機械学習勉強中です。
業務上の課題に対してマネージメントサービスを活用して解決していく、という事をやりたいのですが、機械学習、ハードル高いです。
この前、amazon Personalizeを使ってレコメンドを実現しようとか思って試して見ましたが、少し独自の要件が含まれるだけで一気に難しくなる。そしてトレーニングに時間がかかるため、トライ&エラーに時間がかかって効率悪い。
案外、sage makerとか使って地味に頑張る方が近道なんじゃ?と思いました。
そんなわけで勉強のために、タイタニックします。ただやっても頭に入りにくいので自分なりにアレンジという意味でSageMaker使います。SageMaker使い慣れておきたいというのもある。
あとランダムフォレストでやってみるのが普通っぽいけど、xGBoostってやつにしてみてます。勾配ブースティングというのが使われてるとかなんとかで、タイタニックの上位入賞者もよく使ってるらしい。
タイタニック?
そんなわけでまずはタイタニックですよ。あの有名な某大型客船沈没映画のやつ。
知らない人には何のこっちゃ?、って話だけど機械学習エンジニアにとってはタイタニック=kaggleのチュートリアル。
kaggleっていう機械学習のコンペのプラットフォーム的なやつがありまして、これは腕のいいデータサイエンティストが、企業側(など)が求める課題に対して最良の分析モデルを提供するようなところです。
でも素人に縁がないかというとそうでもなくて、練習用のためだけのコンペもあったりします。それの代表的なのがタイタニック。
テーマとしてはどんな人が生存しやすいか、または死にやすいかというものを分析するという暗いものだったりします。(なんでそういう重いテーマなんだろう?日本人とはやはり文化が違うなー)
乗客のデータがCSVで提供され、それから如何に生死を予想できるかというゲーム。スコアが高いと優勝です。あとdead or aliveの情報も提供されるので教師あり学習です。
準備
kaggle
ざっくりの流れ。
- https://www.kaggle.com/
- アカウント作る
- ログインする
- https://www.kaggle.com/competitions
- titanicをsearch
- https://www.kaggle.com/c/titanic
- join competition
- https://www.kaggle.com/c/titanic/data
- Dataタブ開く
- test.csvとtrain.csvをDL
S3
データの保存先になるので作って起きます。
| Key | Value |
|---|---|
| bucket name | 任意 |
バケットポリシー(バケット名、ロール名は各自)
{
"Version": "2012-10-17",
"Id": "SagemakerS3BucketAccessPolicy",
"Statement": [
{
"Sid": "SageMakerS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::00000000:role/service-role/AmazonSageMaker-ExecutionRole-xxxxxxxx"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::sagemaker-xxxxxxxx",
"arn:aws:s3:::sagemaker-xxxxxxxx/*"
]
}
]
}
SageMaker
ざっくりの流れ。
- aws console開く
- SageMaker開く
- ノートブックインスタンスの作成。名前はtitabook, インスタンスはt2.medium、IAMロールは新規作成してます
- 作成されたノートブックインスタンスをopen
- test.csv と train.csvをuploadしておく
- 「New」からconda_python3を選択して、新しいノートブックを立ち上る
