![]() 当記事は2016/1月に投稿しましたが、現時点(【2019/2月】)では既に古くなっています。記事自体はアーカイブの目的でこのまま残しますが、当記事の内容を参考になさらないようにお願いいたします。代替の記事としては下記などがございます。
当記事は2016/1月に投稿しましたが、現時点(【2019/2月】)では既に古くなっています。記事自体はアーカイブの目的でこのまま残しますが、当記事の内容を参考になさらないようにお願いいたします。代替の記事としては下記などがございます。
Predictive Analyticsとは?
こんにちわ!石田と申します。( Qiita初投稿です )
 追記) 2016/10/25付でPredictive Analyticsの名前はWatson Machine Learningになりました。
追記) 2016/10/25付でPredictive Analyticsの名前はWatson Machine Learningになりました。
BluemixのPredictive Analyticsとは、昨今流行の「予測分析」をするものです。(この人がこの商品を買う確率はx%、みたいな将来の予測をするやつですね)予測分析は様々な統計解析手法を駆使して行いますが、大きな流れとしては ①実績データから予測モデルを構築する(モデリング) ②本番データに予測モデルを適用して予測結果を得る(スコアリング)の2つのフェーズにわけられます。IBMの予測分析ソフトウエアではSPSS Modelerが有名ですが、BluemixのPredictive AnalyticsとはSPSS Modelerの機能のうち「スコアリング」の機能のみを切り出して機能限定でBluemix上で手軽に実行できるようにしたサービス、と言えます。