どうもエンジニアのirohasです。
先日、物体検出の論文を漁っていて、最近流行りのYolov7の論文を読んで実装してみたので、必要に応じて解説しながら、どんな感じになったか紹介できればと思います。
(https://arxiv.org/pdf/2207.02696.pdf)
目次
1.はじめに
2.環境
3.物体検出って何?
4.Yoloとは
5.Yolov7の紹介
6.使用する作品について
7.キャラ紹介
8.データセットの前処理
9.データセットの作成
10.学習
11.結果
12.感想
13.参考文献
1. はじめに
皆さんはラブライブ!を知っていますか?
アニメオタクなら一度は聞いたことがある伝説のアイドルアニメです。
ストーリーだけでなく、曲もライブコンテンツも素晴らしい作品なのでシリーズ通して全人類に見てもらいたい作品です。(クソデカボイス)
下にシリーズごとのサイト貼っておくのでぜひ気になる方は覗いてみてください!
初代ラブライブ:https://www.lovelive-anime.jp/news/?series=lovelive
ラブライブサンシャイン:https://www.lovelive-anime.jp/news/?series=sunshine
虹ヶ咲学園スクールアイドル同好会:https://www.lovelive-anime.jp/news/?series=nijigasaki
ラブライブ!スーパースター!:https://www.lovelive-anime.jp/news/?series=superstar
蓮ノ空女学院スクールアイドルクラブ:https://www.lovelive-anime.jp/v-schoolidol/
まぁせっかくこう言うことするならオリジナルのデータで学習させてみたいよねってことで、
今回はこの数あるシリーズの中から、ラブライブ!スーパースター!を使用して物体検出を行なっていこうと思います。
2. 環境
PC: MacOS
言語: Python v3.10
ツール: Roboflow
3. 物体検出って何?
物体検出とは、下記リンクの記事において、「物体検出は、画像や動画中の物体のインスタンスを見つけるためのコンピュータビジョン技術である。物体検出アルゴリズムは、通常、機械学習やディープラーニングを活用して意味のある結果を生成しています。人間は画像や映像を見るとき、一瞬のうちに興味のあるオブジェクトを認識し、その位置を特定することができます。物体検出の目標は、この知能をコンピュータで再現することです。」と説明されており、「物体検出は、自動車が走行車線を検出したり、歩行者を検出したりして、交通安全を向上させる先進運転支援システム(ADAS)を支える重要な技術である。また、ビデオ監視や画像検索システムなどにも応用されている。」とも説明されています。
詳しくはこちら↓
What Is Object Detection?
4. Yoloとは
YOLOはリアルタイムオブジェクト検出アルゴリズムです。YOLO(You Only Look Once)の名前通り、このアルゴリズムでは検出窓をスライドさせるような仕組みを用いず、画像を一度CNNに通すことで、オブジェクトを検出することができます。
まず、このセクションではYOLOについて簡単に説明します。YOLOアルゴリズムで使用する教師データは少々複雑であるため、アルゴリズムのイメージを把握することは教師データの構造を理解することにも役立ちます。
YOLOは2つのプロセスを同時に行います。オブジェクトの検出とクラス分類です。
YOLOでは、画像をグリッドセルとして扱います。Fig1は元のイメージで、Fig2はグリッドセルを画像に当てはめたものです。この例では縦方向と横方向にそれぞれ7つのセルをおいています。


YOLOではそれぞれのセルがバウンディングボックスをオブジェクトに当てはめる役割を担っています。例えば、Fig3内の赤色で示されたセルはFig4にかかれているように、セル周辺の2つのバウンディングボックスを設置する役割があります。一つのセルが設置するバウンディングボックスの数はユーザが指定することが出来ます。


セルはバウンディングボックスを設置するのと同時に、クラス確率もP(Car|Object)も出力します。これはオブジェクトが存在していた場合どのクラスに属するかを示す事後確率です。Fig5はそれぞれのセルが示すクラス確率の最大値を取るクラスで色付けをしたものです。
ここでFig3、Fig4、Fig5を統合して考えます。Fig3で赤く塗られたセルは、Fig4のようなバウンディングボックスを予測し同時にFig5のようなクラス確率を持ちます。結果として、バウンディングボックスはオレンジ色のクラスのオブジェクトのバウンディングボックスとなります。

同様に、すべてのセルが設置した残りのバウンディングボックスについてもクラス毎に色をつけた図がFig5隣ります。最後の処理として、NMS(Non-Maximum Suppression)という処理を施します。
NMSはバウンディングボックスを結合する処理を担います。以上の処理により、Fig7のようなバウンディングボックスを得ることが出来ます。


