この記事について
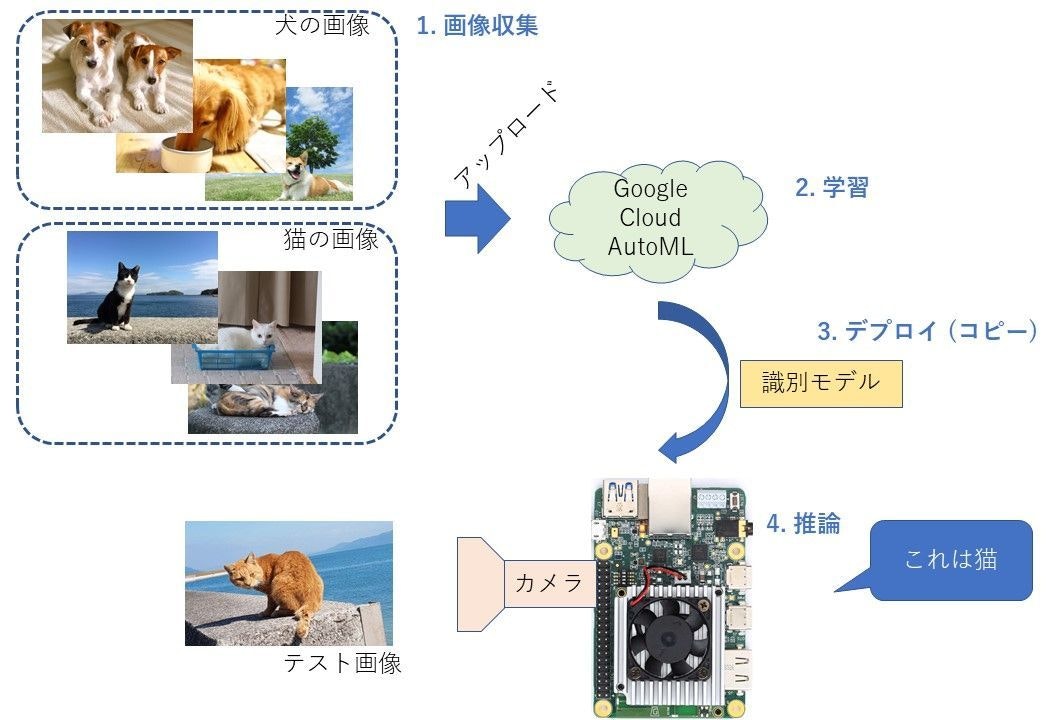
やること
- Google Cloud Platform (GCP) で提供されているAutoML Visionを使用して、画像識別モデルを作ります
- 作成するのは簡単な、「猫」と「犬」を識別するモデル (Classification Model)
- Edge TPU用にモデルを学習し、Coral Dev Board上で動かします
- 最終的に、カメラに写っている画像が、犬か猫かを判定するアプリケーションを作ります
Cats and Dogs Classification by Google Cloud AutoML and Coral Dev Board pic.twitter.com/nddTQrRSyz
— iwatake (@iwatake2222) September 23, 2019
対象
- Deep Learningに興味があるけど、理論分からない人
- モデルそのものよりも、完成したモデルを使って何かを作る方に興味がある人
- チュートリアル(https://cloud.google.com/vision/automl/docs/quickstart?hl=ja )見るのが面倒な人
- 初心者の方でも分かるように、出来るだけ画像をたくさん載せました
- チュートリアルだと、使用するデータセットはありもののcsvファイルをインポートするだけでしたが、本記事では自分で選んだ画像を使って学習します
- クラウドやサーバのAPI開発するWeb系の人もぜひ!
- エッジ(組み込み)に関係するのは最後の部分だけなので、途中のモデルを作るところまではWeb系の方にも参考になると思います
注意
- 現時点(2019/9/23)ではまだβ版です。そのため、操作方法などは今後変わる可能性があります
- 最新情報はオフィシャルのドキュメント ( https://cloud.google.com/vision/automl/docs/quickstarts?hl=ja )をご確認ください
