はじめに
LangChain 1.0がリリースされました。
詳細は以下の公式Blogを確認ください。
主な変化点は以下のドキュメントにも掲載されています。
ドキュメント含めて大きく変更されており、またαリリースの際よりも組み込みMiddlewareも増えてましたので、個人的に気になる内容をピックアップしてDatabricks Free Edition上で検証していきます。
この記事では、LangChain v1のカスタムミドルウェアについて取り上げます。
LangChainのミドルウェアについては以前の記事でも取り上げていますので、良ければ一読ください。
上記記事は組み込みミドルウェアの利用について記載していますが、エージェントの処理内容によっては独自のミドルウェアを作る必要があります。
今回は公式ドキュメントの内容に基づいて、カスタムミドルウェアをDatabricks上で作成してみます。
カスタムミドルウェアを作る
カスタムミドルウェアの作成方法は以下の2種類あります。
- デコレータベース: 関数デコレータを使ってミドルウェアを定義する方法。シンプルに作れる。
- クラスベース: ミドルウェアをクラスとして定義する方法。複雑な処理も定義可能。
どちらも試してみます。
準備
まずはノートブックを作成して必要なパッケージをインストール。
TracingのためにMLflowもインストールします。
また、Retry関連をサポートするパッケージtenacityもインストールしておきます。
%pip install -U langchain>=1.0.0 langchain_openai>=1.0.0 mlflow tenacity
%restart_python
次に利用する基本モデルをセットアップします。
利用するモデルは任意でOKですが、今回はdatabricks-qwen3-next-80b-a3b-instructを利用しました。
from langchain.chat_models import init_chat_model
import mlflow
mlflow.langchain.autolog()
creds = mlflow.utils.databricks_utils.get_databricks_host_creds()
model = init_chat_model(
"openai:databricks-qwen3-next-80b-a3b-instruct",
api_key=creds.token,
base_url=creds.host + "/serving-endpoints",
)
共通で利用するツールも用意しておきます。
from langchain.tools import tool, ToolRuntime
@tool
def get_weather(city: str, runtime: ToolRuntime) -> str:
"""指定した都市の天気を取得します。"""
return f"It's always sunny in {city}!"
デコレータベースのカスタムミドルウェア
事前定義されたデコレータを関数に指定することで、カスタムミドルウェアを作ることができます。利用可能なデコレータは2025年11月初頭時点で以下の通り。
Node スタイル(特定の実行ポイントで実行):
-
@before_agent– エージェント開始前(呼び出しごとに1回) -
@before_model– 各モデル呼び出しの直前 -
@after_model– 各モデル応答の直後 -
@after_agent– エージェント完了後(呼び出しごとに1回)
Wrap スタイル(実行をインターセプトして制御):
-
@wrap_model_call– 各モデル呼び出しを囲む -
@wrap_tool_call– 各ツール呼び出しを囲む
便利なデコレータ:
-
@dynamic_prompt– 動的システムプロンプトを生成する(@wrap_model_callでプロンプトを変更するのと同等)
NodeスタイルとWrapスタイルで修飾できる関数のパラメータが異なることに注意が必要です。
実際にこの中のいくつかを使ったカスタムミドルウェアを作って動かしてみます。
from langchain.agents.middleware import (
before_model,
after_model,
wrap_model_call,
before_agent,
after_agent,
wrap_tool_call,
AgentState,
ModelRequest,
ModelResponse,
dynamic_prompt,
)
from langchain.messages import AIMessage
from langchain.agents import create_agent
from langgraph.runtime import Runtime
from typing import Any, Callable
# ノードスタイル: エージェント実行前のロギング
@before_agent
def log_before_agent(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("Agent処理を開始します")
print(
f"before_agent: {len(state['messages'])}件のメッセージでエージェントを呼び出そうとしています"
)
return None
# ノードスタイル: エージェント実行後のロギング
@after_agent
def log_after_agent(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("Agent処理を終了します")
print(
f"after_agent: {len(state['messages'])}件のメッセージでエージェント処理を完了しました"
)
# ノードスタイル: モデル呼び出し前のロギング
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(
f"before_model: {len(state['messages'])}件のメッセージでモデルを呼び出そうとしています"
)
return None
# ノードスタイル: モデル呼び出し後のバリデーション
@after_model(can_jump_to=["end"])
def validate_output(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
last_message = state["messages"][-1]
if "BLOCKED" in last_message.content:
return {
"messages": [AIMessage("そのリクエストには対応できません。")],
"jump_to": "end",
}
return None
