![]() 当記事は2017/8月に投稿しましたが、現時点(【2019/2月】)では既に古くなっています。記事自体はアーカイブの目的でこのまま残しますが、当記事の内容を参考になさらないようにお願いいたします。FlowsはWatson Studioに含まれましたので、代替の記事としては下記などがございます。
当記事は2017/8月に投稿しましたが、現時点(【2019/2月】)では既に古くなっています。記事自体はアーカイブの目的でこのまま残しますが、当記事の内容を参考になさらないようにお願いいたします。FlowsはWatson Studioに含まれましたので、代替の記事としては下記などがございます。
はじめに
こんにちわ!この記事は「Bluemix上で機械学習モデルを簡単に作れる「Watson Machine Learning」を使ってみた」の続きです。今回はブラウザー上でSPSS Modelerみたいに簡単に機械学習モデルをつくれるFlows(Canvasとも呼ばれる)をご紹介します。
以下は記事執筆時点(2017/08月)のものです。Flowsはまだベータなので先々、画面が変わっていたり機能が強化されていたらすいません。
Flowsとは?
百聞は一見に如かず、で要はこんなのです。ブラウザー上でSPSS ModelerのようなUIと操作性で機械学習モデルを作成・デプロイできます。
- 現在(2017/08)はベータですので、「お披露目」的な意味合いが強いです
- ランタイムとしてSpark環境向け/SPSS環境向けの2種類が提供されています
- 2つの環境のUIや操作性はほぼ共通していますが、各々の環境で提供されている手法・ノードは異なっています。(今はSPSS Flowの方がノード数は多いです。当記事の末尾にパレット上のノード一覧を付けましたので、よろしければご参照ください)
