Kaggle Advent Calenderの14日目の記事です。13日目はあらいさんの記事「CompetitionだけではないKaggleの魅力」でKaggleのCompetition以外の部分を非常にわかりやすくまとめてくださっています。15日目はちずちずくんの記事「機械学習実験環境を晒す」で、こちらもとても勉強になりましたのでぜひご覧ください。
私の記事では2020年にKaggleで開催された画像分類コンペの1位の手法を振り返っていきたいと思います。コンペ終了後に金メダルだったチームが共有してくれる解法はどれも勉強になりますが、1位のチームはその中でも特に磨きがかかっているものが多いと思います。この記事ではコンペの概要や難しかったところをまとめつつ、金メダルの中でも特に差を分けて1位になったところを私なりに分析できればと思っています。
ホントは画像を含むすべてのコンペを紹介したかったのですが、今回は**「画像分類」が課題でメダルが付与されるコンペティションにしぼりました。ですが、それでも2020年に8コンペ開催されていたので、そこそこのボリュームにはなりました。
私が参加してないコンペティションもいくつかあり、そちらについてはポイントや着目すべき箇所がずれているかもしれません..もし「もっとここが大事だったぞ!」**とかあれば教えていただけると嬉しいです!
最後に、ハードなコンペを戦い抜いたあとに素晴らしい解法を共有していただいている1位のチームの方々には感謝の気持でいっぱいです。本当に有難うございます。
紹介するコンペ一覧
[1.Bengali.AI Handwritten Grapheme Classification](#1-Bengali.AI Handwritten Grapheme Classification)
[2.Deepfake Detection Challenge](#2-Deepfake Detection Challenge)
[3.Prostate cANcer graDe Assessment (PANDA) Challenge](#3-Prostate cANcer graDe Assessment (PANDA) Challenge)
[4.ALASKA2 Image Steganalysis](#4-ALASKA2 Image Steganalysis)
[5.SIIM-ISIC Melanoma Classification](#6-SIIM-ISIC Melanoma Classification)
[6.Google Landmark Retrieval 2020](#7-Google Landmark Retrieval 2020)
[7.Google Landmark Recognition 2020](#8-Google Landmark Recognition 2020)
[8.RSNA STR Pulmonary Embolism Detection](#9-RSNA STR Pulmonary Embolism Detection)
おわりに
1. Bengali.AI Handwritten Grapheme Classification

- Link: https://www.kaggle.com/c/bengaliai-cv19
- 開催期間: 2019/12/19 ~ 2020/3/9
コンペ概要
こちらのコンペはベンガル語の部首を分類する問題でした。1つの単語からGrapheme root(168クラス)、Consonant diacritic(11クラス)、Vowel diacritic(7クラス)の3つタイプの部首のそれぞれのクラスを予測する課題でした。データは、画像サイズが(137, 236)のグレースケールで約20万枚です。
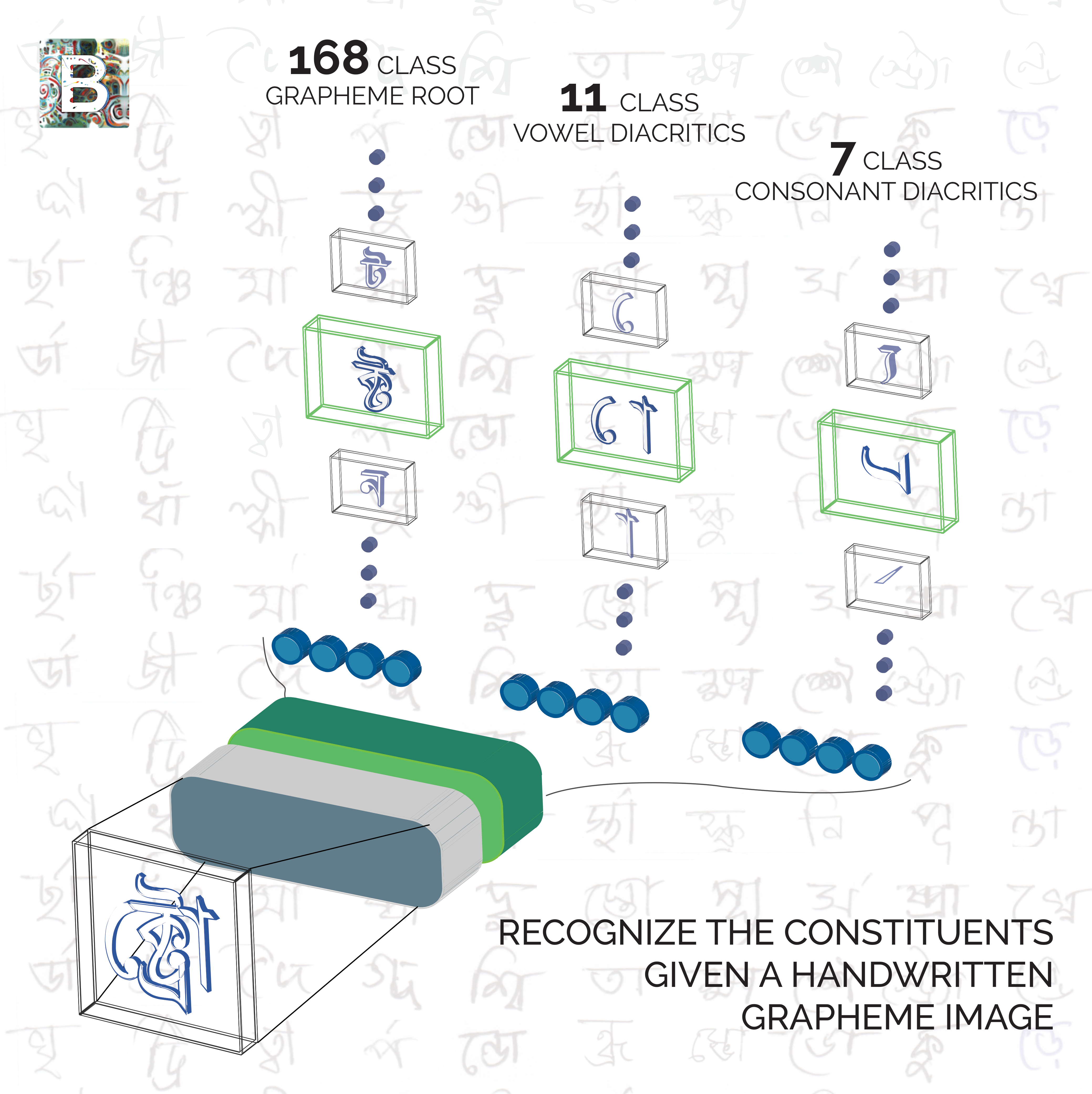
課題としては非常に取り組みやすいものだったと思います。コンペ中盤では様々なAugmentationの方法が議論されており、そのコードは今でも役立っています。
Kernel: AugMix based on albumentations
