この記事の目的
機械学習をするうえで、前処理として外れ値(外れたサンプル)を処理したいです。
そこで、以下の2点のやり方を、この記事にメモしておきます。
- 機械学習的手法で外れ値を検出・除去したい
- その手続きをPipelineの一部として組み込みたい
なお、外れサンプルを除外したままにすることはできず、何らかの値で補完してやる必要がありました。
環境
- Windows 10
- Python 3.7.1 (64bit)
- scikit-learn 0.20.0
データセットの用意
私が用意したデータセットを使用します。
内容の詳しい説明は省きますが、回帰を目的とした131 samples x 3 featuresのデータセットです。
StandardizeScaler()がすでに適用されています。
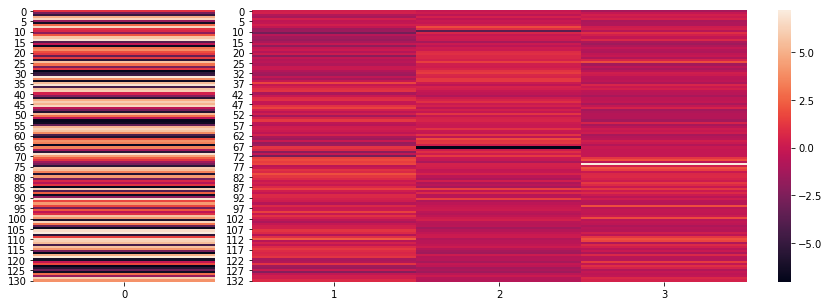
ぱっと見、1つ目の変数はいい感じです。
しかし2つ目と3つ目の変数には外れ値がありそうです。
2つ目と3つ目の変数を散布図に描いてみます。
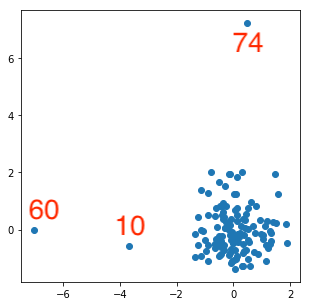
わかりやすく外れていますね。
赤字の数字は、何番目のサンプルかを示しています(編集して加えました)。
3つ全部の変数を3Dで見てみます。
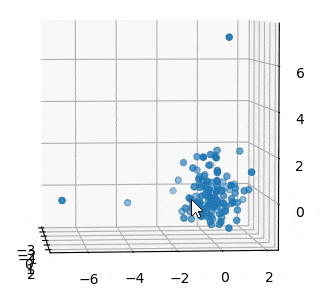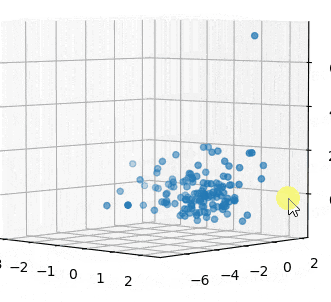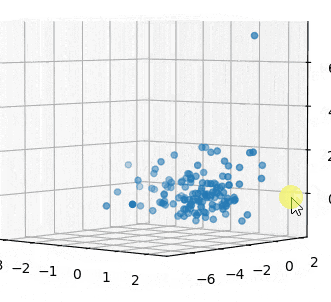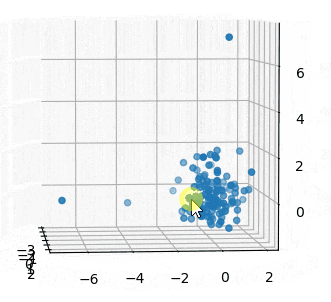
3Dでみても、サンプル10はともかく、60と74はがっつり外れてますね。
外れ値の検出
LocalOutlierFactor()を試す
sklearn document 2.7. Novelty and Outlier Detectionを見ると、LocalOutlierFactor()が紹介されています。
Local Outlier Factorというアルゴリズムについてググると、わかりやすい記事が見つかったので、解説はそちらへ譲ります。
これを適用してみましょう。
from sklearn.neighbors import LocalOutlierFactor
local_outlier_factor = LocalOutlierFactor(contamination='auto', novelty=True)
local_outlier_factor.fit(X)
predicted = local_outlier_factor.predict(X)
contaminationは、外れ値の割合を示す引数で、閾値に影響を与えるようです。
デフォルトは0.1ですが、今後のバージョンアップで'auto'がデフォになるようだったのでこれにしてみました。
noveltyはTrueにしないと、新規データに適用できなくなるとのことだったのでTrueにします。
結果を見てみましょう。

1は外れ値でないサンプル(inlier)、-1は外れ値(outlier)を意味しています。
またプロットしてみます。
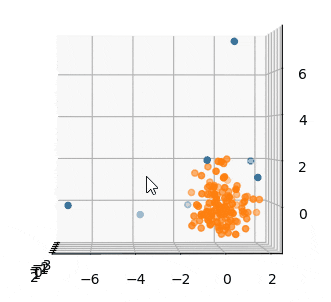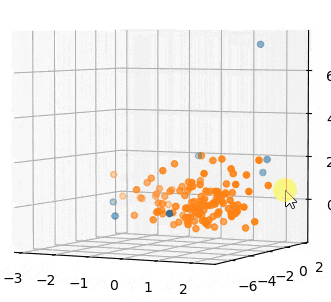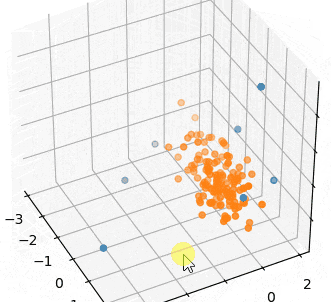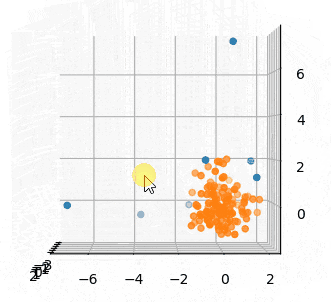
青が外れ値です。
外れてるとも言い難いサンプルまで外れ値になってるように感じます。
