret'}, callback=self.parse_first_page)
Feed Exporter の自作
予め用意されている Feed Exporter では機能が不足するなどの理由で自作する場合は、site-packages/scrapy/exporters.py を参考に、BaseItemExporter クラスを継承して作成します。
呼び出す場合は、settings.py でクラス名を指定します。
FEED_EXPORTERS = {
'csv': 'my.OriginalCsvItemExporter'
}