Kernel: GridMask
評価指標はMacro-averaged Recallでした。3つの部首のうち一番の基礎となる部首については2倍のWeightがかけられていました。この評価指標の特性を理解して、クラスバランスを考慮した補正をかけることでかなりスコアが上がったようです。
Discussion: 14th Place - Hacking Macro Recall - Chris Writeup
ポイント
このコンペのポイントは未知の単語に対する対応です。テストデータには訓練データにはない単語が存在しており、単純に1つの単語画像から各部首のクラスを学習してしまうと、モデルが部首の組み合わせを覚えてしまい、未知の単語の新たな部首の組み合わせに対し性能を発揮できませんでした。
金圏のチームはMetric learningなどで訓練データに存在する単語かどうかを判定した後、未知の単語には別の方法で学習した識別器を用いるという方法が多かったように感じます。
1st place solution
Link: https://www.kaggle.com/c/bengaliai-cv19/discussion/135984
1位の解法はGANを用いた非常にエレガントな手法でした。図はDiscussionの引用です。
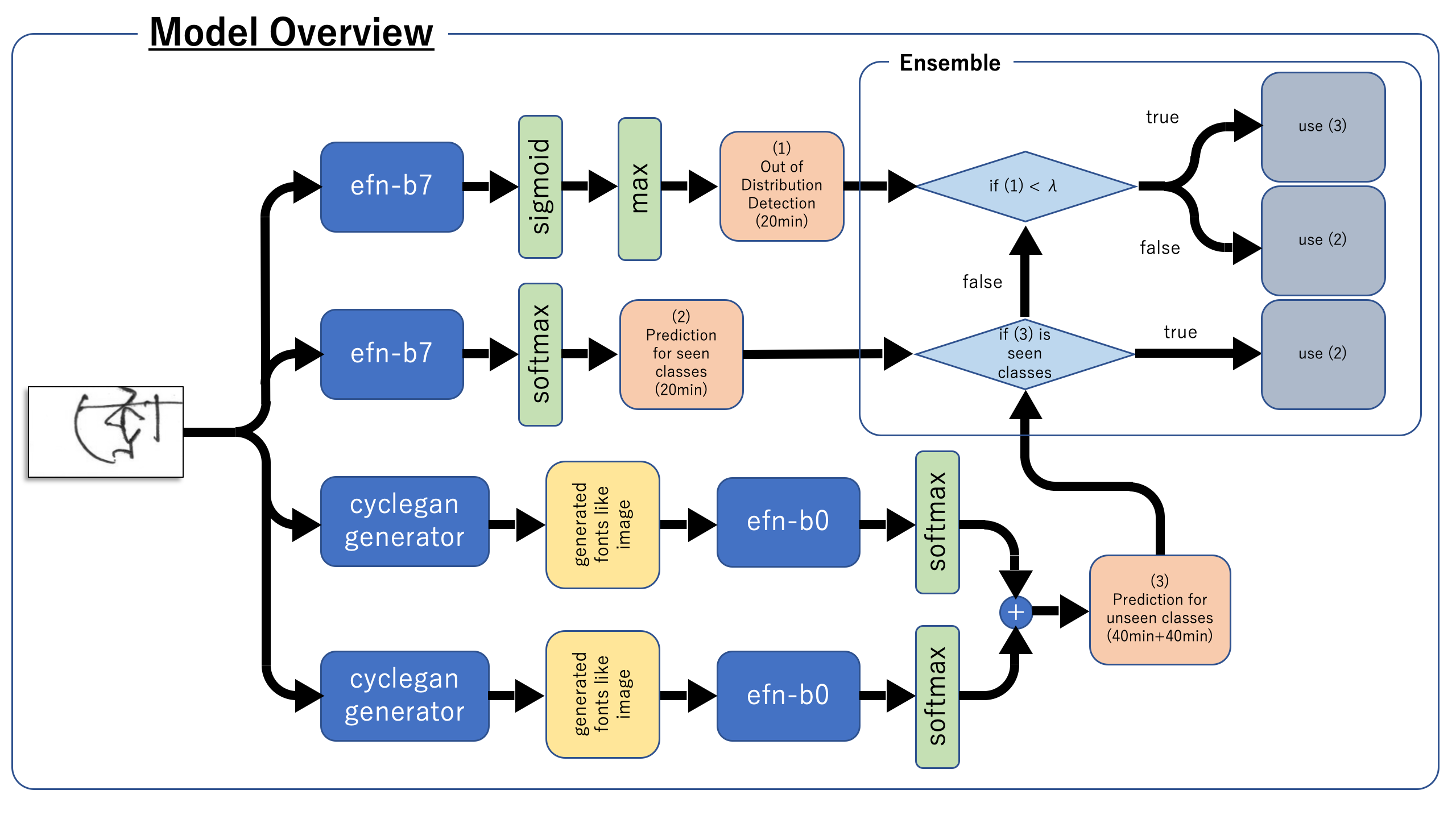
大きな流れは、
- CycleGANで手書き文字をフォント文字に変換
- すべての文字を作成し、文字レベルでクラス分類
- 文字レベルの分類器で未知/既知を分ける。
- 既知のものは訓練データをしっかり使って学習、予測
- 未知についてはさらにOut of Distribution modelで未知判定
- 未知のものは文字レベルの分類機で予測
このコンペでは与えられたデータから部首を組み合わせて文字を作り画像として保存することができました(このときフォントを指定可能)。それで部首の組み合わせで起こりうるすべての単語を作ってCycleGANで学習し、手書き文字をフォント調に変換させていました。その後、EfficientNetB0でどの単語に属するかを文字レベルで分類しています。それが図の下二段のパートになります。2つあるのは2種類のフォントでモデルを作ったからです。訓練に存在しない未知の単語については、この分類機の結果を予測値としています。
さらに図の一番上のパートでは、既知の各単語についての2値分類を行い(単語ごとにSigmoid → Binary Cross Entropy)、それでどの単語にも属していないものについても同じくEfficientNetB0での予測値を最終結果としています。
最後に、既知の単語については、図の上から二段目のモデルでどの単語に分類されるかを予測していました。多くの参加者は、どの部首に属するかを予測していたのに対して、単語単位での予測を行っていたところもユニークだと感じました。
ソロでこのCycleGANを用いたパイプラインを考え、実装しきって1st placeをもぎ取っているのは圧巻でした。
2. Deepfake Detection Challenge
- Link: https://www.kaggle.com/c/deepfake-detection-challenge
- 開催期間: 19/12/11 ~ 20/3/31
コンペ概要
こちらのコンペは動画に写っている人の顔が本物か偽物か、Deepfakeで作られたものかを当てるという課題でした。動画単位でFakeかどうかの2値分類で評価指標はLoglossでした。
データは合計500GB近くあり、比較的大きめのデータセットでした。動画は約10秒で30FPSなので、一つの動画あたりの画像数は300枚。またFakeの動画の場合、元となった本物の動画も与えられていたようです。
このコンペでは一度1位になったチームが外部データのライセンスの関係で資格を失うといった悲しいことが起こったコンペでもあります。賞金総額が$100万と非常に高いということもあいまってか、この事件はKaggleの枠を超えて注目されていたと思います。
ポイント
