導入
以下の記事を以前から興味深く読んでいました。
上記記事はClaude Destop+MCPを使ってBigQueryのデータを分析し、最終的にHTML形式のレポート出力まで実施されています。
DatabricksのAI/BI Genieを使うことでも近いことができそうだなーと思いつつ、特にビジネス部門の方が分析するケースを考えるとこの内容は非常に面白いと感じました。
そして、同様のことを行うエージェントはDatabricks単体でも実装できそうだと思ったので、実際にやってみた、という内容になります。
実装&試験はDatabricks on AWS上で実施しました。
ノートブックはサーバレスクラスタで実行しています。
実行結果のみ確認したい方はStep4以降を参照ください。
実装方針
下記で紹介されているDatabricks LabのDatabricks MCPサーバを利用してエージェントを作成します。
2025年5月現在、ベータ版かつSLAの設定もされていませんので利用には注意ください。
上記MCPサーバはDatabricksの下記機能を利用するものになります。
- Unity Catalog Functions
- Vector Search Index
- Genie Space
これらの機能(+LLMの能力)を利用することで自然言語を使ったテーブル操作から資料化までを行います。
また、テーブル操作は上記MCPサーバでは直接行えないため、Genieを通じて行います。
今回は以下記事で作成したダミーの「売上テーブル」を利用するGenie Spaceを再利用しました。
DatabricksのFederation Queryを利用すればBigQueryや他のデータベースのテーブルも利用することができます。便利。
なお、中核となるLLMはDatabricksネイティブのClaude Sonnet 37を利用します。
では、実装してみます。
Step1. 準備
ノートブックを作成し、必要なパッケージをインストール。
%pip install -qq langchain-mcp-adapters langgraph databricks-langchain databricks-agents rich nest-asyncio loguru uv
%pip install -qq mlflow
%restart_python
次に、DatabricksのMCPサーバのリポジトリをgitを使って取得します。
!git clone https://github.com/databrickslabs/mcp.git databricks-mcp
次にDatabricksのModel ServingでAPIサーバをデプロイするために、MLflowのChatAgentインターフェースを備えたエージェントを定義します。
基本的にはこの記事で解説しているものと同様です。(微修正しています)
少し長いですが、コードを全文掲載。
%%writefile databricks_mcp_agent.py
from typing import Literal, Generator, List, Optional, Any, Dict, Mapping, Union
import uuid
import asyncio
import sys
import os
import mlflow
from databricks_langchain import ChatDatabricks
from langgraph.prebuilt import create_react_agent
from langchain_core.messages import AIMessage, BaseMessage, convert_to_openai_messages
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from functools import reduce
from loguru import logger
# Tracingの有効化
mlflow.langchain.autolog()
def filter_messages(messages: list[ChatAgentMessage]):
# tool関連の呼び出しログを省略し、直近の5件のみログとして使用する
return list(filter(lambda x: x.role != "tool" and x.tool_calls is None, messages))[-5:]
class DatabricksMCPChatAgent(ChatAgent):
def __init__(self, model):
self.model = model
self.mcp_connections = None
def load_context(self, context):
databricks_mcp_path = context.artifacts["databricks_mcp"]
databricks_config = context.model_config.get("databricks", {})
catalog = databricks_config.get("catalog", "system")
schema = databricks_config.get("schema", "ai")
genie_ids = databricks_config.get("genie_ids", [])
schema_params = ["-s", f"{catalog}.{schema}"]
genie_params = ["-g", ",".join(genie_ids)] if genie_ids else []
# Databricks MCP Server用設定
self.mcp_connections = {
"databricks": {
"command": "uv",
"args": [
"--directory",
databricks_mcp_path,
"run",
"unitycatalog-mcp",
]
+ schema_params
+ genie_params,
"env": {
"UV_PROJECT_ENVIRONMENT": os.environ.get(
"UV_PROJECT_ENVIRONMENT", ".venv"
),
"DATABRICKS_HOST": os.environ.get("DATABRICKS_HOST"),
"DATABRICKS_TOKEN": os.environ.get("DATABRICKS_TOKEN"),
"DATABRICKS_SQL_WAREHOUSE_ID": os.environ.get(
"DATABRICKS_SQL_WAREHOUSE_ID"
),
"DATABRICKS_RUNTIME_VERSION": os.environ.get(
"DATABRICKS_RUNTIME_VERSION", "client.2.5"
),
},
"transport": "stdio",
},
}
print("loaded contexts.")
