始めに
Apache Kafkaを一から勉強したので、学んだことをできるだけ簡単な言葉で噛み砕いて自分なりにまとめてみました。
この記事の対象者
・Apache Kafkaとはそもそも何か知りたい方
・Apache Kafkaの勉強を始めた方
この記事で伝えること
・Apache Kafkaとは何か
・Apache Kafkaの仕組み
・Apache Kafkaの特徴
Apache Kafkaとは?
Apache Kafkaとは、
「複数台のサーバーで大量のデータを処理する分散メッセージングシステム」
のことです。
まずはメッセージングシステムについて説明していきます。
メッセージングシステムとは?
現在の世の中では、リアルタイムで大量のデータが生成され続けています。
これらは「ストリームデータ」と呼ばれており、様々な場所でリアルタイムに収集され、活用されています。
例えば、交通状況もストリームデータの一つであり、渋滞状況の把握などに使われています。
作られたデータは利用場所に送信する必要がありますが、
直接繋げようとすると、下記の図のようにかなり複雑な構成になり、開発・運用・管理が難しくなります。
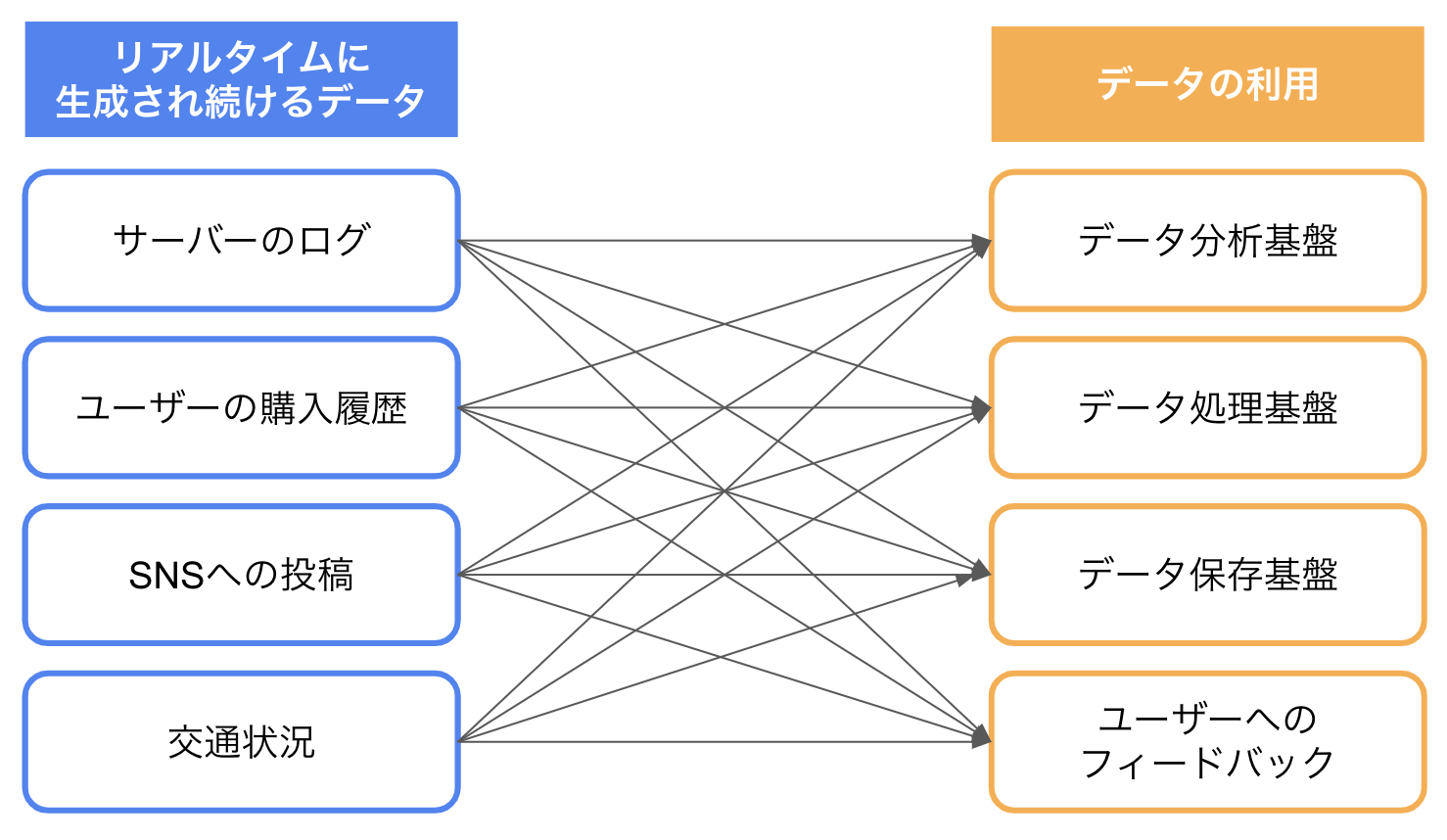
そこで、データ生成場所とデータ利用場所に 中継役 となるメッセージングシステムを配置します。
Apache Kafkaはこの中継役(メッセージングシステム)に当たるもの です。
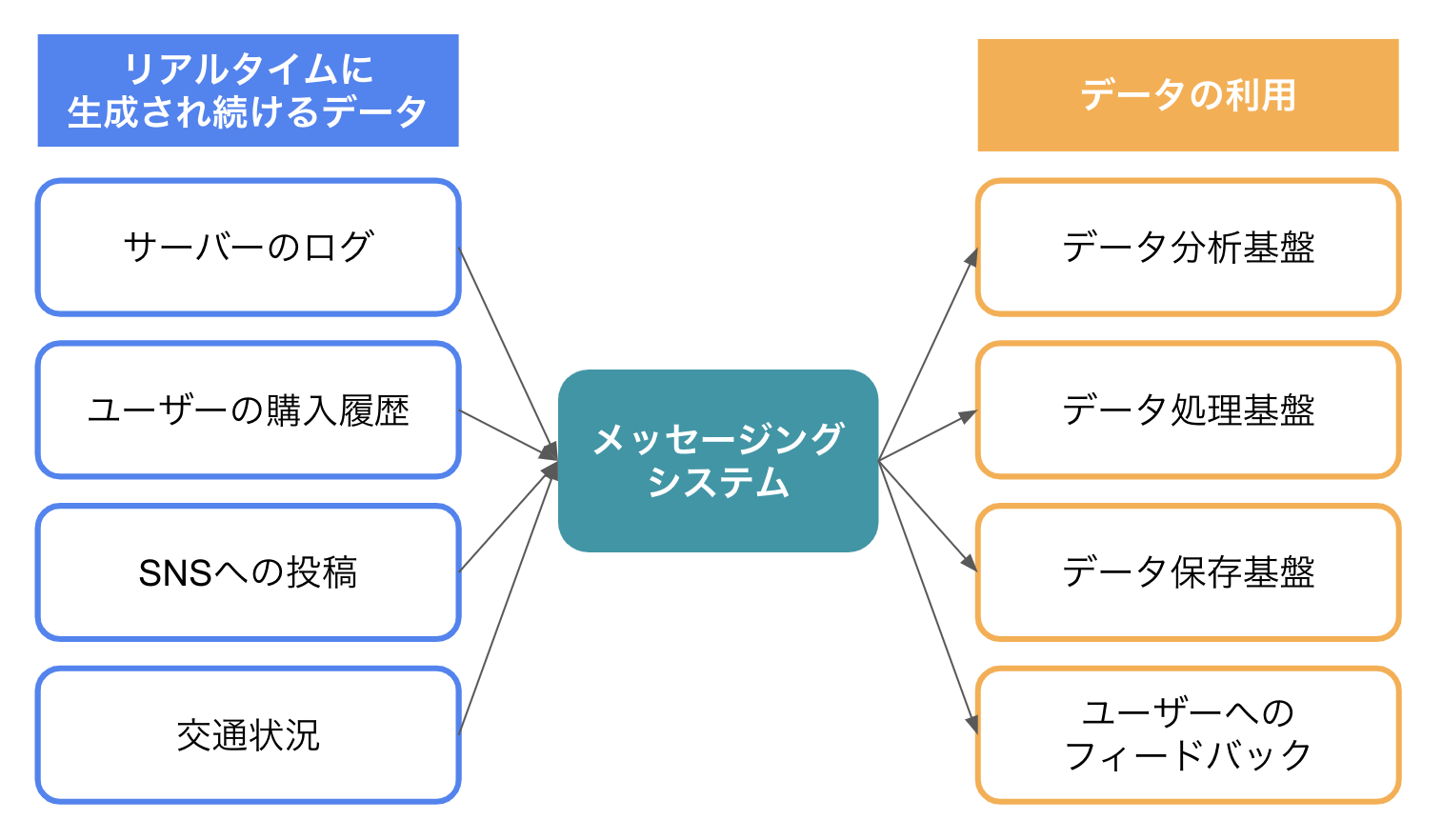
メッセージングシステムを介すことで、下記のようなメリットがあります。
-
シンプルな構成を実現できる
