概要
この記事では、webアプリケーション開発の「ウェ」の字も知らない筆者が、FlaskとHerokuを利用してwebアプリケーションをデプロイするまでの記事になります。
- 自作のwebアプリケーションを作ってみたい!
- Pythonを用いた開発をしてみたい!
- LINEで話す相手が本当に自分のことを好きなのか確かめたい。
というような願望をふわっと抱いたことのある方に刺さるよう書こうと思いますので、どうぞよろしくお願いします。
こちらが作成したアプリへのリンクです。
本記事の流れ
- pythonで分析
- Flaskサーバー構築
- フロントを書く
- ローカルでの実行テスト
- 必要機能追加
- データベース機能追加
- Heroku移行してデプロイ
追記したい記事
・ 分析のpythonスクリプト一部抜粋
・ MySQLからPostgreSQLにDB移行する流れ → 本来はダンプするのが常識らしい
前提
以下は筆者のアプリ作成時のステータスです。
- サーバーやネットワークの知識は基本情報試験並みかそれ以下
- webアプリケーション開発やデプロイは未経験
- Pythonによるデータ分析はそこそこできる(調べればわかる)
- HTML, CSS, JavaScriptが大体書ける(又は見たらわかる)
こんな感じの筆者が0→1で作成しました。
開発phaseで一般的な開発常識を外れることがありますがご了承ください。
作成するもの
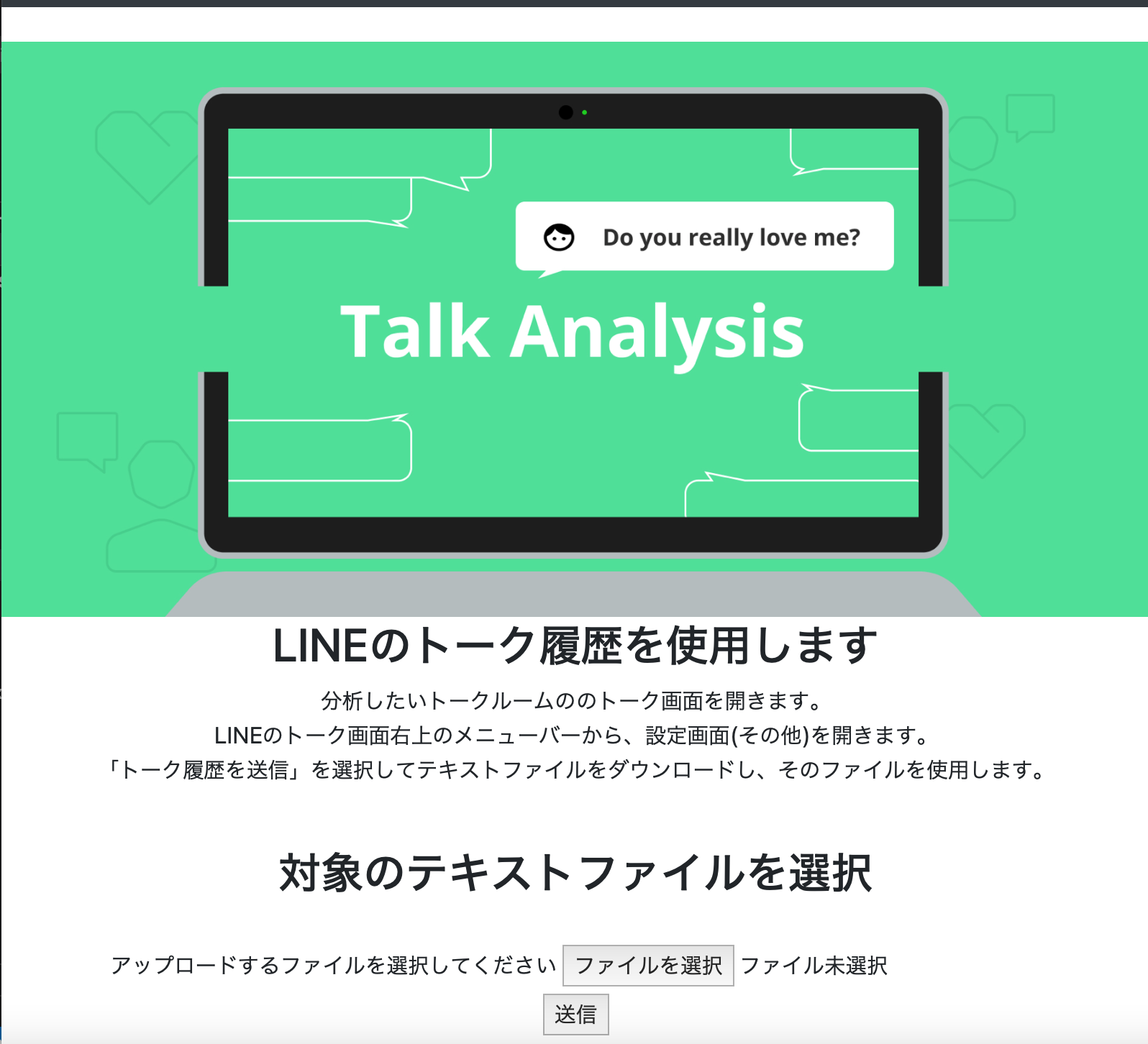
1番最初に表示されるページがこちらです。
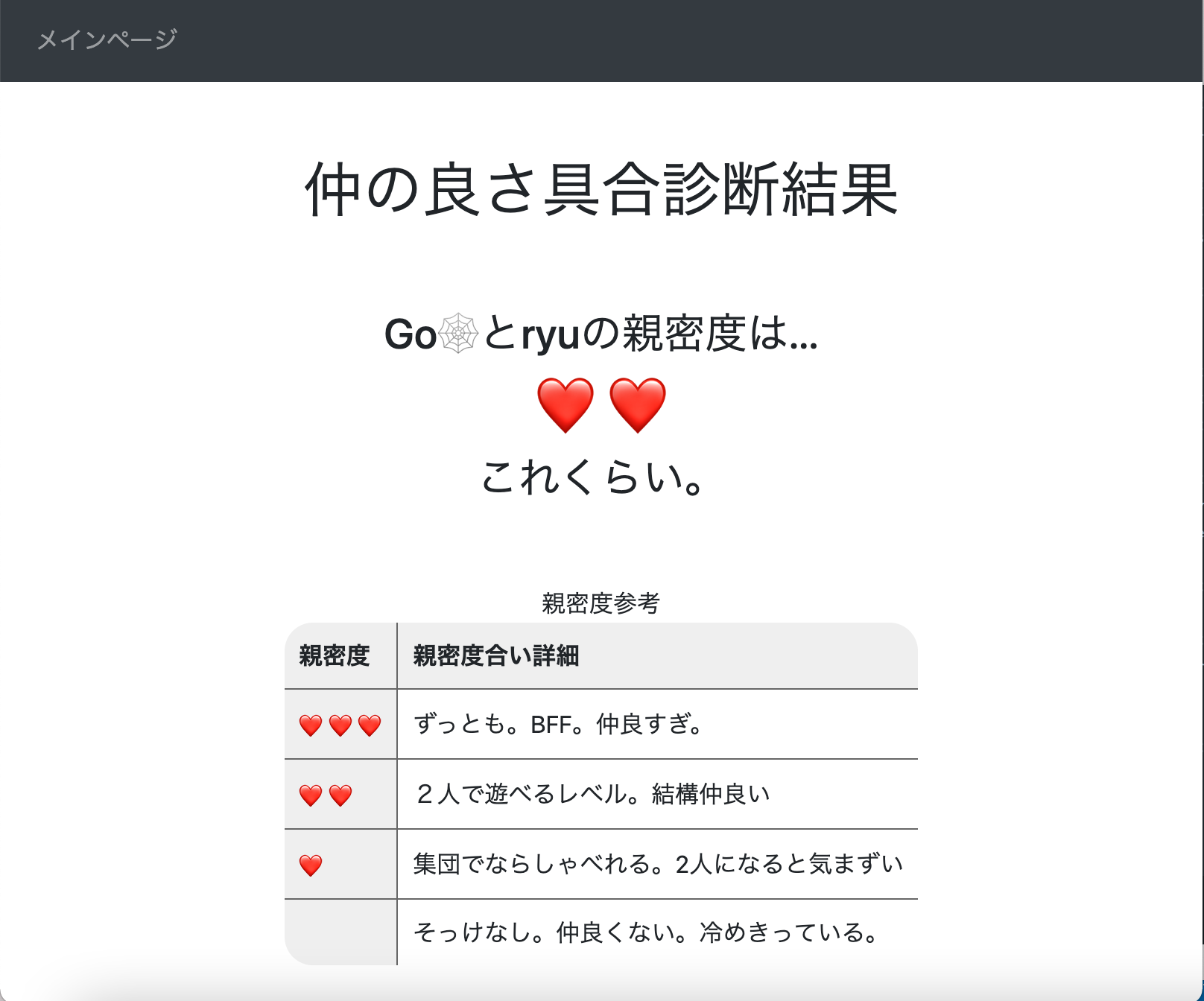
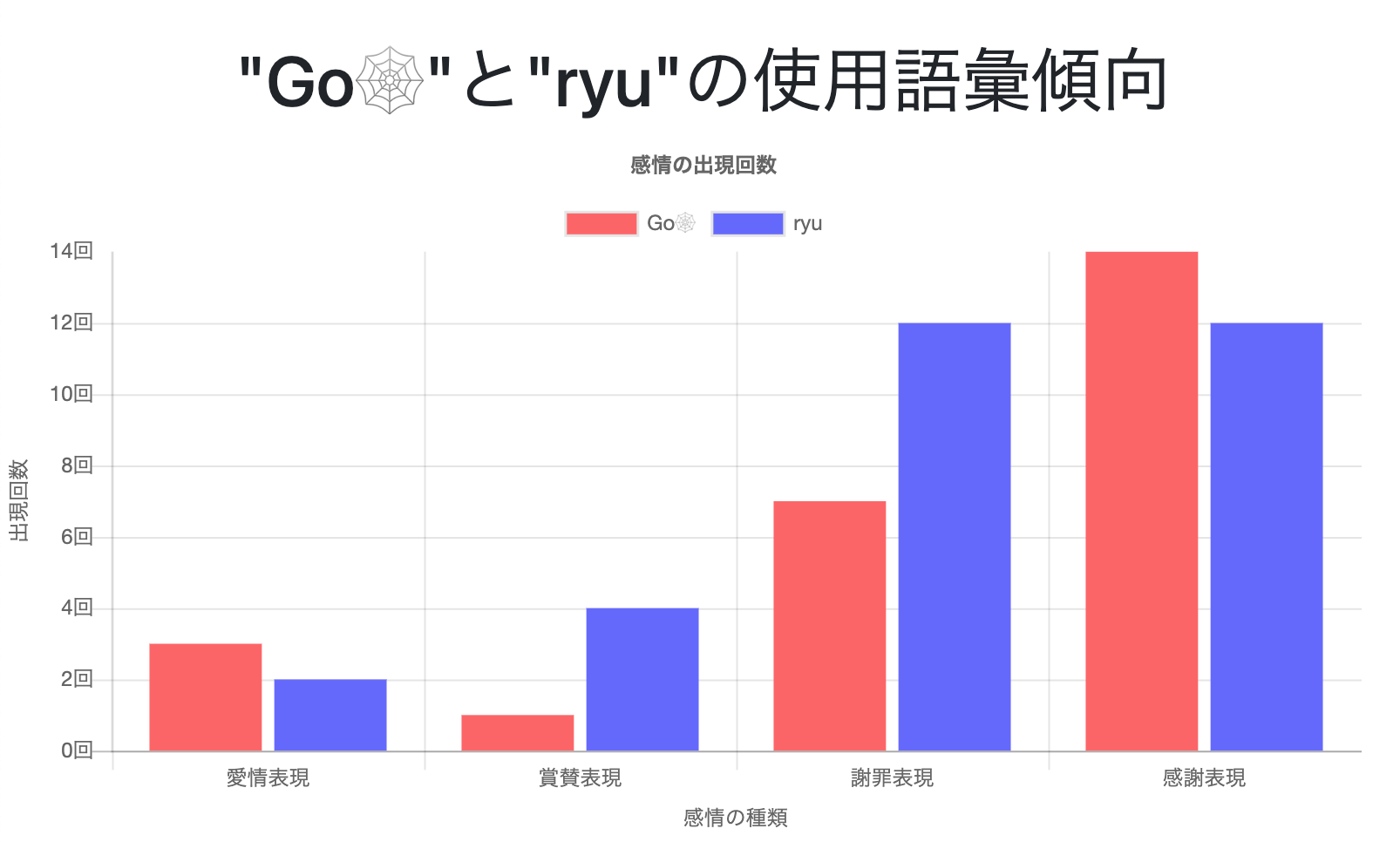
分析結果を表示させるページがこちらです。

実行環境
- MacOS BigSur
- python 3.8.11
- Flask 2.0.1
- heroku 7.56.1
- MySQL
- postgreSQL
1. LINEのテキスト分析
pythonでLINEのトークスクリプトを分析します。
LINEのテキスト分析は別のQiita記事を書こうと思いますので、そちらを参考にしてください。
[執筆中]
2. Flaskアプリの作成
とりあえずローカル環境でflaskアプリを動作させることを目標にします。
Flaskインストール
pip install flask
開発環境はご自身で作成してください。僕はanacondaの仮想環境上で開発しました。
Flaskサーバーの構築
全体のディレクトリ構造はこんな感じです。