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
"""
指定されたチャットメッセージリストを使用して回答を生成する
Args:
messages (list[ChatAgentMessage]): チャットエージェントメッセージのリスト。
context (Optional[ChatContext]): オプションのチャットコンテキスト。
custom_inputs (Optional[dict[str, Any]]): カスタム入力のオプション辞書。
Returns:
ChatAgentResponse: 予測結果を含むChatAgentResponseオブジェクト。
"""
gen_messages = []
usages = []
for c in self.predict_stream(messages, context, custom_inputs):
gen_messages.append(c.delta)
usages.append(c.usage.model_dump(exclude_none=True))
return ChatAgentResponse(messages=gen_messages, usage=self._sum_usages(usages))
def predict_stream(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> Generator[ChatAgentChunk, None, None]:
"""
指定されたチャットメッセージリストを使用して、非同期的にエージェントを呼び出し、結果を取得します。
Args:
messages (list[ChatAgentMessage]): チャットエージェントメッセージのリスト。
context (Optional[ChatContext]): オプションのチャットコンテキスト。
custom_inputs (Optional[dict[str, Any]]): カスタム入力のオプション辞書。
Returns:
ChatAgentResponse: 予測結果を含むChatAgentResponseオブジェクト。
"""
if self.mcp_connections is None:
return ChatAgentChunk(
delta=self._convert_lc_message_to_chat_message(
AIMessage(content="No response. Please load context.")
),
)
async def stream_with_mcp_tools(model, server_params, messages: list):
"""MCP Serverと通信して回答を取得する"""
async with stdio_client(server_params, errlog=None) as (read, write):
async with ClientSession(read, write) as session:
# 接続を初期化
await session.initialize()
# ツールを取得
tools = await load_mcp_tools(session)
logger.debug(f"tools: {tools}")
# エージェントを作成して実行
agent = create_react_agent(model, tools)
async for mode, event in agent.astream(
{"messages": messages}, stream_mode=["updates", "values"]
):
logger.debug(f"{mode}:{event}")
if mode == "updates":
for v in event.values():
messages = v.get("messages", [])
for msg in messages:
yield ChatAgentChunk(
delta=self._convert_lc_message_to_chat_message(msg),
usage=msg.response_metadata.get("usage", {}),
)
# close session
await session.__aexit__()
messages = filter_messages(messages)
server_params = StdioServerParameters(
command=self.mcp_connections["databricks"]["command"],
args=self.mcp_connections["databricks"]["args"],
env=self.mcp_connections["databricks"]["env"],
)
streamer = stream_with_mcp_tools(
self.model,
server_params,
self._convert_messages_to_dict(messages),
)
loop = asyncio.get_event_loop()
while True:
try:
yield loop.run_until_complete(streamer.__anext__())
except StopAsyncIteration:
break
except RuntimeError as e:
