こちらの続きです。
だいぶ長かったですが、これで最後です。
導入
前回はCRAGのパイプラインをLangGraphを使って実装しました。
第4回はUIの実装です。 これでQ&Aアプリぽくなります。
また、いくつか改善に向けた考察を入れておきます。
流れの解説
UIはStremlitで実装します。
さくっとデータアプリを作る分には本当に便利ですね。
Lakehouse Appが使えると、UIもDatabricksマネージドサービスで構築できると思うのですが、続報がありませんね。。。
DAIS2024で何か発表があるのかな。。。
また、StreamlitはDatabricksのクラスタ上で起動しますが、今回のコードはシングルユーザモードのクラスタのみに対応しています。共有クラスタでは(私の環境下では)このままだと動きませんでした。
Step1. Streamlitのコードを記述
ワークスペース内にstreamlit_ui.pyというPythonファイルを作成し、以下のようにコードを記述します。ファイルは、第3回で作成したgraph.pyと同じ場所に置いてください。
streamlit_ui.py
import os
import sys
import streamlit as st
import pandas as pd
from typing import Any, Union
from pydantic import BaseModel, conlist
from graph import build_graph
import graph
class EventOutput(BaseModel):
node: str
message: str
data: Union[Any, None] = None
def convert_documents_to_pandas(documents):
page_content_df = pd.DataFrame(
[d.page_content for d in documents], columns=["page_content"]
)
metadatas_df = pd.DataFrame([d.metadata for d in documents])
return pd.concat([page_content_df, metadatas_df], axis=1)
def handle_event_output(event):
result = None
if "retrieve" in event:
state = event.get("retrieve")
message = f"次の質問に対する関連文書を取得しました: {state.get('question')}"
documents = convert_documents_to_pandas(state.get("documents"))
result = EventOutput(node="retrieve", message=message, data=documents)
elif "generate" in event:
state = event.get("generate")
documents = convert_documents_to_pandas(state.get("documents"))
message = state.get('generation')
result = EventOutput(node="generate", message=message, data=documents)
elif "transform_query" in event:
state = event.get("transform_query")
message = f"次のワードでWeb検索します: {state.get('web_query')}"
result = EventOutput(node="transform_query", message=message)
elif "web_search_node" in event:
state = event.get("web_search_node")
search_result = state.get("documents")[-1].page_content
message = f"Webから検索結果を取得しました"
result = EventOutput(
node="web_search_node", message=message, data=search_result