- 名前は適当に変えます。titanoteとしました
- 下記コードをノートブックに入力し、Shift+Enter
bucket = '自身で作ったバケット名'
prefix = 'sagemaker/xgboost-dm'
# Define IAM role
import boto3
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import sagemaker
from sagemaker import get_execution_role
from sagemaker.predictor import csv_serializer
# 指定したROLEを読み込み
role = get_execution_role()
# train.csvの先頭を表示してみる
df_train = pd.read_csv('./train.csv')
df_train.head(10)
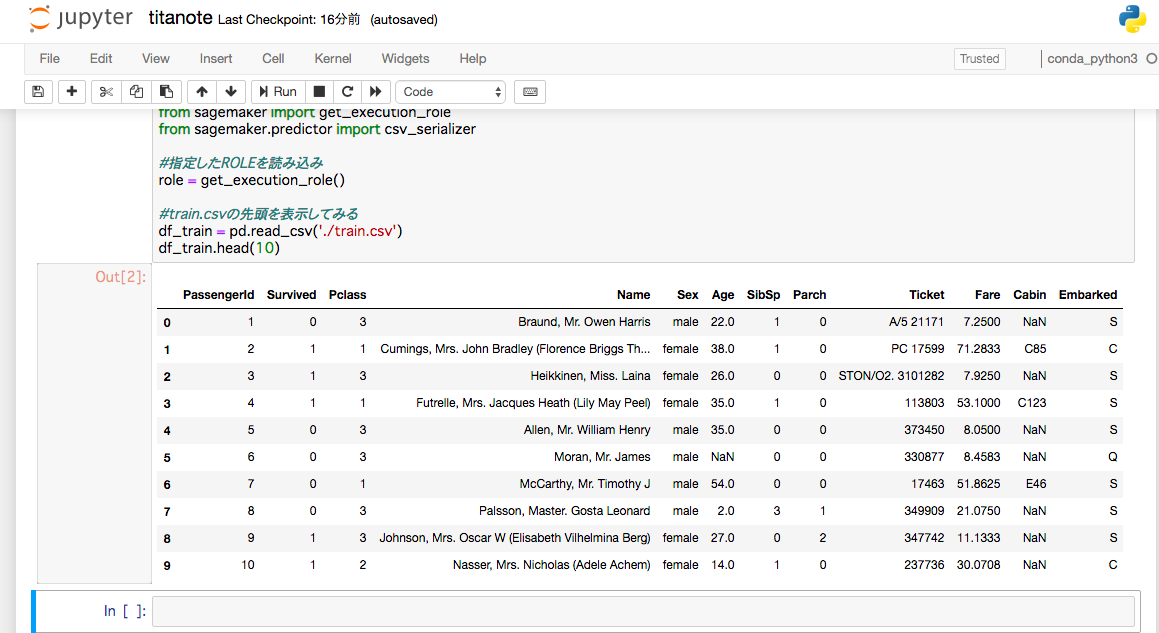
以上で下準備完了です。
データの確認、前処理
データの確認
今回データは二種類あります
| データ名 | ファイル名 | 補足 |
|---|---|---|
| 学習用データ | train.csv | 正解あり |
| 本番予測用データ | test.csv | 正解なし |
前処理
とは言っても、高スコアを狙うという目的ではないので最低限の事だけやっておきます。
まず欠損値の確認
df_train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
AgeやCabin(キャビン番号)が大きく欠損していますね。
おおよそこちらのサイト様の内容を元にこれらを埋めます。(けっこう雑な埋め方ではあります)。
Cabinはあるなしで1or0にしました。
full_data = [df_train,df_test]
for i,dataset in enumerate(full_data):
#欠損値の処理
dataset["Embarked"] = dataset["Embarked"].fillna("S")
dataset["Age"] = dataset["Age"].fillna(df_train["Age"].median())
#カテゴリ変数の処理
dataset = pd.get_dummies(dataset,columns=["Embarked"])
dataset["Sex"] = dataset["Sex"].map({"male":0,"female":1})
dataset["Cabin"] = dataset["Cabin"].map(lambda x: 0 if x is None else 1)
if i==0:
df_train = dataset
else:
df_test = dataset
## 不要なカラムの削除
df_train = df_train.drop(["Name","Ticket"], axis=1)
df_test = df_test.drop(["Name","Ticket"], axis=1)
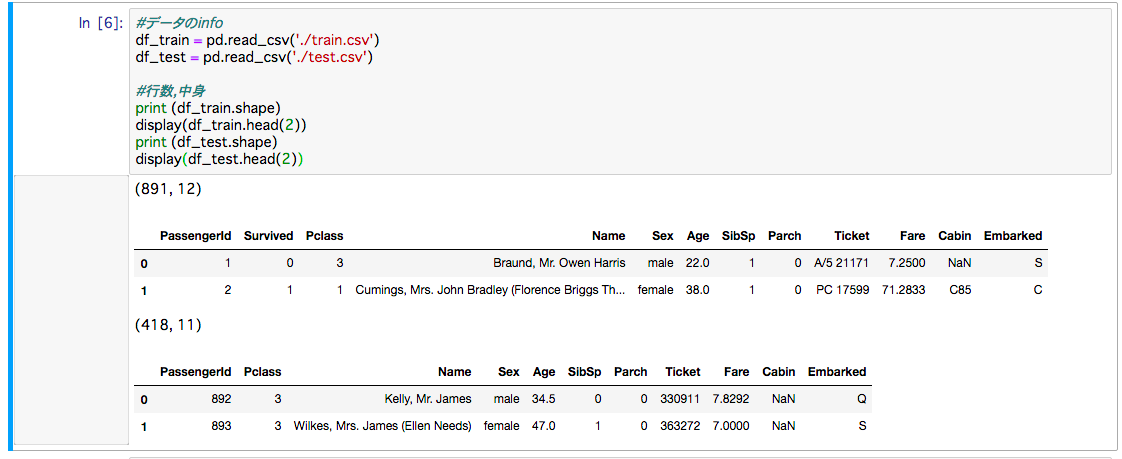
こうなる
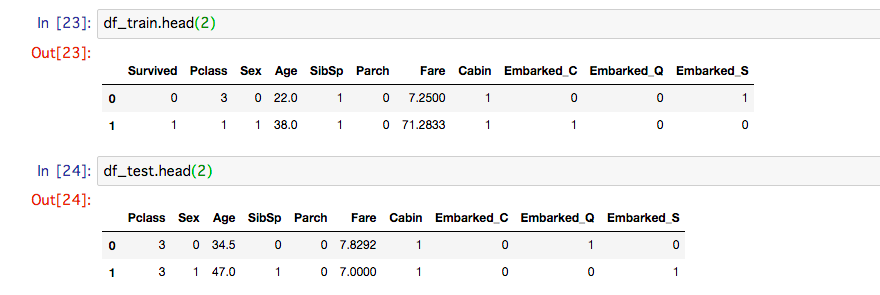
トレーニング
計算にはxgboost用のECRイメージをつかったDocker環境で行います。
なのでデータをまずS3に置く。
df_trainから検証用のデータも作られてます。
(このあたりはあまりよくわかっていない)
train_data, validation_data, test_data = np.split(df_train.sample(frac=1, random_state=1729), [int(0.7 * len(df_train)), int(0.9 * len(df_train))]) # Randomly sort the data then split out first 70%, second 20%, and last 10%
