こんにちは @ishimasa です。
今回はデータベースにかける負荷を最小限にするように業務中にインデックスを貼る機会があったのでこれを機に新卒エンジニアがインデックスについて調べ、仕組みについてお話ができればと思います。
なお、本記事はAll About Group(株式会社オールアバウト) Advent Calendar 2022の1日目の投稿です。
インデックスとは
インデックスとは、テーブルに格納された特定のカラムのレコードを早く見つけるために使用するデータ構造のことです。
インデックスにはいくつかの種類がありますがMySQLで一般的に使用されているのがB-treeというデータ構造です。(B-treeの説明は今回は触れません。)
データの検索をする際には上から1つずつ検索するという方法もありますが、データが大量にある場合、1つのレコードに対するカラム数が多い場合は効率が非常に悪くなります。
日常で辞書を使うタイミングはあまりないかもしれないですが、想像してみてください。辞書で検索する際に一つの単語を調べるのにかかる時間はかかって2分ほどだと思います。辞書は大量の単語というデータを持っているのになぜこんなに簡単に調べることができるのでしょうか?
それは「索引」を使用しているからです。索引を使用すればほしい情報がどこにあるのかすぐに見つけることができます。
インデックスを比喩する言葉としてこの索引は度々使用されますが、テーブルにある情報を検索する場合に、「どこに何があるか」をわかりやすくしてくれる役割を持っています。
簡単にイメージをしてみましょう
例えば以下のようなCountry_nameテーブルがあるとします。
| id | name |
|---|---|
| 1 | Japan |
| 2 | United States |
| 3 | China |
| 4 | Germany |
| 5 | Egypt |
| 6 | United Kingdom |
このテーブルからnameの値を検索する場合、nameカラムのデータが順番に並んでいないため、スキャンする際に多くのレコードをみることになります。
この程度のデータ数ならば問題はないですが、データ数が膨大になればなるほどその差は顕著になります。
今回の場合にnameカラムにインデックスを貼ると以下のようになります。
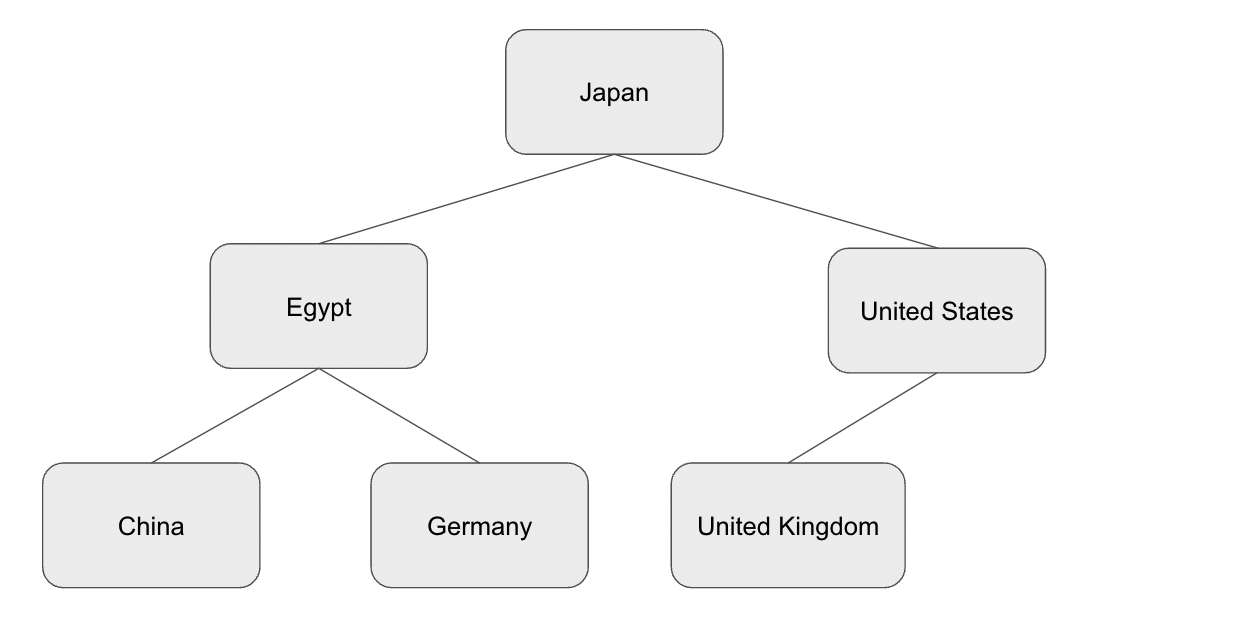
nameインデックスによって木構造で対象のカラムをいち早く取得する事ができます。
この場合にnameカラムに関してのスキャンがかかるとより少ないレコード数でデータを取得することが可能になっています。
例えば
SELECT * FROM Country_name WHERE name = 'Germany'
とクエリを流す際にnameのカラムが昇順になっているためレコードを上から見て一致するレコードを素早く見つけることができようになっています。
インデックスのメリット・デメリット
ここまででインデックスを使用するとなんかとりあえず早くなりそう、便利になりそうといった感じがしていると思いますが、メリットもあればデメリットもあります。
少しだけ紹介したいと思います。
メリット
- 検索する際、特定のレコードを素早く検索することができるため、検索のパフォーマンスが早くなる
- ソート作業を省略できる
デメリット
- データの登録、変更の際、索引変更のための処理が加わるので索引がないテーブルに比べると時間がかかる
簡潔にまとめると検索自体は早くなるけれども追加、変更の作業の際には時間がかかってしまう、ということです。
インデックスをつけて悪くなることは考えづらいですがインデックスをつけてより検索に時間がかかってしまう場合もあるのでなんでもかんでもインデックスを貼ろうとせずまずは一考してみて下さい。
インデックスの使用確認
MySQLではEXPLAINを用いてクエリがどのように実行されているのかを確認することができます。
MySQL 5.6.3 以降は SELECT, UPDATE, DELETE, INSERT, REPLACE ステートメントにおいて EXPLAIN を実行できます。
EXPLAINの見方(参考:MySQL8.0リファレンスマニュアル)
| カラム | 意味 |
|---|---|
| id | SELECT識別子 |
| select_type | SELECT型 |
| table | 出力行のテーブル |
| partitions | 一致するパーティション |
| type | 結合型 |
| possible_keys | 選択可能なインデックス |
| key | 実際に選択されたインデックス |
| key_len | 選択されたキーの長さ |
| ref | インデックスと比較されるカラム |
| rows | 調査される行の見積もり |
| filtered | テーブル条件によってフィルタ処理される行の割合 |
| Extra | 追加情報 |
上記の項目がEXPLAINによって調べることができる項目になります。
この中でも特に実際にみるときに使用するカラムに関してまとめて行きます。
type