)
elif "grade_documents" in event:
state = event.get("grade_documents")
documents = convert_documents_to_pandas(state.get("documents"))
message = f"質問の回答を含む文書のみに限定しました: {len(documents)}件"
result = EventOutput(node="grade_documents", message=message, data=documents)
return result
st.set_page_config(
page_title="Databricks document Q&A",
page_icon="📝",
layout="wide",
initial_sidebar_state="collapsed",
)
app = build_graph()
# セッション初期化
if "histories" not in st.session_state:
st.session_state["histories"] = []
st.title("📝 Databricks Q&A")
default_questions = [
"Delta Lakeとは何ですか?",
"Unity Catalogを導入することで何ができるのですか?",
"ワークスペースユーザとアカウントユーザの違いは何ですか?",
"Delta Live Tablesはdbtと比べてどのような優位性がありますか?",
"データウェアハウスを構築する際の注意点は?",
"Databricksはどのクラウドプラットフォーム上で利用することができますか?",
"日本で最もりんごの収穫量が大きい都道府県はどこ?",
"大阪で行くべき飲食店を3カ所、その理由を含めて教えてください。",
]
buttons_placeholder = st.empty()
question_placeholder = st.empty()
message_placeholder = st.empty()
status_placeholder = st.empty()
with buttons_placeholder.container():
default_buttons = [st.button(q) for q in default_questions]
# チャットUI
prompt = st.chat_input(default_questions[0])
for i, default_button in enumerate(default_buttons):
if default_button:
prompt = default_questions[i]
break
if prompt:
buttons_placeholder.empty()
with question_placeholder.container():
st.write(prompt)
with st.spinner("Thinking..."):
status = st.status("processing...", expanded=True)
if st.button("新しい問い合わせ"):
st.rerun()
for event in app.stream({"question": prompt}):
output = handle_event_output(event)
if output:
# 最終出力の場合
if output.node == "generate":
with message_placeholder.container():
st.write("### 回答:")
st.write(output.message)
st.caption(f"Generated by {graph.generate_endpoint_name}")
if len(output.data) > 0 and "url" in output.data.columns:
url_df = output.data[["url"]].drop_duplicates()
st.write("### 参考リンク:")
links_text_list = ["- " + link for link in url_df["url"] if isinstance(link, str)]
