はじめに
Workatoでリストを特定行数でバッチ処理行いたい場合、Repeat for eachのRepat modeを「Batch of items」に設定し、Batch sizeを任意の処理件数で一括処理を行えます。
それによりリストのデータをCSVで1000件区切りに出力したりなどが実現可能です。
しかしリストに特定の親となるキー項目と明細行を持ち、データ分割した時にそのキーを分離してはならないとなった時に上記のバッチ処理は実現が困難になります。
今回はSQL Collectionで関数を使い、特定の行数かつ特定のキーがバッチ処理で分離せず処理する方法を説明します。
ユースケース
スプレッドシートに以下のような店舗ごとの売上データを持っており、今回の例では約2500件ほどのデータ量とします。
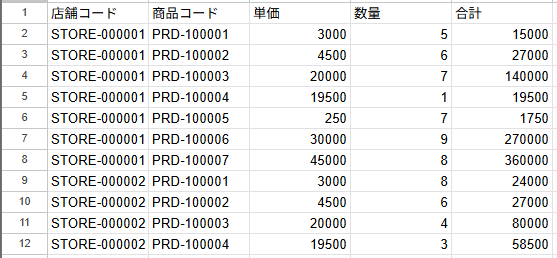
売上データをCSVに変換してシステムにインポートするためには、以下の制約を持っています。
・一括インポートは1000件以下
・店舗コードはファイルを分離してインポートしてはならない