# 念のため各データフレームのサイズを確認
df_train.shape, train_data.shape, validation_data.shape, test_data.shape
training_features = np.array(df_train.drop(['Survived'], 1).columns)
dump_svmlight_file(X=train_data.drop(['Survived'], axis=1), y=train_data['Survived'], f='train.libsvm')
dump_svmlight_file(X=validation_data.drop(['Survived'], axis=1), y=validation_data['Survived'], f='validation.libsvm')
# Boto3を使ってS3へファイルをコピーする
boto3.Session().resource('s3').Bucket(bucket).Object(os.path.join(prefix, 'train/train.libsvm')).upload_file('train.libsvm')
boto3.Session().resource('s3').Bucket(bucket).Object(os.path.join(prefix, 'validation/validation.libsvm')).upload_file('validation.libsvm')
実行
from sagemaker.session import s3_input
# 対象リージョンのxGboostのコンテナを指定。(ジョブが実行される仮想環境)
containers = {'ap-northeast-1': '501404015308.dkr.ecr.ap-northeast-1.amazonaws.com/xgboost:latest'}
sess = sagemaker.Session()
# Sagemaker Setting
xgb = sagemaker.estimator.Estimator(containers['ap-northeast-1'],
role,
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
output_path='s3://{}/{}/output'.format(bucket, prefix),
sagemaker_session=sess)
# Hyper Parameter
# objective パラメータ:XGBoost にどのような問題 ( 分類、回帰、ランク付けなど ) を解決するかを指示
# binary:logistic:バイナリ分類の問題
xgb.set_hyperparameters(eta=0.1,
objective='binary:logistic',
num_round=25)
# Input File指定
# 訓練データとS3を連携してあげる
s3_input_train = sagemaker.s3_input(s3_data='s3://{}/{}/train'.format(bucket, prefix), content_type='libsvm')
s3_input_validation = sagemaker.s3_input(s3_data='s3://{}/{}/validation/'.format(bucket, prefix), content_type='libsvm')
# Trainning実行
xgb.fit({'train': s3_input_train, 'validation': s3_input_validation})
正常に終わると下記のように出力される。3分くらいか。m4.xlargeが1台で2円もかかってないくらい?