- Google Cloudのアカウント登録が事前に必要です
- 要クレジットカード
- 無料枠内であれば、課金はされません
- Google Cloud Storageと課金設定が事前に必要かもしれません
- 課金設定をしても、無料枠内であれば、課金はされません
- やり方は、https://cloud.google.com/vision/automl/docs/quickstart?hl=ja をご確認ください
環境
-
モデル開発、ホストPC
- Windows 10 (ブラウザが使えれば何でもいいはず)
- Google Chrome (FireFoxだと、一部機能がうまく動きませんでした。)
-
Coral Dev Board (ターゲット環境) <- モデルを作るだけなら不要
- https://coral.withgoogle.com/docs/dev-board/get-started/ でセットアップ
- 本記事内では、ユーザ名、IPアドレスは、
mendel@192.168.1.36とする - バージョン情報
mendel@orange-eft:~$ cat /etc/os-release PRETTY_NAME="Mendel GNU/Linux 3 (Chef)" NAME="Mendel GNU/Linux" VERSION_ID="3" VERSION="3 (chef)" ID=mendel ID_LIKE=debian HOME_URL="https://coral.withgoogle.com/" SUPPORT_URL="https://coral.withgoogle.com/" BUG_REPORT_URL="https://coral.withgoogle.com/"
識別モデルの開発
画像集め
識別する対象となる画像を集めます。
今回は、「猫」と「犬」を分類するので、それぞれの画像が必要になります。識別のためには、最低100枚の学習用画像が必要です。理想的には1000枚以上必要です(https://cloud.google.com/vision/automl/docs/beginners-guide#importing )。