まずはシンプルにRepeat for eachのRepat modeを「Batch of items」に設定し、Batch sizeを1000件にしてCSVを出力するレシピを作って出力する事とします。
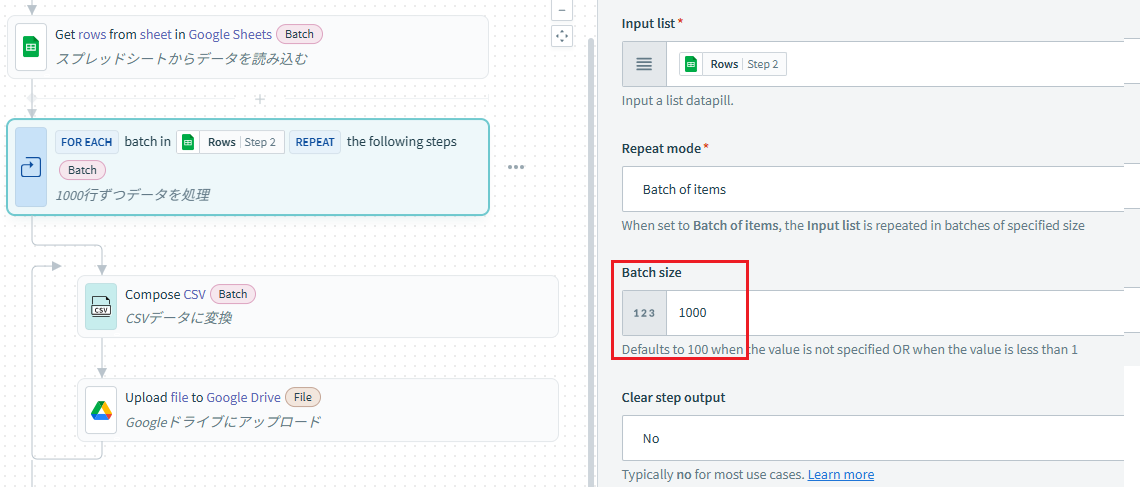
約2500件のデータを1000件区切りに出力したため、3ファイル作成される事となります。
その結果がこちら。
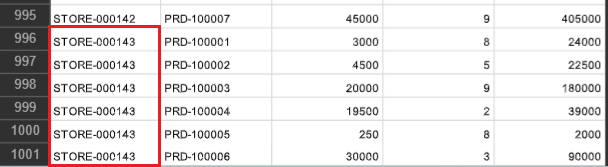
・1ファイル目の最終行
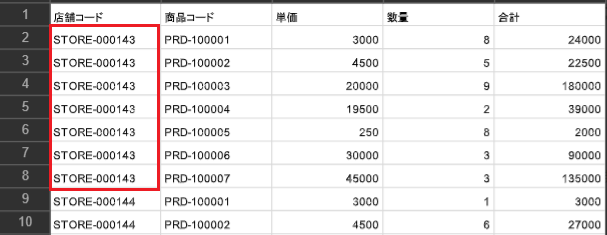
・2ファイル目の先頭行
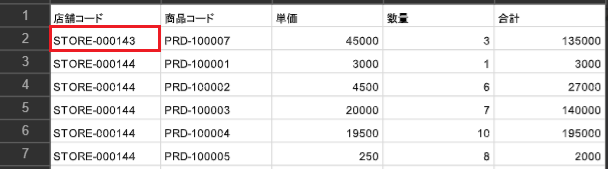
この場合、店舗コード「STORE-000143」が1ファイル目と2ファイル目に分かれているため、制約に対して結果はNGとなります。
SQL Collectionと関数を駆使してデータ分析のための情報を付加する
制約をクリアするため、SQL Collectionと関数を利用しスプレッドシートの情報に以下のデータを付加して分析をしながらファイルを分割します。