2019-06-29 11:43:38 Starting - Starting the training job...
2019-06-29 11:43:39 Starting - Launching requested ML instances......
2019-06-29 11:44:46 Starting - Preparing the instances for training.........
2019-06-29 11:46:38 Downloading - Downloading input data
2019-06-29 11:46:38 Training - Training image download completed. Training in progress..
Arguments: train
[2019-06-29:11:46:39:INFO] Running standalone xgboost training.
[2019-06-29:11:46:39:INFO] File size need to be processed in the node: 0.03mb. Available memory size in the node: 8452.55mb
[11:46:39] S3DistributionType set as FullyReplicated
[11:46:39] 623x11 matrix with 4287 entries loaded from /opt/ml/input/data/train
[11:46:39] S3DistributionType set as FullyReplicated
[11:46:39] 178x11 matrix with 1227 entries loaded from /opt/ml/input/data/validation
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 48 extra nodes, 0 pruned nodes, max_depth=6
[0]#011train-error:0.125201#011validation-error:0.252809
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 42 extra nodes, 0 pruned nodes, max_depth=6
[1]#011train-error:0.117175#011validation-error:0.224719
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 42 extra nodes, 0 pruned nodes, max_depth=6
[2]#011train-error:0.117175#011validation-error:0.224719
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 42 extra nodes, 0 pruned nodes, max_depth=6
[3]#011train-error:0.11557#011validation-error:0.230337
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 48 extra nodes, 0 pruned nodes, max_depth=6
[4]#011train-error:0.109149#011validation-error:0.224719
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 46 extra nodes, 0 pruned nodes, max_depth=6
[5]#011train-error:0.11236#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 58 extra nodes, 0 pruned nodes, max_depth=6
[6]#011train-error:0.110754#011validation-error:0.224719
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 56 extra nodes, 0 pruned nodes, max_depth=6
[7]#011train-error:0.110754#011validation-error:0.224719
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 58 extra nodes, 0 pruned nodes, max_depth=6
[8]#011train-error:0.110754#011validation-error:0.224719
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 48 extra nodes, 0 pruned nodes, max_depth=6
[9]#011train-error:0.107544#011validation-error:0.230337
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 62 extra nodes, 0 pruned nodes, max_depth=6
[10]#011train-error:0.104334#011validation-error:0.224719
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 54 extra nodes, 0 pruned nodes, max_depth=6
[11]#011train-error:0.102729#011validation-error:0.230337
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 52 extra nodes, 0 pruned nodes, max_depth=6
[12]#011train-error:0.104334#011validation-error:0.230337
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 58 extra nodes, 0 pruned nodes, max_depth=6
[13]#011train-error:0.099518#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 54 extra nodes, 0 pruned nodes, max_depth=6
[14]#011train-error:0.101124#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 48 extra nodes, 0 pruned nodes, max_depth=6
[15]#011train-error:0.101124#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 50 extra nodes, 0 pruned nodes, max_depth=6
[16]#011train-error:0.099518#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 56 extra nodes, 0 pruned nodes, max_depth=6
[17]#011train-error:0.101124#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 50 extra nodes, 0 pruned nodes, max_depth=6
[18]#011train-error:0.099518#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 52 extra nodes, 0 pruned nodes, max_depth=6