# for "Attempted to exit cancel scope in a different task than it was entered in" Exception.
# 暫定対応
break
def _convert_lc_message_to_chat_message(
self, lc_message: BaseMessage
) -> ChatAgentMessage:
"""LangChainメッセージをChatAgentMessageに変換する。"""
msg = convert_to_openai_messages(lc_message)
if not "id" in msg:
msg.update({"id": str(uuid.uuid4())})
return ChatAgentMessage(**msg)
def _sum_usages(self, usages: list[dict]) -> dict:
"""使用量のリストから使用量を合計する。"""
def add_usages(a: dict, b: dict) -> dict:
pt = "prompt_tokens"
ct = "completion_tokens"
tt = "total_tokens"
return {
pt: a.get(pt, 0) + b.get(pt, 0),
ct: a.get(ct, 0) + b.get(ct, 0),
tt: a.get(tt, 0) + b.get(tt, 0),
}
return reduce(add_usages, usages)
def _convert_lc_message_to_chat_message(
self, lc_message: BaseMessage
) -> ChatAgentMessage:
"""LangChainメッセージをChatAgentMessageに変換する。"""
msg = convert_to_openai_messages(lc_message)
if not "id" in msg:
msg.update({"id": str(uuid.uuid4())})
return ChatAgentMessage(**msg)
def _sum_usages(self, usages: list[dict]) -> dict:
"""使用量のリストから使用量を合計する。"""
def add_usages(a: dict, b: dict) -> dict:
pt = "prompt_tokens"
ct = "completion_tokens"
tt = "total_tokens"
return {
pt: a.get(pt, 0) + b.get(pt, 0),
ct: a.get(ct, 0) + b.get(ct, 0),
tt: a.get(tt, 0) + b.get(tt, 0),
}
return reduce(add_usages, usages, {})
# DatabricksネイティブのClaude 3.7 SonnetをLLMとして利用
LLM_ENDPOINT_NAME = "databricks-claude-3-7-sonnet"
llm = ChatDatabricks(model=LLM_ENDPOINT_NAME)
# エージェントを作成
AGENT = DatabricksMCPChatAgent(model=llm)
mlflow.models.set_model(AGENT)
これでエージェントの定義が完了しました。
Step2. エージェントのロギング
定義したエージェントをMLflowに保管します。
一度、セッションをリスタート。
%restart_python
その上で、nest_asyncioパッケージを使ってノートブック内でもasync_ioを利用できるようにします。
import nest_asyncio
nest_asyncio.apply()
MLflowのlog_modelを呼び出して、定義したエージェントを保管します。
環境変数の中身やGenie SpaceのIDを指定するところがありますので、環境に合わせて変更ください。
import mlflow
from powerpoint_mcp_agent import LLM_ENDPOINT_NAME
from mlflow.models.resources import DatabricksServingEndpoint
import os
os.environ["UV_PROJECT_ENVIRONMENT"] = os.environ["VIRTUAL_ENV"]