・集約キー(店舗コード)を昇順に並べた時の順序(以下、集約キー番号)
⇒DENSE_RANK
・集約キー(店舗コード)単位の明細数(以下、明細カウント)
⇒COUNT
・集約キー(店舗コード)単位の明細行番号(以下、明細行番号)
・行番号
⇒ROW_NUMBER
| DENSE_RANK | COUNT | ROW_NUMBER |
|---|---|---|
| 順位付ける(同位の場合は重複する 次の順位は飛ばさず連番となる) | 集計する | 行番号を付ける |
また、関数にはOVER句という範囲指定を利用して特定の範囲を分析する。
| PARTITION BY | ORDER BY |
|---|---|
| 特定の分析範囲を設定する | 順序付ける |
これらを使用して以下のクエリを作成します。
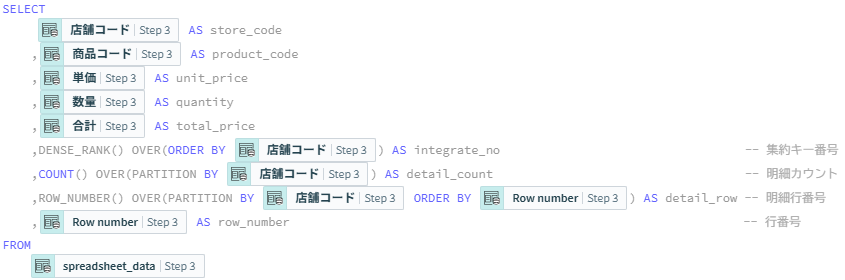
関数を使ったカラム名は以下の通りに設定します。
集約キー番号 ⇒ integrate_no
明細カウント ⇒ detail_count
明細行番号 ⇒ detail_row