データ生成場所は、どのデータ利用場所にデータを送ればよいかを考える必要がなくなり、メッセージングシステムに送ればよいだけになります。
同様にデータ利用場所もメッセージングシステムからのみデータを受信すれば済むようになります。
データ生成場所・データ利用場所ともに接続先を一つにできるため、とてもシンプルな構成を実現することができます。 -
構成の変更に強くなる
新しいデータ生成場所・データ利用場所が作られても、メッセージングシステムに繋げばよいだけになり、実装コストが低くなります。
このようなメリットはありますが、下記のような懸念が浮かんだ方もいるのではないでしょうか。
- メッセージングシステムや連携しているシステムに不具合が起きた場合、どうなる?
- データの送受信量が増えたら、性能は悪くなってしまう?
- そもそもどのように他のシステムと連携するのか?
ここからはKafkaの特徴を見て、以上の懸念をどのように解消しているのかを説明していきたいと思います。
その前に、Kafkaのデータ送受信の基本的な構成を簡単に説明します。
Apache Kafkaの構成
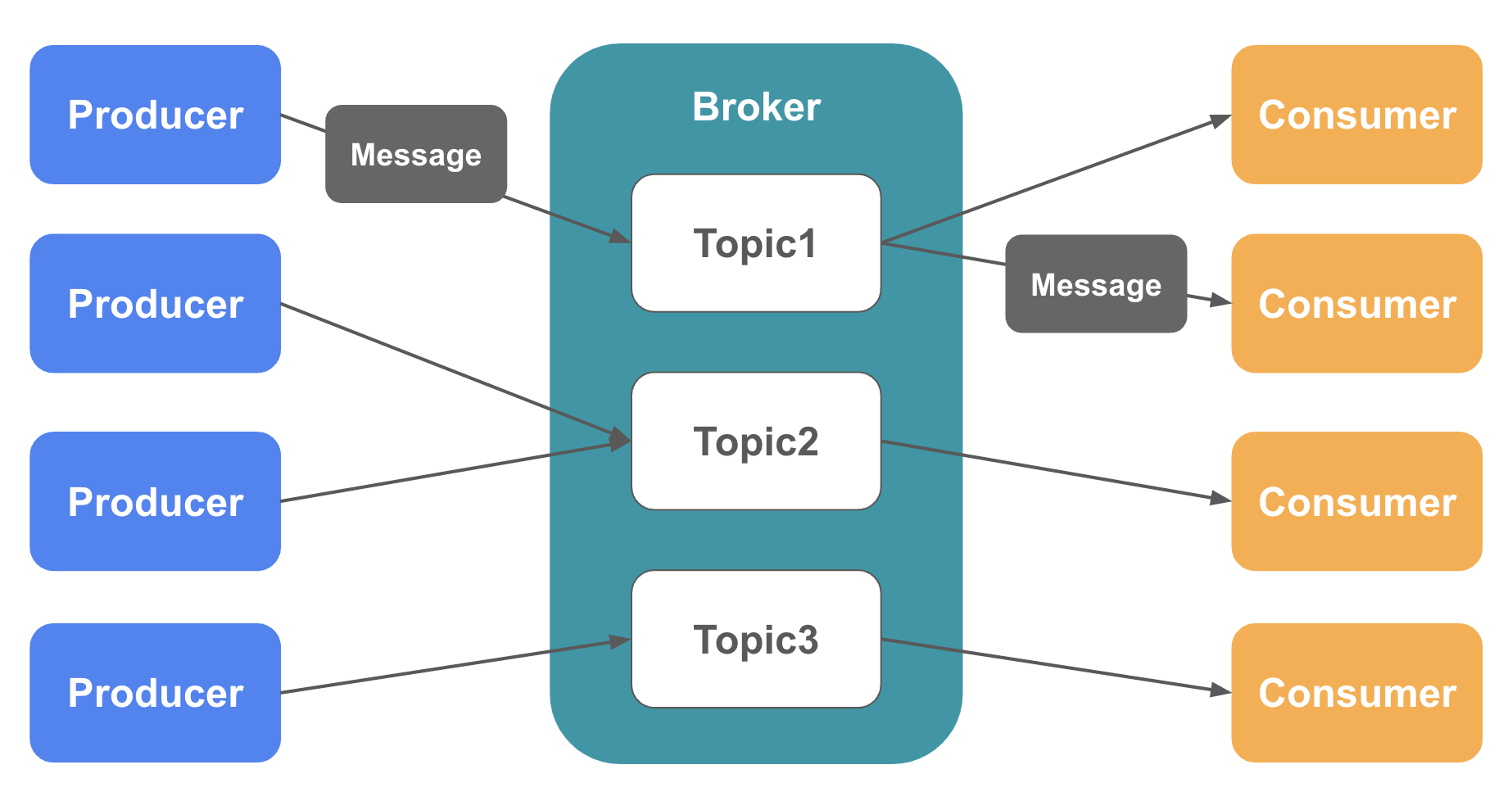
以下がKafkaを構成する主要な要素になります。
以降の説明では、ここで紹介する用語を使っていきます。
-
Broker
データを受信・送信するサービス。中継役。 -
Message
Kafkaが受信し送信するデータの単位。 -
Producer
データの送信元。Brokerに対してMessageを送信する。 -
Consumer
データの送信先。BrokerからMessageを取得する。 -
Topic
