きっかけ
ライブラリを色々みて回っていたら、めちゃめちゃスターされているリポジトリがあったのでみに行ってみると、
色々なデータ構造やアルゴリズムをJSで実装しているというすごいリポジトリでした。
https://github.com/trekhleb/javascript-algorithms
なかなかJSでのデータ構造/アルゴリズム関連の実装例をまとまった形でみることはできないので、「ふむふむ」と読んでいたのですが、読むだけでは自分の脳が追いつかない部分があったので、下記のルールで独自にTypeScriptで書き直していこうと思いました!
【ルール】
- TypeScriptで書くこと。
- つまづいたりわかりづらく感じたところは日本語でコメントをつけていくこと。
- 自分の好きな書き方にリファクタしてもOK
- 一部の主要なメソッドだけ抜き出して書く
そして今回は トライ木の項目を書きました。
github:takanokana/ts-study-algorithm
トライ木(trie)とは
木構造の一種で、各ノードにキーを持ち、rootから順番に辿っていく構造となっています。
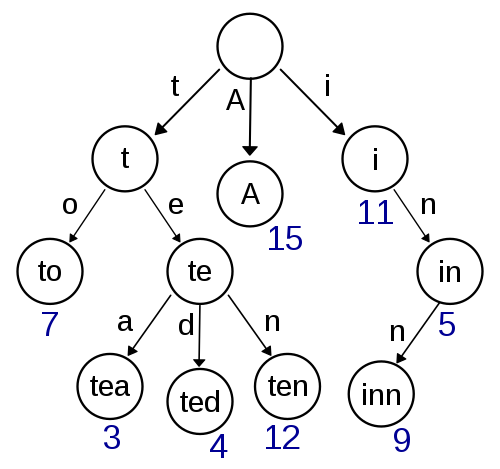
画像はWikipediaより
トライ木の良いところは、検索が非常に高速に行える点です。
例えば100万個の単語をトライ木に登録したとしても、rootから順に文字を検索していけばいいので文字の長さ分だけの計算コストを払うだけですみます。
TypeScriptでの実装
まずはトライ木を形成するためのNodeにあたるクラスを実装します。
このNodeは、
- キーとなる文字
char - 単語の最後かどうかのフラグ
isLastChar - そのノードが持つ子ノードの一覧
children
をコンストラクタで定義しています。
export default class TrieNode {
// 保持する文字
char: string
// 文字列の最後であるか。 car/carpetどちらも登録されている際に、切れ目がわかるように。
isLastChar: boolean;
// 直下子ノード
children: Map<string, TrieNode>
constructor(char?: string, isLastChar = false) {
this.char = char
this.isLastChar = isLastChar;
this.children = new Map()
}
/** 直下子ノードの取得 */
getChild(character: string) {
return this.children.get(character)
}
/** 直下子ノードの追加 */
addChild(character: string, isLastChar: boolean) {
// ない場合は新規でNodeを作成
if(!this.children.has(character)) {
this.children.set(character, new TrieNode(character, isLastChar))
}
const childNode = this.children.get(character)
childNode.isLastChar = childNode.isLastChar || isLastChar
return childNode;
}
/** 直下子ノードの削除 */
// 1.子コンポーネントを持たないこと
// 2.isLastCharがfalseであること(deleteWordでisLastCharをはずす)
removeChild(character: string) {
const childNode = this.getChild(character)
if(
childNode
&& !childNode.isLastChar
&& !childNode.hasChildren()
) {
this.children.delete(character)
}
}
/** 該当ワードが存在するか */
hasChild(character: string) {
return this.children.has(character)
}
/** 子Nodeを持っているかどうか */
hasChildren() {
return this.children.size !== 0
}
}
各Nodeの情報は木本体が管理するのではなく各Nodeがchildrenにて管理します。
次に木本体のクラスです。
木はrootのNodeの情報を持つのみです。
import TrieNode from './TrieNode';
export default class Trie {
head: TrieNode
children: TrieNode[]
constructor() {
this.head = new TrieNode();
}
/** 文字列の挿入 */
insertWord(word: string) {
const characters = Array.from(word)
let currentNode = this.head
for(let charIndex = 0; charIndex < word.length; charIndex++) {
const isLastChar = charIndex === characters.length - 1
currentNode = currentNode.addChild(characters[charIndex], isLastChar)
}
}
/** 文字列の削除 */
deleteWord(word: string) {
const depthFirstDelete = (currentNode: TrieNode, charIndex = 0) => {
// 指定単語の長さのスコープを抜けた場合は何もしない
if(charIndex >= word.length) return