# ラップスタイル: リトライロジック
@wrap_model_call
def retry_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
for attempt in range(3):
try:
return handler(request)
except Exception as e:
if attempt == 2:
raise
print(f"エラー発生後にリトライ {attempt + 1}/3: {e}")
@wrap_tool_call
def retry_tool(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
for attempt in range(3):
try:
return handler(request)
except Exception as e:
if attempt == 2:
raise
print(f"エラー発生後にリトライ {attempt + 1}/3: {e}")
# カスタムミドルウェアを指定したエージェントを作成
agent = create_agent(
model=model,
middleware=[
log_before_agent,
log_after_agent,
log_before_model,
validate_output,
retry_model,
retry_tool,
],
tools=[get_weather],
)
# ストリームで実行出力
for stream_mode, chunk in agent.stream(
{"messages": [{"role": "user", "content": "東京の天気を教えて"}]},
stream_mode=["updates"],
):
print(f"stream_mode: {stream_mode}")
print(f"content: {chunk}")
print("\n")
実行結果は以下の通り。
Agent処理を開始します
before_agent: 1件のメッセージでエージェントを呼び出そうとしています
stream_mode: updates
content: {'log_before_agent.before_agent': None}
before_model: 1件のメッセージでモデルを呼び出そうとしています
stream_mode: updates
content: {'log_before_model.before_model': None}
stream_mode: updates
content: {'model': {'messages': [AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 21, 'prompt_tokens': 163, 'total_tokens': 184, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'qwen3-next-instruct-091725', 'system_fingerprint': None, 'id': 'chatcmpl_c6bc7f00-7c6d-4ef7-9bb7-d3275d93968e', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--7931868b-5fba-482a-b924-5b5908b68f88-0', tool_calls=[{'name': 'get_weather', 'args': {'city': '東京'}, 'id': 'call_9f687a52-f073-4204-b40d-86f29223da60', 'type': 'tool_call'}], usage_metadata={'input_tokens': 163, 'output_tokens': 21, 'total_tokens': 184, 'input_token_details': {}, 'output_token_details': {}})]}}
stream_mode: updates
content: {'validate_output.after_model': None}
stream_mode: updates
content: {'tools': {'messages': [ToolMessage(content="It's always sunny in 東京!", name='get_weather', id='48be2fb2-faf3-43ba-a662-5a2445d65250', tool_call_id='call_9f687a52-f073-4204-b40d-86f29223da60')]}}
before_model: 3件のメッセージでモデルを呼び出そうとしています
stream_mode: updates
content: {'log_before_model.before_model': None}
stream_mode: updates
content: {'model': {'messages': [AIMessage(content='東京の天気は晴れです!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 11, 'prompt_tokens': 205, 'total_tokens': 216, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'qwen3-next-instruct-091725', 'system_fingerprint': None, 'id': 'chatcmpl_d9fd9557-54f7-466a-a668-e796ac853615', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--6062aa52-ec07-49d9-aa88-515a21370c3c-0', usage_metadata={'input_tokens': 205, 'output_tokens': 11, 'total_tokens': 216, 'input_token_details': {}, 'output_token_details': {}})]}}
stream_mode: updates
content: {'validate_output.after_model': None}
Agent処理を終了します
after_agent: 4件のメッセージでエージェント処理を完了しました
stream_mode: updates
content: {'log_after_agent.after_agent': None}
MLflow Tracingとしての履歴は以下のように記録されました。