Messageを種類ごとに管理するためのストレージ。Broker上で管理される。
Producer・Consumerは 特定のTopicを指定してMessageの送信・受信 を行います。
Apache Kafkaの特徴
それではKafkaの特徴を見ていきましょう。
Kafkaには大きく分けて以下4つの特徴があります。
- 分散システム
- データのディスクへの永続化
- メッセージの送達保証
- わかりやすいAPIの提供
分散システム
一つの窓口でデータの受け取り・送信を処理する場合、データ量が増えるにつれて負荷は上がっていきます。
また、その窓口に障害が発生した場合、受け取ったデータが失われたり、データの送信ができなくなったりしてしまいます。
これを防ぐために、Kafkaでは分散システムを実現しています。
まずは、Kafkaの分散システムの仕組みを見ていきましょう。
先ほどBroker上ではメッセージを種類ごとにTopicで管理していると説明しましたが、Topicはさらに以下の要素で構成されています。
-
Partition
Topicをさらに分割するため単位。 -
Replica
Partitionの複製。つまりデータの複製のこと。
また、Replicaには二つの種類があります。
-
Leader Replica
Producerからメッセージを受け取り、Consumerにメッセージを送信する役割を持つ。
各Partitionに必ず一つ存在している。 -
Follower Replica
Leader Replicaからメッセージを取得して複製を保ち、障害発生時に備える。
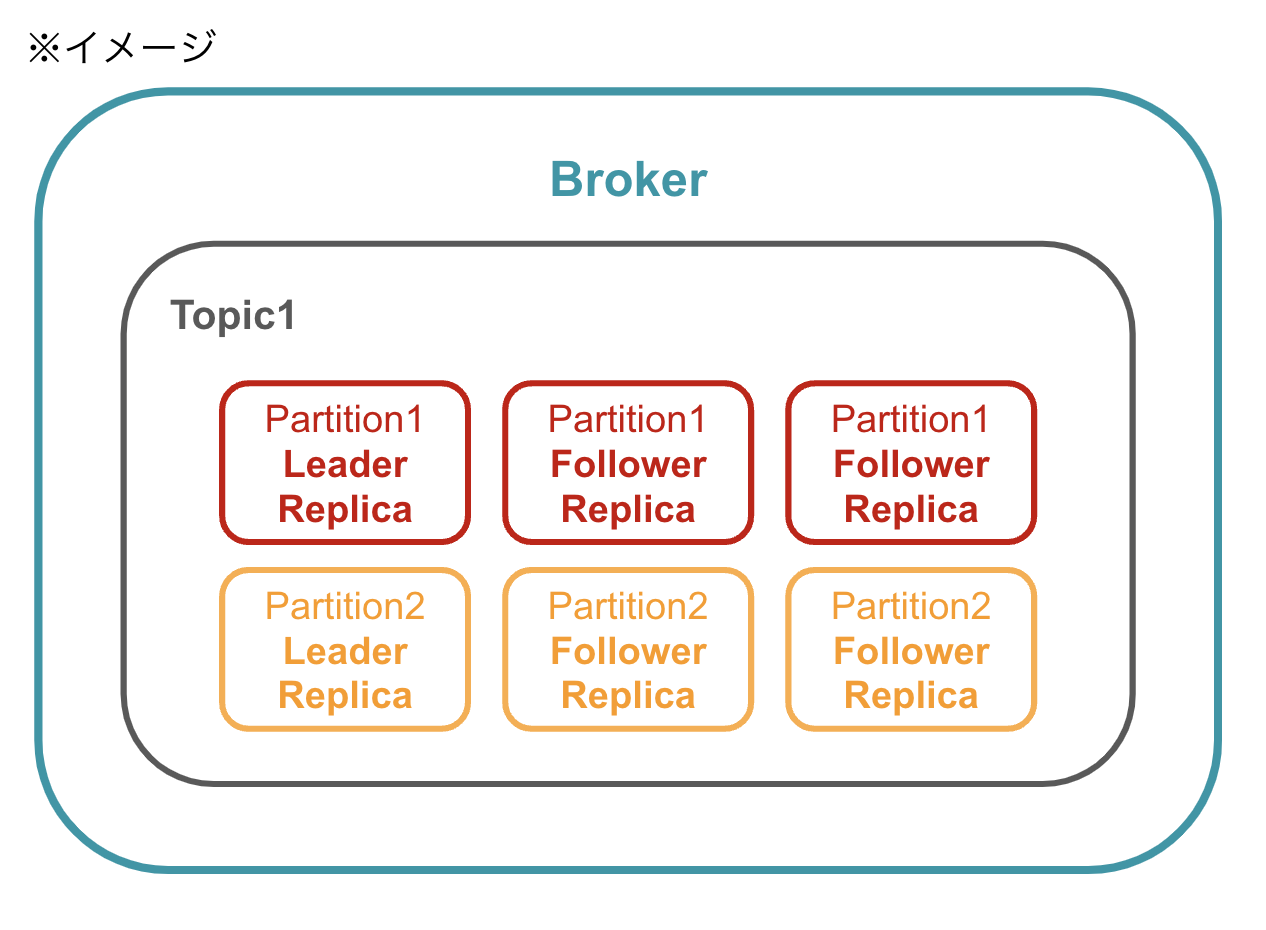
