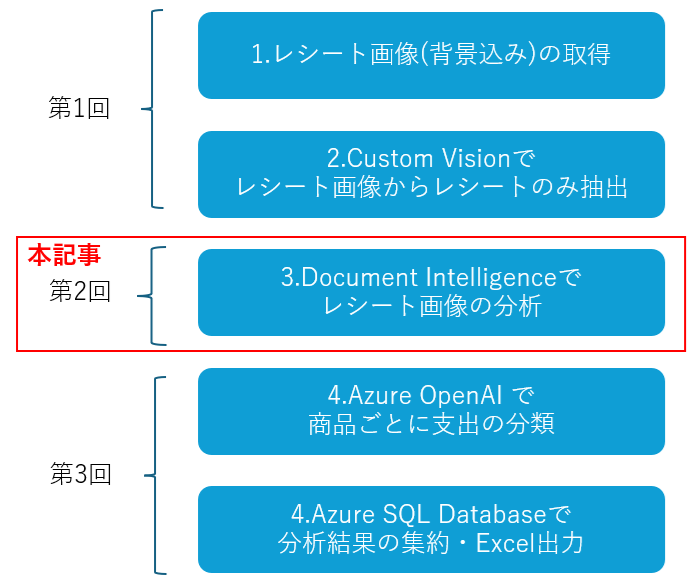
0.概要
①昨今市中には文字認識(OCR)サービスが多くあるが、Azureベースのシステムへの組み込みも意識して、今回はAzure単体で、レシートから出費をどのように集計できるか試す。
②集計の際に出費の分類を入力することが手間であるため、Azure OpenAIで自動的に推測させる。
第2回では、Document Intelligenceの事前構築済みモデル(レシートモデル)を特に重点的に取り扱う。公式の事前構築モデルのサンプルコードは請求書モデルしかないため(想定)、様々なドキュメントや応答データを確認しながらソースコードを組み立てていく。
今回は最終的に、レシート画像33枚から、自動的にデータをDBに蓄積して、集計結果のExcelファイルを出力する。
なお今回は記事が長いため、3回程度に分けて投稿する。
4.レシート分析プログラム
4.1.Azure AI Document Intelligence(旧Form Recognizer)
今回はAzureのドキュメント分析用AIであるAzure AI Document Intelligenceを利用する。
Azure AI Document Intelligenceは大きく分けて以下の3つから構成されている。
- 汎用抽出モデル:汎用的にフォームやドキュメントからテキストを抽出するモデル
- 事前構築積みモデル:領収書、請求書等特定の書類に特化したモデル
- カスタムモデル:各自で準備したデータセットでカスタマイズし、特定のユースケース固有のフォームに対応できるモデル
※参考:Microsoft公式「Azure AI Document Intelligence とは?」
https://learn.microsoft.com/ja-jp/azure/ai-services/document-intelligence/overview?view=doc-intel-4.0.0
今回はそれぞれのモデルを簡単に操作した後、レシート分析に最も適した「事前構築済みモデル」で実際にレシートを分析してみる。
4.2.汎用抽出モデル
今回はドキュメントレイアウトモデルを試してみる。
こちらは以下の公式ページのイメージのように、文書から文書構成する部品(テーブル、チェックボックス等)、場所、文字列等を取得する。
※参考:Microsoft公式「ドキュメント インテリジェンス レイアウト モデル」
https://learn.microsoft.com/ja-jp/azure/ai-services/document-intelligence/prebuilt/layout?view=doc-intel-4.0.0&viewFallbackFrom=form-recog-3.0.0&tabs=sample-code
4.2.1.Azure AI Document Intelligenceのデプロイ
①ポータルからリソースをデプロイする
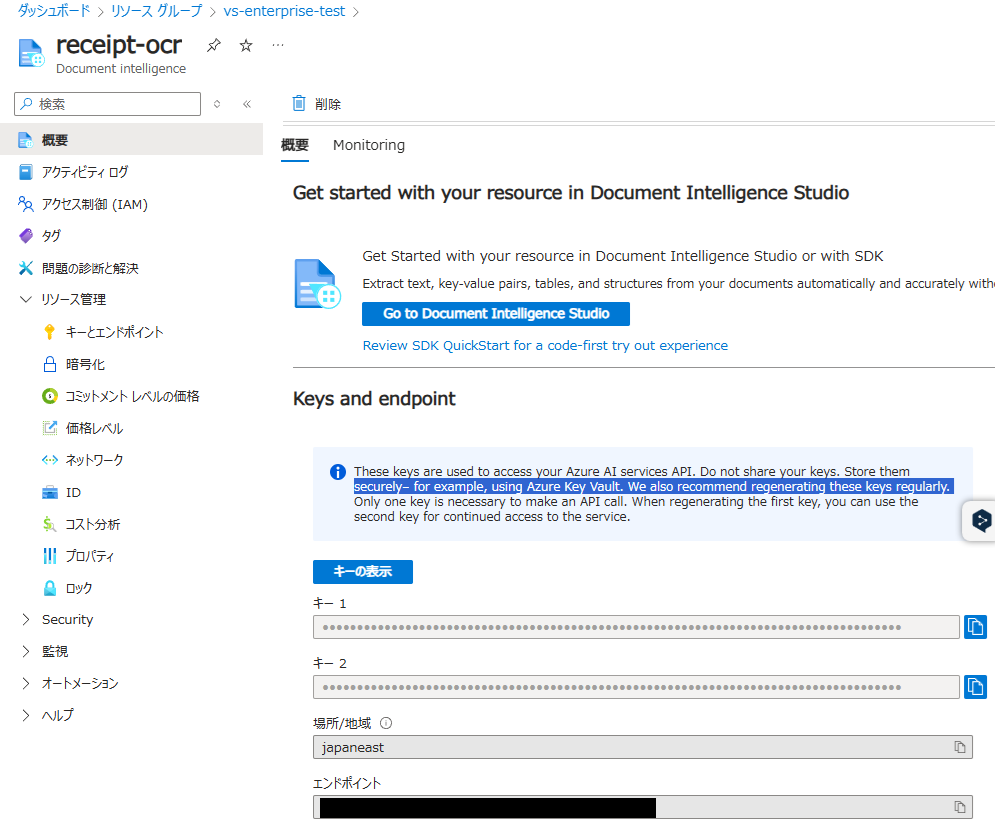
②リソースのページからキーとエンドポイントを控えておく
4.2.2.Pythonコードから汎用抽出モデル(レイアウトモデル)の呼び出し
以下を参考にPyhtonコードを組み立て、画像のレシートを分析する。
ソースコードは公式ページの記載を参考にする。
※参考:Microsoft公式「Azure AI Document Intelligence とは?」
https://learn.microsoft.com/ja-jp/azure/ai-services/document-intelligence/overview?view=doc-intel-4.0.0#layout
※参考:「Document Intelligence の概要」
https://learn.microsoft.com/ja-jp/azure/ai-services/document-intelligence/quickstarts/get-started-sdks-rest-api?view=doc-intel-4.0.0&preserve-view=true&pivots=programming-language-python#layout-model
①Document Intelligenceへ画像を送信する前に、以下の関数で画像ファイルをPDFへ変換する。
変換はimg2pdfを利用する。
import img2pdf
#ファイルパスで指定した画像をPDFに変換する関数
def image2pdf(image_filepath, dst_pdf_path):
with open(dst_pdf_path, "wb") as pdf_file:
pdf_file.write(img2pdf.convert(image_filepath))
※今回はレシート画像を全てPDFに変換したが、公式ページの「入力要件」によれば、画像での入力にも対応している。
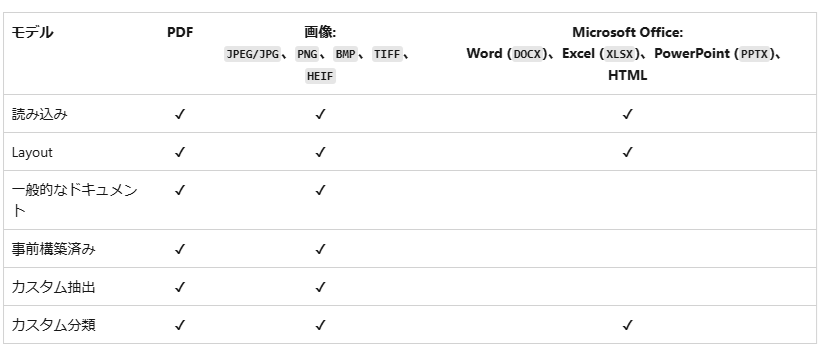
②Document Intelligenceへの接続情報を定義する。4.2.1章の②で控えたキーとエンドポイントを使用する。
※この後も接続情報が多く登場するため、ここから機密情報は環境変数ではなく、iniファイルに記載する。
import configparser
#iniファイルの読み込み