パラメータを調整して閾値を上げる
外れ値とみなす条件をもう少し厳しくします。
contaminationは外れ値の割合だということなので、少し低めてみます。
デフォルトが0.1なので、0.05にしてみましょう。
local_outlier_factor.set_params(**{'contamination': .05});
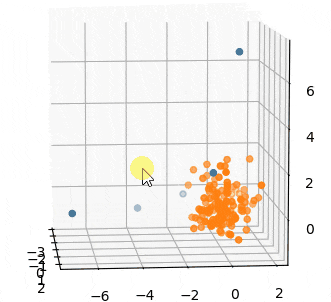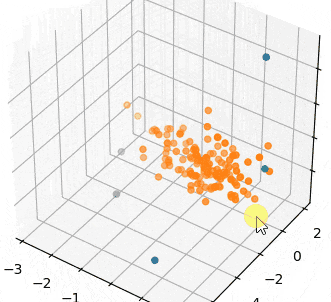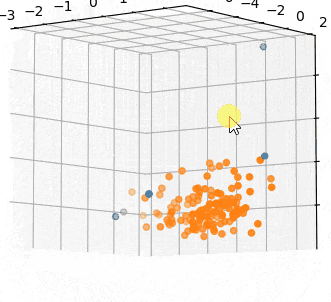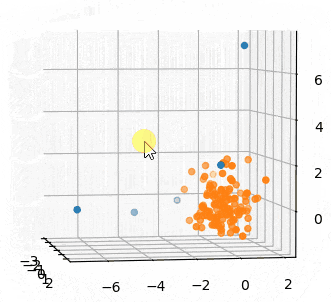
さっきより外れ値扱いのサンプル数が減っていることがわかります。
新規データに適用する
Cross-Validationにかけることを意識して、データをTrainとTestに分割します。
そして、Trainデータに.fit()したLocalOutlierFactorが、Testデータに対してどうpredictするのかみてみましょう。
X_test = X[:43, :]
X_train = X[ 43:, :]
local_outlier_factor.fit(X_train)
idx_outlier_train = local_outlier_factor.predict(X_train) == -1
idx_outlier_test = local_outlier_factor.predict(X_test ) == -1
わかりやすさ重視で、あえてsklearnの機能を使わずに分割してます。
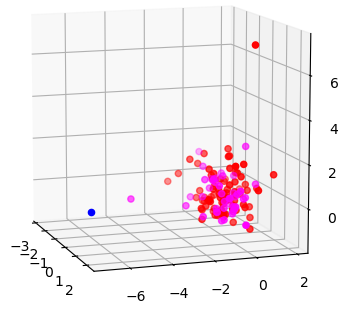
赤:トレーニングのInlier
青:トレーニングのOutlier
マゼンタ:テストのInlier
シアン:テストのOutlier
…なのですが、シアンのサンプルはありません。
テストデータはすべてInlierと判定されたようです。
特に目立つ2つの外れ値(サンプル60, 74)が、どちらもトレーニングデータに入っています。
60は外れ値としてみなされているようですが、74はInlierに振り分けられています。
contaminateには引き続き0.01を使っていますが、もっと大きい値の方がよいのかもしれません。
もう一度、別の方法で分割してやってみます。
今回は、サンプル10, 60, 74のいずれもテストデータに入っています。
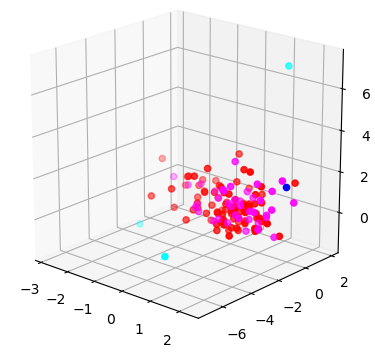
トレーニングデータにおいては、それほど外れているように見えないサンプルがOutlierになりました(青)。
一方テストデータにおいては、きちんと10, 60, 74のサンプルがOutlierとしてシアンになりました。
Pipelineに組み込む
sklearnでGrid searchをしたり、Cross-validationをする際、
「LocalOutlierFactorで検出したサンプルを除く」
という手順を含めてくれるととても便利です。
そこで、この記事やこの記事を参考にしつつ、上記手続きをsklearn.Pipelineに組み込めるようにします。
ただし、サンプルの数を減らすような操作をPipelineに組み込むことは難しいようです(参考)。
そこで目標を、「LocalOutlierFactorで検出したサンプルを除いて補完する」こととします。
sklearn準拠モデルを作る
目標達成のため、上記手続きをsklearn準拠モデルとしてclassにまとめる必要があります。