テーブルの結合方法を表します。
適切なものから順に説明します。
| 種類 | 説明 |
|---|---|
| system | テーブルに行が1行しかない時。 const結合型の特殊ケース |
| const | テーブルに一致するレコードが最大で1つあり、クエリ開始時に読み取られる。 この行のカラム値は定数とみなされる事がある const テーブルは、1 回しか読み取られないため、非常に高速。 |
| eq_ref | 前のテーブルの行の組み合わせごとに、 このテーブルから 1 行ずつ読み取られる。 |
| ref | 前のテーブルの行の組み合わせごとに、 一致するインデックス値を持つすべての行がこのテーブルから読み取られる。 |
| fulltext | 結合は FULLTEXT インデックスを使用して実行される。 |
| ref_or_null | refとほぼ同じ。 MySQL が NULL 値を含む行の追加検索を実行することが追加される。 |
| index_merge | インデックスマージ最適化が使用されたことを示す。 |
| range | 行を選択するためのインデックスを使用して、特定の範囲にある行のみが取得される。 |
| index | インデックスツリーがスキャンされることを除いて、ALL と同じ。 |
| ALL | フルテーブルスキャンが、前のテーブルの行の組み合わせごとに実行される。 |
基本的にはindex、ALLが選ばれていない限りは問題ないと考えて良いと思います。
key
MySQL が実際に使用を決定したインデックスを示す。
自分が想定したインデックスが使用されていれば問題ないです。
rows
MySQL がクエリを実行するためにスキャンする必要があると考える行数です。
大きければ大きいほど時間がかかってしまい、DBにかかる負担も大きくなるので注意が必要です。
Extra
クエリを高速にしたい場合は Using filesort および Using temporary の値に気をつけましょう。
Using filesort は ORDER BY をする際に、クイックソートを実行します。データ量が大きい時に一時テーブルを作成するので処理に時間がかかり、DBに与える負担もその分大きくなります。
Using temporary は一時テーブルを作成して処理を行うので同様に時間がかかります。
Using filesort および Using temporary が表示されている場合は改善を試みたほうがいいです。
インデックスの貼り方と確認方法および削除方法
インデックスを貼るには以下のいずれかで貼る事ができます。
CREATE INDEX インデックス名 ON テーブル名 (カラム名)
ALTER TABLE テーブル名 ADD INDEX インデックス名(カラム名);
インデックスを貼ったら貼られているのかの確認をしましょう。
SHOW INDEX FROM テーブル名
インデックスを消したい時は以下のいずれかで消すことができます。
DROP INDEX インデックス名 ON テーブル名;
ALTER TABLE テーブル名 DROP INDEX インデックス名;
実際にインデックスを貼ってみる
今回はMySQLの公式のサンプルデータを使ってインデックスの検証をしてみたいと思います。
Other MySQL Documentation
以下の記事を参考にしてMySQL設定をしました。
MySQLのちゃんとしたサンプルデータ
今回使用するテーブル情報は以下です。
テーブル名:country
レコード数:239
CREATE TABLE `country` (
`Code` char(3) NOT NULL DEFAULT '',
`Name` char(52) NOT NULL DEFAULT '',
`Continent` enum('Asia','Europe','North America','Africa','Oceania','Antarctica','South America') NOT NULL DEFAULT 'Asia',
`Region` char(26) NOT NULL DEFAULT '',
`SurfaceArea` decimal(10,2) NOT NULL DEFAULT '0.00',
`IndepYear` smallint(6) DEFAULT NULL,
`Population` int(11) NOT NULL DEFAULT '0',
`LifeExpectancy` decimal(3,1) DEFAULT NULL,
`GNP` decimal(10,2) DEFAULT NULL,
`GNPOld` decimal(10,2) DEFAULT NULL,
`LocalName` char(45) NOT NULL DEFAULT '',
`GovernmentForm` char(45) NOT NULL DEFAULT '',
`HeadOfState` char(60) DEFAULT NULL,
`Capital` int(11) DEFAULT NULL,