config_ini = configparser.ConfigParser()
config_ini.read('receipt_analysis.ini', encoding='utf-8')
# Azure Document Interrigenceのキーを作成
endpoint = config_ini["Document Intelligence"]["AZURE_DOCUMENT_INTELLIGENCE_RECEIPT_ENDPOINT"]
key = config_ini["Document Intelligence"]["AZURE_DOCUMENT_INTELLIGENCE_RECEIPT_KEY"]
③Docuemt Intelligenceへファイルを送信して推論する。ファイルは「pdf_file_path」で指定されたファイルのものを送信する。結果がオブジェクト形式でresultへ格納される。
with open(pdf_file_path, "rb") as doc:
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
analyze_request=doc,
output_content_format="markdown",
content_type="application/octet-stream",
)
result: AnalyzeResult = poller.result()
④以下がプログラムの全量となる公式ドキュメントではログの出力までであるが、分かりづらいため、PyMuPDFでPDFに予測結果をプロットする。
※PyMuPDFドキュメント
https://pymupdf.readthedocs.io/ja/latest/
はまりやすいポイントは以下2点あった
(1)Document Intelligenceの座標は「インチ」であるため、「pixcel」に変換する必要がある(以下ソースコード4つ目の関数で変換を実装している)
(2)PyMuPDFは「import fitz」で使用できるが、ライブラリは「pip install PyMuPDF」でインストールしないとfitz.open()が動かない
※「pip install fitz」を実行してしまった場合はアンインストールが必要
https://stackoverflow.com/questions/69160152/pymupdf-attributeerror-module-fitz-has-no-attribute-open
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeResult
from azure.ai.documentintelligence.models import AnalyzeDocumentRequest
import os
import img2pdf
import json
import datetime
import fitz
import configparser
#iniファイルの読み込み
config_ini = configparser.ConfigParser()
config_ini.read('receipt_analysis.ini', encoding='utf-8')
# Azure Document Interrigenceのキーを作成
endpoint = config_ini["Document Intelligence"]["AZURE_DOCUMENT_INTELLIGENCE_RECEIPT_ENDPOINT"]
key = config_ini["Document Intelligence"]["AZURE_DOCUMENT_INTELLIGENCE_RECEIPT_KEY"]
# 文書のライン内の単語を取得する関数
def get_words(page, line):
result = []
for word in page.words:
if _in_span(word, line.spans):
result.append(word)
return result
# 特定の単語(word)が与えられたスパン(spans)の範囲内にあるか判定する関数
def _in_span(word, spans):
for span in spans:
if word.span.offset >= span.offset and (
word.span.offset + word.span.length
) <= (span.offset + span.length):
return True
return False
#ファイルパスで指定した画像をPDFに変換する関数
def image2pdf(image_filepath, dst_pdf_path):
with open(dst_pdf_path, "wb") as pdf_file:
pdf_file.write(img2pdf.convert(image_filepath))
# ポリゴン座標をRectに変換する関数(Document intelligenceの座標はPDFの場合inchで返却される)
def polygon_to_rect(polygon):
# polygonは [x1, y1, x2, y2, ...] の形式
# インチからポイントに変換するために72倍する
x_coords = [x * 72 for x in polygon[0::2]] # x座標をポイントに変換
