⓪はじめに
前々から「流行りのAIとかディープラーニングやってみたい!」と思っていたので、ミーハー魂から2017年5月のGWの自由研究として、機械学習(ディープラーニング)の前提知識0からの勉強を決意。実際に作ったもののサンプル動画等はこちらより。最終的なコードはこちらに。
【つくったもの】
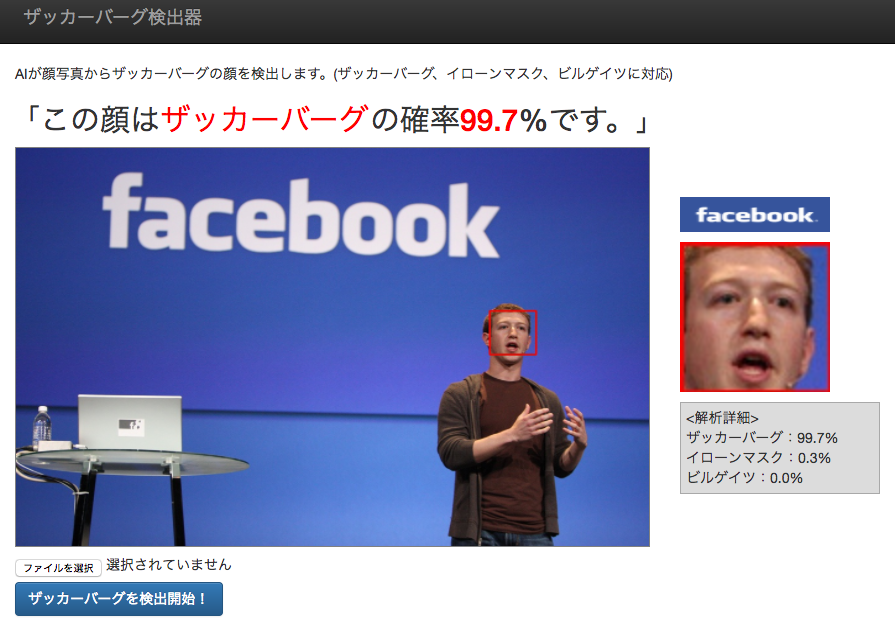
シリコンバレーの大御所起業家のマーク・ザッカーバーグ氏(Facebook)、ビル・ゲイツ氏(Microsoft)、**イーロン・マスク氏(SpaceX,Tesla)**の3人の顔を識別するAI。
(現状、まだこちらはネット上にアップしていません。時間がある時にアップしたいです *2017年5月時点)
【筆者(@AKIKIKIKIKIKIK)のプロフィール】
データ解析や機械学習の前提知識はなし。プログラミングの大体は独学。RailsでWEBアプリ作るのが好き。
【機械学習&ディープラーニングで参考にさせて頂いた文献】
流石にディープラーニングをやるのに、機械学習について全く知らんのはまずいと思い、まずは色々とウェブ上の情報を見てみて、どんなことができてどんなことができないのかを知る。
(「TensorFlow」「ディープラーニング」で出てくるWEBの情報などは大抵読んだ。後は「ニューラルネットワークってなんぞや?」ということを調べたり。)
特に参考にさせて頂いたのが、
TensorFlowによるももクロメンバー顔認識
[TensorFlowでアニメゆるゆりの制作会社を識別する]
(http://kivantium.hateblo.jp/entry/2015/11/18/233834)
のお二方の記事です。こちらの記事がなかったら実際に動作するものまでたどり着けなかったなと思うほど、参考にさせて頂きました。大変感謝ですm(_ _)m
【使用する機械学習ライブラリ】
機械学習のライブラリは色々あるが、今回は学習の対象をGoogle社の機械学習ライブラリであるTensorFlowに絞ることにした。理由は下記。
・Googleのライブラリということでコミュニティも盛んで今後も盛り上がりそう
・話題の囲碁AIのAlphaGoなどにも使用されているとのことで
・便利な関数も多く、機械学習初心者でも"機械学習"を体験しやすい
・今回取り組む前に自分が唯一知っていた機械学習ライブラリ
など理由によりチョイスしました。正直あまり深く他の機械学習ライブラリとの比較検討はしていません。もっと使いやすいものものあるのかもしれないです。今回の記事では、TensorFlowのセットアップ手順などは他記事にいっぱい書かれているので、ここでの記載を省きます。
【TensorFlowで何をするか決める】
比較的色んな人がやっていて、ちょうどいい難易度そうだった「TensorFlowでの顔識別機能の実装」を選択。過去の先人の方々はももクロ、おそ松さん、ゆるゆりなどを対象にしていて、顔認識させる対象は自分の好きなキャラや人物を選ぼうと思い、識別対象は自分の好きな人物であるFacebook創業者の「マーク・ザッカーバーグ」に決定。(顔画像を集めやすそうという観点からも)
【実際にやってみる】
以下に自分の取り組んだ手順を記載。尚、今回は「TensorFlowを理解して使いこなす」ことより、「ディープラーニングを体験すること」を念頭に進めました。TensorFlowを使いこなすにはまだまだ時間が必要だなと。。。
①学習用顔データの収集と準備

(まずはこのちょっと不気味なザッカーバーグ氏の顔データを準備するまでの流れ)