st.write("\n".join(links_text_list))
status.update(
label="Process complete!", state="complete", expanded=False
)
else:
with status_placeholder.container():
with status:
st.write(output.message)
if output.data is not None:
# with st.expander("Show details"):
st.write(output.data)
このファイル内でgraph.py内のbuild_graphを呼び出し、LangGraphのグラフを構築して利用しています。
Step2. Streamlitをノートブック上で起動
上のpythonファイルと同じ場所にノートブックを作成し、Streamlitを起動する処理を記述します。
まず、パッケージをインストール。
graph.py内で利用するパッケージも合わせてインストールします。
%pip install --upgrade --force-reinstall databricks-vectorsearch
%pip install -U langchain langgraph langchain_community tavily-python pydantic
%pip install streamlit
dbutils.library.restartPython()
次に環境変数を設定。
第3回と同様、TavilyとDatabricksエンドポイント用のAPIトークンを設定します。
(TavilyのAPIトークン設定については第3回の記事を参照ください)
import os
# Tavily APIを実行するためのAPIキーを設定
os.environ["TAVILY_API_KEY"] = dbutils.secrets.get("tavily", "api_key")
os.environ["DATABRICKS_HOST"] = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get()
os.environ["DATABRICKS_TOKEN"] = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
Streamlit起動後にブラウザから接続するURLを取得し、Notebook上に表示します。
また、streamlit_ui.pyとgraph.pyをワークスペースからクラスタ内のローカルストレージにコピーしています。
ローカルストレージにコピーするのは開発生産を高めるためで、別のノートブックからこのファイルを更新することで、Streamlitのソースリロードが出来るようになります。
(ワークスペース上のファイルから直接起動すると、ファイルの更新をStreamlit上で感知できないため)
from multiprocessing.pool import ThreadPool
from dbruntime.databricks_repl_context import get_context
import os
def front_url(port: int = 8501):
"""
フロントエンドを実行するための URL を返す
Returns
-------
proxy_url : str
フロントエンドのURL
"""
ctx = get_context()
proxy_url = f"https://{ctx.browserHostName}/driver-proxy/o/{ctx.workspaceId}/{ctx.clusterId}/{port}/"
return proxy_url
# コードセットのコピー
dbutils.fs.cp(f"file:{os.getcwd()}/streamlit_ui.py", "file:/tmp/dev/st/streamlit_ui.py")
dbutils.fs.cp(f"file:{os.getcwd()}/graph.py", "file:/tmp/dev/st/graph.py")
# URL表示
displayHTML(f"<a href='{front_url(port)}' target='_blank' rel='noopener noreferrer'>別ウインドウで開く</a>")