画像収集には、https://www.pakutaso.com/ と https://www.photo-ac.com/ のフリー素材サイトを使用させていただきました。スクレイピングはせずに、ちまちま右クリック->保存しました。
後で使いやすいように、cat というフォルダとdog というフォルダにそれぞれ保存しました。ファイル名は何でもよいです。
cat_and_dog/
- images/
- cat/
- choge.jpg
- cfuga.jpg
- ...
- dog/
- dhoge.jpg
- dfuga.jpg
- ...
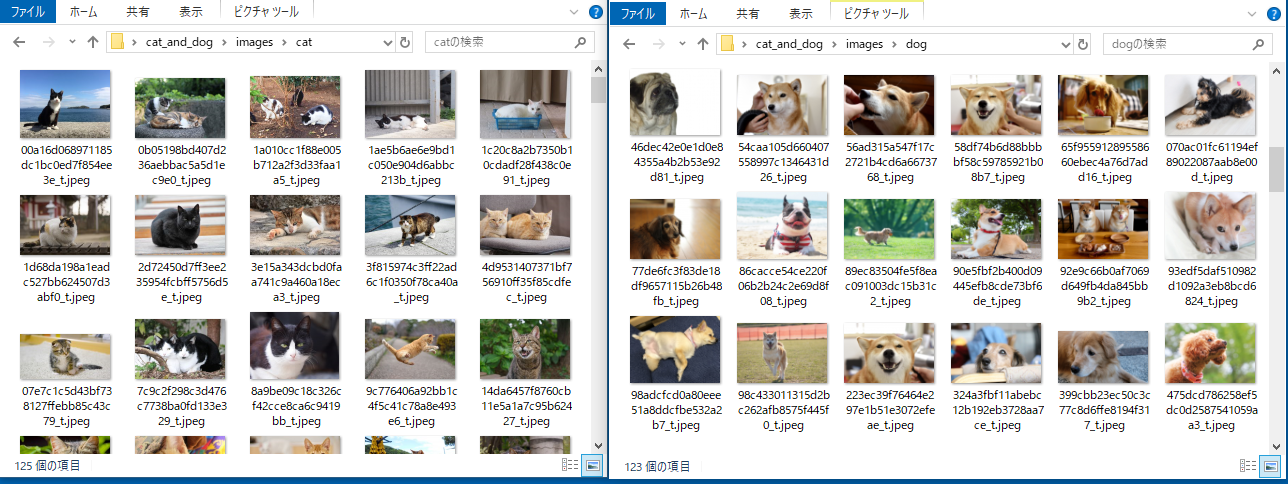
データセットの用意
データセットの作成
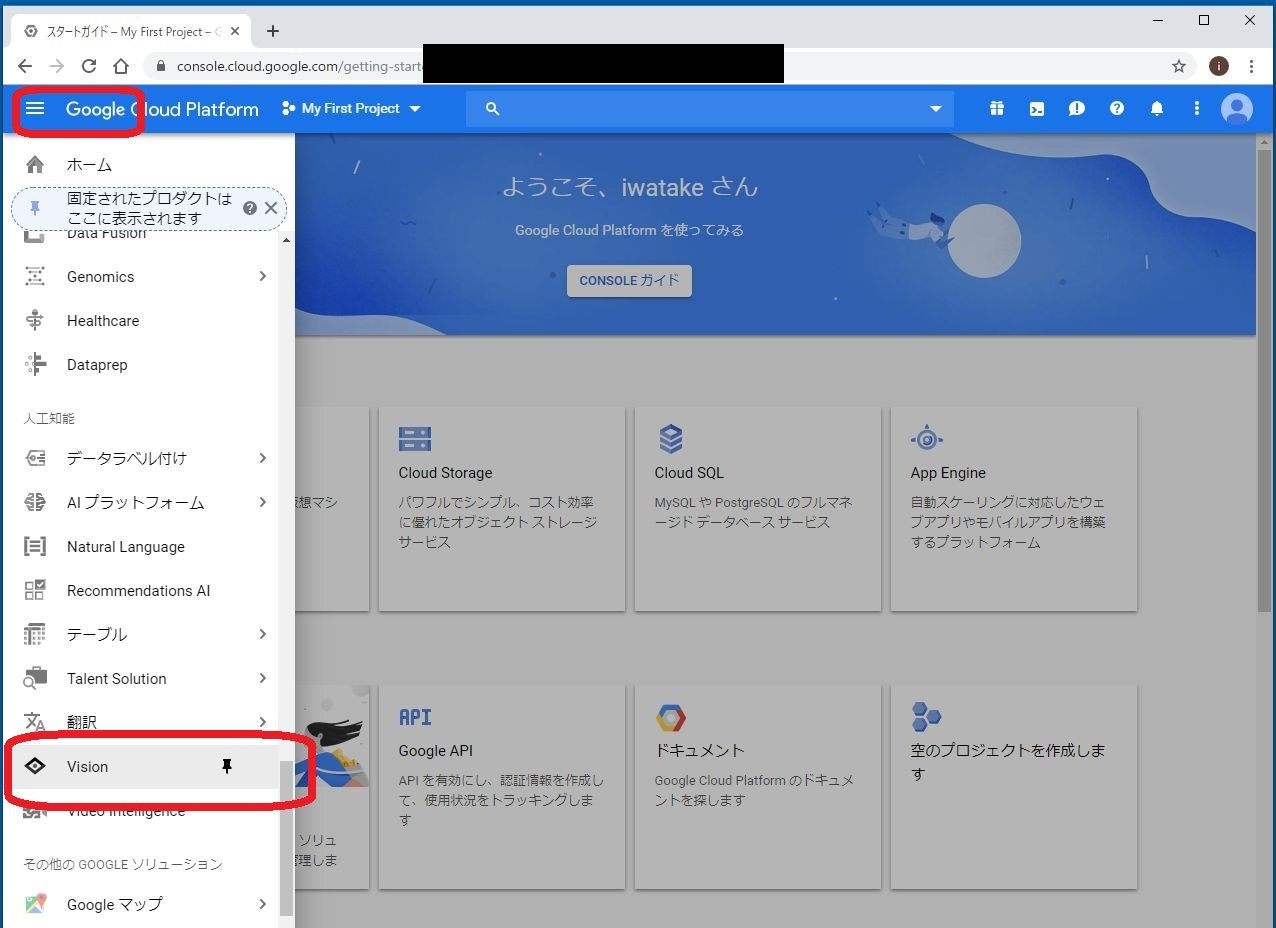
https://console.cloud.google.com/home/ の左上の三本線をクリックして、Vision を選びます。
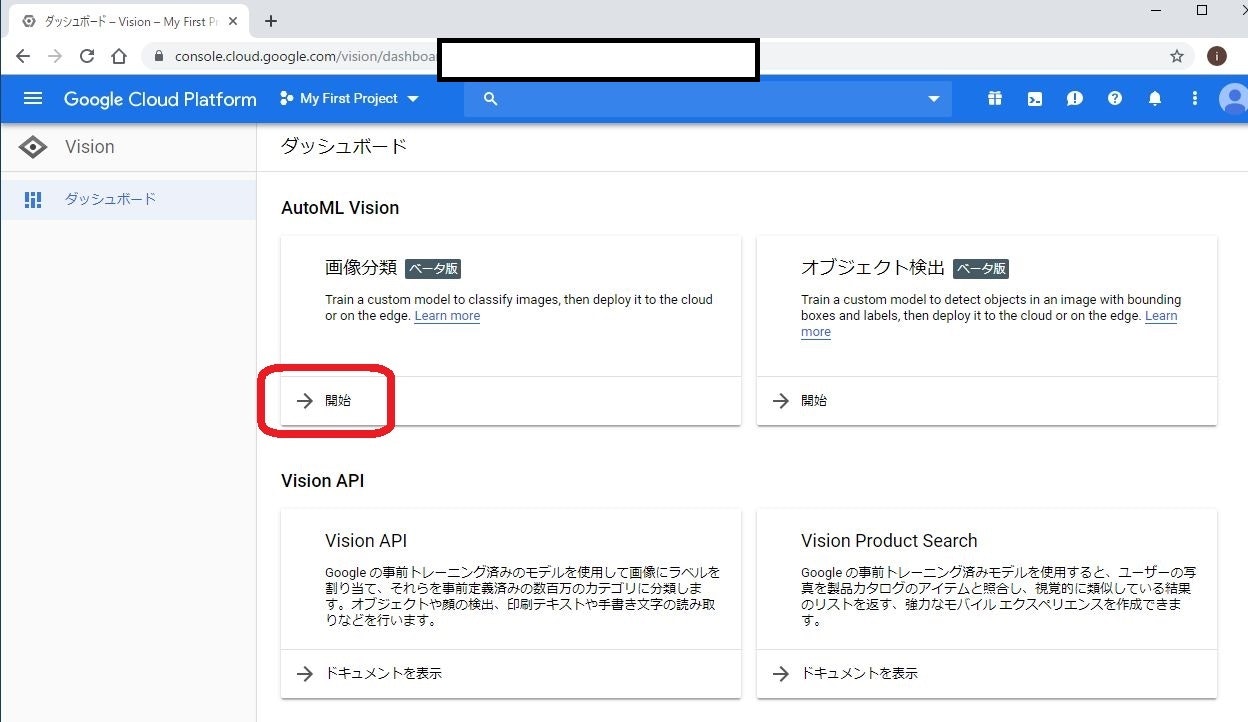
AutoML Visionのホーム画面です。今回は識別モデルを作るので、「画像分類」の「開始」をクリックします。
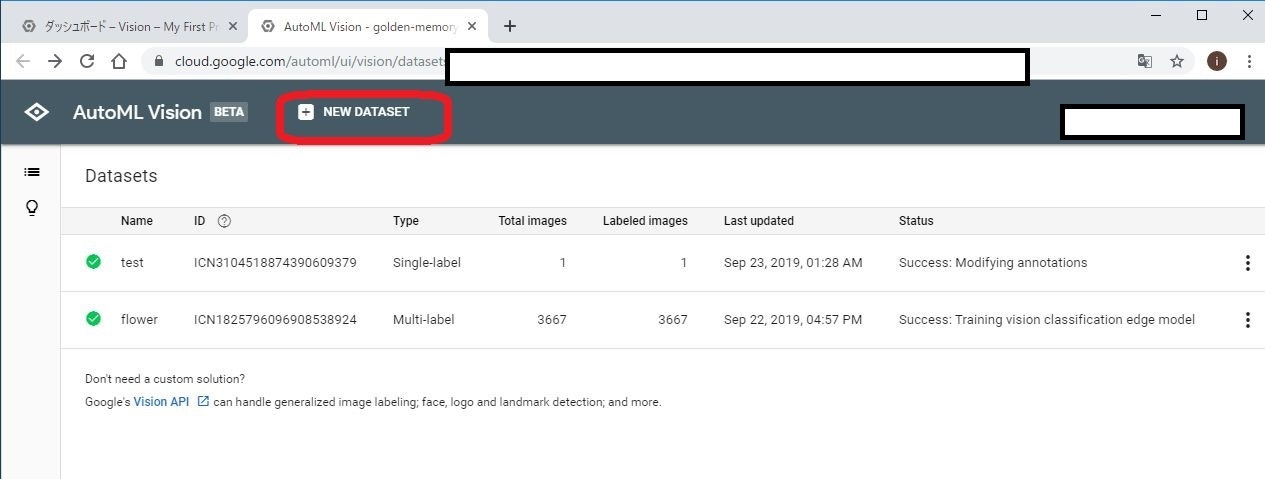
一般的なソフトウェア開発ですと、「プロジェクト」や「ソリューション」という単位で管理されますが、AutoMLでは「Dataset」として管理されるようです。
上部の「* NEW DATASET」をクリックして、新しいデータセットを作成します。
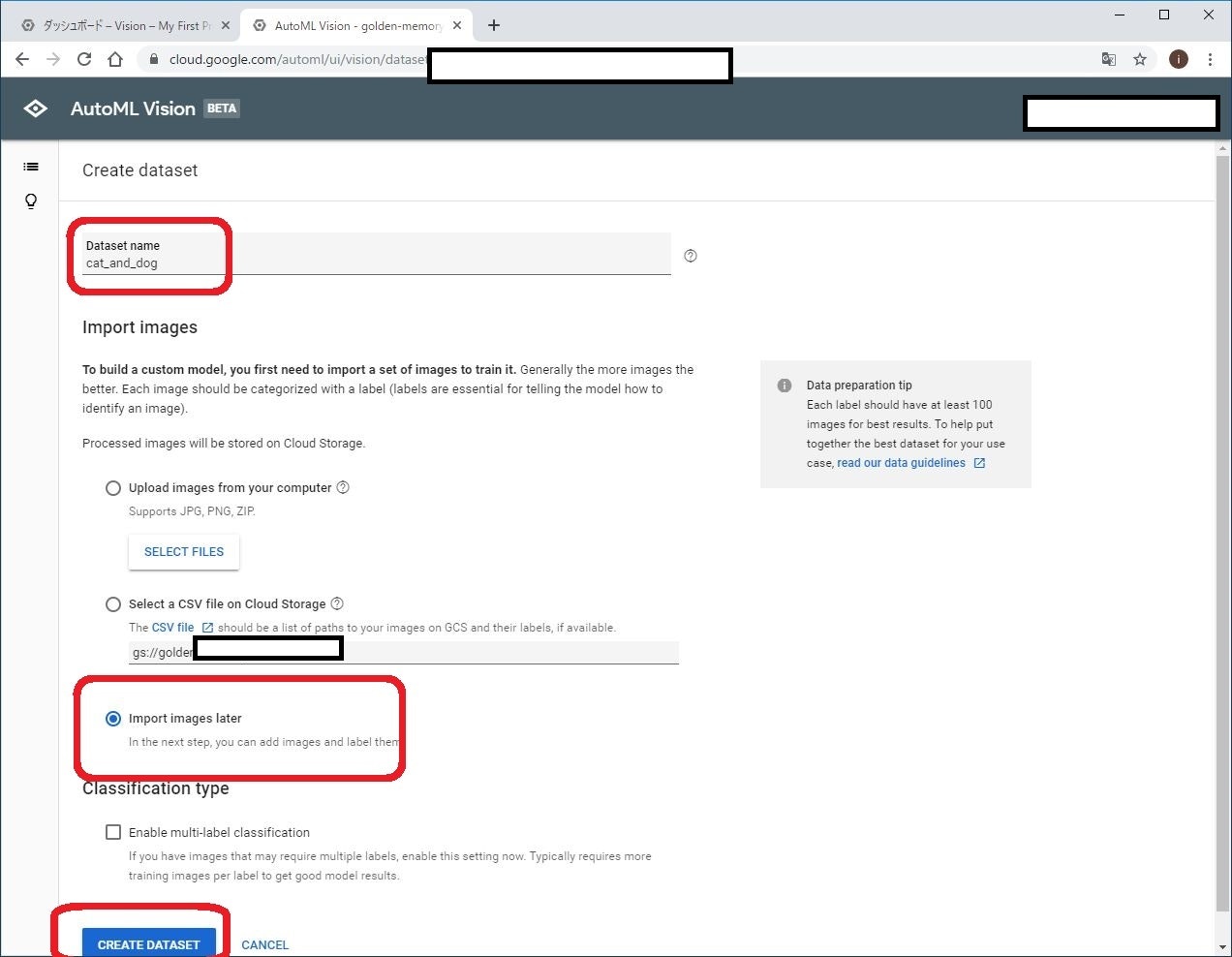
データセット作成画面です。
名前は適当に「cat_and_dog」としました。
画像の追加方法として、以下の2つがあります
- PC上の画像をアップロードする
- Google Cloud Storage上のCSVファイルを参照する