このコンペは珍しく動画形式ということでどう取り組むかが最初は難しかったと思います。動画のフレームを使うだけでは精度が出ず、顔をクロップしてきて学習するのが1つポイントだったかなと思います。顔を抽出するモデル自体は使用しやすいGithubがあり、意外と難しくないようにも感じました。しかし、コードコンペティションということもあり、それを組み込んでパイプラインを作るのは想像よりも大変だと思います。
1st place solution
Link: https://www.kaggle.com/c/deepfake-detection-challenge/discussion/145721
Github: https://github.com/selimsef/dfdc_deepfake_challenge
1位の方のポイントをまとめてみました。
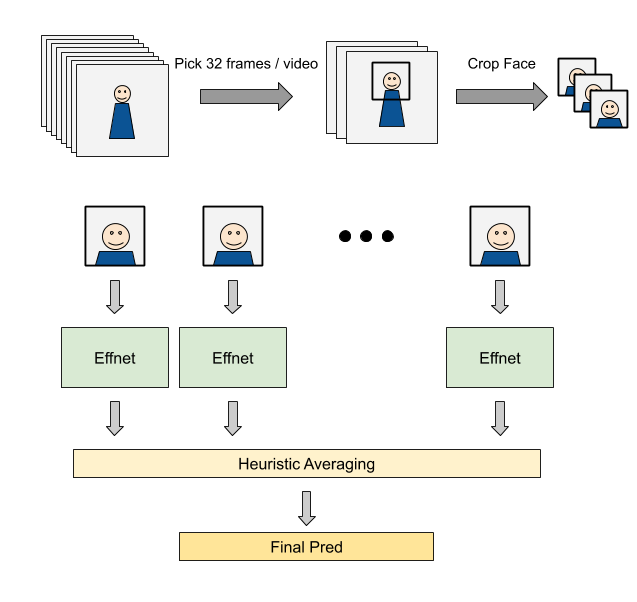
- 動画に合わせて入力サイズを調整し、facenet-pytorchで顔検出。30%上下左右にマージンを取る。
- EfficientNetがスコアが良かった。EfficientNetB7が一番良くてSeed averageなども含め多くのモデルをアンサンブルしている。
- 1つの動画につき32フレーム使用。
- 32フレームの予測からヒューリスティックな方法で動画の予測値を計算
- もし1/3以上のフレームがある閾値よりもFakeと予測していたら、閾値以上の予測値のみを平均:よりFakeの予測
- もし30%以下がある閾値よりもRealだと予測していたら、閾値以下の予測値を平均:よりOKな予測
- それ以外は、単純に32フレームの予測を平均
- ValidationのときRealの動画に対するloglossとFakeの動画に対するloglossの2つをチェック
- 顔の一部を覆ったり、目や鼻を隠すような独自のAugmentationを使うことで汎化能を向上
動画ということでRNNを試したチームも多くいたようですが、今回のケースでは機能しなかったようです。動画中の顔がFake or notなので時系列情報は必要なさそうなので納得ではあります。
もう一つ面白いアプローチとして、Segmentationのモデルを使用したものがありました。FakeについてはRealの動画も与えられていたので、FakeとRealの差分などをマスクとしたSegmentationのタスクを一緒に学習させるという方法です。スコア向上につなげることができたチームもいたようですが、1位の方はDidn't workだったそうなので、結局シンプルな分類モデルで十分強かったようです。
3. Prostate cANcer graDe Assessment (PANDA) Challenge
- Link: https://www.kaggle.com/c/prostate-cancer-grade-assessment
- 開催期間: 2020/4/21 ~ 2020/7/22
コンペ概要
こちらのコンペは前立腺癌の組織の画像を用いて生検の精度を競うものでした。データ数は10000万枚程度でしたが、医療画像なので1枚1枚が高解像度でデータサイズは400GB近くありました。評価指標はquadratic weighted kappaでISUPという5段階のGradeを予測します。データセットはDarolinska、Radboudという2つの組織から収集されており、提供組織によって若干データの雰囲気が違いました。またピクセルレベルでISUPのグレードが記述されているマスクが与えられているのもあ特徴的でした。しかし、このあたりは最終的な結果にそれほど影響しなかったようです。

ポイント
上手のようにスライドガラスに切片が貼り付けられているような画像なのですが、ただでさえ大きな画像をこのまま学習させると白いスペースが大きく非効率です。そこで効率的に組織片のある領域をクロップしてきて左上から順番に並べていく方法がKernelに投稿され、ほぼすべてのチームがこちらの方法を使用したと思います。
Kernel: PANDA 16x128x128 tiles
