RでGISを行うメリットは、高度な統計手法を利用できることです。GRASS GISやQGISでは提供されていないポイントデータの分布に関する分析をRで行います。
### 必要なパッケージの読み込み
library(tidyverse)
library(sf)
library(GISTools)
library(spatstat)
library(ggthemes)
### データの読み込み
# st_read()関数でsfクラスでシェープファイルを読み込み
map<-st_read(dsn="data/",layer="kokudo_gyousei_utm54") #国土数値情報行政界
point<-st_read(dsn="data/",layer="site") #道南の遺跡の位置
読み込んだデータは道南の遺跡地図と行政界のシェープファイル
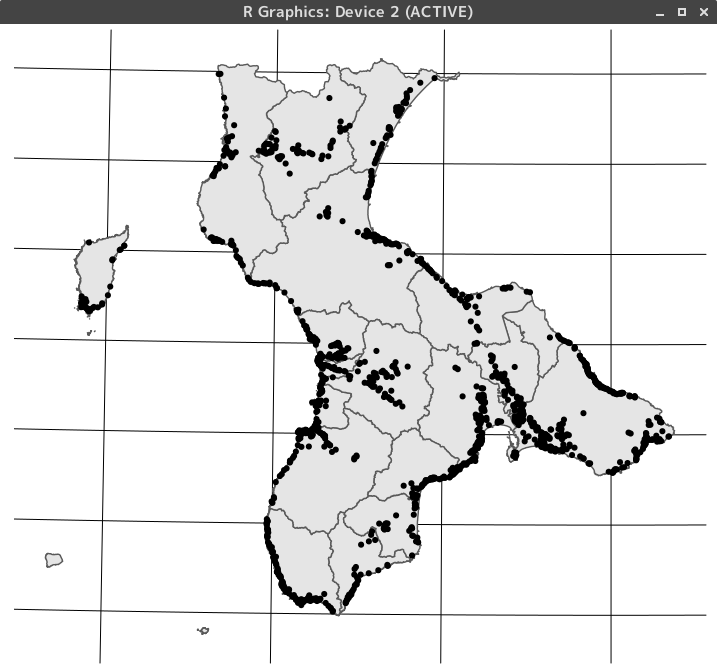
### ggplotのgeom_sf()で地図を描画
## theme_map()を指定
ggplot()+
geom_sf(data=map)+
geom_sf(data=point) +
theme_map()
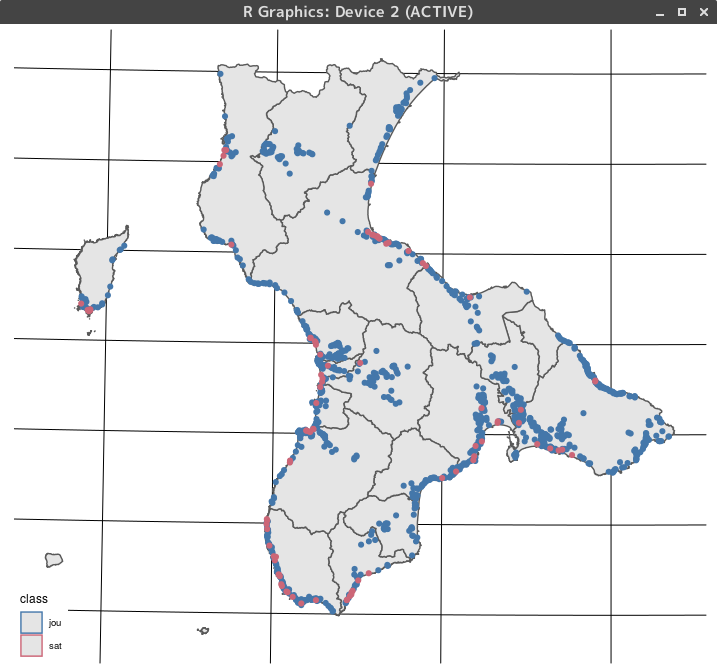
擦文の遺跡と縄文の遺跡の分布に違いがあるか?