実際の利用の際の流れとしては①まずSPSS Modelerを使って予測モデルを作成する ②作成した予測モデル(*.str)をPredictive Analyticsにアップロードして、アプリからスコアリングを実行する、という2段階の流れになります。
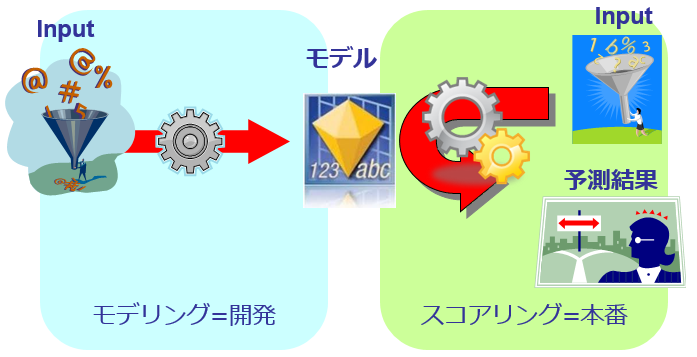
- 記事執筆時点(2016/1)ではリアルタイム・スコアリングのみに対応でした。
- その後DB入力やバッチスコアリング、モデルのトレーニング等にも対応したのでバッチ編を投稿しました。(2016/10) そちらもよろしければ、どうぞ。
早速やってみる
では実際にPredictive Analyticsを使ってみます。Github上にモデルやアプリケーションのサンプル一式がありますが、今回は話を簡単にするためにSPSS Modelerに標準添付の「はじめてのモデル」であるローン審査のモデル(modelingintro.str)を使ってやってみます。またBluemix上でのスコアリングは要はREST(or SOAP)で呼べばいいので、今回はアプリは利用せずPOSTMANで直接REST要求を出してみます。
大まかな流れ
以下がおおまかな流れになります。
1.SPSS Modeler(30日評価版)をダウンロードしてPCにインストールする
2.SPSS Modeler「モデル作成の概要」のチュートリアルに沿って簡単なモデルを構築する
3.構築したモデルに「スコアリング・ブランチ」を設定する
4.Bluemix上でお好みのランタイムとPredictive Analyticsをインスタンス化し、両者をバインドして環境情報(VCAP_SERVICE)を入手する