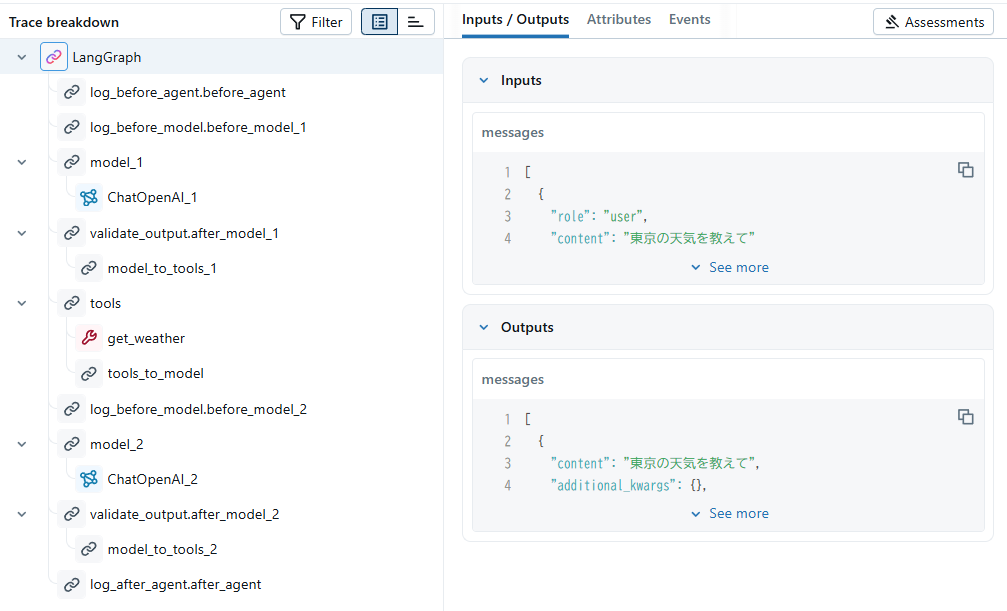
特にMLflow Tracingの結果がわかりやすいですが、LLMへのクエリが実行されるまでにlog_before_agent関数やlog_before_model関数が実行されていることがわかります。また、その後もカスタムミドルウェアとして設定した内容がエージェント内処理に組み込まれて実行されています。
少しだけわかりづらいのは、@wrap_model_callや@wrap_tool_callの処理については、現時点でMLflow Tracingに記録されないようです。
シンプルにモデル・ツール呼び出し前後への処理挿入などにはデコレータベースで十分なカスタム処理が作れそうに思います。
クラスベースのカスタムミドルウェア
クラスAgentMiddlewareをオーバーライドする形でミドルウェアを定義することもできます。
例えば、モデル呼び出し前後でロギングタスクを挿入するミドルウェアは以下のようになります。
from langchain.agents.middleware import AgentMiddleware, AgentState
from langgraph.runtime import Runtime
from typing import Any
class LoggingMiddleware(AgentMiddleware):
def before_model(
self, state: AgentState, runtime: Runtime
) -> dict[str, Any] | None:
print(f"About to call model with {len(state['messages'])} messages")
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"Model returned: {state['messages'][-1].content}")
return None
# クラスベースのミドルウェアをエージェントで使用
agent = create_agent(
model=model,
middleware=[
LoggingMiddleware(),
],
tools=[get_weather],
)
for stream_mode, chunk in agent.stream(
{"messages": [{"role": "user", "content": "東京の天気を教えて"}]},
stream_mode=["updates"],
):
print(f"stream_mode: {stream_mode}")
print(f"content: {chunk}")
print("\n")
実行結果は以下の通り。
About to call model with 1 messages
stream_mode: updates
content: {'LoggingMiddleware.before_model': None}
stream_mode: updates
content: {'model': {'messages': [AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 21, 'prompt_tokens': 163, 'total_tokens': 184, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'qwen3-next-instruct-091725', 'system_fingerprint': None, 'id': 'chatcmpl_1d55a4d1-ab31-4312-bbaa-b496164c69ee', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--d573f642-1076-4be3-bc50-e33afc0c7efc-0', tool_calls=[{'name': 'get_weather', 'args': {'city': '東京'}, 'id': 'call_1830b19e-a9b2-49e2-b8f5-597638840fd6', 'type': 'tool_call'}], usage_metadata={'input_tokens': 163, 'output_tokens': 21, 'total_tokens': 184, 'input_token_details': {}, 'output_token_details': {}})]}}
Model returned:
stream_mode: updates
content: {'LoggingMiddleware.after_model': None}
stream_mode: updates
content: {'tools': {'messages': [ToolMessage(content="It's always sunny in 東京!", name='get_weather', id='62a57953-cbc0-4c47-87c7-1dacdd702914', tool_call_id='call_1830b19e-a9b2-49e2-b8f5-597638840fd6')]}}
About to call model with 3 messages
stream_mode: updates
content: {'LoggingMiddleware.before_model': None}
stream_mode: updates
content: {'model': {'messages': [AIMessage(content='東京の天気は快晴です!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 11, 'prompt_tokens': 205, 'total_tokens': 216, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'qwen3-next-instruct-091725', 'system_fingerprint': None, 'id': 'chatcmpl_8dd3e772-eab5-47c5-a767-c4257bc3dfcc', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--cdb5dae5-50ca-4279-8efc-5cc4faa33626-0', usage_metadata={'input_tokens': 205, 'output_tokens': 11, 'total_tokens': 216, 'input_token_details': {}, 'output_token_details': {}})]}}
Model returned: 東京の天気は快晴です!
