本ページは OCI: HPC Cluster のサブページになります。
Autoscaling 関連
Q: HPC Cluster v2.10.4.xにてクラスタの作成が失敗する
発生条件
- HPC Clusterの以下verを利用している
- v2.10.4
- v2.10.4.1
- Cluster Networkを利用している
条件に当てはまる場合、クラスタ生成時のログ/opt/oci-hpc/logs/create_*-*-*_YYYYMMDDHHMM.logに以下のエラーが記録されています。
null_resource.configure (local-exec): TASK [cloud-agent_update : Install OCA v1.37 for OL8] **************************
null_resource.configure: Still creating... [5m0s elapsed]
null_resource.configure (local-exec): An exception occurred during task execution. To see the full traceback, use -vvv. The error was: OSError: Could not open: /home/opc/.ansible/tmp/ansible-tmp-1711806282.4298182-358591-200976381407070/oracle-cloud-agent-1.37.2-10459.el8.x86_64qwr37e9r.rpm
null_resource.configure (local-exec): fatal: [inst-8gstc-BMcompute-1-hpc]: FAILED! => changed=false
null_resource.configure (local-exec): module_stderr: ''
null_resource.configure (local-exec): module_stdout: |-
null_resource.configure (local-exec): Traceback (most recent call last):
null_resource.configure (local-exec): File "/home/opc/.ansible/tmp/ansible-tmp-1711806282.4298182-358591-200976381407070/AnsiballZ_dnf.py", line 107, in <module>
null_resource.configure (local-exec): _ansiballz_main()
null_resource.configure (local-exec): File "/home/opc/.ansible/tmp/ansible-tmp-1711806282.4298182-358591-200976381407070/AnsiballZ_dnf.py", line 99, in _ansiballz_main
null_resource.configure (local-exec): invoke_module(zipped_mod, temp_path, ANSIBALLZ_PARAMS)
null_resource.configure (local-exec): File "/home/opc/.ansible/tmp/ansible-tmp-1711806282.4298182-358591-200976381407070/AnsiballZ_dnf.py", line 48, in invoke_module
null_resource.configure (local-exec): run_name='__main__', alter_sys=True)
null_resource.configure (local-exec): File "/usr/lib64/python3.6/runpy.py", line 205, in run_module
null_resource.configure (local-exec): return _run_module_code(code, init_globals, run_name, mod_spec)
null_resource.configure (local-exec): File "/usr/lib64/python3.6/runpy.py", line 96, in _run_module_code
null_resource.configure (local-exec): mod_name, mod_spec, pkg_name, script_name)
null_resource.configure (local-exec): File "/usr/lib64/python3.6/runpy.py", line 85, in _run_code
null_resource.configure (local-exec): exec(code, run_globals)
null_resource.configure (local-exec): File "/tmp/ansible_ansible.legacy.dnf_payload_onv1gwkn/ansible_ansible.legacy.dnf_payload.zip/ansible/modules/dnf.py", line 1447, in <module>
null_resource.configure (local-exec): File "/tmp/ansible_ansible.legacy.dnf_payload_onv1gwkn/ansible_ansible.legacy.dnf_payload.zip/ansible/modules/dnf.py", line 1436, in main