const character = word[charIndex]
const nextNode = currentNode.getChild(character)
// トライ木にない文字がある場合はreturn
if(nextNode == null) return
depthFirstDelete(nextNode, charIndex + 1)
// ここから先は、再帰なので文字末端から呼ばれていく
// isLastCharをはずすことで削除可能にする
if(charIndex === (word.length - 1)) {
nextNode.isLastChar = false
}
// nextNodeは以下の場合のみ削除する。
currentNode.removeChild(character)
}
depthFirstDelete(this.head)
return this
}
/** 指定単語が存在するかどうか */
doesWordExist(word: string) {
const lastCharacter = this.getLastCharacterNode(word)
// 最後の文字のnodeがあり、最後の文字フラグが立っていればOKs
return !!lastCharacter && lastCharacter.isLastChar
}
/** 最後の文字と紐づくNodeを取得 */
private getLastCharacterNode(word: string) {
const characters = Array.from(word)
let currentNode = this.head
for (let i = 0; i < characters.length; i++) {
if(!currentNode.hasChild(characters[i])) return
currentNode = currentNode.getChild(characters[i])
}
return currentNode
}
}
少し長いので主要なメソッドを切り出します。
文字列の挿入
/** 文字列の挿入 */
insertWord(word: string) {
const characters = Array.from(word)
let currentNode = this.head
for(let charIndex = 0; charIndex < word.length; charIndex++) {
const isLastChar = charIndex === characters.length - 1
currentNode = currentNode.addChild(characters[charIndex], isLastChar)
}
}
こちらでは、実際に辞書に単語を登録するためのメソッドです。
単語内の文字列をforで回して文字を登録していきます。
1文字目が2文字目の子に、2文字目が3文字目の子に...となるようになっていますね。
また、どこが単語の最後かわかるようにフラグを登録しています。
文字列の削除
/** 文字列の削除 */
deleteWord(word: string) {
const depthFirstDelete = (currentNode: TrieNode, charIndex = 0) => {
// 指定単語の長さのスコープを抜けた場合は何もしない
if(charIndex >= word.length) return
const character = word[charIndex]
const nextNode = currentNode.getChild(character)
// トライ木にない文字がある場合はreturn
if(nextNode == null) return
depthFirstDelete(nextNode, charIndex + 1)
// ここから先は、再帰なので文字末端から呼ばれていく
// isLastCharをはずすことで削除可能にする
if(charIndex === (word.length - 1)) {
nextNode.isLastChar = false
}
currentNode.removeChild(character)
}
depthFirstDelete(this.head)
return this
}
削除指定された単語の各文字ごとにdepthFirstDelete を呼び出していきます。
再帰なので、一番最後の文字からcurrentNode.removeChild(character)で(削除可能であれば)削除されていきます。
削除していい文字とは、
- 1.子コンポーネントを持たないこと
- 2.isLastCharがfalseであること(deleteWordでisLastCharをはずす)
1は当然、子コンポーネントがあるということは他の単語の要素になっているので削除することはできません。
2は上記コード内にて
if(charIndex === (word.length - 1)) {
nextNode.isLastChar = false
}
を実行していますので、削除申請された単語のフラグだけが折れるようになっています。
使い方
import Trie from './Trie'
const trie = new Trie();
trie.insertWord('test') // testという単語を登録
trie.insertWord('tonight') // tonightという単語を登録
trie.insertWord('terser') // terserという単語を登録
console.log(trie.doesWordExist('dog')) // false
console.log(trie.doesWordExist('tes')) // false
console.log(trie.doesWordExist('test')) // true
しっかり動いています。