os.environ["DATABRICKS_HOST"] = "DatabricksのAPIホスト。secretsを使って指定することをお薦めします"
os.environ["DATABRICKS_TOKEN"] = "DatabricksのAPIトークン。secretsを使って指定することをお薦めします"
os.environ["DATABRICKS_SQL_WAREHOUSE_ID"] = "Databricks SQAウェアハウスのID"
# Claude 3.7を利用するためのリソース設定
resources = [DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME)]
input_example = {
"messages": [
{
"role": "user",
"content": "今何時?",
}
]
}
artifacts = {
"databricks_mcp": "databricks-mcp",
}
model_config = {
"databricks":{
"catalog":"system",
"schema":"ai",
"genie_ids":["利用するGenie SpaceのID"]
}
}
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path ="databricks_mcp_agent", # for mlflow 2.0
artifacts=artifacts,
model_config=model_config,
python_model="databricks_mcp_agent.py",
input_example=input_example,
pip_requirements=[
"mlflow",
"langgraph==0.4.1",
"langchain-mcp-adapters==0.0.10",
"databricks-langchain==0.4.2",
"uv==0.7.2",
"loguru",
],
resources=resources,
)
Step3. エージェントのデプロイ
保管したエージェントを、Databricks Mosaic AI Agent Frameworkを使ってエンドポイントにデプロイします。
まずはUnity Catalog上にエージェントを登録。
mlflow.set_registry_uri("databricks-uc")
catalog = "training" # エージェント登録先の任意のカタログを指定
schema = "llm" # エージェント登録先の任意のスキーマを指定
model_name = "databricks_mcp_agent"
UC_MODEL_NAME = f"{catalog}.{schema}.{model_name}"
# モデルをUCに登録する
model_uri = logged_agent_info.model_uri
uc_registered_model_info = mlflow.register_model(
model_uri=model_uri, name=UC_MODEL_NAME
)
Agent Frameworkを使って、Unity Catalog上に登録したエージェントをAPIエンドポイントとしてデプロイします。
環境変数の指定が非常に重要なので適切に指定ください。
from databricks import agents
agents.deploy(
UC_MODEL_NAME,
uc_registered_model_info.version,
scale_to_zero=True,
environment_vars={
"DATABRICKS_HOST": "{{secrets/xxxx/xxxxx}}", # DatabricksのAPIホストを示すsecrets文字列の設定
"DATABRICKS_TOKEN": "{{secrets/xxxx/xxxxxxxxxxx}}", # DatabricksのAPIキーを示すsecrets文字列の設定
"DATABRICKS_SQL_WAREHOUSE_ID": "Databricks SQAウェアハウスのID",
"UV_PROJECT_ENVIRONMENT": ".venv",
"DATABRICKS_RUNTIME_VERSION": "client.2.5",
},
)
エラーが起きなければ、数分程度でデプロイが完了します。
