動機
我が家のZaimデータを描画する基盤を作ったの記事で、airflowを使った似たような基盤を作っていた人のブログを見ていたら、Scrapyを使ったスクレイピングスクリプトのサンプルが掲載されていたので、試しに使ってみようと思った。
(参考元の記事)
「人とWebに優しい」Scrapyの使い方サンプル〜 #PyConJP 2017のつづき(なお野球)
やったこと
上記参考元の記事に掲載されていたgithubのリポジトリをフォークして、別ブランチで別なサイトをスクレイプしてくるサンプルを作ってみた。ソースは下記。
NORADのTLE軌道データを取得してDBに格納するサンプル
肝心のスクレイピング部分は、NORADのTLEを拾ってくるというマニアックなものなので、全くもってサンプルに向いていないけれど。
NORADってなに?
NORADとは北アメリカ航空宇宙防衛司令部。物々しい名前で、その名が示す通り米軍の一組織だけれども、毎年この時季になるとサンタクロースを追跡したりするお茶目なところです。
NORADがサンタ追跡60周年。きっかけは少女の間違い電話だった
TLEってなに?
TLEとはTwo Line Elementのこと。その名前の通り2行のテキストデータで表された人工衛星等の地球軌道上物体の軌道情報のことです。2行軌道要素形式@Wikipedia
なんで、こんな扱いにくそうなフォーマットなのかというと、まあ歴史ですね。
宇宙開発は東西冷戦時代からの多くの枯れた技術の遺産を使っているので、今も旧システムとの互換性のために、その当時から使われていた古いフォーマットを使う慣習が残っている。
それで何をしたのか?
このNORADのTLEをCelestrakというサイトが公開しているので、こいつらを取りに行って、そこに載っている軌道情報(軌道Epoch[日時]、平均運動、離心率、軌道傾斜角、昇交点赤経、近地点引数、平均近点角など)と付加情報(衛星カタログ番号、衛星名など、アポジ、ペリジ、軌道高度など)を取ってきたり計算したりして、Sqliteのデータベースに保存するというスクリプトを作った。
TLEのparseには、sgp4パッケージを使った。
本当はこのパッケージはTLEを軌道伝搬する(任意のEpoch[日時]での予測軌道を算出する)のに使うことができるのだけど、ここでは単純に情報をパースして必要な値を取り出すのみに使っている。
Scrapyフレームワークとファイル構成
ファイルをgit cloneして、scrape-space-objectブランチをチェックアウトする。
$ git clone https://github.com/inTheRye/scrapy-sample-baseball.git
$ git checkout scrape-space-object
ファイル構成を表示。
$ cd scrapy-sample-baseball
$ tree .
.
├── LICENSE
├── README.md
└── space_object
├── scrapy.cfg
└── space_object
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
└── tle.py
公式サイトにあるScrapyの構成は以下の通り。
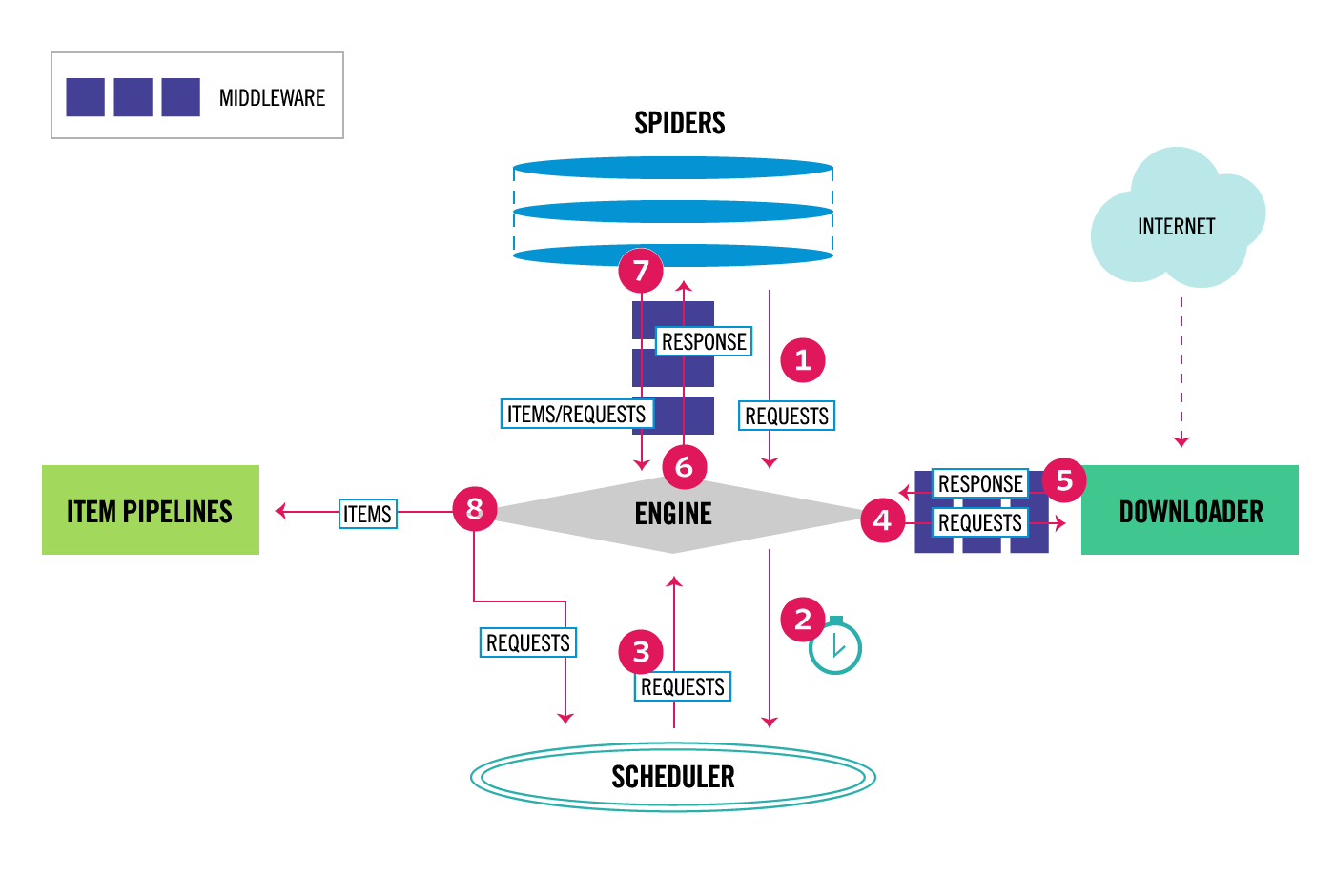
