0.概要
①昨今市中には文字認識(OCR)サービスが多くあるが、Azureベースのシステムへの組み込みも意識して、今回はAzure単体で、レシートから出費をどのように集計できるか試す。
②集計の際に出費の分類を入力することが手間であるため、Azure OpenAIで自動的に推測させる。
第2回では、Document Intelligenceの事前構築済みモデル(レシートモデル)を特に重点的に取り扱う。公式の事前構築モデルのサンプルコードは請求書モデルしかないため(想定)、様々なドキュメントや応答データを確認しながらソースコードを組み立てていく。
今回は最終的に、レシート画像33枚から、自動的にデータをDBに蓄積して、集計結果のExcelファイルを出力する。
なお今回は記事が長いため、3回程度に分けて投稿する。
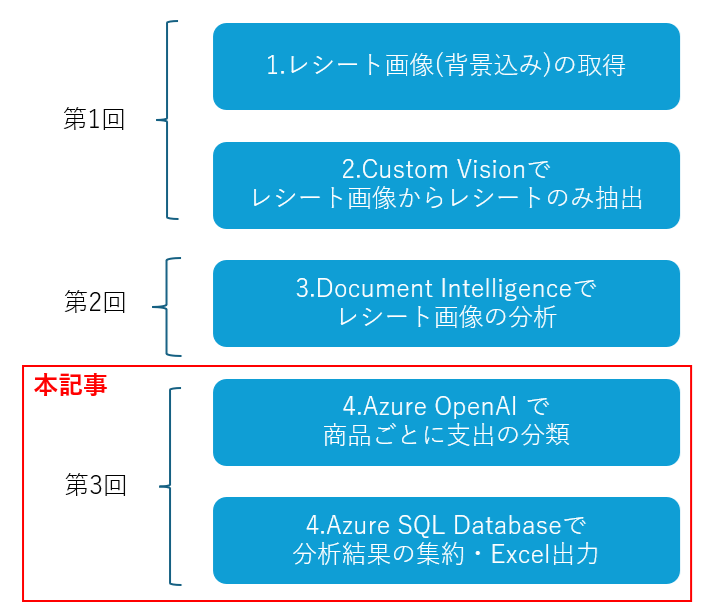
5.AzureOpenAIでの出費の分類
レシートを集計するときに、品目ごとに出費の種類(食費、遊行費など)を記載したいが、手動だと手間がかかるため、4章で抽出した店名と商品名からAzureOpenAIで自動的に入力させてみる。
5.1.Azure OpenAIリソースのデプロイ
昨年と比較してAzure OpenAIのGUI回りが変更されたため、改めて記載する。
①Azure OpenAIのリソースをデプロイする。

②リソース画面の[開始する]タブより[Azure OpenAI Metrics Dashboard]を選択して「Azure AI Foundry」を開く。

③「Azure AI Foundry」の左タブより[デプロイ]-[モデルのデプロイ]-[gpt-4o]を選択し[確認]を選択する。
※現状o1は申請しないと使えないため、今回はgpt-4oとする。

④デプロイ名は後ほどPythonプログラムで使用するため控えておく

⑤後ほど使用するため、ホーム画面より「APIキー」と「Azure OpenAIエンドポイント」を控えておく。

⑥Pythonコードを以下の通り作成する。④⑤で控えた値は以下の通り定義する。
- ④で控えた「モデル名」をmodelへ代入
- ⑤で控えた「APIキー」をapi_keyへ代入
- ⑤で控えた「Azure OpenAIエンドポイント」をazure_endpointへ代入
※参考:Microsoft公式「Python を使用して OpenAI エンドポイントと Azure OpenAI エンドポイントを切り替える方法」
https://learn.microsoft.com/ja-jp/azure/ai-services/openai/how-to/switching-endpoints
# 店名と商品名から商品ジャンルを推測する関数
def predict_genre_of_item(store_name, item_name, system_prompt_path="config\\system_prompt.txt", user_prompt_path="config\\user_prompt.txt"):
# AzureOpenAIクライアントの作成
client = AzureOpenAI(
api_key=config_ini["Azure Open AI"]["AOAI_OCR_RECEIPT_KEY"],
api_version="2024-07-01-preview",
azure_endpoint=config_ini["Azure Open AI"]["AOAI_OCR_RECEIPT_ENDPOINT"]
)
# プロンプトのテキストファイルを読み込み、店舗と商品の情報を追記
system_prompt_sentence = open(system_prompt_path, 'r', encoding='utf-8').read()
user_prompt_sentence = open(user_prompt_path, 'r', encoding='utf-8').read()
user_prompt_sentence += f"""
### 店舗名
{store_name}
### 商品名
{item_name}
"""
# AzureOpenAiに問い合わせ
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt_sentence},
{"role": "user", "content": [
{"type": "text", "text": user_prompt_sentence }
]}
]
)
# 回答からgenreタグの中身を抽出して戻り値とする
result = response.choices[0].message.content
genre = re.search(r'<genre>(.*?)</genre>', result)
return genre.group(1)
このプログラムでは、「config\user_prompt.txt」で定義したプロンプトに、店名と商品名をつなげて、プロンプトとしてgptモデルへ送信する。
なお、今回のプロンプトは以下の通りとし、プロンプトで与えられた選択肢から適切なものをタグ内に記載して返答することを強要する。Pythonコードは応答を受け取るとタグ内の文字を抽出し、戻り値として返答する。
### 指示
以下の「### 店舗名」「### 商品名」に従い、商品のジャンルを推測して答えてください。
「店舗名」は商品を購入した店舗、「商品名」は店舗で購入した商品の名前です。
ジャンルは「食費」、「生活費」、「遊行費」としてください。
-「食費」は食品類とします。
-「生活費」は食費以外で生活に必要なものとします。
-「遊行費」は生活に必要がないものとします。
### 回答
回答は「### 回答フォーマット」に従い<genre></genre>タグにジャンルのみを回答し、それ以外のことは書かないでください。
### 回答フォーマット
<genre></genre>
----以下はプログラムで結合----
### 店舗名
{store_name}
### 商品名
{item_name}
⑦推論の結果店名と商品ごとに、以下の画像のように推論された。今回は「食費」、「生活費」、「遊行費」の3択であるが、「ウコンの力」が遊行費で、「ヘパリーゼ」が生活費であったりと、改善の余地がある。
今回は割愛するが、推論の根拠を説明させることで、間違いの原因を確認して改善できることが期待できる。

※店名は割愛
6.推論結果のDB格納
今回はAzure SQL Databaseサーバのリソースを使用する。
6.1.リソースのデプロイ
今回は最小限の構成でデプロイする。



6.2.テーブルの定義
テーブルは以下の通り作成する。Document Intelligenceが推論誤りをする場合を考慮し、原則NULL許容とする。
またレシートテーブルの主キーは自動採番とした。
- レシートテーブル(receipt)

- 商品テーブル(item)

6.3.DB格納プログラムの作成
①日付データと時刻データはレシートごとに様々な形式で表記されているため以下のコードで変換する。
それぞれの関数内のリストと、変換対象の文字列が一致した場合のみ変換処理を実行する。
# レシートから読み取った日付型をSQLServerの日付型に変換する関数
def date_to_sqldate(captured_date):
# 変換前のフォーマットの候補
date_formats = [
"%Y/%m/%d", # 2025/01/03
"%Y年%m月%d日", # 2025年01月03日
"%Y-%m-%d" # 2024-02-03
]