参考サイト:
https://www.renom.jp/ja/notebooks/tutorial/image_processing/yolo/notebook.html
5. Yolov7の紹介
YOLOv7は2022年7月に公開された物体検出モデルの最新バージョンで、論文によると、
YOLOv7は、5FPSから160FPSの範囲において、既知のオブジェクト検出器を速度、精度ともに上回り、GPU V100で30FPS以上のリアルタイムオブジェクト検出器の中で最も高い精度(56.8% AP)を達成しました。
YOLOv7-E6 object detector (56 FPS V100, 55.9% AP) は、変換器ベースの検出器 SWINL Cascade-Mask R-CNN (9.2 FPS A100, 53.9% AP) を速度で509%、精度で2%、また畳み込みベースの検出器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) も上回り、これらの検出器の性能は、GPU V100で30FPS以上のリアルタイム物体検出器として最も優れています。YOLOR(FPS A100、AP55.2%)では、速度が551%、精度が0.7%向上しました。
さらにYOLOX、Scaled-YOLOv4、YOLOv5、DETR、Deformable DETR、DINO-5scale-R50、ViT-Adapter-B、その他多くのオブジェクト検出器を速度、精度ともに上回っています。
このように他のオブジェクト検出器と比較して、高速かつ高精度な検出が可能です。
そして、YOLOv7は、特徴的な点として、他のデータセットや事前学習を一切行わず、その重みも一切使用せず、MSCOCOデータセットのみで一から学習します。
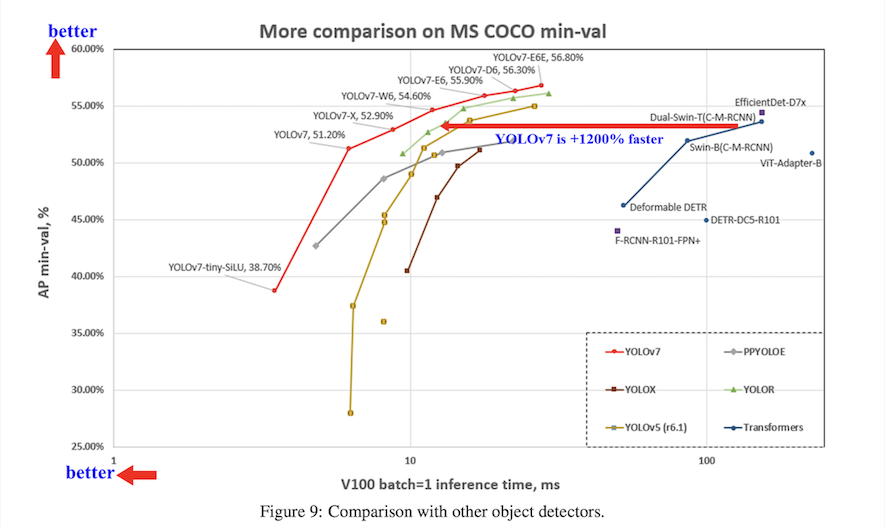
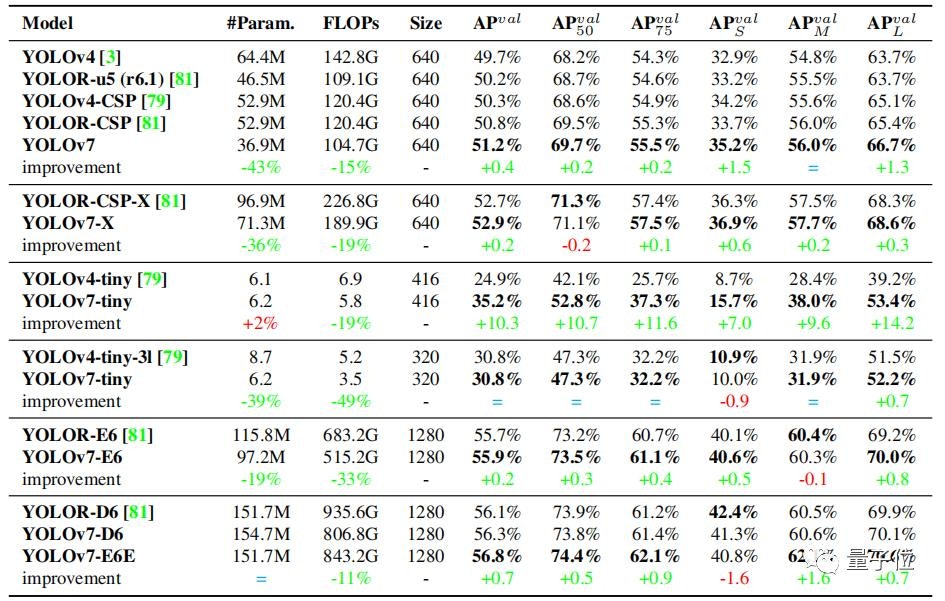
参考論文:https://arxiv.org/pdf/2207.02696.pdf
6. 使用する作品について
今回はデータとしてラブライブ!シリーズの中でも現在2期まで放送され、これから3期が放送予定の「ラブライブ!スーパースター!」を使用します。