[19]#011train-error:0.099518#011validation-error:0.247191
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 54 extra nodes, 0 pruned nodes, max_depth=6
[20]#011train-error:0.096308#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 52 extra nodes, 0 pruned nodes, max_depth=6
[21]#011train-error:0.096308#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 50 extra nodes, 0 pruned nodes, max_depth=6
[22]#011train-error:0.099518#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 58 extra nodes, 0 pruned nodes, max_depth=6
[23]#011train-error:0.096308#011validation-error:0.241573
[11:46:39] src/tree/updater_prune.cc:74: tree pruning end, 1 roots, 46 extra nodes, 0 pruned nodes, max_depth=6
[24]#011train-error:0.097913#011validation-error:0.241573
2019-06-29 11:46:51 Uploading - Uploading generated training model
2019-06-29 11:46:51 Completed - Training job completed
Billable seconds: 38
モデルホスティング(Model Hosting)
トレーニングが終わったらモデルとしてデプロイしないといけないみたいです。
## ml.c4.xlargeのインスタンスでデプロイ
xgb_predictor = xgb.deploy(initial_instance_count=1,
instance_type='ml.c4.xlarge')
これは10分くらいかかった。
これでエンドポイントが作られます。次はいよいよ計算です。
予測の精度確認(評価 / Evaluation)
# データの受け渡しのための設定を行っておく
xgb_predictor.content_type = 'text/csv'
xgb_predictor.serializer = csv_serializer
# 500行ごとの小バッチに区切ってxgb_predictorで予測算出する
def predict(data, rows=500):
split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))
predictions = ''
for array in split_array:
predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')])
return np.fromstring(predictions[1:], sep=',')
# read test set
test = pd.read_csv('test.csv')
# 欠損値の処理
test["Embarked"] = test["Embarked"].fillna("S")
test["Age"] = test["Age"].fillna(test["Age"].median())
# カテゴリ変数の処理
test = pd.get_dummies(test,columns=["Embarked"])
test["Sex"] = test["Sex"].map({"male":0,"female":1})
test["Cabin"] = test["Cabin"].map(lambda x: 0 if x is None else 1)
# 不要なカラムの削除
test = test.drop(["Name","Ticket"], axis=1)
# 前項目で作成したtest_dataからターゲット項目を削除して予測を出力
predictions = predict(test.as_matrix())
display(predictions)
print("mean : {}".format(np.mean(predictions)))
dfresult = pd.DataFrame(np.round(predictions), test.PassengerId)
dfresult.columns = ['Survived']
dfresult.to_csv('predictions.csv')
print("done.")
そんなわけで、こういう結果になりました。
array([0.56800085, 0.64323086, 0.64390188, 0.69936836, 0.67838591,
0.70015025, 0.64323086, 0.87944376, 0.7285533 , 0.077229 ,
0.67082649, 0.75037909, 0.87944376, 0.6986953 , 0.87944376,
0.87372106, 0.88438755, 0.7285533 , 0.67082649, 0.64323086,
0.86085993, 0.74320841, 0.87944376, 0.87944376, 0.80679947,
0.42183638, 0.87944376, 0.70266461, 0.87944376, 0.16312739,
0.73075742, 0.87944376, 0.16312739, 0.16312739, 0.87944376,
0.7285533 , 0.69936836, 0.66299492, 0.69936836, 0.077229 ,
0.49640083, 0.87372106, 0.56800085, 0.89312547, 0.87944376,
0.67082649, 0.87944376, 0.72054607, 0.86085993, 0.73744482,
0.87944376, 0.88816524, 0.87372106, 0.80679947, 0.88816524,
0.07131565, 0.43970123, 0.7364583 , 0.78286159, 0.87952745,
0.67852372, 0.88816524, 0.71235019, 0.7285533 , 0.80679947,
0.88816524, 0.66185677, 0.87944376, 0.87372106, 0.77982104,
0.72054607, 0.66185677, 0.43970123, 0.87372106, 0.87952745,
0.87952745, 0.69936836, 0.6986953 , 0.89312547, 0.72054607,
0.75469542, 0.86095446, 0.75037909, 0.67082649, 0.86530024,
0.64865762, 0.67082649, 0.68408245, 0.72054607, 0.87372106,
0.67838591, 0.72054607, 0.80667645, 0.69936836, 0.87372106,
0.72054607, 0.86085993, 0.43970123, 0.66185677, 0.47898954,
0.87944376, 0.87372106, 0.72054607, 0.72054607, 0.70015025,
0.16312739, 0.66185677, 0.72054607, 0.69936836, 0.89312547,
0.75995058, 0.72054607, 0.87944376, 0.7285533 , 0.86095446,