# 候補の形式で日付の解析に成功した場合SQLServerのDATE型に対応する"YYYY-MM-DD"フォーマットに変換
for format in date_formats:
try:
parsed_dt = datetime.strptime(captured_date, format)
return parsed_dt.strftime("%Y-%m-%d")
except ValueError:
pass
# どのフォーマットでも解析できなかった場合はNULLを返す
return "NULL"
# レシートから読み取った時間をSQLServerのTIME(7)型に直す関数
def time_to_sqltime(captured_time):
# 変換前のフォーマットの候補
time_formats = [
"%H:%M", # 例) "14:05"
"%H:%M:%S", # 例) "14:05:59"
"%H時%M分", # 例) "14時05分"
"%H時%M分%S秒" # 例) "14時05分59秒"
]
# 候補の形式で解析に成功した場合はSQLServerのTIME(7)へ変換する
for format in time_formats:
try:
parsed_time = datetime.strptime(captured_time, format).time()
return f"{parsed_time:%H:%M:%S}.{parsed_time.microsecond:06d}0"
except ValueError:
pass
# どのフォーマットでも解析できなかった場合はNULLを返す
return "NULL"
②DBを更新するための接続文字列を以下の通り作成する
#Azure SQL Satabaseへの接続
server = config_ini["Azure SQL"]["server"]
database = config_ini["Azure SQL"]["database"]
username = config_ini["Azure SQL"]["username"]
password = config_ini["Azure SQL"]["password"]
driver= config_ini["Azure SQL"]["driver"]
with pyodbc.connect('DRIVER='+driver+';SERVER=tcp:'+server+';PORT=1433;DATABASE='+database+';UID='+username+';PWD='+ password, autocommit=False) as conn:
with conn.cursor() as cursor:
接続に必要なそれぞれの値は、リソース画面の[データベースの接続文字列の表示]から表示する

今回はレシート1枚につき、2テーブルを同時に更新するため、「autocommit=False」を指定し、全ての処理が成功した場合のみコミットする。
③レシートから抽出した文字をDBに格納するプログラムの全量は以下の通り。
※クエリ文字列のNULLの取り扱いが冗長になっているため、改善の余地がある。
※Document Intelligenceの応答から値を取得する部分の説明は4.3.1章で記載したため、割愛する。
def store_record_to_db(receipts, receipt_filename, log_directory = "log\\sql", log_filename = "sqllog.txt"):
# ドキュメントの読み取り
if receipts.documents:
for idx, receipt in enumerate(receipts.documents):
# 取引日の取得
transaction_date = receipt.fields.get("TransactionDate")
if transaction_date:
# 正しい形式で格納されているため、valueDateの属性があれば優先して使う。無ければcontentを使う
if "valueDate" in transaction_date:
transaction_date_value = transaction_date["valueDate"]
print("ValueDate")
else:
transaction_date_value = transaction_date["content"]
print("ContentDate")
# SQL Server型の日付型へ変換
transaction_date_value = date_to_sqldate(transaction_date_value)
else:
transaction_date_value = "NULL"
# 取引時間の取得
transaction_time = receipt.fields.get("TransactionTime")
if transaction_time:
transaction_time_value = transaction_time["content"]
# SQL Server型のTIME(7)型へ変換
transaction_time_value = time_to_sqltime(transaction_time_value)
else:
transaction_time_value = "NULL"
# 小計の取得
subtotal = receipt.fields.get("Subtotal")
if subtotal:
subtotal_amount = subtotal["valueCurrency"]["amount"]
else:
subtotal_amount = "NULL"
# 税金の取得
total_tax = receipt.fields.get("TotalTax")
if total_tax:
total_tax_amount = total_tax["valueCurrency"]["amount"]
else:
total_tax_amount = "NULL"
# 合計金額の取得
total = receipt.fields.get("Total")
if total:
total_amount = total["valueCurrency"]["amount"]
else:
total_amount = "NULL"
# 店名の取得(正常の場合はSQL内で文字列で扱うためシングルクオートを追加)
marchan_name = receipt.fields.get("MerchantName")
if marchan_name:
marchan_name_content = marchan_name["content"]
else:
marchan_name_content = "NULL"
#Azure SQL Satabaseへの接続
server = config_ini["Azure SQL"]["server"]
database = config_ini["Azure SQL"]["database"]
username = config_ini["Azure SQL"]["username"]
password = config_ini["Azure SQL"]["password"]
driver= config_ini["Azure SQL"]["driver"]
# SQL操作のログ出力
# ファイル名用の現在日時(YYYYMMDD_HHmmss)
current_datetime = datetime.now()
current_datetime_string = current_datetime.strftime('%Y%m%d_%H%M%S')