今回は以下のような名前のエンドポイントが作成されました。

Step4. エージェントを使ってデータベースの対話と資料化を実施する
それではDatabricksのPlaygroundを使ってエージェントを利用し、分析と資料化を行ってみましょう。

今回は以下のシナリオで試用します。
- 日本語の対話で売上情報を簡易分析
- 分析結果をグラフも加えてHTML形式で資料化
1 - 売上分析する
まずは2024年の月別売上を確認してみましょう。

実行すると、Databricks MCPサーバがGenie Spaceに適したものが無いかを探しに行きます。

適切なものが見つかり、適切なクエリを生成・実行まで進みます。

最終的に以下のような結果が得られました。

続けて、四半期ごとの集計も指示します。

今回は処理過程で集計表記を変更するためのPythonコード生成・実行も行われていました。

こちらも最終的には以下のような結果が得られています。
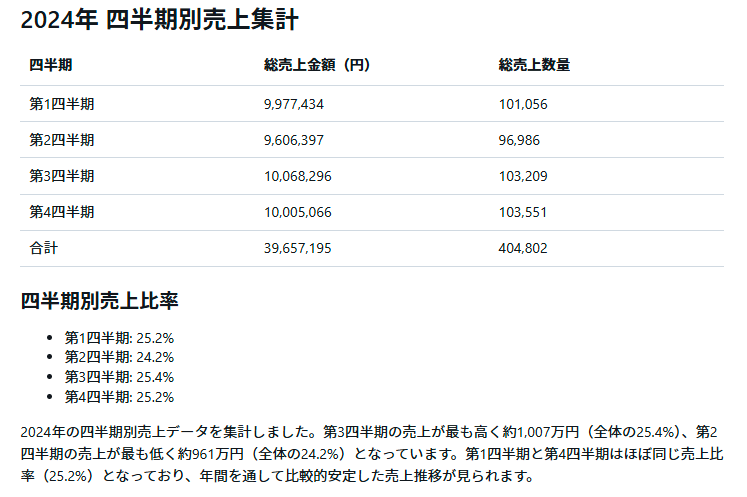
簡単ですが、売上情報の集計・分析がエージェントとの対話で完結しました。
2 - レポートを作成する
これまでの対話結果を用いてレポートを作成します。
個々のグラフ作成を細やかに行おうかとも思ったのですが、ざっくり作成させてみます。

すると、以下のようにHTMLコードを出力してくれました。
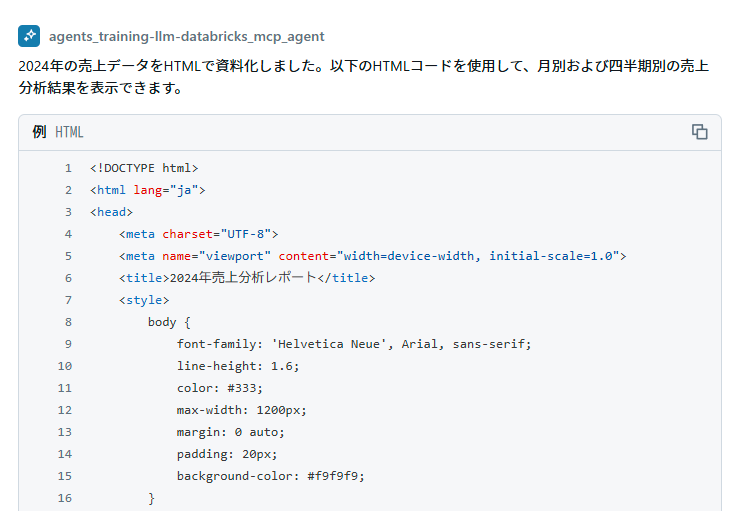
HTML全文も載せておきます。
HTML出力結果
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>2024年売上分析レポート</title>
<style>
body {
font-family: 'Helvetica Neue', Arial, sans-serif;
line-height: 1.6;
color: #333;
max-width: 1200px;
margin: 0 auto;
padding: 20px;
background-color: #f9f9f9;
}
.container {
background-color: white;
padding: 30px;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
}
h1 {
color: #2c3e50;
text-align: center;
margin-bottom: 30px;
border-bottom: 2px solid #3498db;
padding-bottom: 10px;
}
h2 {
color: #2980b9;
margin-top: 30px;
border-left: 5px solid #3498db;
padding-left: 15px;
}
table {
width: 100%;
border-collapse: collapse;
margin: 20px 0;
}
th, td {
padding: 12px 15px;
text-align: right;
border-bottom: 1px solid #ddd;
}
th {
background-color: #f2f2f2;
font-weight: bold;
text-align: center;
}
tr:hover {
background-color: #f5f5f5;
}
.chart-container {
margin: 30px 0;
height: 400px;
}
.summary {
background-color: #f8f9fa;
padding: 20px;
border-radius: 5px;
margin: 30px 0;
border-left: 5px solid #3498db;
}
.highlight {
color: #e74c3c;
font-weight: bold;
}
.footer {
text-align: center;
margin-top: 40px;
font-size: 0.9em;
color: #7f8c8d;
}
</style>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
</head>
<body>
<div class="container">
<h1>2024年売上分析レポート</h1>
<div class="summary">
<p>2024年の総売上は <span class="highlight">39,657,195円</span>、総販売数量は <span class="highlight">404,802個</span> でした。
