導入
最近OpenAI社がDeep Researchを発表したり、以前からもGoogle社がDeepResearchをリリースするなど、調査・レポーティング領域での生成AI活用がホットなように思います。
そんな中で、LangChainがOllama Deep Researchというリポジトリを公開しています。
こちらはOllamaでサーブしたローカルLLMを利用できるリサーチエージェント(?)なのですが、こちらを参考にDatabricksの機能を使ったDeepReseacherを作成したいと思います。
上記リポジトリとの変更点は以下になります。
- 処理内で利用するLLMに、Databricksでサーブしているモデルを利用
- シンプル化するために情報検索はTavilyのみに限定(オリジナルはPerplexity APIにも対応)
- TavilyへDatabricksの外部サービス接続を使って接続
- MLflow Tracingに対応
- 実験的にLangGraph Functional APIを使ってワークフローを構築(オリジナルはLangGraph Graph APIを利用)
その他、特にプロンプトについてはオリジナルのものをほぼそのまま利用させていただきました。
開発者の方には深く感謝いたします。
開発はDatabricks on AWS上で実施しました。クラスタはサーバレスです。
Step1. パッケージインストールなど準備
ノートブックを作成し、langgraphなどの必要なパッケージをインストールします。
%pip install -U databricks-sdk
%pip install langgraph databricks-langchain
%pip install mlflow-skinny[databricks]
%restart_python
Step2. プロンプトの準備
エージェントの中で利用するプロンプトを準備します。
こちらはオリジナルリポジトリの内容を利用させていただいています。
以下の3種のプロンプトを定義しています。
- query_writer_instructions: リサーチトピックを基に検索クエリを作成するプロンプト
- summarizer_instructions: 検索結果を基にサマリを作成するプロンプト
- reflection_instructions: 分析サマリを基に知識ギャップを分析しk、追加の検索クエリを立案するプロンプト
query_writer_instructions = """Your goal is to generate a targeted web search query.
The query will gather information related to a specific topic.
<TOPIC>
{research_topic}
</TOPIC>
<FORMAT>
Format your response as a JSON object with ALL three of these exact keys:
- "query": The actual search query string
- "aspect": The specific aspect of the topic being researched
- "rationale": Brief explanation of why this query is relevant
</FORMAT>
<EXAMPLE>
Example output:
{{
"query": "machine learning transformer architecture explained",
"aspect": "technical architecture",
"rationale": "Understanding the fundamental structure of transformer models"
}}
</EXAMPLE>
Provide your response in JSON format:"""
summarizer_instructions = """
<GOAL>
Generate a high-quality summary of the web search results and keep it concise / related to the user topic.
</GOAL>
<REQUIREMENTS>
When creating a NEW summary:
1. Highlight the most relevant information related to the user topic from the search results
2. Ensure a coherent flow of information
When EXTENDING an existing summary:
1. Read the existing summary and new search results carefully.
2. Compare the new information with the existing summary.
3. For each piece of new information:
a. If it's related to existing points, integrate it into the relevant paragraph.
b. If it's entirely new but relevant, add a new paragraph with a smooth transition.
c. If it's not relevant to the user topic, skip it.
4. Ensure all additions are relevant to the user's topic.
5. Verify that your final output differs from the input summary.
< /REQUIREMENTS >
< FORMATTING >
- Start directly with the updated summary, without preamble or titles. Do not use XML tags in the output.
< /FORMATTING >"""
reflection_instructions = """You are an expert research assistant analyzing a summary about {research_topic}.
<GOAL>
1. Identify knowledge gaps or areas that need deeper exploration
2. Generate a follow-up question that would help expand your understanding
3. Focus on technical details, implementation specifics, or emerging trends that weren't fully covered
</GOAL>
<REQUIREMENTS>
Ensure the follow-up question is self-contained and includes necessary context for web search.
</REQUIREMENTS>
<FORMAT>
Format your response as a JSON object with these exact keys:
- knowledge_gap: Describe what information is missing or needs clarification
- follow_up_query: Write a specific question to address this gap
</FORMAT>
<EXAMPLE>
Example output:
{{
"knowledge_gap": "The summary lacks information about performance metrics and benchmarks",
"follow_up_query": "What are typical performance benchmarks and metrics used to evaluate [specific technology]?"