# ファイル保管場所
log_filepath = os.path.join(log_directory, log_filename)
# テーブル(receipt)へ値の挿入
# オートコミット無効で接続
with pyodbc.connect('DRIVER='+driver+';SERVER=tcp:'+server+';PORT=1433;DATABASE='+database+';UID='+username+';PWD='+ password, autocommit=False) as conn:
with conn.cursor() as cursor:
# try句の中が全て成功した場合のみコミット
with open(log_filepath, 'a', encoding='utf-8') as logfile:
try:
logfile.write(f"{current_datetime_string}_BIGIN TRANSACTION" + "\n")
# 日付、時刻、店名がNULLの場合はNULL型を挿入
if transaction_date_value == "NULL" and transaction_time_value == "NULL":
query_insert_receipt = f"""INSERT INTO receipt(receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename)
OUTPUT inserted.receipt_id
VALUES(NULL,NULL,N'{marchan_name_content}',{subtotal_amount},{total_amount},{total_tax_amount},N'{receipt_filename}')"""
elif transaction_date_value == "NULL":
query_insert_receipt = f"""INSERT INTO receipt(receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename)
OUTPUT inserted.receipt_id
VALUES(NULL,N'{transaction_time_value}',N'{marchan_name_content}',{subtotal_amount},{total_amount},{total_tax_amount},N'{receipt_filename}')"""
elif transaction_time_value == "NULL":
query_insert_receipt = f"""INSERT INTO receipt(receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename)
OUTPUT inserted.receipt_id
VALUES(N'{transaction_date_value}',NULL,N'{marchan_name_content}',{subtotal_amount},{total_amount},{total_tax_amount},N'{receipt_filename}')"""
else:
query_insert_receipt = f"""INSERT INTO receipt(receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename)
OUTPUT inserted.receipt_id
VALUES(N'{transaction_date_value}',N'{transaction_time_value}',N'{marchan_name_content}',{subtotal_amount},{total_amount},{total_tax_amount},N'{receipt_filename}')"""
logfile.write(f"{current_datetime_string}_EXEC:{query_insert_receipt} " + "\n")
# receiptテーブルの挿入
cursor.execute(query_insert_receipt)
# recieptテーブルの自動採番されたIDを取得
row = cursor.fetchone()
defined_receipt_id = row.receipt_id
# itemテーブルの挿入
# 商品別のリストを取得(SQLに文字列で格納するためシングルクオートを追加)
items = receipt.fields.get("Items")
if items:
valueArray = items["valueArray"]
item_id = 0
for valueElem in valueArray:
item_id += 1
content = valueElem["valueObject"]["Description"]["content"]
#価格が無い場合はNoneを出力
if "TotalPrice" in valueElem ["valueObject"]:
if "valueCurrency" in valueElem["valueObject"]["TotalPrice"]:
amount = valueElem["valueObject"]["TotalPrice"]["valueCurrency"]["amount"]
else:
amount = "NULL"
else:
amount = "NULL"
# 商品名と店舗名から商品ジャンルを推測
genre = predict_genre_of_item(marchan_name_content, content)
query_insert_item = f"INSERT INTO item(receipt_id, item_id, product_name, product_price, genre) VALUES({defined_receipt_id},{item_id},N'{content}',{amount},N'{genre}')"
logfile.write(f"{current_datetime_string}_EXEC:{query_insert_item}" + "\n")
cursor.execute(query_insert_item)
# コミットしてコネクションを閉じる
conn.commit()
cursor.close
conn.close
logfile.write(f"{current_datetime_string}_COMMIT" + "\n")
# データ挿入処理に失敗した場合はレシート単位でロールバック
except Exception as e:
conn.rollback()
cursor.close
conn.close
logfile.write(f"{current_datetime_string}_ROLLBACK" + "\n")
print(traceback.format_exc())
6.3.レシート分析プログラムの全量
レシート画像からDocument Intelligenceの分析結果をDBに格納するまでのプログラム全量を以下に記載する。
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeResult
from azure.ai.documentintelligence.models import AnalyzeDocumentRequest
import os
import img2pdf
import json
from datetime import datetime