- SPSS Flowも現時点ではデスクトップ版のSPSS Modelerほど多くの手法・ノードが実装されているわけではありませんので、「SPSS Modelerの代わり」にはなりません。
SPSS Flowをやってみる
ネタ元: このチュートリアルです。
1. シナリオ
ある人が慢性腎臓病(chronic kidney disease)かどうかを判定する機械学習モデルを作ります。結果はYES/NOなので「分類」(Classification)の問題です。

2. データのダウンロード
WML-KidneyDiseaseTutorialからClone/Downloadしてzipを解凍します。filesディレクトリーにchronic_kidney_disease_full.csvができます。
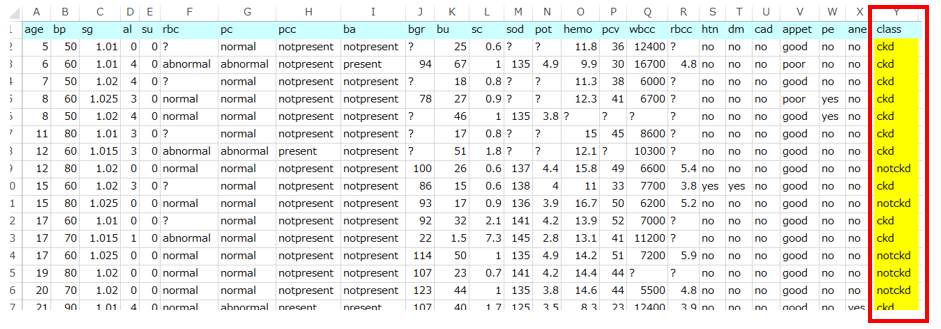
データは以下のようなCSVで、一番右側の「class」フィールドの値が「ckd(chronic kidney disease)」か「notckd」かを予測することになります。
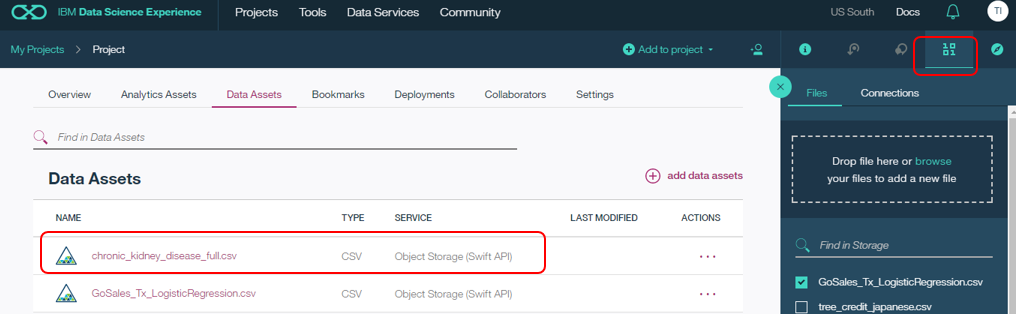
3. DSXにログインしてデータをアップロードする
具体的な手順は重複するので割愛します。前の記事などご参照ください。こんな感じでファイルがDSX上に登録されました。
4. プロジェクトにFlowを登録する
「Add to project」で「Flow」を選択
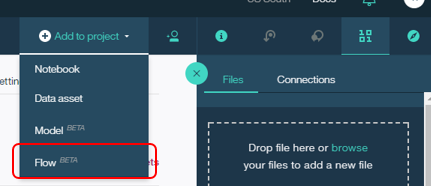
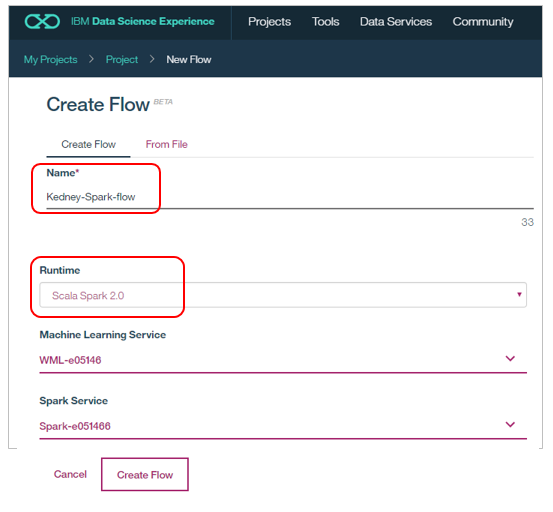
お好きなフローの名前を入力し、ランライムは「IBM SPSS Modeler」を選択して「Create Flow」
