
TL;DR
- せっかくトレーニング済みの著名OSSディープラーニング・モデルがあっても、モデルだけじゃ専門家でないと再利用できないじゃん
- MAXなら1コマンドでDLモデルをRESTサービス化してくれるので、ややこしいことを知らない初心者でもモデルを楽に再利用できますよ~
- (2019/04) Node-REDからも使えるよ
って話です。
![]() (2019/04/17)
(2019/04/17) ![]() MAXが公開されて約1年たちましたが、Blog: 「Expanding the reach of the IBM Model Asset eXchange (2019/03/29)」に、この一年の振り返りと各種記事への(まとめ的な)リンクがあります。
MAXが公開されて約1年たちましたが、Blog: 「Expanding the reach of the IBM Model Asset eXchange (2019/03/29)」に、この一年の振り返りと各種記事への(まとめ的な)リンクがあります。

![]() (2019/04/08) MAX、久々に見たらモデルが+8で30個に増えていたので、記事をアップデートしました。
(2019/04/08) MAX、久々に見たらモデルが+8で30個に増えていたので、記事をアップデートしました。
はじめに
こんにちわ!石田です。今日はModel Asset Exchange(MAX)というIBMが始めたオープンソース・プロジェクト1の紹介をさせていただきます。
TensorFlowやKerasなどのディープラーニングのフレームワークを使ったことがある方はご存知かと思いますが、これらフレームワークでトレーニングをしたモデルはストレージ上に保管・復元ができ、可搬性があります。またフレームワーク自体に(例えばImageNetの画像データセットを使ったVGG16などの)著名で実績のある学習済みモデル(Pre-Trained Model)が含まれていて、それらのモデルを誰でも無償で予測に再利用できたり、または転移学習に使うことまで可能になっています。すごい時代になったものですね。。
とはいえ、では「誰でも簡単に学習済みモデルの利点を享受できるか?」と言うとやはり難しく、それなりに高度なフレームワークの知識が無いとせっかくのモデルも使いこなせません。そこでMAXの出番です。MAXは「オープンな学習済みのディープラーニング・モデルの成果を誰でも2簡単に活用できるようにしよう!」ということで立ち上げられたプロジェクトです。
Model Asset Exchangeって何? 1分でご説明します
- Model Asset Exchange(MAX)は2018/3月からIBMが始めたオープンソース・プロジェクトです
-
 2019/4月現在、「Model Asset Exchange」のサイトには以下のような感じで30個のトレーニング済みでライセンス面をクリアにしたディープラーニング・モデルがリソース一式と共に無償で公開されています(OSSなのでもちろん誰でも使えます)
2019/4月現在、「Model Asset Exchange」のサイトには以下のような感じで30個のトレーニング済みでライセンス面をクリアにしたディープラーニング・モデルがリソース一式と共に無償で公開されています(OSSなのでもちろん誰でも使えます)
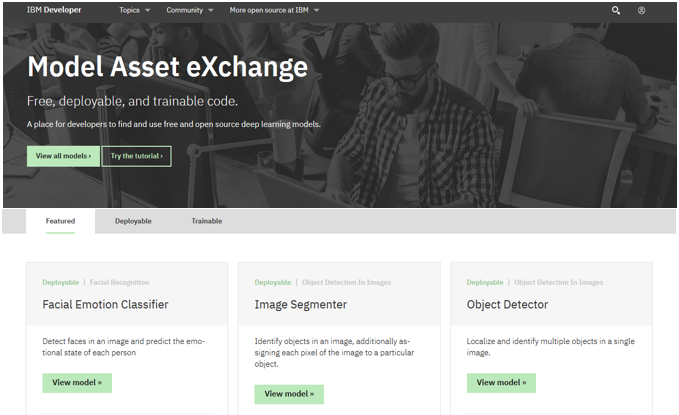
- 用意されているモデルの種類はディープラーニングに絡んだもので、画像、テキスト、音声などからお好きなものを選んで利用できます。(Watson APIには無い機能も多いです)
- 単にネット上に学習済みモデルがカタログ的に置いてあるだけではありません。モデルを簡単に使うためのWebサービス化/Docker化の仕組みと共にGithub上にリソース一式が公開されています
- 各種ディープラーニング・フレームワークの知識やPython/Flaskを用いたWeb公開の仕組みなどはすべて準備済みで隠蔽されていますので、開発は一切不要です
-
DockerHubにDockerイメージがあるので、いちいちローカルでBuildせずに(クラウドでもオンプレミスでも)お手持ちのDocker環境に簡単にデプロイして学習済みのモデルを利用できます
- ローカルのDocker環境でビルドしたければ、わずか3-4コマンドで簡単にモデルをDockerビルド/デプロイすることも、できます
- Docker上で稼動するので、オンプレ/クラウド問わずデプロイできます
![]() 1分終了です。
1分終了です。
どんなモデルがあるの? (2019/4時点で公開中のモデルのご紹介)
