Pythonの学習を兼ねて、自分の興味のあるサイトをスクレイピングしました。
本格的なプログラミング未経験でも割とスグにできた内容なので、
未熟ですが備忘録も兼ね、現時点でわかったことを記載します。
スクレイピングとは
Webサイトから情報を抽出することを指します。
大量のデータであっても抽出を手間なく、自動で実行できるのがメリットです。
やりたいこと(今回の例題)
架空のラーメン屋のメニューを取得し、JSONに格納し、保存します。
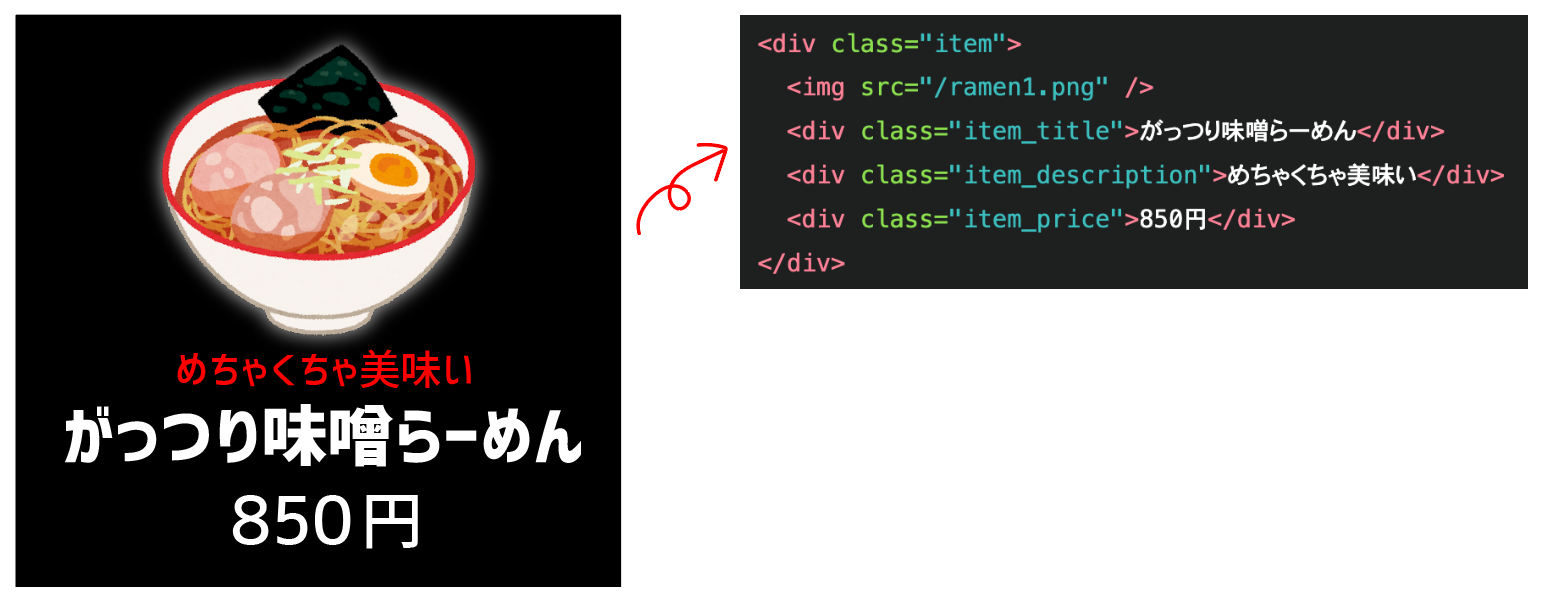
<div class="item">
<img src="/ramen1.png" />
<div class="item_title">がっつり味噌らーめん</div>
<div class="item_description">めちゃくちゃ美味い</div>
<div class="item_price">850円</div>
</div>
スクレイピングの注意点
・サイトの利用規約やrobots.txtファイルを確認し、法律・道徳の許す範囲で行うこと。
・取得先のサーバーに負荷をかけないよう、適切な待機時間を設けること。
前提
・[必須]Pythonのインストール
参考記事
Pythonには主要なバージョンで「Python」と「Python3」が存在し、
同時にインストールすると複雑なことになるため片方のみが推奨です。
・[必須]必要ライブラリのインストール
コマンドプロンプトもしくはターミナルを開いて以下のコマンドを実行してください。
(Python3のコード例を記載)
pip3 install pandas
pip3 install tkinter
・[推奨]VSCodeのインストール
参考記事
必須ではないですが、メモ帳などに記載していくよりはこちらの方が快適です
完成品
早速作っていきます。
VSCodeやメモ帳にて新規ファイルを作成し、下記のように記載し、拡張子を「.py」にして保存します。
# 各種モジュールのインポート
import requests
from bs4 import BeautifulSoup
import json
import re
import time
import random
# 5秒の待機時間を設定する
time.sleep(5)
# 空のリストを作成
result = []
# ラーメン屋A
target_url = 'スクレイピングするサイトページのURL'
# requests.get()を用いてメソッドでリクエストを送信
res = requests.get(target_url)
# レスポンスのエンコーディングを自動的に推測するメソッドを利用
res.encoding = res.apparent_encoding
# 取得したHTML文字列をBeautifulSoupオブジェクトに変換
soup = BeautifulSoup(res.content, 'html.parser')
# クラス「item」をまるごと取得
elements = soup.find_all('div', class_='item')
# for文でリストを処理
for elements in elements:
# ラーメン名の取得 取得できない場合はnoneを返す
name_elements = elements.find(class_='item_title')
name = name_elements.text if name_elements else None
# 説明文の取得 取得できない場合はnoneを返す
description_elements = elements.find(class_='item_description')
description = description_elements.text if description_elements else None
# 料金の取得 取得できない場合はnoneを返す
price_elements = elements.find(class_='item_price')
price = price_elements.text if price_elements else None
# 写真の取得 取得できない場合はnoneを返す また、前方にドメインをつける
photo_elements = elements.find('img')
photo = '前方ドメイン' + photo_elements['src'] if photo_elements else None
# 店名は共通のため決め打ちで挿入
shop_name = 'ラーメン屋の名前を一括挿入'