}}
</EXAMPLE>
Provide your analysis in JSON format:"""
Step3. ユーティリティ関数の定義
エージェント処理中に利用するユーティリティ関数を定義します。
主にはTavilyを使った検索や検索結果を整形する関数を定義しています。
なお、Tavily検索については、以前の記事で作成したDatabricksの接続オブジェクトを再利用して実装しました。
Tavilyに対する接続オブジェクトの作成については、手前みそですがこちらを参照ください。
import os
import requests
from typing import Dict, Any
import mlflow
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ExternalFunctionRequestHttpMethod
def deduplicate_and_format_sources(
search_response, max_tokens_per_source, include_raw_content=False
):
"""
検索APIからの単一の検索応答または応答のリストを受け取り、フォーマットします。
raw_contentを約max_tokens_per_sourceに制限します。
include_raw_contentは、フォーマットされた文字列にTavilyからのraw_contentを含めるかどうかを指定します。
Args:
search_response: 次のいずれか:
- 検索結果のリストを含む'results'キーを持つ辞書
- 検索結果を含む辞書のリスト
Returns:
str: 重複を排除したソースを含むフォーマットされた文字列
"""
# 入力を結果のリストに変換
if isinstance(search_response, dict):
sources_list = search_response["results"]
elif isinstance(search_response, list):
sources_list = []
for response in search_response:
if isinstance(response, dict) and "results" in response:
sources_list.extend(response["results"])
else:
sources_list.extend(response)
else:
raise ValueError("入力は'results'を持つ辞書または検索結果のリストでなければなりません")
# URLで重複を排除
unique_sources = {}
for source in sources_list:
if source["url"] not in unique_sources:
unique_sources[source["url"]] = source
# 出力をフォーマット
formatted_text = "ソース:\n\n"
for i, source in enumerate(unique_sources.values(), 1):
formatted_text += f"ソース {source['title']}:\n===\n"
formatted_text += f"URL: {source['url']}\n===\n"
formatted_text += (
f"Most relevant content from source: {source['content']}\n===\n"
)
if include_raw_content:
# トークンあたり約2文字の粗い推定を使用
char_limit = max_tokens_per_source * 2
# Noneのraw_contentを処理
raw_content = source.get("raw_content", "")
if raw_content is None:
raw_content = ""
print(f"警告: ソース {source['url']} に対してraw_contentが見つかりません")
if len(raw_content) > char_limit:
raw_content = raw_content[:char_limit] + "... [truncated]"
formatted_text += f"Full source content limited to {max_tokens_per_source} tokens: {raw_content}\n\n"
return formatted_text.strip()
def format_sources(search_results):
"""検索結果をソースの箇条書きリストにフォーマットします。
Args:
search_results (dict): Tavily検索応答に結果を含む
Returns:
str: ソースとそのURLを含むフォーマットされた文字列
"""
return "\n".join(
f"* {source['title']} : {source['url']}" for source in search_results["results"]
)
@mlflow.trace
def tavily_search(query, include_raw_content=True, max_results=3):
"""Tavily APIを使用してウェブを検索します。
Args:
query (str): 実行する検索クエリ
include_raw_content (bool): フォーマットされた文字列にTavilyからのraw_contentを含めるかどうか
max_results (int): 返す最大結果数
Returns:
dict: 検索応答を含む:
- results (list): 各検索結果辞書を含むリスト:
- title (str): 検索結果のタイトル
- url (str): 検索結果のURL
- content (str): コンテンツのスニペット/要約
- raw_content (str): 利用可能な場合のページのフルコンテンツ"""