project
|── app.py // 実際に実行するpythonファイル
└── templates
|── index.html // webページを書くところ
└── result.html // 分析結果を表示するページ
で、app.pyを書いていきます。
from flask import Flask
from flask import render_template
from flask import url_for
app = Flask(__name__, static_folder='static')
@app.route('/')
def main():
return render_template('index.html', title='LINE TALK ANALYSIS')
@app.route("/templates", methods=["GET"])
def index():
return render_template("index.html")
if __name__ == "__main__":
# webサーバー立ち上げ
app.run(debug=True, host="127.0.0.1", port=8085)
これでFlaskサーバーを立ち上げることができ、ローカル環境でwebアプリを起動することができます。
この段階ではまだ表示するwebページを何も書いていないのでindex.htmlを書きに行きます。
3. HTMLを書く
ひとまずはチュートリアルとしてローカルで動くところまで持っていければいいので、シンプルにいきましょう。
<head>
test output
</head>
<boby>
<h1>
Hello World
</h1>
</boby>
これを、上記のwebアプリのディレクトリ構造に合うようtemplatesフォルダの内部に作成しておきます。
textファイルをflaskサーバーで受け取ったり、分析結果をwebブラウザに送ったりする作業は少し手間なので保留して、一旦webページを表示させてみます。
4. ローカルでの実行テスト
以下はtarminalで実行する内容です。
// 今回のprojectディレクトリへ移動
$ cd project
// python実行
$ python app.py
これで表示されるURLをブラウザに打ち込むとHello Worldと表示されるはずです。
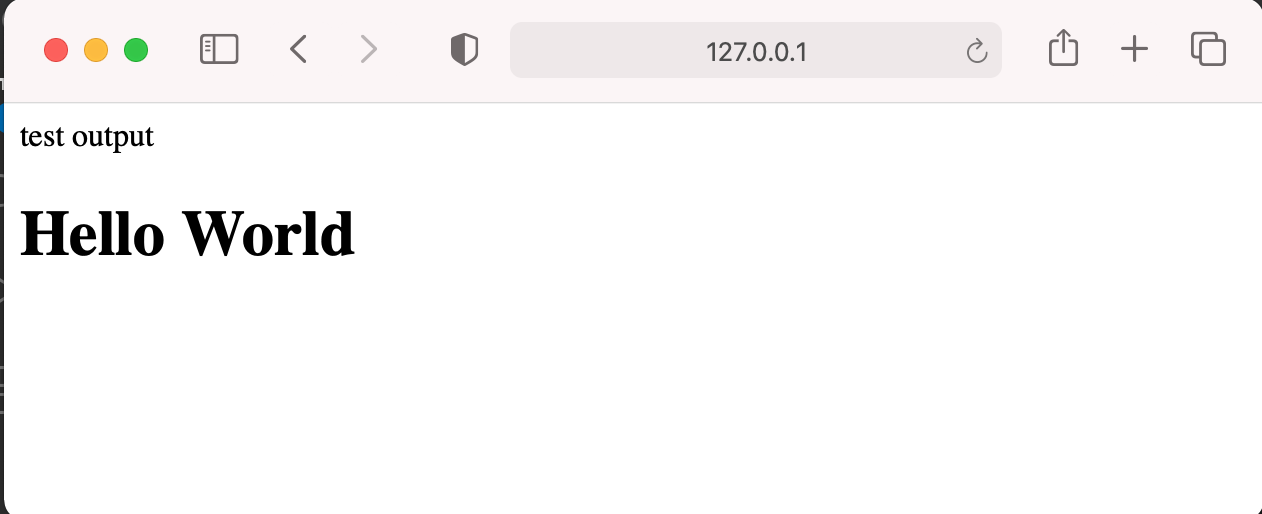
以上で、ローカルでの動作確認は完了です。
flaskのチュートリアルはこんな感じで、必要機能の実装をしていきましょう!