y_coords = [y * 72 for y in polygon[1::2]] # y座標をポイントに変換
# 最小と最大の座標を使って矩形を作成
return fitz.Rect(min(x_coords), min(y_coords), max(x_coords), max(y_coords))
# 切り取り済みレシートをPDFに変換し汎用レイアウト分析し、結果JSONと予測結果をプロットしたPDFを返却する関数
def analyze_layout(src_directory, tmp_directory, image_file_name, anotated_directory, log_directory = "log"):
# document intelligenceのクライアントを作成
document_intelligence_client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
# 画像のPDFへの変換
image_file_path = os.path.join(src_directory, image_file_name)
pdf_file_path = os.path.join(tmp_directory, image_file_name[:-5]+".pdf")
image2pdf(image_file_path, pdf_file_path)
# PDFを汎用抽出モデルで分析
with open(pdf_file_path, "rb") as doc:
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
analyze_request=doc,
output_content_format="markdown",
content_type="application/octet-stream",
)
result: AnalyzeResult = poller.result()
# ログ出力
# ログファイル名
# ファイル名用の現在日時(YYYYMMDD_HHmmss)
current_datetime = datetime.datetime.now()
current_datetime_string = current_datetime.strftime('%Y%m%d_%H%M%S')
log_filename = current_datetime_string + "_" + image_file_name[:-5]+".txt"
log_filepath = os.path.join(log_directory, log_filename)
# ログファイルへの情報の追記
with open(log_filepath, 'a', encoding='utf-8') as logfile:
# resultの全量を出力
logfile.write("----Print result ----" + "\n")
# 結果をJSON形式で整形して表示
formatted_results = json.dumps(result.as_dict(), indent=4, ensure_ascii=False)
logfile.write(formatted_results + "\n")
# 手書き文字列の有無を出力
logfile.write("-----Whether exsist hundritten content?-----" + "\n")
if result.styles and any([style.is_handwritten for style in result.styles]):
logfile.write("Document contains handwritten content" + "\n")
else:
logfile.write("Document does not contain handwritten content" + "\n")
for page in result.pages:
logfile.write(f"----Analyzing layout from page #{page.page_number}----" + "\n")
# ドキュメントのサイズ(インチで表示されている)
logfile.write(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}" + "\n"
)
# ページの中から行を抽出
if page.lines:
# 行ごとに単語を抽出して確度を表示
logfile.write("-----Print word of line in the page-----" + "\n")
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
logfile.write(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'" + "\n"
)
for word in words:
logfile.write(
f"......Word '{word.content}' has a confidence of {word.confidence}" + "\n"
)