,DENSE_RANK() OVER(ORDER BY {店舗コード}) AS integrate_no
,COUNT() OVER(PARTITION BY {店舗コード}) AS detail_count
,ROW_NUMBER() OVER(PARTITION BY {店舗コード} ORDER BY {Row number}) AS detail_row
このクエリを出力した場合、以下の結果となります。
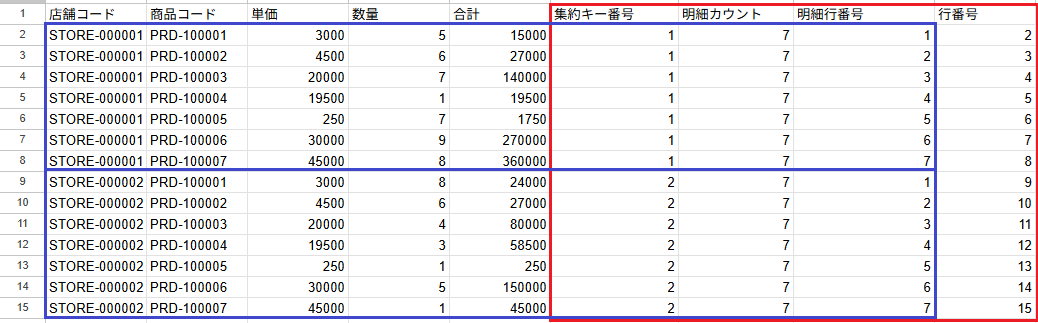
それでは、上記のデータ分析を踏まえ実装してみます。
実装
レシピとしては以下の構成となっています。
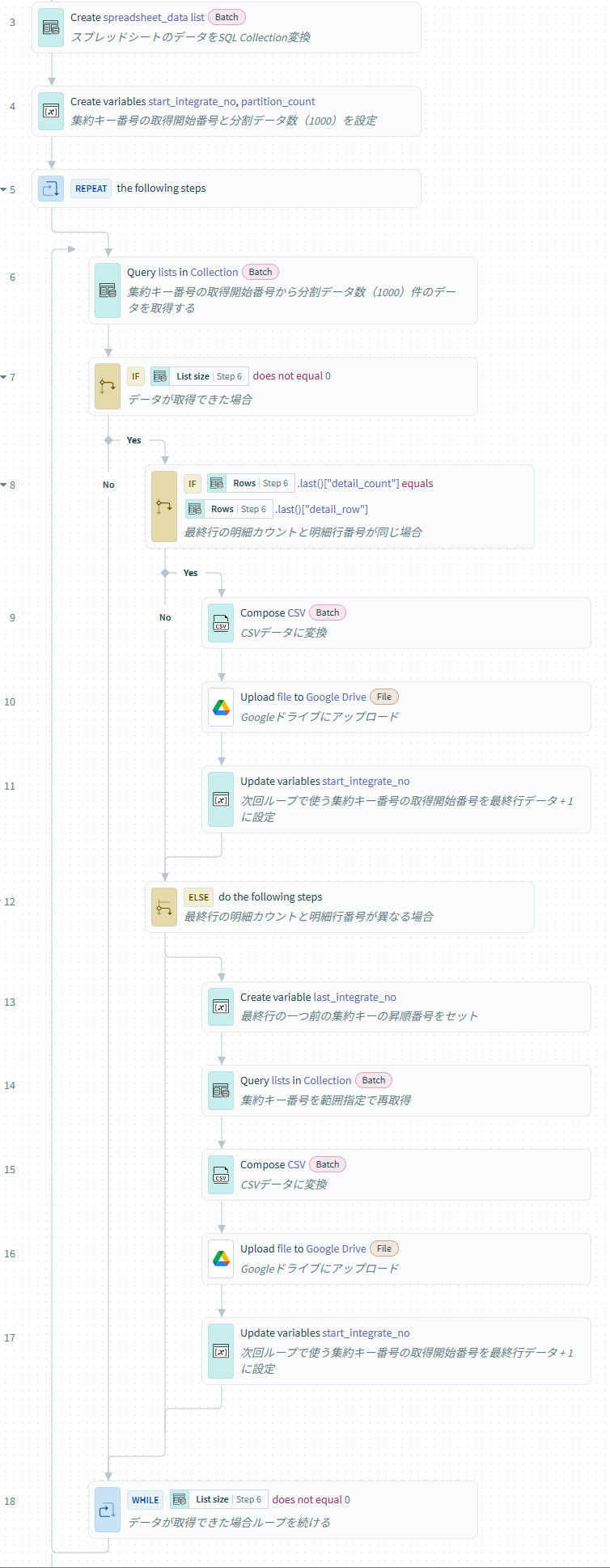
1.集約キー番号の取得開始番号と分割データ数を設定
ループの前に、集約キー番号の取得開始番号と分割するデータ数を設定します。
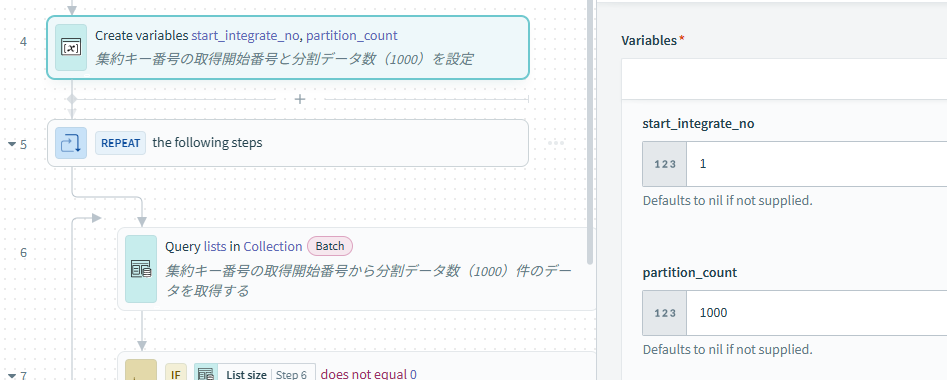
集約キー番号は1から採番されるので1を、今回は1000件区切りで出力するので1000を設定します。