result = WorkspaceClient().serving_endpoints.http_request(
conn="tavily_api",
method=ExternalFunctionRequestHttpMethod.POST,
path="search",
json={
"query": query,
"max_results": max_results,
"include_raw_content": include_raw_content,
},
headers={"Content-Type": "application/json"},
)
# TODO: エラーハンドリング
return result.json()
def remove_thinking_text(text):
""" <think>タグで囲われたテキストを削除する
Args:
text (str): 処理するテキスト
Returns:
str: 処理結果
"""
while "<think>" in text and "</think>" in text:
start = text.find("<think>")
end = text.find("</think>") + len("</think>")
text = text[:start] + text[end:]
return text
Step4. DeepResearcherエージェントの定義
ようやく本題。
リサーチを行うエージェントの処理をLangGraphのFunctional APIを使って構成します。
(ワークフローの流れは下図のようになります)

大まかには、最初にリサーチしたいトピックをエージェントに対して指定し、その内容を基にWeb検索クエリを作成&検索、検索結果を基に調査結果をサマリ、さらに深堀する検索を実施・・・というのを繰り返して最終結果をまとめるという流れです。
また、このエージェント内では以下の記事でDatabricks上にサービングしたDeepSeek-R1-Distill-Llama-8Bを利用しました。
せっかくならDeepSeek R1から蒸留した推論モデルを利用したかったので。。。
import json
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.func import entrypoint, task
from langgraph.checkpoint.memory import MemorySaver
from databricks_langchain import ChatDatabricks
generate_model_name = "deepseek_r1_distilled_llama8b_v1"
reasoning_model_name = "deepseek_r1_distilled_llama8b_v1"
max_web_research_loops = 3
max_tokens = 4000
checkpointer = MemorySaver()
@task
def generate_query(research_topic: str):
"""ウェブ検索のためのクエリを生成する"""
# プロンプトをフォーマット
query_writer_instructions_formatted = query_writer_instructions.format(
research_topic=research_topic
)
# クエリを生成
llm_json_mode = ChatDatabricks(
endpoint=generate_model_name,
temperature=0,
max_tokens=max_tokens,
format="json",
)
result = llm_json_mode.invoke(
[
SystemMessage(content=query_writer_instructions_formatted),
HumanMessage(content=f"Generate a query for web search:"),
]
)
# R1 Resoningモデルの場合、出力を調整
result.content = remove_thinking_text(result.content)
query = json.loads(result.content)
return query["query"]
@task
def web_research(search_query: str) -> (list, list):
"""ウェブから情報を収集する"""
# ウェブを検索
search_results = tavily_search(
search_query, include_raw_content=True, max_results=1
)
search_str = deduplicate_and_format_sources(
search_results, max_tokens_per_source=1000, include_raw_content=True
)
return {
"sources_gathered": [format_sources(search_results)],
"web_research_results": [search_str],
}
@task
def summarize_sources(
research_topic: str, web_research_results: str, previous_summary: str
) -> str:
"""収集したソースを要約する"""
# ヒューマンメッセージを構築
if previous_summary:
human_message_content = (
f"<User Input> \n {research_topic} \n <User Input>\n\n"
f"<Existing Summary> \n {previous_summary} \n <Existing Summary>\n\n"
f"<New Search Results> \n {web_research_results} \n <New Search Results>"