軽く作品説明
あらすじ
第1期
東京の原宿にある新設校の私立結ヶ丘女子高等学校に入学した澁谷 かのんは、同じく新入生である唐 可可に誘われてスクールアイドルグループ「クーカー」としての活動を始める。ダンスが上手い幼馴染の嵐 千砂都の協力もあってスキルを上げていくが、生徒会長の葉月 恋はかのんたちのスクールアイドル活動を「学校に不要なもの」として敵視する。やがて、子役として活動していた平安名 すみれや千砂都も加わり、人気グループ・Sunny Passionとの交流を経て成長するかのんたち。恋もまた、亡き母がスクールアイドルを恨んでいたという考えが誤解であったことに気づき、自身もかのんたちの活動に魅せられてスクールアイドルをしてみたい気持ちが芽生えており、そんな彼女をかのんたちは快く迎える。5人となったかのんたちはグループ名を「Liella!」に改め、スクールアイドルの全国大会「ラブライブ!」に挑戦。イルミネーションが輝く通りでのステージで、輝かしいパフォーマンスを披露するのだった。
第2期
前回のラブライブ!で準優勝となったLiella!は2年生に進級し、結ヶ丘に新1年生が入学して来た。その中で、桜小路 きな子、米女 メイ、若菜 四季、鬼塚 夏美の4人がスクールアイドル部に入部。ともにLiella!として次のラブライブ!での優勝を目指していく。だが、Liella!をライバル視する少女ウィーン・マルガレーテが現れ、その圧倒的なパフォーマンスで様々なイベントを席巻していく。やがて始まったラブライブ!で、マルガレーテは前回優勝者のSunny Passionを東京地区予選で破り、次の段階へ進む。Sunny Passionの無念を背負ったLiella!は東京地区本選で彼女と勝負。結果、マルガレーテを下して全国大会決勝への進出を決めたLiella!は、見事に優勝を果たす。かのんはマルガレーテとの約束であるオーストリアへの留学に向けて準備するが、突如マルガレーテから留学中止を告げられ、混乱するかのんの叫びで物語は終わる。(Season3へ)
参考文献:ラブライブ!スーパースター!
7. キャラ紹介
学習の前にラブライブを知らない人向けに軽く名前と画像だけでキャラ紹介をしておきます。(判別時にキャラがわからないとアレなので)
知っている人はスキップで大丈夫です!
・澁谷 かのん(しぶや かのん)

・唐可可(タン クゥクゥ)

・嵐 千砂都(あらし ちさと)

・平安名 すみれ(へあんな すみれ)

・葉月 恋(はづき れん)

・桜小路 きなこ(さくらこうじ きなこ)

・米女 メイ(よねめ めい)

・若菜 四季(わかな しき)

・鬼塚 夏美(おにつか なつみ)