# ページの中からSlection Marks(選択BOX)を抽出し
logfile.write("-----Print Selection Marks in the page-----" + "\n")
if page.selection_marks:
for selection_mark in page.selection_marks:
#selection_mark.sate:マークが選択されているかどうか、selection_mark.polygon:座標、selection_mark.confidence:確信度
logfile.write(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}" + "\n"
)
# テーブル構造があればテーブルごとに詳細を表示
if result.tables:
logfile.write("-----Print all table structures, if this page have tables-----" + "\n")
for table_idx, table in enumerate(result.tables):
logfile.write(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns" + "\n"
)
if table.bounding_regions:
for region in table.bounding_regions:
logfile.write(
f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}" + "\n"
)
for cell in table.cells:
logfile.write(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'" + "\n"
)
if cell.bounding_regions:
for region in cell.bounding_regions:
logfile.write(
f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'" + "\n"
)
logfile.write("----------------------------------------" + "\n")
# PDFへ結果をプロット
document = fitz.open(pdf_file_path)
for page in result.pages:
pdf_page = document.load_page(page.page_number - 1)
# ページに矩形を描画
for line in page.lines:
rect = polygon_to_rect(line.polygon)
# 赤い枠
pdf_page.draw_rect(rect, color=(1, 0, 0), width=0.5)
pdf_page.insert_text(rect.tl, line.content, fontsize=6, color=(1, 0, 0),fontname="japan")
# 選択マークを描画
if page.selection_marks:
for mark in page.selection_marks:
rect = polygon_to_rect(mark.polygon)
# 緑: 選択, 黄色: 非選択
color = (0, 1, 0) if mark.state == "selected" else (1, 1, 0)
pdf_page.draw_rect(rect, color=color, width=0.5)
# テーブルを描画
for table in result.tables:
for cell in table.cells:
rect = polygon_to_rect(cell.bounding_regions[0].polygon)
# 青い枠
pdf_page.draw_rect(rect, color=(0, 0, 1), width=0.5)
pdf_page.insert_text(rect.tl, cell.content, fontsize=6, color=(0, 0, 1), fontname="japan")
# プロット済みPDFを保存
output_path = os.path.join(anotated_directory, image_file_name[:-5]+".pdf")
document.save(output_path)
document.close()
if __name__ == "__main__":
# 切り取り済みレシート画像のディレクトリ
src_directory = "cropped_image"
# 一時ファイル保存先のディレクトリ
tmp_directory = "temp"
# ログ保管先のディレクトリ
log_directory = "log\prebuilt-layout"
# アノテーション済みPDF保管先のディレクトリ
anotated_directory = "anotated_pdf\prebuilt-layout"
# ファイルのリストを取得
image_list = [filename for filename in os.listdir(src_directory) if not filename.startswith('.')]