null_resource.configure (local-exec): File "/tmp/ansible_ansible.legacy.dnf_payload_onv1gwkn/ansible_ansible.legacy.dnf_payload.zip/ansible/modules/dnf.py", line 1410, in run
null_resource.configure (local-exec): File "/tmp/ansible_ansible.legacy.dnf_payload_onv1gwkn/ansible_ansible.legacy.dnf_payload.zip/ansible/modules/dnf.py", line 1068, in ensure
null_resource.configure (local-exec): File "/tmp/ansible_ansible.legacy.dnf_payload_onv1gwkn/ansible_ansible.legacy.dnf_payload.zip/ansible/modules/dnf.py", line 968, in _install_remote_rpms
null_resource.configure (local-exec): File "/usr/lib/python3.6/site-packages/dnf/base.py", line 1317, in add_remote_rpms
null_resource.configure (local-exec): raise IOError(_("Could not open: {}").format(' '.join(pkgs_error)))
null_resource.configure (local-exec): OSError: Could not open: /home/opc/.ansible/tmp/ansible-tmp-1711806282.4298182-358591-200976381407070/oracle-cloud-agent-1.37.2-10459.el8.x86_64qwr37e9r.rpm
null_resource.configure (local-exec): msg: |-
null_resource.configure (local-exec): MODULE FAILURE
null_resource.configure (local-exec): See stdout/stderr for the exact error
null_resource.configure (local-exec): rc: 1
本問題は/opt/oci-hpc/playbooks/new_nodes.ymlファイルの修正が必要になります。
修正前に以下のようにバックアップを取得してください。
cd /opt/oci-hpc/playbooks/
cp -a new_nodes.yml new_nodes.yml.org
修正点はnew_nodes.ymlファイルの49行から51行です。この3行を削除します。
修正前:

修正後:
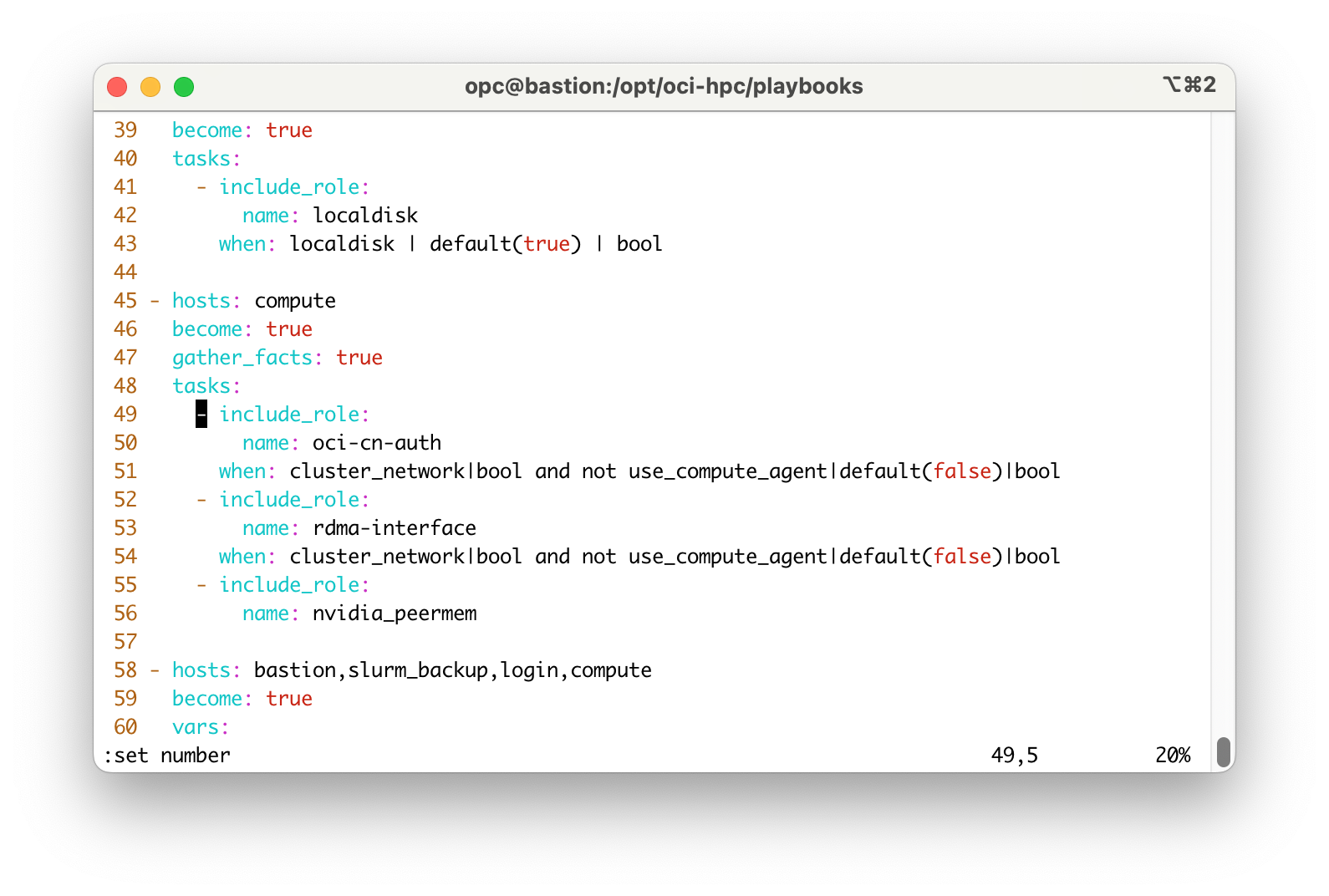
修正後のdiffは以下のようになります。
[opc@bastion playbooks]$ diff new_nodes.yml new_nodes.yml.org
49a50,52
> name: cloud-agent_update
> when: cluster_network|bool and use_compute_agent|default(false)|bool
> - include_role:
修正が完了したら再度ジョブを投入し、クラスタが正しく作成され、ジョブが投入できるか確認をします。
Q: queues.conf を修正後、/opt/oci-hpc/bin/slurm_config.sh を実行したらエラーになった
エラーの内容としては以下を想定します。slurm_config.shの実行にてreconfigure slurmタスクがFAILEDしています。
[opc@bastion bin]$ ./slurm_config.sh
PLAY [bastion,slurm_backup,compute,login] *****************************************************************************************************************************************
TASK [Gathering Facts] ************************************************************************************************************************************************************
ok: [bastion]
〜省略〜
TASK [slurm : move topology.conf on backup slurm controller] **********************************************************************************************************************
skipping: [bastion]
RUNNING HANDLER [slurm : reconfigure slurm] ***************************************************************************************************************************************
FAILED - RETRYING: [bastion -> 127.0.0.1]: reconfigure slurm (5 retries left).
