初めまして。Qiita&アドベントカレンダー初投稿です。よろしくお願い致します![]()
今回はWeb Audio API を利用してキャラクター(VOICEROID)に口パク(リップシンク)を実装したので、その実装過程を紹介したいと思います。
何でこんなもの作ったか
個人用で作っていたwebアプリにガイド的な存在としてキャラクターイラスト付きでVOICEROIDを登場させ、音声案内をしてもらっていました。
しかし、イラストなので当然VOICEROIDがしゃべっても、動きがないんですよね。特に口が。
そこで、どうにか音声に合わせて口を動かせないかと思い、実装に至りました。
完成品
ともあれ、まずは完成品をご覧ください。
https://youtu.be/E6miOvn_ha4
どうですか?母音に合わせてやってるわけではないので、正確ではありませんが、僕は結構いい線行っていると思います。
では実際にやったことを紹介します。
画像&声の準備
今回登場するVOICEROIDは琴葉葵ちゃんです。
使用イラストは使用用途が自由だったMtU様のを利用させて頂きます。
https://seiga.nicovideo.jp/seiga/im9664585
イラストでどうやってリップシンクさせるかですが、
イラストを体レイヤー・顔レイヤー・口レイヤーに分けて独立した画像にします。
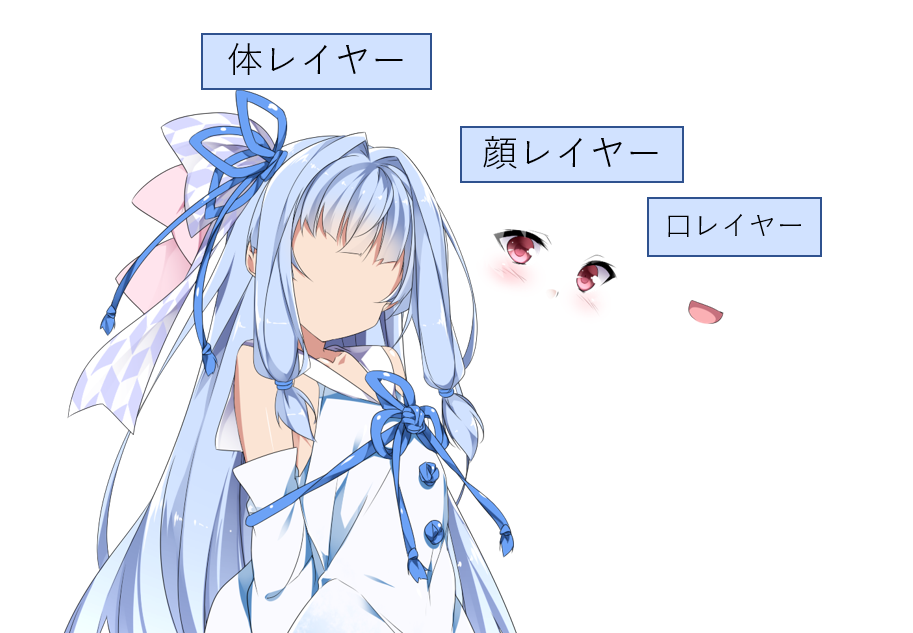
各レイヤーが重なるように画像を配置、音声に合わせて口レイヤーの画像を差し替えることで口が動いているように見せます。
加えて、顔と口を分けることでリップシンクを保ちつつ、顔全体の表情を差し替えられるようにします(今回は表情の差し替えはしていませんが...)。
使用イラストはPSD形式(目、口、頬など各レイヤー分けされている画像形式)だったのでレイヤー事に画像を切り出しました。
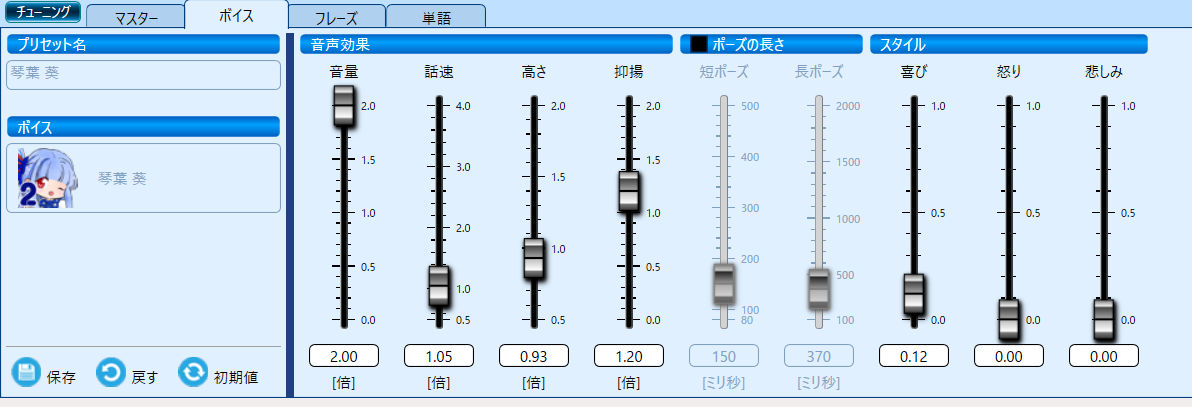
声はVOICEROID2を利用して作成しました。わかる方向けですが、VOICEROIDの調声パラメータは以下になります。
どうやって声とリップシンクさせるか
精密にリップシンクするなら、母音に応じて口の形を変える方法が良さそうですが、母音の判別は難しく一筋縄ではいかなそうでした。(フォルマント?というものを使えば判別できそうでしたが、求め方がわかりませんでした。)
そのため、もっと単純なものにして、__音の強度(スペクトル)が強ければ開口、弱ければ閉口する方式__にします。
その強度を取得にはWeb Audio APIのAnalyserNodeを利用します。
Web Audio API
今回の主役です。Webで音を再生する際は<audio>タグが一般的ですが、このAPIを利用することで音の再生のみならず、加工や解析が行えるようになります。
使い方や概念ははMDN docsに詳しく書かれています。簡単に説明すると
1.音声の入力ノードと加工ノード、出力ノードを定義する
2.入力ノード→加工ノード→出力ノードの順に接続すると音声が再生される
3.加工ノードの種類を変えることで音声に対して加工や解析を行えるようになる
という具合です。
AnalyserNode