`Code2` char(2) NOT NULL DEFAULT '',
PRIMARY KEY (`Code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
今回流すクエリは以下になっています。
人口(population)が1億人以上のレコードを取ってくるようにしています。
SELECT * FROM country WHERE population > 100000000;
このクエリをインデックスを貼る前にEXPLAINの結果を見てましょう。
mysql> EXPLAIN SELECT * FROM country WHERE population > 100000000;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | country | NULL | ALL | NULL | NULL | NULL | NULL | 239 | 33.33 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
先ほどあげたtype,key,rows,extraに注目してみると
全レコードをスキャンしてインデックスを貼っていないのでkeyに何も指定されていないことがわかります。
データがこの程度の量であれば問題ないのですが、大量のデータ、またDB自体に多くのクエリが流されるような場合にはフルテーブルスキャンは非常に危険になっています。
それでは実際にインデックスを貼ってみましょう
mysql> CREATE INDEX index_population ON country (population);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
インデックスが貼られているのかの確認をしてみましょう
mysql> SHOW INDEX FROM country;
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| country | 0 | PRIMARY | 1 | Code | A | 239 | NULL | NULL | | BTREE | | |
| country | 1 | index_population | 1 | Population | A | 226 | NULL | NULL | | BTREE | | |
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.01 sec)
index_populationという名前でインデックスが作成されていることが確認できます。
インデックスが確認できたのでクエリにEXPAINを貼ってみてみましょう。
mysql> EXPLAIN SELECT * FROM country WHERE population > 100000000;
+----+-------------+---------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | country | NULL | range | index_population | index_population | 4 | NULL | 10 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
同様にtype,key,rows,extraに注目してみてみると
インデックスindex_populationを使用して10レコードのみをスキャンしてデータ取得をしている事がわかります。
インデックス貼る前と比較してスキャンするレコード数が激減しているのでDBへかかる負担を抑えることができています。
最後に不要になったインデックスの削除もしてみましょう
mysql> DROP INDEX index_population ON country;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
削除したので確認しましょう
mysql> SHOW INDEX FROM country;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| country | 0 | PRIMARY | 1 | Code | A | 239 | NULL | NULL | | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.01 sec)
index_populationが削除されている事が確認できました。
以上がインデックスの作成から削除までの流れになります。
DBに負荷をかけないクエリの作成、にぜひ活かしてみてください。
まとめ
今回は
- インデックスとは何か
- EXPLAINについての簡潔な説明
- インデックスを実際に使ってみる
上記にスポットを当ててみましたがこれを機に今回省略したB-tree,EXPLAINの他のカラムの詳細についての学習もしてみてください。
最後までご閲覧ありがとうございました。