こちらの(精神的)続編です。
※ 本文はコードだらけで非常に長いです。実行結果だけ見たい人はStep6.に移動ください。
導入
OpenAI社のDeepResearch登場以後、Perplexity Deep ResearchやGrokのDeep Research機能など、調査・レポーティング分野でのサービス提供が盛んです。
そんな中で、LangChain社がOpen Deep Researchというリポジトリを公開しました。
これは以前公開されたOllama-Deep-Researcherと比べて、
- レポート全体の構成作成(Planning)
- 構成に対するユーザからの意見収集(Human-in-the-Loop)
- 各セクションからのサマリ自動作成
といった機能を備えています。
以前の記事を書いていた時にも、構成作成を加えたらちゃんとしたレポートを作れるなあと思っていたのですが、まさにそれを実現するような内容です。
処理の流れとしては、リポジトリ内のReadMeで下図のように解説されています。
Researchだけではなく、Planning/Structure部を追加して完全なレポート作成を担うことができます。
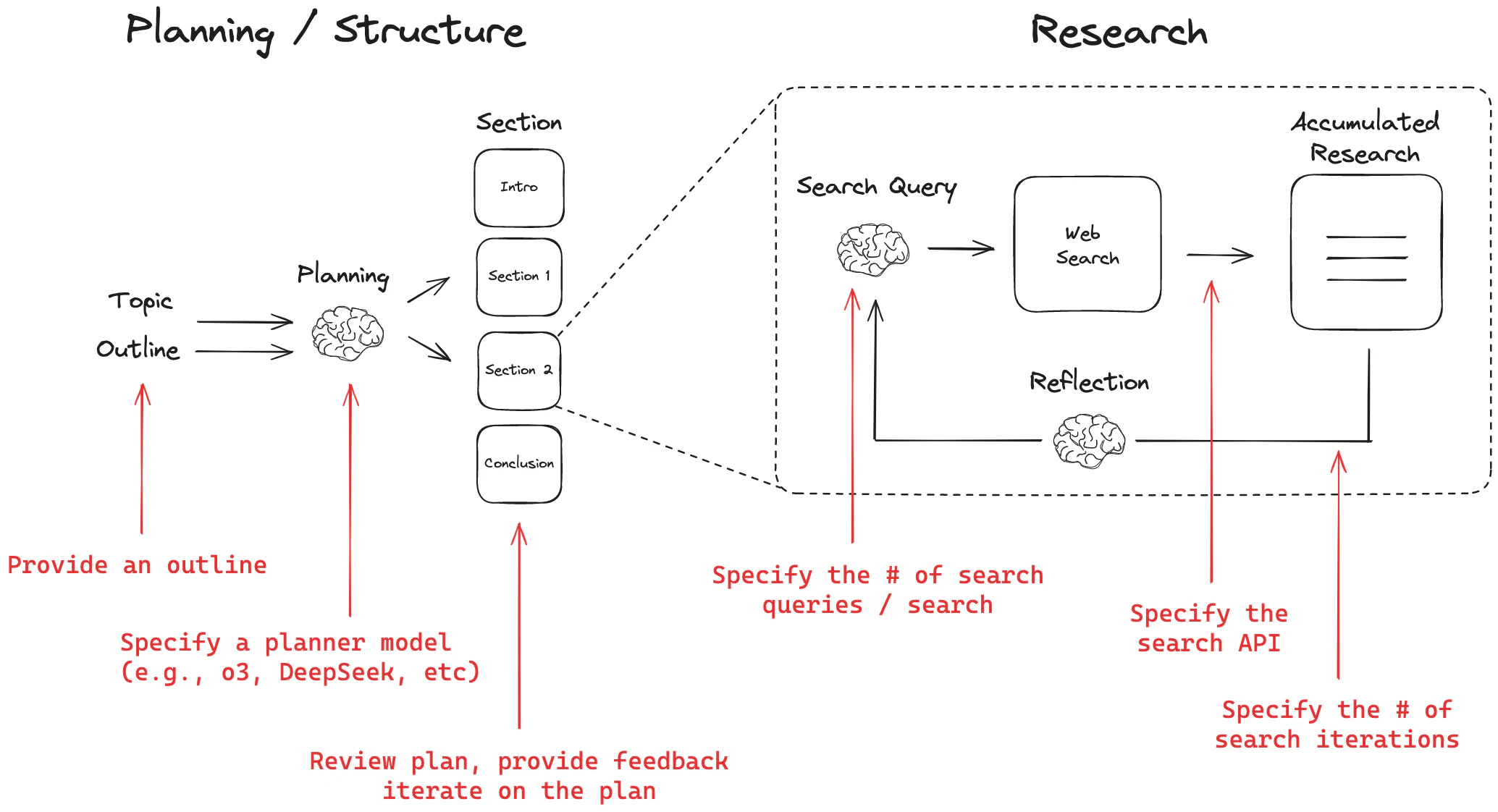
かなり面白そうでしたので、今回もこちらのリポジトリの内容を参考にさせていただき、Databricks上で動作する簡易Deep Reseach機能を自己学習のために実装してみます。
というか、ほとんどリポジトリ内のコードを基にしたウォークスルー(一部は変更)となっています。
この記事は自分の勉強用にリポジトリ内のコードを読み解いて車輪の再実装をしています。
Opne Deep Researchを利用する分には、このリポジトリをインストールして利用することをお薦めします。(pipからinstallできます)
サンプルノートブックも以下にあります。どのようなレポートが最終的に実装できるかわかるかと思います。
https://github.com/langchain-ai/open_deep_research/blob/main/src/open_deep_research/graph.ipynb
今回の記事で実装する内容は、オリジナルリポジトリと比較して以下の変更点があります。
- 処理内で利用するLLMに、Databricksでサーブしているモデルを利用
- オリジナルはAnthropicやGroqのAPI等を利用するようになっています。
- 今回はPay-per-tokensで提供されている
databricks-meta-llama-3-3-70b-instructを利用しました
- シンプル化するために情報検索はTavilyのみに限定(オリジナルはPerplexity APIにも対応)
- 各種プロンプトを日本語に翻訳して利用
- トークン効率や回答精度の面ではマイナスですが、日本人としてのわかりやすさを優先しました
- TavilyへDatabricksの外部サービス接続を使って接続
- MLflow Tracingに対応
- LangGraph Functional APIを使ってワークフローを構築(オリジナルはLangGraph Graph APIを利用)
プロンプト等、オリジナルのものを利用させていただいてもらっています。
本リポジトリの開発者・関係者には深く感謝いたします。
今回の記事は2025/2/15ごろのリポジトリを参考にさせてもらっています。
Open-Deep-Reseachは現在も積極的にアップデートが入っていますので、興味を持たれた方はオリジナルのリポジトリを是非活用ください。
開発はDatabricks on AWS上で実施しました。クラスタはサーバレスです。
Step1. パッケージインストールなど準備
Databricks上でノートブックを作成し、langgraphなどの必要なパッケージをインストールします。
%pip install -U databricks-sdk
%pip install langgraph databricks-langchain
%pip install "mlflow-skinny[databricks]>=2.20.2" loguru
%restart_python
Step2. プロンプトの準備
エージェントの中で利用するプロンプトを準備します。
こちらはオリジナルリポジトリの内容を日本語に翻訳して利用させていただいています。
以下、6種のプロンプトを定義しています。
- report_planner_query_writer_instructions: 調査レポートの構成を作成するためのWeb検索するクエリ作成用プロンプト
- report_planner_instructions: 調査レポートの章立て作成用プロンプト
- query_writer_instructions: 章(セクション)の中身を作成するために必要な検索クエリ作成用プロンプト
- section_writer_instructions: セクションの中身を検索結果を基に作成するプロンプト
- section_grader_instructions: 書かれたセクションの中身をレビューし、修正が必要かどうかを判定するためのプロンプト
- final_section_writer_instructions:序章・結論部を全体の中身を俯瞰しながらアップデートするためのプロンプト
この内容なprompts_jp.pyという外部ファイルに出力し、後続の処理では出力されたファイルを利用する形にしています。(プロンプトを後から切り分けて編集可能にするため)
%%writefile prompts_jp.py
# レポートの計画を支援するための検索クエリを生成するためのプロンプト
report_planner_query_writer_instructions="""あなたはレポートの計画を支援する専門の技術ライターです。
<Report topic>
{topic}
</Report topic>
<Report organization>
{report_organization}
</Report organization>
<Feedback>
{feedback}
</Feedback>
<Task>
あなたの目標は、レポートセクションの計画に役立つ包括的な情報を収集するために{number_of_queries}件の検索クエリを生成することです。
必ず{number_of_queries}件のクエリを生成してください。
クエリは以下の条件を満たす必要があります:
1. Report topicに関連していること
2. Report organizationで指定された要件を満たすこと
3. Feedbackがあれば、それを考慮すること
クエリは、レポート構造に必要な幅をカバーしながら、高品質で関連性のある情報源を見つけるのに十分具体的である必要があります。
</Task>"""
# レポート計画を生成するためのプロンプト
report_planner_instructions="""レポートの計画を立てたいです。
<Task>
レポートのセクションのリストを生成してください。
各セクションには以下のフィールドが含まれている必要があります:
- Name - このレポートセクションの名前。
- Description - このセクションでカバーされる主なトピックの概要。
- Research - このレポートセクションのためにウェブリサーチを行うかどうか。
- Content - セクションの内容、これは今のところ空白のままにしてください。
例えば、イントロダクションと結論は他の部分から情報を抽出するため、リサーチを必要としません。
</Task>
<Topic>
レポートのトピック:
{topic}
</Topic>
<Report organization>