最後にStreamlitを起動します。
!streamlit run /tmp/dev/st/streamlit_ui.py
Step3. 動かす
では、動かしてみましょう。
取得したURLにブラウザからアクセスすると、以下のような画面が表示されます。
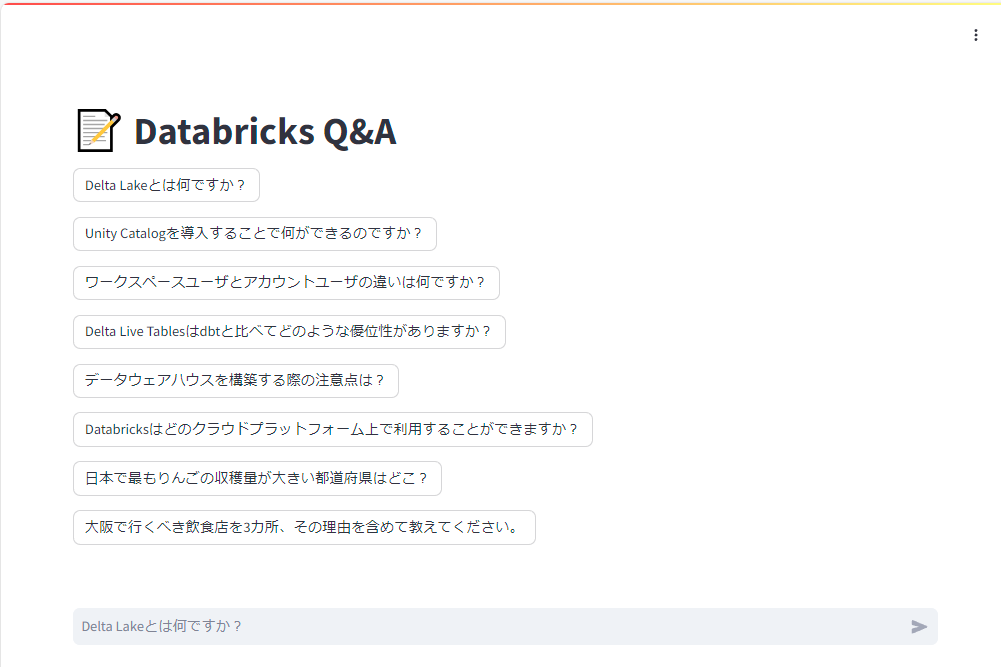
いくつかショートカットがありますので、一番上の「Delta Lakeとは何ですか?」を押してみましょう。
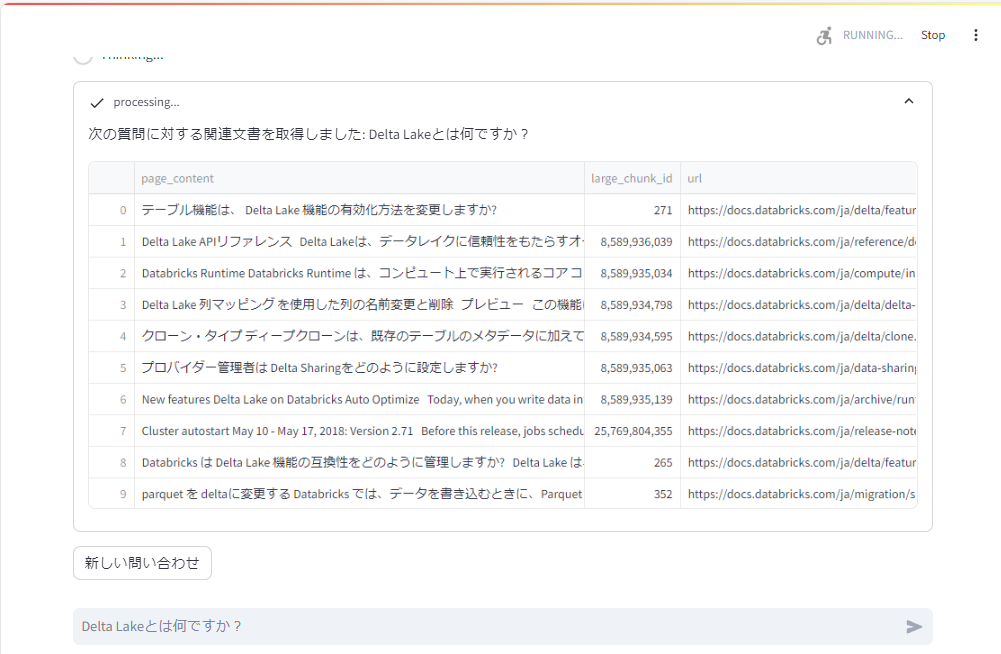
検索された文書など、処理の過程が表示されます。
全てのプロセスが終わると、回答結果と参考リンクが表示される、というUIとなっています。

ちなみに、ベクトルデータに存在しない場合はWeb検索で回答を作るため、以下のような質問も回答できます。
利用しているLLM(Mistral-7B-Instruct v0.3)の性能的に、少し日本語はおかしいですが。

GIFですが、動画にするとこんな感じ。

※ 全体の処理時間内訳としては、最後の回答生成処理が大半を占めまる印象です。文書検索やそのグレードチェックは十分な速度で実施されています。
グレードチェック部分がボトルネックにならないかと心配していましたが、vLLMで構築したエンドポイントは十分なスループットが出ていました。
改善点の考察
より性能を高めたり、実運用を考えたりする上で、改善点が大量にあります。
全部あげきるのは大変なので、いくつか記載します。
エラーハンドリングとロギング
エラーハンドリングやロギング処理の大半を省略しています。
ちゃんと入れましょう。
あとテストも。
コスト最適化
このパイプラインでは、以下4つのエンドポイントを利用しています。
- Databricks Vector Search用エンドポイント
- 埋め込み用モデルのエンドポイント
- グレードチェックを行うLLMバッチ処理エンドポイント
- 最終回答生成やクエリ変換を行うLLMエンドポイント
これらは起動時間でコストがかかります。
運用の仕方によっては全てプロプライエタリなLLM APIを利用したほうがコストを安く抑えらえるかもしれません。
また、バッチ処理用と最終回答生成用のエンドポイントは1本に統合したほうがコストを抑えられる可能性があります。
利用するLLMとの組み合わせを考慮しつつ、コスト最適な構成を考えることが大事だと思います。
LLMの選択
RAGの性能は、検索性能とLLMによる回答生成の性能に大きく依存すると考えています。
検索部分ではグレードチェックを行っていますが、これに特化したLLM(ファインチューニングしたLLM)を利用することでより必要な文書の選択性能を上げられます。
(もちろんLLMである必要はなく、従来のNLPの領域でも十分な性能が得られるかもしれません)
また、回答生成においてはなるべく性能の良いLLMを使う方がよい結果を得られます。
検索性能が多少悪くても、ここで優秀なLLMを使うことでカバーできたりもします。
ここのLLM選択、もしくは独自に構築するかなど、改善のための選択肢は多くあるように思います。
プロンプト制御
プロンプトエンジニアリングも性能向上に置いては考慮するべきです。
また、今回はソースコード内にプロンプトを埋め込んでいますが、プロンプトもきちんとモジュール化するべきです。
このあたりLangSmith/LangChainHub等を利用して外部リソースとして扱えるようにしたほうがよいでしょう。(Databricksにもプロンプト管理のサービスが追加されると有難いのですが)
まとめ
全4回にわたる内容になりましたが、なるべくDatabricksマネージドなサービスを利用してちょっと高度なRAG Chatbotを構築してみました。
今回はCRAGで行いましたが、Adaptive RAGなど他の手法だとまた違う結果が得られるかもしれません。
Q&A型のようなChatbotは様々なアプローチや解説が出てきており、Difyなどもあってかなり簡単に構築できるようになってきた印象があります。
とはいえ、十分な性能を出すのは結構大変であり、ゆえにまだまだ深い分野です。
Databricksはこういった仕組を構築するには非常によいプラットフォームだと改めて思いました。今後も様々アップデートがあるでしょうし、これらを多くの人が活用して、LLM等生成AI活用がどんどん浸透していくとよいと考えています。