以下が![]() 2019/4月時点で公開中のモデル一覧です。ディープラーニングということでVision,Text, Audioなど様々な分野のものがあります。Text系は英語のみ
2019/4月時点で公開中のモデル一覧です。ディープラーニングということでVision,Text, Audioなど様々な分野のものがあります。Text系は英語のみ![]() なので日本のお客様ではそのままは使えないかもしれませんし、癌の検出のモデルって何に使うんかいな、という気もしますが、Vision系は「画像内の複数のオブジェクトを検出する」機能とか、「画風変換」「白黒・カラー変換」機能など、既存のWatson APIのVisual Recognitionに無い機能もありますので、日本のお客様でも使えるんじゃないかと思います。
なので日本のお客様ではそのままは使えないかもしれませんし、癌の検出のモデルって何に使うんかいな、という気もしますが、Vision系は「画像内の複数のオブジェクトを検出する」機能とか、「画風変換」「白黒・カラー変換」機能など、既存のWatson APIのVisual Recognitionに無い機能もありますので、日本のお客様でも使えるんじゃないかと思います。
| # | 名称 | 説明 | Domain | Framework | Application |
|---|---|---|---|---|---|
| 1 | Inception-ResNet-v2 | 第3世代のResNetを使用して画像内のオブジェクトを識別します | Vision | Keras | Image Classification |
| 2 | Scene Classifier | Places365データセットの場所/場所ラベルに従って画像を分類します | Vision | Pytorch | Image Classification |
| 3 | Image Caption Generator | 画像の内容を記述するキャプションを生成します | Vision | TensorFlow | Image Caption Generatorv |
| 4 | Review Text Generator | (レストラン評価サイトである)Yelpレビューデータセットのテキストに似た英語テキストを生成します | Text/NLP | Keras | Language Modeling |
| 5 | Sports Video Classifier | ビデオに含まれるスポーツの種類を分類します | Vision | TensorFlow | Video Classification |
| 6 | Adversarial Cryptography3 | 敵対的な暗号のニューラル・ネットワークにより通信を保護します | Text | ? | ? |
| 7 | Object Detector | 単一のイメージ内の複数のオブジェクトの位置を特定し、識別します | Vision | TensorFlow | Object Detection |
| 8 | ResNet-50 | 第1世代のResNetを使用して画像内のオブジェクトを識別します | Vision | Keras | Image Classification |
| 9 | Fast Neural Style Transfer | ソースイメージのコンテンツと別のイメージのスタイルを混在させた新しいイメージを生成します(画風変換) | Vision | Pytorch | Style Transfer |
| 10 | News Text Generator | One Billion Wordsデータセットのニュース記事に似た英語のテキストを生成します | Text | TensorFlow | Text generation |
| 11 | Spatial Transformer Network3 | イメージの変換や回転などの空間変換を大きなモデルに追加できるニューラルネットワークコンポーネントを学習します | Vision | ? | ? |
| 12 | Image Segmenter | イメージ内のオブジェクトを識別し、特定のオブジェクトにイメージの各ピクセルを割り当てます(≒塗り絵) | Image & Video | Tensorflow | Semantic image segmentation |
| 13 | Audio Classifier | 短いオーディオクリップ中のサウンドを特定します(≒「何の音?」) | Audio | Keras/TensorFlow | Classification |
| 14 | Word Embedding Generator3 | テキストファイルから埋め込みベクトルを生成します | Text | ? | ? |