第3四半期の売上が最も高く、第2四半期が最も低い結果となりました。年間を通して比較的安定した売上推移が見られます。</p>
</div>
<h2>月別売上集計</h2>
<div class="chart-container">
<canvas id="monthlyChart"></canvas>
</div>
<table>
<thead>
<tr>
<th>月</th>
<th>売上金額(円)</th>
</tr>
</thead>
<tbody>
<tr><td>1月</td><td>3,552,754</td></tr>
<tr><td>2月</td><td>2,865,604</td></tr>
<tr><td>3月</td><td>3,559,077</td></tr>
<tr><td>4月</td><td>3,365,489</td></tr>
<tr><td>5月</td><td>3,130,658</td></tr>
<tr><td>6月</td><td>3,110,251</td></tr>
<tr><td>7月</td><td>3,373,186</td></tr>
<tr><td>8月</td><td>3,366,064</td></tr>
<tr><td>9月</td><td>3,329,046</td></tr>
<tr><td>10月</td><td>3,358,921</td></tr>
<tr><td>11月</td><td>3,363,628</td></tr>
<tr><td>12月</td><td>3,282,518</td></tr>
</tbody>
</table>
<h2>四半期別売上集計</h2>
<div class="chart-container">
<canvas id="quarterlyChart"></canvas>
</div>
<table>
<thead>
<tr>
<th>四半期</th>
<th>総売上金額(円)</th>
<th>総売上数量</th>
<th>売上比率</th>
</tr>
</thead>
<tbody>
<tr><td>第1四半期</td><td>9,977,434</td><td>101,056</td><td>25.2%</td></tr>
<tr><td>第2四半期</td><td>9,606,397</td><td>96,986</td><td>24.2%</td></tr>
<tr><td>第3四半期</td><td>10,068,296</td><td>103,209</td><td>25.4%</td></tr>
<tr><td>第4四半期</td><td>10,005,066</td><td>103,551</td><td>25.2%</td></tr>
<tr><td><strong>合計</strong></td><td><strong>39,657,195</strong></td><td><strong>404,802</strong></td><td><strong>100.0%</strong></td></tr>
</tbody>
</table>
<h2>分析結果</h2>
<ul>
<li>3月の売上が最も高く約356万円、2月の売上が最も低く約287万円となっています。</li>
<li>第3四半期の売上が最も高く約1,007万円(全体の25.4%)、第2四半期の売上が最も低く約961万円(全体の24.2%)となっています。</li>
<li>第1四半期と第4四半期はほぼ同じ売上比率(25.2%)となっており、年間を通して比較的安定した売上推移が見られます。</li>
<li>2月は他の月と比較して売上が約20%低くなっています。この要因の分析と対策が必要かもしれません。</li>
</ul>
<div class="footer">
<p>© 2024 売上分析レポート | 作成日: 2024年12月15日</p>
</div>
</div>
<script>
// 月別売上グラフ
const monthlyCtx = document.getElementById('monthlyChart').getContext('2d');
const monthlyChart = new Chart(monthlyCtx, {
type: 'bar',
data: {
labels: ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月'],
datasets: [{