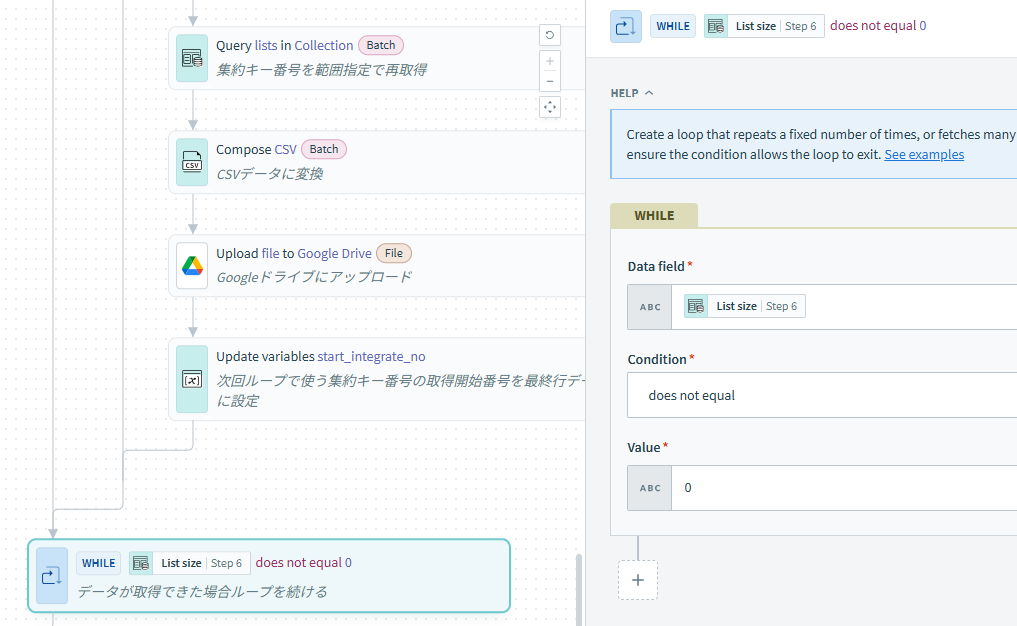
2.Repeat whileでループ
今回は全件取得できたかをループ内の処理結果で判定するのでRepeat for eachではなくRepeat whileでループを行います。
ループの条件は5.ループの判定にて解説します。
3.集約キー番号の取得開始番号から分割データ数分のレコードを取得
SQL Collectionと関数を駆使してデータ分析する情報を付加する
にて解説した関数を使ったクエリを使い、1.で作成した集約キー番号の取得開始番号を条件に分割するデータ数分SQL Collectionで取得します。
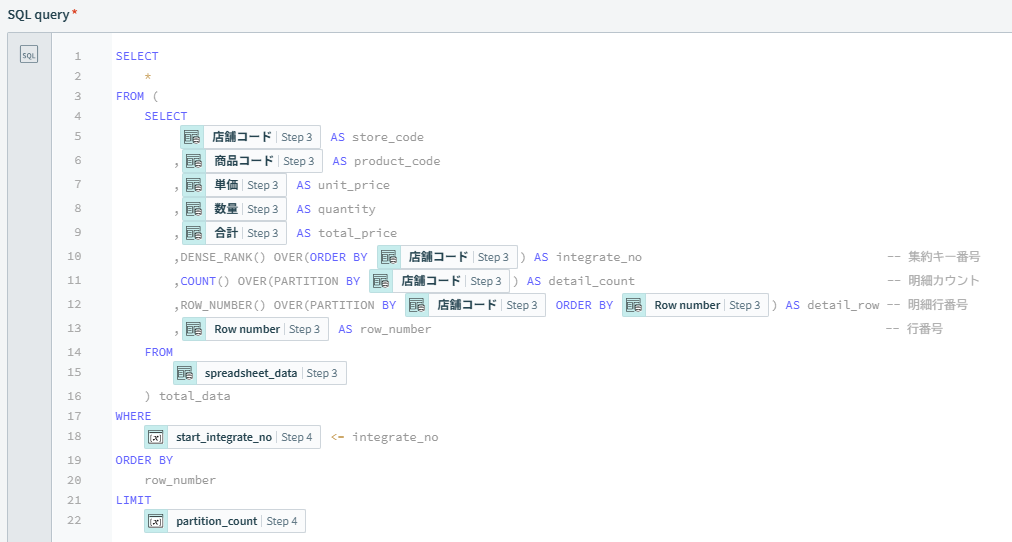
3~16行目で集約キー番号・明細カウント・明細行番号を付与したサブクエリを作成し、外のクエリで最終的に条件を付けて出力する方法です。
WHERE句の条件は、取得開始番号以上の集約キー番号を条件としています。
ORDER BYのソート順は行番号、LIMIT句で分割データ数(今回の場合1000件)を上限に取得します。