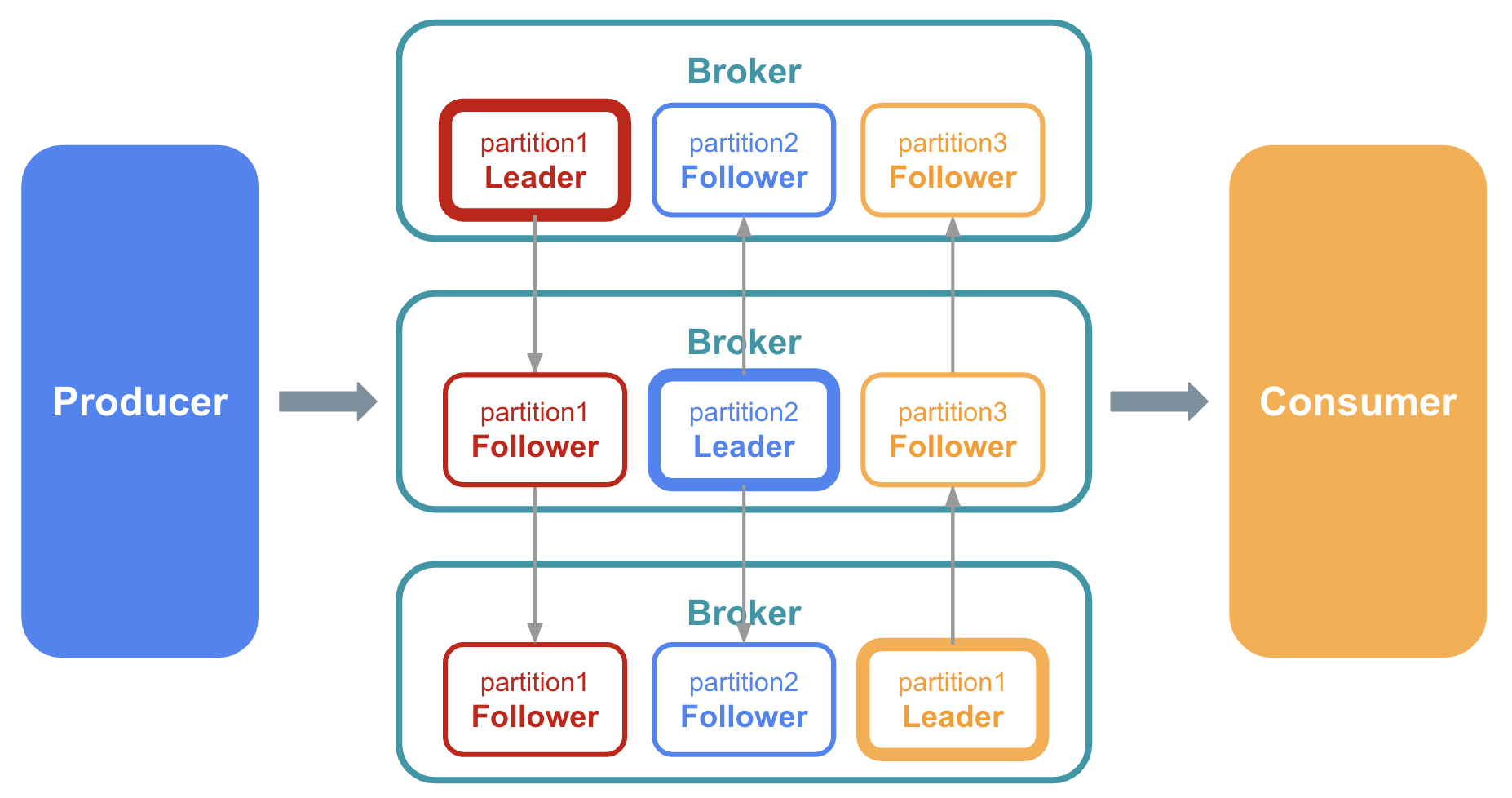
ここではわかりやすくするために、Partion、Replicaが一つのBrokerに配置されているように図を書きましたが、実際には 各Replicaは異なるBrokerに配置 されます。
Replicaを異なるBrokerに配置することで、Kakaは分散処理を実現しているのです。
以下の図のように同じPartitionのLeader Replica・Follower Replicaを異なるBroker上に配置することで、 一つのメッセージの複製が複数のサーバーで管理される ようになります。
また、実際にデータのやり取りを行うPartitionは複数のサーバーに分散されるため、 サーバーそれぞれの役割も分散される ことになります。
このような分散システムの実現によって、以下のようなメリットがあります。
-
スケールアウトが可能
サーバー(Broker)を増やしPartitionを再配置することで、Partitionの役割も均等になり、各Partitionの役割が少なくなります。サーバーの役割が分散されるため、性能も上がります。 -
障害発生時のデータ紛失を防ぐ
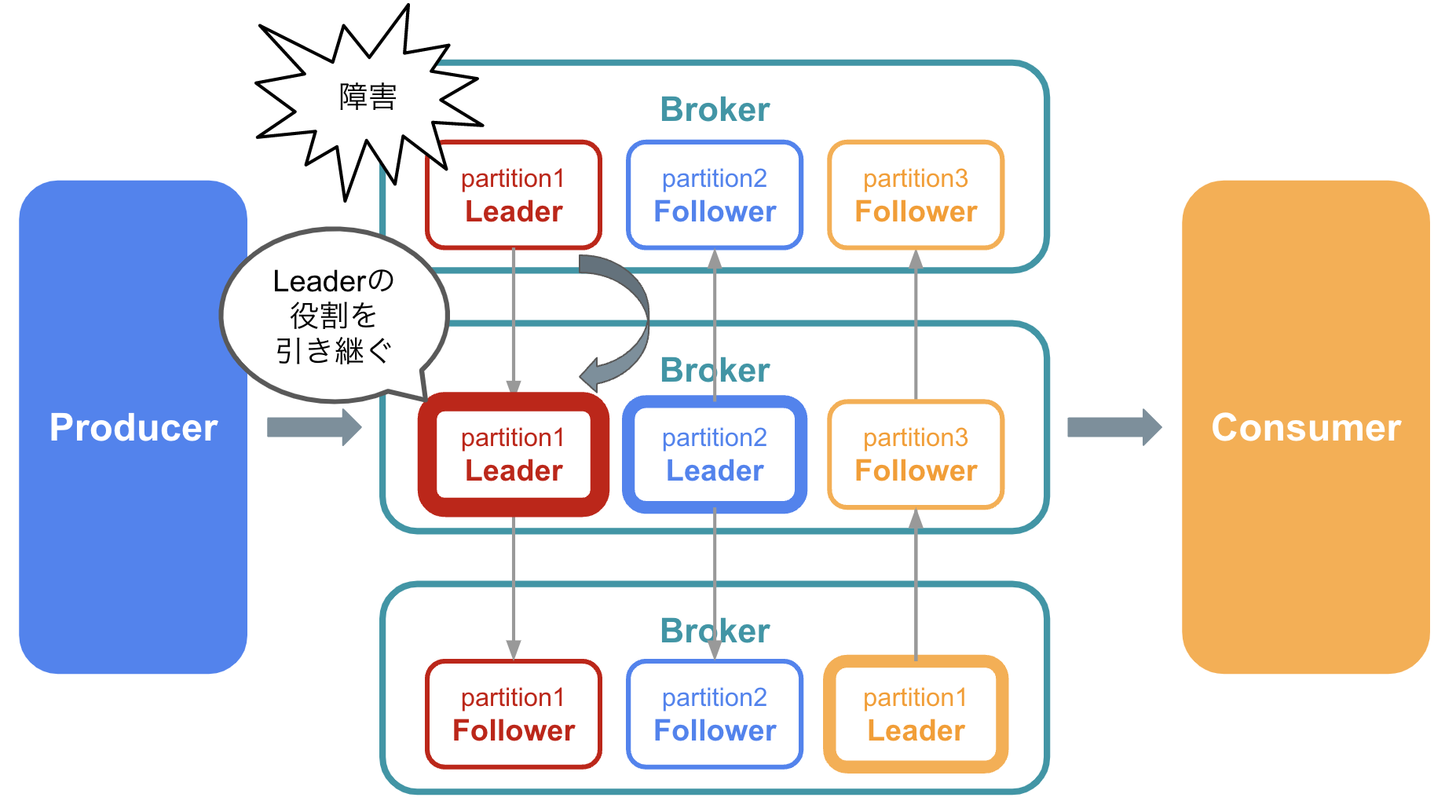
別のBrokerにデータの複製があるため、あるBrokerに障害が発生してもデータは失われません。
また、Leaderが配置されているBrokerで障害が発生しても、 別のBrokerに配置されているFollowerがすぐにLeaderとしての役割を引き継ぐ ため、データの受信・送信を問題なく続けることができます。
データのディスクへの永続化