1.ザッカーバーグ氏の画像データを収集
MicroSoft社の検索エンジンBingのAPIを使用し**「zuckerberg」**のワードで検索時の画像データをクロールしてきて、PCへ保存する。
Bing Search API v2 から v5 へ移行した話
(Bingの画像検索APIの使い方などはこちらを参考にさせて頂きました。ありがとうございました。今回は基本pythonですが、rubyの方が得意なのでpythonの必要がない所はrubyで書いています。)
require "open-uri"
require "FileUtils"
require 'net/http'
require 'json'
# 保存先ディレクトリ
@dirName = "./zuckerberg_image/"
# 保存用ディレクトリを作る(ディレクトリがない場合は新たにディレクトリを作成)
FileUtils.mkdir_p(@dirName) unless FileTest.exist?(@dirName)
# 画像URLから指定フォルダに画像を保存する関数
def save_image(url, num)
filePath = "#{@dirName}/zuckerberg#{num.to_s}.jpg"
open(filePath, 'wb') do |output|
open(url) do |data|
output.write(data.read)
end
end
end
# 検索ワード
search_word = 'zuckerberg'
# 保存する枚数(APIの仕様上一気に150枚が限界っぽい)
count = 150
# Bing Search API(公式のコードをそのまま使用)
# https://dev.cognitive.microsoft.com/docs/services/56b43f0ccf5ff8098cef3808/operations/571fab09dbe2d933e891028f
uri = URI('https://api.cognitive.microsoft.com/bing/v5.0/images/search')
uri.query = URI.encode_www_form({
'q' => search_word,
'count' => count
# 'offset' => 150(指定した数だけ検索結果をスキップ)
})
request = Net::HTTP::Post.new(uri.request_uri)
request['Content-Type'] = 'multipart/form-data'
request['Ocp-Apim-Subscription-Key'] = '自分のAPIキーを代入' # Fix Me
request.body = "{body}"
response = Net::HTTP.start(uri.host, uri.port, :use_ssl => uri.scheme == 'https') do |http|
http.request(request)
end
# searchwordの検索画像をcountの枚数だけ保存する
count.times do |i|
begin
image_url = JSON.parse(response.body)["value"][i]["thumbnailUrl"]
save_image(image_url, i)
rescue => e
puts "image#{i} is error!"