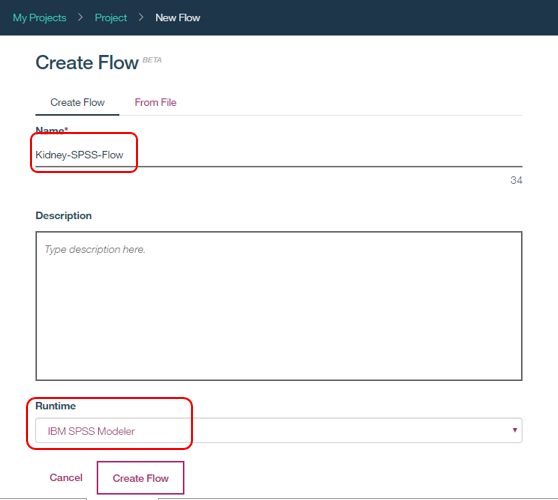
空のキャンバスが開きました
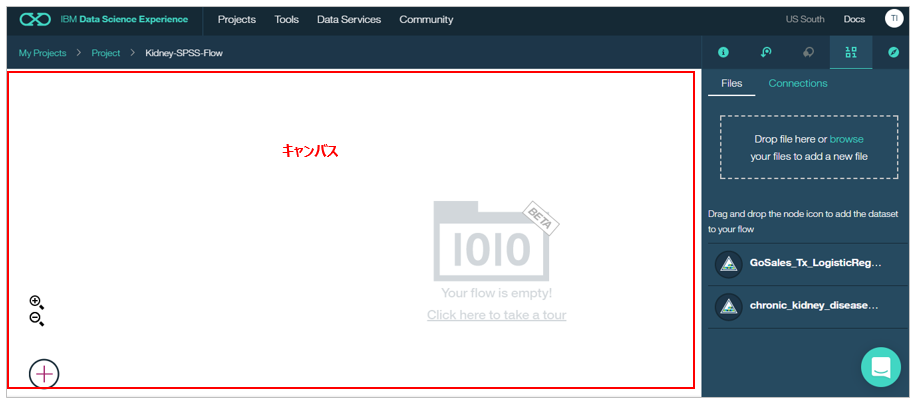
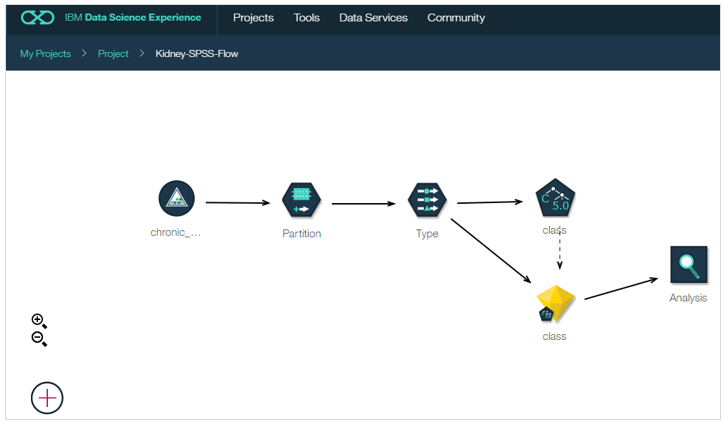
5. フローを作る
まずは右側のリストから先程のファイルをキャンバス上にドラッグ&ドロップします
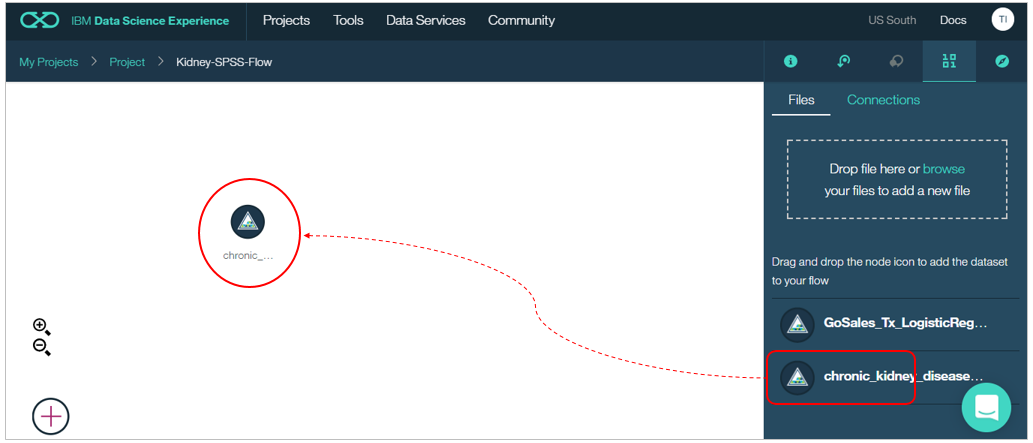
左下の十字をクリックするとパネルが開きます。「Field Operations」のタブから「Partition」を選んでキャンバスにドラッグ&ドロップします
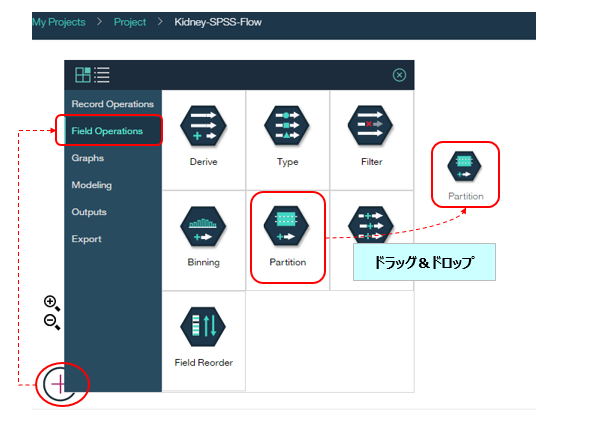
データとPartitionを接続します。繋ぐ際は操作上のコツがあるのですが、①起点となるファイルのノードの上にマウスを持っていくと、青い丸で囲まれます ②この状態でマウスの選択を離さずに終点であるPartitionのノードまで伸ばします。(接続は点線で表示されます) ③終点上でマウスの選択を離すと2つのノードが実線で結ばれます。

同様の操作でパレットから以下2つのノードも追加します。
| タブ | ノード |
|---|---|
| Field Operations | Type |
| Modeling | C5.0 |
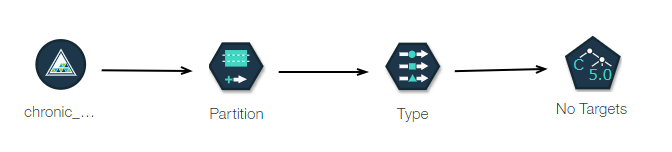
結果、以下のようなフローができました
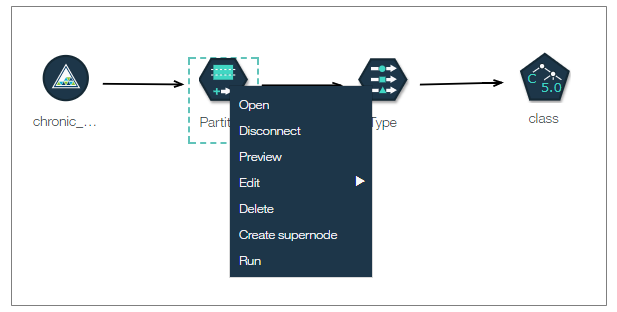
ノードで右クリックするとコンテキスト・メニューが表示されます
6. ノードの設定をする