既存のデータセットを使用する際には2のCSVファイル使用の方が便利だと思うのですが、今回は何が起きているかを理解するためにも1の画像をアップロードする方式を使います。
ただ、画像はこの段階ではまだアップロードしないで、後からアップロードしようと思います。そのため、ここでは import images later を選びます。
最後に、CREATE DATASET をクリックして完了です。
ラベル付け作業
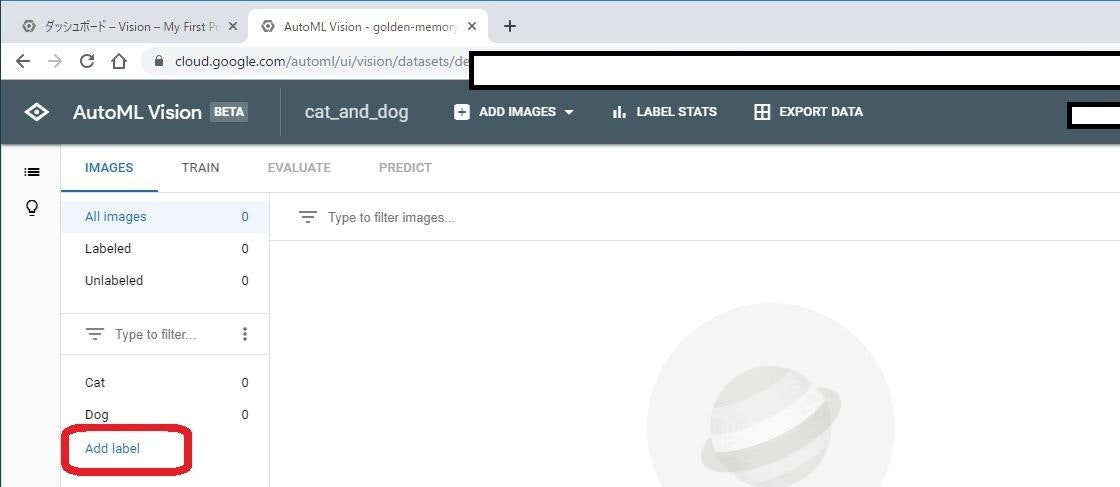
この画面で、このデータセット内の画像を管理します。
画像の追加、削除、ラベリングが行えます。
今回は、「猫」と「犬」の分類を行うので、2つのラベルが必要になります。
左下のAdd label をクリックして、「Cat」と「Dog」を追加します。
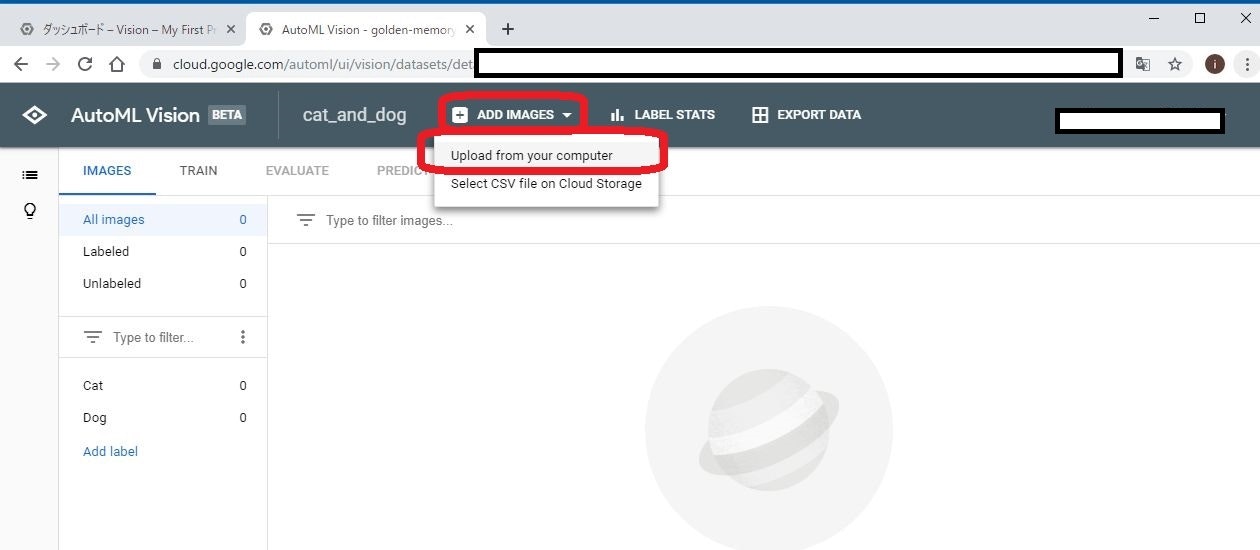
画面上部のADD IMAGES から、Upload from your computer を選びます。
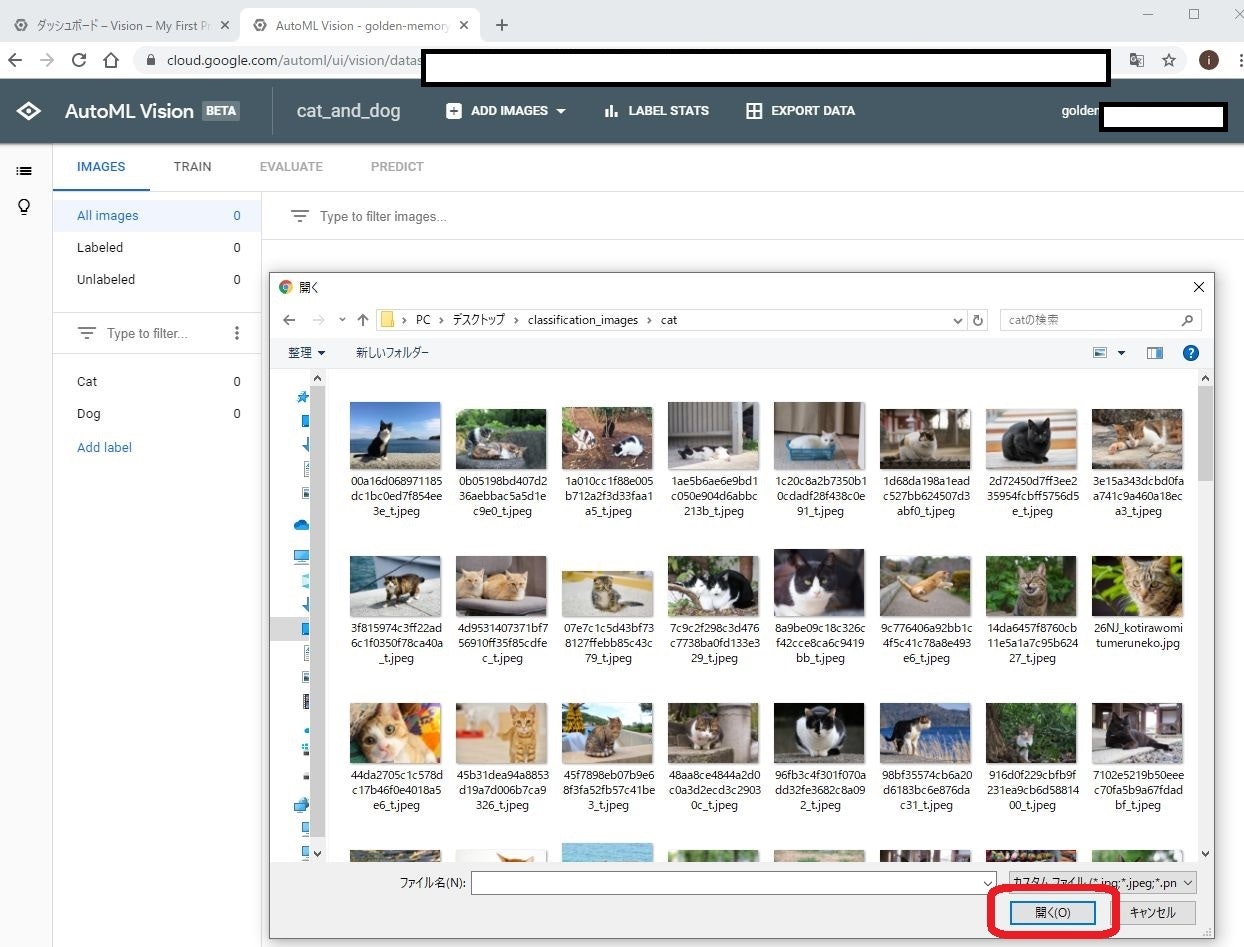
そして、先ほど用意した画像を選びます。
注意点としては、この段階ではまずは猫の画像だけをアップロードします。これは、管理画面上で猫と犬の画像がごっちゃにならないようにするためです。
画像のアップロードと取り込みには数分の時間がかかります。
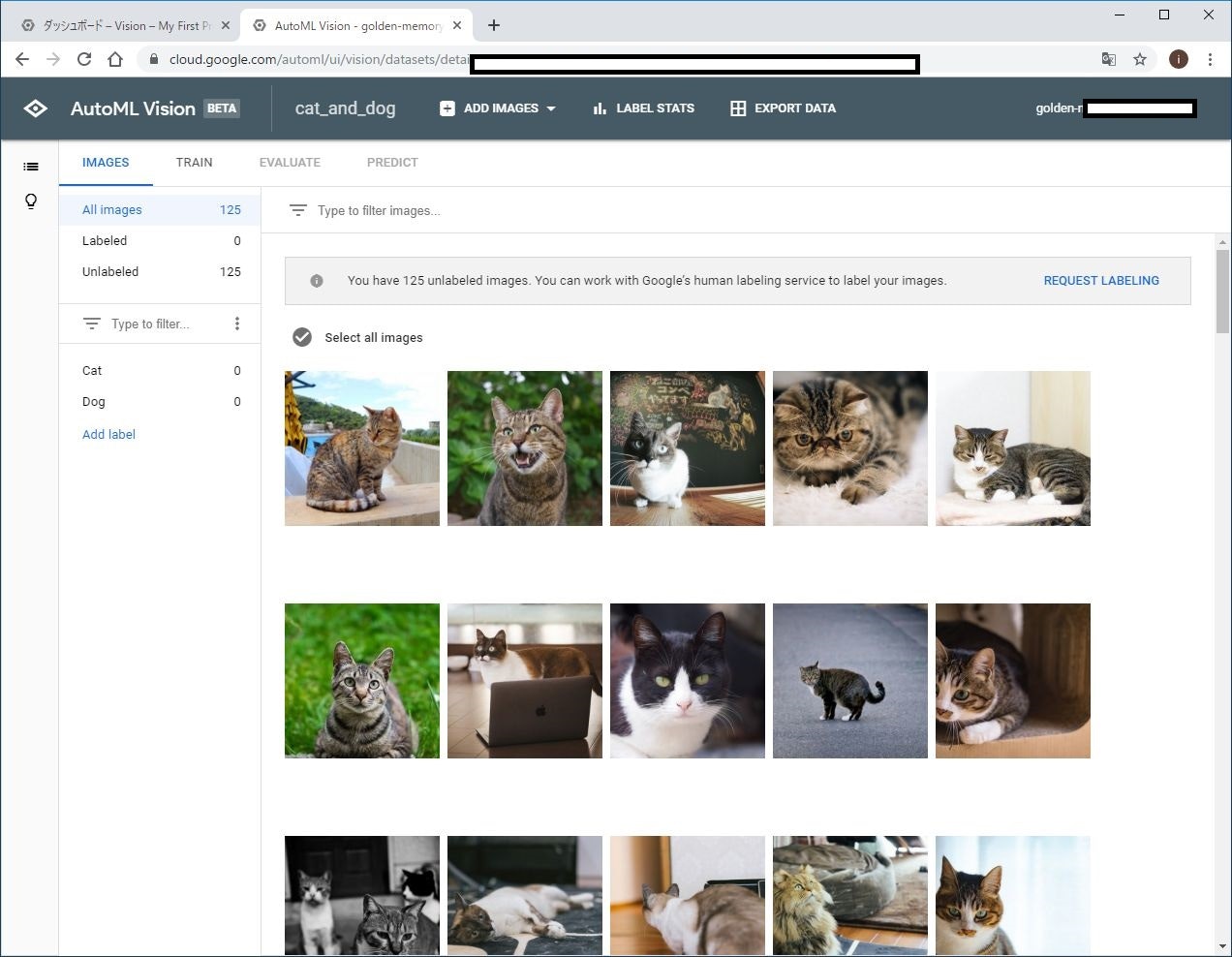
無事に取り込みが終わると、このように、画像一覧が表示されます。
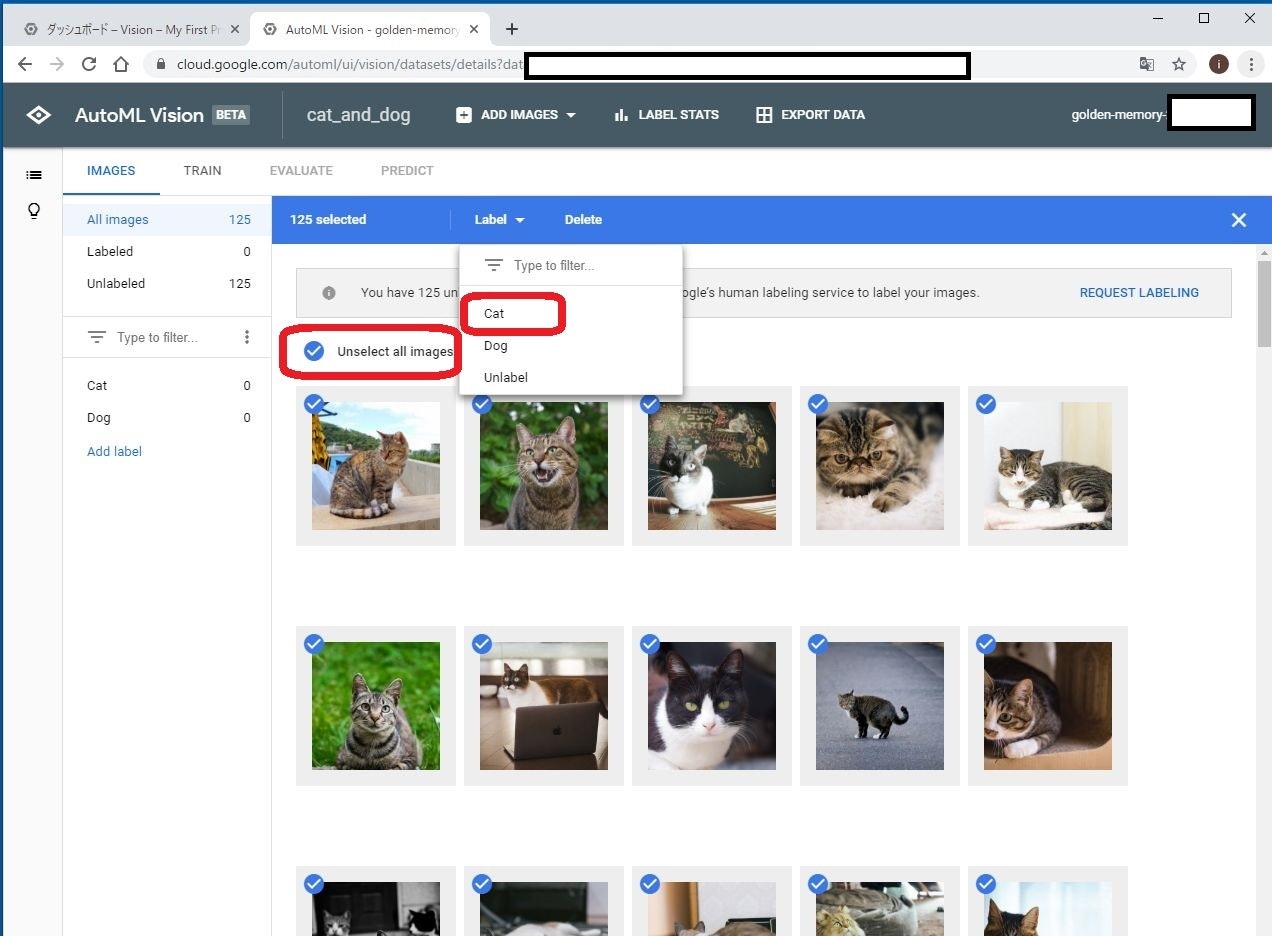
今表示されている画像は全て猫の画像なので、一気に「Cat」のラベルを付けてしまいます。
Select all images をクリックし、Label からCat を選びます。
これによって、今取り込み済みの全画像に対して、Cat のラベルが付けられました。
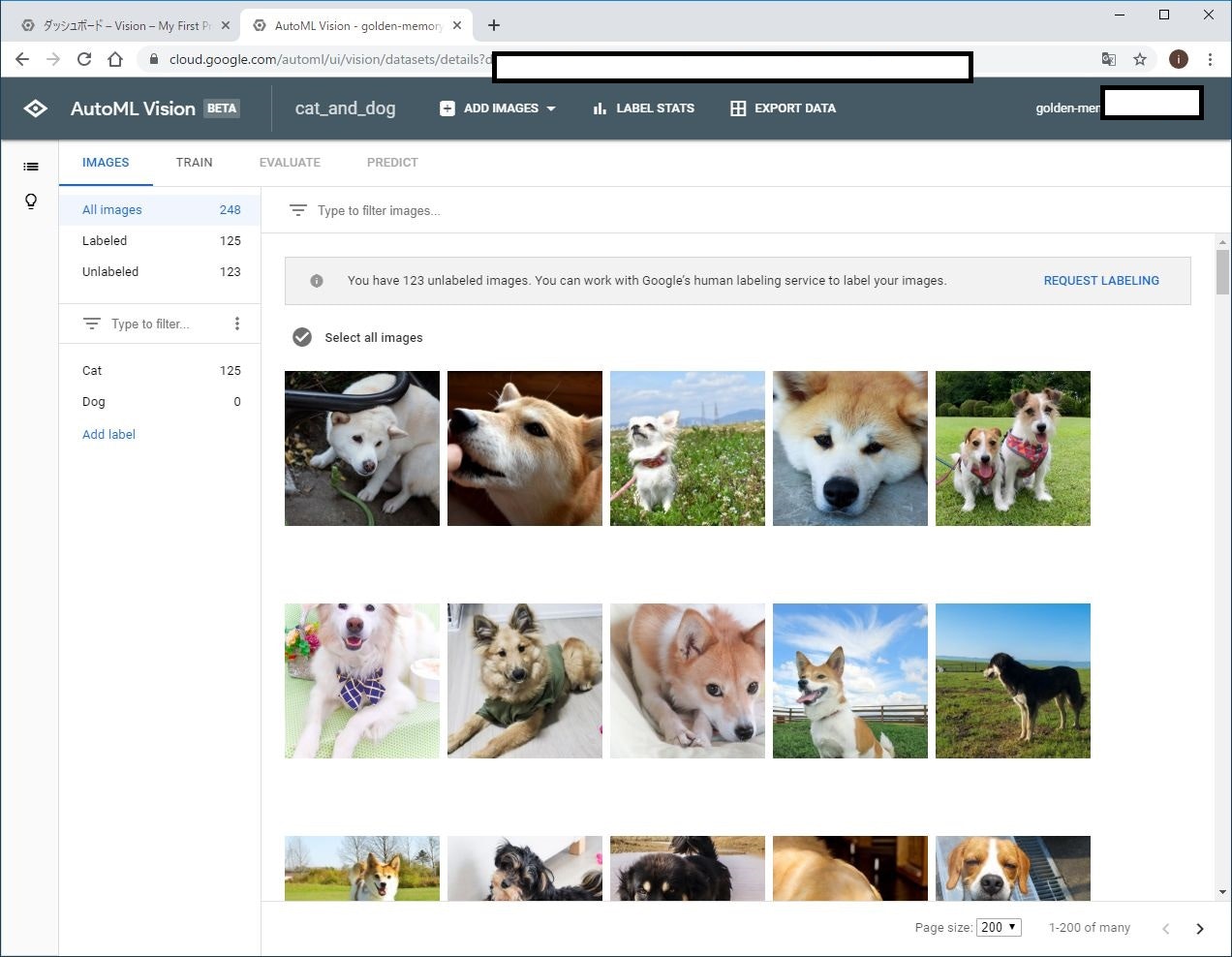
犬に対しても同様に、画像を読み込みます。