| 15 | Breast Cancer Mitosis Detector | 有糸分裂腫瘍細胞の画像に有糸分裂が存在するかどうかを検出します | Vision | Keras | Cancer Classification |
| 16 | Image Colorizer | 白黒画像をカラー化します | Vision | TensorFlow | Image Coloring |
| 17 | Audio Embedding Generator | オーディオファイルから埋め込みベクトルを生成します | Audio | TensorFlow | Embeddings |
| 18 | Facial Age Estimator | 顔のイメージから年齢を推測します | Vision | Keras & TensorFlow | Facial Recognition |
| 19 | Facial Recognizer | イメージから顔を識別します | Vision | TensorFlow | Face Detection |
| 20 | Weather Forecaster | 過去のデータから天候を予想します | Weather | TensorFlow / Keras | Time Series Prediction |
| 21 | Name Generator 3 | Kaggle US Baby Namesをベースに名前を生成します | Text | TensorFlow | Text generation |
| 22 |
|
up, downなどの簡単な命令について、指示する音声のバリエーションを生成します | Audio | TensorFlow | Audio Modeling |
| 23 |
|
粒度の粗いイメージを補完して、粒度の高い(きれいな)イメージに変換します | Vision | TensorFlow | Super-Resolution |
| 24 |
|
短い文章からセンチメント(感情)を検出します | NLP | TensorFlow | Sentiment Analysis |
| 25 |
|
顕微鏡写真のイメージから核の写っている場所検出します | Vision | Keras | Object Detection |
| 26 |
|
英語の音声(5秒以下のWAV)をテキストに変換します | Audio | TensorFlow | Speech Recognition |
| 27 |
|
人物の顔写真から感情を推測します | Vision | ONNX | Facial Recognition |
| 28 |
|
イメージから顔を識別し、画像が欠けていれば補います | Vision | TensorFlow | Image Completion |
| 29 |
|
人物のイメージ群からポーズ(姿勢のライン)を検出します | Vision | TensorFlow | Human Pose Estimation |
| 30 |
|
テキスト中の単語と(人物・場所・組織などの)タグの一致を検出します | NLP | Keras | Named Entity Recognition |
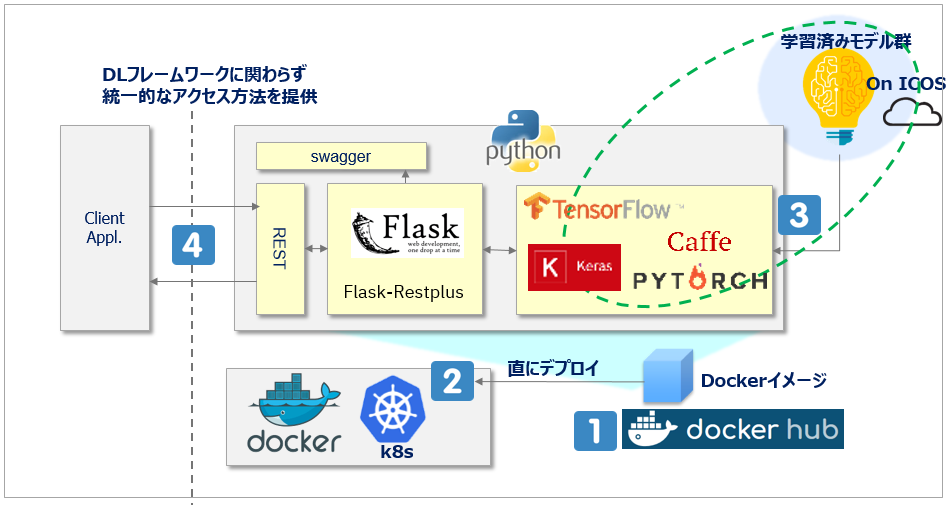
MAXの裏の仕組み(結局、何やってんの? )
以下が仕組み面のイメージ図です。MAXを使わない場合はフレームワーク毎の「学習済みモデル」(図の右上に相当)があるだけですが、MAXを使えばそのモデルを使ったRESTのエンドポイントを自動的に生成してくれるのでクライアントからのモデルの利用(Consume)がとても楽4になります。(Tensorflow, Kerasなどフレームワーク毎のお作法の違いを吸収して統一的なアクセス方法を提供できる利点も見逃せません)
![]() (2019/04/08) ご参考/背景談ですが、記事「Learn What Lies Beneath Our Ready-to-Run Deep Learning Models」にオープンソースのモデルをMAXに乗せるためのプロセスの解説がありました。論文の調査から始めて、IPやライセンスのクリアなど、地道に色々やってるんですね。
(2019/04/08) ご参考/背景談ですが、記事「Learn What Lies Beneath Our Ready-to-Run Deep Learning Models」にオープンソースのモデルをMAXに乗せるためのプロセスの解説がありました。論文の調査から始めて、IPやライセンスのクリアなど、地道に色々やってるんですね。
Docker Hubを使う場合(1コマンドで完了=楽!)
