はじめに
OCIで新しいIntel CPUベース(Granite Rapids世代)のシェイプVM.Standard4.Ax.Flexが利用できるようになりました(AshburnとPhoenixで確認済み)。
公式ブログ、ドキュメントについては以下をご確認ください。
ブログ内では前世代と比較した強化ポイントとして、IPCとメモリ帯域の向上やIntel AMXによるAI推論性能の向上などが挙げられています。
本記事では、上記ブログで言及されていた以下の3点について、実際にベンチマークを実行して前世代と比較してみます。
- IPC / CPU性能
- メモリ帯域
- AMX命令セットによる LLM 推論性能
比較対象は以下の2つです。
| Shape | 位置づけ |
|---|---|
| VM.Standard3.Flex | 1世代前の Intel Shape |
| VM.Standard4.Ax.Flex | 新しい Intel Shape |
検証内容
今回使用したベンチマークは以下です。
| 観点 | 使用ツール | 確認したいこと |
|---|---|---|
| IPC / CPU性能 | UnixBench | 汎用的なCPU性能の差 |
| メモリ帯域 | STREAM | メモリ帯域の差 |
| AMX | llama.cpp | AMX有効時のLLM推論性能 |
IPC/メモリ帯域 性能
UnixBench
まずはUnixBenchを使って、CPU性能を比較します。
なお、UnixBenchはIPCそのものを直接測定するベンチマークではありません。ただし、同じ条件で Shape 間の比較を行うことで、CPU世代差による汎用的な処理性能の傾向を見ることができます。
そのため、本記事ではIPCを含めたCPU性能の参考値としてUnixBenchを使用しています。
スペック
UnixBench は、以下の条件で実行しました。
| Shape | Core | Memory (GB) |
|---|---|---|
| VM.Standard3.Flex | 1 | 16 |
| VM.Standard4.Ax.Flex | 1 | 16 |
OS Image: Oracle-Linux-9.7-2026.03.31-0
実行方法
sudo yum -y install perl perl-Time-HiRes make gcc
wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/byte-unixbench/UnixBench5.1.3.tgz
tar xf UnixBench5.1.3.tgz
cd UnixBench/
./Run
結果
1 core / 2 threads の結果です。
トータルスコア, Index Score
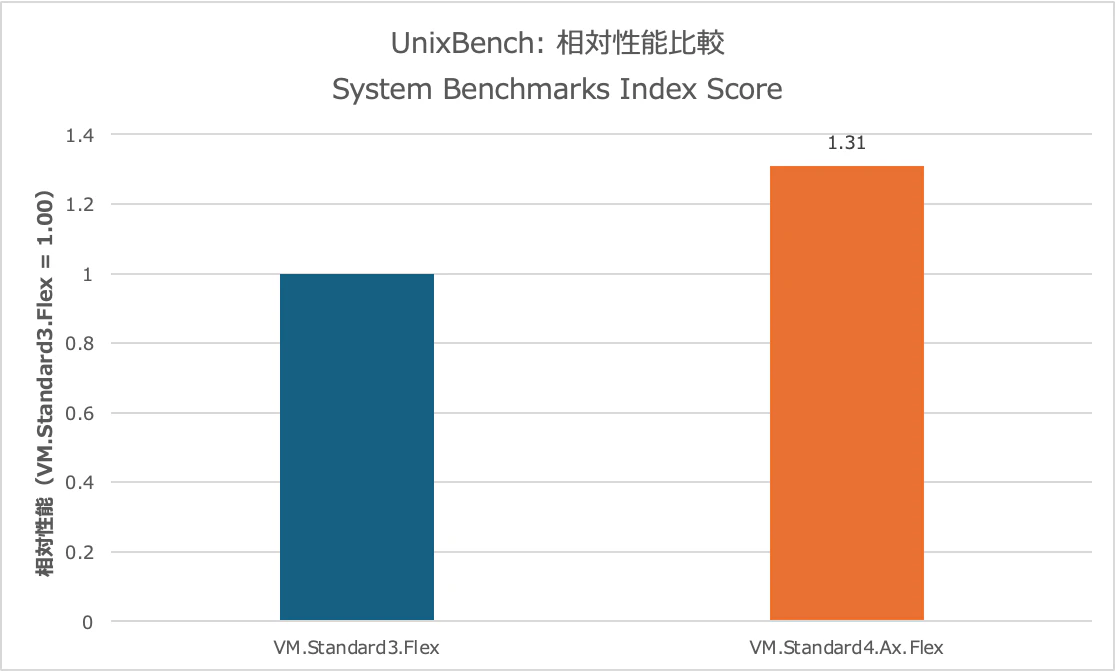
