14日目はいのいちさんの【Kaggle】2020年に開催された画像分類コンペの1位の解法を紹介します
です!
16日目は俵さんの黒魔術への招待:Neural Network Stacking の探求です!
Kaggleをやる私に必要なもの
こんにちは、皆さんはKaggleやってますか? 正直なことをいうと、自分はあまりKaggleコンペに参加してないのでエアプ勢になってます。どちらかというとマイナーなコンペばかりに参加してて……
Kaggle(広義)で勝つためにたくさんの実験を回しますが、何も考えていないと後々苦しみます。
僕がコンペに参加してる時のあるあるをまとめます。
- 今日やった実験は明日は忘れてる
- 破壊的変更ばかりする
- commitがだるい
- ソースが汚い
諸々あってそろそろちゃんとした実験環境整えようかなという気になって自分のソースコードを整理してました。その頃にちょうどadvent calendarの時期になってたので折角の機会だしということで共有することにしました。
大事なこと↓↓
コード編
- 再現性
- デバッグしやすい
- 汎用性の高い関数
をデコレータで畳み掛ける!
おおまかなまとめ
- 乱数で実験を固定
これがないと何も始まらない。
- 再現したかったらgitのversionから実験名(乱数)を探す
ちゃんとcommitしようね。でも、面倒なので自動化しちゃおう。
- いつか必要になりそうな情報はちゃんと保存しておこうね
MLflowがあるよ
- コードの中には値を書かないでね
hydraを使ってconfigファイルを作ろう。実験管理がしやすくなるよ。
- 特徴量は列ごとに保存しようね
実行効率が良くなるよ。再現もしやすくなるし。
hydra

yamlファイルに保存されているパラメータを読み込み、pythonファイルで流し込むまでのプロセスをやってくれるライブラリです。
簡単な解説
- yamlファイルを作る(config)
- デコレータをつける
@hydra.main()
def main(cfg):
return None
cfgは辞書型になるのであとはcfg["parameter"]と呼び出すだけです。
MLflow

機械学習に関する実験管理ツールです。実験同士の比較も簡単なのでオススメです。
こちらは下記のリンクの解説がわかりやすいです。
MLflow 〜これで機械学習のモデル管理から API 作成まで楽にできるかも〜
GitPython
見たほうがわかりやすいです。コマンドラインで操作してたことをpythonコードでやるだけです。
もちろん、os.system()のようなことでも代用可能です。
特徴量管理
takapyさんのスライド

takapyさんは下の記事を参考にしています。ここには具体的な実装例が書かれています。
Kaggleで使えるFeather形式を利用した特徴量管理法
自分はこれらの実装に少し手を加えてより使いやすいようにさせました。
列ごとの管理
使いたい特徴量を簡単に呼び出すことができます。また、列ごとにまとめておくことでメモリの効率化も図れます。(全部を呼び出してからカラム指定するのは非効率)
特徴量ごとにクラスを書くのですが、各々の値は干渉しないようになっているので管理も楽になってます。(バグが生まれにくい)
実践ottoコンペ
Otto Group Product Classification Challenge
守ること
- 具体的な値はconfigで
- 再現可能性を重視
- ベタ書きしない(関数を使う)
tree
軽く説明しておきます。
- data: 基本的にデータの保管庫
- config: hydraで読み込むためのyaml形式のconfig
- feature: あとで説明する。特徴量(.pkl)とその説明(.csv)が入る
- src: ソースコードを置く
- outputs: submitする用のファイルを置く
.