import fitz
import pyodbc
import configparser
from openai import AzureOpenAI
import re
import traceback
#iniファイルの読み込み
config_ini = configparser.ConfigParser()
config_ini.read('receipt_analysis.ini', encoding='utf-8')
# Azure Document Interrigenceのキーを設定
endpoint = config_ini["Document Intelligence"]["AZURE_DOCUMENT_INTELLIGENCE_RECEIPT_ENDPOINT"]
key = config_ini["Document Intelligence"]["AZURE_DOCUMENT_INTELLIGENCE_RECEIPT_KEY"]
# 文書のライン内の単語を取得する関数
def get_words(page, line):
result = []
for word in page.words:
if _in_span(word, line.spans):
result.append(word)
return result
# 特定の単語(word)が与えられたスパン(spans)の範囲内にあるか判定する関数
def _in_span(word, spans):
for span in spans:
if word.span.offset >= span.offset and (
word.span.offset + word.span.length
) <= (span.offset + span.length):
return True
return False
#ファイルパスで指定した画像をPDFに変換する関数
def image2pdf(image_filepath, dst_pdf_path):
with open(dst_pdf_path, "wb") as pdf_file:
pdf_file.write(img2pdf.convert(image_filepath))
# ポリゴン座標をRectに変換する関数(Document intelligenceの座標はPDFの場合inchで返却される)
def polygon_to_rect(polygon):
# polygonは [x1, y1, x2, y2, ...] の形式
# インチからポイントに変換するために72倍する
x_coords = [x * 72 for x in polygon[0::2]] # x座標をポイントに変換
y_coords = [y * 72 for y in polygon[1::2]] # y座標をポイントに変換
# 最小と最大の座標を使って矩形を作成
return fitz.Rect(min(x_coords), min(y_coords), max(x_coords), max(y_coords))
# レシートから読み取った日付型をSQLServerの日付型に変換する関数
def date_to_sqldate(captured_date):
# 変換前のフォーマットの候補
date_formats = [
"%Y/%m/%d", # 2025/01/03
"%Y年%m月%d日", # 2025年01月03日
"%Y-%m-%d" # 2024-02-03
]
# 候補の形式で日付の解析に成功した場合SQLServerのDATE型に対応する"YYYY-MM-DD"フォーマットに変換
for format in date_formats:
try:
parsed_dt = datetime.strptime(captured_date, format)
return parsed_dt.strftime("%Y-%m-%d")
except ValueError:
pass
# どのフォーマットでも解析できなかった場合はNoneを返す
return "NULL"
# レシートから読み取った時間をSQLServerのTIME(7)型に直す
def time_to_sqltime(captured_time):
# 変換前のフォーマットの候補
time_formats = [
"%H:%M", # 例) "14:05"
"%H:%M:%S", # 例) "14:05:59"
"%H時%M分", # 例) "14時05分"
"%H時%M分%S秒" # 例) "14時05分59秒"
]
# 候補の形式で解析に成功した場合はSQLServerのTIME(7)へ変換する
for format in time_formats:
try:
parsed_time = datetime.strptime(captured_time, format).time()
return f"{parsed_time:%H:%M:%S}.{parsed_time.microsecond:06d}0"
except ValueError:
pass
# どのフォーマットでも解析できなかった場合はNoneを返す
return "NULL"
# 切り取り済みレシートをPDFに変換し汎用レイアウト分析し、結果のオブジェクトを返却する関数
def analyze_layout(src_directory, tmp_directory, image_file_name):
# Document Intelligenceのクライアントを定義
document_intelligence_client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
# 画像のPDFへの変換
image_file_path = os.path.join(src_directory, image_file_name)
pdf_file_path = os.path.join(tmp_directory, image_file_name[:-5]+".pdf")
image2pdf(image_file_path, pdf_file_path)
# PDFファイルをDocument Intelligenceの領収書モデルで分析
with open(pdf_file_path, "rb") as doc:
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-receipt",
analyze_request=doc,
output_content_format="markdown",
content_type="application/octet-stream",
)
receipts = poller.result()
return receipts
# Document Intelligenceの予測結果をログに出力する関数
def write_log(receipts, log_directory = "log"):
# ログ出力
# ログファイル名
# ファイル名用の現在日時(YYYYMMDD_HHmmss)
current_datetime = datetime.now()
current_datetime_string = current_datetime.strftime('%Y%m%d_%H%M%S')
log_filename = current_datetime_string + "_" + image_file_name[:-5]+".txt"
log_filepath = os.path.join(log_directory, log_filename)
# ドキュメントの読み取り
if receipts.documents:
# ログファイルを追記モードで開く
with open(log_filepath, 'a', encoding='utf-8') as logfile:
# resultの全量を出力
logfile.write("----Print result ----" + "\n")
# 結果をJSON形式で整形して表示
formatted_results = json.dumps(receipts.as_dict(), indent=4, ensure_ascii=False)
logfile.write(formatted_results + "\n")
# 商品名と価格の分析結果を出力する
for idx, receipt in enumerate(receipts.documents):
logfile.write(f"--------Analyzing receipt #{idx + 1}--------" + "\n")
# 取引日の取得
transaction_date = receipt.fields.get("TransactionDate")
if transaction_date:
# 正しい形式で格納されているため、valueDateの属性があれば優先して使う。無ければcontentを使う
if "valueDate" in transaction_date:
transaction_date_value = transaction_date["valueDate"]
else:
transaction_date_value = transaction_date["content"]
logfile.write(f"取引日:{transaction_date_value}" + "\n")
transaction_time = receipt.fields.get("TransactionTime")
if transaction_time:
transaction_time_value = transaction_time["content"]
logfile.write(f"取引時間:{transaction_time_value}" + "\n")
# 商品別のリストを取得
items = receipt.fields.get("Items")
if items:
valueArray = items["valueArray"]
for valueElem in valueArray:
content = valueElem["valueObject"]["Description"]["content"]
#価格が無い場合はNoneを出力
if "TotalPrice" in valueElem ["valueObject"]:
if "valueCurrency" in valueElem["valueObject"]["TotalPrice"]:
amount = valueElem["valueObject"]["TotalPrice"]["valueCurrency"]["amount"]
logfile.write(f"アイテム名:{content} 単価:{amount}" + "\n")
else:
logfile.write(f"アイテム名:{content} 単価:None" + "\n")
else:
logfile.write(f"アイテム名:{content} 単価:None" + "\n")
# 小計の取得
subtotal = receipt.fields.get("Subtotal")
if subtotal:
subtotal_amount = subtotal["valueCurrency"]["amount"]
logfile.write(f"小計:{subtotal_amount}" + "\n")
# 税金の取得
total_tax = receipt.fields.get("TotalTax")
if total_tax:
total_tax_ammount = total_tax["valueCurrency"]["amount"]
logfile.write(f"消費税:{total_tax_ammount}" + "\n")
# 合計金額の取得
total = receipt.fields.get("Total")
if total:
total_ammount = total["valueCurrency"]["amount"]
logfile.write(f"合計金額:{total_ammount}" + "\n")
logfile.write(f"--------End Analyzing receipt #{idx + 1}--------" + "\n")
# 結果をPDFに出力する関数
def write_pdf(receipts, tmp_directory, anotated_directory ,image_file_name):
# PDFへ結果をプロット
pdf_file_path = os.path.join(tmp_directory, image_file_name[:-5]+".pdf")
document = fitz.open(pdf_file_path)
pdf_page = document.load_page(0)
# 商品別のリストを取得
for idx, receipt in enumerate(receipts.documents):
items = receipt.fields.get("Items")
if items:
# 取引日のプロット
transaction_date = receipt.fields.get("TransactionDate")
if transaction_date:
# 正しい形式で格納されているため、valueDateの属性があれば優先して使う。無ければcontentを使う
if "valueDate" in transaction_date:
transaction_date_value = transaction_date["valueDate"]
else:
transaction_date_value = transaction_date["content"]
polygon_transaction_date = transaction_date["boundingRegions"][0]["polygon"]
# 黒色の枠
rect_transaction_date = polygon_to_rect(polygon_transaction_date)
pdf_page.draw_rect(rect_transaction_date, color=(0, 0, 0), width=0.5)
pdf_page.insert_text(rect_transaction_date.tl, str(transaction_date_value), fontsize=6, color=(0, 0, 0),fontname="japan")
# 取引時間のプロット
transaction_time = receipt.fields.get("TransactionTime")
if transaction_time:
transaction_time_value = transaction_time["content"]
polygon_transaction_time = transaction_time["boundingRegions"][0]["polygon"]
# 黒色の枠
rect_transaction_time = polygon_to_rect(polygon_transaction_time)
pdf_page.draw_rect(rect_transaction_time, color=(0, 0, 0), width=0.5)