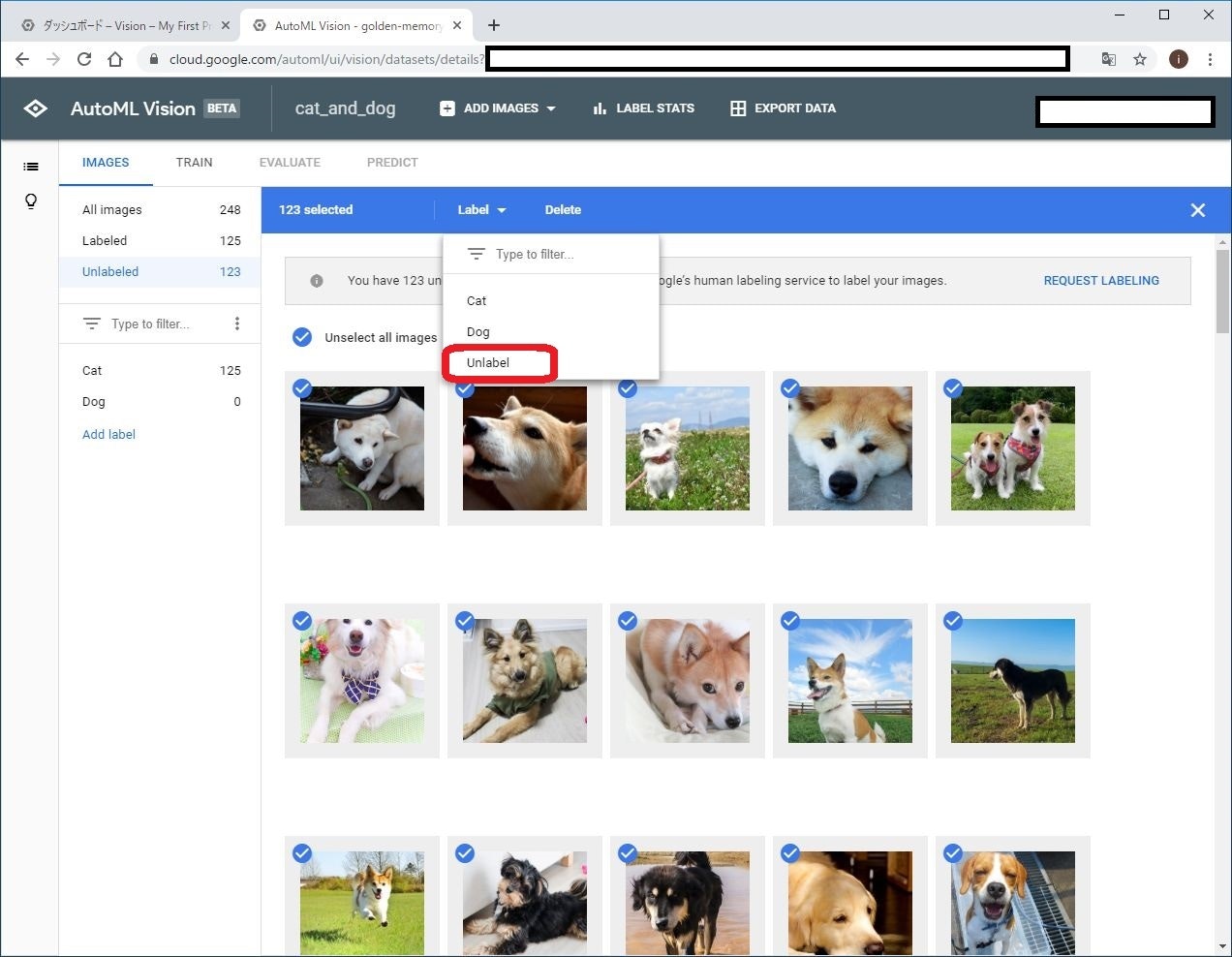
この時点で、猫画像に対しては「Cat」というラベル付与済み。新たに読み込んだ犬画像に対してはラベルが付与されていません。
Type to filter をクリックして、Unlabel を選択します。すると、ラベルが付与されていない画像(つまり、犬画像)のみが選択されます。
これに対して、「Dog」のラベルを付与します。
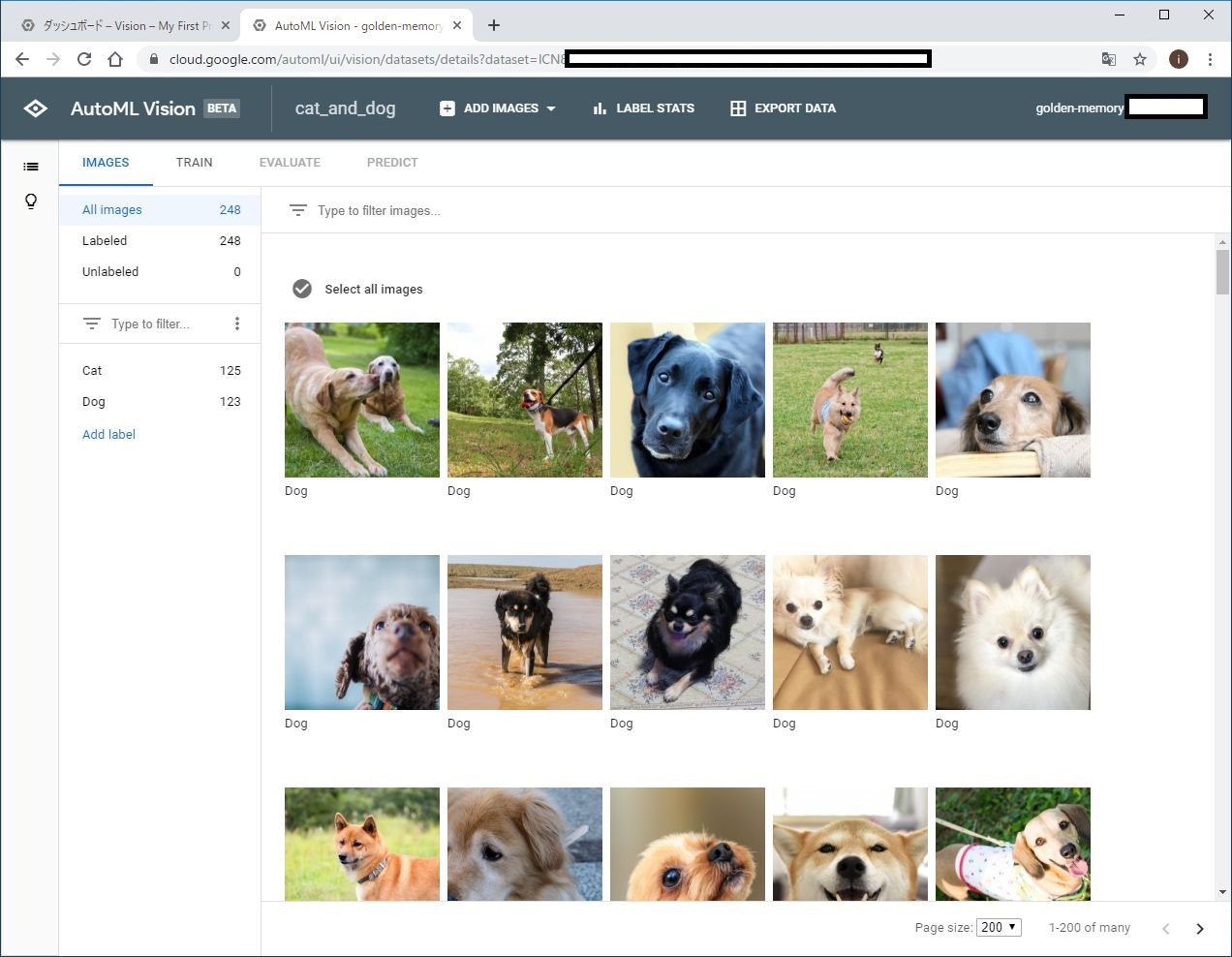
結果、このように猫と犬の画像に対して「Cat」と「Dog」のラベルが付与されました。
学習
学習
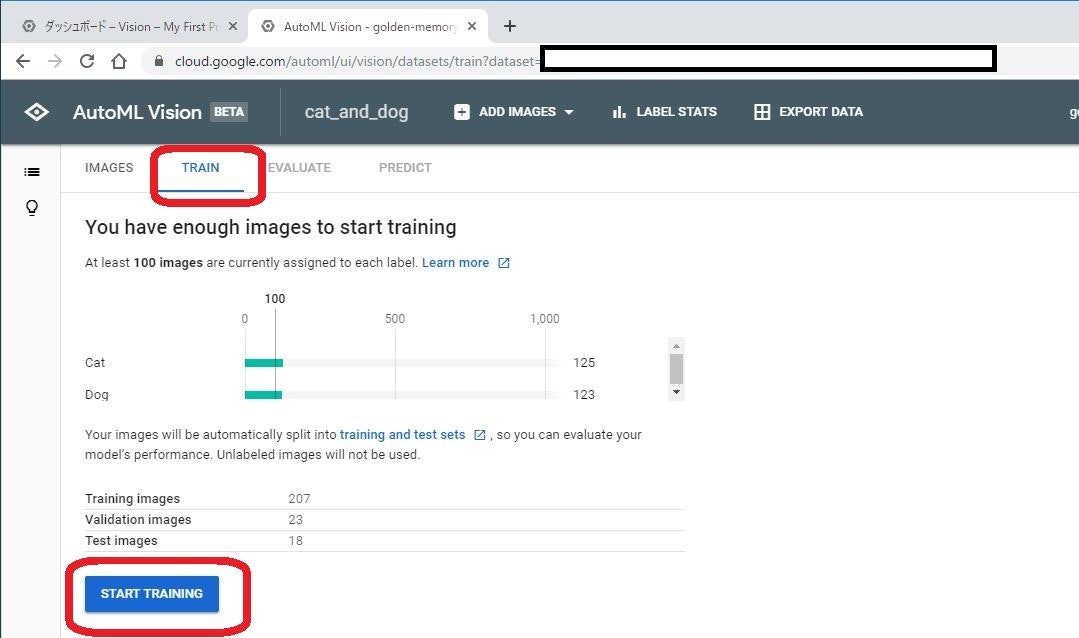
TRAIN タブを選び、学習用の画面に移ります。
データセットの統計情報が表示されます。全ての画像の中から、Training用画像、Validation用画像、Test用画像に自動的に振り分けられます。
最低でも100枚の学習用画像が必要と言われているので、今回はぎりぎりです。これは、学習をするのにぎりぎりというだけであって、十分な精度が出ることを保証するわけではありません。100枚では十分な精度を出すのには足りていません。(今回は、お手軽に試す、というのが目的なので。。)
画面下のSTART TRAINING をクリックして学習を開始します。
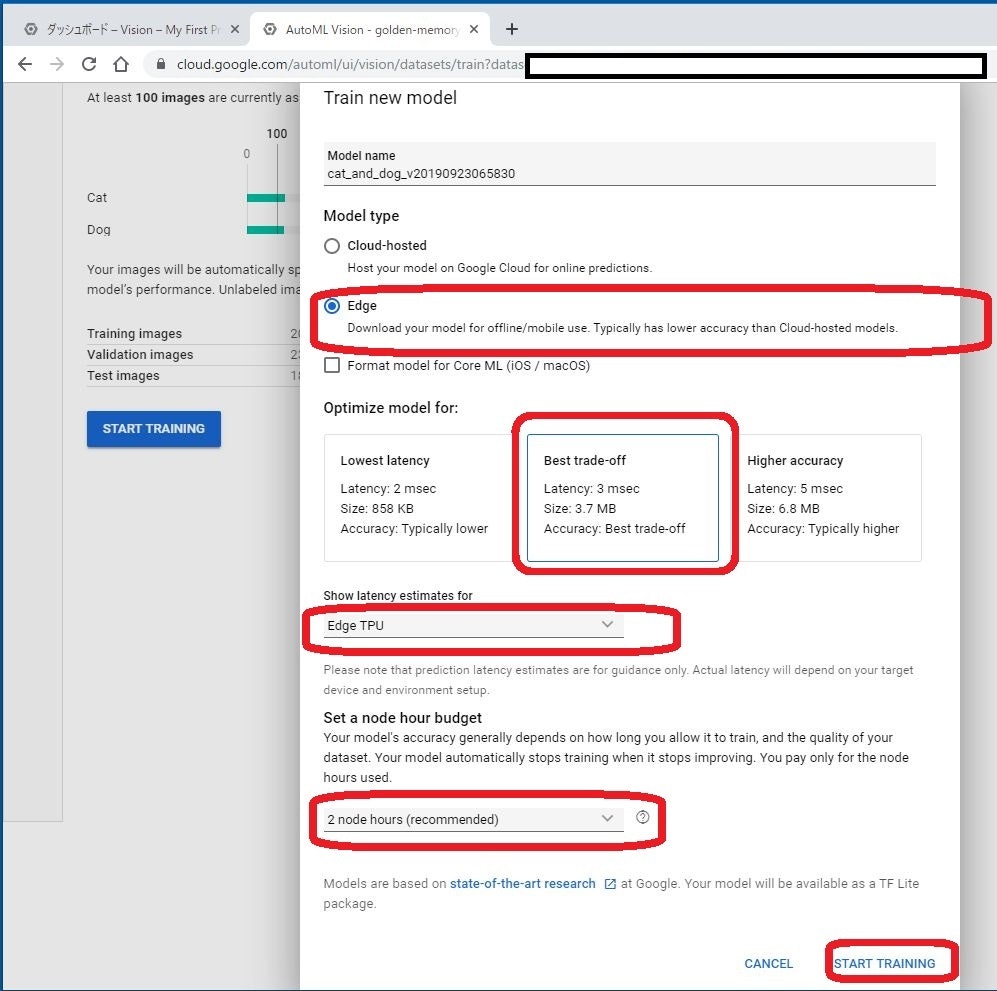
作成するモデルの設定をします。
今回、最終的にはCoral Dev Boardで動かしたいので、以下のような設定にしました。
- Model type: Edge
- Optimize model for: Best trade-off
- Show latency estimation for: Edge TPU (作成するモデルには関係ない?)
- Set a node hour budget: 2 node hours (これくらいの規模だと、2 node hoursもかからずに終わると思います。もっと大規模なモデル作成時には、この数字を大きくする必要があると思います。)