5. 必要機能追加
追加で必要な機能は、
- ユーザーからflaskサーバーにテキストファイルを送信する機能
- 取得したテキストファイルを分析する機能
- 分析結果をクライアント側に返す機能
- 返ってきた結果をかっこよく表示させるページ
です。なのでまず、テキストファイルを受け取りに行きます。
textファイルを送信するボタン追加
下記のrequest.files['ファイル名']
でtextファイルを読み込むことができます。
@app.route('/',methods=['POST'])
def post():
input_text = request.files['file1']
変数 = 分析結果を返す関数(input_text)
return render_template('result.html', result.htmlで出力したい変数)
html側では、以下をボタンとして追加します。
<form method="post" enctype="multipart/form-data">
<label for="file1">アップロードするファイルを選択してください</label>
<input type="file" id="file1" name="file1" multiple>
<div>
<button>送信</button>
</div>
</form>
参考にしたドキュメント
https://msiz07-flask-docs-ja.readthedocs.io/ja/latest/patterns/fileuploads.html
取得したファイルを分析する機能
詳しくはGithubのコードを参照してもらい、ここでは簡単な関数を記載します。
def get_result(input_text):
line_df = pandas.read_csv(input_text, sep='\n')
line_df = line_df.rename(columns={line_df.columns[0]:'talks'})
line_df = line_df[1:]
# 正規表現でトークから日付を取得し新しいカラムとして結合する
date_list = []
date_pattern = '(\d+)/(\d+)/\d+\(.?\)'
for talk in line_df['talks']:
result = re.match(date_pattern, talk)
if result:
date_t = result.group()
date_list.append(date_t)
else:
date_list.append(date_t)
line_df['date'] = date_list
flag = line_df['talks'].isin(line_df['date'])
line_df = line_df[~flag]
line_df.dropna(inplace=True)
time_l = []
user_l = []
talk_l = []
date_l = []
count = 0
for date, talk in zip(line_df['date'], line_df['talks']):
# もし正規表現で時間が取れたらスプリットして3つに分ける
if(re.match('(\d+):(\d+)', talk)):
try:
if(len(talk.split('\t')[0]) == 5):
date_l.append(date)
time_l.append(talk.split('\t')[0])
user_l.append(talk.split('\t')[1])
talk_l.append(talk.split('\t')[2])
count = count + 1
else:
continue
except:
talk_l.append("メッセージの送信取り消し")
count = count + 1
else:
talk_l[count-1] = talk_l[count-1] + talk
line_df = pandas.DataFrame({"date" : date_l,
"time" : time_l,
"user" : user_l,
"talk" : talk_l})
user1 = line_df['user'].unique()[0]
user2 = line_df['user'].unique()[1]
user1_len = len(line_df[line_df['user']==user1])
user2_len = len(line_df[line_df['user']==user2])
return user1_len, user2_len, user1, user2
テキストファイルをpython側で受け取ったら、データの分析がしやすいようにデータを整形する作業から始めます。
テキストファイルは読み込んだ際、日時:名前:トーク
という形式のデータなのですが、トークの中にタブが含まれていたりと不都合が多いので、一旦読み込んでから正規表現でデータを分解してカラムに加えています(ただのゴリ押しなのでお勧めしない方法です。)
データの整形が終わったらあとは各々が好きに分析すればよく、今回は簡単にするために、
- トークしているユーザーの名前
- 各ユーザーの喋った総回数
を返す関数を作成しました。
分析結果を返す機能
クライアント側で最終的に表示させたい数値等のデータ(分析結果)を、flaskのrender_templateという関数で返してもらいます。
def post():
input_text = request.files['file1']
user1_len, user2_len, user1, user2 = get_result(input_text)
return render_template('result.html', user_name1=user1, user_name2=user2, user1_len=user1_len, user2_len=user2_len)