stream_mode: updates
content: {'LoggingMiddleware.after_model': None}
MLflow Tracingの結果は以下のようになります。
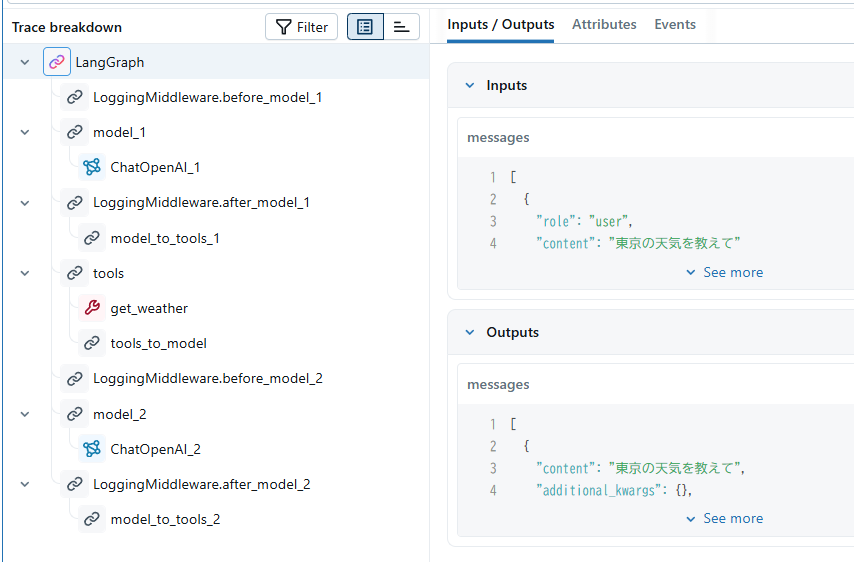
LoggingMiddlewareがモデル呼び出し前後でタスクを実行しているのがわかります。
次にWrapスタイルのクラスベースカスタムミドルウェアも試してみます。
モデルが失敗した際にリトライする&MLflow Tracingへモデルへの入力を記録するミドルウェアです。
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from typing import Callable
from mlflow.entities import SpanType
from tenacity import retry, stop_after_attempt, wait_fixed, wait_exponential, RetryError, after_log
import time
from collections.abc import Awaitable
class RetryMiddleware(AgentMiddleware):
def __init__(self, max_retries: int = 3):
super().__init__()
self.max_retries = max_retries
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
)
def wrap_handler(request):
with mlflow.start_span(name="model_call", span_type=SpanType.CHAIN) as span:
span.set_inputs(request)
return handler(request)
return wrap_handler(request)
# aから始まる関数を定義することで、async使用時の処理も定義できる模様
# 今回は使わない
async def awrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], Awaitable[ModelResponse]],
) -> ModelResponse:
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
)
async def awrap_handler(request):
with mlflow.start_span(name="model_call", span_type=SpanType.CHAIN) as span:
span.set_inputs(request)
return await handler(request)
return await awrap_handler(request)
# クラスベースのミドルウェアをエージェントで使用
agent = create_agent(
model=model,
middleware=[
RetryMiddleware(),
],
tools=[get_weather],
)
for stream_mode, chunk in agent.stream(
{"messages": [{"role": "user", "content": "東京の天気を教えて"}]},
stream_mode=["updates"],
):
print(f"stream_mode: {stream_mode}")
print(f"content: {chunk}")
print("\n")
出力結果は以下の通り。
処理としては、モデル呼び出し時にエラーが発生した場合リトライするようになっていますが、今回は正常系のみの実行結果となります。
stream_mode: updates
