はじめに
スパムフィルターについて考えてみます。
スパムフィルターは下記のようなものです。
スパムフィルタとは、メールソフトやWebメールサービスの機能の一つで、
受信したメールの中から迷惑な広告などの
メール(スパムメール、迷惑メール)を検出して、
削除したり専用の保管場所に移したりすること。
また、そのような機能を提供するソフトウェア。
by IT用語辞典
受信したメールの中から、迷惑メールと迷惑メールではない二つのものに分類するためのフィルタになります。
では、どのようにして分類するのか?
→Scikit-learnにあるベイズフィルターを使用することで簡単に分類することができます。
処理の手順は下記です。

使用するデータ
使用するデータは、こちらになります
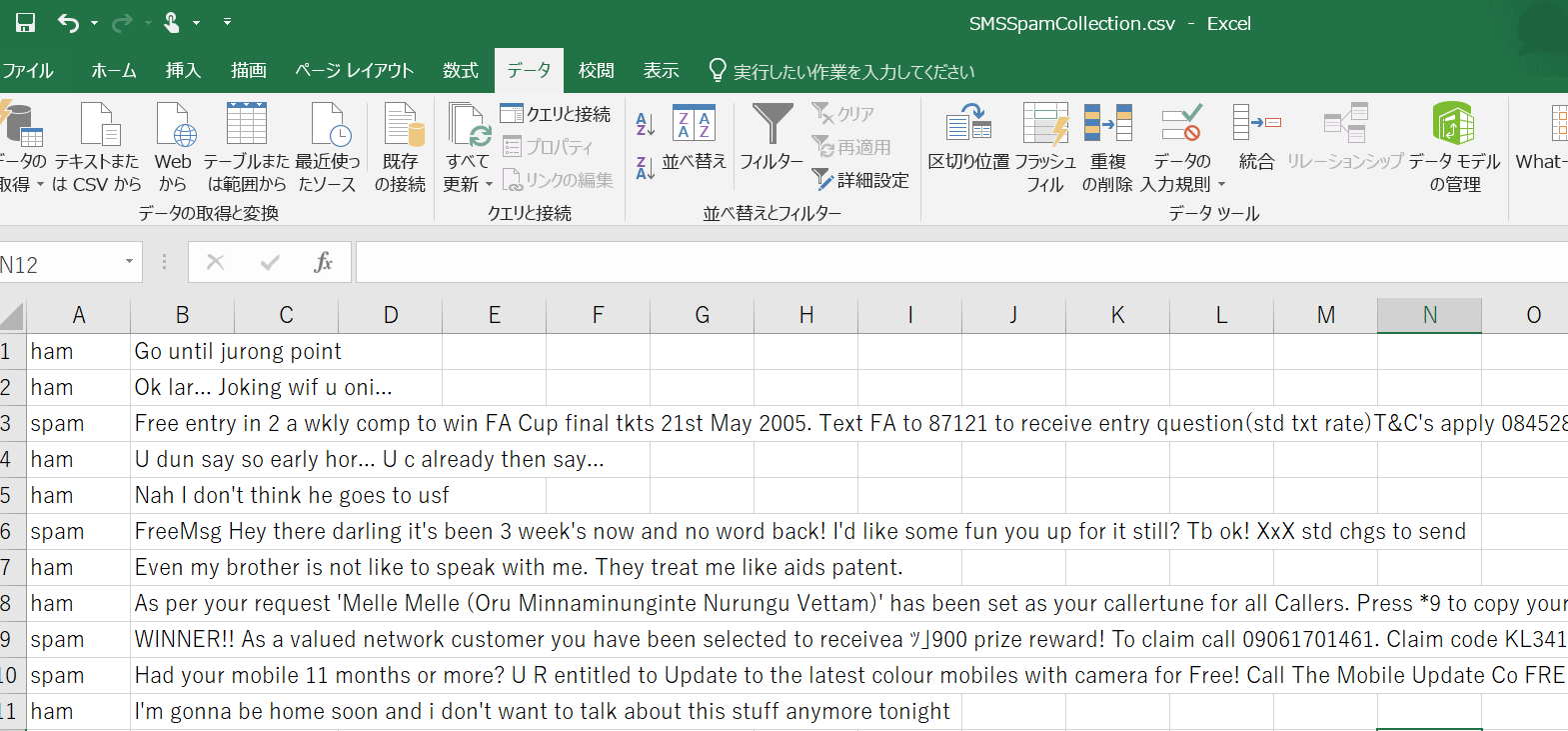
上記のように、それぞれの文章に対して、ham(迷惑メールではないメール)かspam(迷惑メール)の二つが区別されたデータになっています。全部で5572レコードあります。
コード
import numpy as np
import pandas as pd
import codecs
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
使用するパッケージをimportします。
from sklearn.feature_extraction.text import CountVectorizerは、データ内の単語をカウントし、特徴量を作成するために使用します。出現する単語をカウントするためのcountVectorizerインスタンスを生成します。
from sklearn.naive_bayes import MultinomialNB
は、ナイーブベイズをするために使用します。
from sklearn.model_selection import train_test_split
は、TrainデータとTestデータを分けるために使用します。
with codecs.open("hogehoge/SMSSpamCollection.csv",mode ="r", encoding= "Shift-JIS",errors="ignore") as file:
df = pd.read_table(file, delimiter="\t",header=None)
通常のpd.read_csvだとエラーが発生してしまったので、上記のような読み込み方をしています。
df.columns = ['class', 'message']
df = df.rename(columns={0:'class',1:'message'})
df.head(5)
with構文を使った読み込み方だと、カラムが0,1と書いてあるため、renameを使用してclassとmessageと変更します。

vectrozer = CountVectorizer()
counts = vectrozer.fit_transform(df['message'].values)
print(counts)
文書の単語をカウントするCountCVectorizer()のインスタンスを生成し、fit_transform関数を用いて各単語数を表すベクトルに変換しています。
classifier = MultinomialNB()
targets = df['class'].values
classifier.fit(counts,targets)
MultinomianNBの分類器を作成(classifier)し、単語のカウントと、classを表すデータを入れて訓練しています。
example = {'Earn 10000$!','Hi Bob!'}
example_counts = vectrozer.transform(example)
predictions = classifier.predict(example_counts)
predictions
exapmleに二つのメッセージを入れます。
このメッセージを、vetroroizerを使って、単語数のベクトルに変換し、classifierのpredict関数を使って、判定してみます。
結果は、どちらもhamでした。Earn 10000$!の方は、spamだと思うのですが、、、
TrainデータとTestデータに分けてやってみる。
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
with codecs.open("hogehoge/SMSSpamCollection.csv",mode ="r", encoding= "Shift-JIS",errors="ignore") as file:
