本記事は、自身のポートフォリオサイトに、キーワードの完全一致や部分一致ではなく、文章の意味ベースでの近さを使って検索できるスマート検索機能を実装した内容をまとめます。
はじめに
ポートフォリオを構築した(下リンク)のですが、件数が増えていくと多種多様なタイトルや説明文、タグが連なると思います。
部分一致検索は表記ゆれがあった途端、うまく表示できない可能性があります。(英語と日本語が混じっても同様)また、文脈上近い内容であれば一緒に並べてみたいとなりました。
↓ 導入先(画面右上の検索フィールド)
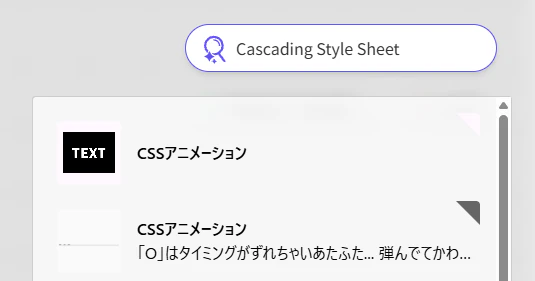
↑ 例:「Cascading Style Sheet」という文言は無いが検索が実現
検索の実行位置
検索そのものは非常に単純です。部分一致検索したい場合、フロントエンド側で処理するのかバックエンド側(もしくはデータベース側)でやるのかという形になります。
Next.js(React)環境下なら、<input value={searchTerm} />のように配置してuseEffectに依存させ、配列にincludesをすればフロントで気軽に実装可能です。
スマート検索は検索キーワードとの関連性を見る必要があり、学習済みモデルを読み込んでから処理するのでバックエンド側での処理となります。
構成図
Go(Echo)でバックエンドサーバーを既に組み立てているので、Python(FastAPI)のバックエンドを新たに増設して運用します。
バックエンド間はREST APIでやり取りしました。
FROM python:3.12-slim
WORKDIR /app
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app ./app
EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
fastapi==0.136.1
uvicorn[standard]==0.47.0
sentence-transformers==5.4.1
# PostgreSQL用
psycopg[binary]==3.3.4
pgvector==0.4.2
非常にシンプルな構成になっております。
Docker composeにて、embeddingサービスとして登録したのでhttp://embedding:8000でGoのバックエンドからアクセスができるようになります。
埋め込みベクトルの取得
登録済みで未埋め込みのデータはまとめて定期実行にて、検索キーワードはその都度にてベクトルへの埋め込みを行います。
今回、使用するモデルは「Multilingual E5」のsmall版:multilingual-e5-smallです。
DOI: https://doi.org/10.48550/arXiv.2402.05672
リリース: https://github.com/microsoft/unilm/tree/master/e5
BERT系の埋め込みモデルであり、文中のトークン同士を全体的に把握する仕組みや前後関係の把握が可能です。
smallにおける出力段の次元は384であり、内容的に近い値同士は、この空間内で近い位置に配置されます。
最終的にコサイン類似度で比較し、最大の1に近い順で並び替えればキーワードに対して最も類似している結果○○選が作成できます。
from fastapi import FastAPI
app = FastAPI(lifespan=lifespan)
# 返す型
class EmbedResponse(BaseModel):
model: str
dimensions: int
vectors: list[list[float]]
@app.post("/embed", response_model=EmbedResponse)
def embed(request: EmbedRequest) -> EmbedResponse:
if request.input_type == "query":
vectors = embed_queries(request.texts)
else:
vectors = embed_passages(request.texts)
return EmbedResponse(
model=model_id,
dimensions=len(vectors[0]),
vectors=vectors,
)
@lru_cache(maxsize=1)
def get_model() -> SentenceTransformer:
return SentenceTransformer("intfloat/multilingual-e5-small")
# 検索ワードの埋め込み
def embed_queries(texts: list[str]) -> list[list[float]]:
model = get_model()
inputs = [f"query: {text}" for text in texts]
vectors = model.encode(
inputs,
normalize_embeddings=True,
show_progress_bar=False,
)
return vectors.tolist()
# 検索対象の埋め込み
def embed_passages(texts: list[str]) -> list[list[float]]:
model = get_model()
inputs = [f"passage: {text}" for text in texts]
vectors = model.encode(
inputs,
normalize_embeddings=True,
show_progress_bar=False,
)
return vectors.tolist()
E5系のモデルは検索対象にpassage: 、検索ワードにquery: と接頭辞を使う必要があります。(そういう学習がされている)
したがって、定期実行(reindex)はembed_passagesを使い、検索時はembed_queriesを使います。
def build_chunks(work: dict[str, Any]) -> list[SearchChunk]:
work_id = str(work["id"])
chunks: list[SearchChunk] = []
summary = make_chunk(
work_id,
"summary",
f"タイトル: {work['title']}。 概要: {work['comment']}。",
)
if summary:
chunks.append(summary)
description = make_chunk(
work_id,
"description",
work.get("description") or "",
)
if description:
chunks.append(description)
# 他チャンク略
return chunks
def main() -> None:
# 更新が必要なリスト取得&登録データ内で埋め込み単位のデータへ分割
works = fetch_dirty_works()
chunks = [chunk for work in works for chunk in build_chunks(work)]