# リスト内の画像全てに対してレイアウトの推論を実行
for image_file_name in image_list:
analyze_layout(src_directory, tmp_directory, image_file_name, anotated_directory, log_directory)
4.2.3 汎用モデル(レイアウトモデル)でレシートを分析した結果
プログラムを実行の結果全てのレシートに対して部品種別ごとに色がつき、Document Intelligenceが理解した文字が表示される。
今回は青がテーブル構造、赤は文字列として解釈されている。

レイアウトモデルでは文字の読み取りやドキュメント上のレイアウトは解釈できるが、どの項目がレシートの何を意味しているかは分からない、そのため、後述の事前構築済みモデル(レシートモデル)を利用して、レシート上の文字も分析する必要がある。
※例えば、「小計」という文字は認識できても、これが「課税前の金額」であることは分析できない。全て同じ店のレシートであればこれでもごり押しできるかもしれないが、今回は多様な店のレシートがあるため、専用のモデルが必要となる。
4.3.事前構築済みモデル(レシートモデル)
次に事前構築済みモデル(レシートモデル)を取り扱う。
- レシートモデルはレシートを分析して、文字や数字が何を表しているのか確認する。
※参考:Microsoft公式より「Azure AI Document Intelligence とは?」
https://learn.microsoft.com/ja-jp/azure/ai-services/document-intelligence/overview?view=doc-intel-4.0.0#receipt
※参考:「Document Intelligence 領収書モデル」
https://learn.microsoft.com/ja-jp/azure/ai-services/document-intelligence/prebuilt/receipt?view=doc-intel-4.0.0 - 取得できるフィールドは以下に記載されている
※参考:GitHubリポジトリ「Azure-Samples」
https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/schema/2024-11-30-ga/receipt.md - また以下の通り日本語にも対応している
※参考:Microsoft公式「Language support: prebuilt models」
https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/language-support/prebuilt?view=doc-intel-4.0.0&tabs=languages%2Cthermal#receipt
4.3.1.Pythonコードによるレシートモデルの利用
事前構築モデルの公式サンプルコードは請求書モデルしかないため(想定)、公式サンプルコードと、レシートモデルの応答と、4.3章の「Azure-Samples」に記載されたフィールド開設を、総合的に確認しながらソースコードを組み立てる。
※参考:Microsoft公式「Document Intelligence の概要」
https://learn.microsoft.com/ja-jp/azure/ai-services/document-intelligence/quickstarts/get-started-sdks-rest-api?view=doc-intel-4.0.0&preserve-view=true&pivots=programming-language-python#layout-model
なお、レシートモデルも4.2.2章のレイアウトモデルとリソースやキーは同様であるため、リソースのデプロイやキーの設定は割愛する。
①まずは以下の関数でレシートモデルへ接続する。他のモデルとの違いは「document_intelligence_client.begin_analyze_document()」関数の第1引数の指定が異なるのみである。(今回はprebuilt-receipt)どうやらこの引数で、利用するモデルを決定できそう。
# 切り取り済みレシートをPDFに変換し汎用レイアウト分析し、結果のオブジェクトを返却する関数
def analyze_layout(src_directory, tmp_directory, image_file_name):
# Document Intelligenceのクライアントを定義
document_intelligence_client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
# 画像のPDFへの変換
image_file_path = os.path.join(src_directory, image_file_name)
pdf_file_path = os.path.join(tmp_directory, image_file_name[:-5]+".pdf")
image2pdf(image_file_path, pdf_file_path)
# PDFファイルをDocument Intelligenceの領収書モデルで分析
with open(pdf_file_path, "rb") as doc:
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-receipt",
analyze_request=doc,
output_content_format="markdown",
content_type="application/octet-stream",
)
receipts = poller.result()
return receipts
②次に上記プログラムで取得したDocument Intelligenceの戻り値をJSONに変換して出力する。
# Document Intelligenceの予測結果をログに出力する関数
def write_log(receipts, log_directory = "log"):
# ログ出力
# ログファイル名
# ファイル名用の現在日時(YYYYMMDD_HHmmss)
current_datetime = datetime.now()
current_datetime_string = current_datetime.strftime('%Y%m%d_%H%M%S')