0.63214946, 0.7364583 , 0.78312886, 0.87944376, 0.87372106,
0.88816524, 0.72054607, 0.87944376, 0.63466513, 0.72054607,
0.75604331, 0.71235019, 0.16312739, 0.75304621, 0.69936836,
0.47898954, 0.72438419, 0.077229 , 0.7364583 , 0.43970123,
0.67082649, 0.7364583 , 0.89312547, 0.66299492, 0.21170847,
0.07131565, 0.87952745, 0.77982104, 0.87372106, 0.75037909,
0.71276873, 0.87944376, 0.66299492, 0.87372106, 0.87372106,
0.87944376, 0.67082649, 0.077229 , 0.49640083, 0.07131565,
0.7364583 , 0.87952745, 0.63281286, 0.75037909, 0.71381521,
0.7364583 , 0.75469542, 0.88816524, 0.7364583 , 0.75304621,
0.16312739, 0.87944376, 0.077229 , 0.87372106, 0.66299492,
0.7364583 , 0.7364583 , 0.67838591, 0.7364583 , 0.21170847,
0.80667645, 0.87944376, 0.87519258, 0.80667645, 0.7796855 ,
0.89312547, 0.87944376, 0.87944376, 0.72054607, 0.87952745,
0.75995058, 0.88816524, 0.70015025, 0.07131565, 0.75304621,
0.87372106, 0.87372106, 0.64950532, 0.7016952 , 0.80667645,
0.56800085, 0.80667645, 0.71235019, 0.86530024, 0.69936836,
0.78286159, 0.68346721, 0.87952745, 0.87372106, 0.86530024,
0.87372106, 0.62455928, 0.86530024, 0.87372106, 0.67082649,
0.16312739, 0.7364583 , 0.87944376, 0.6986953 , 0.62455928,
0.87944376, 0.67082649, 0.86095446, 0.87874675, 0.69936836,
0.88816524, 0.66299492, 0.86530024, 0.71235019, 0.72438419,
0.72456229, 0.68558294, 0.72054607, 0.67205954, 0.88438755,
0.87944376, 0.87372106, 0.7285533 , 0.67082649, 0.87944376,
0.66185677, 0.86085993, 0.7285533 , 0.89312547, 0.87944376,
0.6986953 , 0.80667645, 0.87944376, 0.67082649, 0.16312739,
0.87944376, 0.88816524, 0.87944376, 0.87372106, 0.64865762,
0.87372106, 0.66185677, 0.87944376, 0.69936836, 0.47898954,
0.7364583 , 0.72054607, 0.4697313 , 0.89312547, 0.71235019,
0.72891057, 0.66185677, 0.87372106, 0.74470991, 0.89312547,
0.67082649, 0.86530024, 0.7364583 , 0.69936836, 0.70015025,
0.87944376, 0.72054607, 0.87944376, 0.78286159, 0.7364583 ,
0.87372106, 0.86530024, 0.75037909, 0.88816524, 0.86530024,
0.66299492, 0.74470991, 0.72054607, 0.75469542, 0.15313464,
0.64323086, 0.7364583 , 0.87944376, 0.7364583 , 0.69936836,
0.87944376, 0.64323086, 0.7364583 , 0.87519258, 0.47898954,
0.67082649, 0.80667645, 0.16312739, 0.87944376, 0.56800085,
0.62455928, 0.88816524, 0.75995058, 0.69936836, 0.72054607,
0.6986953 , 0.80679947, 0.70906991, 0.86085993, 0.42183638,
0.68408245, 0.7285533 , 0.7364583 , 0.62455928, 0.86085993,
0.74320841, 0.86095446, 0.86530024, 0.67082649, 0.87944376,
0.72054607, 0.7364583 , 0.89312547, 0.87372106, 0.87952745,
0.70266461, 0.87944376, 0.87944376, 0.87372106, 0.89312547,
0.80667645, 0.87944376, 0.7364583 , 0.74186629, 0.67082649,
0.87372106, 0.89312547, 0.64323086, 0.87944376, 0.7364583 ,
0.86530024, 0.64323086, 0.21170847, 0.86095446, 0.64865762,
0.74320841, 0.89312547, 0.64323086, 0.88816524, 0.88816524,
0.87944376, 0.86530024, 0.87944376, 0.80667645, 0.15313464,
0.73075742, 0.84910911, 0.67082649, 0.72054607, 0.73744482,
0.07131565, 0.87944376, 0.88816524, 0.69936836, 0.87944376,
0.21170847, 0.64865762, 0.077229 , 0.87944376, 0.88816524,
0.86530024, 0.87944376, 0.70096177, 0.75304621, 0.87519258,
0.87952745, 0.66299492, 0.86530024, 0.84910911, 0.07131565,
0.72054607, 0.67082649, 0.64865762, 0.74186629, 0.89312547,
0.80667645, 0.72054607, 0.7016952 , 0.71235019, 0.14230555,
0.87944376, 0.86818522, 0.15313464, 0.70096177, 0.15171826,
0.87944376, 0.7364583 , 0.87944376, 0.71235019, 0.64323086,
0.87952745, 0.75995058, 0.87944376, 0.87944376, 0.75037909,
0.88816524, 0.86530024, 0.87874675, 0.7364583 , 0.74470991,
0.72054607, 0.87944376, 0.61581296, 0.69936836, 0.87944376,
0.64323086, 0.69936836, 0.16312739])
mean : 0.7211633707133938
done.
