はじめに
IT企業でseleniumをマクロとかPythonで動かす程度の、カスタマーサポート担当やってますー。
たまたま見つけたAI開発コンテスト「Neural Network Console Challenge」に参加してみたので、投稿しますー。
「Neural Network Console Challenge」とは
ソニーネットワークコミュニケーションズ株式会社がノンプログラミングでAI開発できるGUIツールである「Neural Network Console(以下NNC)」を、
ピクスタ株式会社が普段扱うことのできない10,000点もの人物画像データを提供することで、初心者にも優しいAI開発チャレンジになっているみたいです。
テーマ決め
このチャレンジでは画像分類のテーマを各自が決めて、NNCで学習。学習結果をプロセスとともに提出するというもの。
画像を見渡す中で人物が写った画像がやはり多そうだったので、まずは顔を抽出。
OpenCVの分類器でPIXTA画像から大量の顔を切り抜く。
画像の前処理?については下記記事を参考にさせていただきました。初心者にもわかりやすい投稿者様に感謝。
ディープラーニングでザッカーバーグの顔を識別するAIを作る
TensorFlowによるももクロメンバー顔認識
顔の抽出
# -*- coding:utf-8 -*-
import cv2
import numpy as np
from PIL import Image
# PIXTA画像を保存したフォルダ
input_data_path = './pixta_images/'
# 切り抜いた画像の保存先ディレクトリ
save_path = './cutted_face_images/'
# OpenCVのデフォルトの分類器のpath
cascade_path = './opencv/data/haarcascades/haarcascade_frontalface_default.xml'
faceCascade = cv2.CascadeClassifier(cascade_path)
# 顔検知に成功した数
face_detect_count = 0