return文でrender_templateを用いており、user_name1,user_name2,user1_len,user2_lenを、それぞれresult.htmlで利用できるように投げています。
こちらがrender_templateのドキュメントで、
https://msiz07-flask-docs-ja.readthedocs.io/ja/latest/tutorial/templates.html
こちらが参考にした記事です。
https://qiita.com/nagataaaas/items/4662237cfb7b92f0f839
返ってきた結果をかっこよく表示させるページ
ここから先はJava Script書いて行きます。
本記事の趣旨とはズレるため、専用の記事を書くまでは上げているGithubを参考にしてください。
もしくは、自分がこちらの記事を参考にして作成したものなので合わせてご参照ください。
https://qiita.com/Haruka-Ogawa/items/59facd24f2a8bdb6d369
https://news.mynavi.jp/article/zerojavascript-3/
6. データベース接続
ここからが2つ目の壁でした。
ローカル環境ではMySQLを利用していたのですが、Herokuの無料プランだと、サポートしているDBがPostgreSQLだけだったので、MySQLから移行しなければなりませんでした。
Herokuデプロイを最初から目的としている場合は、PostgreSQLを最初から利用するのが良さそうです。
(ローカル環境ではMySQLで動いているので一旦MySQLの接続までを書きます。)
DBに接続情報を書く
以下の関数を用いると、ローカルで作成したsampleというDBに接続することができます。
(事前にDBは作成している必要がありますが、作成に関してはこの辺の記事を参考にしました。)
https://www.dbonline.jp/mysql/database/index1.html
https://prog-8.com/docs/mysql-database-setup
def conn_db():
conn = mysql.connector.connect(
host = 'localhost',
port = '3306',
user = 'root',
password = 'root',
db = 'sample'
)
return conn
conn = conn_db() # DB接続
cursor = conn.cursor() # カーソルを取得
cursor.execute('####') # クエリを書く
conn.close() # DB切断
DBに接続してからは
- テーブルの作成
- データ取得
- データ追加
の動作を行って最後に切断すればアプリのバックエンド側でDBを触ることができます。
さぁこれでアプリケーションに必要な機能が全て揃いました!
ローカルで遊ぶ分には困らないと思います!
が、せっかく作成したのでポートフォリオにするためにもデプロイしたいの思うのが人間の性。
なんならデプロイせんと意味がない。
ですので、MySQL → PostgreSQLに移行することで、
ローカルで作成したアプリをHerokuデプロイします。
7. herokuデプロイ
- 必要ファイルの作成
- Herokuアカウント作成
- HerokuでDB作成
- Python script側のDB接続情報を変更する
この流れでデプロイしていきます。
herokuデプロイに必要なファイル作成
まず最初に、デプロイするプロジェクトファイルの構造を整理しておきます。
project--templates/
|_Procfile
|_app.py
|_runtime.txt
|_requirements.txt
このような階層構造にしています。
ここから、まだ作成していない3つのファイルを作成します。
runtime.txt
pythonのバージョンを記載したruntime.txtを作成します。
以下のコマンドだと、読み取れる表記と異なる場合があるため、ハイフンの位置等に注意してください。
python --version > runtime.txt
requirement.txt
次に、関連モジュールの一覧を記載したrequirements.txtの作成をします。
pip freeze > requirements.txt
Procfile
プログラムの実行方法を記載したProcfileを記載します。
web: gunicorn app:app --log-file=-
僕はgunicornを使いました。
上記のファイル作成時に参考した記事はこちらです!
デプロイする
Herokuのアカウント作成→デプロイはrakusのtechブログを参考にしました。
非常にわかりやすかったのでとてもおすすめです。
基本的には上からドキュメントを追っていけば進むのですが、個人的にスタックしたポイントと、それを解決するときに参考にしたリンクを貼って締めたいと思います。
buildpacksの設定
Heroku DBアクセス
データベースのアクセスまではこれを参考にしました。
portの指定をなくす
ローカル環境だと、8080等でポートを指定しますが、herokuデプロイ時は取り除きます。
webサーバーがapサーバーを叩く時にポートが80だと、root権限が必要なのですが、実行者(クライアント側)はherokuのroot権限を持っていないので弾かれてしまうためです。
(Flaskはデフォルトの設定で大丈夫なのですが、Djangoのデフォルト設定はまた違うため別途で設定する必要があります。)
最後に
後半のデプロイ部分は説明をだいぶ端折りましたが、webアプリケーションを一般公開する流れはなんとなく掴んでいただけたかと思います。
pythonで関数を作ってみたり、アプリを作ってみてもどうやってwebアプリに組み込むのかわからないという方は多いと思いますが、今回の記事が少しでも皆さんのためになれば幸いです。
拙い文章ではありましたが、ここまでご精読ありがとうございました!