まとめました↓
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.impute import SimpleImputer
from copy import deepcopy
class CleanOutlier(BaseEstimator, TransformerMixin):
def __init__(self, contamination=0):
self.contamination = contamination
def fit(self, X, y=None):
if self.contamination==0: return self
self.lof = LocalOutlierFactor(contamination=self.contamination, novelty=True)
self.lof.fit(X)
return self
def transform(self, X_):
X = deepcopy(X_)
if self.contamination==0: return X
idx_outlier = self.lof.predict(X)==-1
X[idx_outlier, :] = np.nan
simple_imputer = SimpleImputer()
X = simple_imputer.fit_transform(X)
return X
LocalOutlierFactorで検出したサンプルを一旦np.nanに変換し、SimpleImputer()を使って平均値を補完しています。
使うとこうなります。
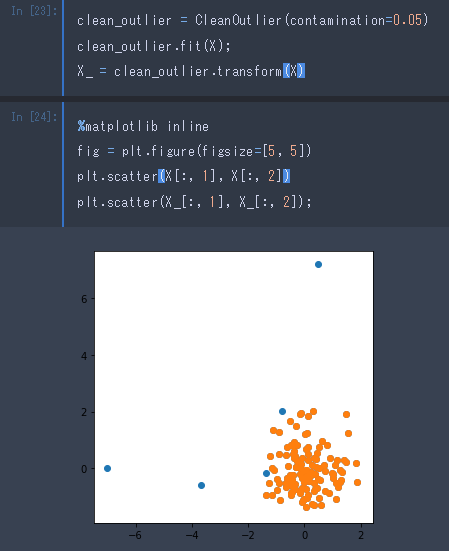
ちゃんと外れ値がなくなりました。
Pipelineの一部として使う
外れ値の検出・除去・補完 → LASSOによる回帰 というPipelineを用意します。
Grid searchとCross validationによって、LocalOutlierFactorのcontamination引数とLASSOのalpha引数について、最適なものを探します。
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import Lasso
from sklearn.model_selection import GridSearchCV
pipeline = make_pipeline(CleanOutlier(), Lasso(random_state=0))
params = {'cleanoutlier__contamination': [0, 0.05, 0.1],
'lasso__alpha' : [0.5, 1.0, 1.5]}
grid_search = GridSearchCV(pipeline, params, iid=False, cv=5)
grid_search.fit(X_train, y_train);
続いて、contaminationの値がテストスコアにどう影響を与えたのかみてみましょう。
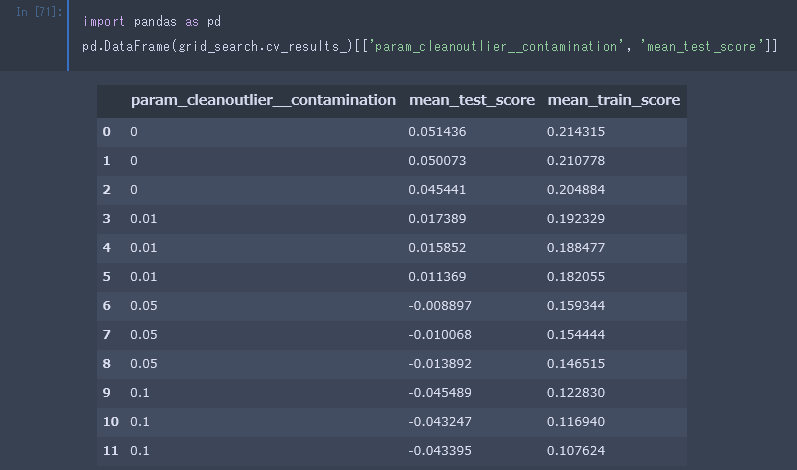
今回のデータでは、外れ値処理しないのが一番というなんともしまらない結果に…
まとめ
問題のあるサンプルをいかに処理するかは、精度の高い機械学習モデルを作るうえで重要になるかと思います。
GridSearchCVにより、様々な強度での外れ値処理を簡単に試せるのは便利ではないでしょうか。
今回用意したデータでは「処理しない」のが一番という結果になりましたが、その結果を得られたこと自体が重要なはずです。