├── README.md
├── config # hydraで呼び出す
│ └── config.yaml # メインのconfig(ほかにもyamlを作ることも出来る)
├── data # dataset関連はここに集約
│ ├── sampleSubmission.csv
│ ├── test.csv
│ └── train.csv
├── features # 作った特徴量は列ごとにpickle形式で吐き出す
│ ├── _features_memo.csv # 特徴量のメモ
│ ├── base_data.pkl
│ └── pca.pkl
├── outputs # 提出用
│ ├── 118547.csv
│ ├── 736294.csv
│ └── 829643.csv
├── requirements.txt
├── src # ソース
│ ├── feature_engineering.py # 特徴量エンジニアリング
│ ├── inference.py # (Kaggle Notebookでの)推論用
│ ├── mlruns # MLflowのログ
│ │ ├── 0
│ │ ├── 1
│ │ ├── 2
│ │ ├── 3
│ │ └── 4
│ ├── outputs # hydraのログ
│ │ └── 2020-12-12
│ ├── preprocess.py # 前処理
│ └── train.py # 訓練
└── utils.py
config
import hydra
@hydra.main(config_name="../config/config.yaml")
def main(cfg):
run(cfg)
hydraを使うので、下のようにyaml形式でパラメータを書き、上のようにデコレータを置くことでcfgに辞書型のデータが渡されます。
base:
# 存在する特徴量だとしても上書きするか
overwrite: true
seed: 1234
n_folds: 4
# optunaを使うかどうか
optuna: false
num_boost_round: 1500
# LightGBMのパラメータ
parameters:
objective: "multiclass"
num_class: 9
max_depth: 8
learning_rate: .02
metric: "multi_logloss"
num_leaves: 31
verbose: -1
# trainingに使用する特徴量
features: [
"base_data",
"pca",
]
覚えておいてほしいのが、hydraをデコレータとして持ってくるとカレントディレクトリが変更されるということです。
具体的に、src/outputs/2020-12-12のようにhydraに渡したconfigファイルなどが保存されるフォルダにカレントディレクトリが移動されてしまいます。
何も考えずにデータを読み込んだり書き込んだりすると事故ります。
気をつけましょう!
import hydra
@hydra.main()
def run():
cwd = hydra.utils.get_original_cwd()
data = pd.read_csv(cwd + "hogehoge.csv")
git関係
実行する前と実行したあとそれぞれのときにcommitします。
そうすることで、実行後に生成されるlogなどもgithubにアップロードをしたときにいつ生成されたファイルなのかわかるからです。(実行中に関係ないファイル操作をするとややこしくなりますが)
ここのデコレータは少し煩雑です。なぜなら、commit messageに含めるための実験名(rand)を引数として取る必要があるからです。
-
git_commitsを呼ぶ -
func_decorator()が呼ばれる -
before runningのcommitが行われる -
funcが実行される -
after runningのcommitが行われる - githubにpushされる
import git
def git_commits(rand):
def func_decorator(my_func):
print("experiment_name: ", rand)
repo = git.Repo(str(Path(os.getcwd()).parents[0]))
repo.git.diff("HEAD")
repo.git.add(".")
repo.index.commit(f"{rand}(before running)")
def decorator_wrapper(*args, **kwargs):
my_func(*args, **kwargs)
repo.index.commit(f"{rand}(after running)")
repo.git.push('origin', 'master')
return decorator_wrapper