log_filename = current_datetime_string + "_" + image_file_name[:-5]+".txt"
log_filepath = os.path.join(log_directory, log_filename)
# ドキュメントの読み取り
if receipts.documents:
# ログファイルを追記モードで開く
with open(log_filepath, 'a', encoding='utf-8') as logfile:
# resultの全量を出力
logfile.write("----Print result ----" + "\n")
# 結果をJSON形式で整形して表示
formatted_results = json.dumps(receipts.as_dict(), indent=4, ensure_ascii=False)
logfile.write(formatted_results + "\n")
③すると成形後で数千行のJSONが出力される。ここから、JSONと公式のフィールドの説明を突合しながら必要な部分を探る。
④まずは以下のレシートを分析した結果のJSONを確認する

⑤レシート内の個別の商品はJSON内の[Items]-[ValueArray]内に配列構造で入っていた。配下の「Content」に品名、「amount」に金額が入っている
"Items": {
"type": "array",
"valueArray": [
{
"type": "object",
"valueObject": {
"Description": {
"type": "string",
"valueString": "XXXステーキ150gセット",
"content": "XXXステーキ150gセット",
"boundingRegions": [
{
"pageNumber": 1,
"polygon": [
0.994,
4.7077,
3.4361,
4.7433,
3.4327,
4.9745,
0.9907,
4.939
]
}
],
"confidence": 0.94,
"spans": [
{
"offset": 121,
"length": 16
}
]
},
"TotalPrice": {
"type": "currency",
"valueCurrency": {
"currencySymbol": "¥",
"amount": 1900.0,
"currencyCode": "JPY"
},
⑥小計はJSON内の[Subtotal]-[amount]に入っていた。公式の説明では課税前となっているが、レシートによっては小計に課税後の金額が記載されているため、Subtotalに課税後の金額が格納されている。
"Subtotal": {
"type": "currency",
"valueCurrency": {
"currencySymbol": "¥",
"amount": 4400.0,
"currencyCode": "JPY"
},
⑦税についてはJSON内の[TaxDetails]-[valueArray]-[Amount]-[Amount]に記載されていた。
税は10%と8%の記載がある場合、双方の合計金額の値を取ろうとしていた。
"TaxDetails": {
"type": "array",
"valueArray": [
{
"type": "object",
"valueObject": {
"Amount": {
"type": "currency",
"valueCurrency": {
"currencySymbol": "¥",
"amount": 400.0,
"currencyCode": "JPY"
},
※以下はレシートモデルが税の合計金額を課税額として認識した例(青枠部分)

⑨合計金額は、[Total]-[amount]に記載されていた。
"Total": {
"type": "currency",
"valueCurrency": {
"currencySymbol": "¥",
"amount": 4400.0,
"currencyCode": "JPY"
},
⑩同じ要領で日付、時間、店名の要素も特定していく。それぞれは以下の場所にあった
- 日付:[TransactionDate]-[ValueDate] or [content]
※ ValueDateのほうが正しいフォーマットで入っているが、値が無い場合がある。 - 時間:[TransactionTime]-[content]
- 店名:[MerchantName]-[content]
⑪確認結果を持って、必要な値をテキストに抽出するプログラムを作成する。
# Document Intelligenceの予測結果をログに出力する関数
def write_log(receipts, log_directory = "log"):
# ログ出力
# ログファイル名
# ファイル名用の現在日時(YYYYMMDD_HHmmss)
current_datetime = datetime.now()
current_datetime_string = current_datetime.strftime('%Y%m%d_%H%M%S')
log_filename = current_datetime_string + "_" + image_file_name[:-5]+".txt"
log_filepath = os.path.join(log_directory, log_filename)
# ドキュメントの読み取り
if receipts.documents:
# ログファイルを追記モードで開く
with open(log_filepath, 'a', encoding='utf-8') as logfile:
# resultの全量を出力
logfile.write("----Print result ----" + "\n")
# 結果をJSON形式で整形して表示
formatted_results = json.dumps(receipts.as_dict(), indent=4, ensure_ascii=False)
logfile.write(formatted_results + "\n")
# 商品名と価格の分析結果を出力する
for idx, receipt in enumerate(receipts.documents):
logfile.write(f"--------Analyzing receipt #{idx + 1}--------" + "\n")