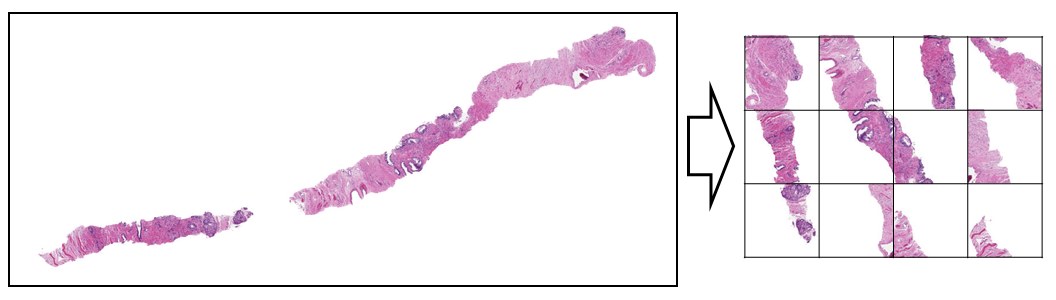
(図はKernelより引用)
これをもとに作成されたKernelが今回のコンペティションのベースになっていました。
Kernel: Train EfficientNet-B0 w/ 36 tiles_256 [LB0.87]
また、与えられた訓練データは非常にNoisyでした。これについてはちゃんと情報が提供されていて、Karolinskaでは1人の専門家によって、Radboudは医学部の学生がラベルを付けていたようです。一方で、テストデータは3人の専門家によってラベル付けされているので比較的正確だと考えられます。
また、非常に似ているデータも訓練データにはありました。これについては、カーネルで画像をハッシュ化して類似度を計算し、似ている画像は除くといった方法がとても参考になりました。
Kernel: Imagehash to detect duplicate images
1st place solution
Link: https://www.kaggle.com/c/prostate-cancer-grade-assessment/discussion/169143
Slide: https://docs.google.com/presentation/d/1Ies4vnyVtW5U3XNDr_fom43ZJDIodu1SV6DSK8di6fs/edit#slide=id.p
スライドが非常に美しくまとまっていますので、ぜひご覧ください。
Denoisingが重要なこのコンペで1位のチームはシンプルにターゲットからより離れているデータを取り除いています。これにより、データ数はけっこう落ちるようですが、Privateは専門家3人でラベリングしたクリーンなデータということもあり、厳選されたクリーンなデータで学習させることが優勝に繋がったようです。
私が1位の解法で非常に勉強になったなと思ったのは、Foldの切り方でした。画像の類似度を計算して似ている画像を取り除くのではなくて、同じFoldに入れることでCVが安定したそうです。これにより、Denoisingの効果も更に高まったのではないかと予想しています。
またターゲットを評価対象であるISUP gradeだけではなくて、その一歩手前のGleason scoreの1つめ(左側)も一緒に学習させていまいた。こういった細かなところもとても参考になるSolutionでした。
4. ALASKA2 Image Steganalysis

- Link: https://www.kaggle.com/c/alaska2-image-steganalysis
- 開催期間: 2020/4/27 ~ 2020/7/20
コンペ概要
こちらのコンペは秘密情報が画像に埋め込まれているかどうかを予測するコンペティションでした。この秘密情報を画像などに埋め込む技術をステガノグラフィーというのですが、ぱっと画像を見ただけでは秘密情報を埋め込まれているかどうか全くわかりません。
こちらが実際のデータになります。

JMiPOD、JUNIWARD、UERDがステガノグラフィーの技術を表しています。75,000枚種類の画像があり、それぞれにつきOriginalと上記3種の方法で秘密情報が埋め込まれた画像がjpegファイルで訓練画像として提供されていました。
評価指標はWeighted AUCで、True Positive Rateの値が0.4以下のものには2倍のWeightがかかっていました。
ポイント
ステガノグラフィーの検出ではカラースペース(特にYCbCr)と離散コサイン変換の係数(DCT coefficient)が重要なポイントになったようです。これはJPEGの圧縮アルゴリズムの途中に出てくるもので、秘密情報の埋め込みはそういったところが関係しているようです。以下のKernelの途中にわかりやすくまとまっていたので参考にしてください。
Kernel: Steganalysis:Complete Understanding and Model, Had-we-been-doing-it-all-wrong?
