はじめに
アプリ作成のきっかけ
- 建設系社内SEをする傍ら、現場作業の負担軽減に役立つアプリ開発をしてみたかった
やりたかったこと
- 現場業務終了後、工具を現場に置き忘れる問題への対策に画像認識を生かした
忘れ物チェックツールを作りたい
制限
- 受講期間内に物体認識を習得することが困難であったため、画像に移っている工具を分類するところまで開発する
技術解説
開発環境
- google colaboratory
- python 3.8.12
画像収集
- icrawlerを用いて画像を収集した
google colaboratory上で以下を実行
pip install icrawler #作業開始時に一度だけ実行する
from icrawler.builtin import BingImageCrawler
# Bing用クローラーの生成
bing_crawler = BingImageCrawler(
downloader_threads=1, # ダウンローダーのスレッド数
storage={'root_dir': 'drive/MyDrive/test'}) # ダウンロード先のディレクトリ名
# クロール(キーワード検索による画像収集)の実行
bing_crawler.crawl(
keyword="作業工具 メジャー", # 検索キーワード(日本語もOK)
max_num=10) # ダウンロードする画像の最大枚数
以下、工具の種類ごとにフォルダ分けして画像を収集した。画像の枚数は1種類につき40枚程度
drive/Mydriveというのはグーグルドライブ領域のため、グーグルドライブ上からも編集可能
(フォルダごと削除する場合はグーグルドライブ必須)
./drive/MyDrive/dri/#ドライバー
./drive/MyDrive/hum/#金槌
./drive/MyDrive/meg/#メジャー
./drive/MyDrive/pliers/#ペンチ
./drive/MyDrive/File/#やすり
./drive/MyDrive/wrench/#スパナ
./drive/MyDrive/saw/#のこぎり
./drive/MyDrive/cutter/#カッターナイフ
./drive/MyDrive/bar/#バール
./drive/MyDrive/clamp/#クランプ
モデルの作成
- 教師あり学習
収集した画像の8割を訓練データとして予測モデルを作成し、残りの2割を使って予測モデルに対しての正解率を計算する
正解率の高いモデルの作成を目標とするが、収集した画像しか予測できない過学習にならないように60%~70%を目標とする
- コードの解説
モデルに必要なライブラリの宣言部。モデル作成にはtensorflowを採用している
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# モデルの保存
import os
from google.colab import files
収集した画像を変数に展開し、50pxの正方形に加工して配列に格納している
上記では10種類の工具画像を用意したがモデル作成時は3種類で作成している。理由は下記モデルの正解率問題を参照
# パスを設定
path_dri = os.listdir('./drive/MyDrive/dri/')#ドライバー
path_hum = os.listdir('./drive/MyDrive/hum/')#金槌
path_meg = os.listdir('./drive/MyDrive/meg/')#メジャー
img_dri = []
img_hum = []
img_meg = []
for i in range(len(path_dri)):
img = cv2.imread('./drive/MyDrive/dri/' + path_dri[i])
img = cv2.resize(img, (50,50))
img_dri.append(img)
for i in range(len(path_hum)):
img = cv2.imread('./drive/MyDrive/hum/' + path_hum[i])
img = cv2.resize(img, (50,50))
img_hum.append(img)
for i in range(len(path_meg)):
img = cv2.imread('./drive/MyDrive/meg/' + path_meg[i])
img = cv2.resize(img, (50,50))
img_meg.append(img)
)
X=ドライバーと金槌とメジャーの画像をまとめて配列に代入
y=正解ラベルの定義。ドライバーは[0]、金槌は[1]、メジャーは[2]を画像の枚数と同じ数だけ配列に代入
X = np.array(img_dri + img_hum + img_meg)
y = np.array([0]*len(img_dri) + [1]*len(img_hum) + [2]*len(img_meg))
配列に格納した画像群をランダムに並び替える
train=訓練データ(全体の8割)を代入、test=検証データ(残り2割)を代入
one-hot=ビット列にする。今回は3種類に分類するのでドライバーの場合は「1,0,0」になる
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 正解ラベルをone-hotの形にします
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
モデルの実装~作成
.addメソッドの最後は必ず分類の種類数と合わせる
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dense(64, activation='relu'))
top_model.add(Dense(3, activation='softmax'))
# 入力はvgg.input, 出力は, top_modelにvgg16の出力を入れたもの
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_test, y_test))
作成したモデルをherokuへデプロイするためmodel.h5というファイル名でローカルに保存
# resultsディレクトリを作成
result_dir = './drive/MyDrive/results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( './drive/MyDrive/results/model.h5' )
モデルの正解率問題
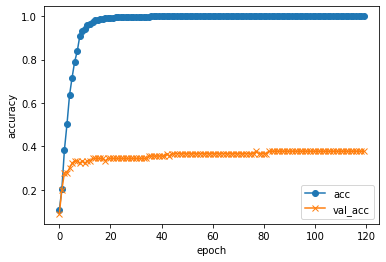
- 10種類の工具からモデル作成を試みたところ40%程度未満の正解率しか得られなかった。
10種類の工具画像から作成した際の正解率のグラフ
(val_accが正解率で、epochが訓練データを繰り返して学習させた回数)
3種類の工具画像から作成した際の正解率のグラフ
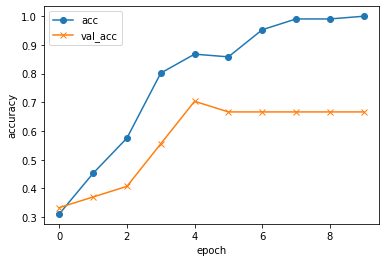
- 画像を使って立体物の分類を実現する難しさ
ドライバー、やすり、のこぎりはそれぞれ柄があって先に細長い金属がついた棒状をしており似たような形状をしている。
現物を見れば立体的に形状を把握できるので、ドライバーの柄の丸みや、のこぎりのサイズ感で簡単に分類できるが画像だと立体感やサイズ感に乏しくその辺りを上手く分類するにはより大量の訓練データとモデル作成コストが必要ではないかと推測している。
アプリのURL
https://mnisttest1016.herokuapp.com/
さいごに
立体物の形状で分類するよりは商品パッケージのように分類できるシンボルマークがハッキリしている物の方が適していると感じた。
レジでの商品の検品などに応用できないか興味がわいた。