まだノードを繋いだだけです。各ノードをダブルクリックすると設定パネルが表示されますので順番に見ていきましょう。
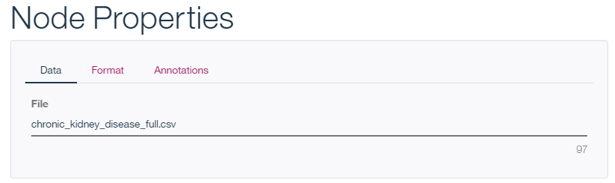
1) ファイル・ノード
ファイル名以外に区切り文字、文字コードなどの設定ができます。今は「見るだけ」にします。(=「Cancel」)
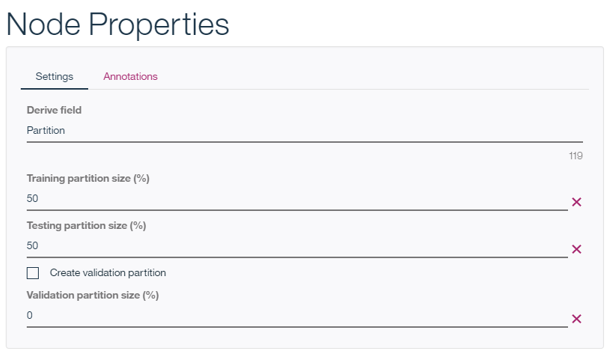
2) Partitionノード
レコードを教師データとテスト・データに分割する比率を指定します。品質評価用のデータを取り分けておくこともできます。今は「見るだけ」にします。(=「Cancel」)
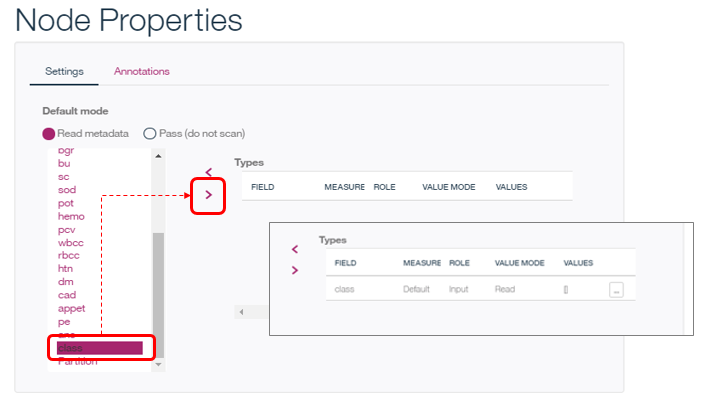
3) Typeノード
ここで「予測したいこと(目的変数)」が何であるか、の設定をします。
今回のデータでは「慢性腎臓疾患かどうか」を表すフィールドは「class」ですので、左側のフィールドのリストから「class」を選択して「>」ボタンで目的変数に設定します。するとclassが右側に移動します。
右側の「Edit」をクリックすると
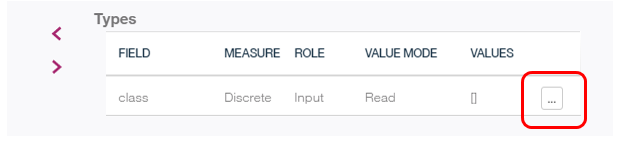
パネルが開くので「Role」を「Target」に変更して「OK」。これで「classが目的変数だよ」と指定したことになります。

4) C5.0ノード
今は空ですが、Typeノードの設定が引き継がれるのでこのままでいいです。今は「見るだけ」にします。(=「Cancel」)
7. モデルを作る
ではお待ちかね、モデルを作りましょう!「C5.0」ノードで右クリックして「Run」
SPSS Modelerでお馴染みのモデル(ゴールデン・ナゲット)ができましたね!