5.作成したモデルをBluemixのPredictive Analyticsにアップロードする
6.POSTMANでREST要求を出しスコアリングを行う
PCへのSPSS Modelerの導入
お手元にSPSS Modelerをお持ちの場合はそれを、お持ちでない場合はここから30日評価版をダウンロードしてPCにインストールします。インストールは特に難しいことは何もなく、「次へ」を押していけば終わります。
予測モデルの作成
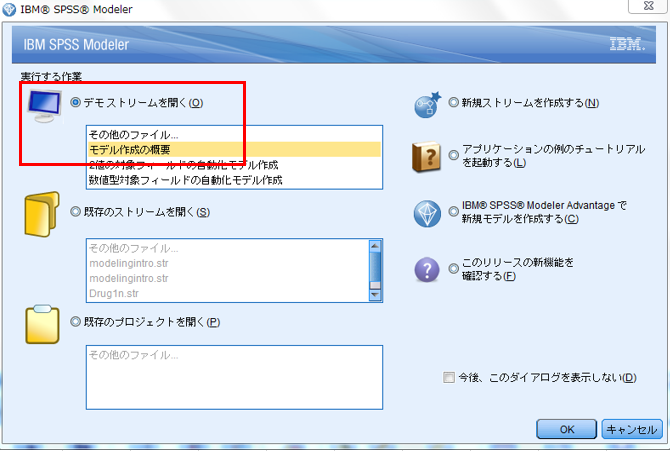
SPSS Modelerを起動し「デモストリームを開く」で「モデル作成の概要」を選択します。
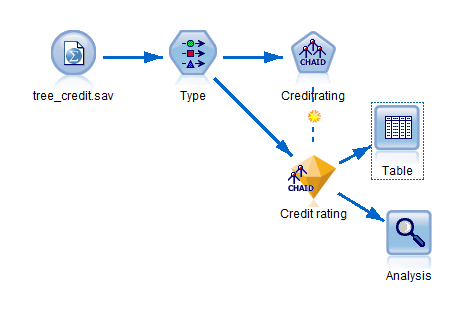
作りかけのモデル(modelingintro.str)が開きますので、SPSS文書のチュートリアル「モデル作成の概要」に沿って予測モデルを完成させます。(「モデルの評価」の章まで実施ください)業務的には金融機関の融資担当者が顧客の属性(年齢、収入レベル、クレジットカードの枚数など)を用いて融資可否を予測するシナリオです。
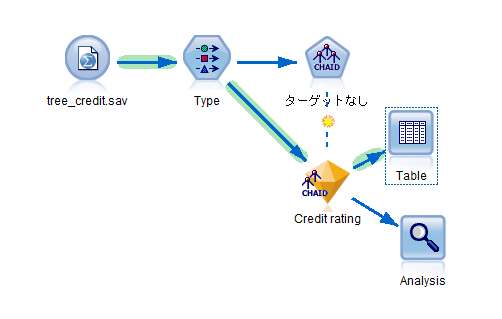
最終的には以下のような感じになります。
スコアリング・ブランチの設定
同シナリオは以下の5つの顧客属性データから「融資可否」(Credit rating)を予測するものでした。
- 年齢(Age)
- 収入レベル(Income level)
- クレジットカードの枚数( Number of credit cards )