Kafkaでは、BrokerがProducerからメッセージを受け取るとディスク上に保存を行います。
これにより、 Consumerは任意のタイミングでメッセージを取り出すことができる ようになります。
Brokerが能動的に送るのではなく、Consumerからのリクエストに応答して受動的にデータを送る仕組みにより、以下のメリットがあります。
-
バッチ処理を実現できる
Consumerが任意のタイミングでデータを受信するという仕組みを活用し、Broker上に複数のメッセージを溜めておき、一括で受信することで、バッチ処理を実現することも可能です。
データを順次処理するストリーム処理とデータをまとめて処理するバッチ処理両方を実装できるため、柔軟にデータを利用することができます。 -
onsumerが故障した際のBrokerへの影響が少ない
Consumerからのリクエストが無ければBrokerはデータを送信しません。そのため、Consumerが故障してもBrokerのデータ送信を停止するといった対応が不要になります。
メッセージの送達保証
Kafkaには、Messageが正しく送信・受信されたことを確認する機能や、失敗した時のリトライ機能が備わっています。
前提として、送達保証には一般的に以下3つのレベルがあります。
| レベル | 概要 | 説明 |
|---|---|---|
| At Most Once | 1回は送達を試みる | メッセージが失われても、再送信しない。性能は最も良い。 |
| At Least Once | 少なくとも1回は送達する | メッセージを複数回送信することを許容し、メッセージを失わない。複数回送信するため、データが重複する可能性がある。 |