# 全取得結果をresultに出力
result.append({
'name': name,
'description': description,
'price': price,
'photo': photo,
'photo': shop_name
})
# resultをJSON形式でファイルに書き込む
with open('ramen-result.json', 'w') as f:
json.dump(result, f, ensure_ascii=False, indent=4)
# jsonファイルを読み込んで中身を表示
with open('ramen-result.json', 'r') as f:
print(f.read())
記載した保存し、ターミナルやコマンドプロンプトから
python3 [ファイル名].py
と入力することで実行できます。
※pythonのバージョンによっては3は不要
※ターミナルでの実行場所はその.pyファイルが有る場所を指定してください。
結果、.pyファイルと同じ場所にresult.jsonが保存されます。
また、無事に取得できればこの場合、下記の様になっていると思います。
{
"name": "がっつり味噌らーめん",
"description": "めちゃくちゃ美味い",
"price": "850円",
"photo": "前方ドメイン/ramen01.png",
"shop_name": "ラーメン屋の名前を一括挿入"
}
コツ
いきなり全てのコードを書かない
私が遭遇した問題ですが、デベロッパーツールでは普通に取れていても、
実行してみると上手く成功しませんでした。
複数の問題で1日程度苦戦したのですが結果は、
JavaScriptによってHTMLが生成される場合には機能しないこともある。
その場合はSeleniumといったツールを使用する必要がある。
ということと、
リストを回す中で取得できないときが存在する場合、if文を用意してelseで"none"を返すようにしないとエラーが発生する。
でした。
これらのことに気付かずムダな時間を過ごさないためにも、すべてのコードを一度に記述せず、最初にBeautifulSoupで取得したものをprintで表示し、少しずつ追加していく方が書きやすそうです。
デベロッパーツールと実際に取得しているhtmlが違ったりもするので、セレクタ以降で間違えることを避けるためにもその方が安心です。
メソッド一覧
サイト毎に調整が必要で少し面倒なのが、メソッドで要素を絞る部分です。
前述通りsoupの取得結果をprintで表示したり、ChromeでデベロッパーツールをF12で表示させて、要素を見ながら置いていくのがベターです。
このとき用いる、メソッドは少し複雑なのでよく使うものを下記にまとめています。
| メソッド名 | 説明 |
|---|---|
| find() | 引数に指定したタグを最初に見つけた要素を返す。 |
| find_all() | 引数に指定したタグをすべて含む要素をリストで返す |
| select() | CSSセレクタを用いて要素を取得する |
| get() | 指定した属性の値を取得する |
| text | 要素のテキストを取得する |
| contents | 要素の子要素をリストで取得する |
| parent | 要素の親要素を取得する |
| children | 要素の子要素をイテレータで取得する |
| next_sibling | 要素の次の兄弟要素を取得する |
| previous_sibling | 要素の前の兄弟要素を取得する |
■特に基本のもの例
find()
指定されたタグを検索して、最初に見つかった要素を返します
例:soup.find('div')は、HTMLドキュメント内の最初の <div>要素を取得
find_all()
指定されたタグを検索して、すべての要素をリストで返します。
例:soup.find_all('div')は、HTMLドキュメント内のすべての <div>要素を取得
状況にあわせてこれらのメソッドの引数に要素やクラス名を入れて用いることが多いと思います。
例えば、
find(class_='hoge') hogeクラスを取得。要素は問わない。
find('div', {'class': 'hoge'}) div要素のhogeクラスを取得。
また、.textを用いることでタグに挟まれているテキストを取得したり、
['href']や['alt']を用いることでその要素を絞って抜き出すことも可能です。
次回予告
保存したJSONファイルを加工した上で、webサイト上に出力したいと思います。