- 学歴( Education )
- カー・ローン( Car loans )
予測モデルが完成したら以下の2点を変更して、任意の場所に任意の名前で「名前を付けてストリームを保存」します。(拡張子は*.str )
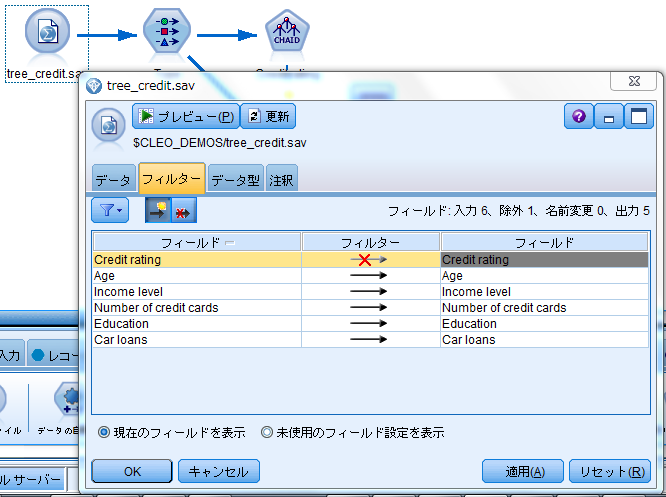
1.予測モデルを用いてスコアリングを行う際は「融資可否」(Credit rating)のフィールドは予測対象そのものであるので入力としては不要です。よってtree_credit.savの入力から「フィルター」を指定してCredit ratingのフィールドを除外します。(今回は話を簡単にするためにモデル作成時と同じファイルを使いますが、本来は別の本番データを入力にします)
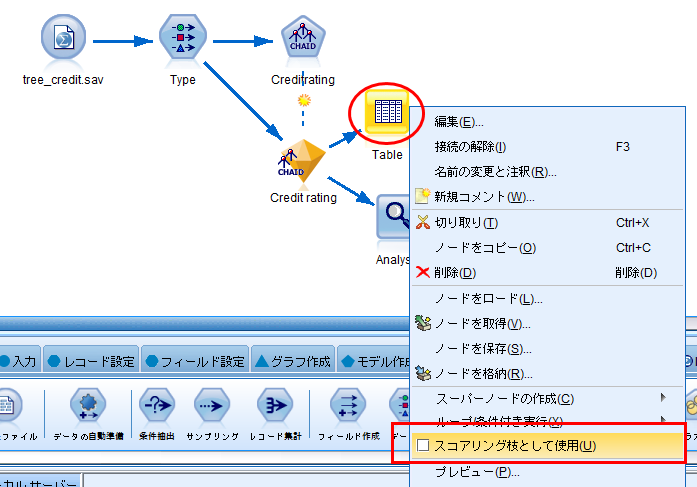
2.「Table」ノードを右クリックして「スコアリング枝として使用」を選択します。結果、スコアリングするフローの線が緑色になります。(この操作を忘れるとBluemixにモデルファイルをアップロードしてもスコアリング対象がない、とのエラーになりますのでご注意ください)
Bluemix上ランタイムでとPredictive Analyticsをインスタンス化する
Bluemix上でお好みの言語のランタイムとPredictive Analyticsのインスタンス( Free-Plan )を準備し、両者をバインドします。
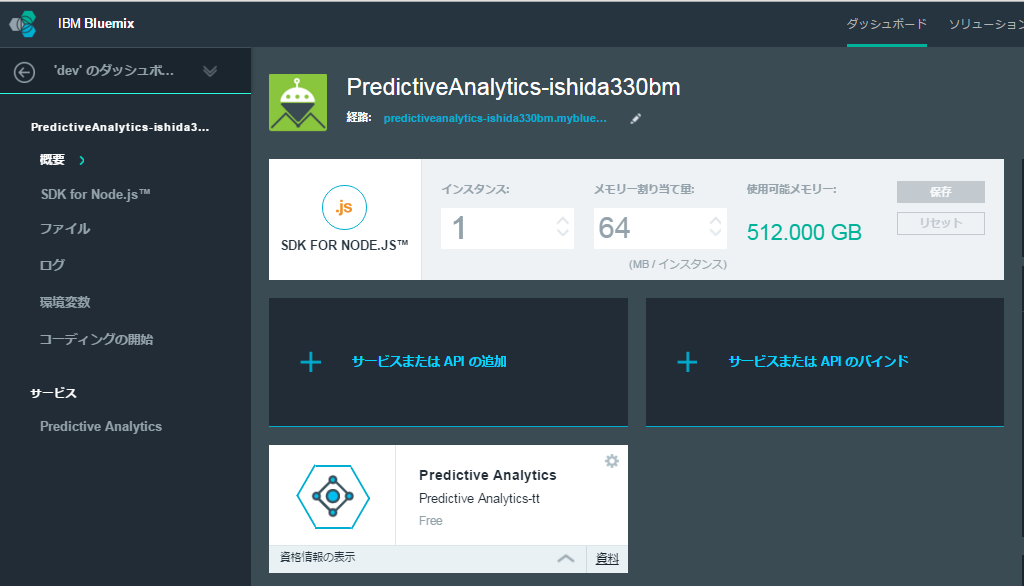
その後、Predictive Analyticsの「資格情報」のURLとアクセスキーをメモします。