DCT coefficientsについては以下のKernelの説明が分かりやすかったです。画像には空間領域と周波数領域があり、DCTを使うことで画像を空間領域から周波数領域に変換できるようです。
Kernel: Updated AUC + DCT(Discrete Cosine Transform), 5. DCT (Discrete Cosine Transform) coefficients
上位に食い込むには、このDCTをうまくモデルで学習して予測に加えることが重要だったようです。
1st place solution
Link: https://www.kaggle.com/c/alaska2-image-steganalysis/discussion/168548
1位のチームのポイントです。
- Spatial domain modelとDCT domain modelを別々に学習。
- Spatial domain modelは秘密情報が消えないようにモデルを少し修正
- 2つのモデルの中間層を用いて2nd stage学習
- AugmentationはCutmixが特に有効
パイプラインを図示してみました。
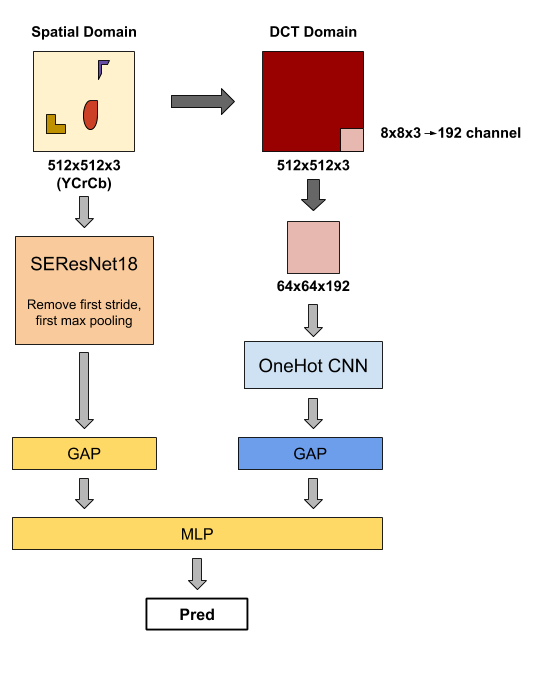
1st stageでSpatial domainを学習させるために用いたモデルは、最初の畳み込み層のStrideと最初のMaxpoolingを抜いています(おそらくこの辺 torchvision resnet)。そうすることで、モデルの特徴マップの解像度が高い状態で保たれるので埋め込まれた秘密情報が失われないようです。ResNet18を使用してはいますが、この変更により計算量はかなり増えてとても複雑なモデルになっています。
DCT domainモデルではこちらの論文(An Intriguing Struggle of CNNs in JPEG
Steganalysis and the OneHot Solution)を参考にモデルを作成しています。この論文は2020年に出たばかりのもので、情報収集の早さと範囲の広さの凄さがわかります。
DCT domainのモデル自体はそこまでスコアは高くないのですが、最後に中間層を用いた2nd stageのモデルを用いることで一段とスコアを向上させていました。
5. SIIM-ISIC Melanoma Classification

- Link: https://www.kaggle.com/c/siim-isic-melanoma-classification
- 開催期間: 2020/5/27 ~ 2020/8/17
コンペ概要
こちらのコンペは皮膚の写真からメラノーマかどうかを2値分類で予測する課題でした。訓練画像は約33,000枚、テスト画像は約10,000枚で最近では珍しくCSVを提出するタイプの課題でした。評価指標もROC AUCととてもわかり易いものでした。難しいところとして、訓練画像33,000枚のうちメラノーマの画像が600枚弱しかなく、かなりなりInbalanceなデータセットでした。画像の他にメタ情報として、患者のID、性別、おおよその年齢、体のどこの部位の写真か、詳細な診断、良性腫瘍かどうか、そして最後にメラノーマかどうかのターゲットがありました。
このコンペティションは実は毎年開催されており、今回が始めてKaggleでの開催でした。昨年のものはこちらになります。ISIC 2019
これまでの解法は論文でまとめられており、アンサンブルが特に効きそうな課題だということがわかります。前年と違うところは、これまではメラノーマかどうかだけではなく詳細な診断を予測するクラス分類の問題でしたが、今年はメラノーマかどうかだけを予測するというものでした。
コンペ期間中に公開されたTPUを用いて学習するKernelが非常に強力で、金圏の中でもこのKernelのパラメータを変えてアンサンブルしただけのチームが見られました。Inbalanceで同一画像の患者があるなど適切にCross validationのFoldを切るのが難しいデータでしたが、KFoldの分け方もリークが起こらないようにして、かつバランスをとった完璧なもので、このベースラインを超えるのはなかなか難しかったように感じます。
Kernel: Triple Stratified KFold with TFRecords
TFRecordの作り方からもKernelにあげてくれていたので、もしTPUを使ってみたい方がいればこちらのKernelはとても参考になると思います。
Kernel: How To Create TFRecords
またImagenetで学習済みのモデルで画像をベクトル化し、tSNEで次元削減をしたこちらのDiscussionもとても面白かったので皮膚の画像が苦手ではない人は見てみてください。
Discussion: View Images with RAPIDS cuML TSNE
InbalanceでかつPublicが30%とすこし少ないこともあり、Public LBに簡単にOverfitしてしまうコンペティションでした。一方で、PrivateはLocal CVと連動していたらしく、Trust CVをしっかりすることが重要なコンペでもありました。
ポイント
多様なモデルをアンサンブルすることでした。とくに様々な画像サイズで学習させたモデルを作ることが効いていたようです。
またターゲットをうまく拡張することが効いたようです。今年のコンペはメラノーマかどうかの2値分類でしたが、メラノーマでないものにはNeviという非常にメラノーマに似ている画像がありました。Discussionでもこの点は言及されており、これをモデルにちゃんと組み込んだチームがトップになっていました。
Discussion: Reached >= 0.966 LB with new idea!!
1st place solution
Link: https://www.kaggle.com/c/siim-isic-melanoma-classification/discussion/175412
Github: https://github.com/haqishen/SIIM-ISIC-Melanoma-Classification-1st-Place-Solution
1位のチームの概要です。
- 前年までのデータも合わせて安定したValidationを作った。
- モデルのアーキテクチャは昨年の1位のチームのもの。
- ターゲットをメラノーマ、Nevi、Unknown、BKLの4クラスにした。
- Hard augmentation
- ランクにしてアンサンブル
モデルのアーキテクチャは昨年の優勝者のものをベースにメタデータも加えたものでした。
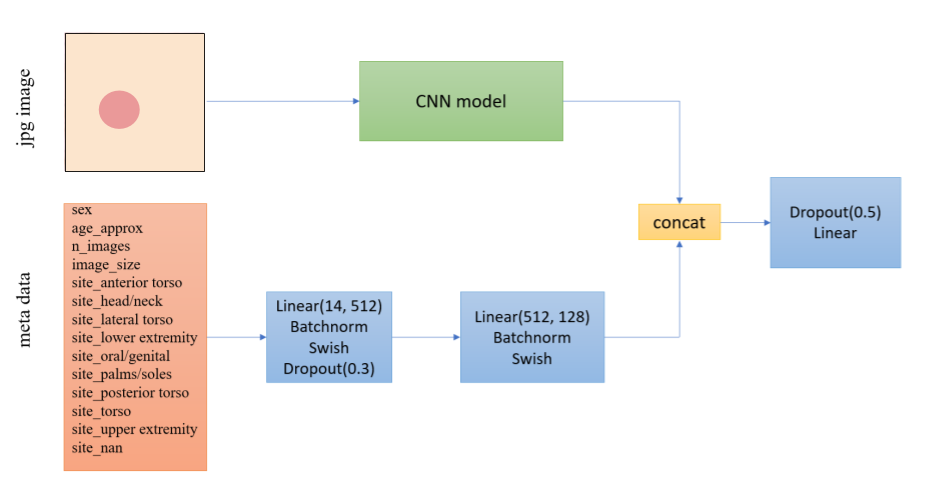
(図はDiscussionより、一部改変)
BackboneはEfficientNetB3~B7を使用。画像サイズは384〜896といろいろなものを使っています。
今年のデータは陽性のデータが少なく、Validationが安定しにくかったようです。より安定したValidationを作るため、昨年までのデータを足したデータセットを使い、CVをしています。そして、今年のデータだけのCVと昨年までのデータをたしたCVの両方をモニターすることでCVが安定したようです。
また、PublicにOverfitしやすいコンペではありましたが、アンサンブルをすることでCVとLBが相関して上がっていったそうです。
ターゲットを細分することでかなりスコアが上がったようです。2位のチームも同じようにしていたのですが、メラノーマに似ているNeviを1つのターゲットとして分けることが重要でした。