最後に、START TRAINING をクリックして学習が開始されます。
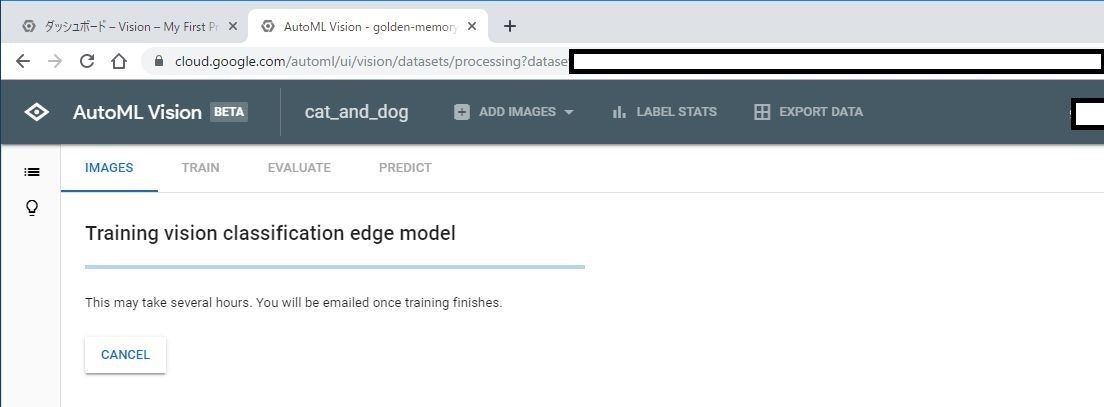
学習中はこのような画面になります。
ブラウザは閉じても大丈夫です。
完了したらメールが届きます。
コスト
今回は、1 compute hourで完了しました。実時間では、30~40分くらいでした(総画像数=248枚。ラベル数=2)。
かかった料金は約500円でした。が、プロモーションクレジット(約8,000円)内なので無料です。
無料枠金額はおそらく、アカウントあたり 15 ノード時間の無料トレーニング x $4.95 (https://cloud.google.com/vision/automl/pricing?hl=ja) で計算されます。
性能
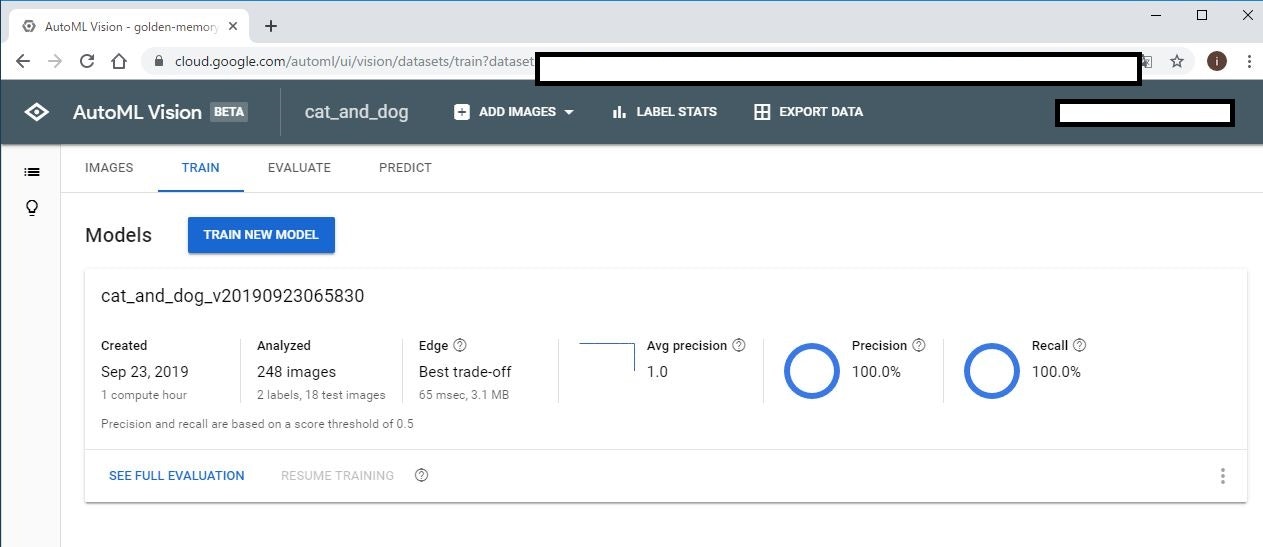
学習が完了すると、TRAIN タブにはこのように、モデルの性能サマリーが表示されます。
テスト用画像が少ないためか、精度(Precision)も再現率(Recall)も100%という凄い結果になりました。
ちなみに、ここで表示されているLatency = 65msec はPixel1で実行した場合の時間らしいです。実際にEdge TPUで実行した場合には、学習開始時の設定に表示されていた、Latency: 3msec となるはずです。
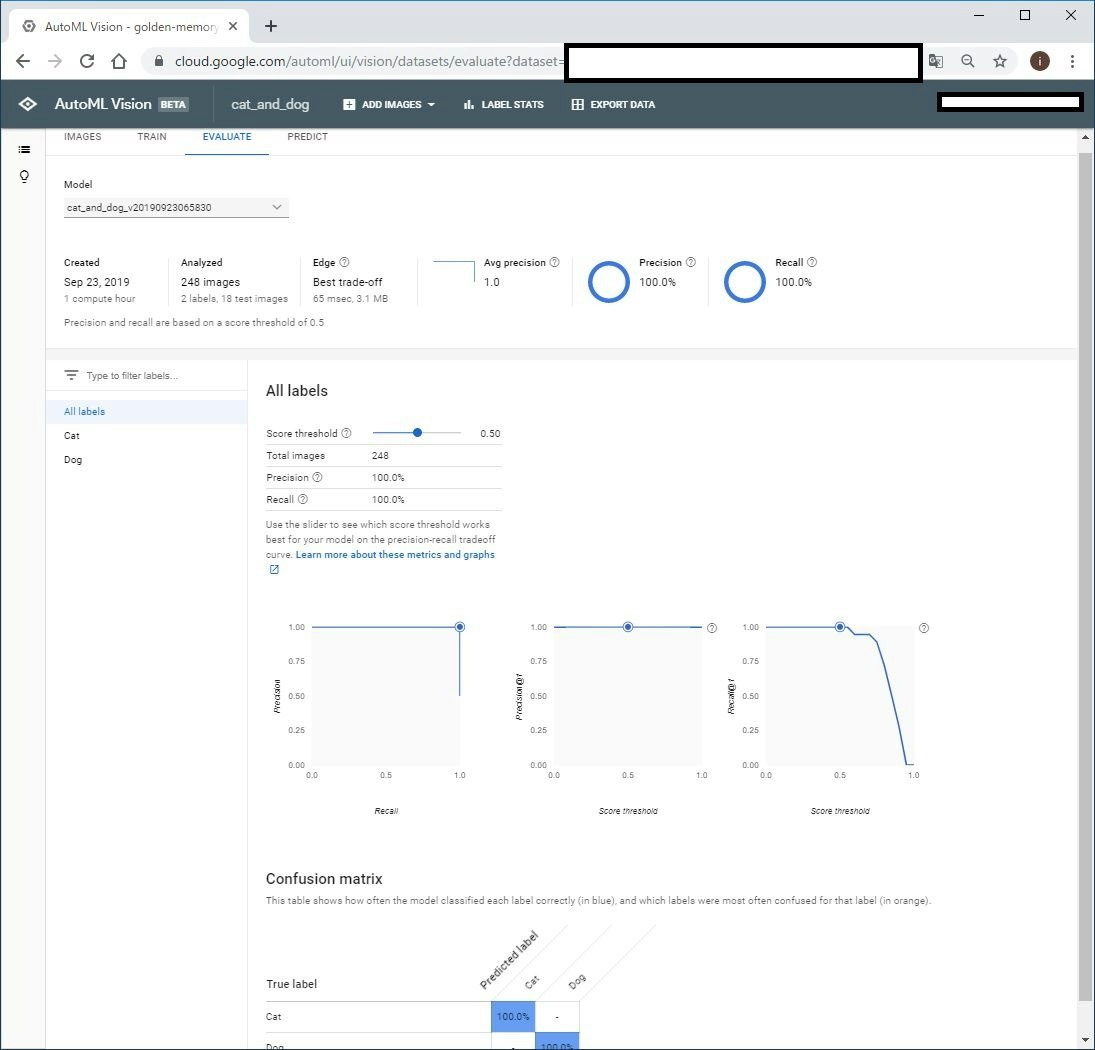
より詳細な性能レポートを見たい場合には、EVALUATE タブに移ります。
モデル出力
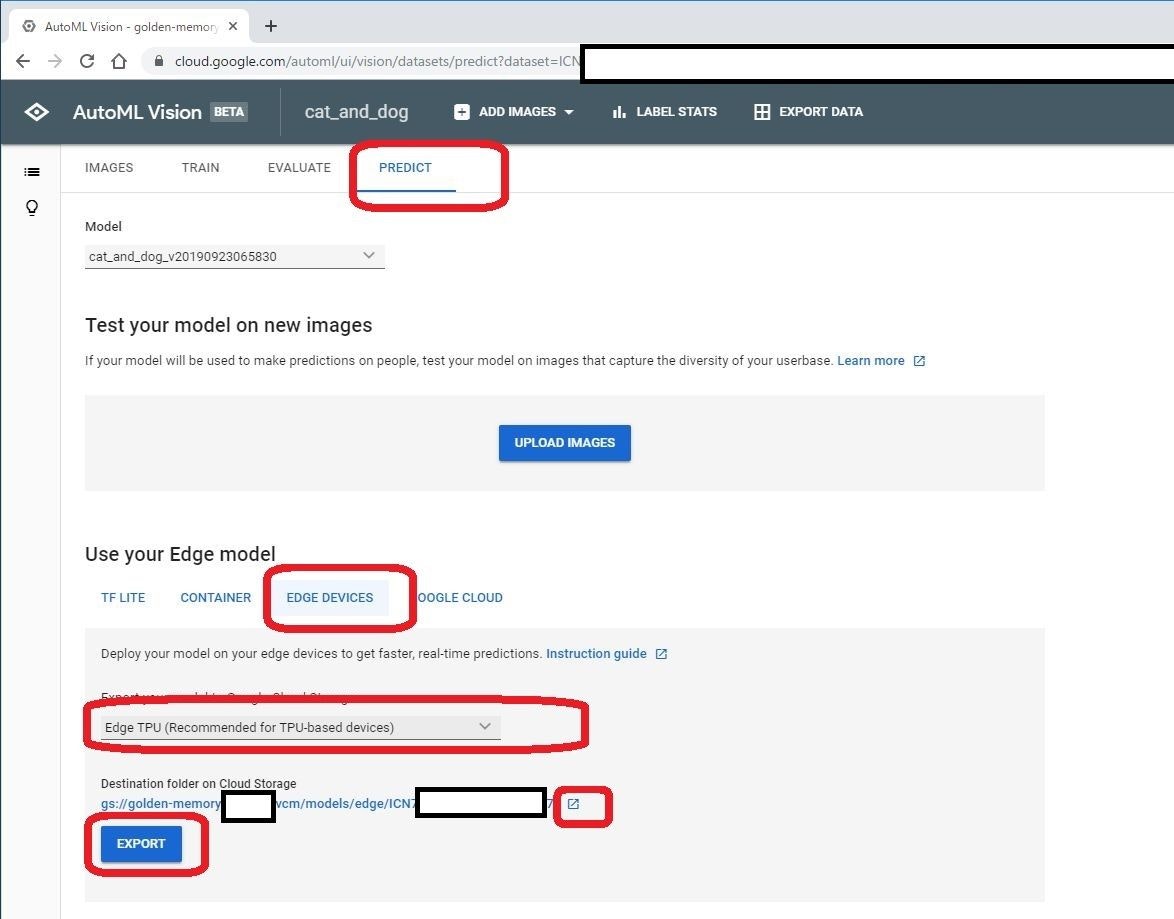
PREDICT タブに移ります
ここで、UPLOAD IMAGES をクリックして、色々な画像をアップロードして識別処理を試すことが出来ます。
下部のUse your Edge model で、実際に使用可能なモデルを出力します。