レポートはこの構成に従ってください:
{report_organization}
</Report organization>
<Context>
レポートのセクションを計画するために使用するコンテキストは次のとおりです:
{context}
</Context>
<Feedback>
レビューからのレポート構造に関するフィードバック(もしあれば):
{feedback}
</Feedback>
"""
# クエリライターの指示
query_writer_instructions="""あなたは技術レポートセクションを書くための包括的な情報を収集するためのターゲットウェブ検索クエリを作成する専門の技術ライターです。
<Section topic>
{section_topic}
</Section topic>
<Task>
{number_of_queries}の検索クエリを生成する際には、以下を確実に行ってください:
1. トピックの異なる側面をカバーする(例:コア機能、実世界のアプリケーション、技術アーキテクチャ)
2. トピックに関連する具体的な技術用語を含める
3. 関連する場合は年のマーカーを含めて最新情報をターゲットにする(例:"2024")
4. 類似技術/アプローチとの比較や差別化を探す
5. 公式ドキュメントと実践的な実装例の両方を検索する
クエリは次のようにする必要があります:
- 一般的な結果を避けるのに十分具体的であること
- 詳細な実装情報をキャプチャするのに十分技術的であること
- セクション計画のすべての側面をカバーするのに十分多様であること
- 権威ある情報源(ドキュメント、技術ブログ、学術論文)に焦点を当てること
</Task>"""
# セクションライターの指示
section_writer_instructions = """あなたは技術レポートの一部を作成する専門の技術ライターです。
<Section topic>
{section_topic}
</Section topic>
<Existing section content (if populated)>
{section_content}
</Existing section content>
<Source material>
{context}
</Source material>
<Guidelines for writing>
1. 既存のセクション内容が埋められていない場合、新しいセクションをゼロから書いてください。
2. 既存のセクション内容が埋められている場合、既存のセクション内容と新しい情報を統合して新しいセクションを書いてください。
</Guidelines for writing>
<Length and style>
- 厳密に150-200ワードの制限
- マーケティング言語を使用しない
- 技術的な焦点
- 簡単で明確な言葉で書く
- 最も重要な洞察を**太字**で始める
- 短い段落を使用(最大2-3文)
- セクションタイトルには##を使用(Markdown形式)
- ポイントを明確にするのに役立つ場合にのみ、1つの構造要素を使用:
* 比較する2-3の主要項目を焦点とした表(Markdown表記法を使用)
* または適切なMarkdownリスト表記法を使用した短いリスト(3-5項目)
- 箇条書きには`*`または`-`を使用
- 番号付きリストには`1.`を使用
- 適切なインデントとスペースを確保
- 以下のソース資料を参照する### Sourcesで終了:
* 各ソースをタイトル、日付、URLでリスト
* フォーマット:`- タイトル : URL`
</Length and style>
<Quality checks>
- タイトルとソースを除いて正確に150-200ワード
- ポイントを明確にするのに役立つ場合にのみ1つの構造要素(表またはリスト)を慎重に使用
- 具体的な例/ケーススタディ1つ
- 太字の洞察で始める
- セクション内容を作成する前に前置きなし
- 最後にソースを引用
</Quality checks>
"""
# セクション評価の指示
section_grader_instructions = """指定されたトピックに対するレポートセクションをレビューしてください:
<section topic>
{section_topic}
</section topic>
<section content>
{section}
</section content>
<task>
技術的な正確さと深さを確認して、セクションがトピックを適切にカバーしているかどうかを評価してください。
セクションが基準を満たさない場合、欠けている情報を収集するための具体的なフォローアップ検索クエリを生成してください。
</task>
<format>
grade: Literal["pass","fail"] = Field(
description="応答が要件を満たしているか('pass')または修正が必要か('fail')を示す評価結果。"
)
follow_up_queries: List[SearchQuery] = Field(
description="フォローアップ検索クエリのリスト。",
)
</format>
"""
final_section_writer_instructions="""あなたはレポートの残りの部分から情報を統合するセクションを作成する専門の技術ライターです。
<Section topic>
{section_topic}
</Section topic>
<Available report content>
{context}
</Available report content>
<Task>
1. セクション固有のアプローチ:
イントロダクションの場合:
- レポートタイトルには#を使用(Markdown形式)
- 50-100ワードの制限
- 簡単で明確な言葉で書く
- 1-2段落でレポートの核心的な動機に焦点を当てる
- レポートを紹介するための明確な物語のアークを使用
- 構造要素を含めない(リストや表なし)
- ソースセクションは不要
結論/要約の場合:
- セクションタイトルには##を使用(Markdown形式)
- 100-150ワードの制限
- 比較レポートの場合:
* Markdown表記法を使用して焦点を当てた比較表を含める必要があります
* 表はレポートからの洞察を抽出する必要があります
* 表のエントリは明確で簡潔に保つ
- 非比較レポートの場合:
* レポートで述べたポイントを要約するのに役立つ場合にのみ1つの構造要素を使用:
* レポートに存在する項目を比較する焦点を当てた表(Markdown表記法を使用)
* または適切なMarkdownリスト表記法を使用した短いリスト:
- 箇条書きには`*`または`-`を使用
- 番号付きリストには`1.`を使用
- 適切なインデントとスペースを確保
- 具体的な次のステップや影響で終了
- ソースセクションは不要
3. 執筆アプローチ:
- 一般的な声明よりも具体的な詳細を使用
- すべての言葉を重要にする
- 最も重要なポイントに焦点を当てる
</Task>
<Quality Checks>
- イントロダクションの場合:50-100ワードの制限、#を使用したレポートタイトル、構造要素なし、ソースセクションなし
- 結論の場合:100-150ワードの制限、##を使用したセクションタイトル、最大1つの構造要素、ソースセクションなし
- Markdown形式
- 応答にワード数や前置きを含めない
</Quality Checks>"""
Step3. 各種Pydanticクラスの定義
後続の処理で利用するPydanticのデータクラスを定義します。
主にはLLMに対してStructured Outputを強制させるために使用します。