6. Google Landmark Retrieval 2020.

- Link: https://www.kaggle.com/c/landmark-retrieval-2020
- 開催期間: 20/6/30 ~ 20/8/17
コンペ概要
2018年、2019年に引き続き今年も開催されたLandmark Retrieval Challenge。与えられたQuery画像と同じランドマークを持つ画像を探し出す課題です。評価指標はmean Average Precision @ 100、つまり100位までのAverage Precisionの平均です。評価指標についてはこちらの記事(「平均適合率」と「MAP」の意味)を参照していただければ雰囲気がつかめるかと思います。
昨年まではCSV提出形式だったのですが、今年は少し特殊な形式でした。Tensorflow 2.2に互換性のあるモデルを作成し、zip fileで提出してKaggle側でそのモデルを実行しスコアを計算するという方法でした。
次に紹介するGoogle Landmark Recognitionと同じデータセットを使用しているのですが、総データ数は訓練データで4,132,914枚あり非常に膨大でした。データとしてKaggleで与えられていたのは昨年のWinnerチームが使用していたCleanなデータセットで、そのサイズは10分の1程度でした。(参考: 昨年のRetrieval/Recognitionの解法 1st/3rd place solution by Team smlyaka)
ポイント
このコンペはベースラインを設計するのが難しかったのではないかと思います。提出形式が特殊で、データ数も多く、Publicに公開されているベストのNotebookを少しでも超えれば銀メダルにという状況でした。
上位陣の解法をみると、ベースを作った上で画像サイズやモデルのBackboneの比較などを行えているように感じました。慣れない形式のコンペで盤石なベースラインを作る忍耐力が必要だったのかなと感じます。
1st place solution
Link: https://www.kaggle.com/c/landmark-retrieval-2020/discussion/176037
arXive: https://arxiv.org/abs/2009.05132
この解法で衝撃的だったのは、Google colabのTPUで取り組んでいたことだと思います。データセットが非常に大きく、大きなリソースが必要と考えられ、ただでさえやりづらいこのコンペをColab TPUで乗り切って1位になったのは驚きでした。
図はDiscussionより引用しました。
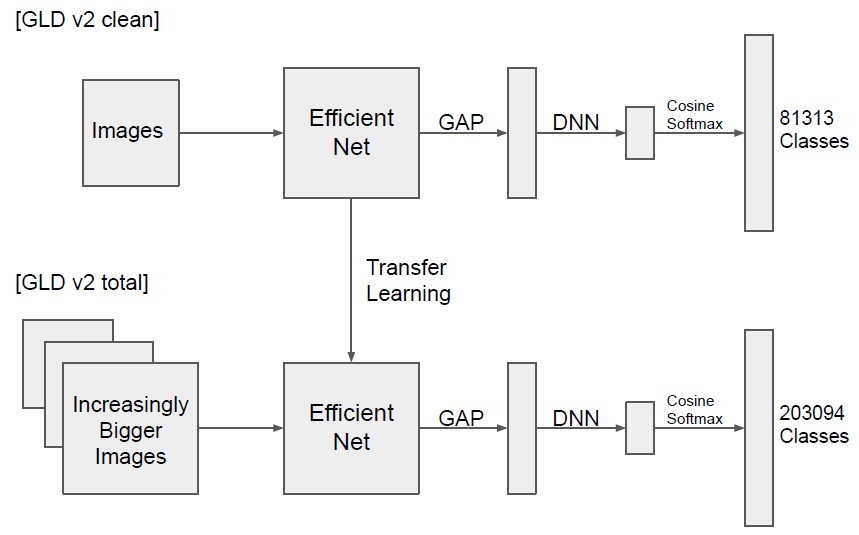
モデルはEfficientNetB5 ~ 7を使用。LandmarkのコンペではGeM poolingがCNNのあとに使われることが多いのですが、この解法ではGAPを使用しています。また最終層はMetric learningで使われるCosineFaceのSoftmaxを使用しており、このあたりもベーシック他の参加者との差分にはなってないように感じます。
他のチームと差分になったのは、おそらくEfficientNetが機能する条件を見つけ出したことなのかなと思っています。まずはじめにCleanなデータセットで学習させたあと全データでの学習を行っています。全データ学習にすることでスコアがGold圏外から一気に5位くらいまで来ています。さらに、その全データ学習のときに、画像サイズを512 -> 640 -> 736とどんどん大きくしており、ここで一段とスコアが上がりすでに1位相当のモデルができています。最後にアンサンブルで2位との差を一気に広げています。
解法を読むと比較的シンプルではありますが、これをColabo TPUでやりきったのは本当にすごいと思いました。
7. Google Landmark Recognition 2020

- Link: https://www.kaggle.com/c/landmark-recognition-2020
- 開催期間: 20/6/29 ~ 20/9/29
コンペ概要
こちらのコンペはRetrievalと同じデータセットをつかって、テストデータであるQueryの画像に近いクラス番号と確信度を出します。評価指標はGlobal Average Precisionというあまり見かけないものです。こちらのKernelの中身を見ていただけると雰囲気をつかめると思いますの参考にしてください。Retrievalと違ってこちらは通常のコードコンペティションだったので比較的参加しやすかったとは思います。RetrievalのSolutionもすでに出揃っており、さらにRetrieval上位の人たちがRecognitionの上位にもいたことから、RetrievalのSolutionを参考に私も少し参戦していました。しかし、こちらもHostのベースライン(学習はこちらのGithub link)を超えるには一筋縄ではいかない感じはありました。
ポイント
このコンペでは、どのようにLocal CVを作るかが一つ目のカギだったようです。TestデータがLandmarkを含まない場合は、「Non landmark」として予測する必要がありました。しかし、KaggleのデータページからダウンロードできるものにはNon landmarkはなかったようで、うまくNon landmarkを加味した検証環境を作ることが難しかったようです。