pdf_page.insert_text(rect_transaction_time.tl, str(transaction_time_value), fontsize=6, color=(0, 0, 0),fontname="japan")
# アイテム別金額のプロット
valueArray = items["valueArray"]
for valueElem in valueArray:
# アイテム名のプロット
content = valueElem["valueObject"]["Description"]["content"]
polygon_content = valueElem["valueObject"]["Description"]["boundingRegions"][0]["polygon"]
# 赤い枠
rect_content = polygon_to_rect(polygon_content)
pdf_page.draw_rect(rect_content, color=(1, 0, 0), width=0.5)
pdf_page.insert_text(rect_content.tl, content, fontsize=6, color=(1, 0, 0),fontname="japan")
# 金額が無い場合は処理しない
if "TotalPrice" in valueElem ["valueObject"]:
if "valueCurrency" in valueElem["valueObject"]["TotalPrice"]:
# 金額のプロット
amount = valueElem["valueObject"]["TotalPrice"]["valueCurrency"]["amount"]
polygon_amount = valueElem["valueObject"]["TotalPrice"]["boundingRegions"][0]["polygon"]
# 緑色の枠
rect_amount = polygon_to_rect(polygon_amount)
pdf_page.draw_rect(rect_amount, color=(0, 1, 0), width=0.5)
pdf_page.insert_text(rect_amount.tl, str(amount), fontsize=6, color=(0, 1, 0),fontname="japan")
# 小計のプロット
subtotal = receipt.fields.get("Subtotal")
if subtotal:
subtotal_amount = subtotal["valueCurrency"]["amount"]
polygon_subtotal = subtotal["boundingRegions"][0]["polygon"]
# 黄色の枠
rect_subtotal = polygon_to_rect(polygon_subtotal)
pdf_page.draw_rect(rect_subtotal, color=(1, 1, 0), width=0.5)
pdf_page.insert_text(rect_subtotal.tl, str(subtotal_amount), fontsize=6, color=(1, 1, 0),fontname="japan")
# 税金のプロット
total_tax = receipt.fields.get("TotalTax")
if total_tax:
total_tax_ammount = total_tax["valueCurrency"]["amount"]
polygon_total_tax = total_tax["boundingRegions"][0]["polygon"]
# 青色の枠
rect_total_tax = polygon_to_rect(polygon_total_tax)
pdf_page.draw_rect(rect_total_tax, color=(0, 0, 1), width=0.5)
pdf_page.insert_text(rect_total_tax.tl, str(total_tax_ammount), fontsize=6, color=(0, 0, 1),fontname="japan")
# 合計金額のプロット
total = receipt.fields.get("Total")
if total:
total_ammount = total["valueCurrency"]["amount"]
polygon_total = total["boundingRegions"][0]["polygon"]
# 水色の枠
rect_total = polygon_to_rect(polygon_total)
pdf_page.draw_rect(rect_total, color=(0, 1, 1), width=0.5)
pdf_page.insert_text(rect_total.tl, str(total_ammount), fontsize=6, color=(0, 1, 1),fontname="japan")
# プロット済みPDFを保存
output_path = os.path.join(anotated_directory, image_file_name[:-5]+".pdf")
document.save(output_path)
document.close()
# 店名と商品名から商品ジャンルを推測する関数
def predict_genre_of_item(store_name, item_name, system_prompt_path="config\\system_prompt.txt", user_prompt_path="config\\user_prompt.txt"):
# AzureOpenAIクライアントの作成
client = AzureOpenAI(
api_key=config_ini["Azure Open AI"]["AOAI_OCR_RECEIPT_KEY"],
api_version="2024-07-01-preview",
azure_endpoint=config_ini["Azure Open AI"]["AOAI_OCR_RECEIPT_ENDPOINT"]
)
# プロンプトのテキストファイルを読み込み、店舗と商品の情報を追記
system_prompt_sentence = open(system_prompt_path, 'r', encoding='utf-8').read()
user_prompt_sentence = open(user_prompt_path, 'r', encoding='utf-8').read()
user_prompt_sentence += f"""
### 店舗名
{store_name}
### 商品名
{item_name}
"""
# AzureOpenAiに問い合わせ
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt_sentence},
{"role": "user", "content": [
{"type": "text", "text": user_prompt_sentence }
]}
]
)
# 回答からgenreタグの中身を抽出して戻り値とする
result = response.choices[0].message.content
genre = re.search(r'<genre>(.*?)</genre>', result)