(ここのdescription部はオリジナルである英語表記のままにしました)
from typing import Annotated, List, TypedDict, Literal
from pydantic import BaseModel, Field
import operator
class Section(BaseModel):
name: str = Field(
description="Name for this section of the report.",
)
description: str = Field(
description="Brief overview of the main topics and concepts to be covered in this section.",
)
research: bool = Field(
description="Whether to perform web research for this section of the report."
)
content: str = Field(description="The content of the section.")
class Sections(BaseModel):
sections: List[Section] = Field(
description="Sections of the report.",
)
class SearchQuery(BaseModel):
search_query: str = Field(None, description="Query for web search.")
class Queries(BaseModel):
queries: List[SearchQuery] = Field(
description="List of search queries.",
)
class Feedback(BaseModel):
grade: Literal["pass", "fail"] = Field(
description="Evaluation result indicating whether the response meets requirements ('pass') or needs revision ('fail')."
)
follow_up_queries: List[SearchQuery] = Field(
description="List of follow-up search queries.",
)
Step4. ユーティリティ関数の定義
エージェント処理中に利用するユーティリティ関数を定義します。
主にはTavilyを使った検索や検索結果を整形する関数を定義しています。
なお、Tavily検索については、以前の記事で作成したDatabricksの接続オブジェクトを再利用して実装しました。
Tavilyに対する接続オブジェクトの作成については、手前みそですがこちらを参照ください。
オリジナルリポジトリとの変化点として、Tavilyの検索は単体のクエリを検索する関数としています。
オリジナルでは、複数クエリを非同期で検索する関数にしていましたが、今回の記事ではLagnGraph内で並行実行する形に変更しました。
import os
import asyncio
import requests
import mlflow
from loguru import logger
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ExternalFunctionRequestHttpMethod
def deduplicate_and_format_sources(
search_responses, max_tokens_per_source, include_raw_content=True
):
"""
検索応答のリストを受け取り、読みやすい文字列にフォーマットします。
raw_contentを約max_tokens_per_sourceに制限します。
Args:
search_responses: 各検索応答を含む辞書のリスト。各辞書には以下が含まれます:
- query: str
- results: 辞書のリスト。各辞書には以下のフィールドが含まれます:
- title: str
- url: str
- content: str
- score: float
- raw_content: str|None
max_tokens_per_source: int
include_raw_content: bool
Returns:
str: 重複を排除したソースを含むフォーマットされた文字列
"""
# すべての結果を収集
sources_list = []
for response in search_responses:
if response:
sources_list.extend(response["results"])
# URLで重複を排除
unique_sources = {source["url"]: source for source in sources_list}
# 出力をフォーマット
formatted_text = "Sources:\n\n"
# トークンあたり約2文字の概算を使用
char_limit = max_tokens_per_source * 2
for i, source in enumerate(unique_sources.values(), 1):
formatted_text += f"Source {source['title']}:\n===\n"
formatted_text += f"URL: {source['url']}\n===\n"
content = source["content"]
# 一定文字数より多い場合、省略する
if len(content) > char_limit:
content = content[:char_limit] + "... [truncated]"
formatted_text += (
f"Most relevant content from source: {content}\n===\n"
)
if include_raw_content:
raw_content = source.get("raw_content")
if raw_content is None:
raw_content = ""
logger.warning(
f"Warning: No raw_content found for source {source['url']}"
)
if len(raw_content) > char_limit:
raw_content = raw_content[:char_limit] + "... [truncated]"
formatted_text += f"Full source content limited to {max_tokens_per_source} tokens: {raw_content}\n\n"
return formatted_text.strip()
def format_sections(sections: list[Section]) -> str:
"""セクションのリストを文字列にフォーマット"""
formatted_str = ""
for idx, section in enumerate(sections, 1):
formatted_str += f"""
{'='*60}
Section {idx}: {section.name}
{'='*60}
Description:
{section.description}
Requires Research:
{section.research}