擦文文化の遺跡と縄文時代の遺跡の分布に差があるかどうかを調べます。
一つのフィールド(period)に複数の時期区分が入力されているので、grepl()を使って擦文と縄文の遺跡に分けて抽出します。
### 擦文と縄文に分類した新たなフィルード(class)を追加
## select関数が他のパッケージの関数と衝突しているみたいなのでdplyr::でパッケージを明示
point<-point%>%
mutate(class = case_when(
grepl("擦文",period) == TRUE ~ "sat",
grepl("縄文",period) == TRUE ~ "jou"
))%>%
filter(class=="jou" | class=="sat") %>%
dplyr::select(class)
## データの内容
head(point)
Simple feature collection with 6 features and 1 field
geometry type: POINT
dimension: XY
bbox: xmin: 403989.5 ymin: 4697690 xmax: 406840.4 ymax: 4716456
epsg (SRID): NA
proj4string: +proj=utm +zone=54 +ellps=GRS80 +units=m +no_defs
class geometry
1 jou POINT (405113.2 4706010)
2 jou POINT (405571.3 4700497)
3 jou POINT (403989.5 4716456)
### ggplotで描画
ggplot()+
geom_sf(data=map)+
geom_sf(data=point,aes(colour=class))+
theme_map()+
scale_colour_ptol()
spatstatパッケージを使う
spatstatパッケージは地理空間にかかわる様々な統計手法を提供します。
データ形式が独自のpppオブジェクトなので、sfクラスをpppオブジェクトに変換する必要があります。
これが今回の記事のポイントです
sfクラスを直接pppオブジェクトに変換するのは難しいので、データフレームに変換して処理していきます。
以下のような手順です。
- 遺跡位置データをデータフレームに変換
- 遺跡位置データからxy座標を取り出してデータフレームに変換
- xy座標を遺跡位置データにマージ
- pppオブジェクト生成
### point(遺跡の位置データ)をデータフレームに変換
point_df<-point%>%as.data.frame()
### pointオブジェクトからxy座標を取り出す
## coordinates()関数でxy座標を抜き出してデータフレームに変換
coord<-point%>%st_coordinates()%>%as.data.frame()
## xy座標だけが抜き出された
head(coord)
X Y
1 405113.2 4706010
2 405571.3 4700497
3 403989.5 4716456