![]() すでにDocket Hub上にイメージ一式が置いてあります。
すでにDocket Hub上にイメージ一式が置いてあります。
![]() 動かしたい環境に対してデプロイします( docker run or kubectl apply -f )
動かしたい環境に対してデプロイします( docker run or kubectl apply -f )
![]() デプロイの過程で、自動的にクラウド上に公開されている学習済みモデルをwgetして起動時にロードしてくれます。さらにFlaskを使ってRESTのエンドポイントも準備してくれます。(要は「終わるのを待ってればいい」だけです。)
デプロイの過程で、自動的にクラウド上に公開されている学習済みモデルをwgetして起動時にロードしてくれます。さらにFlaskを使ってRESTのエンドポイントも準備してくれます。(要は「終わるのを待ってればいい」だけです。)
![]() 起動したらあとはRESTのエンドポイントを叩いて使うだけ、です。
起動したらあとはRESTのエンドポイントを叩いて使うだけ、です。
自分でDockerイメージをローカル・ビルドしたい場合
イメージをカスタマイズしたい、などの場合はこちらの方法を。
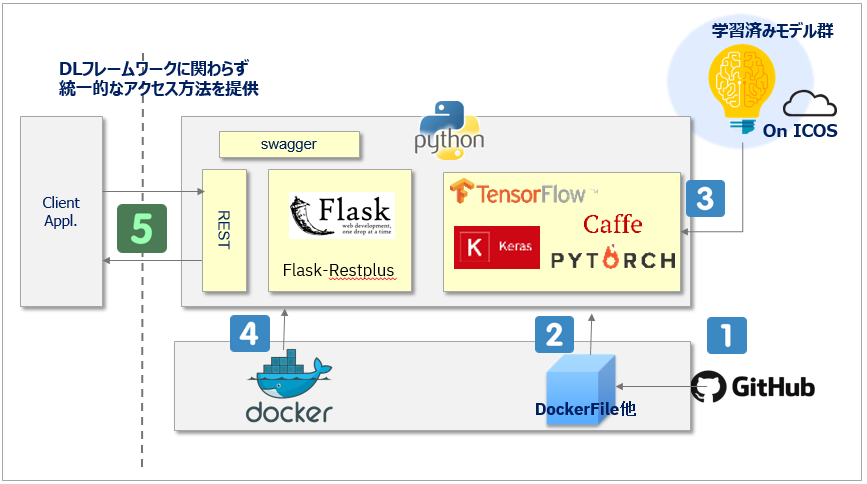
![]() まずは使いたいモデルのGithubリポジトリをクローンします( git clone )
まずは使いたいモデルのGithubリポジトリをクローンします( git clone )
![]() Dockerファイルをビルドします( docker build )
Dockerファイルをビルドします( docker build )
![]() ビルドの過程で、自動的にクラウド上に公開されている学習済みモデルをwgetして起動時にロードしてくれます。さらにFlaskを使ってRESTのエンドポイントも準備してくれます。(要は「終わるのを待ってればいい」だけです。)
ビルドの過程で、自動的にクラウド上に公開されている学習済みモデルをwgetして起動時にロードしてくれます。さらにFlaskを使ってRESTのエンドポイントも準備してくれます。(要は「終わるのを待ってればいい」だけです。)
![]() イメージのビルドが終わったら起動します( docker run )
イメージのビルドが終わったら起動します( docker run )
![]() あとはRESTのエンドポイントを叩いて使うだけ、です。
あとはRESTのエンドポイントを叩いて使うだけ、です。
具体的な使い方
![]() (2019/04/08) MAX使い方入門のチュートリアル「Get started with the Model Asset Exchange」が出てました。
(2019/04/08) MAX使い方入門のチュートリアル「Get started with the Model Asset Exchange」が出てました。
使いたいモデルの「Get the model」ボタンを押すと対応するGithubのページに飛ぶので、そこに書いてあるビルド/デプロイ手順を実行するだけ、です。以下の3通りの方法が書かれています。
① Docker Hub上のイメージを使ってDockerへデプロイ
② Docker Hub上のイメージを使ってKubernetesへデプロイ
③ 自分でイメージをローカルビルドしてデプロイ
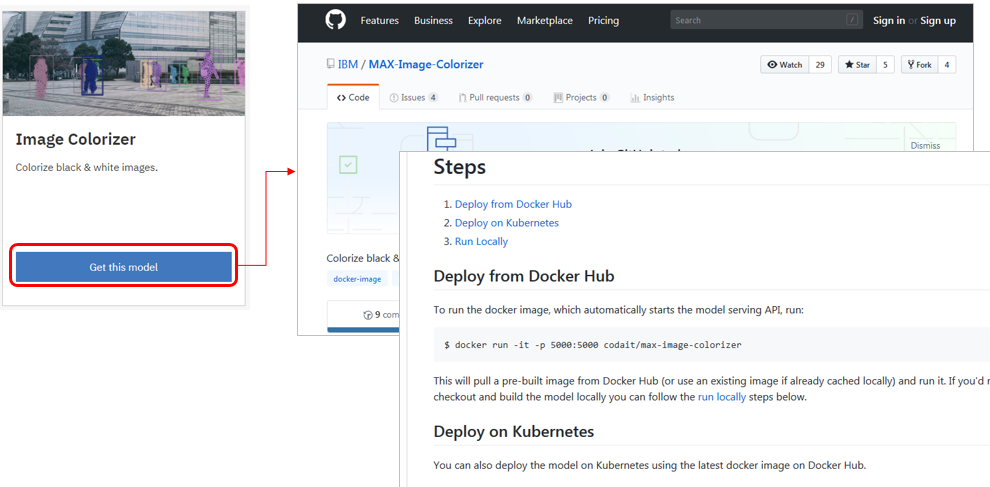
Image Colorizer(白黒写真をカラー化)を使ってみた
ということで、わかりやすい例としてImage Colorizerを使って白黒写真をカラーに着色してみます。結果、ローカルビルドでも数分でモデルをRESTを介して使えました。めちゃ簡単すぎるやん!
0. 前提環境
Dockerが動くこと。私はUbuntu 16.4上のDocker 17.12を使いました。
1.githubのクローン
git clone https://github.com/IBM/MAX-Image-Colorizer.git
root@ubuntu:~# git clone https://github.com/IBM/MAX-Image-Colorizer.git
Cloning into 'MAX-Image-Colorizer'...
remote: Counting objects: 35, done.
remote: Compressing objects: 100% (28/28), done.
remote: Total 35 (delta 8), reused 26 (delta 5), pack-reused 0
Unpacking objects: 100% (35/35), done.