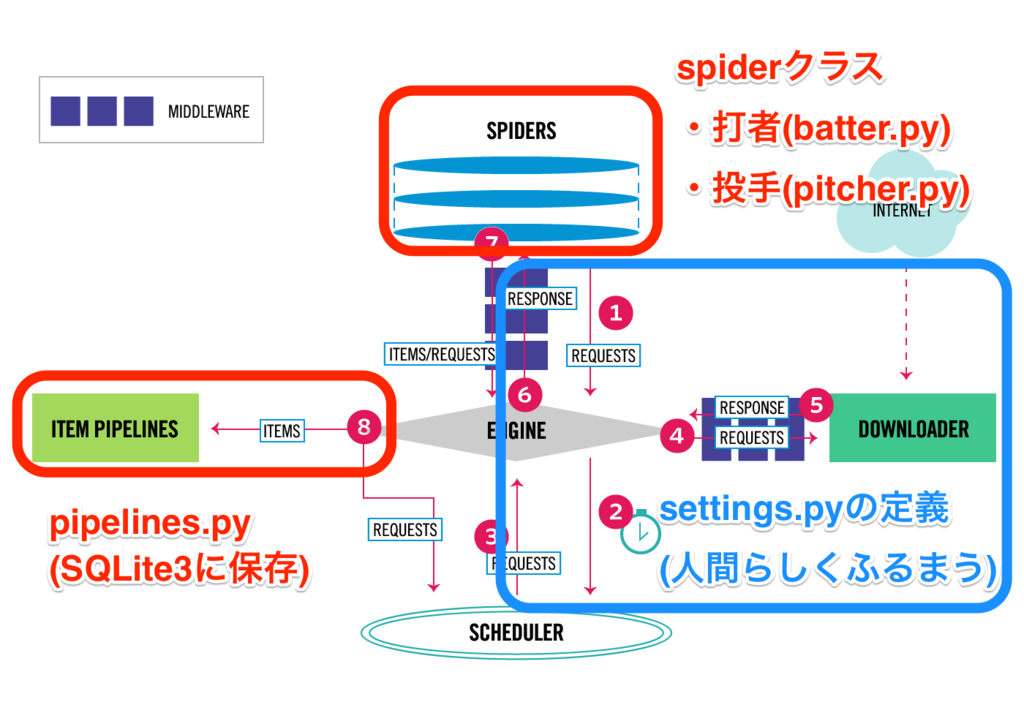
fork元のオリジナルのExampleの構成との対応は以下。
フレームワークと対応付けた元々のScrapyの使い方の説明は、「人とWebに優しい」Scrapyの使い方サンプル〜 #PyConJP 2017のつづき(なお野球)に詳しく載っているのでここでは割愛。
基本的にforkしてきたサンプルの構成をそのまま踏襲した。
items.pyで、軌道データを作る箱を作って、ディレクトリ名をbaseballからspace_objectに変更して、pitcher.py、batter.pyの代わりにtle.pyという名前でspiderを作成した。
スクレイピング実行
Scrapyのエンドポイントに移動して、コマンドを実行する。
$ cd scrapy-sample-baseball/space_object
$ scrapy crawl tle
(1ページを60秒の間隔をあけてcrawlする設定になっているので結構時間がかかります。)
space_object.dbが作成されて、DBが登録される。
カタログ番号とEpochで複合主キーに設定しているけどが、取ってくるデータに一部重複があるので、たまにDB登録できないエラーが表示されるけど、気にしない。
DBの中身確認
Sqliteに接続。
$ sqlite3 space_object.db
テーブルとスキーマを確認して、レコード件数をカウント。
sqlite> .tables
tle
sqlite> .schema tle
CREATE TABLE tle (
soname text,
satnum integer,
jdsatepoch text,
epoch text,
bstar text,
inclo real,
nodeo real,
ecco real,
argpo real,
mo real,
no real,
sma real,
apogee real,
perigee real,
altitude real,
create_date date,
update_date date,
primary key(satnum, jdsatepoch)
);
sqlite> select count(*) from tle;
5936
5936件が登録されている。
satnum(カタログ番号)でユニークな数を数える。
sqlite> select count(*) from (select * from tle group by satnum);
5832
satnum(カタログ番号)でユニークな数を数えると5832件。実際の軌道上物体はもっと多いが、NORADのTLEで公開されている物体としてはこのくらいの数のようだった。
テーブルの中身を確認。
sqlite> select * from tle limit 5;
INTELSAT 37E (IS-37E)|42950|2458068.44607586|2017-11-10 22:42:20.954304|0.0|0.0092|105.0882|9.96e-05|1.91850431103571|260.4552|1.00266670199563|42166.1658892|42161.9661390775|42170.3656393226|35788.0288892|2017-11-12 22:37:21|2017-11-12 22:37:21