| Exactly Once | 1回だけ送達する | メッセージが失われることも重複することもなく、確実に送達できる。性能は最も悪くなる。 |
Kafkaでは送達保証のレベルをこの3つから選択し設定することが可能ですが、
当初Kafkaは At Least Once を実現する製品としてリリースされました。
At Least Onceを実現するための概念として、AckとOffset Commitというものがあります。
-
Ack
Brokerがメッセージを受け取った際に、Producerに対して受け取ったことを返答すること。ProducerがAckを受け取らなかった場合、再送するべきだと判断することができる。 -
Offset Commit
ConsumerがBrokerからどこまでメッセージを受け取り、Consumer側の処理が完了したかを知らせること。
※オフセット:基準となる位置からの差・距離

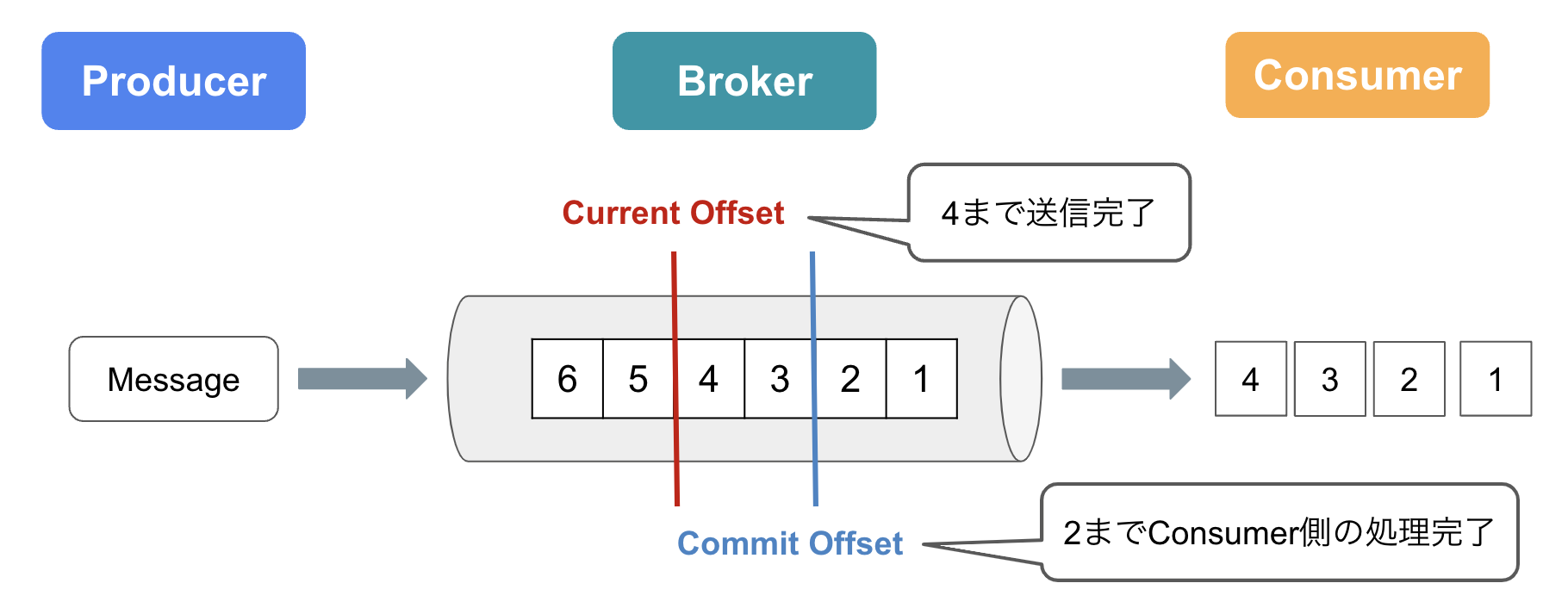
オフセットという言葉にもあるように、BrokerとConsumerのやり取りでは、 「どこまで送信したか」「どのまで処理が完了したか」 という位置情報を管理しています。
具体的には、Partitionで受信したメッセージには連番が振られ、以下二つの位置情報でどのメッセージまで処理したかを記録します。
-
Current Offset
Consumerがどこまでメッセージを読んだかを示す -
Commit Offset
ConsumerがどこまでOffset Commitしたかを示す
ここからは、上記2つの位置情報を利用した、メッセージの送信に失敗した際のリトライの仕組みについて説明していきます。