### point_dfとcoordを結合します。
## これでpointデータと同じ状態のデータフレームができる
point_join<-bind_cols(point_df,coord)
# geometryが残ったままだが、classとxy座標が独立したフィールドになる
head(point_join)
class geometry X Y
1 jou POINT (405113.2 4706010) 405113.2 4706010
2 jou POINT (405571.3 4700497) 405571.3 4700497
3 jou POINT (403989.5 4716456) 403989.5 4716456
pppオブジェクトを生成
### pppオブジェクトを生成
## c(),c()は分析対象領域のx座標とy座標の最小値、最大値
## marks=は遺跡の区分が入ったclassフィールドをfactorに変換して渡す。
point_p<-ppp(point_join2$X,point_join2$Y,
c(point_join2$X%>%min(),point_join2$X%>%max()),
c(point_join2$Y%>%min(),point_join2$Y%>%max()),
marks=factor(point_join2$class))
spatstatの機能を利用した可視化
sfクラスのデータをpppオブジェクトに変換できたので、spatstatパッケージの機能を利用した可視化を行います。
### 散布図を出力
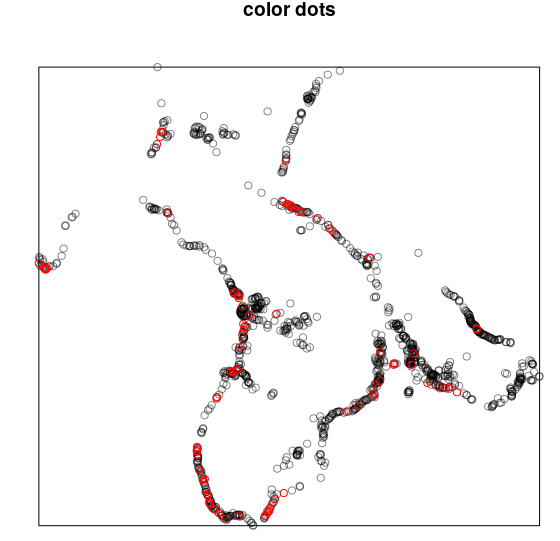
plot(split(point_p)$jou,main="color dots" )
points(split(point_p)$sat,col=10)
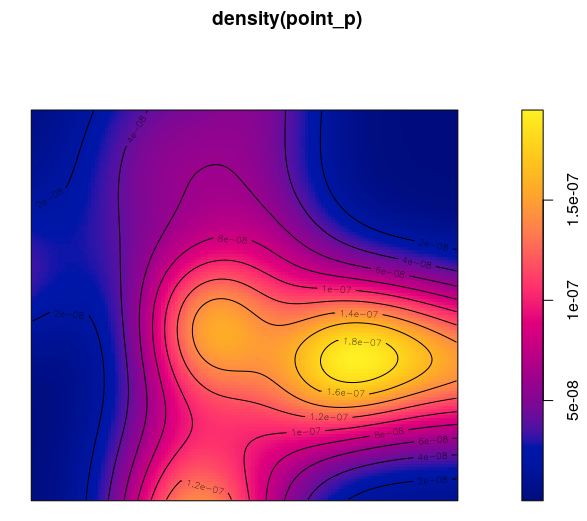
### カーネル密度推定図と等高線を出力
point_p%>%density()%>%plot(1)
point_p%>%density()%>%contour(add=T)
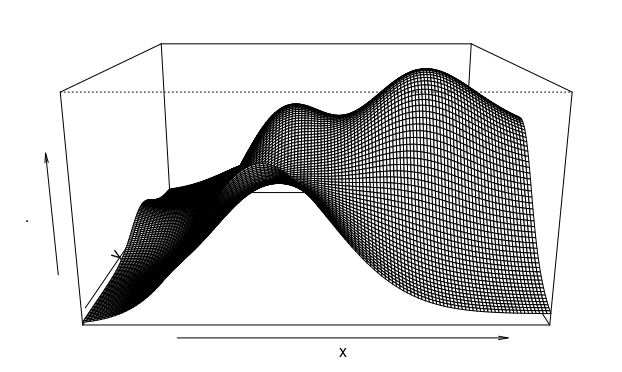
### 3D出力
point_p%>%density()%>%persp()
遺跡はランダムに分布しているのか?
L関数を利用して遺跡データの空間分布の偏りを判定します。
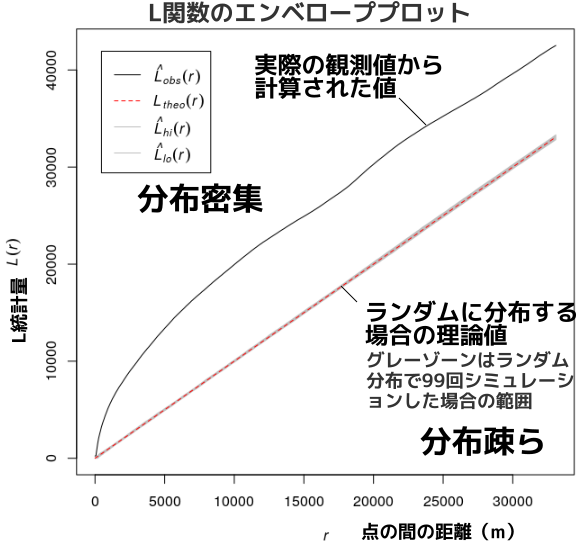
### シミュレーションによる適合度(L関数)
point_p%>%envelope(Lest,nism=99)%>%plot()
エンベローププロットはランダムに分布すると仮定した場合の理論値と実測値のずれを可視化します。
理論値(赤点線)より上に実測値がプロットされていれば密集した分布、下にプロットされていればまばらに分布すると判断します。
遺跡の分布は赤点線よりかなり上に実測値(黒線)がプロットされているので、「密集した分布」と言えそうです。
遺跡分布は地形や開発状況に左右されるので当然といえば当然かもしれません。
擦文文化期の遺跡と縄文時代の遺跡立地は異なるのか?