作られたモデルの内容を見てみます。ナゲットを右クリックして「View Model」
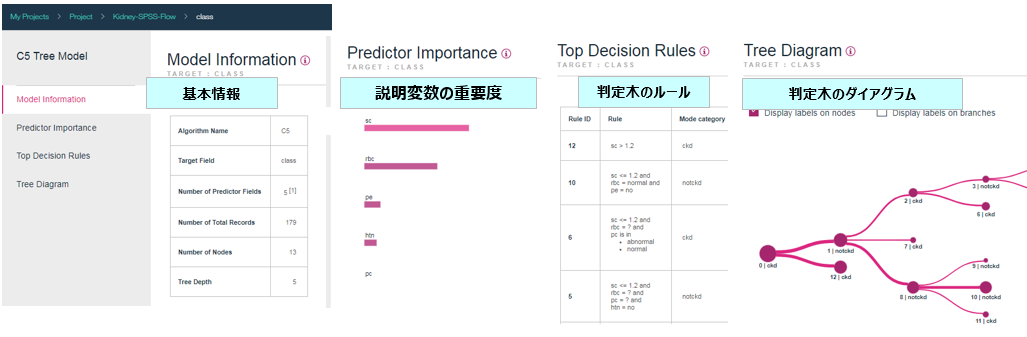
こんな感じでモデルの内容が見られます
モデルの評価もできます。パレットから「Analysis」ノードをドラッグ&ドロップしてナゲットと接続します。
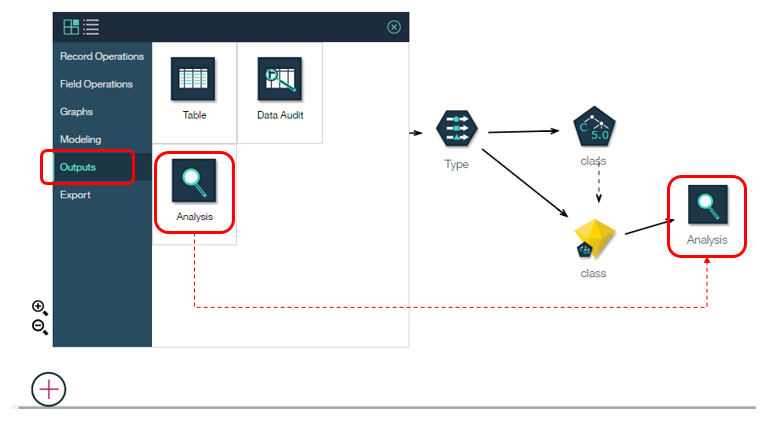
「Analysis」ノードをダブルクリックで開いて、分析したい内容4つにチェックして閉じます。
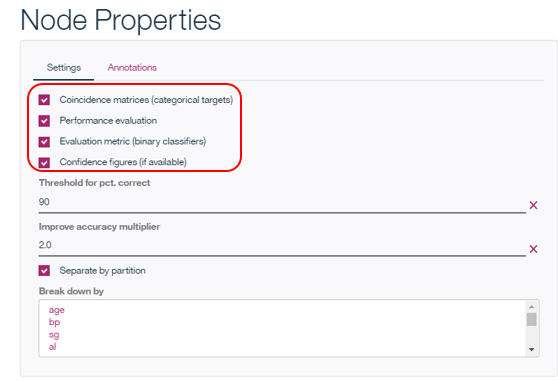
右クリックして「Run」
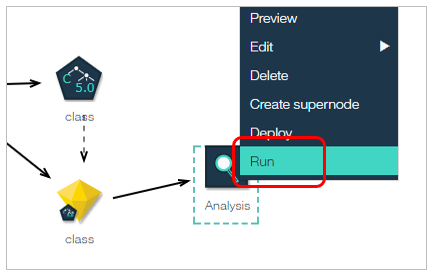
右側にOutputが表示されるのでダブルクリック
モデルの評価結果のレポートが表示されます
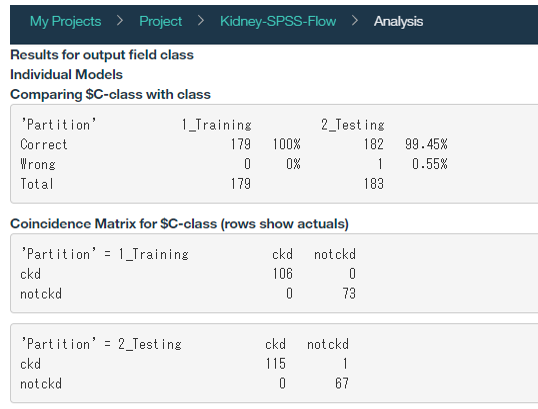
8.モデルをデプロイする
Sparkの場合とちがい、今のところSPSSの場合は実行環境への1クリックでのデプロイはできません。(先々の計画はあるそうですが)現時点では、*.strファイルをダウンロードしてご自身で改めてSPSS Scoring Serviceにデプロイしていただく必要があります。