return func_decorator
万一datasetをpushしてしまったとき
エラーを吐かれます。変にいじっても更に複雑になって収拾がつかなくなるのでおとなしくしましょう。 .gitignore の設定をちゃんと忘れない事はもちろんですが、ことが起きたとしたら、安全なversionの番号をコピーして後ろに戻しましょう。そして問題のcommitを削除するなどして難を乗り越えましょう。
git reset "version number"
特徴量エンジニアリング
少し長くなりますが、具体例があるほうがわかりやすいと思うので紹介します。
お気持ちとしては、列ごとに管理してからconfigで使いたい列を指定して読み込むほうが実験や再現がしやすくなるよね〜というところです。
Kaggleで使えるFeather形式を利用した特徴量管理法
この天音さんの記事を参考にFeatureクラスを書きました。ベースとなるそのクラスはutils.pyにあるのですが、あとで紹介します。(少し難解なので)
大事なポイントは
- クラス名が特徴量名となるクラスを作る
-
create_features()内のself.dataを更新する -
create_memo()にその特徴量に関するメモを残す
これらのクラスは最後のrun()内のglobals()で読み込まれて勝手に実行されるので野ざらしにしておいてOKです!(言い方おかしい気がするけど気にしない)
余談ですが、class書くのが割とだるいのでPyCharmでしたらライブテンプレートに登録することをオススメします。
from utils import Feature, generate_features, create_memo
from src.preprocess import base_data
import pandas as pd
import hydra
from sklearn.decomposition import PCA
# 生成された特徴量を保存するパス
Feature.dir = "features"
# trainとtestを結合して基本的な前処理を行ったデータを呼ぶ
data = base_data()
class Base_data(Feature):
def create_features(self):
self.data = data.drop(columns=["id"])
create_memo("base_data", "初期")
class Pca(Feature):
def create_features(self):
n = 20
pca = PCA(n_components=n)
pca.fit(
data.drop(
columns=["train", "target", "id"]
)
)
# カラム名
n_name = [f"pca_{i}" for i in range(n)]
df_pca = pd.DataFrame(
pca.transform(data.drop(
columns=["train", "target", "id"]
)),
columns=n_name
)
self.data = df_pca.copy()
create_memo("pca", "pcaかけただけ")
@hydra.main(config_name="../config/config.yaml")
def run(cfg):
# overwriteがfalseなら上書きはされない
# globals()からこのファイルの中にある特徴量クラスが選別されてそれぞれ実行される
generate_features(globals(), cfg.base.overwrite)
# デバッグ用
if __name__ == "__main__":
run()
実行するとfeatureの下に以下のようなファイルが生成されます。
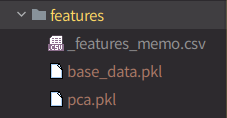
また、_feature_memo.csvはgithub上で見ることもできます。 良い感じ。
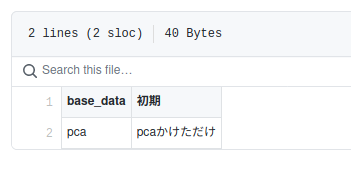
ちなみにですが、cfg.base.overwriteをtrueにすれば、既に実行し保存した特徴量も上書きするし、falseにすれば、保存されている特徴量は実行されません。
一回一回の計算が重いときは、基本falseにして、関数を上書きしたときにはfeatures/hoge.pklを削除してあげればfalseでも実行されるので良いと思います。
MLflow
今回の記事は書きたいことが盛り沢山なのでMlflow自体の解説は省きます。
そもそも論
実験はすべて乱数で管理しています。被ったときのことを考えてないのは内緒です。(エラーが出るとはずなので再実行する予定です)
rand = np.random.randint(0, 1000000)
hydraの功罪