# 埋め込み処理
vectors = embed_passages([chunk.content for chunk in chunks])
# DB保存処理(略)
埋め込みベクトル登録処理はmain関数を定期実行することで解決可能になります。
(PostgreSQLならpgvectorで可能)
検索と表示
バックエンド間
検索対象のベクトルは既に埋まっているので後は比較するだけです。
フロントエンドからバックエンド(Go,Echo)、そしてEmbeddingサービスへとやり取りができるようにします。
func main() {
router := echo.New()
// /works/searchを有効にする
epWorks := router.Group("/works")
epWorks.GET("/search", pSrv.handleSearchWorks)
router.Start(/* addr */)
}
func (pSrv *server) embedQuery(ctx context.Context, queryText string) ([]float64, error) {
payload := embedRequest{
Texts: []string{queryText},
InputType: "query",
}
body, err := json.Marshal(payload)
req, err := http.NewRequestWithContext(
ctx,
http.MethodPost,
"http://embedding:8000/embed",
strings.NewReader(string(body)),
)
req.Header.Set("Content-Type", "application/json")
client := http.DefaultClient
res, err := client.Do(req)
defer res.Body.Close()
var parsed embedResponse
json.NewDecoder(res.Body).Decode(&parsed)
return parsed.Vectors[0], nil
}
func (pSrv *server) handleSearchWorks(c echo.Context) error {
queryText := strings.TrimSpace(c.QueryParam("q")) // クエリパラメータ取得
limit := 10 // 取得件数
ctx := c.Request().Context()
// キーワードのベクトル埋め込み
vector, err := pSrv.embedQuery(ctx, queryText)
// ベクトルと登録リストとの比較
hits, err := pSrv.searchWorkIDs(ctx, vector, limit)
if len(hits) == 0 {
return c.JSON(http.StatusOK, []workResponse{})
}
orderedWorks := /* ヒット順でデータを抽出 */
return pSrv.respondWorks(c, orderedWorks)
}
searchWorkIDsでは次のSQLでの取得を行います。
SELECT
work_id,
MIN(work_embedding_vector <=> search_embedding_vector::vector) AS distance
FROM work_search_chunks
WHERE embedding_model = MODEL_ID
GROUP BY work_id
ORDER BY distance ASC
LIMIT 10
ここで、<=>は2つのベクトルのコサイン距離(1-コサイン類似度)を算出するpgvectorの演算子です。
ここまでで、Go→Python(Embedding)が完成したので、残すはNext.js側からの呼び出しを用意するだけです。
フロントエンド—バックエンド間
"use client";
const SEARCH_DELAY = 300; // ms: ユーザーの入力後の検索までの遅延
const SEARCH_API_URL = "/api/works/search"; // /apiはリバプロで付加
const SEARCH_QUERY_KEY = "q";
export default function SearchField() {
const [searchTerm, setSearchTerm] = useState("");
const [hitWorks, setHitWorks] = useState<Work[]>([]);
useEffect(() => {
if (searchTerm.trim() === "") return;
// 遅延実行
const handler = setTimeout(() => {
const fetchSearchResults = async () => {
// fetch url 構築
const url = new URL(SEARCH_API_URL, window.location.origin);
url.searchParams.append(SEARCH_QUERY_KEY, searchTerm);
// 検索 API
const response = await fetch(url.toString());
const results = (await response.json()) as Work[];
// 検索結果格納
setHitWorks(results);
};
fetchSearchResults();
}, SEARCH_DELAY);
return () => {
clearTimeout(handler);
};
}, [searchTerm]);
return (
<React.Fragment>
<div>
<input
value={searchTerm}
onChange={(e) => setSearchTerm(e.target.value)}
/>
</div>
<div>
{searchTerm.trim() === "" || hitWorks.length === 0 ? (
<p>
作品が見つかりませんでした
</p>
) : (
<ul>
{hitWorks.map((work) => (
<li>
{work.title}
</li>
))}
</ul>
)}
</div>
</React.Fragment>
);
}
これにて、ユーザーの入力から検索結果の表示までが完成しました。
実際に本番環境で使っていますが、smallでもかなり満足のいく精度を得られている実感があります。
- title + comment
- description
- tech stacks
の3つにチャンクを分けて最小のコサイン距離を使っていますが、descriptionなどの記述が十分であることを何より重視すべきだとは思います。
もし、検索の優先順位などを考えたい場合はコサイン距離にバイアスをかけてみるのも面白いかもしれません。
動作環境+おわりに
Amazon Lightsailの環境
- vCPU: 1
- RAM: 2GB
- SSD: 60GB
Pythonのバックエンドでモデルを読み込むと1GB近くはメモリを食うため、Swapがあると良いです(筆者は4GB)
よきスマート検索ライフ(実装側)を