Content:
{section.content if section.content else '[Not yet written]'}
"""
return formatted_str
@mlflow.trace
def tavily_search(query, include_raw_content=True, max_results=5):
"""Tavily APIを使用してウェブを検索します。
Args:
query (str): 実行する検索クエリ
include_raw_content (bool): フォーマットされた文字列にTavilyからのraw_contentを含めるかどうか
max_results (int): 返す最大結果数
Returns:
dict: 検索応答を含む:
- results (list): 各検索結果辞書を含むリスト:
- title (str): 検索結果のタイトル
- url (str): 検索結果のURL
- content (str): コンテンツのスニペット/要約
- raw_content (str): 利用可能な場合はページのフルコンテンツ"""
response = WorkspaceClient().serving_endpoints.http_request(
conn="tavily_api",
method=ExternalFunctionRequestHttpMethod.POST,
path="search",
json={
"query": query,
"max_results": max_results,
"include_raw_content": include_raw_content,
"topic": "general",
},
headers={"Content-Type": "application/json"},
)
if not response.ok:
return None
return response.json()
def remove_thinking_text(text):
"""<think>タグで囲われたテキストを削除する
Args:
text (str): 処理するテキスト
Returns:
str: 処理結果
"""
while "<think>" in text and "</think>" in text:
start = text.find("<think>")
end = text.find("</think>") + len("</think>")
text = text[:start] + text[end:]
return text
Step5. DeepResearcherエージェントの定義
さて、本番です。
リサーチを行うエージェントの処理をLangGraphのFunctional APIを使って実装します。
割と複雑なグラフとなっており、主な処理を実行するフロー(図の左側)と、セクション内容を作成するサブフロー(図の右側)で構成しています。
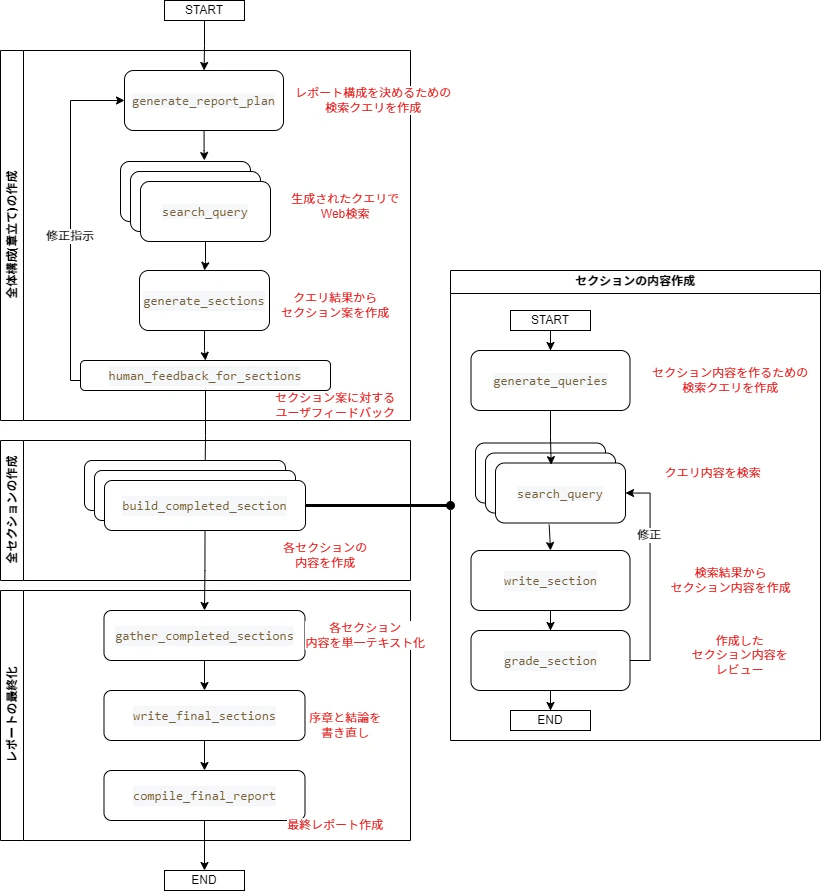
共通設定 -> サブフロー定義 -> メインフロー定義 の順番に作成していきます。
Step5-1. 共通設定
必要なモジュールのインポートや、LLMのエンドポイント名など、共通で利用する変数定義をしておきます。
今回はLLMとしてDatabricksのPay-per-tokens方式で提供されている基盤モデルdatabricks-meta-llama-3-3-70b-instructを利用します。
また、MAX_xxxの変数は、検索時の結果を何件取得するかや、LLMに与えるコンテキストの量・出力量を制御するパラメータです。
変えると結果も変わってきますが、今回は小さめにしています。
from typing import Literal
import json
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.func import entrypoint, task
from langgraph.types import Command, interrupt
from langgraph.checkpoint.memory import MemorySaver
from databricks_langchain import ChatDatabricks
from loguru import logger
writer_model_name = "databricks-meta-llama-3-3-70b-instruct"
planner_model_name = "databricks-meta-llama-3-3-70b-instruct"
MAX_SEARCH_RESULT_FOR_SECTION_GENERATION = 1
MAX_SEARCH_RESULT_FOR_SECTION_COMPLETION = 3
MAX_TOKENS_PER_SOURCE = 400
MAX_WRITTING_TOKENS = 1000
MAX_PLANNING_TOKENS = 1000
from prompts_jp import (
report_planner_query_writer_instructions,
report_planner_instructions,
query_writer_instructions,
section_writer_instructions,
final_section_writer_instructions,
section_grader_instructions,
)
DEFAULT_REPORT_STRUCTURE = """ユーザー提供のトピックに基づいてレポートを作成するためにこの構造を使用してください:
1. はじめに(調査不要)
- トピック領域の簡単な概要
2. 本文セクション:
- 各セクションはユーザー提供のトピックのサブトピックに焦点を当てるべきです
3. 結論
- 本文セクションを要約する1つの構造要素(リストまたは表)を目指す
- レポートの簡潔な要約を提供する"""
Step5-2. サブフロー - セクションの内容作成を行う処理
セクション情報を指定すると、関連情報を検索してセクションの中身を作成する処理をLangGraphのFunctional APIを使って定義します。
フロー図の以下の部分ですね。
build_section_with_web_researchメソッド内で各タスクのフローを記載しています。(余談ですが、LangGraph Functional APIでは各タスクを簡単に並行処理化できて便利です)
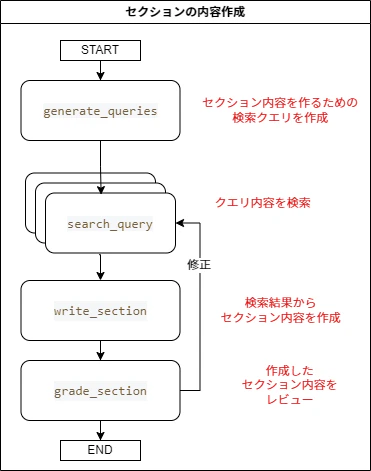
@task
def search_query(query: str, max_results: int = 2) -> dict:
"""TavilyでWeb検索を実行するタスク(ノード)"""
return tavily_search(query, max_results=max_results)
@task
def generate_queries(section: Section, number_of_queries: int = 2) -> list[SearchQuery]:
"""レポートセクションの検索クエリを生成するタスク(ノード)"""
# クエリ生成用のLLM/プロンプトの準備
writer_model = ChatDatabricks(
model=writer_model_name,
temperature=0,
)
structured_llm = writer_model.with_structured_output(Queries)