新しいので当然ではありますが、、トータルスコアではVM.Standard4.Ax.FlexのほうがVM.Standard3.Flexより高い結果となりました。
UnixBench の Index Score は、整数演算、浮動小数点演算、プロセス生成、ファイルコピー、シェルスクリプト実行など、複数のサブテストを総合したスコアです。
そのため、この結果は「IPCだけの差」として見るのではなく、Linux 環境における汎用的な処理性能の差 として見るのがよいですね。
個別スコア
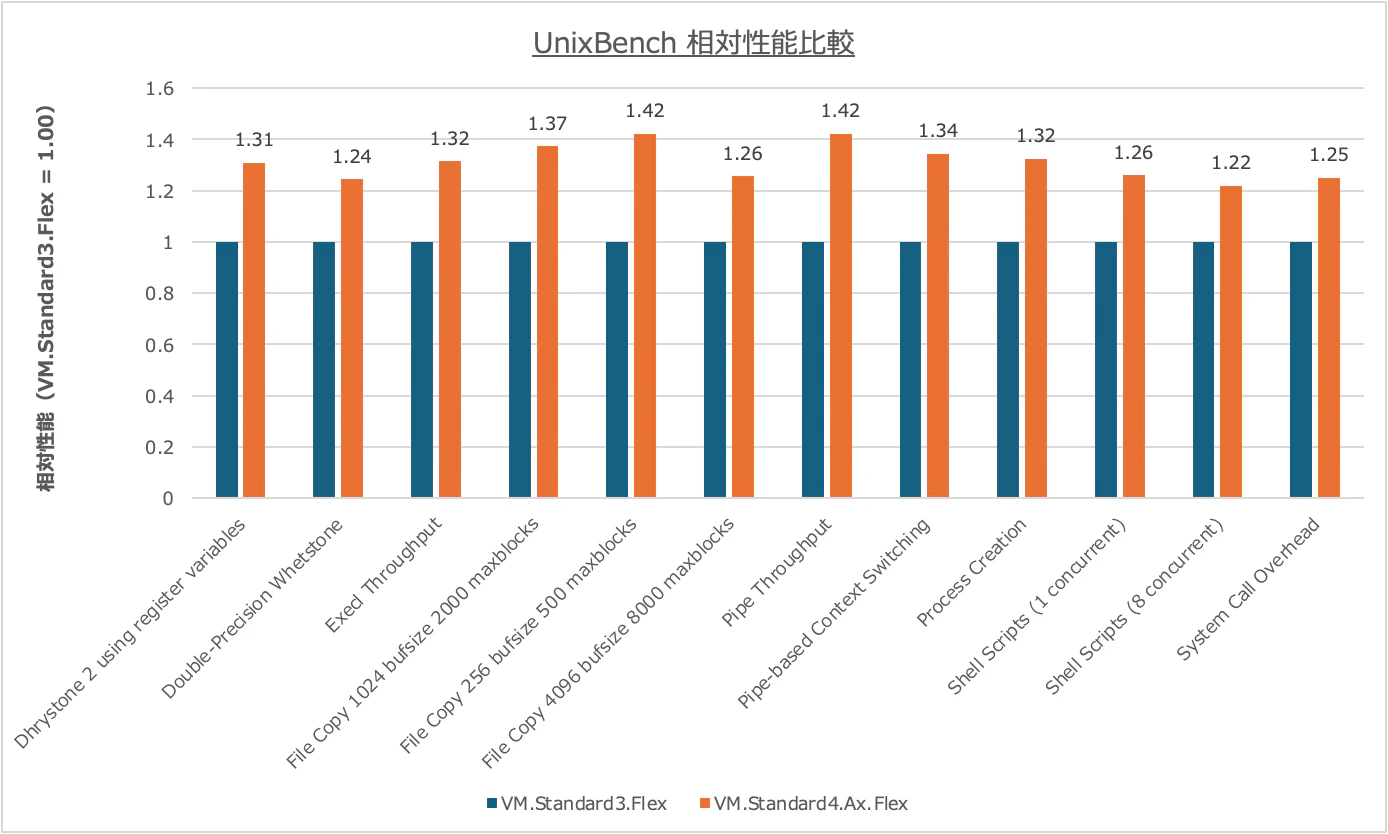
個別スコアを見ると、どの処理で差が出ているかを確認できます。
ここでも概ねそれぞれの値が1.3倍前後となっているので、想定される性能差ではないでしょうか。
メモリ帯域
Oracle の公式ブログでは、前世代と比較してメモリチャネルや DDR5 の速度向上により、メモリ帯域の向上が説明されています。
STREAM
STREAM は、メモリ帯域を測定するためによく使われるベンチマークです。
Copy, Scale, Add, Triad の4種類の処理を実行し、それぞれのメモリ帯域を MB/s で確認できます。
スペック
両インスタンスのスペックは以下のようにしました。
VM.Standard4.Ax.FlexのベアメタルシェイプBM.Standard4.Ax.120は120coreでNPS6であるため、NPSあたり20coreであることを考慮してそれ以下でキリの良い16coreとしました。
| Shape | Core | Memory, GB |
|---|---|---|
| VM.Standard3.Flex | 16 | 64 |
| VM.Standard4.Ax.Flex | 16 | 64 |
OS Image: Oracle-Linux-9.7-2026.03.31-0
コンパイル
wget http://www.cs.virginia.edu/stream/FTP/Code/stream.c
gcc -O \
-mcmodel=large \
-DSTREAM_ARRAY_SIZE=800000000 \
-fopenmp \
-march=native \
stream.c \
-o stream
実行
export OMP_NUM_THREADS=32
export OMP_PROC_BIND=TRUE
./stream
結果

今回の条件では、VM.Standard4.Ax.Flex のほうが全項目で高いメモリ帯域 となりました。
STREAMの結果でもVM.Standard4.Ax.Flexでのメモリ帯域の改善を確認できました。
AMX
最後に、Intel AMX の効果を確認します。
AMX(Advanced Matrix Extensions)は、行列演算を高速化するための拡張命令セットです。