puts e
end
end
これで指定したディレクトリにzuckerberg1.jpg,zuckerberg2.jpg,zuckerberg3.jpg...みたいな感じで画像データが保存されているかと思います。大体こんな感じ。この次にこの画像たちの顔部分だけ抽出して切り抜きます。
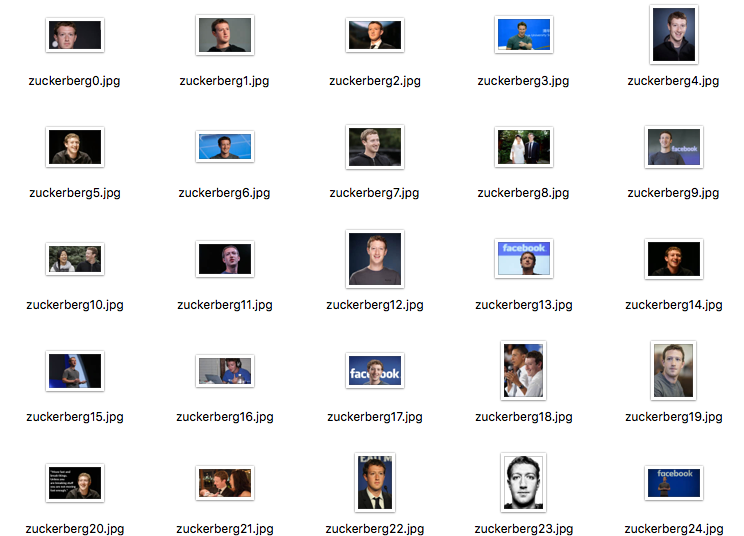
2.ザッカーバーグ氏の顔部分を抽出し切り抜く
画像処理ライブラリのOpenCVを使い、集めた画像データから顔を切り抜きます。
OpenCVは初めて使いましたが、セットアップや使い方などは下記のブログ等が非常に参考になりました。感謝ですm(_ _)m
Mac OS X で OpenCV 3 + Python 2/3 の開発環境を整備する方法
OpenCVを使った顔認識(Haar-like特徴分類器)
Python OpenCVの基礎 ついに顔検出してみます
ググれば他にも色々あると思われます。今回はOpenCVのセットアップの手順や詳細な使い方は割愛します。1

(OpenCVの分類器が検出した顔部分を切り抜いて保存します。OpenCV便利!)
# -*- coding:utf-8 -*-
import cv2
import numpy as np
# 先ほど集めてきた画像データのあるディレクトリ
input_data_path = './zuckerberg_images/zuckerberg'
# 切り抜いた画像の保存先ディレクトリ(予めディレクトリを作っておいてください)
save_path = './cutted_zuck_images/'
# OpenCVのデフォルトの分類器のpath。(https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xmlのファイルを使う)
cascade_path = './opencv/data/haarcascades/haarcascade_frontalface_default.xml'
faceCascade = cv2.CascadeClassifier(cascade_path)
# 収集した画像の枚数(任意で変更)
image_count = 300
# 顔検知に成功した数(デフォルトで0を指定)
face_detect_count = 0
# 集めた画像データから顔が検知されたら、切り取り、保存する。
for i in range(image_count):
img = cv2.imread(input_data_path + str(i) + '.jpg', cv2.IMREAD_COLOR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
face = faceCascade.detectMultiScale(gray, 1.1, 3)
if len(face) > 0:
for rect in face:
# 顔認識部分を赤線で囲み保存(今はこの部分は必要ない)
# cv2.rectangle(img, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (0, 0,255), thickness=1)
# cv2.imwrite('detected.jpg', img)
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
cv2.imwrite(save_path + 'cutted_zuck' + str(face_detect_count) + '.jpg', img[y:y+h, x:x+w])
face_detect_count = face_detect_count + 1
else:
print 'image' + str(i) + ':NoFace'
これで指定した保存先に、cutted_zuck1.jpg、cutted_zuck2.jpg、cutted_zuck3.jpgのような感じで、顔部分が切り抜かれた画像たちが保存されていると思います。因みに、ザッカーバーグ氏の画像の場合、意外と奥さんと写ってる写真が多く、奥さんの顔も一緒に切り抜かれて保存されていたので、そこは手動で取り除きました。(後はなぜか顔じゃないものを顔と認識してしまったものとかも除外しました。)

こんな風になってればOK!全部で350枚くらいの顔データが集まりました。因みにこれだけ同一人物の顔データが集まると結構と不気味w
参考にさせて頂いた顔識別の先人のお方も書いてますが、顔認識させるときは絶対自分の好きな人物を選ぶといいと思いますw
(因みに、OpenCVは顔が斜めになってると検知しにくいらしく、画像を少しずつ回転させながら検知させるという手法もあるようですが、なぜかザッカーバーグ氏はほぼ綺麗に写っているのか、ほぼ顔を認識してくれました。ありがとうザッカーバーグ!)