system_instructions = query_writer_instructions.format(
section_topic=section.description, number_of_queries=number_of_queries
)
# クエリの生成
queries = structured_llm.invoke(
[SystemMessage(content=system_instructions)]
+ [HumanMessage(content="提供されたトピックに関する検索クエリを生成してください。")]
)
return queries.queries
@task
def write_section(section: Section, search_results: list) -> Section:
"""レポートのセクションを書くタスク(ノード)"""
# 検索結果のソースが重複している場合、重複を除去して結果を単一テキストに整形
source_str = deduplicate_and_format_sources(
search_results,
max_tokens_per_source=MAX_TOKENS_PER_SOURCE,
include_raw_content=True,
)
# システムプロンプトを準備
system_instructions = section_writer_instructions.format(
section_title=section.name,
section_topic=section.description,
context=source_str,
section_content=section.content,
)
# セクションを生成
writer_model = ChatDatabricks(
model=writer_model_name,
temperature=0,
max_tokens=MAX_WRITTING_TOKENS,
)
section_content = writer_model.invoke(
[SystemMessage(content=system_instructions)]
+ [HumanMessage(content="提供されたソースに基づいて、800文字以内でレポートセクションを生成してください。")]
)
# セクションにコンテンツを書き込む
section.content = section_content.content
return section
@task
def grade_section(section: Section) -> Feedback:
"""レポートセクションの採点を行うタスク(ノード)"""
# 採点プロンプト
section_grader_instructions_formatted = section_grader_instructions.format(
section_topic=section.description,
section=section.content,
)
# フィードバック
writer_model = ChatDatabricks(model=writer_model_name, temperature=0)
structured_llm = writer_model.with_structured_output(Feedback)
feedback = structured_llm.invoke(
[SystemMessage(content=section_grader_instructions_formatted)]
+ [HumanMessage(content="レポートを評価し、不足している情報に関するフォローアップ質問を検討してください:")]
)
return feedback
@entrypoint()
def build_section_with_web_research(inputs: dict):
section = inputs["section"]
max_loops_for_build_section = inputs.get("max_loops_for_build_section", 2)
# 初期の検索クエリを作成
feedback = Feedback(
grade="fail",
follow_up_queries=generate_queries(section).result(),
)
# 規定回数もしくは十分なグレードになるまで繰り返す
for _ in range(max_loops_for_build_section):
if feedback.grade == "pass":
break
# 必要なWeb検索を行った上で、セクションを作成/グレード付け
search_results = [
search_query(
query.search_query, max_results=MAX_SEARCH_RESULT_FOR_SECTION_COMPLETION
)
for query in feedback.follow_up_queries
]
section = write_section(
section,
search_results=[r.result() for r in search_results],
).result()
feedback = grade_section(section).result()
return section
このサブフローをテスト実行してみます。
config = {"configurable": {"thread_id": "1"}}
section = Section(
name="Databricksとは",
description="Databricks Platformとは何かの概要",
research=True,
content="",
)
result = build_section_with_web_research.invoke({"section": section}, config)
print(f"Name: {result.name}")
print(f"Description: {result.description}")
print(f"Content: {result.content}")
Name: Databricksとは
Description: Databricks Platformとは何かの概要
Content: ## Databricks Platformの概要
**Databricksは、データ分析とAIソリューションを大規模に構築、デプロイ、共有、保守するための統合されたオープンな分析プラットフォームです**。このプラットフォームは、データの統一とカタログ機能、AIデータの統合、セキュリティとガバナンスの強化など、多くの特長を備えています。Databricksは、データウェアハウス、データレイク、データレイクハウスなどのさまざまなデータ管理アーキテクチャをサポートしています。
## 主な機能と利点
- **データの統一とカタログ機能**: データを一元管理し、検索とアクセスを容易にします。
- **AIデータの統合**: 機械学習と生成AIアプリケーションの構築とデプロイメントをサポートします。
- **セキュリティとガバナンスの強化**: データのセキュリティとガバナンスを強化し、コンプライアンスを確保します。
## 導入事例と成功のためのヒント
Databricksは、さまざまな業界で導入されており、データ分析とAIの分野で革新的な成果を上げています。導入事例では、Databricksの各種機能を利用した実践的な移行方法と成功のためのヒントが紹介されています。
### Sources
- Databricksとは?特長やSnowflakeとの違いも解説|MarTechLab(マーテックラボ) : https://martechlab.gaprise.jp/archives/lpolab/databricks/