test.csvを使う所を想定できてなくて、冗長的になってる部分もあってお恥ずかしいですが、手戻りが発生するとめんどくさいしお金もかかるしでここまでとします。(というかdf_test作ってたな。素直にあれ使ってよかったのか)
xgb_predictor.predict(array)うんちゃらのあたりで、testデータを検証してる感じですね。結果が1に近いほど優秀。
そして平均値72%?
いまいちすね。。
でもせっかくなのでkaggleでsubmitしてみます。
Submit Predictionsを開いてpredictions.csvをおもむろにぶん投げます。くらえ。
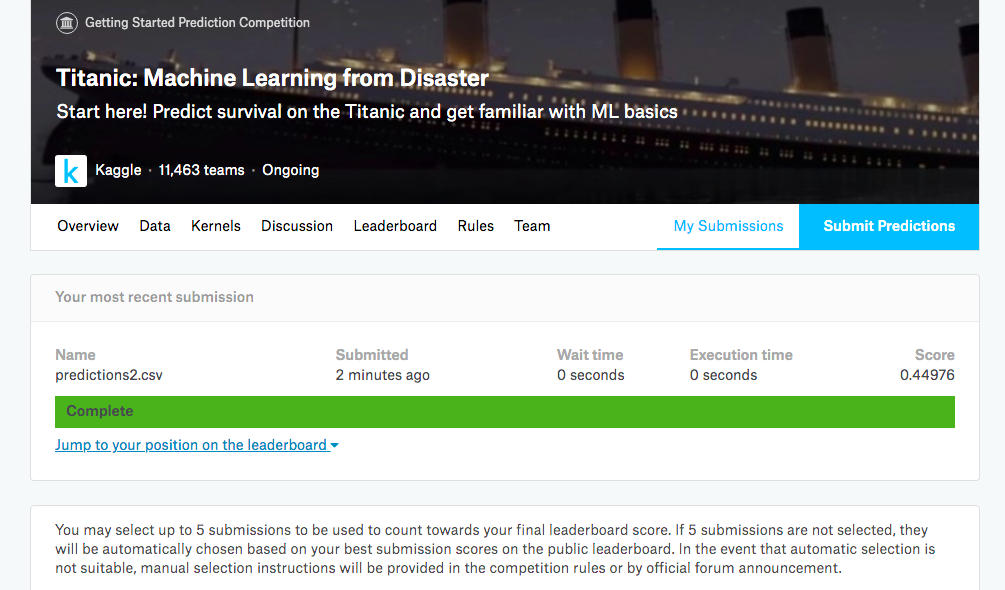
…スコアは0.44976ですってよ。調整のやり甲斐はありますね。やらないけど。
でもまあええっす。やりたい事はできた。
参考にさせていただいたサイトさま
Thx!!
最後に。
エンドポイントとかnotebookはしっかり消しておきましょう。
死ぬほど請求きて死んだら嫌だし。何がどうお金かかるかややこしいので念のため全部消す。