3.ビルゲイツとイーロンマスクにも参加してもらう
ここまで作業をして、ある根本的なミスに気づく。
「ザッカーバーグの顔だけだと、ザッカーバーグの顔は識別できるようになるかもしれないが、"人間の顔" = "ザッカーバーグ"と識別するAIができるんじゃないか。ってか、そもそも今回やりたい識別って入力画像に対して、対応していると思われるラベルを出力して分類する(後程記載)のにラベルが1種類しかないって識別の選択肢がないやん。。。これじゃ識別結果が全部ザッカーバーグになるよ…」
(動き出し当初は識別の仕組みがよくわかっていなかった…orz)
ということで、最低3つくらいのラベル分けにしたいと思い、Microsoft創業者の世界一の億万長者ビルゲイツ氏とSpaceX,Tesla創業者で、自動運転車を作ってたり、人類を火星に送り込もう目論む現役バリバリのイローンマスク氏に参戦してもらうことにしました。壮観なメンバーになって参りました。(最初はイローンマスクでなくスティーブ・ジョブズを選んだが、ジョブズ氏の画像は妙に白黒が多いので、他データとの整合性が取れなくなりそうなので、ジョブズ氏断念。)
なので、実質**「ザッカーバーグとビルゲイツとイーロンマスクの顔を識別するAI」**になります。


全く同じ方法でゲイツ氏とマスク氏の顔データもそれぞれ350枚ほど収集しました。


相変わらず大量の顔は怖い。ちょっと笑える。
4.顔画像たちを整理してまとめる
TensorFlowに集めたデータを学習させる前準備として、まずはTensorFlowへ学習させる学習用データと学習後にモデルの精度をチェックする検証用データの2つに分けます。まず検証用データにそれぞれ100枚を割り当てて残りを学習用データに当てました。検証用データ300枚と学習用データ700枚ほどになりました。
この学習用顔データと検証用顔データたちを以下のようなディレクトリ構成にまとめました。
/data
/train
/zuckerbuerg
/elonmusk
/billgates
/test
/zuckerbuerg
/elonmusk
/billgates
この整理した顔画像データたちを、TensowFlowへの入力データとして、一気に読み込めるように、学習用、検証用それぞれ顔画像ファイルのパスを1つのテキストファイルにまとめたい。この時、各画像が誰の顔に対応しているのかのラベルも一緒につけます。今回はザッカーバーグ:0 イーロンマスク:1 ビルゲイツ:2というラベル分けにしました。
./data/train/zuckerberg/cutted_zuck0.jpg 0
./data/train/zuckerberg/cutted_zuck1.jpg 0
./data/train/zuckerberg/cutted_zuck10.jpg 0
~省略~
./data/train/elonmusk/cutted_elon0.jpg 1
./data/train/elonmusk/cutted_elon1.jpg 1
./data/train/elonmusk/cutted_elon10.jpg 1
~省略~
./data/train/billgates/cutted_gates0.jpg 2
./data/train/billgates/cutted_gates10.jpg 2
./data/train/billgates/cutted_gates100.jpg 2
テキストファイルを出力する簡単なスクリプト。
(またrubyですみません。。もうこれ以降rubyは出てきません。)
require 'fileutils'
train_data_path = "./data/train/data.txt"
test_data_path = "./data/test/data.txt"
FileUtils.touch(train_data_path) unless FileTest.exist?(train_data_path)
FileUtils.touch(test_data_path) unless FileTest.exist?(test_data_path)
test_zuck_data_paths = Dir.glob("./data/test/zuckerberg/*.jpg")
test_elon_data_paths = Dir.glob("./data/test/elonmusk/*.jpg")
test_gates_data_paths = Dir.glob("./data/test/billgates/*.jpg")
train_zuck_data_paths = Dir.glob("./data/train/zuckerberg/*.jpg")
train_elon_data_paths = Dir.glob("./data/train/elonmusk/*.jpg")
train_gates_data_paths = Dir.glob("./data/train/billgates/*.jpg")
File.open(test_data_path, "w") do |f|
test_zuck_data_paths.each { |path| f.puts("#{path} 0") }
test_elon_data_paths.each { |path| f.puts("#{path} 1") }
test_gates_data_paths.each { |path| f.puts("#{path} 2") }
end
File.open(train_data_path, "w") do |f|
train_zuck_data_paths.each { |path| f.puts("#{path} 0") }
train_elon_data_paths.each { |path| f.puts("#{path} 1") }
train_gates_data_paths.each { |path| f.puts("#{path} 2") }
end
データ収集の段階で思ったことは、「意外と人間の顔だけが大量にあるというのは不気味だ」という気づきかもしれないです。画像データの準備が出来たらいよいよTensorFlowで学習開始!