「Analysisノード」の「Deploy」メニューを実行すると、SPSS Modelerのストリーム全体が*.strとしてPCにダウンロードできます。
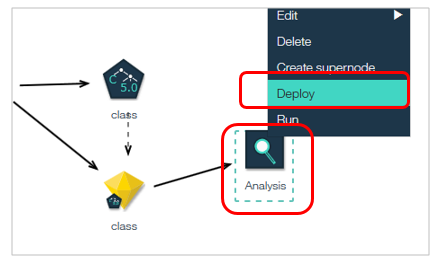
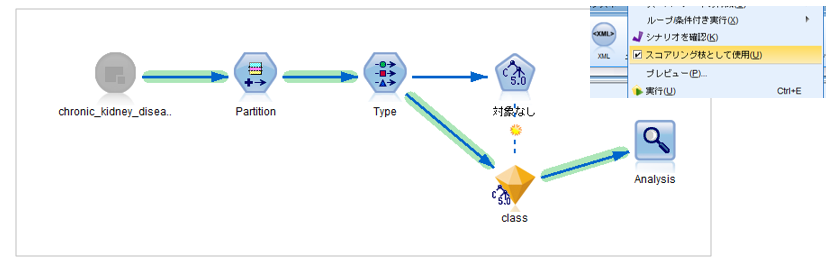
ダウンロードした*.strファイルはSPSS Modelerでそのまま開けます。スコアリング枝も緑の線で設定されています。(もしされていなければ、してください)
あとはこのストリームをWMLの「SPSS Streams Service」にアップロードします。
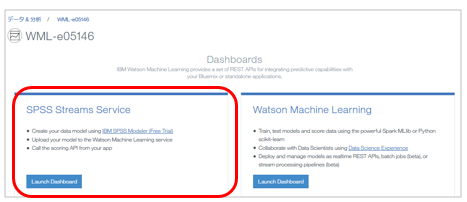
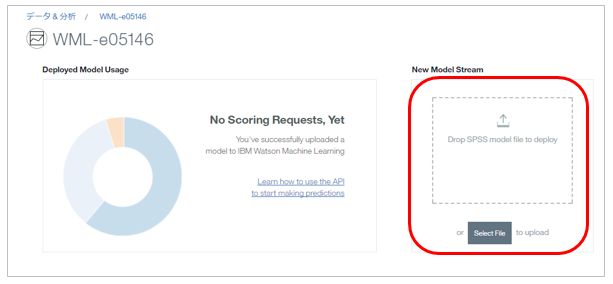
入力ノードが無効なためか、下記のエラーが出ますがモデルのデプロイはできています。
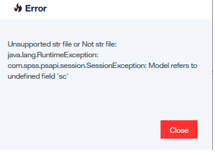
残念ながらSPSS側のサービスはUIで簡単にスコアリングを行う機能が無いようなので、RESTで確認する必要があり今は割愛します。ご興味のあるかたはBluemixのPredictive Analyticsを使ってみたをご参照ください。
SPSS Modeleと同じ操作感でモデルが作れるのがおわかりいただけたかと思います。
SPSS Modelerのストリームファイルの再利用や互換性