LLM 推論、画像認識、レコメンド、自然言語処理など、AI 系ワークロードで使われる行列演算の高速化に利用できます。
今回は VM.Standard4.Ax.Flex 上で llama.cpp をビルドし、以下の3パターンを比較しました。
- AVX無効
- AVX有効
- AMX有効
スペック
| Shape | Core | Memory (GB) |
|---|---|---|
| VM.Standard4.Ax.Flex | 8 | 64 |
OS Image: Oracle-Linux-10.1-2026.04.30-1
llama.cpp のビルド
AVX無効
まず、AVX 系の命令セットを無効化したビルドです。
cmake -B build-noavx \
-DCMAKE_BUILD_TYPE=Release \
-DGGML_NATIVE=OFF \
-DGGML_SSE42=OFF \
-DGGML_AVX=OFF \
-DGGML_AVX2=OFF \
-DGGML_AVX_VNNI=OFF \
-DGGML_AVX512=OFF \
-DGGML_AVX512_VBMI=OFF \
-DGGML_AVX512_VNNI=OFF \
-DGGML_AVX512_BF16=OFF \
-DGGML_FMA=OFF \
-DGGML_F16C=OFF \
-DGGML_BMI2=OFF \
-DGGML_AMX_TILE=OFF \
-DGGML_AMX_INT8=OFF \
-DGGML_AMX_BF16=OFF
cmake --build build-noavx -j
AVX有効
次に、AVX-512 と VNNI を有効化し、AMX は無効化したビルドです。
cmake -B build-noamx \
-DGGML_NATIVE=OFF \
-DGGML_AVX512=ON \
-DGGML_AVX512_VNNI=ON \
-DGGML_AMX_TILE=OFF \
-DGGML_AMX_INT8=OFF \
-DGGML_AMX_BF16=OFF
cmake --build build-noamx -j
AMX有効
最後に、AMX TILE, AMX INT8, AMX BF16 を有効化したビルドです。
cmake -B build-amx \
-DGGML_NATIVE=OFF \
-DGGML_AVX512=ON \
-DGGML_AVX512_VNNI=ON \
-DGGML_AMX_TILE=ON \
-DGGML_AMX_INT8=ON \
-DGGML_AMX_BF16=ON
cmake --build build-amx -j
実行
以下のように llama-cli を実行しました。
./build-noavx/bin/llama-cli \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
-cnv \