Checking connectivity... done.
root@ubuntu:~# cd MAX-Image-Colorizer
root@ubuntu:~/MAX-Image-Colorizer# ls
api app.py assets config.py core Dockerfile docs LICENSE README.md
2.Dockerイメージのビルド
docker build -t max-image-colorizer .
root@ubuntu:~/MAX-Image-Colorizer# docker build -t max-image-colorizer .
Sending build context to Docker daemon 1.561MB
Step 1/12 : FROM continuumio/miniconda3
latest: Pulling from continuumio/miniconda3
cc1a78bfd46b: Pull complete
c9741e205978: Pull complete
(途中省略..)
Successfully built 4721133808e2
Successfully tagged max-image-colorizer:latest
3.Dockerの起動
docker run -it -p 5000:5000 max-image-colorizer
root@ubuntu:~/MAX-Image-Colorizer# docker run -it -p 5000:5000 max-image-colorizer
2018-07-23 08:36:30.212096: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
4.使ってみる
ブラウザーでホスト名:5000番ポートにアクセスするとUIが開きます。
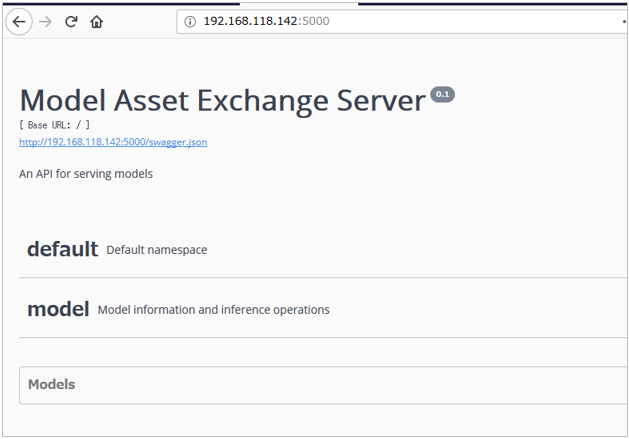
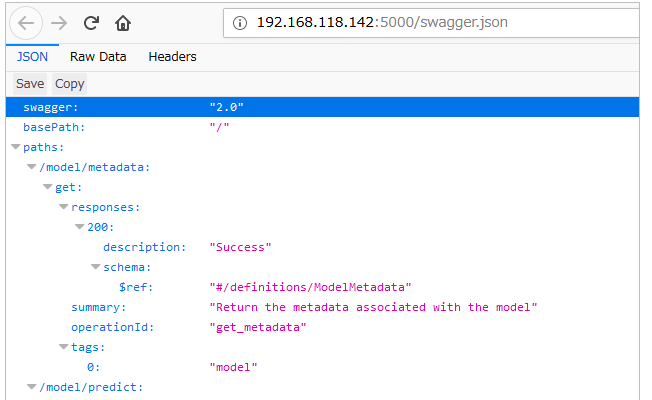
こんな感じでswaggerも見られます
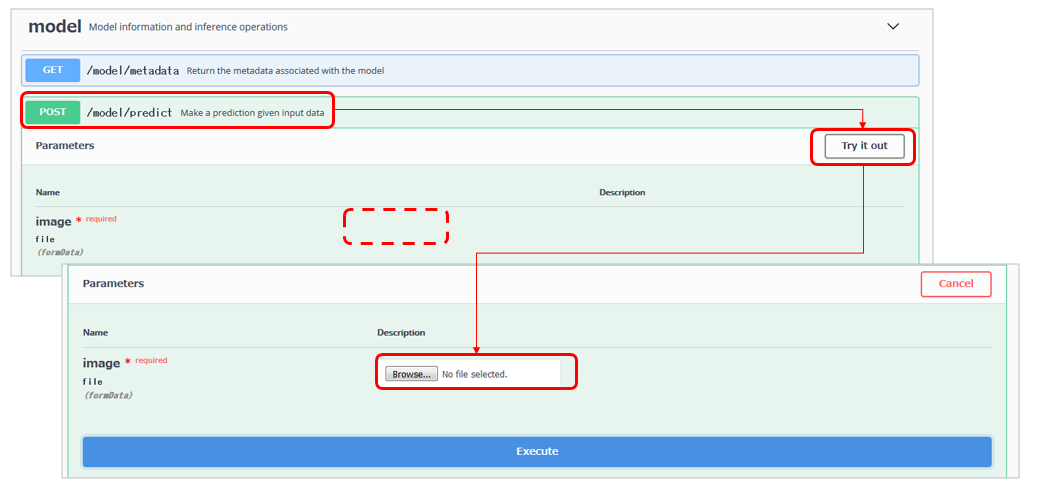
modelのPOSTで**/predict**を選択し「Try it out」ボタンを押すとイメージ選択ボタンが表示されます。
ボタンで任意の白黒の画像ファイルを選択して「Execute」
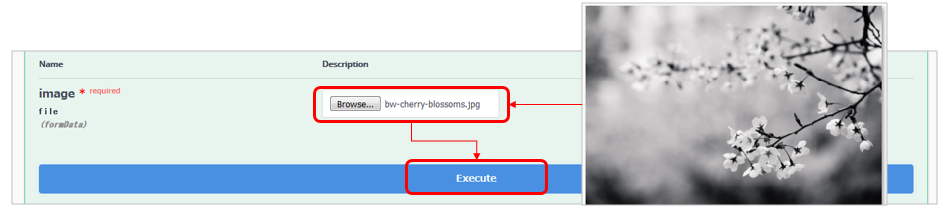
すると以下のようにカラー彩色されたPNGファイルが戻ります。
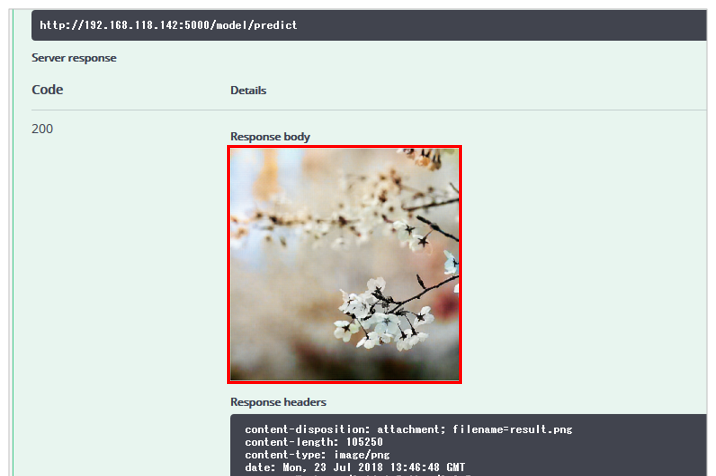
いくつかやってみましたが、こんな感じでした。めっちゃ簡単やん!

Docker Hubのイメージを使うと、もっと簡単!
2018/9月の拡張でDocker Hubにイメージが登録されたので、コマンド一発でデプロイできるようになりました。実際、まっさらなDocker環境で docker run -it -p 5000:5000 codait/max-image-colorizerを一発打って数分放置してたら最後まで動きました。簡単すぎて、まじ、達成感無いっす(←褒めてます)。