4.条件分岐
取得した結果を元に条件を判定します。
SQL Collectionで取得したリストに.last()のformulaを使用する事でリストの最後のデータを判定します。
ここでは最終行データの明細カウント(detail_count)と明細行番号(detail_row)が同じかを条件にします。
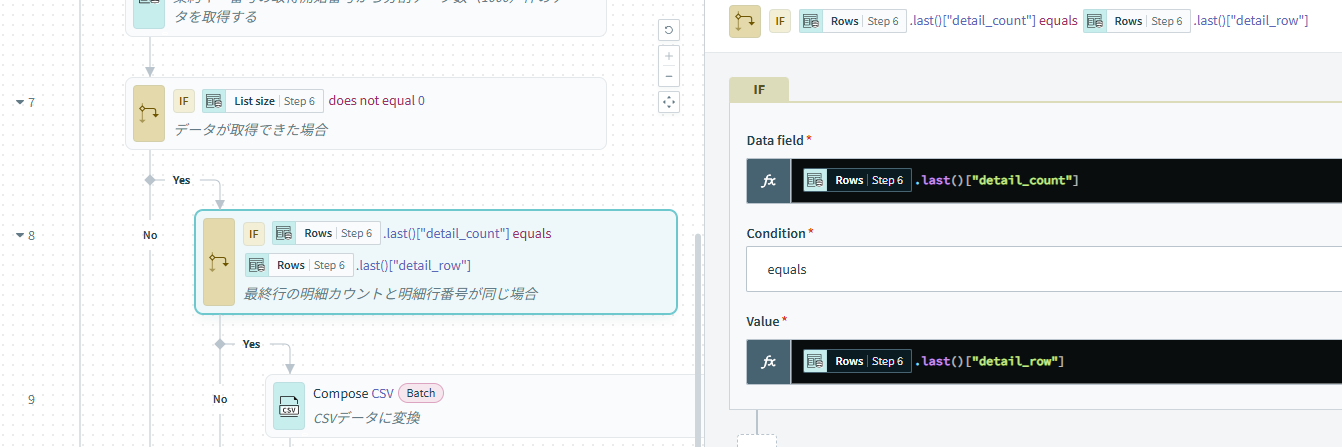
リストにformulaを使って判定する場合にリストが空の状態で使用するとエラーが発生する場合があるので、条件分岐の前にリストのデータが0件でない事を判定する条件を前のステップに設定してください。(添付画像のStep7)
4.1. 最終行の明細カウントと明細行番号が同じ場合
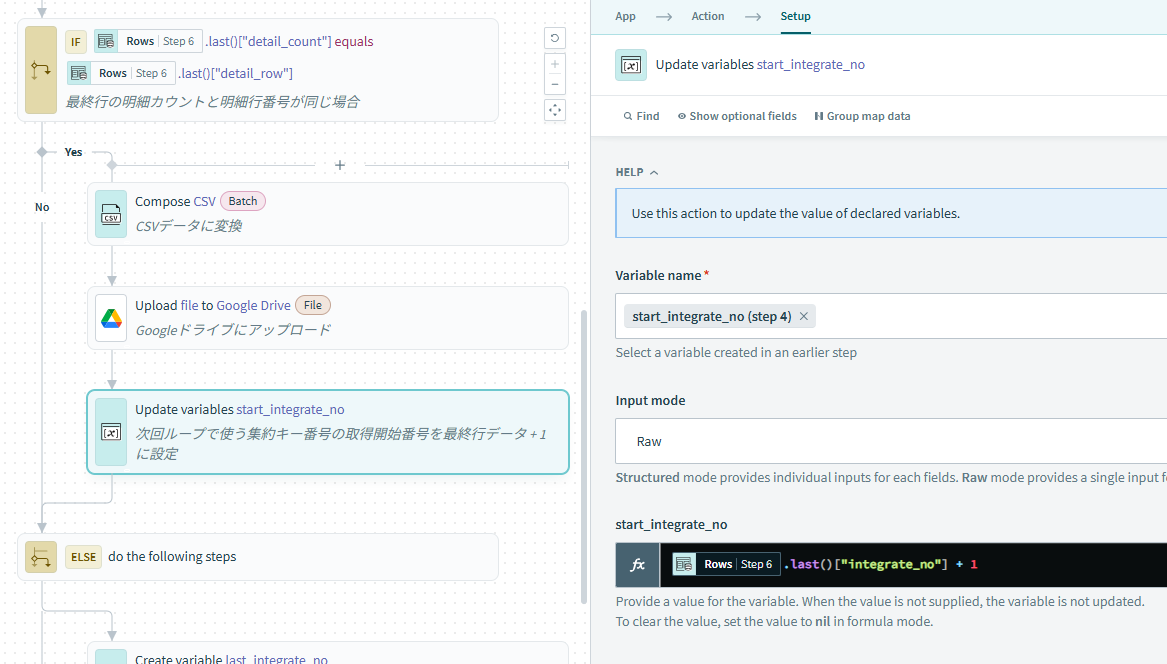
最終行の明細カウントと明細行番号が同じ場合は、分割データ数で取得した場合にキリよく集約キー番号が分離せず取得できていたという事なので、そのままCSVに変換してアップロード可能となります。