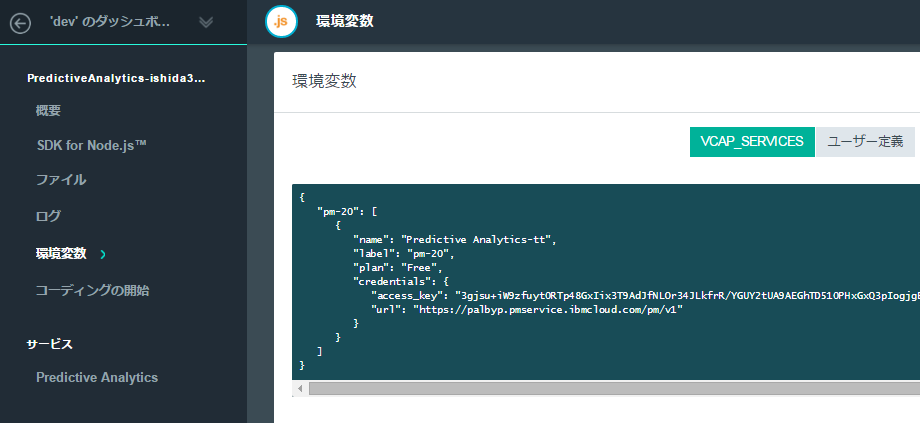
予測モデルのファイルをPredictive Analyticsにアップロードする
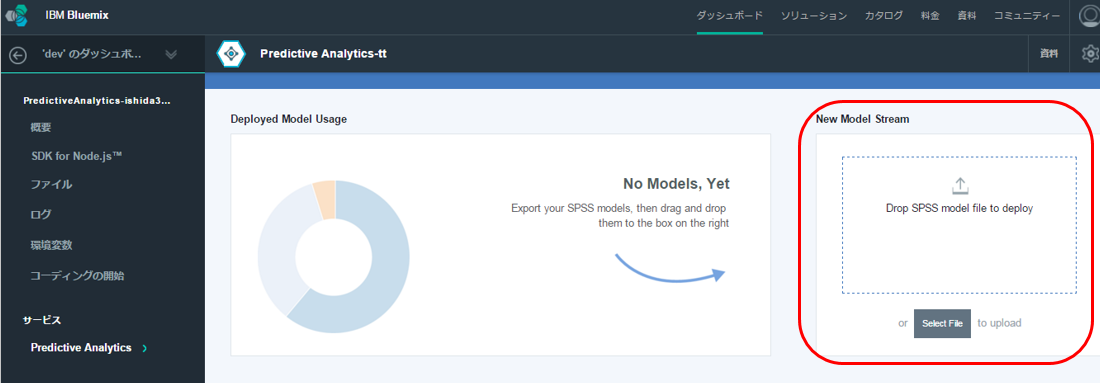
Predictive AnalyticsのUIを使ってSPSS Modelerで保存した予測モデルのファイル(*.str)をアップロードします。
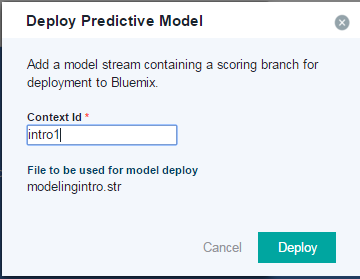
アップロードの過程でContextIDを聞かれますので任意の名前を入力します。(例ではintro1としました) このContextIDはスコアリング実行の際のURLで使います。( Case-Sensitiveですので大文字・小文字にご注意ください)
結果、うまくいけば以下のようにモデルが登録されます。
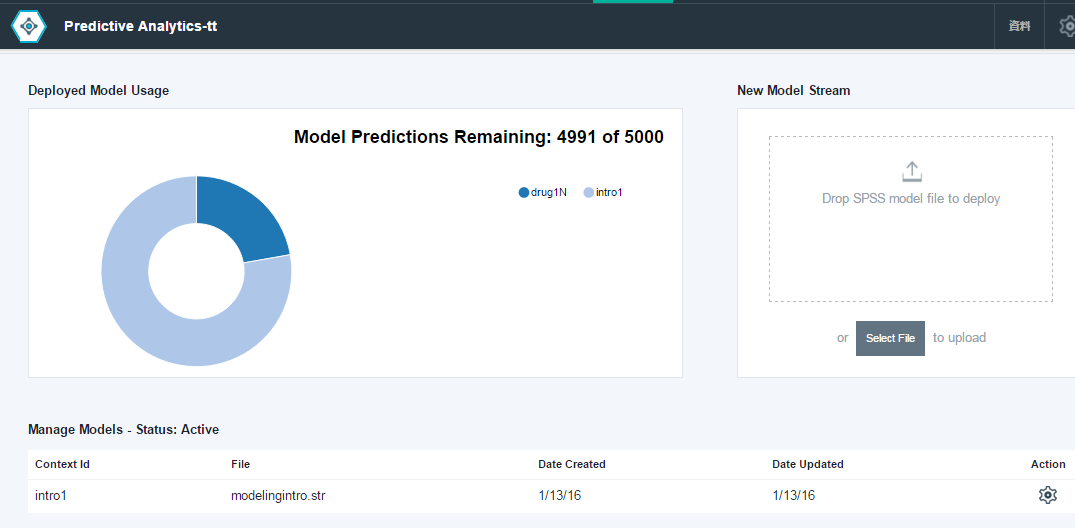
なおFree-Planでは5000スコアリング/月が上限ですが、今月何回実行したのか、がグラフで表示されています。(これを越えた場合は要求が拒否されるだけで自動的にPaid-Planで課金されるわけではなさそうなのでご安心ください。翌月になればクリアされますし。)
スコアリングしてみる
Predictive AnalyticsのこのドキュメントにAPIの使い方が書いてありますが、要は(RESTなら)以下のような感じです。
共通
- サービスへのアクセスURLはBluemixの環境情報(VCAP_SERVICE)から取得
- 認証はURLパラメータとしてセット ~URL~?accesskey=XXXXX(同じく環境変数から)