-t 8
プロンプトは以下を使用しました。
AMX命令がLLM推論を高速化する理由を日本語で説明してください。
同じ条件で、AVX無効、AVX有効、AMX有効の3パターンを実行し、Prompt processing と Generation の tokens/sec を比較します。
結果比較
| ビルドパターン | Prompt, t/s | Generation, t/s |
|---|---|---|
| AVXなし | 9.4 | 3.7 |
| AVXあり | 11.7 | 3.6 |
| AMX有効 | 16.9 | 3.9 |
Prompt processing では、AMX 有効時に大きな性能向上が見られました。
AVXなしと比較すると、以下のようになります。
16.9 / 9.4 = 約1.80倍
AVXありと比較すると、以下のようになります。
16.9 / 11.7 = 約1.44倍
一方で、Generation の tokens/sec は大きく変わりませんでした。
これは、LLM 推論における Prompt processing と Generation の処理特性の違いによるものと考えられます。
Prompt processing では、入力されたトークン列をまとめて処理するため、行列演算の並列性を活かしやすく、AMX の効果が出やすいと考えられます。
一方、Generation は基本的に 1 token ずつ逐次的に生成していく処理になるため、Prompt processing ほど AMX の効果が出にくいと考えられます。
今回の結果では、AMX は特に プロンプト処理の高速化 に効果があることが確認できました。
まとめ
今回は、OCI の Intel CPU ベースの Shape である VM.Standard3.Flex と VM.Standard4.Ax.Flex を比較しました。
確認した内容は以下です。
| 観点 | 結果 |
|---|---|
| UnixBench | VM.Standard4.Ax.Flex のほうが高いスコア |
| STREAM | VM.Standard4.Ax.Flex が全項目で向上 |
| AMX | Prompt processing が大きく高速化 |
UnixBench/STREAMにおいて、VM.Standard4.Ax.Flex のほうが高いスコアとなり、汎用的な CPU 性能の向上が確認できました。
またAMXの効果はかなり分かりやすく出ました。
llama.cpp を使ったLLM推論では、AMX有効時にPrompt processingがAVXなし比で約1.8倍、AVXあり比で約1.4倍となりました。
おわりに
VM.Standard4.Ax.Flex は、単純なCPU性能やメモリ帯域だけでなく、Intel AMXによるAI系ワークロードの高速化が期待できるShapeであることが確認できました。