Web Audio APIの加工ノードの一つです。入力ノードと出力ノードの間に挟むことで高速フーリエ変換(FFT)を行い、音声の波形やスペクトル周波数を取得することができます。
リップシンク実装
ソースは長いのでgithubに上げました。全文はそちらをご覧ください。
https://github.com/Iroha71/character_lipsync4web
以下、ポイントを抜粋します。
AnalyserNodeの準備
- index.html: 52行目~
/* 音声データをAudioBufferに変換 */
preparedBuffer = async (voice_path) => {
ctx = new AudioContext()
const res = await fetch(voice_path)
const arrayBuffer = await res.arrayBuffer()
const audioBuffer = await ctx.decodeAudioData(arrayBuffer)
return audioBuffer
}
/* 入力ノードとAnalyserノードを生成し、出力層に接続 */
buildNodes = (audioBuffer) => {
audioSrc = new AudioBufferSourceNode(ctx, { buffer: audioBuffer })
analyser = new AnalyserNode(ctx)
analyser.fftSize = 512
audioSrc.connect(analyser).connect(ctx.destination)
}
AnalyserNodeを使うためにpreparedBufferとbuildNodesという関数を用意しました。
Web Audio APIに音声ファイルを使う場合はAudioBufferに変換する必要があるため、preparedBuffer関数で音声ファイルをAudioBufferに変換しています。
次にbuildNodes関数で変換されたAudioBufferを入力するノード(AudioBufferSourceNode)、音声解析に使うAnalyserNodeを生成します。AnalyserNodeにはfftSizeを指定します。
fftSizeは高速フーリエ変換を行う際の周波数領域の大きさで__32, 64, 128, 256, 512, 1024, 2048__のいづれかを指定します。値が大きいほどより細かく周波数や波形情報が情報が得られるようになります。
音声解析→音の強度(スペクトル)の取得
- index.html: 97行目~
sampleInterval = setInterval(() => {
let spectrums = new Uint8Array(analyser.fftSize)
analyser.getByteFrequencyData(spectrums)
syncLip(spectrums)
}, 50)
AnalyserNodeのgetByteFreqencyDataを使うことで引数に渡した変数(上記コードだとspectrums)に符号なし整数(Uint8)の配列であらわされたスペクトル情報が格納されます。
スペクトルはsetIntervalで50ms毎に取得するようにします。
リップシンク
- index.html: 71行目~