- HTTPヘダーに Content-Type: application/json;charset=UTF-8 をセット
スコアリング実行要求
以下の形式でRESTの要求を出します。
POST http://{service instance}/pm/v1/score/{contextId}?accesskey={access_key for this bound application}
スコアリングのための入力データはJSON形式で以下のようにHTTP Bodyにて与えます。
例)
{
"tablename":"スコアリング・ブランチの入力の名前",
"header":[入力フィールドの名前の配列],
"data":[[入力データの配列]]
}
基本的に1入力レコードに対して1つの予測結果を返しますが、data部分で複数のレコードを渡せば一度に複数のスコアリングを実行できます。
例) "data":[[入力データ1],[入力データ2],[入力データ3]]
一点念のための補足です。今回はSPSS Modeler上ではtree_credit.savというファイルを読んで予測モデルを構築しましたが、スコアリングの際にはこのファイルに含まれるレコード群は一切使用されません。REST要求時にJSONで記述する"tablename":".."は「モデルのどこを起点とするか」を指定するための単なるエントリー・ポイント/名前にすぎません。実際にスコアリングの入力データになるのは上記REST要求の "data":[[..]]で渡す内容です。
以下はPOSTMANの実行要求と結果です。
要求
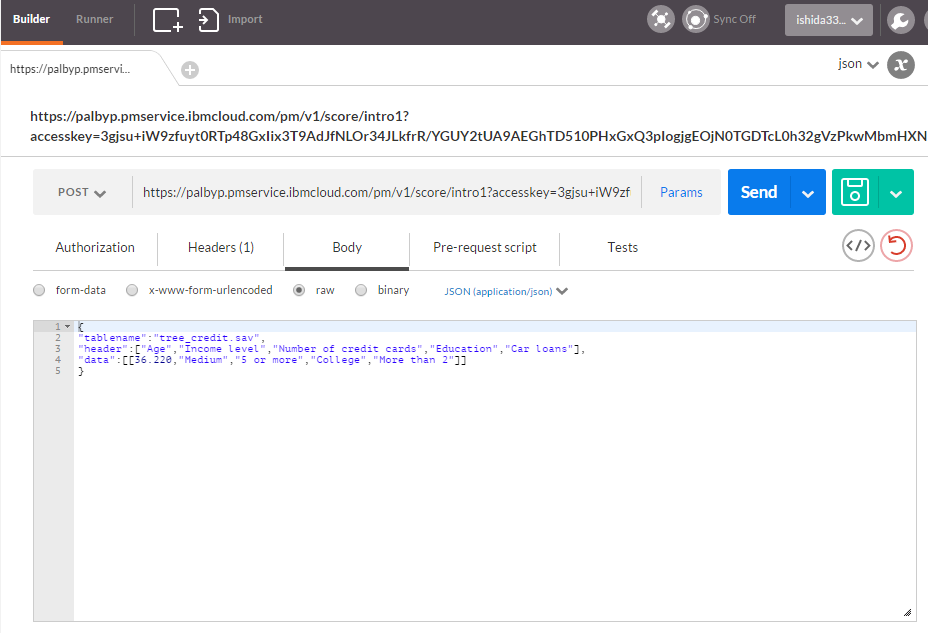
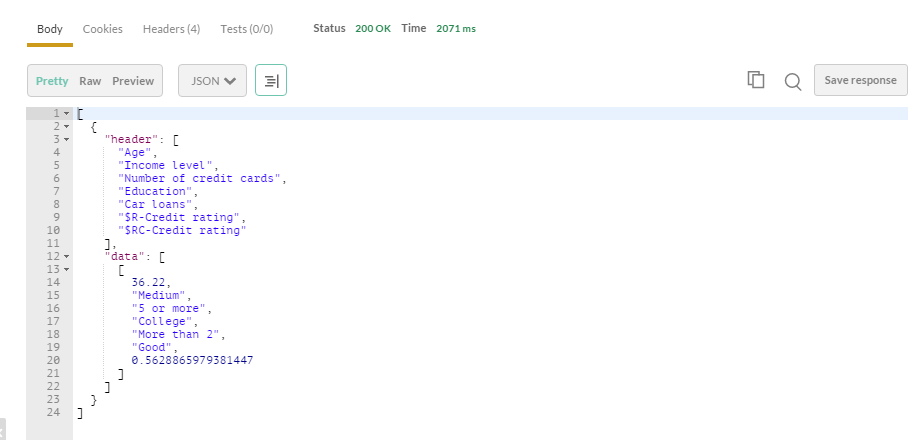