- Databricksとは | Databricks Documentation : https://docs.databricks.com/aws/ja/introduction
- Databricks Apps : https://www.databricks.com/jp/product/databricks-apps
- 導入事例 - Databricks : https://www.databricks.com/jp/customers
与えたセクション情報を基に、DeepResearchを行った上で中身を作成してくれました。
正直、このフロー単体でもいろいろできそうですが、これをメインフローの中で使っていきます。
Step5-3. メインフロー - レポート作成エージェント
では、本フローです。
下図の流れをLangGraphで実装していきます。
コードはかなり長いのですが、Functional APIを使ってフローを記述した結果、それなりに見通しが良くなっている気がしています。(個人の感想)
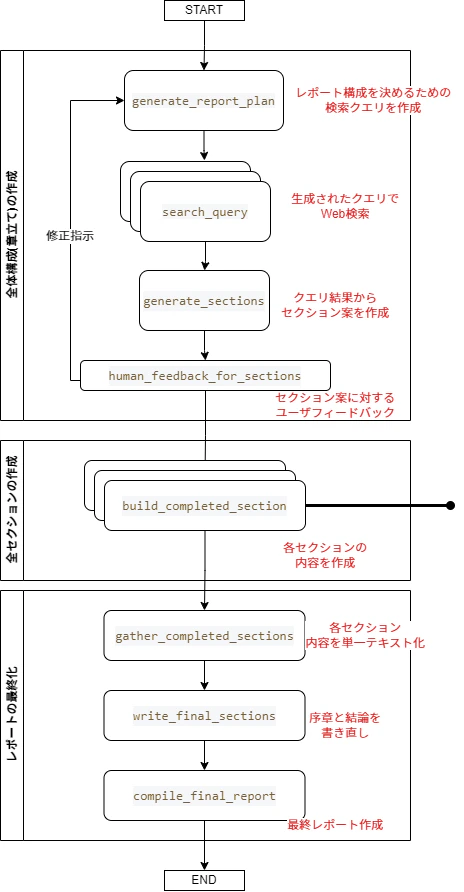
長いので折りたたんでいます。
コード
@task
def generate_report_plan(
topic: str,
feedback_on_report_plan: str = None,
report_structure: str = DEFAULT_REPORT_STRUCTURE,
number_of_queries: int = 2,
) -> List[Section]:
"""レポート計画を生成するタスク(ノード)"""
# 検索クエリを生成
writer_model = ChatDatabricks(model=writer_model_name, temperature=0)
structured_llm = writer_model.with_structured_output(Queries)
# システムプロンプトを準備
system_instructions_query = report_planner_query_writer_instructions.format(
topic=topic,
feedback=feedback_on_report_plan,
report_organization=report_structure,
number_of_queries=number_of_queries,
)
# クエリを生成
results = structured_llm.invoke(
[SystemMessage(content=system_instructions_query)]
+ [HumanMessage(content="レポートのセクションを計画するのに役立つ検索クエリを生成してください。")]
)
# Web検索
query_list = [query.search_query for query in results.queries]
return query_list
@task
def generate_sections(
topic: str,
search_results: List[dict],
feedback_on_report_plan: str = None,
report_structure: str = DEFAULT_REPORT_STRUCTURE,
) -> List[Section]:
"""
検索結果からレポートのセクションを生成するタスク(ノード)
Args:
topic (str): レポートのトピック
search_results (List[dict]): 検索結果のリスト
feedback_on_report_plan (str, optional): レポート計画に関するフィードバック
report_structure (str, optional): レポートの構成
Returns:
List[Section]: 生成されたセクションのリスト
"""
# 検索結果のソースが重複している場合、重複を除去して結果を単一テキストに整形
source_str = deduplicate_and_format_sources(
search_results,
max_tokens_per_source=MAX_TOKENS_PER_SOURCE,
include_raw_content=False,
)
# システムプロンプトの準備
system_instructions_sections = report_planner_instructions.format(
topic=topic,
report_organization=report_structure,
context=source_str,
feedback=feedback_on_report_plan,
)
planner_llm = ChatDatabricks(model=planner_model_name, temperature=0.0, max_tokens=MAX_PLANNING_TOKENS)
# セクションの生成
structured_llm = planner_llm.with_structured_output(Sections)
report_sections = structured_llm.invoke(
[SystemMessage(content=system_instructions_sections)]
+ [
HumanMessage(
content="レポートのセクションを生成してください。応答には、セクションのリストを含む 'sections' フィールドを含める必要があります。各セクションには、name、description、plan、research、および content フィールドが含まれている必要があります。"
)
]
)
sections = report_sections.sections
return sections
@task
def human_feedback_for_sections(
sections: Sections,
) -> (bool, str):
"""レポート計画に関するフィードバックを取得する"""
# セクションを取得
sections_str = "\n\n".join(
f"Section: {section.name}\n"
f"Description: {section.description}\n"
f"Research needed: {'Yes' if section.research else 'No'}\n"
for section in sections
)
# レポート計画に関するフィードバックを取得
feedback = interrupt(
f"次のレポート計画についてフィードバックを提供してください。\n\n{sections_str}\n\n レポート計画はあなたのニーズを満たしていますか? レポート計画を承認するには 'true' を渡すか、レポート計画を再生成するためのフィードバックを提供してください。"
)
# フィードバックが'True'であれば、後続処理を実施。なんらかの文字列が与えられた場合、その内容をレポート構成に加えて再度計画する
if isinstance(feedback, bool):
return True, None
elif isinstance(feedback, str):
return False, feedback
else:
raise TypeError(f"Interrupt value of type {type(feedback)} is not supported.")