# 取引日の取得
transaction_date = receipt.fields.get("TransactionDate")
if transaction_date:
# 正しい形式で格納されているため、valueDateの属性があれば優先して使う。無ければcontentを使う
if "valueDate" in transaction_date:
transaction_date_value = transaction_date["valueDate"]
else:
transaction_date_value = transaction_date["content"]
logfile.write(f"取引日:{transaction_date_value}" + "\n")
transaction_time = receipt.fields.get("TransactionTime")
if transaction_time:
transaction_time_value = transaction_time["content"]
logfile.write(f"取引時間:{transaction_time_value}" + "\n")
# 商品別のリストを取得
items = receipt.fields.get("Items")
if items:
valueArray = items["valueArray"]
for valueElem in valueArray:
content = valueElem["valueObject"]["Description"]["content"]
#価格が無い場合はNoneを出力
if "TotalPrice" in valueElem ["valueObject"]:
if "valueCurrency" in valueElem["valueObject"]["TotalPrice"]:
amount = valueElem["valueObject"]["TotalPrice"]["valueCurrency"]["amount"]
logfile.write(f"アイテム名:{content} 単価:{amount}" + "\n")
else:
logfile.write(f"アイテム名:{content} 単価:None" + "\n")
else:
logfile.write(f"アイテム名:{content} 単価:None" + "\n")
# 小計の取得
subtotal = receipt.fields.get("Subtotal")
if subtotal:
subtotal_amount = subtotal["valueCurrency"]["amount"]
logfile.write(f"小計:{subtotal_amount}" + "\n")
# 税金の取得
total_tax = receipt.fields.get("TotalTax")
if total_tax:
total_tax_ammount = total_tax["valueCurrency"]["amount"]
logfile.write(f"消費税:{total_tax_ammount}" + "\n")
# 合計金額の取得
total = receipt.fields.get("Total")
if total:
total_ammount = total["valueCurrency"]["amount"]
logfile.write(f"合計金額:{total_ammount}" + "\n")
logfile.write(f"--------End Analyzing receipt #{idx + 1}--------" + "\n")
⑫実行の結果、先ほどのレシートに対して以下の通り結果が出力された
--------Analyzing receipt #1--------
取引日:2024年02月10日
取引時間:21:13:20
アイテム名:XXXステーキ150gセット 単価:1900.0
アイテム名:XXXステーキ300gセット 単価:2500.0
小計:4400.0
消費税:400.0
合計金額:4400.0
--------End Analyzing receipt #1--------
⑬文字だけでは分かりづらいため、PDFにも予測結果をプロットする。
※4.2.2章のプログラムを基に、今回抽出した値を連携するのみであるため詳細は割愛する
# 結果をPDFに出力する関数
def write_pdf(receipts, tmp_directory, anotated_directory ,image_file_name):
# PDFへ結果をプロット
pdf_file_path = os.path.join(tmp_directory, image_file_name[:-5]+".pdf")
document = fitz.open(pdf_file_path)
pdf_page = document.load_page(0)
# 商品別のリストを取得
for idx, receipt in enumerate(receipts.documents):
items = receipt.fields.get("Items")
if items:
# 取引日のプロット
transaction_date = receipt.fields.get("TransactionDate")
if transaction_date:
# 正しい形式で格納されているため、valueDateの属性があれば優先して使う。無ければcontentを使う
if "valueDate" in transaction_date:
transaction_date_value = transaction_date["valueDate"]
else:
transaction_date_value = transaction_date["content"]
polygon_transaction_date = transaction_date["boundingRegions"][0]["polygon"]
# 黒色の枠
rect_transaction_date = polygon_to_rect(polygon_transaction_date)
pdf_page.draw_rect(rect_transaction_date, color=(0, 0, 0), width=0.5)
pdf_page.insert_text(rect_transaction_date.tl, str(transaction_date_value), fontsize=6, color=(0, 0, 0),fontname="japan")