syncLip = (spectrums) => {
let totalSpec = 0
const totalSpectrum = spectrums.reduce(function(a, x) { return a + x })
if (totalSpectrum > prevSpec) {
mouseElement.src = './mouse_open.png'
} else {
mouseElement.src = './mouse_close.png'
}
prevSpec = totalSpectrum
}
肝心のリップシンク処理です。AnalyserNodeによる音声解析で取得したスペクトル情報をもとにイラストの口レイヤーを開口、閉口画像に切り替えます。
開口/閉口の判定は前回サンプリングしたスペクトルの合計(prevSpec)と現在サンプリングしたスペクトルの合計(totalSpec)を比較し、前回よりスペクトルの合計が大きい(=音の強度が高い)時は開口、反対に小さい(=音の強度が弱くなった)時は閉口するようにします。
もうひと手間加える
↑のリップシンク処理の結果はこのようになりました。

リップシンク自体はそれなりにできていますが、どうしてもパクパク感がでています。
そこで一工夫入れます。
先ほどは閉口 or 開口でしたが、その中間を加えます。
まず、中間の口の画像を用意します。開き具合の小さい画像にします。
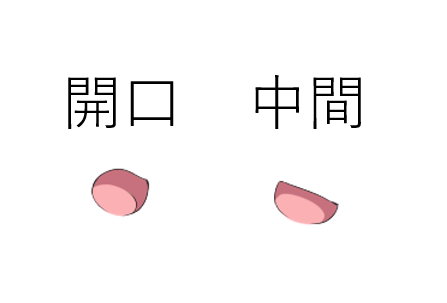
そして、リップシンクの開口・閉口判定処理に中間の条件を追加します。
中間の条件は前回とのスペクトラムの差分がそこまで大きくない場合にします。
syncLip = (spectrums) => {
let totalSpec = 0
const totalSpectrum = spectrums.reduce(function(a, x) { return a + x })
if (totalSpectrum > prevSpec) {
mouseElement.src = './mouse_open.png'
} else if (prevSpec - totalSpectrum < 1000) {
mouseElement.src = './mouse_open_light.png'
} else {
mouseElement.src = './mouse_close.png'
}
prevSpec = totalSpectrum
}
この条件で行った結果

こんな感じで冒頭の動画のような滑らかなリップシンクになりました。
おわりに
- 初めてのqiita投稿の割に癖の強い記事になりましたが、面白い取り組みができました。
- Web Audio APIで音声解析までできるのは驚きでした。波形が取れるので例えばビジュアライザーみたいなのを作ってサイトの演出の一部に使うなんてことも面白そうです。(最近は自動再生が禁止になっているのでそのあたり考えないといけない部分はあるかもしれませんが。)
- スペクトラムを使うリップシンクもどきでしたが、言葉を発している・発していないに合わせる分には十分表現できていると思いました。とても満足です。いや、満足どころか感動しています。
長くなりましたが、以上です。ありがとうございました![]()