結果
入力データに加えて$R-Credit rating(予測結果)と$RC-Credit rating(確信度)がスコアリング結果として戻ってきました。
以下のように複数のレコードを一度に渡すこともできます。
要求
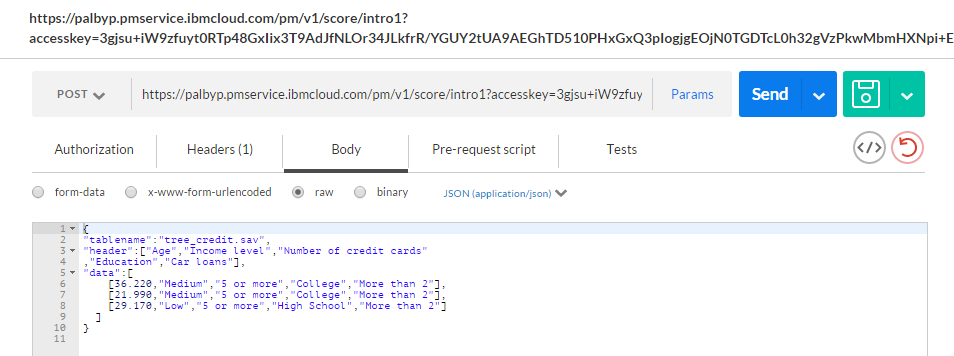
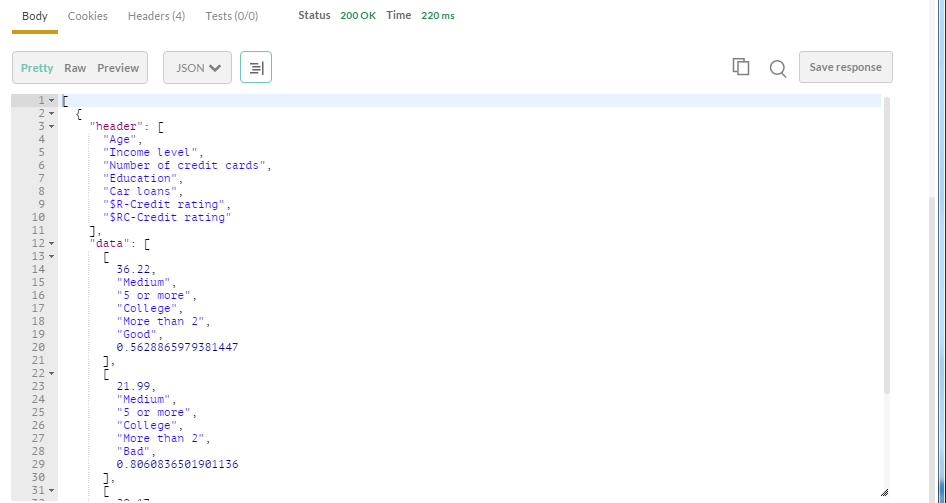
結果
入力レコードに応じたスコアリング結果が返ります。
モデルのメタ情報の取得
以下の形式でRESTの要求を出します。
GET http://{service instance}/pm/v1/metadata/{contextId}?accesskey={access_key for this bound application}&metadatatype=score
POSTMANで実行した結果は下記。スコアリングがエラーになった場合の確認・問題判別に便利です。
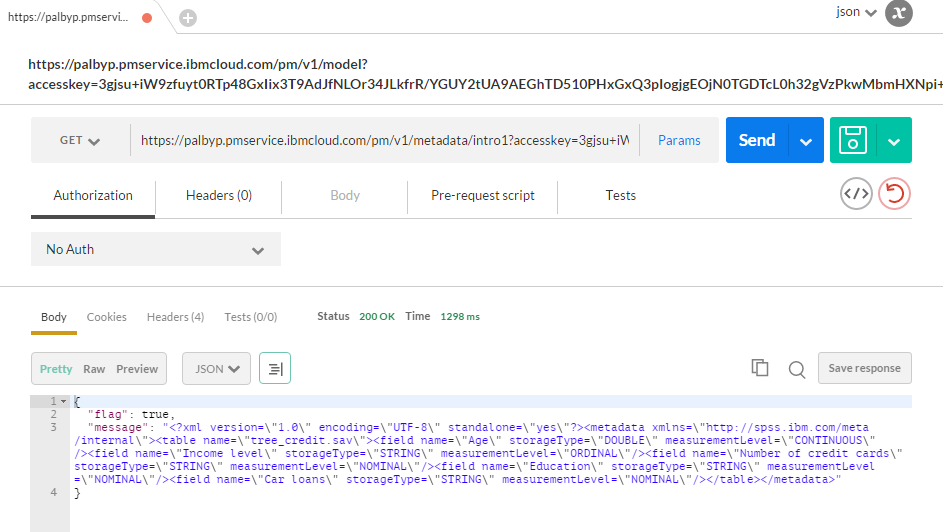
他にも予測モデル自体のCRUDのAPIもあるのでモデル管理を自動化することも可能です。
おわりに
以上がBluemixのPredictive Analyticsの概要です。SPSS Modeler自体が使いやすさに定評のあるツールですが、スコアリングもBluemixを使うと(CADSの環境構築などなしに)非常に簡単にできます。既にSPSS Modelerに慣れている方には特に簡単にお使いいただけるでしょう。開発者のBlogによると現在は「第一段階」でありこれから様々な機能追加が行われるそうなので、お楽しみに!