今回は、Edge TPU用のモデルが欲しいので、EDGE DEVICES を選びます。
その中のEdge TPU (Recommended for TPU-based devices) を選び、EXPORT します。
ボタン上部の、gs://xxx というリンクをクリックすると、モデルが出力されたストレージサーバが開きます。
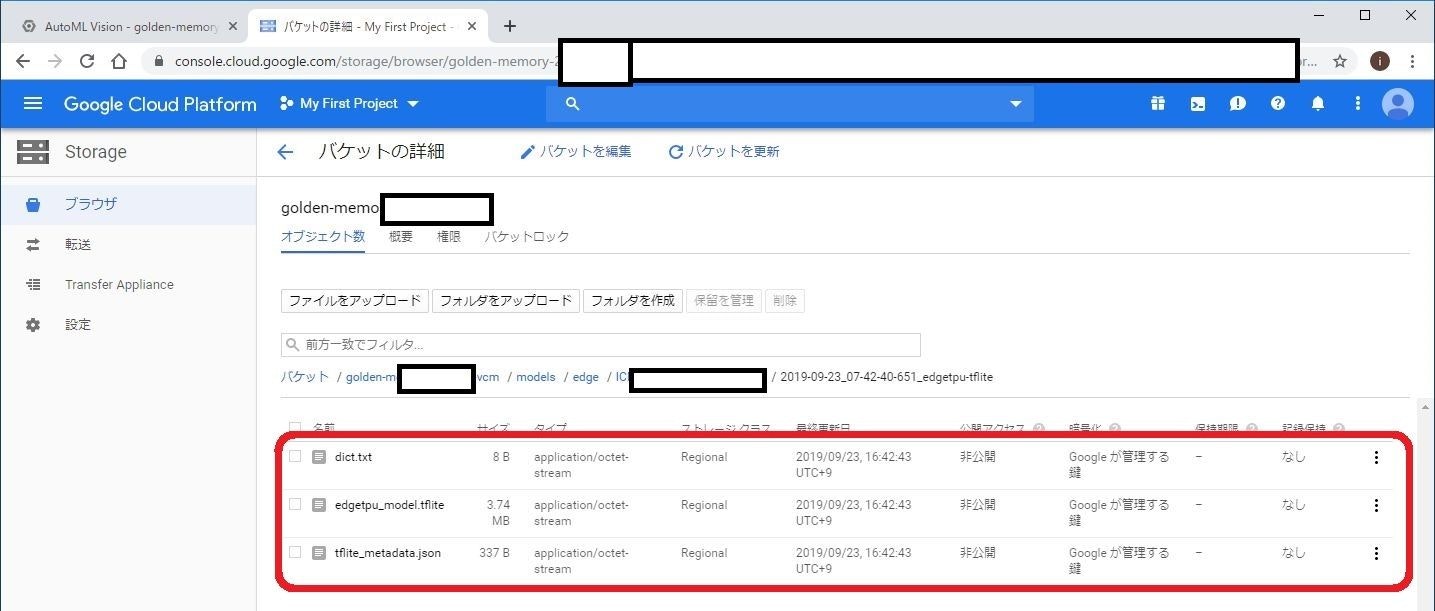
生成物は、Edge TPU用にコンパイルされたtfliteモデル(.tflite)、ラベル用テキストファイル(.txt)、モデル情報を記載したファイル(*.json)の3つです。
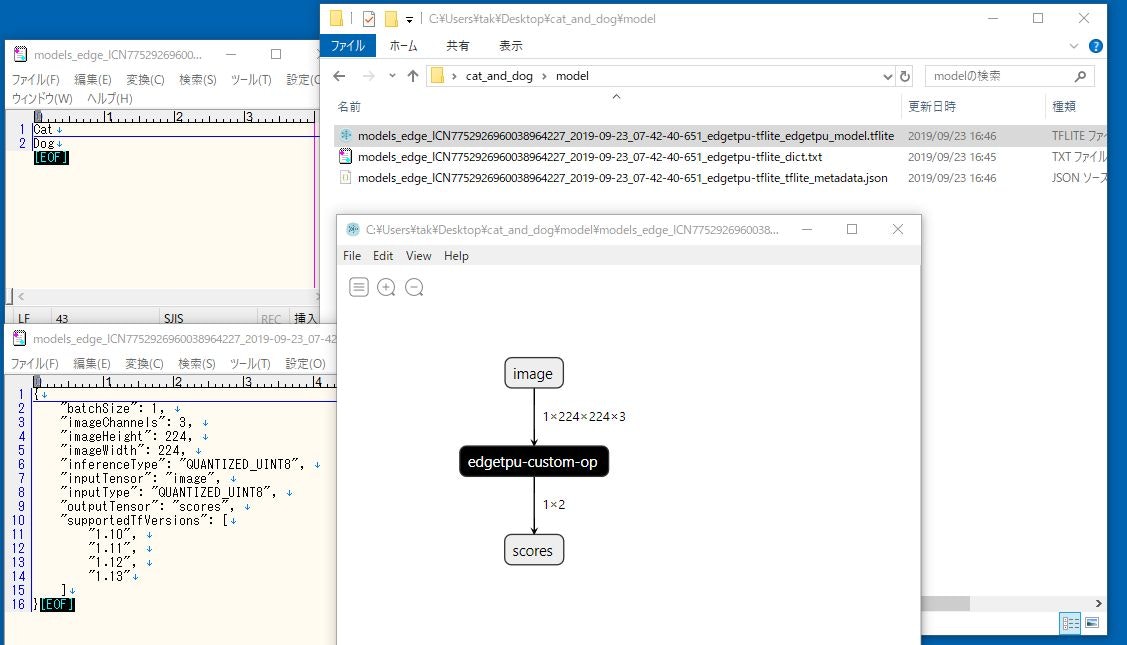
中身はこんな感じです。
ラベルは、0=Cat, 1 = Dogです。
モデルはいつも通り、edgetpu-custom-op になっています。が、先ほどのモデル出力するときに、EDGE DEVICES 用ではなくて、TF LITE を選択すれば通常のtfliteモデルが、CONTAINER を選択すればTensorflow用のpbファイルが出力されるため、モデル構造を確認することが出来ます。
モデルをCoral Dev Board上で使う
試す
まずは簡単なコードで、作成モデルを使用した推論を試します。
(Coral Dev Boardには、demo/classify_image.py が無いので、似たようなコードを自分で書きます。数行ですが。)
モデルとテスト画像をCoral Dev Boardにアップロードする
どういう手順でもいいです。SFTPツール使うのが一番簡単かもしれません。
ここでは、scpコマンドで転送します。ついでに、sshでCoral Dev Boardにログインします。僕はWindows上で作業しているので、msysで行いました。
事前に、出力されたtfliteモデルと、試したい画像(jpg)を、PC上の適当なフォルダに配置します。
cd path-to-model
scp * mendel@192.168.1.36:/home/mendel/.