)
else:
human_message_content = (
f"<User Input> \n {research_topic} \n <User Input>\n\n"
f"<Search Results> \n {web_research_results} \n <Search Results>"
)
# LLMを実行
llm = ChatDatabricks(
endpoint=reasoning_model_name, temperature=0, max_tokens=max_tokens
)
result = llm.invoke(
[
SystemMessage(content=summarizer_instructions),
HumanMessage(content=human_message_content),
]
)
result.content = remove_thinking_text(result.content)
return result.content
@task
def reflect_on_summary(research_topic: str, running_summary: str):
"""要約を反映し、フォローアップクエリを生成する"""
# クエリを生成
llm_json_mode = ChatDatabricks(
endpoint=generate_model_name,
temperature=0,
max_tokens=max_tokens,
format="json",
)
result = llm_json_mode.invoke(
[
SystemMessage(
content=reflection_instructions.format(research_topic=research_topic)
),
HumanMessage(
content=f"Identify a knowledge gap and generate a follow-up web search query based on our existing knowledge: {running_summary}"
),
]
)
# R1 Resoningモデルの場合、出力を調整
result.content = remove_thinking_text(result.content)
follow_up_query = json.loads(result.content)
# フォローアップクエリを取得
query = follow_up_query.get("follow_up_query")
# JSONモードは場合によっては失敗することがあります
if not query:
# プレースホルダクエリにフォールバック
return f"Tell me more about {research_topic}"
# フォローアップクエリで検索クエリを更新
return follow_up_query["follow_up_query"]
@task
def finalize_summary(running_summary: str, sources_gathered: list):
"""要約を最終化する"""
# 収集したすべてのソースを単一の箇条書きリストにフォーマット
all_sources = "\n".join(source for source in sources_gathered)
running_summary = f"## 要約\n\n{running_summary}\n\n ### ソース:\n{all_sources}"
return running_summary
@entrypoint(checkpointer=checkpointer)
def agent(research_topic: str):
running_summary = None
sources_gathered = []
web_research_results = []
# 検索クエリを生成
search_query = generate_query(research_topic).result()
# ループの最大設定数まで検索と質問生成を繰り返す
for _ in range(max_web_research_loops):
# 検索と結果履歴保存
research_results = web_research(search_query).result()
web_research_results.extend(research_results["web_research_results"])
sources_gathered.extend(research_results["sources_gathered"])
# 結果をサマリ
running_summary = summarize_sources(
research_topic, web_research_results[-1], running_summary
).result()
# サマリ結果を基に深堀クエリ生成
search_query = reflect_on_summary(research_topic, running_summary).result()
# 最終回答生成
running_summary = finalize_summary(running_summary, sources_gathered).result()
return running_summary
これで準備完了です。
※ LangGraph Functional APIの理解がまだ不十分なので、もっと良いやり方があるかもしれませんが。。。参考実装ということで。。。
Step5. 実行する
グラフ作成ができたので、実際に動かしてみます。
まず、MLflowのTracingを有効化します。
(LangGraphのFunctional APIもGraph API同様にAutologgingを有効化することで記録できました)
mlflow.langchain.autolog()
では、トピックを指定して実行します。
config = {"configurable": {"thread_id": "1"}}
result = agent.invoke("Databricksについて", config)