ConsumerがMessage3,4を取得し、処理が完了する前(Offset Commitをする前)にConsumerで障害が発生したケースを考えてみましょう。
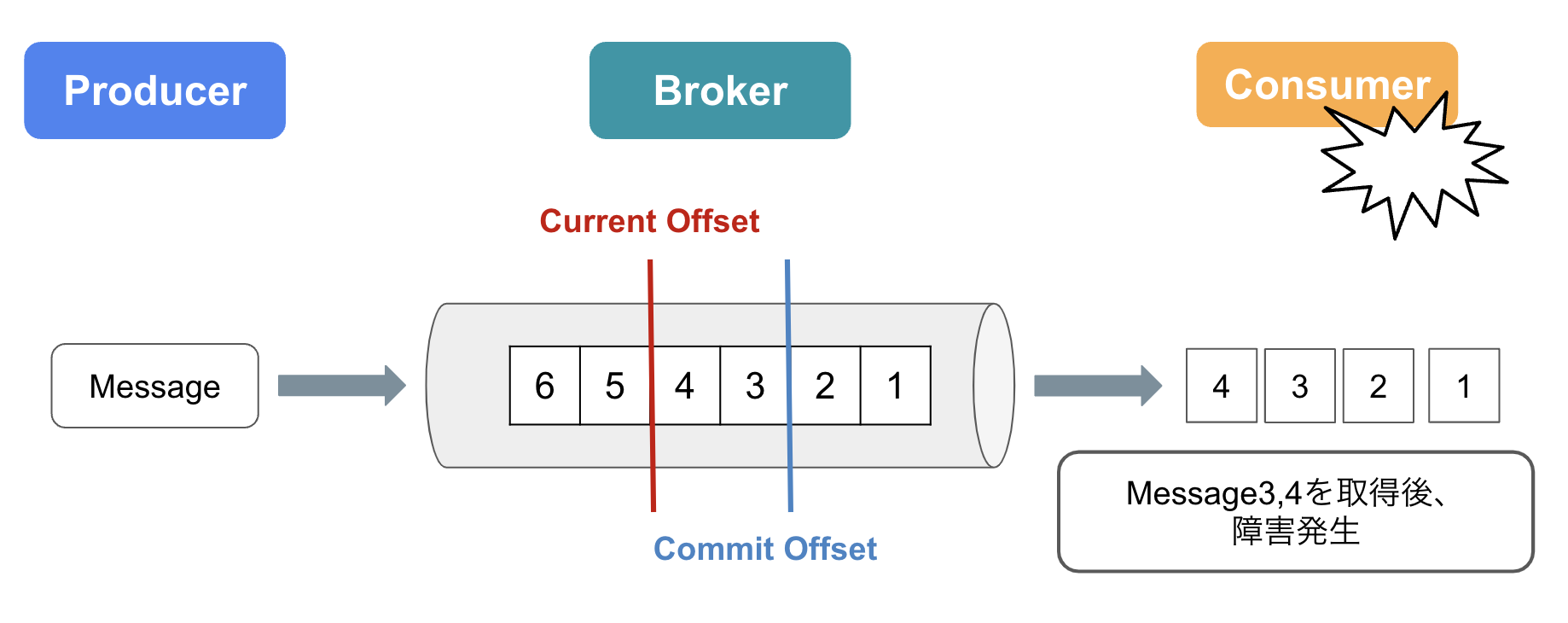
Counsumerが復旧した後、Current OffsetをCommitOffsetまで巻き戻し(ロールバック)を行います。
これにより、ConsumerはMessage3,4を再度受信することが可能になります。
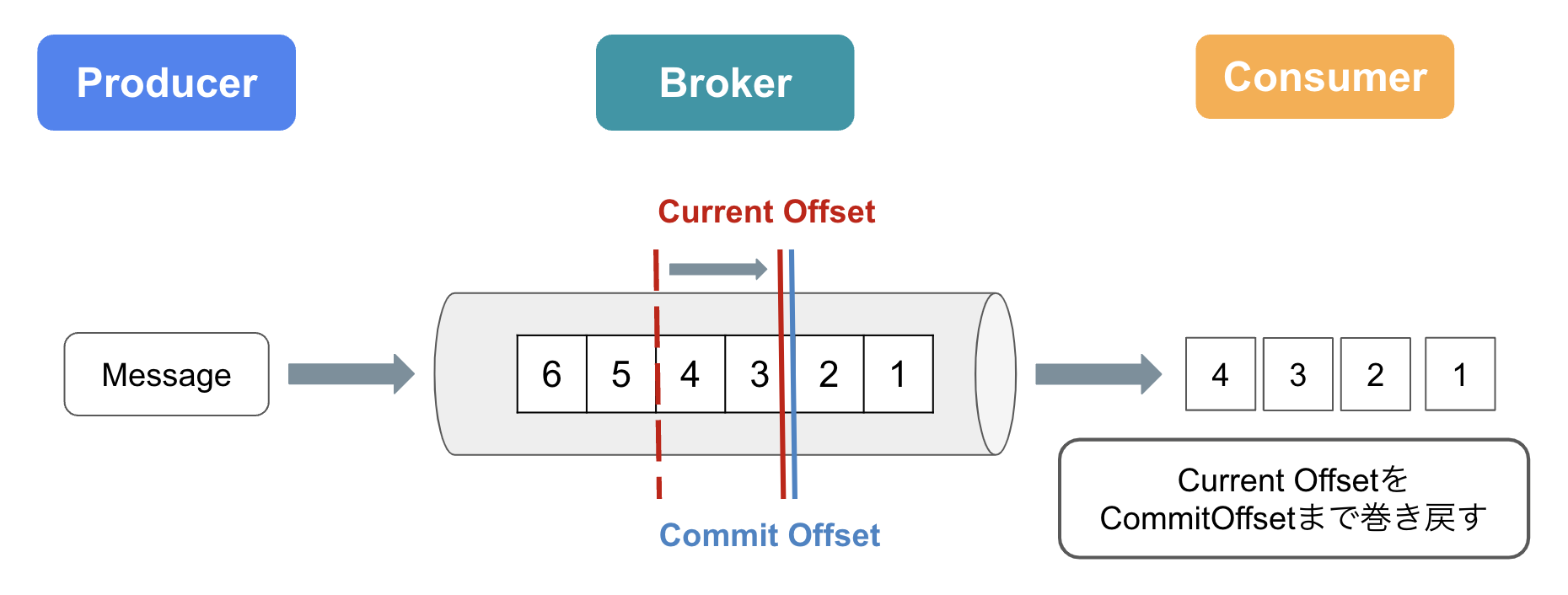
ここで注目したいのが、ConsumerはMessage3,4を2回受信しているということです。
このリトライはAt Least Oneを実現する仕組みであり、重複したデータをどのように対処するかは後続のアプリケーションに委ねられています。
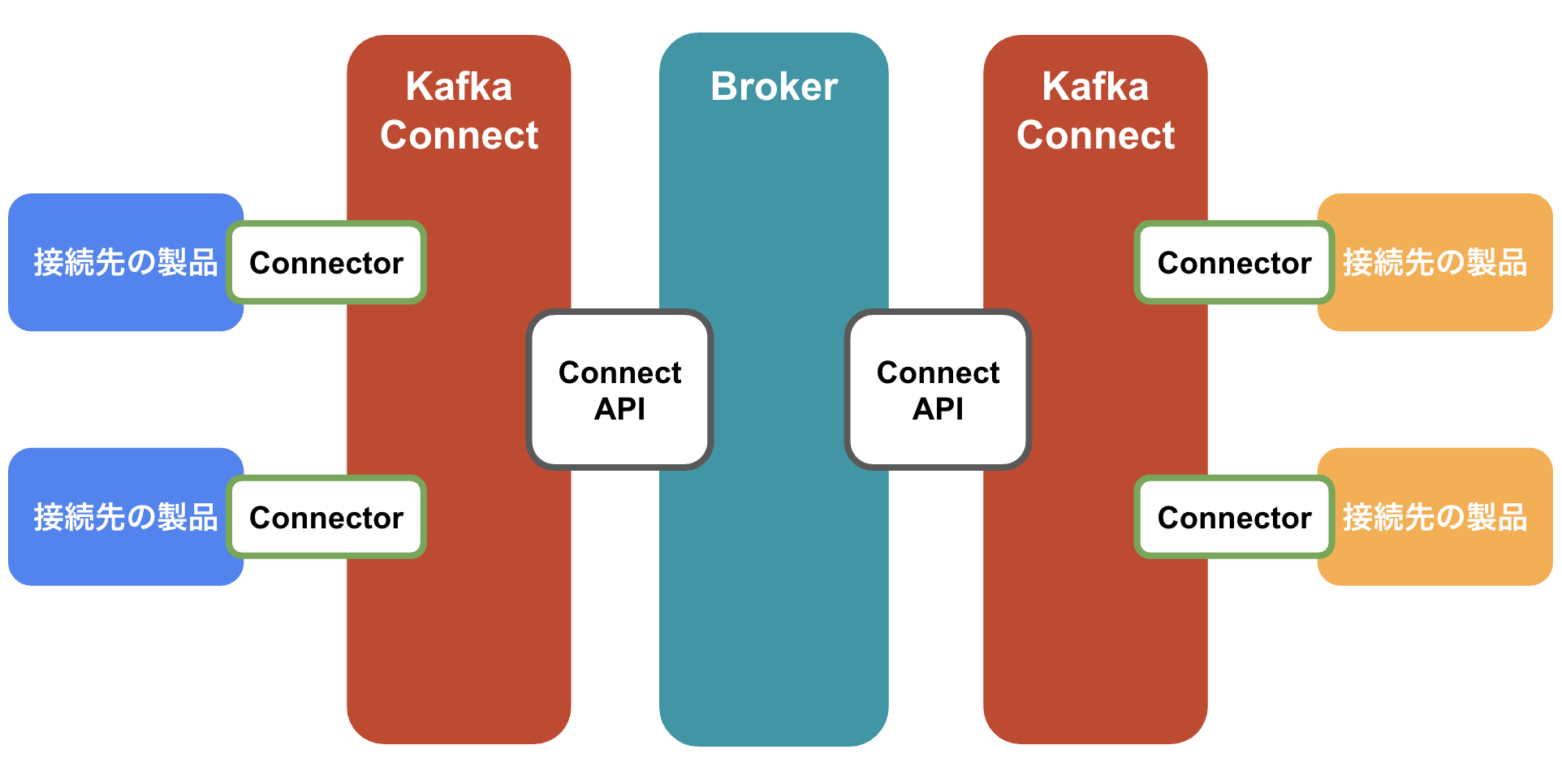
わかりやすいAPIの提供
Kafkaには以下が用意されており、自分で実装することなく連携できる製品が多く存在します。
-
Connect API
Producer・ConsumerがBrokerとやりとりを行うためのAPI。 -
Kafka Connect
Connect APIをベースにProducer・ConsumerとKafkaをつなぐためのフレームワーク。 -
Connector
Kafkaと他製品を繋げるためのプラグイン。製品ごとに用意されているため、接続先にあったConnectorがあれば自分でコーディングする必要なく接続を実現することができます。