root@ubuntu:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest f2a91732366c 10 months ago 1.85kB
root@ubuntu:~# docker run -it -p 5000:5000 codait/max-image-colorizer
Unable to find image 'codait/max-image-colorizer:latest' locally
latest: Pulling from codait/max-image-colorizer
cc1a78bfd46b: Pull complete
<<途中割愛>>
46ce75ca6fb7: Pull complete
Digest: sha256:adf6dcf9c10e80faa0f81f9fe4f7e3af5153dade9a49c644554894ff101b7a5a
Status: Downloaded newer image for codait/max-image-colorizer:latest
2018-09-28 02:47:35.265659: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
画面等は前述と同じなので割愛します。
クライアント側のアプリのサンプルもあります
前述の通り、事前に準備されたディープラーニングのモデルを「お試し」で使ってみるだけなら、生成されたSwaggerのUIを使って簡単に確認できます。業務で使う場合のクライアント側のアプリケーションのサンプルも以下の2つが公開されています。(っても難しい/プロプラエタリな知識は不要です。オープンなので、要はUIがあってRESTでリクエスト出してレスポンスを何らかの方法で描画できればいいんです)
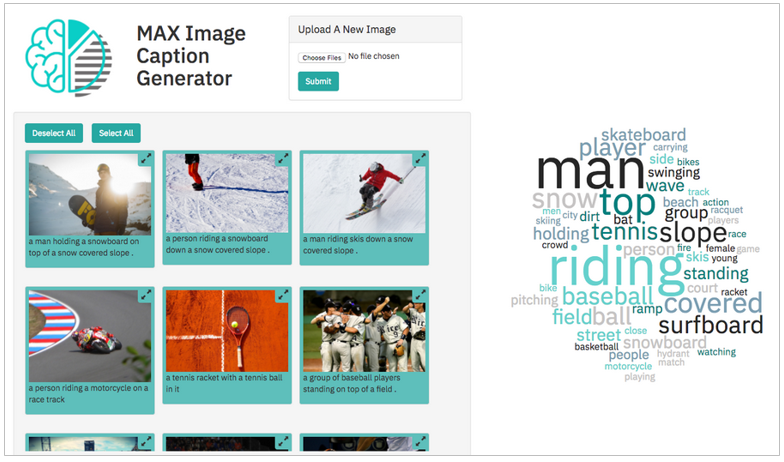
![]() Use an open source image caption generator deep learning model to filter images based on their content in a web application - Imageのキャプションを生成するImage-Caption-Generatorを呼び出すクライアント・アプリケーションのサンプル。(
Use an open source image caption generator deep learning model to filter images based on their content in a web application - Imageのキャプションを生成するImage-Caption-Generatorを呼び出すクライアント・アプリケーションのサンプル。(![]() コード付き)
コード付き)
![]() サンプルアプリはImage-Caption-Generatorとは別にデプロイする必要があります
サンプルアプリはImage-Caption-Generatorとは別にデプロイする必要があります
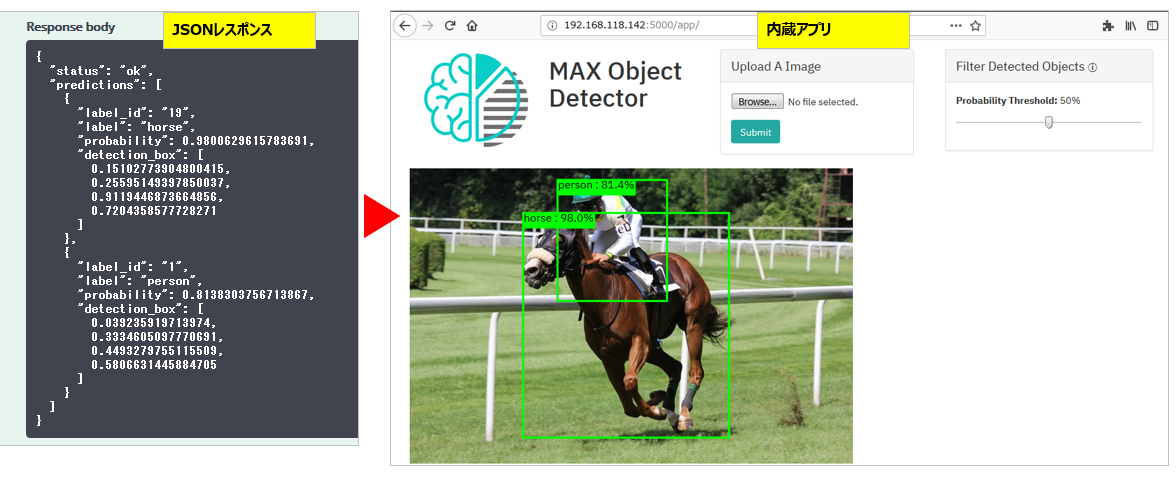