return genre.group(1)
def store_record_to_db(receipts, receipt_filename, log_directory = "log\\sql", log_filename = "sqllog.txt"):
# ドキュメントの読み取り
if receipts.documents:
for idx, receipt in enumerate(receipts.documents):
# 取引日の取得
transaction_date = receipt.fields.get("TransactionDate")
if transaction_date:
# 正しい形式で格納されているため、valueDateの属性があれば優先して使う。無ければcontentを使う
if "valueDate" in transaction_date:
transaction_date_value = transaction_date["valueDate"]
print("ValueDate")
else:
transaction_date_value = transaction_date["content"]
print("ContentDate")
# SQL Server型の日付型へ変換
transaction_date_value = date_to_sqldate(transaction_date_value)
else:
transaction_date_value = "NULL"
# 取引時間の取得
transaction_time = receipt.fields.get("TransactionTime")
if transaction_time:
transaction_time_value = transaction_time["content"]
# SQL Server型のTIME(7)型へ変換
transaction_time_value = time_to_sqltime(transaction_time_value)
else:
transaction_time_value = "NULL"
# 小計の取得
subtotal = receipt.fields.get("Subtotal")
if subtotal:
subtotal_amount = subtotal["valueCurrency"]["amount"]
else:
subtotal_amount = "NULL"
# 税金の取得
total_tax = receipt.fields.get("TotalTax")
if total_tax:
total_tax_amount = total_tax["valueCurrency"]["amount"]
else:
total_tax_amount = "NULL"
# 合計金額の取得
total = receipt.fields.get("Total")
if total:
total_amount = total["valueCurrency"]["amount"]
else:
total_amount = "NULL"
# 店名の取得(正常の場合はSQL内で文字列で扱うためシングルクオートを追加)
marchan_name = receipt.fields.get("MerchantName")
if marchan_name:
marchan_name_content = marchan_name["content"]
else:
marchan_name_content = "NULL"
#Azure SQL Satabaseへの接続
server = config_ini["Azure SQL"]["server"]
database = config_ini["Azure SQL"]["database"]
username = config_ini["Azure SQL"]["username"]
password = config_ini["Azure SQL"]["password"]
driver= config_ini["Azure SQL"]["driver"]
# SQL操作のログ出力
# ファイル名用の現在日時(YYYYMMDD_HHmmss)
current_datetime = datetime.now()
current_datetime_string = current_datetime.strftime('%Y%m%d_%H%M%S')
# ファイル保管場所
log_filepath = os.path.join(log_directory, log_filename)
# テーブル(receipt)へ値の挿入
# オートコミット無効で接続
with pyodbc.connect('DRIVER='+driver+';SERVER=tcp:'+server+';PORT=1433;DATABASE='+database+';UID='+username+';PWD='+ password, autocommit=False) as conn:
with conn.cursor() as cursor:
# try句の中が全て成功した場合のみコミット
with open(log_filepath, 'a', encoding='utf-8') as logfile:
try:
logfile.write(f"{current_datetime_string}_BIGIN TRANSACTION" + "\n")
# 日付、時刻、店名がNULLの場合はNULL型を挿入
if transaction_date_value == "NULL" and transaction_time_value == "NULL":
query_insert_receipt = f"""INSERT INTO receipt(receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename)
OUTPUT inserted.receipt_id
VALUES(NULL,NULL,N'{marchan_name_content}',{subtotal_amount},{total_amount},{total_tax_amount},N'{receipt_filename}')"""
elif transaction_date_value == "NULL":
query_insert_receipt = f"""INSERT INTO receipt(receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename)
OUTPUT inserted.receipt_id
VALUES(NULL,N'{transaction_time_value}',N'{marchan_name_content}',{subtotal_amount},{total_amount},{total_tax_amount},N'{receipt_filename}')"""
elif transaction_time_value == "NULL":
query_insert_receipt = f"""INSERT INTO receipt(receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename)
OUTPUT inserted.receipt_id
VALUES(N'{transaction_date_value}',NULL,N'{marchan_name_content}',{subtotal_amount},{total_amount},{total_tax_amount},N'{receipt_filename}')"""