こちらのサイトから、実装されているConnectorを見ることができます。
https://www.confluent.io/product/connectors/
まとめ
Kafkaとは?
複数台のサーバーで大量のデータを処理する分散メッセージングシステムのこと。
メッセージングシステムとは?
データ生成場所からデータを受け取り、データ利用場所へデータを送信する役割を担う中継役。
Kafkaの特徴は?
- 分散システム
- データのディスクへの永続化
- メッセージの送達保証
- わかりやすいAPIの提供
Kafkaや連携しているシステムに不具合が起きた場合、どうなる?
複数のサーバー(Broker)で分散処理をしているため、あるサーバーが故障しても、他のサーバーで処理を続けられる。データも失わない。
連携システムに故障があった場合は、Ack・Offset Commitという仕組みで、修理後再度データの受信・送信を行うことができる。
データの送受信量が増えたら、性能は悪くなってしまう?
データの量が増えても、サーバーの台数を増やすことで性能を維持・改善することが可能。
そもそもどのように他のシステムと連携するのか?
Kafka Connectというフレームワークが用意されている。また、すでに多くの製品をKafkaに接続するためのConnectorが用意されているため、手間がかかることなく接続可能。
最後に
今回はApache Kafkaについて、概要を簡単にまとめてみました。
まだまだ構造については理解できていない部分や触れられていない部分があるので、引き続き勉強していきたいのと、Kafkaを使ったアプリケーションの開発にも取り組んでみようと思います!