mlflowも色々なファイルを生成するのですが、hydraと併用しているとカレントディレクトリが変更されてしまうので上手くいきません。実行はされますが、mlflowが作成したファイル群はhydraのフォルダの中に保存されてしまって悲しくなります。
ちゃんと元あったパスを指定してあげましょう。
mlflow.set_tracking_uri("file://" + hydra.utils.get_original_cwd() + "/mlruns")
tracking
便利すぎる。これさえあればもう人間はのんびり暮らしていける。
mlflow.lightgbm.autolog()
- 実行したパラメータ
- best_iteration数
- 最終的なスコア
- パッケージ化された学習済みモデル
- importance
これらが勝手に保存されるようになっているので僕らは何もすることがありません。あと追加して保存したいものはコードに書きましょうというお気持ち。具体的にconfigや使った特徴量は保存したいよね。
cd src
mlflow ui
を実行して出てきたリンクを踏んで実験を選択すると下のようなページになります。
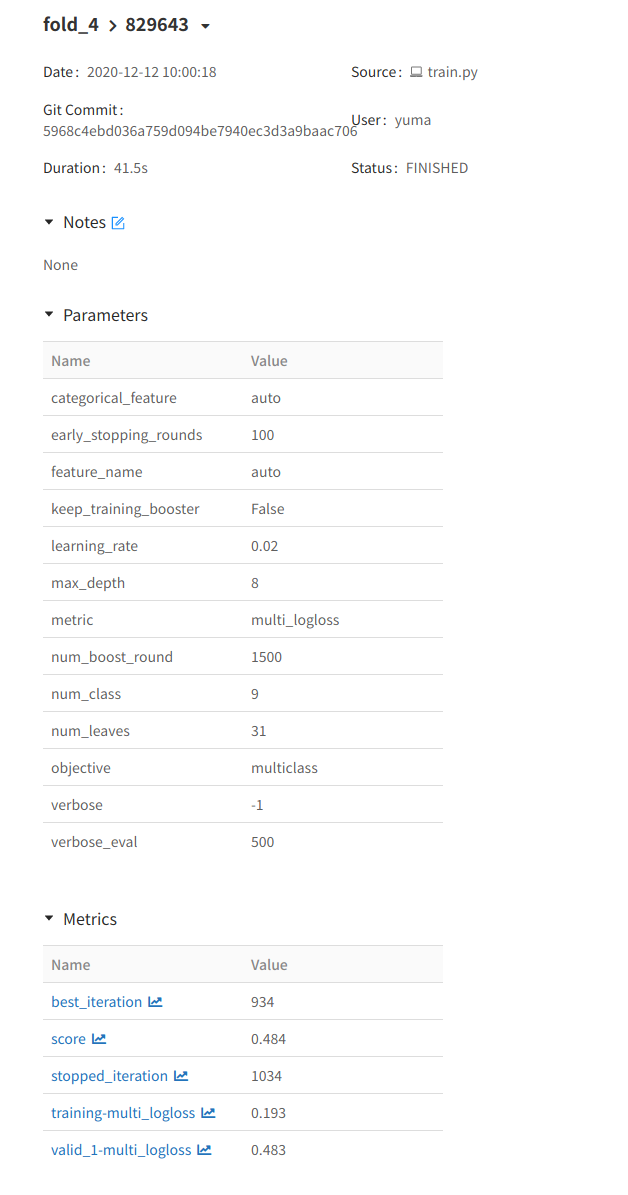
少し改造しよう
追加で保存したいもの
- hydraの生成物(config、log等々)
- 特徴量
- submit用ファイル
hydraが生成するファイルは下のとおりです。
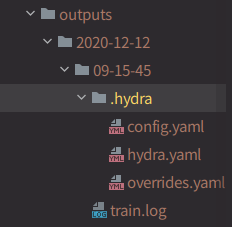
このとき、カレントディレクトリは09-15-45にあるので、以下のようにしてmlflowに保存します。最下行のコードは実行しているファイルから.pyをとって.logをつけたログファイルを指定しています。
本音を言えばglobでこのディレクトリ下にあるファイルを全てぶち込むほうが綺麗に書けると思ったのですが、メモとして吐き出したとても大きなファイルがあった場合に困りそうだったので一つ一つ指定しました。
また、hydraを使っていれば以下のコードで示したようなyamlファイルやlogファイルが吐き出されるので、このように関数として置いておくと便利だと思います。
mlflow.log_metrics()は辞書型の引数を持っていてkeyにmetric、itemにその値を入れるのが普通です。
import mlflow
import os
def save_log(score_dict):
mlflow.log_metrics(score_dict)
mlflow.log_artifact(".hydra/config.yaml")
mlflow.log_artifact(".hydra/hydra.yaml")
mlflow.log_artifact(".hydra/overrides.yaml")
# hydraでは実行したhoge.pyからhoge.logが生成されるのでそれも保存(少し煩雑)
mlflow.log_artifact(f"{os.path.basename(__file__)[:-3]}.log")
mlflow.log_artifact("features.csv") # 自分の場合は特徴量も吐き出しているので
score = {
"rmse": 123, # 例
"mae": 12, # 例
}
save_log(score)
次に特徴量です。念には念を入れて何らかの不手際があって再現がとれなくなっても特徴量名から実装して何とかしようみたいなお気持ちです。
use_cols = pd.Series(train.columns)
use_cols.to_csv("features.csv", index=False, header=False)
mlflow.log_artifact("features.csv")
最後にsubmit用ファイルです。実験名(rand)をつけて保存することを心がけています。これをmlflowに結びつけておくことでmlflow ui上でも変な予測値になってないかななど確認ができます。やっといて損はない。(と思ってる)
file_path = cwd / f"../outputs/{rand}.csv"
ss.to_csv(file_path, index=False)
mlflow.log_artifact(file_path)
おまけ(kaggle関係)
notebook onlyのときなど使えるかもしれないので実装をおいておきます。
イメージとしては、src下にnotebookで実行する用のinference.pyをおきます。また、datasetsにconfigや学習済みモデルをuploadしてinference.pyではconfigから読み込んで実行し、submission.csvを作成するようにしておけばかなり楽になるはずです。
結構駆け足なので何が便利なのかはちゃんと説明しておきます。もし要望があればottoコンペにnotebookをuploadしてそこでinferenceをするところまでやろうと思います。