![]() Object-Detector - こちらは一枚のイメージの中に写っている複数のオブジェクトを識別するもの。RESTで呼び出すだけだと、生のJSONが返るだけ(左側)でぜんぜん面白くありません。そこでサンプルアプリで場所(枠)を描画しています(右側)
Object-Detector - こちらは一枚のイメージの中に写っている複数のオブジェクトを識別するもの。RESTで呼び出すだけだと、生のJSONが返るだけ(左側)でぜんぜん面白くありません。そこでサンプルアプリで場所(枠)を描画しています(右側)![]() 当サンプルアプリはObject-Detector本体に含まれていますので、
当サンプルアプリはObject-Detector本体に含まれていますので、http://your-host:5000/app からアクセスできます。上のサンプルと違って、別途アプリをデプロイする必要はありません、
Kubernetes環境(CaaS) へのデプロイ (2018-08-13 追記)
![]() 記事「Deploying Deep-Learning Models to Kubernetes on IBM Cloud」でMAXのモデルをKubernetes Service on IBM Cloudにデプロイする方法も公開されています。要はKubeにデプロイするためのyamlファイルもGithub上に準備してあるから、あとは
記事「Deploying Deep-Learning Models to Kubernetes on IBM Cloud」でMAXのモデルをKubernetes Service on IBM Cloudにデプロイする方法も公開されています。要はKubeにデプロイするためのyamlファイルもGithub上に準備してあるから、あとはkubectl apply -f ./max-object-detector.yamlてな感じでデプロイするだけ、です。標準的なものなので、中身を書き換えれば他社のCaaSにもデプロイできるはず。
(2019/04追記) Node-REDからも使えます
現時点では全部ではなくて10個くらいですが、MAXのモデルをNODE-REDから使えるようなモジュールが提供されています。使えるものは以下のように「Try in Node-RED Flow」のボタンがあります。
こんな感じでMAX上のモデルをプログラミングなしで簡単に使えます

個々の使い方はドキュメントに記載がありますが、Node-REDに未対応のパーツをカスタムで対応させる方法も公開されています
Creating Custom Node-RED Nodes for your API: The Easy Way
How to add a new node to node red contrib model asset exchange
最後に
Github上で提供されているDockerFileやPythonのソースを見るとわかりますが、「中でやってること」は難しいことやアクロバティックなことは特にしてません。フツーのことをフツーにやってる印象なので、同じようなことは自作でもがんばればできそうです。もしMAXに登録されていないモデルをお持ちであれば、同様の処理方式で包んでサービス化することも比較的容易ではないかと思います。(要はデザイン面の参考/雛形としての用途) いずれにせよ、MAXのエントリは今後も拡充していくそうなので、お楽しみに!