print(result)
実行結果として、以下のような出力を得られました。
## 要約
Databricks is a cloud-based platform designed to unify data engineering, analytics, and machine learning, offering a centralized environment for seamless collaboration among teams. Built on Apache Spark, it simplifies big data processing and enables efficient analysis of large datasets. Key features include Delta Lake for data management and versioning, real-time analytics, and a scalable architecture. Databricks provides tools like SQL Analytics for data analysts and Workspace for collaboration, available on various cloud platforms including Azure, AWS, and Google Cloud. The platform also offers elastic scalability, on-demand autoscaling, and real-time monitoring, streamlining operations in production. APIs and pre-configured environments enable efficient management of the data and ML lifecycle, helping teams deliver value quickly. Databricks provides resources and documentation, along with a free trial, to support users in exploring the platform.
### ソース:
* What is Databricks: A Comprehensive Overview - getondata.com : https://getondata.com/what-is-databricks/
* Elastic Scalability - Databricks : https://www.databricks.com/product/production-ready
* Databricks documentation : https://www.databricks.com/databricks-documentation
日本語に翻訳すると以下のようになります。
要約
Databricksは、データエンジニアリング、分析、機械学習を統合するために設計されたクラウドベースのプラットフォームで、チーム間のシームレスなコラボレーションのための中央集約型環境を提供します。Apache Sparkに基づいており、ビッグデータ処理を簡素化し、大規模データセットの効率的な分析を可能にします。主な機能には、データ管理とバージョン管理のためのDelta Lake、リアルタイム分析、スケーラブルなアーキテクチャが含まれます。Databricksは、データアナリスト向けのSQL AnalyticsやコラボレーションのためのWorkspaceなどのツールを提供し、Azure、AWS、Google Cloudなどのさまざまなクラウドプラットフォームで利用可能です。また、弾力的なスケーラビリティ、オンデマンドのオートスケーリング、リアルタイムモニタリングを提供し、運用を効率化します。APIや事前構成された環境により、データとMLライフサイクルの効率的な管理が可能になり、チームが迅速に価値を提供できるよう支援します。Databricksは、プラットフォームの探索をサポートするためにリソースやドキュメント、無料トライアルを提供しています。
ソース:
- Databricksとは:包括的な概要 - getondata.com : https://getondata.com/what-is-databricks/
- 弾力的スケーラビリティ - Databricks : https://www.databricks.com/product/production-ready
- Databricksドキュメント : https://www.databricks.com/databricks-documentation
正しいっぽい内容ですね。
MLflow Tracingとしても処理の流れが記録されています。
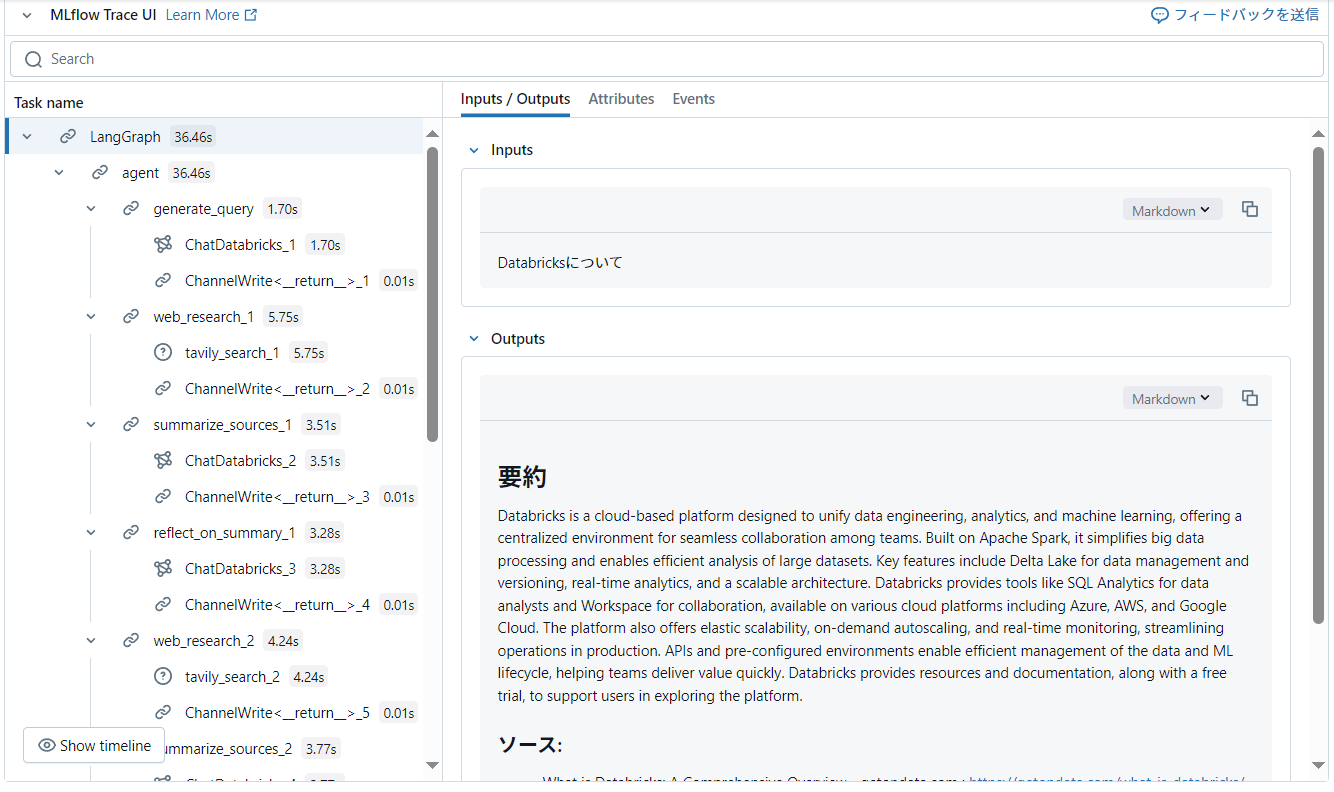
Traceの内容を順に見ていくと、次々と検索クエリ・検索結果を増やしていきながら回答サマリを改定していく流れができていて面白いです。
上記は検索→サマリ→追加検索の流れを3ループ繰り返す設定にしていますが、ループ数を増やすともっと網羅的で正確なリサーチレポートを作れるかもしれません。
サマリフォーマットの定型化やHuman-in-the-Loopによるユーザ意見の反映など、いろいろ改良ができそうです。
また、DeepSeek-R1-Distill-Llama-8BだとJSON出力が安定しなかったので、エラーハンドリングや出力安定化の対応なども必要そうです。
まとめ
Ollama Deep Researcherを基にしたDatabricks版 Deep Researcherを作ってみました。
これをベースにさまざまな改良を加えていくと実用的な自分だけのリサーチエージェントが作れるかもしれません。
また、MLflowのChatAgentとして実装することでDatabricks Mosaic AI Model Serving上にサービングもできそうなので、それも時間があればやってみたいと思います。
こういった具体的な実務利用できそうな内容は作っいて面白いので、もっとやっていきたいなあ。