df = pd.read_table(file, delimiter="\t",header=None)
ここまでは同じですが、次からちょっと変わっていきます。
X = df["message"]
Y = df["class"]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.7, test_size=0.3)
vecount = CountVectorizer(min_df=2)
vecount.fit(X_train)
Xにmessage,Yにclassを入れて、train_test_split関数を用いてX_train,X_test,Y_train,Y_testを作成します。
ちなみにprint(vecount)とすると下記のような結果になります。
CountVectorizer(analyzer='word', binary=False,
decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=2,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
どれだけの単語が取得できたのか、それぞれの単語のカウントは何なのかを知りたい場合は、下記のようにします。
print(len(vecount.vocabulary_))
print(dict(list(vecount.vocabulary_.items())))
vecount.vocabulary_はdict型です。
lenを使うと単語数がわかります。今回の場合は3306でした。
また、print(dict(list(vecount.vocabulary_.items()))) を使うことで下記のような出力結果が得られます。
{'had': 1368, 'your': 3293,
'mobile': 1930, '11mths': 83,
'update': 3045,'for': 1223,
'free': 1239, 'to': 2932,
'latest': 1687, 'colour': 761,
'camera': 645, 'mobiles': 1931,
'unlimited': 3037,
X_train_vec = vecount.transform(X_train)
X_test_vec = vecount.transform(X_test)
X_trainとX_testをベクトル化します。
ddf = pd.DataFrame(X_train_vec.toarray()[0:5],columns=vecount.get_feature_names())
ベクトル化した内容を見てみます。
model = MultinomialNB()
model.fit(X_train_vec,Y_train)
MultinomialNBの分類器を作成し、ベクトル化したX_train_vecとY_trainでモデルを作成します。
print("Train acc = %.3f" % model.score(X_train_vec,Y_train))
print("Test acc = %.3f" % model.score(X_test_vec,Y_test))
どれぐらいの精度なのか調べてみます。
Train acc = 0.991
Test acc = 0.983
でした。
最後に、文章を適用させてみます。
data = np.array(['He wrote Dictionaries.',
'Why am I always so slow',
'Free service! Please Ccontact me.'])
df_data = pd.DataFrame(data,columns=['message'])
df_data_vec = vecount.transform(df_data['message'])
array型で文章を作成し、dataframeに変換させ、vecountにて単語数ベクトルに変換しています。
model.predict(df_data_vec)
結果は、
array(['ham', 'ham', 'spam'], dtype='<U4')
でした。
終わりに
scikit-learnなどで処理する際、返り値の型を意識しておいたほうがいいなと思いました。
例えば、今回の場合はdict型などがあるように、色々な型で処理されることがわかりました。
また、各パッケージで処理した際、様々な関数が用意されています(.get_feature_names()など)
これも、よく使うものはリストにしてまとめておいたほうがいいなと思いました。