# 集めた画像データから顔が検知されたら、切り取り、保存する。
types = ['*.jpg']
paths = []
for t in types:
paths.extend(glob.glob(os.path.join(input_data_path, t)))
for p in paths:
img = cv2.imread(p, cv2.IMREAD_COLOR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
face = faceCascade.detectMultiScale(gray, 1.1, 3)
if len(face) > 0:
for rect in face:
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
cv2.imwrite(save_path + 'cutted_face' + str(face_detect_count) + '.jpg', img[y:y+h, x:x+w])
face_detect_count = face_detect_count + 1
1500枚の画像から約2500くらいの顔が検出されました。検出した顔の中には、顔っぽく見える影やドット柄も含まれており、手作業で削除します。
1000枚程度を削除して、残ったのは1500の顔。
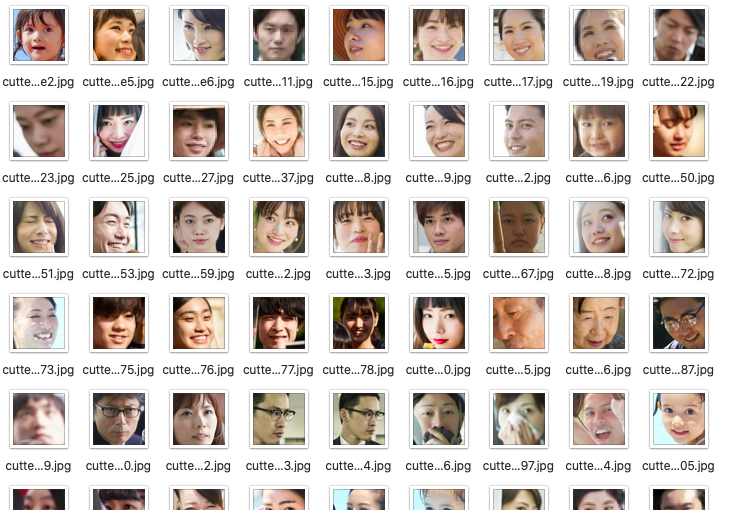
学習用データ提供:PIXTA
運営事務局からのテーマ例には嬉しい/悲しい/恥ずかしいなど、感情によって分類するというものがあったが、顔写真をみていると、笑顔ばっかり。
そこで、笑顔を何種類かに分類することに決めました。
データセットの作成
NNCにアップロードできる形にするため、1500の顔を笑顔の程度で分別していきます。
まず手始めに笑っているか笑っていないかの2つに分類し、それぞれフォルダにまとめました。さらに、ファイル名とラベルを定義したcsvを準備してNNCにアップロード。
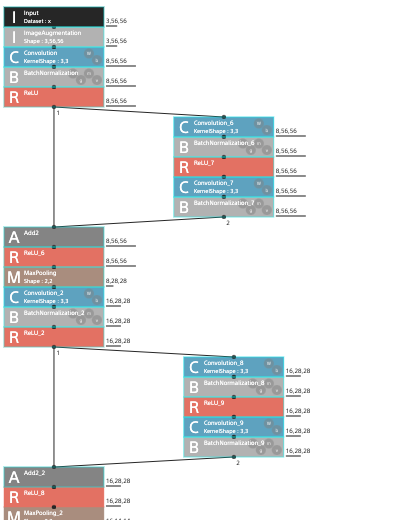