else:
query_insert_receipt = f"""INSERT INTO receipt(receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename)
OUTPUT inserted.receipt_id
VALUES(N'{transaction_date_value}',N'{transaction_time_value}',N'{marchan_name_content}',{subtotal_amount},{total_amount},{total_tax_amount},N'{receipt_filename}')"""
logfile.write(f"{current_datetime_string}_EXEC:{query_insert_receipt} " + "\n")
# receiptテーブルの挿入
cursor.execute(query_insert_receipt)
# recieptテーブルの自動採番されたIDを取得
row = cursor.fetchone()
defined_receipt_id = row.receipt_id
# itemテーブルの挿入
# 商品別のリストを取得(SQLに文字列で格納するためシングルクオートを追加)
items = receipt.fields.get("Items")
if items:
valueArray = items["valueArray"]
item_id = 0
for valueElem in valueArray:
item_id += 1
content = valueElem["valueObject"]["Description"]["content"]
#価格が無い場合はNoneを出力
if "TotalPrice" in valueElem ["valueObject"]:
if "valueCurrency" in valueElem["valueObject"]["TotalPrice"]:
amount = valueElem["valueObject"]["TotalPrice"]["valueCurrency"]["amount"]
else:
amount = "NULL"
else:
amount = "NULL"
# 商品名と店舗名から商品ジャンルを推測
genre = predict_genre_of_item(marchan_name_content, content)
query_insert_item = f"INSERT INTO item(receipt_id, item_id, product_name, product_price, genre) VALUES({defined_receipt_id},{item_id},N'{content}',{amount},N'{genre}')"
logfile.write(f"{current_datetime_string}_EXEC:{query_insert_item}" + "\n")
cursor.execute(query_insert_item)
# コミットしてコネクションを閉じる
conn.commit()
cursor.close
conn.close
logfile.write(f"{current_datetime_string}_COMMIT" + "\n")
# データ挿入処理に失敗した場合はレシート単位でロールバック
except Exception as e:
conn.rollback()
cursor.close
conn.close
logfile.write(f"{current_datetime_string}_ROLLBACK" + "\n")
print(traceback.format_exc())
if __name__ == "__main__":
# 切り取り済みレシート画像のディレクトリ
src_directory = "cropped_image"
# 一時ファイル保存先のディレクトリ
tmp_directory = "temp"
# ログ保管先のディレクトリ
log_directory = "log\prebuilt-receipt"
# アノテーション済みPDF保管先のディレクトリ
anotated_directory = "anotated_pdf\prebuilt-receipt"
# ファイルのリストを取得
image_list = [filename for filename in os.listdir(src_directory) if not filename.startswith('.')]
# リスト内の画像全てに対してレイアウトの推論を実行
for image_file_name in image_list:
# Document Intelligenceで予測
receipts = analyze_layout(src_directory, tmp_directory, image_file_name)
# 予測結果の出力
write_log(receipts, log_directory)
# 予測結果をPDFに表示
write_pdf(receipts, tmp_directory, anotated_directory ,image_file_name)
# DBへ格納
store_record_to_db(receipts, image_file_name)
7.DBの集約結果をExcelに出力
以下のプログラムでクエリの出力結果をExcelへ出力する。
Excelのセルや文字を細かく制御できる「openpyxl」というライブラリもあるが、
今回はPandasで簡易に作成する。
import pyodbc
import pandas as pd
#Azure SQL Satabaseへの接続
server = config_ini["Azure SQL"]["server"]
database = config_ini["Azure SQL"]["database"]
username = config_ini["Azure SQL"]["username"]
password = config_ini["Azure SQL"]["password"]
driver= config_ini["Azure SQL"]["driver"]
cnxn = pyodbc.connect('DRIVER='+driver+';SERVER=tcp:'+server+';PORT=1433;DATABASE='+database+';UID='+username+';PWD='+ password)
cursor = cnxn.cursor()
query = """
SELECT receipt.receipt_id, receipt_date, receipt_time, store_name, subtotal, total, tax, receipt_filename, item_id, product_name, product_price, genre
FROM receipt RIGHT JOIN item ON receipt.receipt_id = item.receipt_id
"""
# クエリを実行してPandasへ格納
df = pd.read_sql(query, cnxn)
df.to_excel('receipt_summary.xlsx',index=False, header=True)
最終的に以下のExcelが出力された。
認識に失敗した要素や、認識できなかった要素があるため、特徴は別途分析する。