処理の最後に次回ループで使用する集約キー番号の取得開始番号を設定するため、最終行の集約キー番号に+1した値をセットします。
4.2. 最終行の明細カウントと明細行番号が異なる場合
最終行の明細カウントと明細行番号が異なる場合は、分割データ数で取得した場合に最終行の集約キー番号が分離されてしまう状態となるため、データの再取得を行います。
最終行で取れた集約キー番号の一つ前まではファイル分離せず取れているため、SQL Collectionで再取得する前に集約キー番号の取得終了番号(last_integrate_no)の変数を作成します。
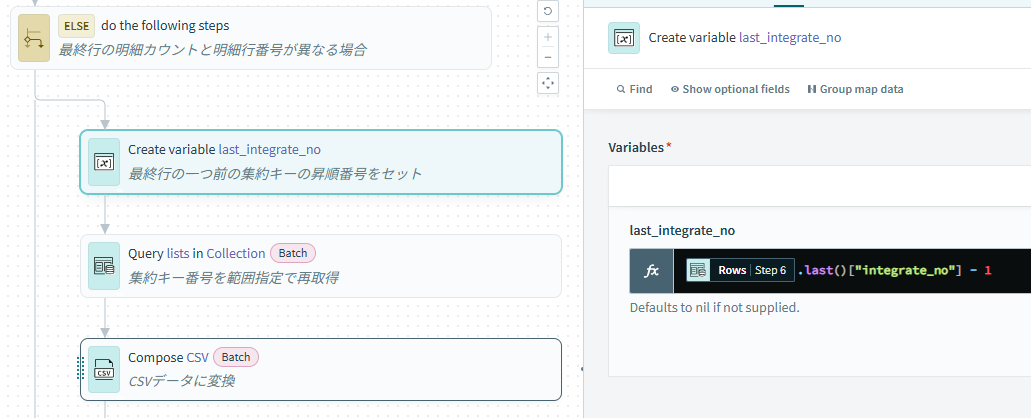
今度はBETWEEN句を使い、集約キー番号の取得開始番号から取得終了番号の範囲指定でデータを再取得します。
クエリ自体は基本的に3.と変わりませんが、赤く囲った部分の条件が変わっています。
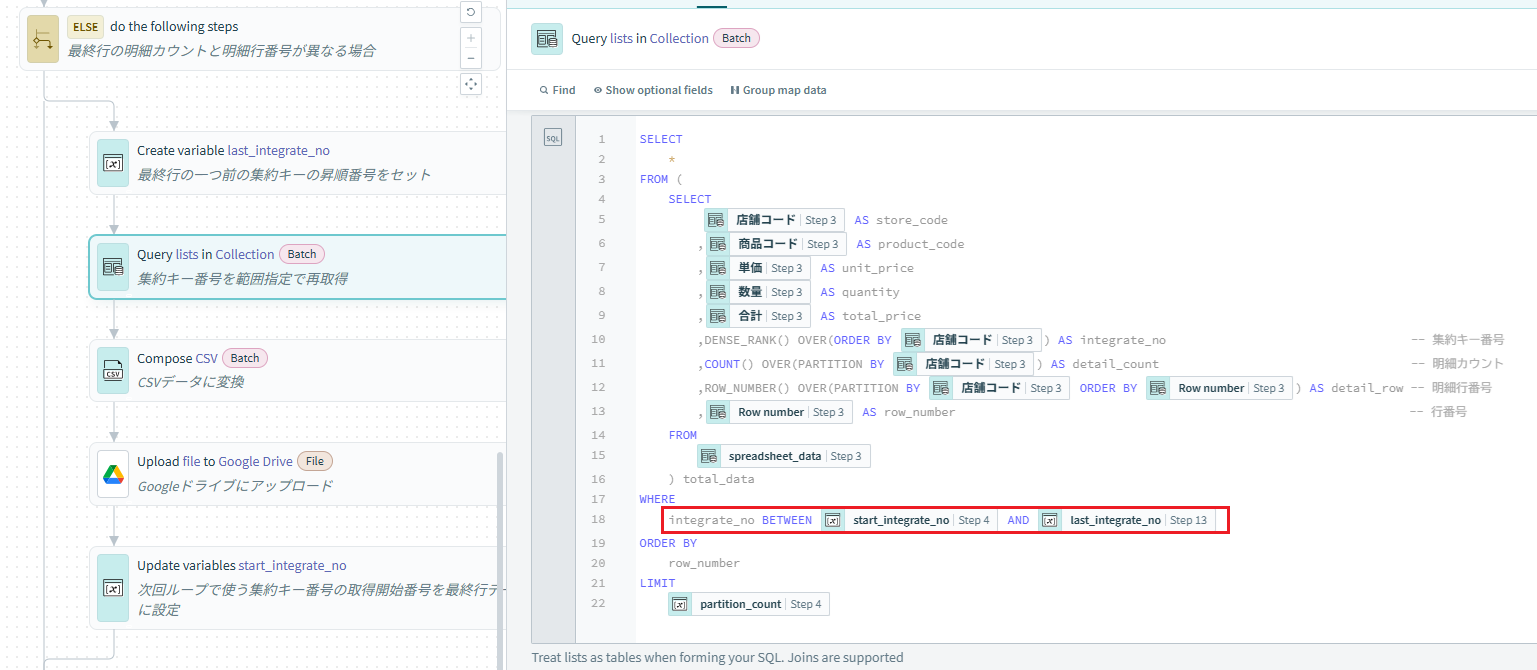
これにより、3.で取得したデータの中で分割データ数の範囲で集約キー番号が分離されないデータを全て取得する事ができます。