一からフローをつくらなくても、SPSS Modelerの既存のストリームを再利用することもできます。フローを作成するときに「From File」を選択して下のボタンから既存のSPSS Modelerのストリーム・ファイルを指定します。
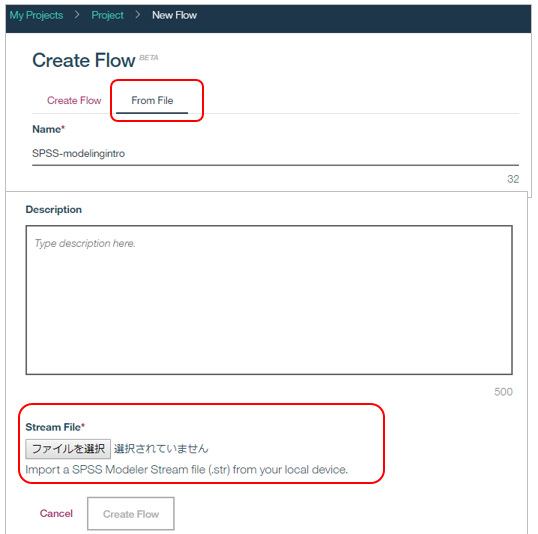
下記はSPSS Modelerの入門用のストリーム「modelingintro.str」を使った例ですが、ほぼ同じ形で取り込まれていますね。
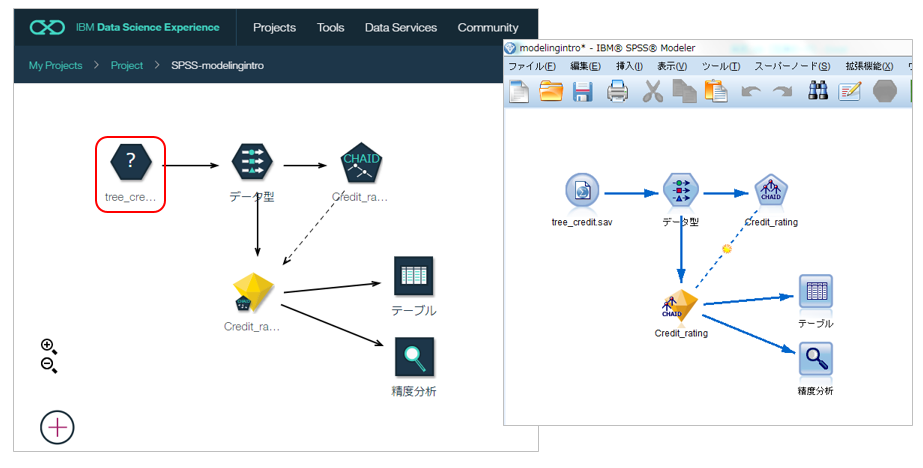
- 元々の入力ファイルはPC上であり、まだObject Storage上に存在しないので?になっています。ここはファイルをアップロードのうえ、修正する必要があります。
- SPSS Modeler側の多様なノードが全部WML側に用意されているわけではないので、残念ながら使えないノードも色々あります。
- 今はPC上のSPSS Modeler -> WML方向のアップロードの話ですが、WML->SPSS Modelerの逆方向も可能です。(「モデル」や「テーブル」ノードを右クリックして「Deploy」でstrファイルがダウンロードできます)
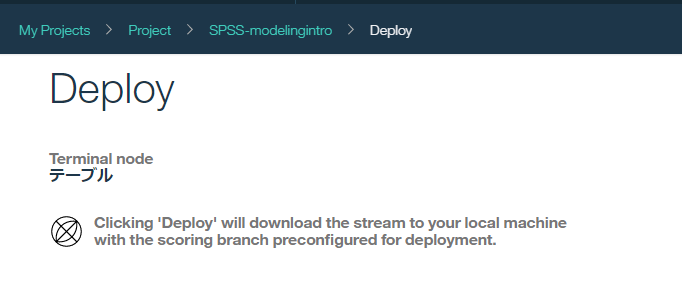
Sparkでもやってみる(と思ったが中断)