擦文文化期の遺跡分布と縄文時代の遺跡分布の関係を可視化します。
仮説としては次の3通りが考えられます。
- 擦文文化期と縄文時代の遺跡は互いに無関係に分布する
- 擦文文化期の遺跡は縄文時代の遺跡に接近して分布する
- 擦文文化期の遺跡は縄文時代遺跡から離れて分布する
いずれの可能性があるのかを「マーク付き点過程(Marked Point Processes)」という手法で可視化します。
### マーク付き点過程
## シミュレーションによる適合度(L関数)
point_p%>%envelope(Lcross,nism=99)%>%plot()
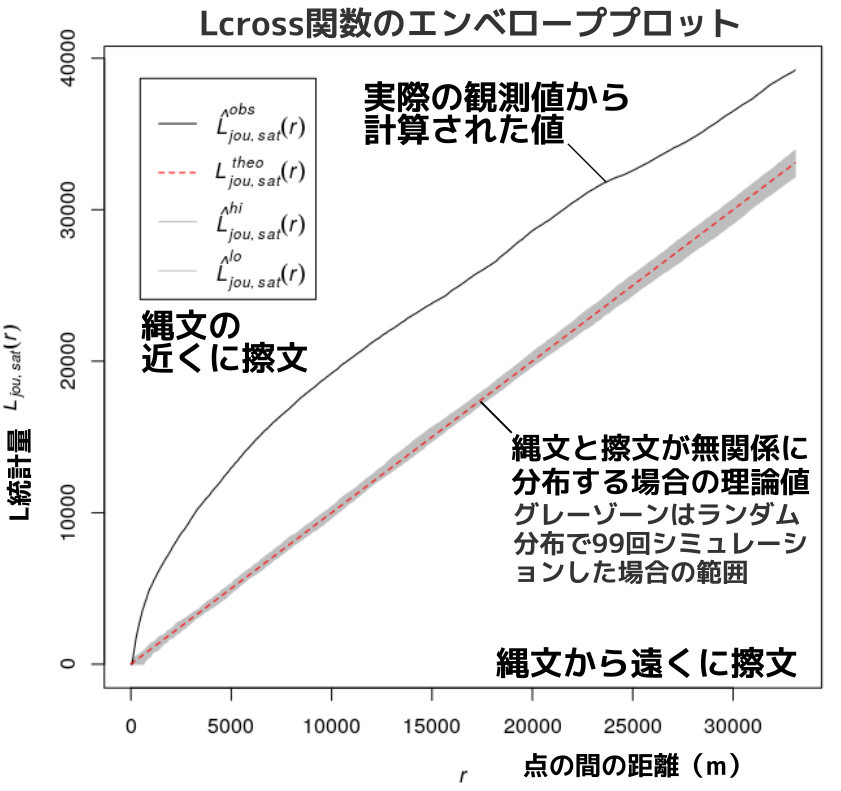
エンベローププロットからは、縄文遺跡の近くに擦文遺跡が分布していることがわかります。
遺跡立地は地形制約が大きいので当然の結果ともいえます。
縄文遺跡と擦文遺跡の立地には何らかの違いがありそうにも思えるのですが、統計的に証明することは難しそうです。
ポイントパターン分析まとめ
spatstatパッケージを使いこなすことが肝心だと思いました。
一番の障害はpppオブジェクトへの変換で、sfパッケージで読み込んだGISデータがそのまま使えないのが手数のかかる原因となっています。
今回は、いったんデータフレームに変換してからpppオブジェクトに変換しましたが、もう少しスマートに処理できるように統合的な処理環境になればよいと感じました。