label: '月別売上(円)',
data: [3552754, 2865604, 3559077, 3365489, 3130658, 3110251, 3373186, 3366064, 3329046, 3358921, 3363628, 3282518],
backgroundColor: 'rgba(54, 162, 235, 0.5)',
borderColor: 'rgba(54, 162, 235, 1)',
borderWidth: 1
}]
},
options: {
responsive: true,
maintainAspectRatio: false,
scales: {
y: {
beginAtZero: true,
title: {
display: true,
text: '売上金額(円)'
}
}
}
}
});
// 四半期別売上グラフ
const quarterlyCtx = document.getElementById('quarterlyChart').getContext('2d');
const quarterlyChart = new Chart(quarterlyCtx, {
type: 'bar',
data: {
labels: ['第1四半期', '第2四半期', '第3四半期', '第4四半期'],
datasets: [{
label: '四半期別売上(円)',
data: [9977434, 9606397, 10068296, 10005066],
backgroundColor: 'rgba(255, 159, 64, 0.5)',
borderColor: 'rgba(255, 159, 64, 1)',
borderWidth: 1
}]
},
options: {
responsive: true,
maintainAspectRatio: false,
scales: {
y: {
beginAtZero: true,
title: {
display: true,
text: '売上金額(円)'
}
}
}
}
});
</script>
</body>
</html>
このHTMLをコピーしhtml形式のファイルとして保存すると、以下のようなレポートになっていることが確認できます。(画像として表示していない下部に4半期推移のグラフ・表や分析結果も記載されています)

グラフはChart.jsを利用して描画されており、インタラクティブ性もあります。
非常にざっくりした指示でしたが、自動的にここまでのレポートを作成してくれるのは凄いですね。
Claude Sonnet 3.7の能力の高さがわかります。
レイアウトやグラフ表現の訂正も対話的に指示すれば制御できると思いますが、社内報告用レポートなどはこのレベルでも十分かもしれません。
おまけ
実はAI/BI Genie単体でもうまく指示するとjavascriptなどのコードを出力してくれます。
(以前はText2SQLに特化していたと思うのですが、多少柔軟に対応してくれるようになっているようです)
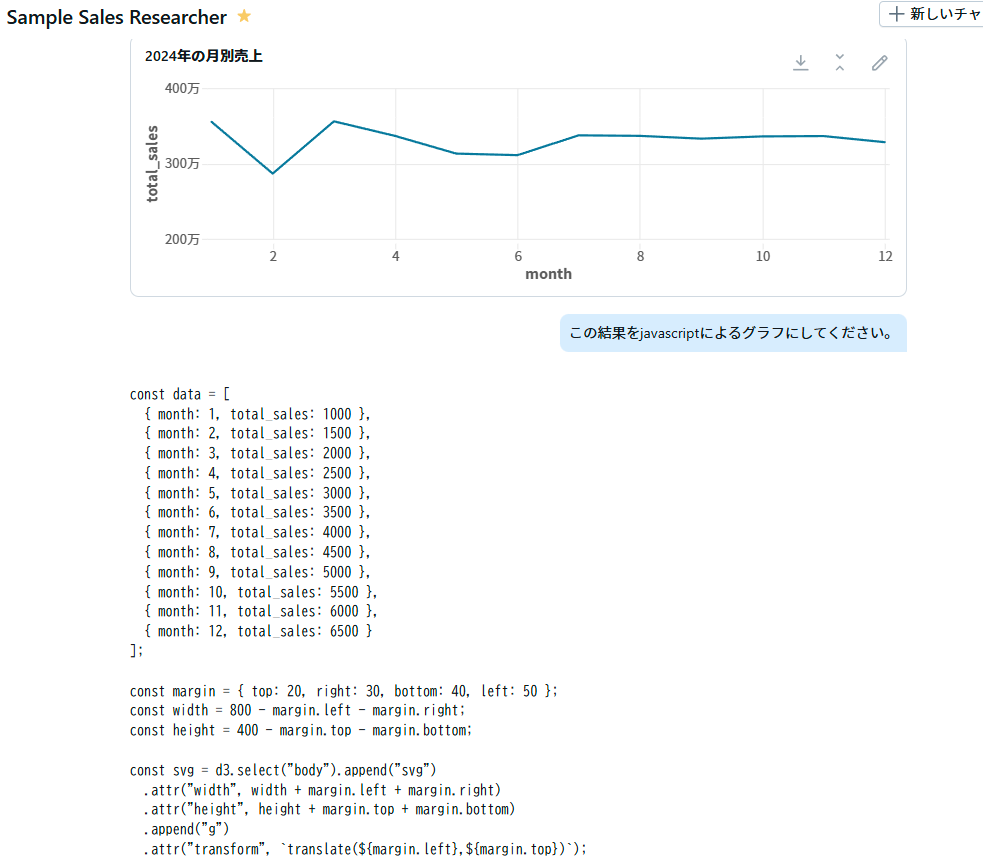
ただ、裏側のLLMの性能問題なのか、なかなか正しいコードは出力してくれません。
(上記の例だと各月の数字が間違っている)
本来的な使い方ではないと思うので、HTML資料出力などは本記事のように適切な別のLLMに実行させる方がよいと思います。
おわりに
Databricksでデータベースと対話するエージェントを作成し、Playground上でHTML資料の作成まで実行させてみました。
改善点として、グラフ化・HTML化はLLMにそのまま実行してもらいましたが、専用のツールを準備した方がよりよいものになると思います。
現状、Databricks Playgroundでは画像表示やHTMLの埋め込み表示ができない(たぶん)ため、利便性で言えばClaude Desktopを使う方が良さそうです。
とはいえ適切なエージェントをDatabricksにデプロイしておくことでPlayground単体でもそのまま業務等に利用できるものができそうだと思いました。
最後に純粋な感想ですが、こういったことが容易にできるようになればなるほど、そもそものデータ整備の重要性を強く感じます。組織のデータをこういった仕組で利用できるように保持できているかがやはり重要であり、データエンジニアリングの世界は益々発展しそうだなと感じています。(私の本業に対するバイアスが強くかかっています)
データ整備の面でも、こういったLLM/生成AI活用をもっと進められればと強く思っています。