続きとおまけ
続きの第2部はこちら:ディープラーニングでザッカーバーグの顔を識別するAIを作る②(AIモデル構築編)
「ディープラーニングでザッカーバーグの顔を識別するAIを作る」<記事全編>
第1部:ディープラーニングでザッカーバーグの顔を識別するAIを作る①(学習データ準備編)
第2部:ディープラーニングでザッカーバーグの顔を識別するAIを作る②(AIモデル構築編)
第3部:ディープラーニングでザッカーバーグの顔を識別するAIを作る③(データ学習編)
第4部:ディープラーニングでザッカーバーグの顔を識別するAIを作る④(WEB構築編)
GitHub:https://github.com/AkiyoshiOkano/zuckerberg-detect-ai
できたAIで試したおまけ画像たち。思った以上の精度で当ててくるということにびっくり。
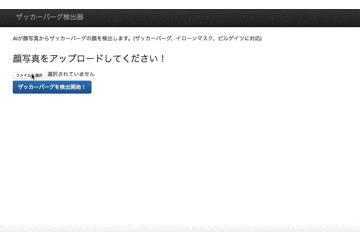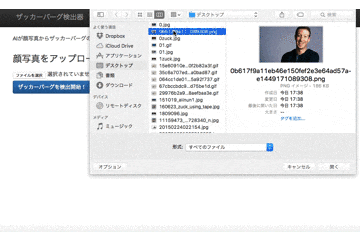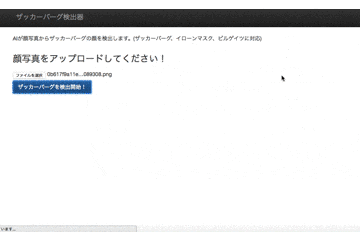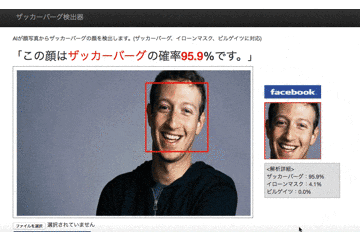
①正面を向いていれば多少角度があっても判定してくれる。
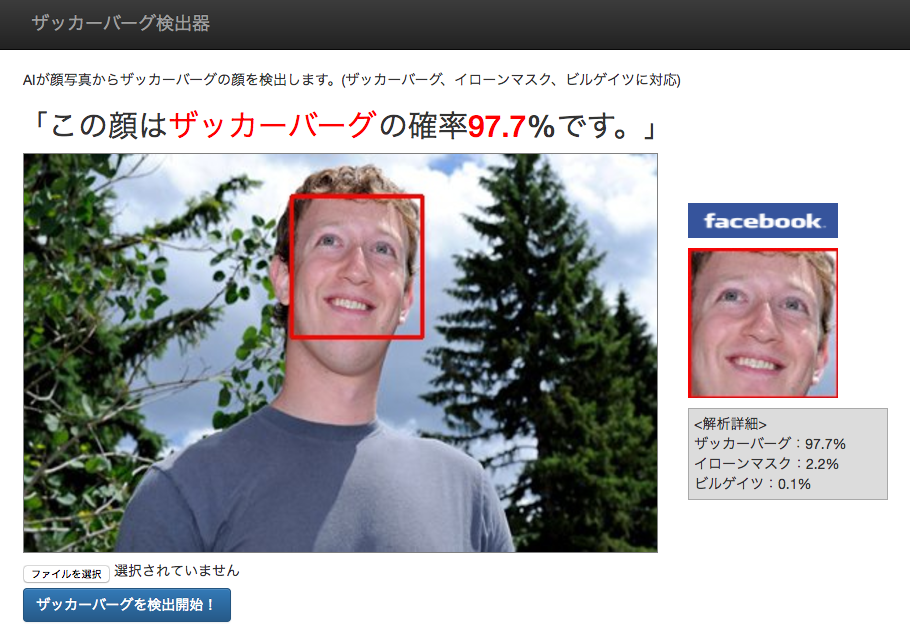
②意外と顔が小さくてもちゃんと判定してくれる。
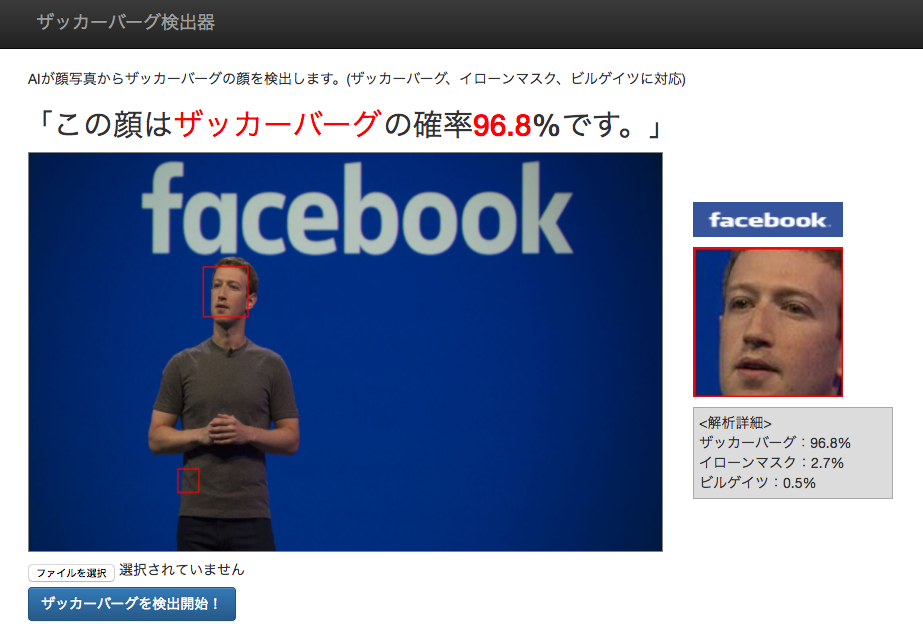
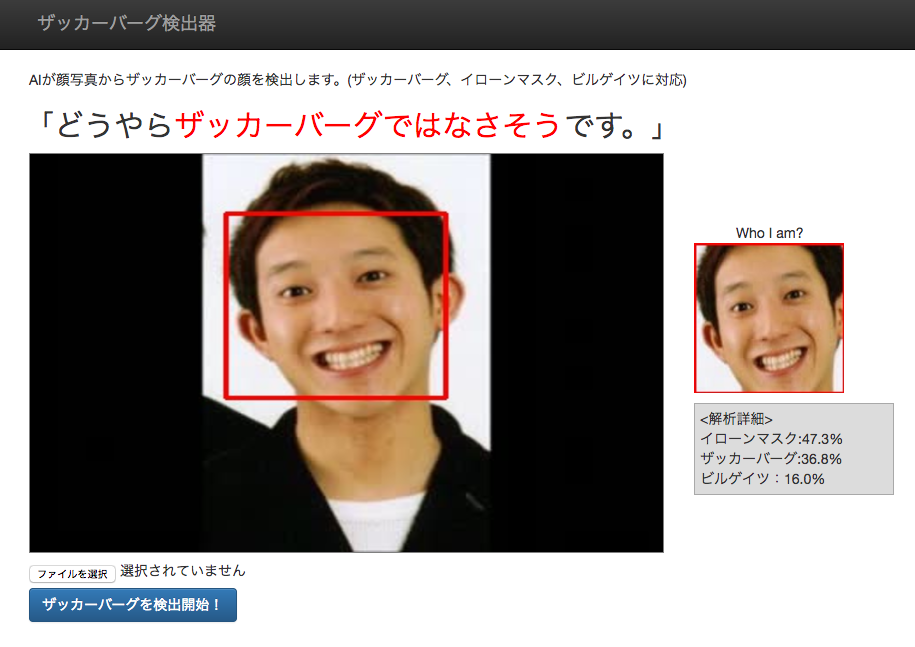
③ザッカーバーグに似てる芸人のサバンナ高橋氏も見分ける
-
自分の時は
ImportError: No module named cv2のエラーが出た。参照させてもらった記事がどれか忘れてしまったが、エラーをググって解決 ↩