また、Postprocessingが重要なポイントだと感じました。Postprocessingとは、「Testの画像からCNNで特徴抽出してきたあと、訓練画像から抽出した特徴量と類似度を計算し、どのLandmarkを持つ画像と似ているかをランク付けするところ」のところを指しています。ここをうまくやることが最後の差分になったのではないかと思いました。
1st place solution
Link: https://www.kaggle.com/c/landmark-recognition-2020/discussion/187821
Github: https://github.com/psinger/kaggle-landmark-recognition-2020-1st-place
arXive: https://arxiv.org/abs/2010.01650
Modelは比較的シンプルでした。
- ArchitectureはSEResNeXtに加えEfficientNetB3やResNet152, Res2Net101など7個使用
- リサイズした後、クロップしたデータで学習し、推論時はクロップなしで予測
- Backboneのあとはどのモデルも512次元にして、最終層はArc Margin Head
重要なポイントの1つ目であるValidation戦略について、配布されたデータにはLandmarkが含まれていない画像はなかったので、昨年のテストセット(ラベル公開済み)をValidationに使用していたようです。また、訓練データは、Validationに存在するラベルのみを使用しています。その結果、Local CVとPublic LBの値がとてもきれいに相関したそうです。
またRetrievalの1位の解法とは違い、データセットは厳選されたCleanのものだけを使用していました。これもValidation戦略がうまくいっていたからこそ、小さいデータセットでも多くの検証を重ねて精度向上に結びつけられたのかなと思います。
もう一つのポイントとしてあげたPostprocessingもほかのチームとは違った方法で、Non landmarkのデータをうまく使い正則化をしていました。
 (図はDiscussionより引用)
(図はDiscussionより引用)
若干番号は異なりますが、論文を参考にどのような処理を行っているかを説明したいと思います。
- テストデータと各訓練画像のCosine類似度を計算(A)
- 訓練画像とNon landmark画像のCosine類似度を計算し、上位5個のNon landmarkの類似度の平均を計算(B)
- A - Bをすることで、Aを正則化
- あるテストデータに対して、類似度の高い上位3つの画像を選択する。
- もし選ばれた画像が同じクラスにほかの画像を持っていたら、その画像の予測値も平均して、そのクラスの確信度とする。
- 最も高い確信度のクラスを選択
- テストデータもNon landmarkと類似度計算して、上位10個のNon landmark確信度の平均を計算(C)
- 6.の確信度からCを引いたものを最終の確信度とする。
Non landmarkのデータをただ単に加えるだけでも一定の効果はあったようですが、このようにNon landmarkは別で類似度を計算してそれを確信度から引くことで、Non landmarkっぽい画像がうまく予測に反映されたようです。
8. RSNA STR Pulmonary Embolism Detection
- Link: https://www.kaggle.com/c/rsna-str-pulmonary-embolism-detection
- 開催期間: 20/9/9 ~ 20/10/26
コンペ概要
こちらも毎年恒例のRSNA主催のコンペティションになります。RSNAは北米放射線学会のことで、毎年それ関連の画像のコンペティションが開かれています。今年は肺のCT画像から肺血栓塞栓症(Pulmonary Embolism, PE)が存在するかどうかを予測するコンペティションでした。
データ数は約7,300人の患者の肺のスライス画像が合計180万枚 DICOM fileで用意されており、サイズも1TB近くありました。
このコンペは評価指標が非常にややこしかったです。画像単位でPEが存在するかに加えて、患者単位でもPEが存在するかどうかを予測するいつようがあります。さらに、患者単位の予測にはPEがどこにあるか、右と左どちらの体積が大きいか、急性か慢性かといったラベルも予測する必要がありました。それぞれについてLogLossを計算し、Weightをかけたものがスコアとなります。
しかし、更に評価指標をややこしくする要因としてLabel consistencyという制約がありました。例えば左下のPEがどこにあるかという項目では、少なくとも1つ以上は0.5を超えていないとダメ、その横の左右の体積はどちらか一つだけ0.5を超えていないとダメ、といったもので、これを満たしていないと入賞資格が与えられませんでした。
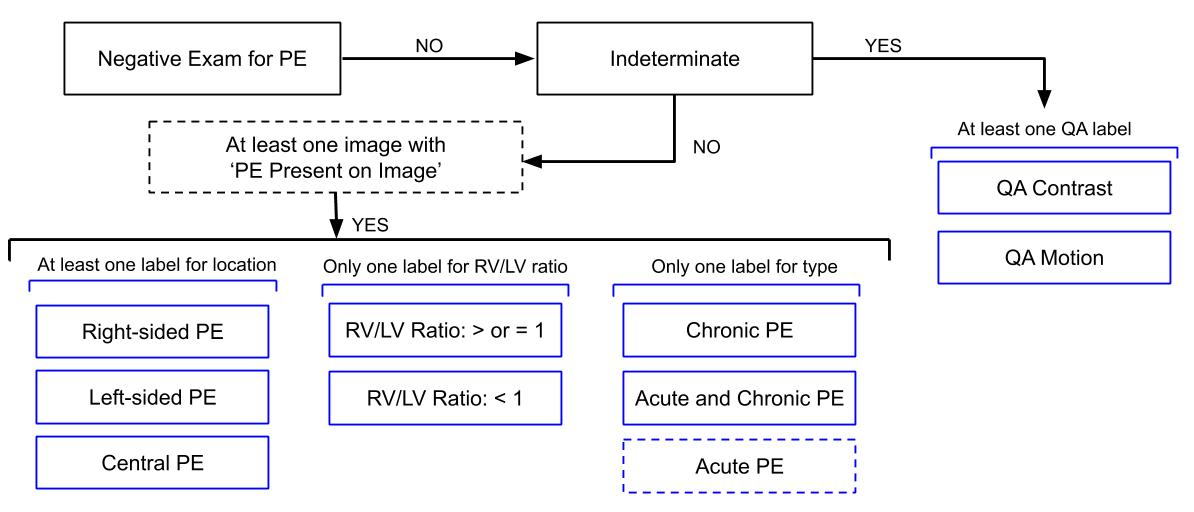
(図はDataの項目より引用)
ポイント