content: {'model': {'messages': [AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 21, 'prompt_tokens': 163, 'total_tokens': 184, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'qwen3-next-instruct-091725', 'system_fingerprint': None, 'id': 'chatcmpl_e70cf480-4f35-4732-a7c9-87af1f701338', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--c60e53b1-d19e-4226-b0fe-6616bb75e908-0', tool_calls=[{'name': 'get_weather', 'args': {'city': '東京'}, 'id': 'call_a584fb05-0615-4a1e-83c6-a092a2ed2469', 'type': 'tool_call'}], usage_metadata={'input_tokens': 163, 'output_tokens': 21, 'total_tokens': 184, 'input_token_details': {}, 'output_token_details': {}})]}}
stream_mode: updates
content: {'tools': {'messages': [ToolMessage(content="It's always sunny in 東京!", name='get_weather', id='2019a2e5-d1cf-4050-ae17-9d0c8a44758b', tool_call_id='call_a584fb05-0615-4a1e-83c6-a092a2ed2469')]}}
stream_mode: updates
content: {'model': {'messages': [AIMessage(content='東京の天気は晴れです!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 11, 'prompt_tokens': 205, 'total_tokens': 216, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'qwen3-next-instruct-091725', 'system_fingerprint': None, 'id': 'chatcmpl_95a9a1b6-4cad-420b-9b1c-44ee488b963e', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--acd770b1-0009-439e-a9af-71d68957d574-0', usage_metadata={'input_tokens': 205, 'output_tokens': 11, 'total_tokens': 216, 'input_token_details': {}, 'output_token_details': {}})]}}
MLflow Tracingの結果は以下のようになります。
ChatOpenAIのクエリ実行前にmodel_callという名前で処理の割り込みが入っているのがわかります。
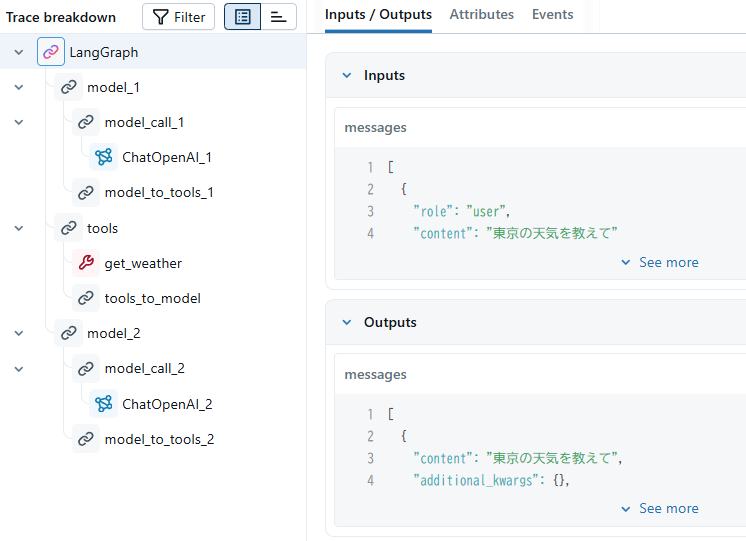
このようにクラスベースでもミドルウェアが定義できます。
デコレータベースと比べての利点は、インスタンスのフィールドでミドルウェアの挙動をコントロールしたり、こちらの記事のようにエージェントの内部状態定義を変更したり、という少し複雑な制御を実行することができます。
使い分けはケースバイケースで判断が必要ですが、実務では深いカスタムが必要となるケースが多いように思うので、クラスベースでのカスタムが多くなるように思います。
まとめ
LangChain v1のコアとも言うべきミドルウェア機能について、カスタムミドルウェアの作成を試してみました。
ドキュメントには「組み込みミドルウェアで事足りる場合は組み込みミドルウェアを使ってね(意訳)」と書いてあり、割とよくあるケースだと組み込みミドルウェアを中心に使用を検討し、それだとどうしても足りない場合はカスタムミドルウェアを作る、という形でカスタムしていくのがいいように思います。
ミドルウェアがかなり便利そうなので、ランタイムであるLangGraphをそのまま使うケースが本当に減りそうです。これからのエージェントアプリ構築においてLangChainとLangGraphどちらで始めるかを迷った場合、LangChainから始めることで概ね満足できる気がしますね。