FAILED - RETRYING: [bastion -> 127.0.0.1]: reconfigure slurm (4 retries left).
FAILED - RETRYING: [bastion -> 127.0.0.1]: reconfigure slurm (3 retries left).
FAILED - RETRYING: [bastion -> 127.0.0.1]: reconfigure slurm (2 retries left).
FAILED - RETRYING: [bastion -> 127.0.0.1]: reconfigure slurm (1 retries left).
fatal: [bastion -> 127.0.0.1]: FAILED! => changed=true
attempts: 5
cmd:
- scontrol
- reconfigure
delta: '0:00:09.005121'
end: '2024-03-27 05:18:44.785001'
msg: non-zero return code
rc: 1
start: '2024-03-27 05:18:35.779880'
stderr: 'slurm_reconfigure error: Unable to contact slurm controller (connect failure)'
stderr_lines: <omitted>
stdout: ''
stdout_lines: <omitted>
NO MORE HOSTS LEFT ****************************************************************************************************************************************************************
PLAY RECAP ************************************************************************************************************************************************************************
bastion : ok=56 changed=7 unreachable=0 failed=1 skipped=75 rescued=0 ignored=0
以下の手順を実行してSlurmのステータスをクリアしてslurmctldを起動します。
opcユーザーからrootにスイッチする
sudo su -
以下のディレクトリに移動して、stateを保持しているファイルを削除する
cd /nfs/cluster/spool/slurm/
/usr/bin/rm node_state* part_state*
slurmctldを起動する
systemctl start slurmctld
slurmctldサービスが問題なく起動されたか確認をする
[root@bastion slurm]# systemctl status slurmctld
● slurmctld.service - Slurm controller daemon
Loaded: loaded (/usr/lib/systemd/system/slurmctld.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/slurmctld.service.d
└─unit.conf
Active: active (running) since Wed 2024-03-27 05:22:40 GMT; 4min 50s ago
Docs: man:slurmctld(8)
Process: 25931 ExecStart=/usr/sbin/slurmctld $SLURMCTLD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 25933 (slurmctld)
Tasks: 18
Memory: 392.6M
CGroup: /system.slice/slurmctld.service
├─25933 /usr/sbin/slurmctld -R
└─25934 slurmctld: slurmscriptd
Mar 27 05:22:40 bastion systemd[1]: Starting Slurm controller daemon...
Mar 27 05:22:40 bastion systemd[1]: slurmctld.service: Can't open PID file /run/slurmctld.pid (yet?) after start: No such file or directory
Mar 27 05:22:40 bastion systemd[1]: Started Slurm controller daemon.
sinfoやsqueueなどコマンドが返ってくることを確認する
[root@bastion slurm]# sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
compute* up infinite 0 n/a
[root@bastion slurm]# squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
Slurm 関連
Q: 計算ノードを reboot したところそのノードにジョブが入らなくなりました
Slurm はノードを reboot させた場合、STATE が down となります。
bastion にて以下のコマンドで idle に戻してください。
sudo scontrol update NodeName=<nodename> state=resume