またCODAITチームは他にも様々な啓蒙活動をしています。ご興味のある方は下記などご参照くださいませ。
![]() CODAITチームのページ(Center for Open-Source Data & AI Technologies)
CODAITチームのページ(Center for Open-Source Data & AI Technologies)
![]() SlideShare - Open Source AI - News and examples - CODAITチームの活動の全容紹介プレゼンチャート
SlideShare - Open Source AI - News and examples - CODAITチームの活動の全容紹介プレゼンチャート
参考文献
IBM Code
IBM Code - Model Asset Exchange
 ブログとチュートリアル
ブログとチュートリアル
![]() 2019/3/28 Expanding the reach of the IBM Model Asset eXchange - MAXに新しく追加されたモデルの紹介や使い方など
2019/3/28 Expanding the reach of the IBM Model Asset eXchange - MAXに新しく追加されたモデルの紹介や使い方など
![]() 2019/3/28 Create a web app to interact with machine learning generated image captions - イメージ認識のチュートリアル
2019/3/28 Create a web app to interact with machine learning generated image captions - イメージ認識のチュートリアル
![]() 2019/6/18 An introduction to the internals of the Model Asset eXchange - MAXが中でやってること、仕組みの解説
2019/6/18 An introduction to the internals of the Model Asset eXchange - MAXが中でやってること、仕組みの解説
![]() 2019/07/16 IBM announces Data Asset eXchange (DAX) to help developers use free and open data and AI - モデルのみならず、オープン・データの流通のためにDAXを開始
2019/07/16 IBM announces Data Asset eXchange (DAX) to help developers use free and open data and AI - モデルのみならず、オープン・データの流通のためにDAXを開始
![]() 2019/8/16 Deploy deep learning models on Red Hat OpenShift - MAXのモデルをOpenShiftにデプロイする方法のチュートリアル
2019/8/16 Deploy deep learning models on Red Hat OpenShift - MAXのモデルをOpenShiftにデプロイする方法のチュートリアル
![]() 2020/1/13 Announcing new data sets on the IBM Data Asset eXchange - DAXへのデータ追加
2020/1/13 Announcing new data sets on the IBM Data Asset eXchange - DAXへのデータ追加
![]() 2020/1/13 Running MAX deep learning models on Raspberry Pi - MAXのモデルをラズパイで動かす方法
2020/1/13 Running MAX deep learning models on Raspberry Pi - MAXのモデルをラズパイで動かす方法
![]() 2018/06/29 Deploying Models from IBM’s Model Exchange to Kubernetes - おなじみNickさんのブログ。MAXのイメージをKubernetesにデプロイする方法
2018/06/29 Deploying Models from IBM’s Model Exchange to Kubernetes - おなじみNickさんのブログ。MAXのイメージをKubernetesにデプロイする方法
![]() 2018/08/01 Reusing Open Source Models in AI Applications - Nickさんのブログ。MAX以外にも有名なモデル・エクスチェンジをいくつか紹介してます
2018/08/01 Reusing Open Source Models in AI Applications - Nickさんのブログ。MAX以外にも有名なモデル・エクスチェンジをいくつか紹介してます
改定履歴
| V | 日付 | 内容 |
|---|---|---|
| 1 | 2018/7/24 | 初版 |
| 2 | 2018/09/28 | maxモデル追加(全22個)&Docker対応を反映 |
| 3 | 2019/04/08 | maxモデル追加(全30個)&NodeRED対応を反映 |
| 4 | 2019/04/17 | 一年振り返りブログ記事を紹介 |
| 5 | 2020/05/06 | MAXや記事のURLが変わっていたので修正 |
![]() この記事によると2018/9/21付でMAXが強化されたそうなので、記述をアップデートしました。(変更点は
この記事によると2018/9/21付でMAXが強化されたそうなので、記述をアップデートしました。(変更点は![]() を付けておきます)
を付けておきます)
- 新しいモデルが5つ追加された
- Docker Hubにイメージが登録された(=ローカルBuildが不要で一発デプロイ)
- Dockerに加えKubernetes環境にもデプロイできるようになった
-
ご参考までに当プロジェクトはIBMのCODAITという専門チームがリードしています。このチームは以前「Spark_Technlogy_Center」という名前でApach_Sparkの啓蒙活動やSystemMLの開発などやっていたのですが、「これからはAIだ!」ってことで2018/3月に同チームが発展的に解消してできたのがCODAITチームです。 ↩
-
「誰でも」は、言葉のあやで、正確には「IT系のスキルをお持ちのデベロッパーなら誰でも」ですね。さすがにITのことを一切知らない方には無理っす。。 ↩
-
「モデルの利用を楽に」という意味では、様々なディープラーニング・フレームワーク間のモデルの互換性・可搬性を確保するための共通フォーマットONNXが思い浮かびますが、あれは絵で言えば右上のDLフレームワーク群と学習済みモデルのあたり(
 周辺)の形式を共通化するお話です。MAXはさらに広くモデルのサービス化やConsumeの部分も対象領域にしています。(要は課題感は似てますが、カバーする領域が違います) ↩
周辺)の形式を共通化するお話です。MAXはさらに広くモデルのサービス化やConsumeの部分も対象領域にしています。(要は課題感は似てますが、カバーする領域が違います) ↩