BSAT-4A|42951|2458068.45300525|2017-11-10 22:52:19.653599|0.0|0.0032|318.0427|4.75e-05|1.58666486035403|94.1876|1.002687320207|42165.5878466516|42163.5849812288|42167.5907120743|35787.4508466516|2017-11-12 22:37:21|2017-11-12 22:37:21
VRSS-2|42954|2458068.66820079|2017-11-11 04:02:12.548256|0.00012619|98.0188|28.4031|0.0019508|3.05470318210851|185.1256|14.7690830848562|7017.23712303695|7003.54789685733|7030.92634921657|639.100123036948|2017-11-12 22:37:21|2017-11-12 22:37:21
IRIDIUM 133|42955|2458068.39008002|2017-11-10 21:21:42.913728|3.2758e-05|86.3978|257.4505|0.0001581|1.7551903622681|259.5724|14.3513141852162|7152.76669691538|7151.6358445006|7153.89754933017|774.629696915383|2017-11-12 22:37:21|2017-11-12 22:37:21
IRIDIUM 100|42956|2458068.45349697|2017-11-10 22:53:02.138208|2.0611e-05|86.3976|257.4177|0.0002204|1.52574763347167|272.7259|14.3513341730964|7152.76005555019|7151.18358723395|7154.33652386643|774.623055550192|2017-11-12 22:37:21|2017-11-12 22:37:21
実際のデータの中身はこんな感じ。
Scrapy使ってみた個人的な感想
とにかくhttpキャッシュが良い
オレオレスクリプトだと、試行錯誤してる時に元サイトにアクセスしまくってしまう時があってヒヤッとすることもあったのだけど、Scrapyだとsettings.pyでHTTPCACHE_ENABLED = Trueとしておけば、キャッシュが効いて以降のアクセスはキャッシュの有効時間HTTPCACHE_EXPIRATION_SECSまでは、キャッシュにアクセスしに行くので、元サイトに迷惑をかけずに済む。
意外に作るの楽
ちょっとしたスクレイピングに、重そうなフレームワーク使うのも面倒だしなーと思って、今まで使ってこなかったけど、作りが単純なので軽い使い方でも使えそうだ。
なんとなく使う前は、railsとかdjangoとか、Webアプリのフレームワークみたいなものを想像してたけど、そこまで重いものではなく、学習コストもそんなに高くはなかった。