# 取引時間のプロット
transaction_time = receipt.fields.get("TransactionTime")
if transaction_time:
transaction_time_value = transaction_time["content"]
polygon_transaction_time = transaction_time["boundingRegions"][0]["polygon"]
# 黒色の枠
rect_transaction_time = polygon_to_rect(polygon_transaction_time)
pdf_page.draw_rect(rect_transaction_time, color=(0, 0, 0), width=0.5)
pdf_page.insert_text(rect_transaction_time.tl, str(transaction_time_value), fontsize=6, color=(0, 0, 0),fontname="japan")
# アイテム別金額のプロット
valueArray = items["valueArray"]
for valueElem in valueArray:
# アイテム名のプロット
content = valueElem["valueObject"]["Description"]["content"]
polygon_content = valueElem["valueObject"]["Description"]["boundingRegions"][0]["polygon"]
# 赤い枠
rect_content = polygon_to_rect(polygon_content)
pdf_page.draw_rect(rect_content, color=(1, 0, 0), width=0.5)
pdf_page.insert_text(rect_content.tl, content, fontsize=6, color=(1, 0, 0),fontname="japan")
# 金額が無い場合は処理しない
if "TotalPrice" in valueElem ["valueObject"]:
if "valueCurrency" in valueElem["valueObject"]["TotalPrice"]:
# 金額のプロット
amount = valueElem["valueObject"]["TotalPrice"]["valueCurrency"]["amount"]
polygon_amount = valueElem["valueObject"]["TotalPrice"]["boundingRegions"][0]["polygon"]
# 緑色の枠
rect_amount = polygon_to_rect(polygon_amount)
pdf_page.draw_rect(rect_amount, color=(0, 1, 0), width=0.5)
pdf_page.insert_text(rect_amount.tl, str(amount), fontsize=6, color=(0, 1, 0),fontname="japan")
# 小計のプロット
subtotal = receipt.fields.get("Subtotal")
if subtotal:
subtotal_amount = subtotal["valueCurrency"]["amount"]
polygon_subtotal = subtotal["boundingRegions"][0]["polygon"]
# 黄色の枠
rect_subtotal = polygon_to_rect(polygon_subtotal)
pdf_page.draw_rect(rect_subtotal, color=(1, 1, 0), width=0.5)
pdf_page.insert_text(rect_subtotal.tl, str(subtotal_amount), fontsize=6, color=(1, 1, 0),fontname="japan")
# 税金のプロット
total_tax = receipt.fields.get("TotalTax")
if total_tax:
total_tax_ammount = total_tax["valueCurrency"]["amount"]
polygon_total_tax = total_tax["boundingRegions"][0]["polygon"]
# 青色の枠
rect_total_tax = polygon_to_rect(polygon_total_tax)
pdf_page.draw_rect(rect_total_tax, color=(0, 0, 1), width=0.5)
pdf_page.insert_text(rect_total_tax.tl, str(total_tax_ammount), fontsize=6, color=(0, 0, 1),fontname="japan")
# 合計金額のプロット
total = receipt.fields.get("Total")
if total:
total_ammount = total["valueCurrency"]["amount"]
polygon_total = total["boundingRegions"][0]["polygon"]
# 水色の枠
rect_total = polygon_to_rect(polygon_total)
pdf_page.draw_rect(rect_total, color=(0, 1, 1), width=0.5)
pdf_page.insert_text(rect_total.tl, str(total_ammount), fontsize=6, color=(0, 1, 1),fontname="japan")
# プロット済みPDFを保存
output_path = os.path.join(anotated_directory, image_file_name[:-5]+".pdf")
document.save(output_path)
document.close()
⑭このプログラムを実行すると要素ごとに認識した枠が表示される。レイアウトモデルとの違いはどの値が単価で、どの値が合計かまで分析できているため、レシートが多様であっても、分析結果を活用してレシートを集計することが期待できる。