処理の最後に次回ループで使用する集約キー番号の取得開始番号を設定するため、再取得した最終行の集約キー番号に+1した値をセットします。
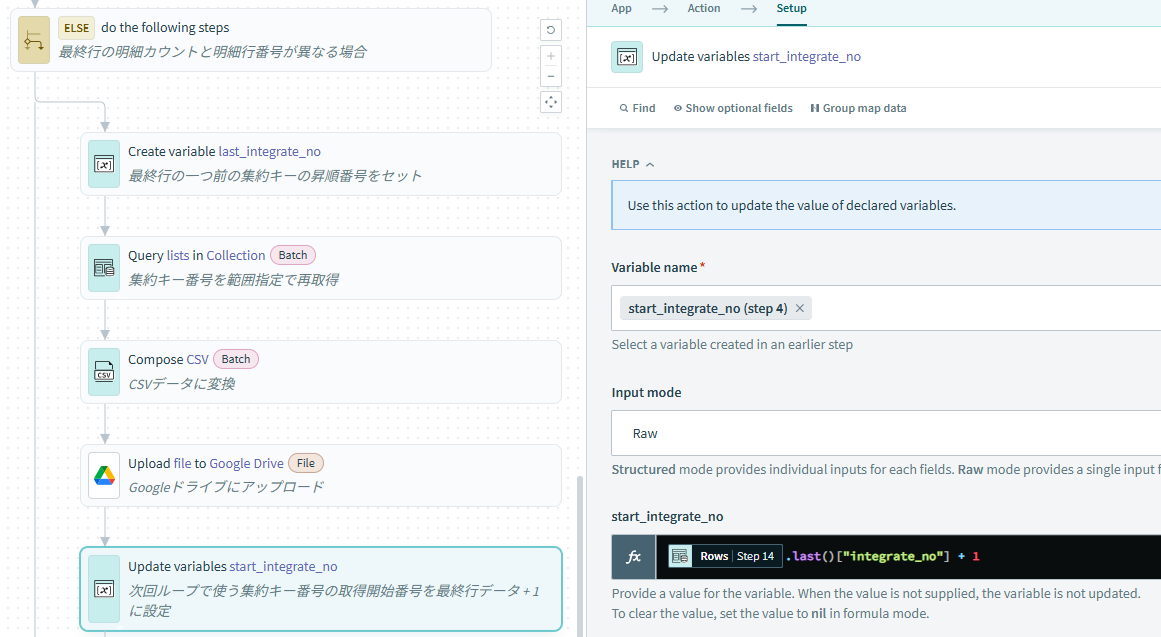
5.ループの判定
Repeat whileのループはすべてのデータが出力されるまでなので、3.の取得件数が0でない事を条件とします。
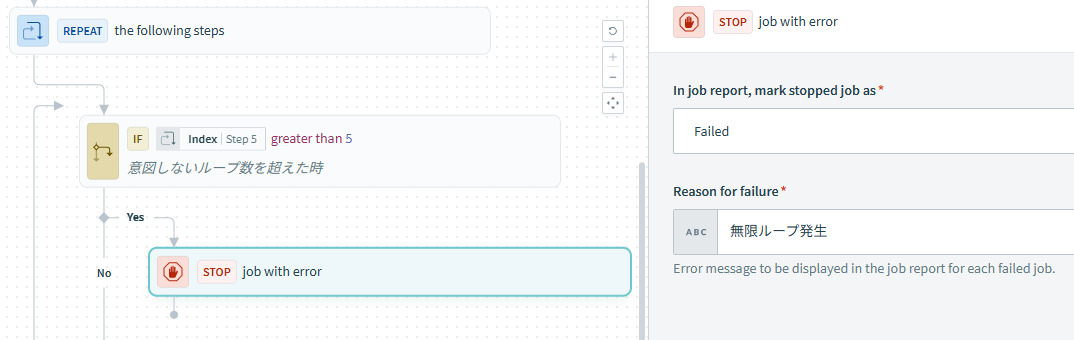
Tips
Repeat whileの条件はデータピルを適切にセットしないと無限ループを発生させる可能性があるので、開発中はループの中で想定しないループの数になったらJOBを終了する処理を入れると開発中の意図しないタスク数の消化を防ぐことができます。
出力結果
・1ファイル目の最終行
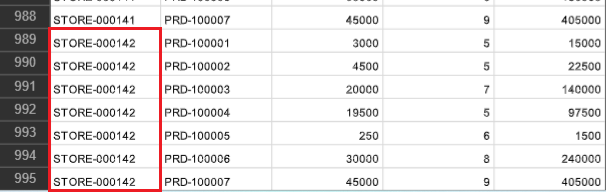
・2ファイル目の先頭行
このように件数に上限があり、かつ特定のキーがファイルを分離してはらならない場合にSQL Collectionと関数を組み合わせて制約をクリアしてファイル分割をする場合の実装方法の紹介でした。