今まではSPSS側のフローでしたが、Spark側のフローも利用可能です。フローを作る際に「Scala Spark 2.0」を選択すればよく、操作性はほぼ同じなのですが、今やるとエラーになり記事が書けません。(ガックリ。。まあベータなんでご容赦ください)
こちらはまた動くようになったら更新します。すいません、
参考文献/URL
Data Science Experience - Flows -ドキュメントです。
以下のチュートリアルは同じ例を2つの環境で行ってます。
SPSS環境でのチュートリアル
Spark環境(Spark ML)でのチュートリアル
Build model by using IBM Watson Machine Learning in Data Science
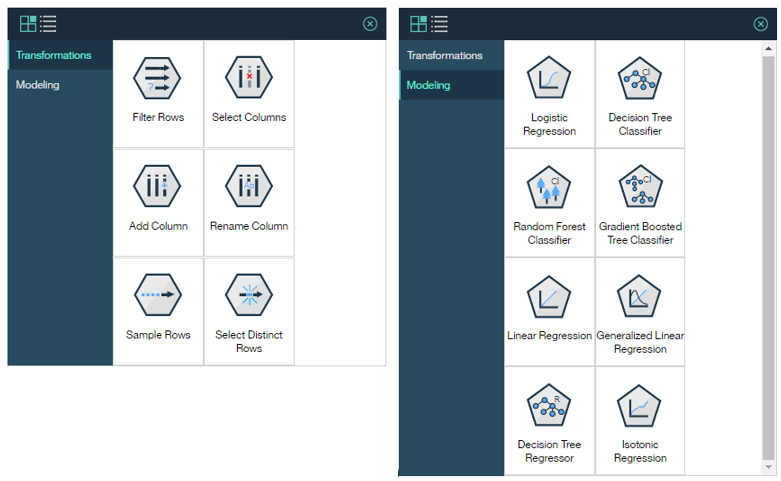
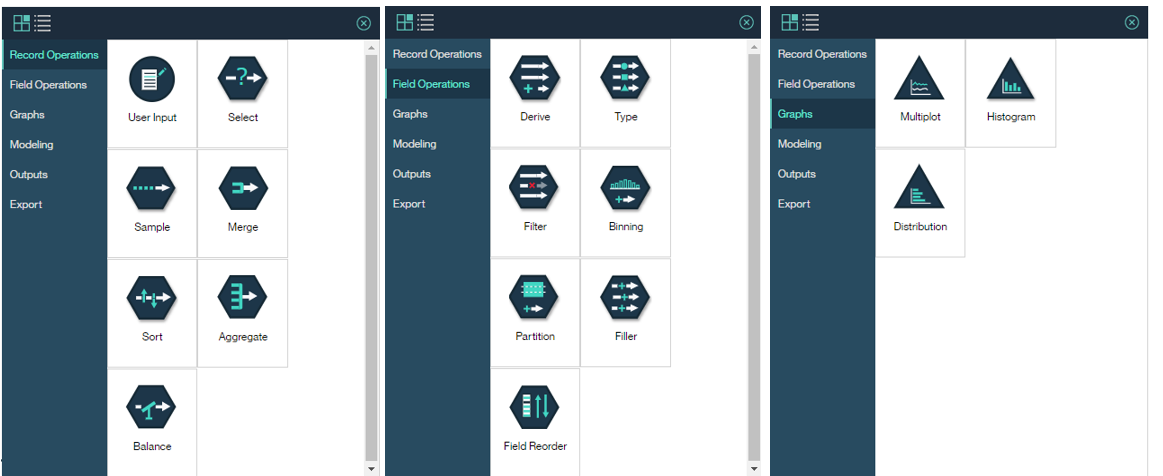
ご参考) SPSS Flowのパレット(記事執筆時点)
ここに各ノードの簡単な説明があります。
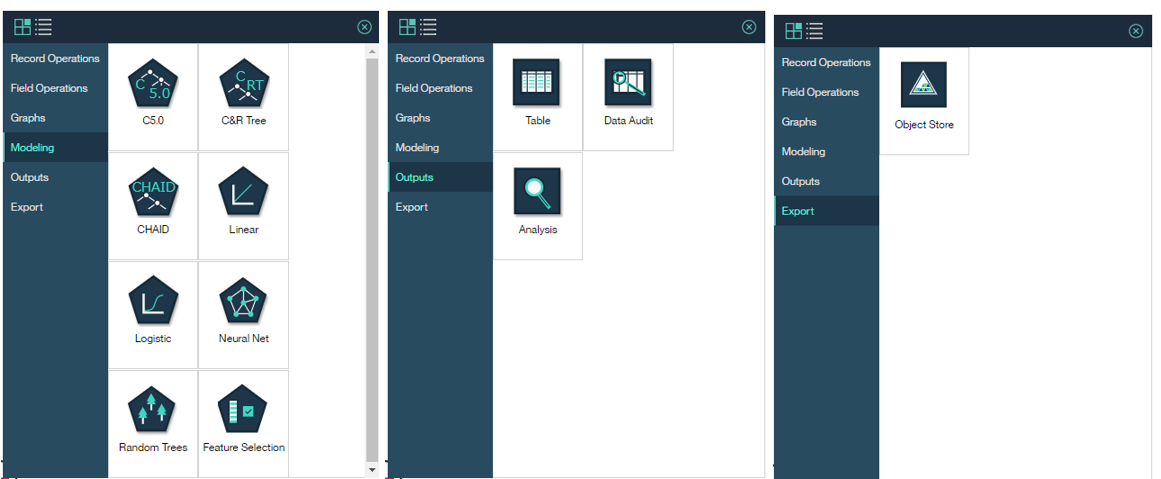
ご参考) Spark Flowのパレット(記事執筆時点)
ここに各ノードの簡単な説明があります。
SPSSに比してまだまだ少なく、「これから」って感じでしょうか。。。