便利なこと
- notebookにuploadする手間がなくなる
- inferenceに使うコードはconfigと学習済みモデルといった外部データに依存するので管理に頭を使う必要がない
- 何もせずともローカルで実行すれば 学習→終わる→upload→kaggle上で実行 までやってくれるのでちゃんと使えば効率化を図れる
Datasets
def add_datasets(rand):
"""upload to kaggle datasets
hydraパス内で実行して
notebooksの前に実行して
"""
metadata = {
"title": f"{rand}",
"id": f"chizuchizu/{rand}",
"licenses": [
{
"name": "CC0-1.0"
}
]
}
data_json = eval(json.dumps(metadata))
with open("dataset-metadata.json", "w") as f:
json.dump(data_json, f)
shutil.copy(".hydra/config.yaml", "config.yaml")
os.system("kaggle datasets create -p .")
Notebooks
def add_notebooks(rand, cwd, cfg):
"""
hydraパス内で実行して
:return: None
"""
meta = {
"id": f"chizuchizu/{rand} inference",
"title": f"{rand} inference",
"language": "python",
"kernel_type": "script",
"code_file": str(cwd / "inference.py"),
"is_private": "true",
"enable_gpu": cfg.kaggle.enable_gpu,
"dataset_sources": [
f"chizuchizu/{rand}",
] + cfg.kaggle.data_sources,
"competition_sources": cfg.kaggle.competitions,
}
data_json = eval(json.dumps(meta))
with open("kernel-metadata.json", "w") as f:
json.dump(data_json, f)
os.system("kaggle kernels push -p .")
細かいところ
実験名をconfigに追記しておけばnotebooksでも読み込みが簡単になると思ったので実装してみました。
def add_experiment_name(rand):
with open(".hydra/config.yaml", "r+") as f:
data = yaml.load(f)
data["experiment_name"] = str(rand)
# f.write(yaml.dump(data))
with open(".hydra/config.yaml", "w") as f:
yaml.dump(data, f)
最後にラッパーもおいておきます。
def kaggle_wrapper(rand, cwd, cfg):
def func_decorator(my_func):
def decorator_wrapper(*args, **kwargs):
my_func(*args, **kwargs)
add_experiment_name(rand=rand)
add_datasets(rand)
add_notebooks(rand, cwd, cfg)
return decorator_wrapper
return func_decorator
これから
技量を上げる
このようなまとめを書いたのはそれはそれで良くても、結局勝てなきゃエアプ勢にしかなれないので2021年はコンペがんばります。
今cassavaコンペちょっとやろうとしてます。
クラウドでも動くように
どちらかというとクラウドでも作業ができるようになりたいというお気持ちです。最近の画像コンペはハイパワーGPUを必要とするので、家の8GBメモリのGPUだと力が弱すぎて……
何にせよ、クラウドでも動くような(何の環境でも実験が可能な)コーディングを心がけていきたいです。
conda→Dockerへ
上のクラウドの話にも繋がりますが、今はanacondaでライブラリ等を管理しています。もちろん、依存関係の衝突も今まで何度も経験してきました。まだないですが、コンペ終盤で新しいパッケージをインストールしようとして環境汚染→復旧不能という自体に陥って終わることだけは避けたいです。
サスティナブルな社会にはDockerが求められているのではないのでしょうか。頑張ります。