学習のモデルはSONYさんがYouTubeで配信しているNNCに関する説明動画を元に、以下のような物を作ってみました。
学習結果はというと、、、
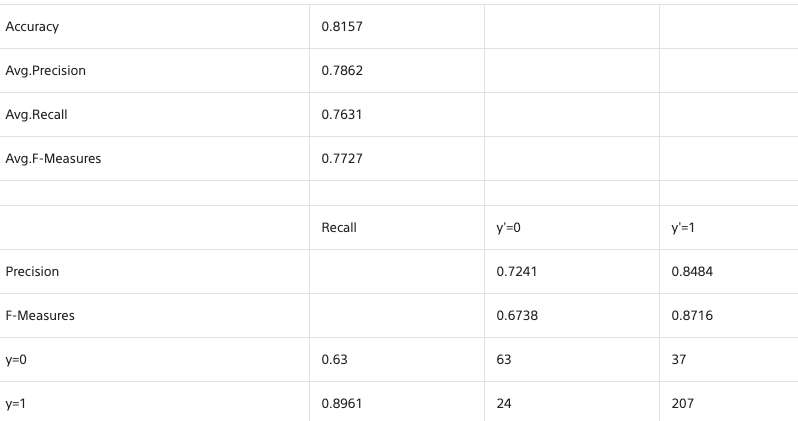
うーん、ラベルそれぞれで画像データの数にばらつきもあったし、こんなものなのかな。
よくわかりませんが、2つの分類では面白くないので、次は分類を増やしていきます。
- アハハ(声が出てる)
- ニコニコ(顔全体の笑顔)
- にこり(口もしくは目が笑う)
- フフフ(微笑み)
- 真顔
追加での顔抽出も行い、それぞれ200枚程度準備して学習データとテストデータに分けてアップロード。
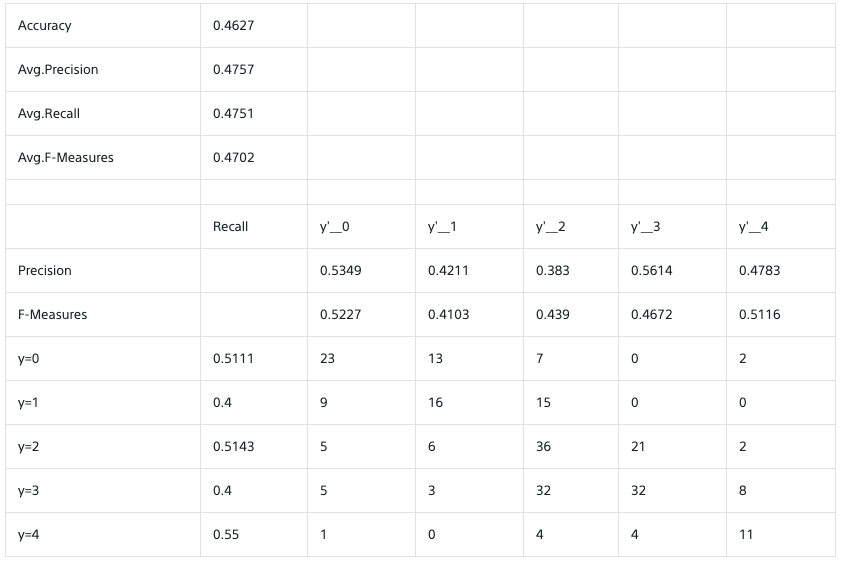
見事にグダグダな結果ですね。横に一つずれてるものも含めれば、なんとなく合ってるくらい。
原因は、私が分別する中でそもそも自分の中で定義できてないからかもしれません。抽出した笑顔をずっと見てると、何がなんだかわからなくなってしまい笑
分類を一つ減らし、4つでデータを作り直しました。
- アハハ(声が出てる)
- ニコニコ(口を開けてる)
- フフフ(口を閉じてる)
- 真顔
さっきより随分改善しました。が70%にも届かず。
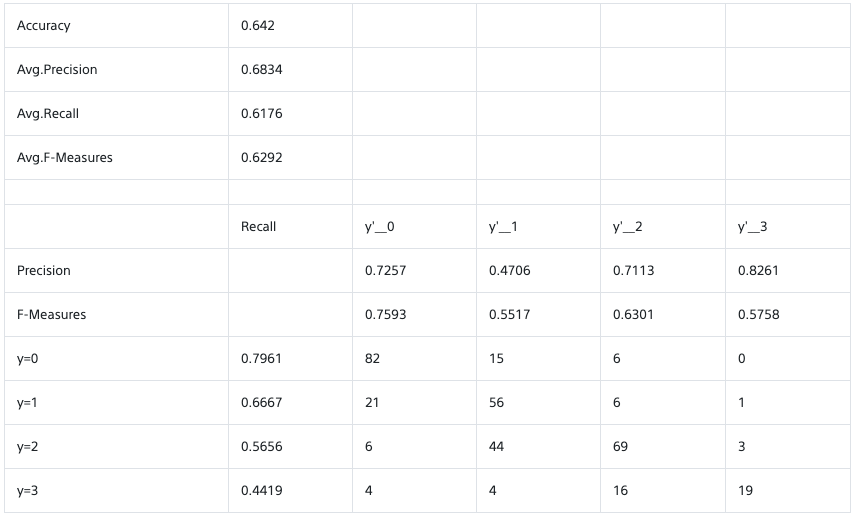
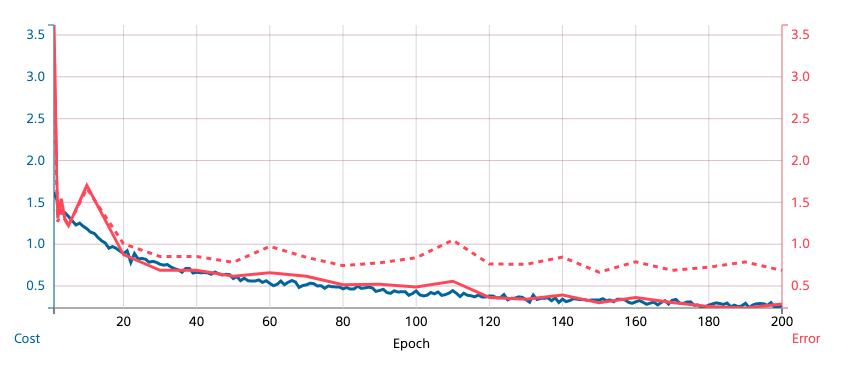
その後は以下の動画塔を参考に、過学習を防ぐためにImage Augmentationやcutout、Dropoutなど試してみるものの、なかなか精度は向上せず。
期限ということもあり、結局中間層を減らし、以下の結果を出してタイムアップのようです。
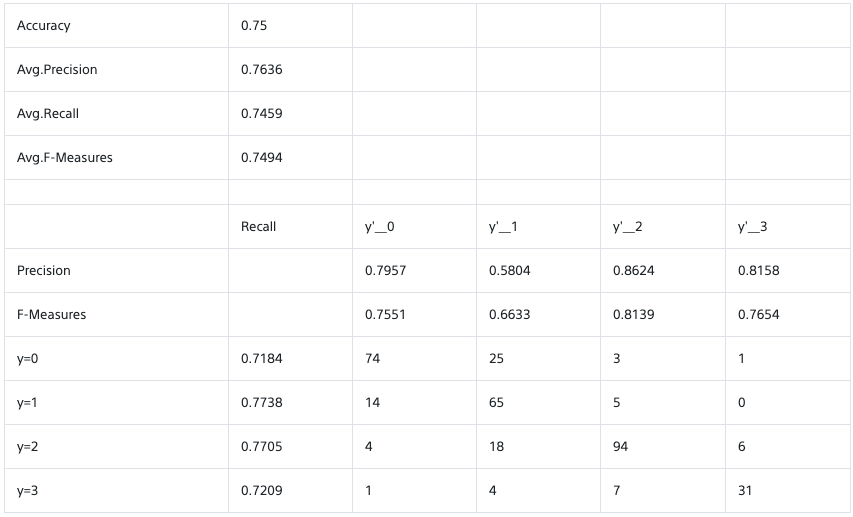

学習用データ提供:PIXTA
75%程度となかなか満足のいく結果とはなりませんでしたが、時間があれば、自分で準備した画像などで改めてチャレンジしてみたいと思いますー。知識ないながらも楽しく取り組めました!