@task
def build_completed_section(section: Section):
"""リサーチ結果からセクションを作成するタスク(ノード)"""
return build_section_with_web_research.invoke(
{
"section": section,
"max_loops_for_build_section": 1,
}
)
@task
def gather_completed_sections(completed_sections) -> str:
"""完了したセクションを収集し、最終セクション作成のためのコンテキストとしてフォーマットするタスク(ノード)"""
return format_sections(completed_sections)
@task
def write_final_sections(
section: Section, completed_report_sections: list[str]
) -> list[Section]:
"""レポートの最終セクションを作成するタスク(ノード)。
これらのセクションはウェブ検索を必要とせず、完了したセクションをコンテキストとして使用します
"""
# システムプロンプトを準備
system_instructions = final_section_writer_instructions.format(
section_title=section.name,
section_topic=section.description,
context=completed_report_sections,
)
# セクションを生成
writer_model = ChatDatabricks(
model=writer_model_name,
temperature=0,
max_tokens=MAX_WRITTING_TOKENS,
)
section_content = writer_model.invoke(
[SystemMessage(content=system_instructions)]
+ [HumanMessage(content="提供されたソースに基づいてレポートセクションを生成してください。")]
)
# セクションにコンテンツを書き込む
section.content = section_content.content
# 更新されたセクションを完了セクションに書き込む
return section
@task
def compile_final_report(
sections: list[Section], completed_sections: list[Section]
) -> str:
"""最終レポートを作成するタスク(ノード)"""
completed_sections = {s.name: s.content for s in completed_sections}
# 完了したコンテンツでセクションを更新し、元の順序を維持する
for section in sections:
section.content = completed_sections[section.name]
# 最終レポートをコンパイル
all_sections = "\n\n".join([s.content for s in sections])
return all_sections
@entrypoint(checkpointer=MemorySaver())
def deep_research_agent(inputs: dict):
"""Deep Researchエージェントのエンドポイント"""
feedback_on_report_plan = None
section_completed = False
# 開発を円滑にするためのオプション情報
completed_sections = inputs.get("completed_sections")
sections = inputs.get("sections", completed_sections)
research_topic = inputs.get("research_topic")
if not research_topic:
raise ValueError("research_topic is required")
if not sections:
while not section_completed:
# 検索クエリ生成
queries = generate_report_plan(research_topic, feedback_on_report_plan)
# 並行検索
search_results = [
search_query(
query, max_results=MAX_SEARCH_RESULT_FOR_SECTION_GENERATION
)
for query in queries.result()
]
# 検索結果からのセクション生成
sections = generate_sections(
research_topic,
search_results=[r.result() for r in search_results],
feedback_on_report_plan=feedback_on_report_plan,
).result()
# セクション構成の人間系チェック(Human-in-the-loop)
section_completed, feedback_on_report_plan = human_feedback_for_sections(
sections
).result()
if not completed_sections:
# 各セクションのコンテンツを作成
build_results = [build_completed_section(section) for section in sections]
completed_sections = [s.result() for s in build_results]
# セクションのコンテンツを集めて単一の文字列に変換
report_sections_from_research = gather_completed_sections(
completed_sections,
).result()
# はじめと結論のセクションに対して、レポート全体内容を基に修正したコンテンツを生成
additional_completed_sections = [
write_final_sections(s, report_sections_from_research)
for s in sections
if not s.research
]
completed_sections = completed_sections + [
s.result() for s in additional_completed_sections
]
# 最終レポートを作成
final_report = compile_final_report(sections, completed_sections)
return final_report.result()
長かったですが(コードだらけですみません)、これでDeep Researchを行うエージェントが作成できました。
Step6. 実行してみる
では、さっそく使ってみましょう。
詳細処理を追えるように、MLflow Tracingを有効化します。
import mlflow
mlflow.langchain.autolog()
また、処理実行状況/結果を表示するためのヘルパー関数を定義。
from IPython.display import Markdown
def _print_deep_research_agent_step(agent, inputs, config) -> str:
output_text = ""
for event in agent.stream(inputs, config):
for task_name, result in event.items():
print(task_name)
print("\n")
if task_name in ("__interrupt__"):
output_text = result[0].value
elif task_name in ("deep_research_agent"):
output_text = result
return output_text
では、実行!
お題は「Databricksとは」で行ってみます。
config = {"configurable": {"thread_id": "1"}}
research_topic = "Databricksとは"
inputs = {"research_topic": research_topic}
Markdown(
_print_deep_research_agent_step(
deep_research_agent,
{"research_topic": research_topic},
config,
)
)
次のレポート計画についてフィードバックを提供してください。
Section: はじめに Description: Databricksの概要 Research needed: No