今年の課題は昨年と組織は違いましたが性質は非常に似ており、昨年の解法がそのまま使えたそうです。部分的にも去年の上位の解法を用いてスコアの向上に繋がったと言っているチームはたくさんありました。去年の解法については、以前私がまとめた記事がありますのでよろしければそちらも参考にしてください。
《Kaggleコンペ紹介》RSNA Intracranial Hemorrhage Detection ~CT画像から頭蓋内出血のタイプ分類~
基本的な戦略としては画像ごとに予測を出し、画像を順番に並べてRNNで前後の結果もふまえた予測を出すことです。
またハイスコアに重要なポイントは、高い解像度の画像を使うことだったようです。これまでのコンペもそうですが、医療画像の場合は高解像度の画像を使うことが精度向上に不可欠なようです。
1st place solution
Link: https://www.kaggle.com/c/rsna-str-pulmonary-embolism-detection/discussion/194145
Github: https://github.com/GuanshuoXu/RSNA-STR-Pulmonary-Embolism-Detection
 (図はDiscussionを引用、一部改変)
(図はDiscussionを引用、一部改変)
1位のポイントはより高解像度にするために肺をDetectionして、その領域をとってきたところだと思います。これにより、より高い解像度の肺を使うことができました。オリジナルの画像サイズが512x512ですが、肺をクロップしてきて、かつ576x576にリサイズしているのでとても高解像度になっています。肺をDetectionするためには、患者ごとに4枚抜き出してきて、Bounding boxをハンドラベルしたようです。(GithubにハンドラベルしたCSVも上がっていたので気になる方は見てみてください。)その後、EfficientNetB0を使ってBBoxの値を直接回帰で予測しています。
1st stageのモデルは画像ごとにPEがあるかどうかの2値分類をしています。
2nd stageではそのモデルの中間層を取り出してきて、CT順に並べてRNNにかけています。このとき、患者ごとにCT画像の枚数は違うのですが、それを揃えるためにcv2でリサイズし、最後にまたもとの数にリサイズして戻していたのも印象的でした。2nd stageの3つ目の矢印のところは、前後のCT画像の中間層の値を結合してベクトルを作っています。これは去年のRSNAコンペ 3位の方の解法に着想を得て行ったようです。
おわりに
最後に1位の解法を眺めてみて大事だと思ったこと、2021年コンペに取り組む際に気をつけたいことを軽くまとめたいと思います。
安定したValidation
当たり前すぎることかもしれませんが、安定したValidationを作ることはやはりコンペティションの勝利につながることがわかりました。Local CVとPublic LBが連動しているかどうか、もし連動していないならどこが原因か、連動してはいるがスコアがCVとLBで乖離しているならなにが原因かなどを考察していくことが、コンペの理解につながっているように感じました。
データはどのようにして作られたか
自分が訓練に使っているデータがどのようにして集められたのか、またテストデータは訓練と同じ性質か、Public/Privateはどうか、だれがラベル付をしたのかを考えることでデータの理解が深まり上位へと繋がっているように思いました。ホストが情報を提供してくれていたり、コンペの説明に書かれていたり、論文に上がっていたり、Discussionで取り上げられていたりとデータのことについて知る方法はいくつか考えられますが、こういった情報にしっかりアンテナを貼って置くことは非常に重要だと思いました。そして、この情報は最初にいった安定したValidationの作成のためには必要不可欠だと思います。
質の高い実験
上位のチームに言えることは、どのチームも非常に多くの実験を行っています。しかし、おそらくですがさらにトップに行くには質の高い実験をしないといけないのではないかと考えています。そして質の高い実験とは、しっかりとした仮説に基づいた実験だと思っています。なぜなら上位チームの解法にはその解法に至った理由が明瞭に書かれているからです。特に金メダル常連のチームはその部分がしっかり書かれているように思います。もちろん最初からクリティカルな部分に気づいていたわけではないと思いますが、しっかりと仮説を立てながら実験を重ねることで必然的にそこにたどり着いているのではないかと考えています。
私なんかは気がついたらモデルやハイパラをちょっと変えた程度のモデルばっかり回していることがあります。確かにそのへんのチューニングも大事かもしれませんが、それ以外にもやるべきことはたくさんあると思います。EDAや評価指標のモニターだけでなく、学習した結果どういったデータが簡単か、どういったデータが難しいか、それはどう難しいのか、ラベルノイズか、間違えた結果どのようなところに分類されているか、Grad-CAMなどで可視化してどういう領域を見ているか、評価指標以外の方法でモデルや結果を評価できないか、などなど分析できることはたくさんあります。こういった分析をもとに仮説を導き出して、実験して、また分析するというサイクルをどれだけたくさん回せるかが重要だと感じました。
最後まで読んでいただきありがとうございました。この記事が少しでも参考になりましたら幸いです。