ssh mendel@192.168.1.36
テストコードで試す
Python3のインタープリタ上で直接コードを書いてしまいます。
面倒なので、モデルとテスト画像も直指定しています。これらの名前は適宜変更してください。
mendel@orange-eft:~/$ python3
Python 3.5.3 (default, Sep 27 2018, 17:25:39)
[GCC 6.3.0 20170516] on linux
Type "help", "copyright", "credits" or "license" for more information.
from edgetpu.classification.engine import ClassificationEngine
from PIL import Image
engine = ClassificationEngine("models_edge_ICN7752926960038964227_2019-09-23_07-42-40-651_edgetpu-tflite_edgetpu_model.tflite")
img = Image.open("20190923_172910.jpg")
for result in engine.ClassifyWithImage(img, top_k=3):
print('---------------------------')
print('Label : ', result[0])
print('Score : ', result[1])
WARNING:root:From <stdin>:1: The name ClassifyWithImage will be deprecated. Please use classify_with_image instead.
---------------------------
Label : 0
Score : 0.882812
---------------------------
Label : 1
Score : 0.117188

今回使用したテスト画像は、上記のような猫画像です。
これに対して、ラベル0(つまり猫)の確率が88%だと出力されました。
無事、識別出来ているようです。
最終アプリケーションを作る
以下のような仕様のアプリケーションを作ります。
- カメラから画像読み込み
- OpenCV形式からPIL形式へ変換
- モデルへ入力
- 猫 or 犬の判定結果を出力
- 上記を繰り返す
OpenCVのインストール
Coral Dev BoardにOpenCVをインストールします。
--- 追記 (2020/02/12)
2020年2月現在は、sudo apt install libopencv-dev でインストールできます。
以下は、セルフビルドの場合です。
--- 追記ここまで
https://medium.com/@balaji_85683/installing-opencv-4-0-on-google-coral-dev-board-5c3a69d7f52f を参考にしました。
たまたまかもしれませんが、make時に並列オプション(-j2 など) を付けるとビルドに失敗しました。
OpenCVビルドのcmakeオプションには以下のようにしました。
cmake \
-D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D ENABLE_NEON=ON \
-D WITH_LIBV4L=ON \
-D WITH_V4L=ON \
-D BUILD_opencv_python3=ON \
-D OPENCV_PYTHON3_INSTALL_PATH=/usr/local/lib/python3.5/dist-packages \
-D INSTALL_PYTHON_EXAMPLES=ON \
..
また、ビルド設定が悪いせいかcv2.soを実行ディレクトリにコピーする必要がありました。
⇒cmakeの指定を見直したら正常にインストールできました (2019/09/24)
cp /usr/local/python/cv2/python-3.5/cv2.cpython-35m-aarch64-linux-gnu.so cv2.so
(例によって、このOpenCVのビルドが今回の全作業のなかで一番手間取りました。。。)
コード
以下のようなシンプルなPythonコードを実装し、モデルとラベルファイルと同じ場所に配置します。
また、ラベルファイルの各行の先頭に番号を付与しておきます。 (dataset_utils.read_label_file では不要)
0 Cat
1 Dog
import time
import cv2
from PIL import Image
from edgetpu.classification.engine import ClassificationEngine
from edgetpu.utils import dataset_utils
MODEL_FILENAME = "models_edge_ICN7752926960038964227_2019-09-23_07-42-40-651_edgetpu-tflite_edgetpu_model.tflite"
LABEL_FILENAME = "models_edge_ICN7752926960038964227_2019-09-23_07-42-40-651_edgetpu-tflite_dict.txt"
def cv2pil(image_cv):
image_cv = cv2.cvtColor(image_cv, cv2.COLOR_BGR2RGB)
image_pil = Image.fromarray(image_cv)
image_pil = image_pil.convert('RGB')
return image_pil
def classify_from_camera():
# Load model and prepare TPU engine
engine = ClassificationEngine(MODEL_FILENAME)
labels = dataset_utils.read_label_file(LABEL_FILENAME)
cap = cv2.VideoCapture(1)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
while True:
start = time.time()
# capture image
ret, img_org = cap.read()
# pil_img = cv2pil(cv2.resize(img_org, (224, 224)))
pil_img = cv2pil(img_org)
# Run inference
results = engine.classify_with_image(pil_img, threshold=0.5, top_k=1)
# Retrieve results
if results:
print ('-----------------------------------------')
for result in results:
print('Label : ', labels[result[0]])
print('Score : ', result[1])
cv2.putText(img_org,
"This is " + str(labels[result[0]]),
(50, 200),
cv2.FONT_HERSHEY_SIMPLEX,
3,
(0, 0, 255),
12)
# Measure time performance
cv2.putText(img_org,
"inference time = " + "{0:.2f}".format(engine.get_inference_time()) + "[msec]",
(20, 30),
cv2.FONT_HERSHEY_SIMPLEX,
1,
(0, 255, 0),
3)
elapsed_time = time.time() - start
cv2.putText(img_org,
"total time = " + "{0:.2f}".format(elapsed_time * 1000) + "[msec] (" + "{0:.1f}".format(1 / elapsed_time) + " fps)",
(20, 60),
cv2.FONT_HERSHEY_SIMPLEX,
1,
(0, 255, 0),
3)
# Draw the result
cv2.imshow('image', img_org)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cv2.destroyAllWindows()
if __name__ == '__main__':
classify_from_camera()
結果
USBカメラを接続して、以下コマンドで実行すると、本記事冒頭の動画のようになります。
python3 cat_dog_classification.py
推論時間は見積もり通り約3msecでした。
精度も、適当なGoogle検索をした画像をカメラで撮影してみましたが、精度よく識別できていました。ポメラニアン(?)など、かわいい系の犬は猫に誤認識されることがありました。
推論用関数に関して
2019のSptember Update以降、engine.ClassifyWithImage はwill be deprecated とwarningが出ます。そのため代わりにclassify_with_image を使いました。
ライブラリバージョンが古い環境では、今まで通りClassifyWithImageをご使用ください。
まとめ
Google Cloud AutoMLを使って、画像識別モデルを作りました。
注目すべきは、モデル作成時には1つのコードも書いていない点です。簡単なモデルであれば、非エンジニアでも作成できてしまいます。
(とはいえ実際には、画像を集めるためにクローリングしたり、効率よく分類するためにスクリプトを書いたりすると思いますが。)
今回は簡単のために、画像を直接アップロードして、ブラウザ上でラベル付けを行いました。
量が増えてくると、ローカルで作業してcsvを作成したり、GCPのスクリプトでラベル付けcsvを作成して、それを読み込む方が効率的だと思います。
作成したモデルを、Coral Dev Boardにデプロイして、猫と犬を識別するアプリケーションを作りました。
これは、あくまでサンプル(と個人の趣味)としてこうしただけでデプロイ先はラズパイでもいいですし、非Edge TPUなTensorFlowLiteを使っても良いですし、Web上でも大丈夫です。
最後に一言
ここまでお読みいただき、ありがとうございました。
せっかく本記事を読んでいただいたので、今すぐにでもAuto MLを試してみることをお勧めします。
本記事では、出来るだけ画像を多用し、分かりやすく記載したつもりです。
ですが、GCP AutoML上の操作方法や操作画面は今後変わる可能性があります。半年もしたら本記事の内容が全く役に立たなくなる可能性もあります。
今(2019/9/23)であれば、本記事をなぞるだけでモデル開発を簡単に体験することが出来ます。
半日もかからず終わりますので、少しでも興味のある方はぜひ試してみてください。
本業でDeep Learningに関わるかどうかに関係なく、少しでも経験したことがあるかないかというのは、大きな違いになるかと思います。