Section: Databricksの特徴 Description: Databricksの機能と特徴 Research needed: Yes
Section: Databricksの用途 Description: Databricksの用途と活用事例 Research needed: Yes
Section: 結論 Description: Databricksのまとめ Research needed: No
レポート計画はあなたのニーズを満たしていますか? レポート計画を承認するには 'true' を渡すか、レポート計画を再生成するためのフィードバックを提供してください。
MLflow Traceログ
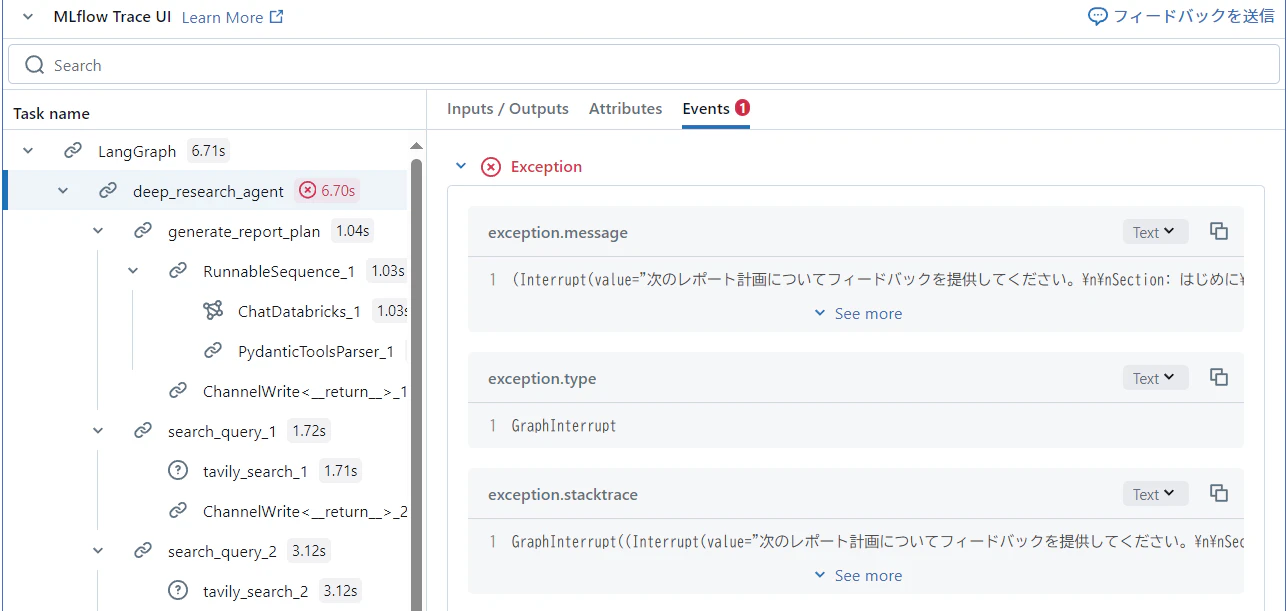
最初に指定されたトピックを基に作成するレポートのセクションをエージェントが作成します。
その後、レポートの構成がこれでよいかどうかをエージェントからユーザへ質問されます。(Human-in-the-Loop)
少し物足りない内容なので、Databricksとよく比較検討されるSnowflakeとの比較を加えてもらうよう指示します。
human_input = Command(resume="Snowflakeとの比較を加えてください")
Markdown(
_print_deep_research_agent_step(
deep_research_agent,
human_input,
config,
)
)
次のレポート計画についてフィードバックを提供してください。
Section: はじめに Description: Databricksの簡単な概要 Research needed: No
Section: Databricksの特徴 Description: Databricksの主な特徴と機能 Research needed: Yes
Section: Snowflakeとの比較 Description: DatabricksとSnowflakeの比較 Research needed: Yes
Section: 結論 Description: レポートの要約 Research needed: No
レポート計画はあなたのニーズを満たしていますか? レポート計画を承認するには 'true' を渡すか、レポート計画を再生成するためのフィードバックを提供してください。
Snowflakeとの比較がセクションに追加されました。
この構成でよさそうなので、レポートを作成してもらいます。
human_input = Command(resume=True)
Markdown(
_print_deep_research_agent_step(
deep_research_agent,
human_input,
config,
)
)
結果は下記の通り。(全文は長いので折り畳んで記載しています)

出力レポート
Databricksの簡単な概要
Databricksは、クラウド上の統合分析プラットフォームです。コンセプトは「データとAIの民主化」であり、データ統合とデータ分析、AI活用をすべて行えます。Databricksでは金融や医療、製造、エンターテイメントなど多様な分野・業種で導入され、店舗需要予測やゲノム解析、品質管理などさまざまな場面で活用されています。
Databricksの主な特徴と機能
Databricksは、データエンジニアリング、データ分析、機械学習を強化する包括的なプラットフォームです。 このプラットフォームは、スケーラビリティ、コラボレーション、ワークフロー効率を向上させる5つの基本的な機能を提供します。Databricksの主な特徴と機能には、次のものがあります。
- コラボレーションノートブック: コードの共同作業と共有を可能にするインタラクティブな環境
- Delta Lake: データの一貫性、スケーラビリティ、高速なクエリを確保する信頼性の高いストレージレイヤー
- マネージドSparkクラスター: データ処理のための自動スケーリングクラスター
- 統合された機械学習: 機械学習モデルのビルド、トラッキング、デプロイを簡素化するツール
Sources
- What is Databricks For? A Guide to Big Data and AI Solutions: https://rtslabs.com/what-is-databricks
- What is Databricks? A Complete Guide to Features, Use Cases, and More: https://www.cloudoptimo.com/blog/what-is-databricks-a-complete-guide-to-features-use-cases-and-more/
- Azure Databricks: https://learn.microsoft.com/en-us/azure/databricks/introduction/
DatabricksとSnowflakeの比較
DatabricksとSnowflakeは、データ分析と機械学習の分野で人気のある2つのプラットフォームです。 両者はクラウドベースのソリューションを提供し、ビッグデータの処理と分析を可能にします。しかし、両者のアーキテクチャと機能には大きな違いがあります。
- DatabricksはApache Sparkをベースに構築されており、データエンジニアリング、データサイエンス、ビジネスアナリティクスを統合したプラットフォームを提供します。
- Snowflakeは、クラウドネイティブのデータウェアハウスソリューションであり、データのストレージ、処理、分析をサポートします。
主な違い
- アーキテクチャ: Databricksはデータレイクハウスアプローチを採用し、Snowflakeは従来のデータウェアハウスアーキテクチャを使用します。
- 機能: Databricksは機械学習とリアルタイム分析に強みを持つ一方、Snowflakeはデータウェアハウスとビジネスインテリジェンスに重点を置いています。
Sources
- Databricks vs. Snowflake (2024): Battle of the Best - Who Wins? - eWeek: https://www.eweek.com/big-data-and-analytics/snowflake-vs-databricks/
- Data Platforms Comparison 2024: Databricks vs. Snowflake: https://ashamaei.medium.com/data-platforms-comparison-2024-databricks-vs-snowflake-4ec5fe9f9623
- Databricks vs. Snowflake: An Honest Comparison in 2024: https://select.dev/posts/snowflake-vs-databricks
レポートの要約
Databricksは、クラウド上の統合分析プラットフォームであり、データ統合、データ分析、AI活用を可能にします。Databricksの主な特徴と機能には、コラボレーションノートブック、Delta Lake、マネージドSparkクラスター、統合された機械学習があります。DatabricksとSnowflakeは、データ分析と機械学習の分野で人気のある2つのプラットフォームですが、アーキテクチャと機能には大きな違いがあります。Databricksはデータレイクハウスアプローチを採用し、Snowflakeは従来のデータウェアハウスアーキテクチャを使用します。
それっぽいレポートができあがりました!
まとめ
Open Deep Researchのリポジトリを基に、車輪の再発明をしてみました。
個人的には、LangGraph Functional APIを使って記述し直すなどはチャレンジでした。
簡易的なものではありますが、Deep Researchを個人でも作れるというのは非常に面白いです。
実行速度の問題(結果を得るにはやはり数分かかる)やLLMの性能(入力コンテキストの制限など)など、考えないといけないことは様々ありますが、個人用にカスタムしたリサーチエージェントを持っておくのは面白いかもしれません。
(その場合、オリジナルリポジトリをそのまま利用したほうが良いと思いますが。。。)
LLMもReasoningモデルに対応するとか、これを基にいろいろ修正を加えてみると面白そうです。
ちなみに、LLMをLlama3.3からGPT-4oに変えて実行もしてみましたが、また違った感じのレポートになりました。パラメータもいろいろ変えて見ると結果が変わったりもするので、いじってみるのも面白いです。
個人的に、Deep ResearchはWeb検索だけでなく社内文書を対象に行える仕組みが欲しかったりします。
Web検索ではなく社内DBを検索するように変更すれば、社内レポートの作成がすぐできる(自動化できる)のではないかと。
・・・というか、Databricks Genieにそういう機能が来そうな気がする。
次のData+AI Summitで発表されるかな。。。予測が当たったら誰か褒めてください。