8. データセットの前処理
お待たせしました。ここからはようやくコードを交えた紹介になります。
まずは、データセットを作成するために、動画から指定フレームごとに画像として抽出し、任意のディレクトリに保存していきます。
このあとアノテーションする際に、わかりやすくするため、画像名を連番で保存するようにも設定していきます。
import cv2
import numpy as np
# extract:path = file_path、save_path、steo_num、extention)
def extract(path, dir, step, extension):
movie = cv2.VideoCapture(path) # load mp4
Fs = int(movie.get(cv2.CAP_PROP_FRAME_COUNT)) # calc all frame
path_head = dir + 'liella_' # image header
ext_index = np.arange(0, Fs, step) # extract index
for i in range(Fs - 1): # roop for frame num
flag, frame = movie.read() # load 1 frame from movie
check = i == ext_index # check
# When flag=True, only execute.
if flag == True:
# If the i-th frame is to extract a still image, name and save the file.
if True in check:
# File names should be sequentially numbered when sorted by name later in the folder.
if i < 10:
path_out = path_head + '0000' + str(i) + extension
elif i < 100:
path_out = path_head + '000' + str(i) + extension
elif i < 1000:
path_out = path_head + '00' + str(i) + extension
elif i < 10000:
path_out = path_head + '0' + str(i) + extension
else:
path_out = path_head + str(i) + extension
cv2.imwrite(path_out, frame)
# If the i-th frame is one from which no still image is extracted, no processing is done.
else:
pass
else:
pass
return
extract('./video/liella.mp4', './data/', 25, '.jpg')
今回は公式様より動画を拝借しアニメ一話分をまるまる切り抜きました。
その後、データセット作成のため、データをtrainとvalidに分けていきます。
import shutil
import glob
import random
path_list = glob.glob('./dataset/train/*jpg')
def separate_dataset(path, sep):
file_list = path
list_len = len(file_list)
n = int(list_len*sep)
z = random.sample(file_list, list_len)
train_list = z[:n]
test_list = z[n:]
val_file = './dataset/val/'
print (len(file_list))
print (len(train_list))
print (len(test_list))
for test_path in test_list:
print(test_path)
shutil.move(test_path, val_file)
return [train_list,test_list]
if __name__ == '__main__':
separate_dataset(path_list, 0.7)
大体データセットは8:2か7:3で分けるのがベターなので今回は後者で分けてます。
9. データセットの作成
続いて、仕分けしたデータを使ってデータセットの作成をしていきます。
物体検出において、このタスクはアノテーションと呼びます。
詳しくはこちら↓
アノテーションとは?
今回は数あるアノテーションツールの中から、「RoboFlow」さんを使用しました。
使い方もすごい簡単なので、リンクだけ貼っておきます。
RoboFlow
yamlの作成
Yolov7では学習時にyamlファイルが必要になります。
RoboFlowではデータセット作成と同時にyamlを自動作成してもらえますが、他のツールで作成している人向けにコード貼っておきます。
train: ./dataset/train/
val: ./dataset/valid/
nc: 14
names: ['chisato', 'kanon', 'kinako', 'kuku', 'manmaru', 'mao', 'mei', 'mobu', 'natume', 'natumi', 'ren', 'siki', 'sumire', 'yuna']
roboflow:
workspace: {Your User Name}
project: {Your Project Name}
version: 2
license: MIT
url: {Your Project URL}
10. 学習
git clone コマンドを使用してhttps://github.com/WongKinYiu/yolov7.git をダウンロードします。
使い方に関してはgithub内で詳しく説明されているので、割愛します。
先ほど作成したデータセットを配置し、train.pyを実行します。
train.pyを見ていると、parserでいろいろパラメーターが設定されているので、必要に応じて実行時に入力します。
今回自分の場合は以下のようにして実行しました。
python3 train.py --workers 8 --device 0 --batch-size 8 --data data/liella.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights 'yolov7.pt' --name yolov7-custom --hyp data/hyp.scratch.custom.yaml --project "model/"
実行し、作成されたモデルは、上記のコマンドを見たら分かるとおり、自分の場合は"model/"配下に保存されます。
その後作成したモデルを使用して推論します。
今回は動画での検出のため、mp4ファイルを使用しています。
python3 detect.py --source inference/images/liella_test.mp4 --weights yolov7/model/yolov7-custom5/weights/last.pt --conf 0.25 --img-size 640 --device 0
実行すると、検出結果が反映されたmp4ファイルが作成されます。
11. 結果
実行した結果がこちらです。
画像単位
まずは、動画をスクショしていくつか抜粋してみました。





かなり高精度でキャラ識別ができているのがわかりますね!!
動画
※GIFしか上げられないので、抜粋してます。(スミマセン)

12. 感想
AIエンジニアとして日々いろいろな先端技術研究をしていますが、物体検出はあんまりやったことなかったので、論文のおかげもありいろいろ勉強になりました。
何より、学習よりもアノテーションがすごく大変でした笑
アノテーションは同じことをやり続けるのと、普段の仕事と違って個人での作業なので、作業量が多く、精神的にキツかったですが、休憩をこまめにしたり、音楽聴いたりゲームしたりで気分転換しながら進めたのが大きかったなと思います。
これからも、AIエンジニアとしていろいろ吸収して邁進していきたいです。
13. 参考文献
今回参考に・資料集めをしたサイト等のリンクを貼っておきます。
[Yolov7論文] https://arxiv.org/pdf/2207.02696.pdf
[What Is Object Detection?] https://www.mathworks.com/discovery/object-detection.html
[YOLOとは] https://www.renom.jp/ja/notebooks/tutorial/image_processing/yolo/notebook.html
[ラブライブ!スーパースター! wiki] https://ja.wikipedia.org/wiki/ラブライブ!スーパースター!!#テレビアニメ
[ラブライブ!スーパースター! キャラ集] https://www.lovelive-anime.jp/yuigaoka/member/
[アノテーションとは?] https://www.science.co.jp/annotation_blog/30313/
[RoboFlow] https://app.roboflow.com/
[Yolov7 Git] https://github.com/WongKinYiu/yolov7.git
[Test Data] https://www.youtube.com/watch?v=2tJGGmJhm_E